source:Hacker Noon
Over the years the amount of data that’s getting generated has increased tremendously due to the advancement of technology and the variety of sources that’s is available in the current market. Most of the data now are unclean and messy and needs advanced tools and techniques to be able to extract meaningful insights from it.
These unstructured data, if mined properly could achieve ground-breaking results and help a business achieve outstanding results. As most companies want to stay ahead of their competitors in the market, they have introduced Machine Learning in their workflow to streamline the process of predictive analytics. The state-of-of-art Machine Learning algorithms could produce interesting results if tuned properly with the relevant features and the correct parameters.
However, the traditional Machine Learning algorithms lacks in performance and ability in comparison to its sub-field Deep Learning which works on the principle of Neural Networks. It also takes away the hassle of feature engineering in Machine Learning as more data it gets, the better it learns. To deploy Deep Learning algorithms in the workflow, one needs to have powerful computers with computational capacity.
In this article, you would learn about one of the classes of Deep Learning – Capsule Networks.
Introduction
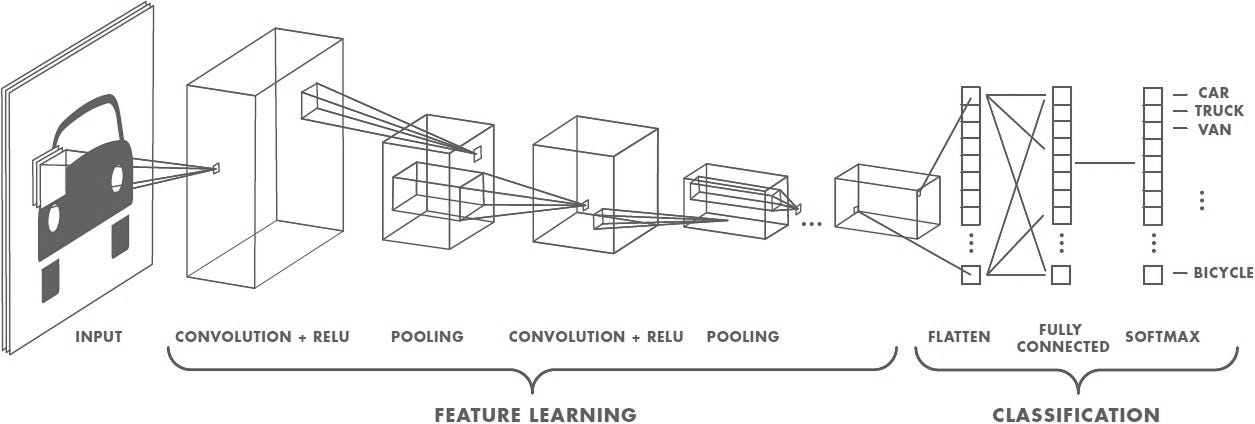
Convolutional Neural Networks or CNN is a class of Deep Learning which is commonly used for working with image data. In 2012, a paper was published which used Deep Convolutional Network to recognize images. Since then, Deep Learning made its breakthrough in all fields from Computer Vision to Natural Language Processing and more often than not gave impressive results. It prompted researches to try different techniques to various applications.
However, despite its insurmountable capabilities, Deep Learning was not going to work everywhere. The flaws starts to emerge when used extensively over a period of time for various purposes. In Convolutional Neural Network, the convolution operation are the main building blocks which detects key features. During training, these weights of these convolution operations are tweaked to identify key features in the image.
During face recognition, the convolutions could be triggers by ears or eyes. Once all the components are found, the face would be identified. However, the capabilities of Convolutional Neural Network could not stretch beyond this point. In a structured facial image, the CNN would work fine but when the image is disjointed and components of a face are misplaced, then it fails to identify the face correctly.
An important point to understand is that the features in the lower level are combined with the upper level features as the weighted sum and the following layer neuron’s weights multiplies the activation of a preceding layer and added. Despite all these, the relationships between features are not taken into account in this context. Convolutional Neural Network fails in the fact that the relationships between features is not considered which is resolved by the Capsule Networks.
Understanding Capsule Networks
For correct image recognition, the hierarchical relationship between the features of the image should be considered. To model these relationships, Capsules provides a new building block. It helps the model to identify the image based on its previous experience instead of relying on independent features. The use of vectors instead of scalars makes it possible to comprehend such rich feature representation. In Convolutional Neural Network, it was the weighting of input scalars, the scalar summation, and so on, whereas in Capsule Networks, the scalars are replaced by vectors. There is matrix multiplication, scalar weighting, and sum of the vectors. There also a non-linear vector-to-vector representation.
