So you want to become a data scientist? Is that because of the hype around this field lately? A lot of companies have realized the importance of data science in their business and are hiring professionals with job titles like Data Scientist, Data Analyst, Data Engineer, AI Engineer and Machine Learning Engineer. Is it because these are some of the top paying jobs in the world? These are valid reasons but once you get to know the power and applications of data science, I believe you’ll be more excited just to solve real-world problems. So, in this article, we’ll be looking at how to get your first data science job in 6 months.
If you’ve read this article on what data science is, you must be clear that pretty much anyone can get into data science. But then the question arises how and where to start? When you begin, it might seem there are just too many things to learn. But the good news is, you don’t need to learn everything to become a data scientist. Fundamentals, Statistics, Programming and Visualization are a must have. Machine Learning is also good to have, and the rest depends on which field you’d like to specialize in. We have an excellent course on Data Science With R & Python that covers these topics. An overview of this course is given below.
Course Roadmap
Week 1-2: Descriptive Stats
For the first week and the start of the second, you’ll be learning about descriptive statistics used for data exploration which is the first step in data analysis. You’ll learn about the central tendency, visualizing data, normal and sampling distribution.
Week 2-4: Inferential Stats
From week two, you’ll be learning about inferential statistics to draw conclusions from a sample of data about the population. You’ll learn about hypothesis testing, correlation, and regression up until week four.
Week 4-7: R
Starting from week four, we get into programming stuff. We begin with a popular language for data analysis R with a deep understanding of the various functionalities and features of R.
Week 8-11: Python
We start looking at another popular programming language in week 8 – Python. We go from the basics of Python to more advanced stuff by using popular Python packages for data science – NumPy, Pandas and Scikit-Learn.
Week 11-19: Machine Learning
Week 11 onwards we embark on a journey of Machine Learning. We start with understanding Supervised and Unsupervised Learning. We then look at techniques for supervised learning like Linear and Logistic Regression. We also look at unsupervised learning algorithms like KMeans Clustering and other important topics like Naive Bayes and Time Series Analysis. We spend much of our course here.
Week 19-20: Tableau
In the final weeks, we learn about a popular reporting tool Tableau and how to integrate Tableau with R/Python.
Week 21 and beyond
After you’ve gained all the knowledge, you’ll be getting your hands dirty with a real-world case study, which you can also add to your portfolio.
Applying your knowledge
Following the course will not only give you brilliant insights into the field from our expert tutors but also helps you keep track of your progress. It’s good that you have gained all these knowledge, but now you need to apply it as well if you’re serious about getting your first data science job. There are some extra steps you need to take. It is not necessary that these steps be taken after you’ve finished the course. In fact, I’d encourage you to take them as early as possible. This will help you gain more confidence as you learn. Below we list some of them:
Practice, practice and more practice
Practice is the key to everything and while you learn from our course, you also need to try things on your own. Find a subfield you’re interested in. That may be analytics, visualization, computer vision or anything else. Once you do, search for the relevant dataset from which you can practice. You can use Google’s latest dataset search engine for that purpose. Once you have used your knowledge on data science to solve any problem, no matter how big or small, make sure you push your code to a public repository like GitHub. This will allow you to incrementally create a portfolio that you can share to potential future employers.
Join data science groups/follow people on social media
The field of data science is constantly evolving and there’s always a new breakthrough going on. So, in order to remain up to date, I’d recommend you to follow groups as well as people related to the field on social media. Artificial Intelligence & Deep Learning is an excellent group on Facebook where people around the world share their research, articles, and problems. Members of the group range from beginners to experienced. They also share new job postings and paid projects every Saturday. You may also find local groups created by like-minded people on Facebook, Twitter, and LinkedIn.
Attend workshops and seminars
Following people/groups online is a great way to learn new things. Attending in-person workshops and seminars organized locally also serves the same purpose, but there’s more to that. In addition, other people also get to know you, your strengths and interests. It is a great way to grow your network and learn about new opportunities. You also get the feeling that you’re not alone in this. You can collaborate with other aspiring data scientists and work on projects of common interest. There’s a School of AI that frequently organize meet-ups. You can find about your city or nearby cities from here. Facebook events is also a good way to find about data science events happening near you.
Create an online/offline presence
Now that you’ve learned a few things on data science and know a handful of people who either work on or have a keen interest in the field, it is now important to create a brand for yourself. Start writing short articles/blogs on what you’ve learned. Don’t worry if you don’t know everything; don’t be afraid to express yourself. Share your articles on platforms such as LinkedIn, where by now you have a decent number of followers of common interest. Organize meet-ups yourself and take an initiative to talk about what you know in person. In this way, you market yourself and when some new opportunities come up, you definitely have an edge over fellow aspiring data scientists.
