As we move towards a data-driven world, we tend to realize how the power of analytics could unearth the most minute details of our lives. From drawing insights from data to making predictions of some unknown scenarios, both small and large industries are thriving under the power of big data analytics.
A-Z Glossary
There are various terms, keywords, concepts that are associated with Analytics. This field of study is broad, and hence, it could be overwhelming to know each one of it. This blog covers some of the critical concepts in analytics from A-Z, and explain the intuition behind that.
A: Artificial Intelligence – AI is the field of study which deals with the creation of intelligent machines that could behave like humans. Some of the widespread use cases where Artificial Intelligence has found its way are ChatBots, Speech Recognition, and so on.
There are two main types of Artificial Intelligence –Narrow AI, and Strong AI. A poker game is an example for the weak or the narrow AI where you feed all the instructions into the machines. It is trained to understand every scenario and incapable of performing something on their own.
On the other hand, a Strong AI thinks and acts like a human being. It is still far-fetched, and a lot of work is being done to achieve ground-breaking results.
B: Big Data – The term Big Data is quite popular and is being used frequently in the analytical ecosystem. The concept of big data came into being with the advent of the enormous amount of unstructured data. The data is getting generated from a multitude of sources which bears the properties of volume, veracity, value, and velocity.
Traditional file storage systems are incapable of handling such volumes of data, and hence companies are looking into distributed computing to mine such data. Industries which makes full use of the big data are way ahead off their peers in the market.
C: Customer Analytics – Based on the customer’s behavior, relevant offers delivered to them. This process is known as Customer Analytics. Understanding the customer’s lifestyle and buying habits would ensure better prediction of their purchase behaviors, which would eventually lead to more sales for the company.
The accurate analysis of customer behavior would increase customer loyalty. It could reduce campaign costs as well. The ROI would increase when the right message delivered to each segmented group.
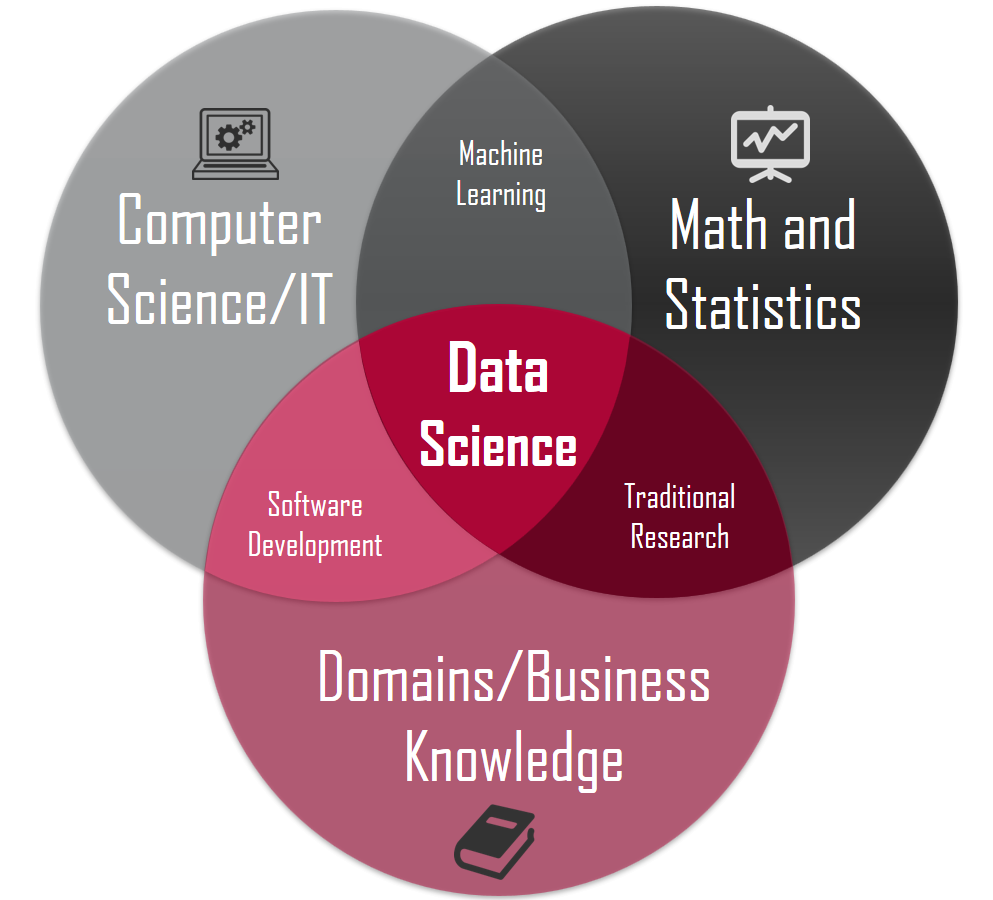
D: Data Science – Data Science is a holistic term which involves a lot of processes which includes data extraction, data pre-processing, building predictive models, data visualization, and so on. Generally, in big companies, the role of a Data Scientist is well defined unlike in startups where you would need to look after all the aspects of an end-to-end project.
source: Towards Data Science
To be a Data Scientist, you need to be fluent in Probability, and Statistics as well, which makes it a lucrative career. There are not many qualified Data Scientists out there, and hence mastering the relevant skills could put you in a pole position in the job market.
E: Excel –An old, and yet the most used after visualization tool in the market is Microsoft Excel. Excel is used in a variety of ways while presenting the data to the stakeholders. The graphs and charts lay down the proper demonstration of the work done, which makes it easier for the business to take relevant decisions.
Moreover, Excel has a rich set of utilities which could useful in analyzing structured data. Most companies still need personnel with the knowledge of MS Excel, and hence, you must master it.
F: Financial Analytics – Financial Data such as accounts, transactions, etc., are private and confidential to an individual. Banks refrain from sharing such sensitive data as it could breach privacy and lead to financial damage of a customer.
However, such data if used ethically could save losses for a bank by identifying potential fraudulent behaviors. It would also be used to predict the loan defaulting probability. Credit scoring is another such use case of financial analytics.
G: Google Analytics – For analyzing website traffic, Google provides a free tool known as Google Analytics. It is useful to track any marketing campaign which would give an idea about the behavior of customers.
There are four levels via which the Google Analytics collects the data – User level which understands each user’s actions, Session level which monitors the individual visit, Page view level which gives information about each page views, and Event level which is about the number of button clicks, views of videos, and so on.