To encode more relational and relative information, vectors help to a large extent. With less training data, you could also get more accuracy using the Capsule Networks. A capsule could detect an image rotated in any direction. The vectors information of features like size, orientation allows the Capsule to provide a richer representation of the features. Instead of more examples, one example with a vector representation is enough for a Capsule Network to train.
In general, smaller objects make up any real object. Suppose, the trunk, roots, and crown forms the hierarchy of a tree. The branches and the leaves are further extensions of the crown. Now, there is some fixation points made by our human eye whenever it sees any object. To recognize this object later on, its relative positions and the fixation point’s nature are analysed by our brain. It decreases the hassle of processing every detail in our brain. The crown of a tree could be identified just by looking at some branches and leaves. The tree is identified after our brain combines such hierarchical information. These objects could be termed as entities.
To recognize certain entities, the CapsNet takes into account the group of neurons or the Capsules. The capsules, corresponding to each entity gives –
- The probability of the existence of the entity.
- The entities instantiation parameters.
The properties of an entity such as size, hue, position, etc., are the instantiation parameters. A rectangle is a geometric object and you would know about its instantiation parameters from its corresponding capsule. A rectangle consists of a six-dimensional capsule. As the probability of an entity existence is represented by the output vector’s length it should follow the condition 0 <= P <= 1. The capsule output could be transformed using the formula.
Vj = (||Sj||^2/ (1 + ||Sj||^2)) * (Sj / ||Sj||)
Here, s is the capsule output. It is a non-linear transformation known as the squashing function. Just like the ReLU activation in Convolutional Neural Network, this is the capsule networks activation function.
In a nutshell, a group of neurons is known as capsule whose activation v = < v1, v2, vn). The entities existence probability is represented by its length and also the instantiation parameter. There are several layers present in a CapsNet. The simple entities corresponds to the lower layer capsules. The output of the high-level capsules are obtained by its combination with the low-level capsules. The complex entities presence are bet by the low-level capsules. For example, a house presence could be comprehended by the presence of a rectangle and a triangle.
The low level capsules receives a feedback from the high-level capsules after its presence of a high-level entity was agreed by the low-level capsules. This is known as coupling effect and the bet on the high-level capsule is increased as a result of it. Now, suppose there are two capsule levels where the circles, triangles form the lower levels and the house, cars forms the high-level.
There would a high activation vectors for the rectangles, triangles capsules. The presence of the high-level objects would be bet by the rectangles, triangles, relative positions. The presence of the house would be agreed increasing the size of the output vector and it would be repeated four-five times which would increase the bets on the house presence compared to the boat or car.
CapsNet Mathematics
Consider layers l and l+1 with capsules m and n. At layer l+1, the capsule activations would be calculated based on the layer l activations. u and v denotes the activations of l and l+1 layers respectively.
At l+1 layer, for capsule j –
- At layer l, the prediction vectors are first calculated and is the product of the weight matrix and the activation.
- For the capsule j of layer l+1, the output vector is calculated. It is calculated by taking the prediction vectors weighted sum.
- The activation is then calculated by applying the squashing function.
The squashing function is computed by adding an epsilon to the square root of the sum of squares and it implements the norm manually.
There is a certain advantage of using the Capsule Networks. The Convolutional Neural Network has pooling layers. The primitive type of Routing Mechanism is the MaxPool which is generally used. In a 4×4 grid of local pool, the higher layer is routed to the most active feature and in routing the higher-level detectors doesn’t have any say. The CapsNet’s routing by agreement mechanism could be compared to this. The Capsule Networks is advantageous over Convolutional Neural Network as it has routing mechanism which are super dynamic. The real-time information detection makes it dynamic in nature.
Conclusion
Deep Learning has revolutionised the analytical Eco space to a large extent. Its capabilities are causing more and more advanced technologies to be developed and several complex business problems are solved. From media to healthcare, everywhere Deep Learning is used to achieve impressive results.
Capsule Networks has been an upgrade over Convolutional Neural Network in classifying images or text. It makes a framework much more human-like and takes the drawbacks that CNN has. Face detection is an important application used over various industries to detect threat, surveillance, and so on. Thus having a system with accurate results could be achieved using the CapsNet.
Dimensionless has several blogs and training to get started with Python, and Data Science in general.
Follow this link, if you are looking to learn more about data science online!
Additionally, if you are having an interest in learning Data Science, Learn online Data Science Course to boost your career in Data Science.
Furthermore, if you want to read more about data science, you can read our blogs here