Apply for jobs
By now, you have a decent portfolio of work to showcase and you might already have one or more job offers. Maybe it’s not from a big company for now, but it’s definitely a step forward. Take it; it all adds up in your résumé. Also, don’t send out the same résumé to all potential employers. Be sure to highlight your skills that match the requirements in the job description. Because employers are seeking for individuals who can solve their problem and if you’ve got that skill, chances are you’ll be invited for an interview. When writing a cover letter, make sure to tell how you’re a good fit for the company. This will give the employers the impression that you’ve thoroughly read through the requirements and that you have an eye for detail.
Prepare for the interview
You should start preparing for an interview even when you’ve not been invited to one. Because then you’ll always be prepared for any and all opportunities that come your way. To be a data scientist, you need to have a strong command of mathematics, statistics, programming, and problem-solving techniques. Again, practice is the key here. Keep brushing up your skills and when you get called up for an interview, you can nail it.
Getting a data science job is not the end of the story, actually, it’s just the beginning. Because this field is constantly evolving, you need to keep learning and keep being updated. So the learning continues as long as you’re in the field. I’d encourage you to follow the rule that I live by – Learn, Share and Repeat.
Most of the literature we find on machine learning talks about two types of learning techniques – supervised and unsupervised. Supervised learning is where we have a labeled dataset. This means we already have data from which to develop models using algorithms such as Linear Regression, Logistic Regression, and others. With this model, we can make further predictions like given data on housing prices, what will the cost of a house with a given set of features be. Unsupervised learning, on the other hand, doesn’t have a labeled dataset, but still, we do have abundant data. The model we create in this setting just needs to derive a pattern amongst the data available. We do this with algorithms such as K Means Clustering, K Nearest Neighbors, etc. to solve problems like grouping a set of users according to their behavior in an online shopping portal. But what if we don’t have so much of data? What if we are dealing with a dynamic environment and the model needs to gather data and learn in real time? Enters reinforcement learning. In this article, we look at the basics of what reinforcement learning is, how it works and some of its practical applications.
Reinforcement Learning through Super Mario
We all have experienced reinforcement learning, quite possibly very early in our lives. We just didn’t know it by its name. Okay, so we’ve all played Super Mario when we were younger right? Just in case you didn’t or have forgotten, this is how it looked like:
You might not be able to totally recall the first time you ever played Mario, but just like any other game, you might have started with a clean slate, not knowing what to do. You see an environment in which you as Mario, the agent, have been placed that consists of bricks, coins, mystery boxes, pipes, sentient mushrooms called Goomba, and other elements. You begin taking actions in this environment by pressing a few keys before you realized then you can move Mario with the arrow keys to the left and right. Every action you take changes the state of Mario. You moved to the extreme left at the beginning but nothing happened so you started moving right. You tried jumping onto the mystery box after which you got a reward in the form of coins. Now, you learned that every time you see a mystery box, you can jump and earn coins. You continued moving right and then you collided with a Goomba after which you got a negative reward (also called a punishment) in the form of death. You could start all over again, but by now you’ve learned that you must not get too close to the Goomba; you should try something else. In other words, you have been “reinforced”. Next, you try to jump and go over the Goomba using the bricks but then you’d miss a reward from the mystery box. So you need to formulate a new policy, one that’ll give you the maximum benefit – gives you the reward and doesn’t get you killed. So you wait for the perfect moment to go under the bricks and jump over the Goomba. After many attempts, you take one such action that causes Mario to step over the Goomba and it gets killed. And then you have an ‘Aha’ moment; you’ve learned how to kill the threat and now you can also get your reward. You jump and this time, it’s not a coin, it’s a mushroom. You again go over the bricks and eat the mushroom. You get an even bigger reward; Mario’s stronger now. This is the whole idea of reinforcement learning. It is a goal-oriented algorithm, which learns techniques to maximize the chances of attaining the goal over many iterations. Using trial and error, reinforcement learning learns much like how humans do.
Comparison with other Machine Learning Techniques
There are a few differences in RL as compared to other machine learning techniques. These include:
There is no supervisor to tell you if you did right or wrong. If you did well, you get a reward, else you would not. If you did terrible, you might even get a negative reward.