H: Hadoop –The framework most commonly used to store, and manipulate big data is known as Hadoop. As a result of high computing power, the data is processed fast in Hadoop.
Moreover, parallel computing in multiple clusters protects the loss of data and provides more flexibility. It is also cheaper, and could easily be scaled to handle more data.
I: Impala – Impala is a component of Hadoop which provides a SQL query engine for data processing. Written in Java, and C++, Impala is better than other SQL engines. Use SQL; the communication enabled between users and the HDFS, which is faster than Hive. Additionally, different formats of a file could also be read using Impala.
J: Journey Analytics – A sequential journey related to customer experience, which meets a specific business referred to as Journey Analytics. Over time, a customer’s interaction with the company compiled from its journey analytics.
K: K-means clustering – Clustering is a technique where you group a dataset into some small groups based on the similar properties shared among the members of the same group.
K-Means clustering is one such clustering algorithm where an unsupervised dataset split into k number of groups or clusters. K-Means clustering could be used to group a set of customers or products resembling similar properties.
L: Latent Dirichlet Allocation – LDA or Latent Dirichlet Allocation is a technique used over textual data in use cases such as topic modeling. Here, a set of topics imagined by the LDA representing a set of words. Then, it maps all the documents to the topics ensuring that those imaginary topics capture words in each text.
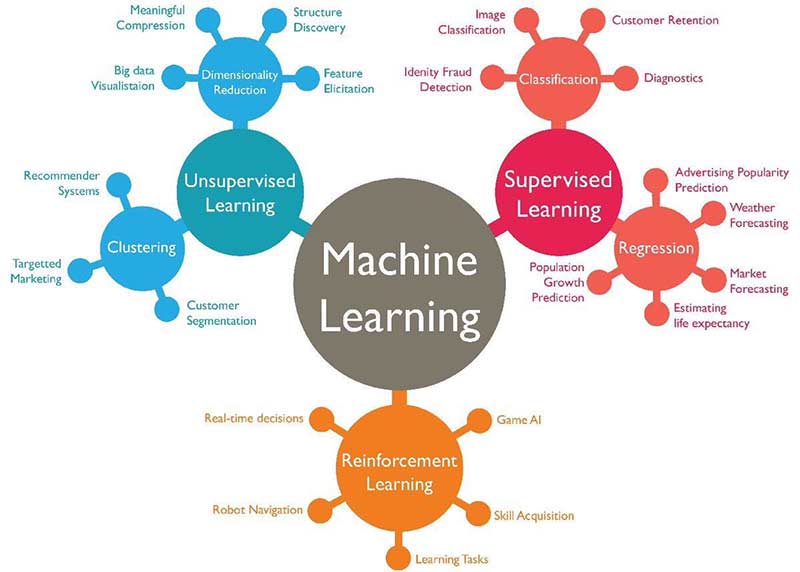
M: Machine Learning – Machine Learning is a field of Data Science which deals with building predictive models to make better business decisions.
A machine or a computer is first trained with some set of historical data so that it finds patterns in it, and then predict the outcome on an unknown test set. There are several algorithms used in Machine Learning, one such being K-means clustering.
source: TechLeer
N: Neural Networks – Deep Learning is the branch of Machine Learning, which thrives on large complex volumes of data and is used to cases where traditional algorithms are incapable of producing excellent results
Under the hood, the architecture behind Deep Learning is Neural Networks, which is quite similar to the neurons in the human brain.
O: Operational Analytics –The analytics behind the business, which focuses on improving the present state of operations, referred to as Operational Analytics.
Various data aggregation and data mining tools used which provides a piece of transparent information about the business. People who are expert in this field would use operational software provided knowledge to perform targeted analysis.
P: Pig –Apache Pig is a component of Hadoop which is used to analyze large datasets by parallelized computation. The language used is called Pig Latin.
Several tasks, such as Data Management could be served using Pig Latin. Data checking and filtering could be done efficiently and quickly with Pig.
Q: Q-Learning –It is a model-free reinforcement learning algorithm which learns a policy by informing an agent the actions to be taken under specific certain circumstances. The problems handled with stochastic transitions and rewards, and it doesn’t require adaptations.
R: Recurrent Neural Networks –RNN is a neural network where the input to the current step is the output from the previous step.
It used in cases such as text summarization was to predict the next word, the last words are needed to remember. The issue of the hidden layer was solved with the advent of RNN as it recalls sequence information.
S: SQL –One of the essential skill in analytics is Structured Query Language or SQL. It is used in RDBMS to fetch data from tables using queries.
Most companies use SQL for their initial data validation and analysis. Some of the standard SQL operations used are joins, sub-queries, window functions, etc.
T: Traffic Analytics –The study of analyzing a website’s source of traffic by looking into its clickstream data is known as traffic analytics. It could help in understanding whether direct, social, paid traffic, etc., are bringing in more users.
U: Unsupervised Machine Learning –The type of machine learning which deals with unlabeled data is known as unsupervised machine learning.
Here, no labels provided for a corresponding set of features, and information is grouped based on the similarity in the properties shared by the members of each group. Some of the unsupervised algorithms are PCA, K-Means, and so on.
V: Visualization –The analysis of data is useless if not presented in the forms of graphs and charts to the business. Hence, Data visualization is an integral part of any analytics project and also one of the key steps in data pre-processing and feature engineering.
W: Word2vec –It is a neural network used for text processing which takes in a text as input and output are a set of feature vectors of the words.
Some of the applications of word2vec are in genes, social media graphs, likes, etc. In a vector space, similar words are grouped using word2vec without the need for human intervention.
X: XGBoost –Boosting is a technique in machine learning by which a strong learner strengthens a weak learner in subsequent steps.
XGBoost is one such boosting algorithm which is robust to outliers, or NULL values. It is the go-to algorithm in Machine Learning competitions for its speed and accuracy.
Y: Yarn –YARN is a component of Hadoop which lies between HDFS, and the processing engines. In individual cluster nodes, the processing operations monitored by YARN.
The dynamic allocation of resources is also handled by it, which improves application performance and resource utilization.
Z: Z-test –A type of hypothesis testing used to determine whether to reject or accept the NULL hypothesis. By how many standard deviations, a data point is further away from the mean could be calculated using Z-test.
Conclusion
In this blog post, we covered some of the terms related to the analytics starting with each letter in the English.
If you are willing to learn more about Analytics, follow the blogs and courses of Dimensionless.
Follow this link, if you are looking to learn more about data science online!
Additionally, if you are having an interest in learning Data Science, Learnonline Data Science Course to boost your career in Data Science.