Reinforcement learning adds in another dimension – time. It can be thought of being in between supervised and unsupervised learning. Whereas in supervised learning, we have labeled data and unsupervised learning we don’t, in reinforcement learning, we have time delayed labels, which we call rewards.
RL has the concept of delayed rewards. So, the reward we just received may not be dependent on the last action we took. It is entirely possible that the reward came because of something we did 20 iterations ago. As you move through Super Mario, you’ll find instances where you hit a mystery box and keep moving forward and the mushroom also moves and finds you. It is the series of actions that started with Mario hitting the mystery box that resulted in him getting stronger after a certain time delay.
The choice we make now affects the set of choices we have in the future. If we choose a different set of actions, we will be in a completely different state and the inputs to that state and where we can go from there differs. If Mario hit the mystery box but chose not to move forward when the mushroom began to move, he’ll miss the mushroom and he won’t get stronger. The agent is now in a different state than he would have been had he moved forward.
Doesn’t RL feel like life in general?
AlphaGo
Reinforcement learning broke into the scene in March 2016 when DeepMind’s AlphaGo, trained using RL, defeated 18-time world champion Go player Lee Sedol 4-1. It turns out the game of Go was really hard to master for the machine, more so than games like Chess simply because there are just too many possible moves and too many numbers of states the game can be in. But how did AlphaGo beat the world champion?
Just like Mario, AlphaGo learned through trial and error, over many iterations. AlphaGo doesn’t know the best strategy, but it knows whether it won or lost. AlphaGo uses a tree search to check every possible move it can make and see which is better. On a 19×19 Go board, there are 361 possible moves. For each of these 361 moves, there are 359 possible second moves and so on. In all, there are about 4.67×10^385 possible moves; that’s way too much. Even with its advanced hardware, AlphaGo cannot try every single move there is. So, it uses another kind of tree search called the Monte Carlo Tree Search. In this search, only those moves that are most promising are tried out. Each time AlphaGo finishes a game, it updates the record of how many games each move won. After multiple iterations, AlphaGo has a rough idea of which moves maximizes its chance of winning.
AlphaGo first trained itself by imitating historic games played between real players. After this, it started playing against itself and after many iterations, it learned the best moves to win a Go match. Before playing against Lee Sedol, AlphaGo played against and defeated professional Go player Fan Hui 5-0 in 2015. At that moment, people didn’t consider it a big deal as AlphaGo hadn’t reached world champion level. But what they didn’t realize was AlphaGo was learning from humans while beating them. So by the time AlphaGo played against Lee Sedol, it had surpassed world champion level. AlphaGo played 60 online matches against top players and world champions and it won all 60. AlphaGo retired in 2017 while DeepMind continues AI research in other areas.
Applications
It’s all fun and games, but where can RL be actually useful? What are some of the real world application? We’ll see some of these below:
Robotics and Manufacturing
One of the largest field of research and now beginning to show real promise is the field of Robotics. Teaching a robot to act similar to humans has been a major research area and also part of several sci-fi movies. With reinforcement learning, robots can learn similar to how humans do. Using this, industrial automation has been simplified. An example is Tesla’s factory that consists of more than 160 robots that do a large part of the work on cars to reduce the risk of defects.
Inventory Management
RL can be used to reduce transit time for stocking and retrieving products in the warehouse for optimizing space utilization and warehouse operations.
Power Systems And Energy Consumption
RL and optimization techniques can be utilized to assess the security of electric power systems and to enhance Microgrid performance. Adaptive learning methods are employed to develop control and protection schemes, which can effectively help to reduce transmission losses and CO2 emissions. Also, Google has used DeepMind’s RL technologies to significantly reduce the energy consumption in its own data centers.
Text, Speech and Dialog Systems
AI researches at SalesForce used deep RL for automatically generating summaries from text based on content abstracted from some original text document. This demonstrated an approach for text mining solution for companies to unlock unstructured text. RL is also being used to allow dialog systems (chatbots) to learn from user interactions and help them improve over time.
Finance
Pit.AI used RL for evaluating trading strategies. RL has immense applications in the stock market. Q-Learning algorithm can be used by anyone to potentially gain income without worrying about market price or risks involved. The algorithm is smart enough to take all these under considerations while making a trade.
Data Science and Machine Learning
A lot of machine learning libraries have been made available in recent times to help data scientists, but choosing a proper model or architecture can still be challenging. Several research groups have proposed using RL to simplify the process of designing neural network architectures. AutoML from Google uses RL to produce state-of-the-art machine-generated neural network architectures for language modeling and computer vision.
A mechanism of testing two techniques or two versions to determine which one is better.