Furthermore, if you want to read more about data science, you can read our blogs here
Big Data is the term that is circling everywhere in the field of analytics in the modern era. The rise of this term came about as the result of the enormous volume of unstructured data that is getting generated from a plethora of sources. Such voluminous unstructured data carries huge information which if mined properly could help a business achieve ground breaking results.
Hence, it’s wide range of applications has made Big Data popular among masses and everyone wants to master the skill associated with it to embrace the lucrative career opportunities that lies ahead. For the data professionals, many companies have various open positions in the job market and the number is only going to increase in the future.
Reason of the craze behind Big Data
The opportunities in the domain of Big Data is diverse and hence its craze is spreading rapidly among professionals from different fields like Banking, Manufacturing, Insurance, Healthcare, E-Commerce, and so on. Below are some of the reasons why its demand keeps on rising.
Talent shortage in Big data – Despite its every increasing opportunity, there is a significant shortage in the number of professionals who are actually trained to work in this field. Those work in IT are generally accustomed with software development or testing, while people from other fields are familiar with spreadsheets, databases and so on.
However, the required skill to load and mine Big Data is missing significantly which makes it the job which is up for grabs for anyone who could master the skills. Business Analysts and managers along with the engineers needs to be familiar with the skills required to work with Big data.
Variety in the types of jobs available – The term Big Data is somewhat holistic and could be misleading in defining the job descriptions for an open position. Even many people use this term in several situations without actually understanding the meaning behind its implementation.
There could be several job types available in the market which has the term Big Data in it. The domain of work could vary from Data analytics to Business analysis to Predictive analytics. It makes easier for one to choose among the various types and train oneself accordingly. Companies like Platfora, Teradata, Opera, etc., have many opportunities in big data for their different business needs.
Lucrative salary – One of the major reasons why professionals are hoping onto the big data ecosystem is the salary that it offers. As it’s a niche skill, hence companies are ready to offer competitive packages to the employees. Those who wants a learning curve and sharp growth in their career, big data could prove to be the perfect option for them.
As mentioned before, there are a variety of roles which requires big data expertise. Below are the opportunities based on the roles in the field of big data.
Big Data Analyst – One of the most sought after roles in Big Data is that of a Big Data Analyst. To interpret data and extract meaningful information from it which could help the business grow and influence the decision making process is the work that a big data analyst does.
The professional also needs to have an understanding of tools such as Hadoop, Pig, Hive, etc. Basic statistics and algorithms knowledge along with the analytics skills is required for this role. For the analysis of data, domain knowledge is another important factor needed. To flourish in this role some of the qualities that is expected from a professional are –
Reporting packages and data model experience.
The ability to analyze both structured and unstructured data sets.
The skill to generate reports that could be presented to the clients.
Strong written and verbal communication skills.
An inclination towards problem solving and an analytical mind.
Providing attention to detail.
The job description for a big data analyst includes –
Interpretation and the collection of data.
To the relevant business members, reporting the findings.
Identification of trends and patterns in the data sets.
Working alongside the management team or business to meet the business needs.
Coming up with new analysis and data collection process.
Big Data Engineer – The design of a big data solutions architect is built upon by the big data engineer. Within the organizations, the development, maintenance, testing, and evaluation of the big data solutions is done by the big data engineer. They also tend to have experience in Hadoop, Spark, and so on, and hence are involved in designing big data solutions. An expert in data warehousing, who builds data processing systems and are comfortable working in the latest technologies.
In addition to this, the understanding of software engineering is also important for someone moving into the big data domain. Experience in engineering large-scale data infrastructures and software platforms should be present as well. Some of the programming or scripting languages a big data engineer should be familiar with are Java, Linux, Python, C++, and so on. Moreover, the knowledge of database systems like MongoDB is also crucial. Using Python or Java, a big data engineer should have a clear sense of building processing systems with Hive and Hadoop.
Data Scientist – Regarded as the sexiest job of the 21st century, a Data Scientist is the regarded as the captain of the ship in the analytical Eco space. A Data Scientist is expected to have a plethora of skills stating from Data Analysis to building models to even client presentations.
In traditional organizations, the role of a Data Scientist is getting more importance as the way the old-school organizations used to work are now changing with the advent of big data. It’s now easier than ever to decipher the data starting from HR to R&D.
Apart from analyzing the raw data and drawing insights using Python, SQL, Excel, etc., a Data Scientist should also be familiar with building predictive models using Machine Learning, Deep Learning, and so on. Those models could save time and money for a business.
Business Intelligence Analyst – This role revolves around gathering data via different sources and also compare that with a competitor’s data. A picture of company’s competitiveness would be developed by a Business Intelligence Analyst compared to other players in the market. Some of the responsibilities of a Business Intelligence Analyst are –
Managing BI solutions.
Through the applications lifecycle, provide reports and Excel VBA applications.
Analyze the requirements and the business process.
Requirements, design, and user manual documentations.
Identifying the opportunities with technology solutions to improve strategies and processes.
Identifying the needs to streamline and improve operations.
Machine Learning Engineer – A software engineer specialized in machine learning fulfils the role of a Machine Learning Engineer. Some of the responsibilities that a Machine Learning Engineer carries out are –
Running experiments with machine learning libraries using a programming language.
The production deployment of the predictive models.
Optimizing the performance and the scalability of the applications.
Ensuring a seamless data flow between the database and backend systems.
Analyzing data and coming up with new use cases.
Global Job Market of Big Data
Businesses and organizations have now put special attention to the full potential of Big Data. India has a large concentration of the jobs available in the big data market. Below are some of the notable points related to the job market of big data.
It is estimated that by 2020, that the number would be approximately seven lakhs for the opportunities surrounding the role of Data Engineers, Big Data Developers, Data Scientists., and so on.
The average time for which an analytics job stays in the market is longer than the other jobs. The compensation for a big data professional is also forty percent more than other IT skills.
Apache Spark, Machine Learning, Hadoop, etc., are some of the skills in the Big Data domain which are the most lucrative. However, hiring such professionals require higher cost and hence it is necessary that better training programs are provided.
Retail, manufacturing, IT, finance is some of the industries which hire big data expertise people.
People with relevant big data skills are a rarity and hence there is a gap between demand and supply. Hence, the average salary is high for people who are working in this field which is more than 98 percent than in general.
How to be job ready?
Despite the rising opportunities in big data, there is still a lack of relevant skills among the professionals. Hence, it is necessary to get your basics right. You should be familiar with the tools and technique coupled up with the domain knowledge would certainly put you in the driving seat.