Activation Function
A function that maps the input to a neuron, to the output. If the result of this function is above a certain threshold, the neuron is activated. Sigmoid Function and ReLU are some examples of the activation function.
Artificial Intelligence
The mechanism by which a machine can take input from the environment via sensors, process this input using the experiences it has gained and take rational and intelligent decision on the environment using actuators, much like how humans do.
AutoEncoders
A neural network where the output is set to be the same as the input and the goal is to train the hidden layers such that the input can be represented in fewer dimensions by encoding.
B
Backpropagation
A technique used in training deep learning networks to update the weights and biases by calculating the gradient so that the accuracy of the network can be improved iteratively.
Bayes’ Theorem
This theorem gives the probability of an event when we already have information about some other condition related to the event. The relation is given by P(A|B) = P(B|A) / P(A)*P(B)
Bias
A parameter that can be used to tweak the output values towards or away from the decision boundary.
Big Data
Large volume of data that cannot be processed by traditional data processing applications and may be analysed to generate valuable insights from the data.
C
Classification
The process of determining the score for an individual entry in order to find out which class the individual belongs to.
Clustering
The method of grouping a set of data such that all elements of a particular group have some common parameters or characteristics.
Confusion Matrix
A matrix that defines the performance of a classification model on a test data for which the true values are known. This matrix uses the True Positive(TP), True Negative (TN), False Positive(FP) and False Negative(FN) to evaluate the performance.
Cost Function
A function for a model that determines the error in prediction of a dependent variable given an independent variable.
Cross-validation
The process of splitting the labelled data into training set and testing set, and after the model has been trained with the training set, testing the model using the testing set for which we already know what the output should be. This results in determining how well the model is working on previously unseen data.
D
Data Mining
The process of gathering relevant data for the area of interest, generate a model to find patterns and relationships amongst the data, and present the derived information in appropriate and useful form.
Data Science
The method of using appropriate tools and techniques to represent the most efficient algorithm for generating insights from a problem set that we have substantial expertise and data on.
Data Wrangling
The process of acquiring data from multiple sources, cleaning the data (removing/replacing missing/redundant data), combining the data to acquire only required fields and entries, and preparing the data for easy access and analysis.
Decision Boundary
A boundary that separates the elements of one class from the elements of another class. See this link for a good explanation on decision boundary.
Decision Tree
A supervised learning algorithm that models a tree where every branch represents a set of alternatives and leaves represent the decisions. By taking a series of decisions along the branches, we ultimately reach the desired result at one of the leaves. See this link for an in-depth explanation on decision trees.
Deep Learning
A subfield of machine learning that uses the power of neural network to accelerate the processing of algorithms to make computations on huge amount of data.
Dependent Variable
A variable that is under test and changes with respect to the change in an independent variable. In a housing price example, change in area results in change in price. Here, price is a dependent variable which depends on the independent variable area.
Dimensionality Reduction
The process of reducing the number of features or dimensions of a training set without losing much information from the data and increase the model’s performance.
E
Exploratory Data Analysis
A data analysis approach used to discover insights in the data, often using graphical techniques.
F
Feature
The input variables in a problem set that can be measured to provide information.
Feature Selection
Selection of a subset of the most relevant attributes in a problem set. This is done for effective model construction.
G
Gradient Descent
An optimization process to minimize the cost function by finding optimum values for the parameters involved.
Graphics Processing Unit (GPU)
A chip that processes complex mathematical functions rapidly and is generally used for image rendering. Deep learning models generally require lots of processing that are not feasible with time constraints using ordinary CPU and hence GPUs are required.
H
Hyperparameter
Parameters in a model that cannot be directly learnt from the data and is decided by setting different values to determine which works best for the model. Tuning the learning rate for a model is an example of hyperparameter.
I
Independent Variable
A variable that is used to change a dependent variable and experiment its values. See dependent variable for example.
L
Label
The output variables in a problem set, whose values are either provided or needs to be predicted.
Latent Variable
A hidden variable that cannot be computed directly, but are measured by computation of other variables that can be measured directly. The other measurable variables ultimately impact the hidden variable. See this link for good examples of latent variable.
Learning Rate
A hyperparameter that is used to adjust the weights of a network with respect to the gradient loss. Small learning rate could result in taking a long time for the model to converge whereas large learning rate could result in the model never being converged. So, an optimal learning rate must be found for best results.
Linear Regression
A regression technique where the linear relationship between a dependent variable and one or more independent variables is determined. The dependent and independent variables are continuous in nature.