Tools like Hive, Hadoop, SQL, Python, Spark are mostly used in this space and hence you should know most of them. Moreover, one should get their hands dirty and work in as many productions based projects as possible to tackle any kind of issues faced during analysis.
Conclusion
There is a huge opportunity for big data and now is the best time than ever to keep on learning and improving your skills.
If you are willing to learn more about Big Data or Data Science in general, follow the blogs and courses of Dimensionless.
Follow this link, if you are looking to learn more about data science online!
Additionally, if you are having an interest in learning Data Science, Learnonline Data Science Course to boost your career in Data Science.
Furthermore, if you want to read more about data science, you can read our blogs here
It is said that most of the modern-day data have been generated in the past few years. The advancement in technology and the growth of the internet is the source of such voluminous unstructured data which is rapidly changing the dynamics of our daily lives. No wonder, Prof. Andrew NG said – ‘Data is the new electricity’.
Introduction
We refer to such data which exhibits the properties such as volume, variety, veracity, and value as Big Data. Big Data Developers has built several architectures to get the best out of this big data. Two such frameworks are Hadoop and Spark.
In this blog post, I would provide a brief about Apache Spark and Amazon EMR and then we would learn how memory of an Apache Spark application could be managed on Amazon EMR.
What is Apache Spark?
Though Hadoop was the most popular Big Data framework built, it lacked the real time data processing capabilities which Spark provides. Unlike in Hadoop, Spark uses both memory and disk for data processing.
The applications in Spark are written mainly in Scala, Java, Python. Other libraries like SQL, Machine Learning, Spark Streaming, and so on are also included. It makes Spark flexible for a variety of use cases.
Many big organizations have incorporated Spark in their application to speed up the data engineering process. It has a directly acyclic graph which boosts performance. A detailed description of the architecture of Spark is beyond the scope of this article.
What is Amazon EMR?
The processing and analysis of Big data in Amazon Web Services is done with the help of a tool known as the Amazon Elastic Map Reduce. As an alternative to in-house cluster computing, an expandable low configuration service is provided by Amazon EMR.
On Apache Hadoop, the Amazon EMR is based upon and across the Hadoop cluster on Amazon EC2 and Amazon S3, the big data is processed. The dynamic resizing ability is referred to by the elastic property which allows flexible usage of resources based on the needs.
In the scientific simulation, data warehousing, financial analysis, machine learning, and so on, the Amazon EMR is used for data analysis. The Apache Spark based workloads are also supported by it which we would see later in this blog.
Managing Apache Spark Application Memory on Amazon EMR
As mentioned earlier, the running of the big data frameworks like Hadoop, Spark, etc., are simplified by the Amazon EMR. ETL or Extract Transform Load is one of the common use cases in the modern world to generate insights from data and one of the best cloud solutions to analyse data is Amazon EMR.
Through parallel processing, various business intelligence and data engineering workloads managed using Amazon EMR. It reduces time, effort, and costs that is involved in scaling and establishing a cluster.
In the distributed processing of big data, a fast, open source framework known as Apache Spark is widely used which relies on RAM performing parallel computing and reducing the input output time. On Amazon EMR, to run a Spark application below steps are performed.
To Amazon S3, the Spark application package is uploaded.
The Amazon EMR cluster is configured and launched with Apache Spark.
From Amazon S3, the application package is installed onto the cluster and the application is ran.
The cluster is terminated post the completion of the application.
Based on the requirements, the Spark application needs to be configured appropriately. There could be virtual and physical issues if the default settings are kept. Below are of the memory related issues in Apache Spark.
Exceeding physical memory – When limits are exceeded, YARN kills the container and throws an error message: Executor Lost Failure: 4.5GB of 3GB physical memory used limits. It would even ask you to boost spark.yarn.executor.memoryOverhead.
Exceeding virtual memory – If the virtual memory exceeds, Yarn kills the container.
Java Heap Space – This is a very common memory issue that we face when the Java Heap Space is out of memory. The error message thrown is java.lang.OutOfMemoryError.
Exceeding Executor memory – When the executor memory required is above a threshold, we get an out of memory error.
Some of the reasons why the above reasons occur are –
Due to the inappropriate setting of the executor memory, executor instances, the number of cores, and so on to handle large volumes of data.
When the YARN allocated memory is exceeded by the Spark executor’s physical memory which creates issues while handling memory intensive operations.
In the Spark executor instance, when memory is not available to perform operations like garbage collection and so on.
On Amazon EMR, to successfully configure a Spark application, the following steps should be performed.
Step 1: Based on the application needs, the number and the type of instances should be determined
There are three types of nodes in Amazon EMR.
The one master node which manages the cluster and acts as a resource manager.
The master node manages the core nodes. The Map-Reduce tasks, the Node Manager daemons are run by the core nodes which executes tasks, manages storage, and sends a report back to the master which gives information about its activeness.
The task node which only performs but doesn’t save the data.
The R-type instances are preferred for memory-based applications while the C type of instances is preferable for compute-intensive applications. The M-type instances provides a balance between compute and memory applications. The number of instances following the selection of the instance type is done based on the execution time of the application, input data sets, and so on.
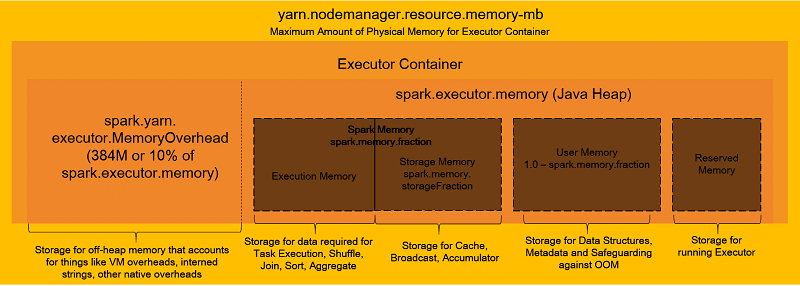
Step 2: Determining the configuration parameters of Spark
source: AWS
There are multiple memory compartments in the Spark executor container among which the only one executes the task. Some of the parameters which need to be configured efficiently are –
For each executor, the size of memory that is required to run the task represented by spark.executor.memory. The formula for executor memory is given by the total per instance RAM divided by the per-instance executor’s number.
The number of virtual cores given by spark.executor.cores. A large number of virtual cores leads to reduced parallelism while vice versa results in high I/O operations. Thus, five virtual cores are optimal.
The driver memory size – spark.driver.memory. This should be equal to the spark.executor.memory.
The driver’s virtual cores number – spark.driver.cores. Setting its value equal to the spark.executor.core is recommended.
The executor’s number – spark.executor.instances. This is calculated by multiplying per instance number of executors with the core instances and subtracting one from the product.
In RDD, the default number of partitions – spark.default.parallelism. To set its value, multiply spark.executor.instances with spark.executor.cores and two.
Some of the parameters which need to be set in the default configuration file to avoid memory and time-out related issues are.
All network transactions timeout – spark.network.timeout.
Each executor’s heartbeats interval – spark.executor.heartbeatInterval.
To save space by compressing the RDDs, the spark.rdd.compress property is set to True.
To compress the data during shuffles, spark.shuffle.compress is set to true.
For joins and aggregations, the number of partitions is set by spark.sql.shuffle.partitions.
The map output is compressed by setting spark.shuffle.compress to True.
Step 3: To clear memory, a garbage collector needs to be implemented
In certain scenarios, out-of-memory errors is led by the garbage collection. In the application, when there are multiple RDDs, such cases would occur. An interference between RDD cached memory and task execution memory would also lead to such cases.
To replace old objects with new in the memory, multiple garbage collectors could be used. The limitations with the old garbage collector could be overcome with the Garbage First Garbage Collector.
Step 4: The Configuration parameters of YARN
The YARN site setting should be set accordingly to prevent virtual-out-of-memory errors. The physical and virtual memory flag should be set to False.
Step 5: Monitoring and debugging should be performed
To monitor the progress of the Spark application Network I/O, etc., the Spark UI and Ganglia should be used. To manage 10 terabytes of data successfully in Spark, we need at least 8 terabytes of RAM, 170 instances of executor, 37 GB of executor per memory, the total virtual CPU’s of 960, 1700 parallelism, and so on.
The default configurations of Spark could lead to out of physical memory error as the configurations are incapable of processing 10 terabytes of data. Moreover, the memory is not cleared efficiently by the default garbage collectors leading to failures quite often.
The future of Cloud
Technology is gradually moving from traditional infrastructure set up to an all cloud-based environment. Amazon Web Services is certainly a frontrunner in cloud services which lets you build and deploy scalable applications at a reasonable cost. It also ensures payment for only those services which are required.
As the size of the data would increase exponentially in the future, it is pertinent that companies and employees master learn the art of using cloud platforms like AWS to build robust applications.
Conclusion
Apache Spark is one of the most sought-after big frameworks in the modern world and Amazon EMR undoubtedly provides an efficient means to manage applications built on Spark.In this blog post, we learned about the memory issues in an Apache Spark application and the measures taken to prevent it.
If you are willing to learn more about Big Data or Data Science in general, follow the blogs and courses of Dimensionless.
Follow this link, if you are looking to learn more about data science online!
Additionally, if you are having an interest in learning Data Science, Learnonline Data Science Course to boost your career in Data Science.
Furthermore, if you want to read more about data science, you can read our blogs here
Data is the new oil and its usage has spread across various domains in the modern world. Professionals from various disciplines like banking, marketing, manufacturing, healthcare, and so on are leveraging the potential of data to streamline their business and stay ahead of their competitors in the market.
It is believed that most of the world’s data have generated in the last few years which is the result of the plethora of channels and medium that’s available these days and also the growing popularity of social media. Those channels generate billions of terabytes of data which if mined properly has the potential to achieve groundbreaking results.
Some of the popular terms related to data are Machine Learning, Deep Learning, Artificial Intelligence, Data Science, and so on. These are the mechanisms in which you derive insights from your data. One of the most used applications of AI is in the field of Healthcare.
Artificial Intelligence in Healthcare
The reliance on independent computer intelligence in healthcare by some of the computer generated solutions are gone in the modern generation. Instead, to analyze data and recommend treatments, human-created algorithms are used. The computer could expand and work on the way human brain functions with the help of neural networks which is the core of Deep Learning.
The concept of Deep Learning is getting increasingly popular in the healthcare industry largely due to its ability to extract complex patterns from data and predict state-of-the-art results. The independent operation of neural networks to separate color, size, etc., can give better outcomes. The transformation of diagnostic medicine and also at an individual cell, the search for cancer could be achieved by such new tools.
The evidence-based approaches are the most commonly used Artificial Intelligence applications in the healthcare industry today. The extraction of information and its application could be done when algorithms get data embedded into them by humans. The combination of appropriate chemotherapy drugs could be recommended by reviewing hundreds of treatment alternatives.The team in the Permanente Medical Group created a model which identifies the patients who could be in the ICU tomorrow. Into a computer system, the algorithm was embedded afterward. The hospitalized patient’s health status was continuously monitored. Whenever a patient was at risk, the physicians were alerted. This could help save thousands of lives by notifying the doctors well in advance.
Visual pattern recognition is another methodology which has made significant strides in the healthcare industry. Using the same human heuristic techniques, it could store thousands of images and is accurate than an average physician by 5% to 10%. In the future, the accuracy could be further between the human and the digital eye. With deep learning gaining traction and machines becoming more powerful, diagnostic methods such as CT, MRI, rash identification, microscopic diagnosis, lesion evaluation, the cardiovascular disease would continue to advance.
Detecting Rare Diseases with Artificial Intelligence
source: The Times
A research carried out at the University of Bonn showed that the diagnosis could be improved by combining portrait photos with genetic and patient data. A rare hereditary disease affects almost half a million children worldwide every year. It could be difficult and time-consuming to obtain a definitive diagnosis. This study was carried out with six hundred and seventy-nine patients and hundred and five rare diseases which concluded that rare diseases could be diagnosed effectively and reliably with the help of artificial intelligence.
The combination of portrait photos with generic and patient data is automatically achieved by the neural networks. In the ‘Genetics of Medicine’ journal, the results are presented. Before the correct diagnosis, a long trail and tribulation process has to be followed by patients with rare diseases. For an early therapy, valuable time is needed to avert progressive damage which could be lost.
Prof. Peter Krawitz, demonstrated the quick and effective diagnosis in facial analysis with the help of artificial intelligence. He did this along with some international team of researchers. The six hundred and seventy-nine patient’s data with a hundred and five different diseases were caused by a change in a single gene. Learning difficulties, stunted growth, bone deformation, etc., was included as well. The intellectual disability was a result of Mabry syndrome. Abnormalities are shown in the faces of those who are affected. This could also be referred to the Kabuki syndrome which is the Japanese traditional form of theatre. The eyelids spaces are long, eye-distance is wide and the eyebrows are arched.