Logistic Regression
A classification technique where the relationship between a binary dependent variable and one or more independent variables is determined.
M
Machine Learning
The process that uses data and statistics to learn and generate algorithms and models to perform intelligent action on previously unseen data.
Model Selection
The process of selecting a statistical model from a set of alternative models for a problem set that results in the right balance between approximation and estimation errors.
Model Tuning
The process of tweaking the hyperparameters in order to improve the efficiency of the model.
N
Natural Language Processing
A field of computer science associated with the study of how computers can understand and interact with humans using the natural language as spoken by humans.
Neural Network
A layered interconnection of neurons that receive input, process the input and use the activation function to generate an output. This output will be the input that is passed onto the next layer and so on until the final output layer. Also known as Artificial Neural Network, it is inspired from how the human brain works.
O
Outlier
Unusual observations in data that lie at an abnormal distance from where majority of the data points are located.
Overfitting
A model is overfitted when it is trained with lots of data such that it learns even the noise parameters in the given data and does not work well with data it has not seen before.
P
Perceptron
A single layer neural network.
Predictive Analysis
A process of predicting unseen events using historical data and statistical techniques derived from data mining and machine learning.
R
Random Forest
A combination of many decision trees in a single model. The predictions are closer to the average in case of random forest as predictions from multiple decision trees are taken into account.
Rectified Linear Unit (ReLU)
An activation function for which the output is 0 if the input is less than 0, otherwise the output is equal to the input. So, it takes the max of zero, i.e. f(x) = max(x,0)
Regression
A technique of measuring the relationship between the mean value of a dependent variable and one or more independent variables.
Reinforcement Learning
A machine learning technique where an agents learn by taking action in an environment and observing the results. The agent can start with no knowledge of the environment and it learns from experience.
S
Sigmoid Function
An S-shaped activation function for which the output approaches 0 if the input approaches -infinity and the output approaches 1 if the input approaches +infinity. The sigmoid function is given by sigmoid(x)=1/(1+e^(-x))
Softmax
A function used in multiple classification logistic regression that calculates the probability of each target class over all possible target classes. The probabilities of each class will be between 0 and 1, and the sum of the probabilities will be equal to 1.
Supervised Learning
A machine learning technique where we provide the model with both the input and the actual output data, and train the model such that the predicted output closely resembles the actual output so that it can later make predictions on unseen data.
Support Vector Machine (SVM)
A supervised machine learning technique which outputs an optimal hyperplane that can classify new examples into multiple classes.
T
Testing Set
A portion of already acquired data we have separated to test the accuracy of the model after the model has been trained with training set. To split 20% of the total available data as test set is considered good but may be changed as per model requirements.
Training Set
A portion of already acquired data we have separated to acquire parameters and train the model which may later be tested with the test set. To split 80% of the total available data as training set is considered fair.
U
Underfitting
A model is underfitted when it is not able to capture the parameters from the given data and hence does not work well even on previously seen data.
Unsupervised Learning
A machine learning technique where we provide the model with only the input data and train the model such that the model learns to determine the pattern in the data and later make predictions on unseen data.
W
Weight
The strength of connection between two neurons of two successive layers in a neural network.
You can also find more terms related to data science and machine learning from the following links:
On Wednesday, September 5, 2018, the data science world was following its usual routine. Data science enthusiasts, students, and professionals were searching for datasets with a simple google search, from Kaggle, from the UCI Machine Learning Repository and so many other resources. Just then, Google dropped one of the coolest tools for the domain of data science that has and will probably change the way people are going to acquire their datasets. This tool is called Dataset Search and it has been one of the hottest topics of discussion of the week regarding the domain of data science. You can try it out from this link.
Now, most of you may already be familiar with what a dataset is. But in case you’re not, let’s have a gentle introduction. Feel free to skip this section if you’re comfortable with datasets.
What is a dataset?
In simple words, a dataset is simply an organized collection of data in a particular domain of interest. This domain may be anything from Global Temperature Changes to Housing Prices to Breast Cancer to Stock Markets; anything where the user wants to explore and find solutions to the problems. Some of the popular datasets are the Iris dataset that contains the sepal and petal widths of different types of flowers, the MNIST dataset which contains data for handwritten digits 0 through 9, Boston Housing Price dataset that contains house prices corresponding to various features such as average number of rooms, per capita crime rate, etc. A dataset contains large amount of historical data about the domain of interest, using which data scientist generate models and algorithms, train and test the model, and hence later make decisions of its own. Data is the single most important thing for any such model and datasets are the bread and butter of a data scientist.