All these characteristic features could be detected by the software from the photo. The most likely of diseases involved could be calculated from the data of the patients and genetic symptoms. DeepGestalt, a neural network developed by FDNA which is an Artificial Intelligence and digital health company.
DeepGestalt was programmed after the computer program was trained with thirty thousand pictures of people suffering from syndrome diseases which are rare. The decisive genetic factors could be filtered out with the combination of facial analysis. A higher rate of diagnosis is a result of the reduction of time in data analysis caused after merging data in a neuronal network. This development enables solving various unsolved cases. Patient’s life could be improved by some extent with the help of this.
The approach of the physicians and the health systems supporting them has a lot of difference between them. AI present various solutions to reduce the gulp between them. Physician’s performance could be radically improved by two Artificial Intelligence approaches. Natural Language processing which interprets natural data in the form of speech and text is one of them. Thousands of medical records could be reviewed by it which would help to evaluate patients suffering from multiple illnesses. Another approach would be reinforcement learning where the doctors would be watched by computers working.
A USA based start-up, Forward uses Artificial Intelligence to follow doctors instead of retrospectively extracting and analyzing the data. The physician’s best work is recorded and analyzed by the computers which benefit patients and their colleagues as well. If the worldwide performance matches the top twenty percent, then diseases like infection, cancer, etc., would decrease substantially.
Mathematics is not the biggest barrier to artificial intelligence. However, it is the acceptance of doctor’s intuition instead of the evidence-based solutions causing the barrier. Physicians rarely tend to defer from their beliefs and it would become more difficult in the coming years when the machine would start to loom over their shoulders.
Investment in AI is expected from the businessmen and the entrepreneurs. Medicine could be taken far beyond its current capability with the help of Machine Learning and Artificial Intelligence. To take the best approaches, creating new diagnosis approaches, hundreds of medical problems treatments, and so on could be achieved with the help of AI.
Medical organizations which are integrated and technology-enabled would acquire these advances sooner. On smartphones or tablets, these solutions could be embraced first followed by pattern recognition software. In the future, various Artificial Intelligence tools could be used by patients themselves and take of their lives as they do with other aspects.
Understanding the Fear of Artificial Intelligence
Despite all the advances that Artificial Intelligence has made and still continue to bring in new studies to solve medical cases, there is a certain fear about AI. From nurse-bots to AI wearables, various solutions have been proposed by several tech firms and start-ups which are not transformative. These are not true machine learning approaches and are just algorithmic in nature. Many have failed in pursuit to deliver quality.
There is a fear that humans would be replaced by machines with AI being the next hyped big thing in medicine. However, these features are more of science-fiction. More than the danger, it offers more opportunities. Machine learning tools would soon be an irreplaceable thing to the physicians as the computer speeds increases in the next ten years.
However, there is a difficult truth that we need to accept. There would be a disappearance of some healthcare jobs if the quality is improved and the cost is lowered in healthcare by technology. Within the next twenty years, Artificial Intelligence could take over most of the market. The pressure is now felt by doctors and several health professionals. However, if new systems improve lives, then it would certainly be adopted. The physician’s role would certainly change in the future. However, it’s still a long way to go before the machine could take the role of physicians and show the same level of empathy which the patients expect.
Conclusion
Deep Learning and Artificial Intelligence could produce several states of the art results if used accurately on relevant data. There are several types of research still going on in medical science to see if AI could eradicate several rare diseases. This article covered some of the practices of AI and how it could be used to detect and treat several rare diseases.
Dimensionless has several blogs and training to get started with Python, and Data Science in general.
After completing high school, I seemed to run after the best colleges or universities in the country or abroad to complete my graduation in flying colours because that was necessary to land myself a good job or take the next step in my career. However, once I completed my graduation, I was unsure and did not know what to do next – whether to get placed with a big organization or continue higher studies.
While some decide on earning straightway, others tend to fulfill their dream of getting a management degree and completing their MBA from a reputed organization. The sky is the limit when you enroll in an MBA program full of belief, hope, desire, and enthusiasm. However, once the graduation time comes closer, we tend to be lost in our choices as to what to do next after acquiring an MBA degree.
Facts About MBA Graduates
At first, I would look into some statistics. Since 2010, the recent grad’s employer demand has reached its highest level as announced in its forward-looking Corporate Recruiters Survey by GMAC which is an organization that administers in the GMAT exam. In a survey which was conducted in the year, 2016 in the month of February and March stated that the recruiters prefer to hire recent graduates from the business schools which was about eighty-eight percent compared to the eighty percent of the companies that hired in the previous year.
In the current MBA market, jobs are still there and there is no reason to worry. However, you might not be satisfied with the job role or the company you are getting recruited for and hence you need to reskill yourself like I did for that particular role and be ready with the opportunity comes. You need to have patience and keeping improving your skills.
Have a Plan
All MBA graduates must have a plan, and hence not having a plan for an MBA graduate is not typical of. It’s a once in a lifetime experience that students get to pursue an MBA. Generally, in advance, students know what they would do after graduation. On the back of several years of work experience, and after careful consideration, the decision to do an MBA was taken. Most MBA graduates have a clear picture of their career and know what they want to do. It is not a wise strategy to decide what to do after obtaining an MBA degree.
I was fully aware of what I would want to achieve in life and was always looked after by the admission committee. Based on self-understanding, a clear thought out career strategy is what the admissions officers would want to see. Why you want to do an MBA and your goals after completing is what they are most interested in.
Based on the professional path of mine, the MBA program was considered by me. The right MBA programs could only be selected when in mind you have clear career goals. Whether an MBA meets your need or how your career could be boosted could only be known after that. On your own scale, each program value could be rated and the facts could be uncovered. For a newly minted MBA grad, it is very important to be realistic. Adam Heyler once said in his youtube channel that your CV could become credible and your network would be expanded if you have the MBA degree. But the lack of work experience would not certainly be made up the MBA degree. Time management is also an important factor which is taught by MBA.
The Post MBA Dilemma
source: PrepAdviser
The current job market possesses a tremendous challenge to every professional, even someone with a lucrative degree as MBA. Gone are those days when an MBA degree guarantees you a high paying job in a big firm. Nowadays, the wave of entrepreneurship has engulfed many and hence so many graduates are moving towards entrepreneurship and starting out their venture. However, it is not a piece of cake to be an entrepreneur in this competitive market and almost ninety percent of start-ups fail after its inception. I was not into entrepreneurship and choose to upgrade myself and follow my dream.
I pursued my MBA in Finance which is often a go-to choice for many students during their graduation certainly due to the prospects of working in major insurance or a banking company. I wanted to work as a Business Analyst, Risk Analyst, and so on. Thus it was pertinent for me to develop an analyst intuition and master the analytical tools such as SQL, Excel, Tableau, etc. If you are interested in working as a Decision Scientist or a Data Scientist, you need to upgrade your skills like me to more advanced skills like Machine Learning, Deep Learning and so on.
However, once I found the potential that data carries and the diverse nature of this field, I wanted to expand my horizons and work as a Data Science consultant in some big corporation and hence I started exploring other domains like Marketing, Human Resource and so on. MBA in Marketing is another such lucrative career with high post-graduation opportunity. Some of the work designation after completing MBA in marketing are – Research Manager or a Senior Analyst, Marketing Analyst, and so on. Data is the new oil and all marketing firms are using the unprecedented potential of data to market their product to the right customers and stay ahead in the race.
Being a Marketing Analyst, you would be responsible to gather data from various sources and thus having the skills of data collection or web scraping is very important. Additionally, I learned at least of data visualization tool like Excel, Tableau, Power BI and others to analyse the performance of different marketing camp gain which could be presented to the shareholders who would make the final business decision. Overall, it was about finding patterns in the data using various tools and ease the process of making decisions for the stakeholders.
MBA in Human Resource may not be as lucrative as the above two but certainly has its own share of value in terms of responsibility and decision making. Whether or not you have been employed as an HR after your graduation has no relation to the fact that you need to Master HR Analytics which I did that would help in dealing with employees.
As an HR professional, you would be engaged mostly in employee relations and thus it is necessary to understand the satisfaction level of each employee and deal with them separately. Onboarding a resource garners a huge amount of financial cost and hence predicting the attrition probability of an employee could avoid financial loss. Thus, data collection and machine learning are two of the important skills which I learned further along with my interpersonal skills.
Supply Chain Management has been in demand and I realized it is important to understand applications of Data Science in this regard because it could take me a long way in my career. The impact of supply chain dynamics could be analysed using the right analytical tools. Data could be collected and leveraged to identify the efficiency of the supply chain.
Additionally, the price fluctuations, commodities availability could also be analysed using Data. If you master Data Analytics like me, you could reduce the risk burden of an organization.
Healthcare management is another important field where students pursue an MBA which deals with practices related to the Healthcare industry. As Data Science had a vast application in the healthcare industry, I had to get my hands dirty and learn the nitty-gritty of analyzing a healthcare dataset. In the HealthCare careful usage of data could lead to ground-breaking achievements in the field of medical science. Applying analytics with relevant data could help in reducing medical cost and also channel the right medicine for a patient.
Deep Learning has made tremendous progress in the HealthCare industry and hence I took some time to understand the underlying working structure of neural networks. It could unearth hidden information from the patient’s data and help in prescribing the appropriate Medicare of the patient.
Conclusion
Though this was a generic overview of the skills I mastered for my own career aspirations after pursuing my MBA. In general, analytics is the need of the hour and every MBA graduate or each professional irrespective of the field they are in could certainly dive into this field without any prior relevant experience. In the beginning, I felt a bit overwhelmed by the vastness of the field but as I moved along I found it interesting and gradually get inclined towards the field.
Overall, along with the management skills, the technical expertise to deal with data and derive relevant information from it would land you a much higher role of a manager or a consultant in a firm which I eventually managed to achieve where you would be the decision maker for your team. Upskilling is very important in today’s world to stay relevant and keep in touch with the rapid advancement in technology.
Dimensionlesshas several blogs and training to get you started with Data Analytics and Data Science.
Never thought that online trading could be so helpful because of so many scammers online until I met Miss Judith... Philpot who changed my life and that of my family. I invested $1000 and got $7,000 Within a week. she is an expert and also proven to be trustworthy and reliable. Contact her via: Whatsapp: +17327126738 Email:judithphilpot220@gmail.comread more
A very big thank you to you all sharing her good work as an expert in crypto and forex trade option. Thanks for... everything you have done for me, I trusted her and she delivered as promised. Investing $500 and got a profit of $5,500 in 7 working days, with her great skill in mining and trading in my wallet.
judith Philpot company line:... WhatsApp:+17327126738 Email:Judithphilpot220@gmail.comread more
Faculty knowledge is good but they didn't cover most of the topics which was mentioned in curriculum during online... session. Instead they provided recorded session for those.read more
Dimensionless is great place for you to begin exploring Data science under the guidance of experts. Both Himanshu and... Kushagra sir are excellent teachers as well as mentors,always available to help students and so are the HR and the faulty.Apart from the class timings as well, they have always made time to help and coach with any queries.I thank Dimensionless for helping me get a good starting point in Data science.read more
My experience with the data science course at Dimensionless has been extremely positive. The course was effectively... structured . The instructors were passionate and attentive to all students at every live sessions. I could balance the missed live sessions with recorded ones. I have greatly enjoyed the class and would highly recommend it to my friends and peers.