Note: If you’re not familiar with what data science is, please read this article first.
Hopefully, by now everyone has a general idea of what a dataset is and why it is important in data science. This now brings us to the next question.
Where can I get a dataset?
You have a problem and you need data to explore the problem. So you begin to search in the most obvious place, where everybody searches for almost everything – Google. Of course, there are other search engines, and we may have used it a few times now and then, but we have to admit it that Google is the most dominant search engine of all. Whether we want a dataset or just want to test our internet connection, we all go to Google. And Google just gives us back the links to the dataset in Kaggle or UCI Machine Learning Repository. And these are really good resources for datasets. In fact, Kaggle not only has datasets but also hosts a lot of competitions to develop machine learning algorithms; some even offer prize money to the best algorithms.
What does Google Dataset Search do differently?
Ultimately, Dataset Search also provides links to Kaggle, UCI ML Repository and other websites with the relevant dataset. Then the question may arise why we would even need the Dataset search. Let’s look at this by an example. Suppose that we want to find the dataset for Global Temperature changes. Following image depicts the result when searching in plain old Google.
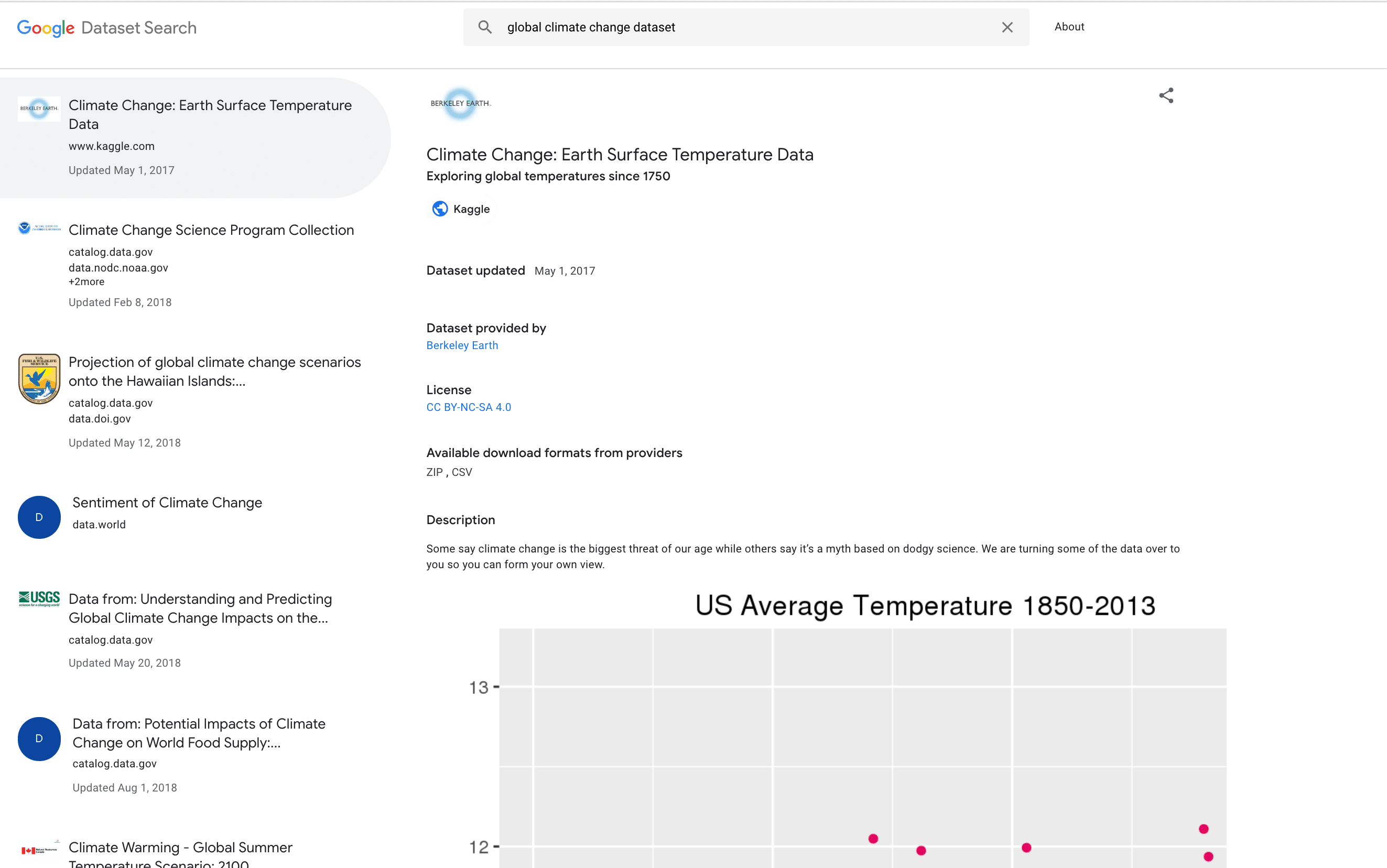
And now let’s search for the same using the Dataset Search
The difference is clear. Simple google search gives us general results, which may or may not be relevant to us. Google Dataset Search gives us more specific results, to the point. On the left pane, it returns all the relevant websites from which we can acquire the data set; the first one here is from Kaggle. On the right pane, it gives us the details such as the dataset updated date, provided by, available download formats and descriptions for the website selected on the left pane. Try it and you’ll see for yourself. The page above also contains a plot for the relevant data.
So, the Google Dataset Search is simply a search engine designed specifically for the purpose of the ease of finding relevant dataset. Whereas traditional Google search deals with more generic results, Dataset Search gives us specific results with extra information. Not only this, as per Natasha Noy, Research Scientist in Google AI, this search engine will display the dataset directly from its hosted area – whether it’s the publisher’s site, author’s personal web page or a digital library, which may not always be easily accessible from traditional search.
If you’ve used Google Scholar, you’ll see that the concept is quite similar. Google Scholar helps us to find articles and research papers more easily. It also lets us create a library of our favorite articles to read. Dataset Search doesn’t have so many features as of yet. Google has introduced it as a Beta version, which means there are going to be a lot more changes, and hopefully a lot more new features that will create ease of access to the data more comfortable.
But not all data may be open and hence available for inspection. In Noy’s words, “The metadata needs to be open, the dataset itself does not need to be. For an analogy, think of a search you do on Google Scholar: It may well take you to a publisher’s website where the article is behind a paywall. Our goal is to help users discover where the data is and then access it directly from the provider.”
How does it work under the hood?
Google utilizes the schema markup for dataset providers in the Dataset Search. You can learn about schema markup from their official page. This markup allows publishers to add descriptions to their data such that search engines such as Google can understand the content of the page more efficiently. Google has developed certain guidelines for the dataset providers with respect to installing Dataset Search. It encourages the data providers to include information such as the creator of the dataset, the methodology of its collection, the date of its publication and update, and the terms under which the data can or cannot be used. This will help search engines to redirect information to anyone searching it more efficiently.
Right now, Dataset Search can be used to find most datasets on topics such as social sciences, environmental sciences, government data and the data provided by news organizations. When more and more data providers adapt to the schema markup, Google can and will expand the variety of datasets that can be accessed from the Dataset Search.
In summary, the Dataset Search is a one-stop shop for the datasets one need to find. Need to find data related to NASA and also from NOAA? No need to keep up to date with their websites. Google’s new search engine will handle that for you, in a much more efficient way. It is exciting times in data science with newer and better tools being developed. Especially given that these advancements come from tech giants like Google, we can expect for more of such tools in the future. We can also expect other tech giants to bring their own sets of tools to keep this healthy competition going and it is ultimately us that will benefit from it. The DataSet Search is going to be an important tool in the arsenal of a data scientist. Sure, it’s not the sharpest tool at the moment, but it’s one that is bound to get better and better with time.
There has been much hype surrounding deep learning in recent times, and one of the cornerstones of deep learning is the neural network. In this article, we will look at what a neural network is and get familiar with the relevant terminologies.
In simplest terms, a neural network is an interconnection of neurons. Now the question arises, what is a neuron? To understand neurons in deep learning, we first need to look at neurons from a biological perspective, from which the concept of neural network has actually been taken.
A neuron is the primary component of our central nervous system (which includes the brain) and is a cell that can receive, process and transmit information when excited. A neuron transmits signals to other neurons via connections called synapses. Based on these synapses, the brain makes the decisions. An interconnection of such neurons forms what is known as, the neural network.
Using this concept from the biological neural network, an Artificial Neural Network (ANN), also simply known as the neural network, is formed. A biological neuron receives signals via the dendrites, the nucleus processes these signals and the axon transmits these signals to other neurons. In the same manner, an artificial neuron input takes an input, does some kind of processing and pass the result to the other neurons in the network. If you’d like an animated version of how a neural network works, check out this video from 3Blue1Brown.
Let’s start with the simplest possible neural network – the perceptron.
A perceptron is a single layer neural network. As we can see from the above figure, a perceptron consists of:
Inputs
Weights
Transfer function
Activation function
Let’s understand this via an example. Suppose that we have a 4×4 image and we want the perceptron to recognize whether this image consists of a vertical line (as shown by dark boxes in the figure above). The inputs (x1,x2,x3, …, x16) are the intensity values for each of the pixel. Now, the weights indicate the strength about how much we care about a particular pixel. As shown in the figure, we are interested in two sets of vertical pixels, so these 8 pixels are assigned a higher weight that the other 8 pixels. This means even if some of the middle pixels are lit up, our perceptron cares less about those pixels. After all the intensity values have been acquired, the weighted sum of the intensities is calculated in the transfer function. Thus, the pixels of our interest have more influence on the result of the transfer function than the others. Finally, the result of this transfer function is passed into an activation function. If the result of the activation function is above a provided threshold, then the perceptron fires, otherwise it doesn’t. In other words, the activation function tells us whether there is a vertical line in our desired locations or not. Since single layer perceptrons can be used to answer these yes/no question, they are also called a linear (binary) classifier.
Besides these, a perceptron also consists of a bias. This bias can be used to tweak the values of the pixels towards or away from the decision boundary.
Now, that we’ve seen what a single layer neural network looks like, let’s take it up a notch. The two-layered neural network, as seen in the above diagram, is a more common representation of a neural network in literature. The concept of what a layer is, may not have been completely clear in case of a perceptron, so this section covers that portion.
In the case of a perceptron, all we had was an input and an output – a single layer. In a two-layered neural network, we have an additional hidden layer. Now, every node of this neural network is basically a perceptron. So, all we’re doing is, we’re stacking a bunch of perceptrons that can make a more complex decision than just the presence of a vertical line.
Taking the above example again, this time we are dealing with multiple perceptrons that have different functions. The goal here is to determine whether the image consists of a digit ‘4’. Here, one perceptron is determining the presence of a vertical line, another determines the presence of a horizontal line and yet another is looking for a vertical line where half of the pixels are lit up and the other half is not.
So, again we give it the inputs for intensities of all the pixels in the input layer. The individual perceptrons fire using the concept already explained above and provide that output to the second layer, the hidden layer. Now, the hidden layer takes these inputs for the vertical line, horizontal line and edge and makes its own sorts of calculations. This hidden layer also has its own transfer function and activation function. What is interesting is that we don’t define the hidden layer explicitly. The hidden layer generates these functions by a process called supervised learning. The hidden layer then passes its decision on to the output layer, which finally tells us whether the image consists of a ‘4’ or not.
Supervised Learning
So, what is this supervised learning and how does the hidden layer learn? Supervised learning is a process where a neural network is given a set of inputs (like the handwritten digits image) and in addition, we also tell it what the label of that set of inputs is (what number is contained in the image). In the example given above, we only gave 4×4 image as the input for simplification. The actual handwritten digits dataset, called the MNIST dataset consists of images of size 28×28 (784 pixels in total) for images of handwritten digits 0 through 9. It also consists of a label for each image.
In the beginning, we give the input layer all the intensities for the pixels and as for the weights, we assign them randomly. Then the hidden layer generates its results and the output layer decides which of the 10 digits it thinks the given image is. As the weights are randomly assigned, the first result (and in fact for many iterations), the result will be incorrect. This is when we give the network feedback using the label we have, that what we gave it was a 4 but it had incorrectly classified it as 9, for instance. The network then re-adjusts its weights and biases by using this feedback so that for the next iteration, it can better predict the given image. This process of re-adjusting the weights and biases using the feedback is known as backpropagation, and the whole process where the network learns using the labeled data to later classify images that don’t have labels is known as supervised learning.
Now the network uses this process of backpropagation to refine its transfer and activation functions. We don’t define these functions explicitly, neither can we program it ourselves. The network finds the parameters to tweak and decide what’s best for it. As the functionality of how this layer adjusts remains hidden from the user, hence the name hidden layer.
Here, we presented only a single hidden layer. In reality, there can be multiple hidden layers and all the layers work similar to the methodology explained above. Such a network is known as a multilayer neural network. There can be as many hidden layers as the problem requires. One such network is shown below.
Each neuron of each layer is just a simple perceptron that takes input from the previous layer, does some sort of calculation and provides the output to the next layer. So even though the above figure may look scary at first, if you break it down, everything is just a perceptron that trains through backpropagation and becomes better at making decisions. And that is the closest we have gotten to modeling how a human brain works, by creating an artificial brain.