Special thanks to the entire team for all the personal attention they provide to query of each and every student.read more
It has been a great experience with Dimensionless . Especially from the support team , once you get enrolled , you... don't need to worry about anything , they keep updating each and everything. Teaching staffs are very supportive , even you don't know any thing you can ask without any hesitation and they are always ready to guide . Definitely it is a very good place to boost careerread more
The training experience has been really good! Specially the support after training!! HR team is really good. They keep... you posted on all the openings regularly since the time you join the course!! Overall a good experience!!read more
Dimensionless is the place where you can become a hero from zero in Data Science Field. I really would recommend to all... my fellow mates. The timings are proper, the teaching is awsome,the teachers are well my mentors now. All inclusive I would say that Kush Sir, Himanshu sir and Pranali Mam are the real backbones of Data Science Course who could teach you so well that even a person from non- Math background can learn it. The course material is the bonus of this course and also you will be getting the recordings of every session. I learnt a lot about data science and Now I find it easy because of these wonderful faculty who taught me. Also you will get the good placement assistance as well as resume bulding guidance from Venu Mam. I am glad that I joined dimensionless and also looking forward to start my journey in data science field. I want to thank Dimensionless because of their hard work and Presence it made it easy for me to restart my career. Thank you so much to all the Teachers in Dimensionless !read more
Dimensionless has great teaching staff they not only cover each and every topic but makes sure that every student gets... the topic crystal clear. They never hesitate to repeat same topic and if someone is still confused on it then special doubt clearing sessions are organised. HR is constantly busy sending us new openings in multiple companies from fresher to Experienced. I would really thank all the dimensionless team for showing such support and consistency in every thing.read more
I had great learning experience with Dimensionless. I am suggesting Dimensionless because of its great mentors... specially Kushagra and Himanshu. they don't move to next topic without clearing the concept.read more
My experience with Dimensionless has been very good. All the topics are very well taught and in-depth concepts are... covered. The best thing is that you can resolve your doubts quickly as its a live one on one teaching. The trainers are very friendly and make sure everyone's doubts are cleared. In fact, they have always happily helped me with my issues even though my course is completed.read more
I would highly recommend dimensionless as course design & coaches start from basics and provide you with a real-life... case study. Most important is efforts by all trainers to resolve every doubts and support helps make difficult topics easy..read more
Dimensionless is great platform to kick start your Data Science Studies. Even if you are not having programming skills... you will able to learn all the required skills in this class.All the faculties are well experienced which helped me alot. I would like to thanks Himanshu, Pranali , Kush for your great support. Thanks to Venu as well for sharing videos on timely basis...😊
I highly recommend dimensionless for data science training and I have also been completed my training in data science... with dimensionless. Dimensionless trainer have very good, highly skilled and excellent approach. I will convey all the best for their good work. Regards Avneetread more
After a thinking a lot finally I joined here in Dimensionless for DataScience course. The instructors are experienced &... friendly in nature. They listen patiently & care for each & every students's doubts & clarify those with day-to-day life examples. The course contents are good & the presentation skills are commendable. From a student's perspective they do not leave any concept untouched. The step by step approach of presenting is making a difficult concept easier. Both Himanshu & Kush are masters of presenting tough concepts as easy as possible. I would like to thank all instructors: Himanshu, Kush & Pranali.read more
When I start thinking about to learn Data Science, I was trying to find a course which can me a solid understanding of... Statistics and the Math behind ML algorithms. Then I have come across Dimensionless, I had a demo and went through all my Q&A, course curriculum and it has given me enough confidence to get started. I have been taught statistics by Kush and ML from Himanshu, I can confidently say the kind of stuff they deliver is In depth and with ease of understanding!read more
If you love playing with data & looking for a career change in Data science field ,then Dimensionless is the best... platform . It was a wonderful learning experience at dimensionless. The course contents are very well structured which covers from very basics to hardcore . Sessions are very interactive & every doubts were taken care of. Both the instructors Himanshu & kushagra are highly skilled, experienced,very patient & tries to explain the underlying concept in depth with n number of examples. Solving a number of case studies from different domains provides hands-on experience & will boost your confidence. Last but not the least HR staff (Venu) is very supportive & also helps in building your CV according to prior experience and industry requirements. I would love to be back here whenever i need any training in Data science further.read more
It was great learning experience with statistical machine learning using R and python. I had taken courses from... Coursera in past but attention to details on each concept along with hands on during live meeting no one can beat the dimensionless team.read more
I would say power packed content on Data Science through R and Python. If you aspire to indulge in these newer... technologies, you have come at right place. The faculties have real life industry experience, IIT grads, uses new technologies to give you classroom like experience. The whole team is highly motivated and they go extra mile to make your journey easier. I’m glad that I was introduced to this team one of my friends and I further highly recommend to all the aspiring Data Scientists.read more
It was an awesome experience while learning data science and machine learning concepts from dimensionless. The course... contents are very good and covers all the requirements for a data science course. Both the trainers Himanshu and Kushagra are excellent and pays personal attention to everyone in the session. thanks alot !!read more
Had a great experience with dimensionless.!! I attended the Data science with R course, and to my finding this... course is very well structured and covers all concepts and theories that form the base to step into a data science career. Infact better than most of the MOOCs. Excellent and dedicated faculties to guide you through the course and answer all your queries, and providing individual attention as much as possible.(which is really good). Also weekly assignments and its discussion helps a lot in understanding the concepts. Overall a great place to seek guidance and embark your journey towards data science.read more
Excellent study material and tutorials. The tutors knowledge of subjects are exceptional. The most effective part... of curriculum was impressive teaching style especially that of Himanshu. I would like to extend my thanks to Venu, who is very responsible in her jobread more
It was a very good experience learning Data Science with Dimensionless. The classes were very interactive and every... query/doubts of students were taken care of. Course structure had been framed in a very structured manner. Both the trainers possess in-depth knowledge of data science dimain with excellent teaching skills. The case studies given are from different domains so that we get all round exposure to use analytics in various fields. One of the best thing was other support(HR) staff available 24/7 to listen and help.I recommend data Science course from Dimensionless.read more
I was a part of 'Data Science using R' course. Overall experience was great and concepts of Machine Learning with R... were covered beautifully. The style of teaching of Himanshu and Kush was quite good and all topics were generally explained by giving some real world examples. The assignments and case studies were challenging and will give you exposure to the type of projects that Analytics companies actually work upon. Overall experience has been great and I would like to thank the entire Dimensionless team for helping me throughout this course. Best wishes for the future.read more
It was a great experience leaning data Science with Dimensionless .Online and interactive classes makes it easy to... learn inspite of busy schedule. Faculty were truly remarkable and support services to adhere queries and concerns were also very quick. Himanshu and Kush have tremendous knowledge of data science and have excellent teaching skills and are problem solving..Help in interviews preparations and Resume building...Overall a great learning platform. HR is excellent and very interactive. Everytime available over phone call, whatsapp, mails... Shares lots of job opportunities on the daily bases... guidance on resume building, interviews, jobs, companies!!!! They are just excellent!!!!! I would recommend everyone to learn Data science from Dimensionless only 😊read more
I am very glad to be part of Dimensionless .Their dedication, in-depth knowledge, teaching and the way they explain to... clarify doubts is tremendous . I recommend this to everyone who wish to build their career in Data Science
With whole heartedly I wish them for their success & future prospectsread more
Being a part of IT industry for nearly 10 years, I have come across many trainings, organized internally or externally,... but I never had the trainers like Dimensionless has provided. Their pure dedication and diligence really hard to find. The kind of knowledge they possess is imperative. Sometimes trainers do have knowledge but they lack in explaining them. Dimensionless Trainers can give you ‘N’ number of examples to explain each and every small topic, which shows their amazing teaching skills and In-Depth knowledge of the subject. Himanshu and Kush provides you the personal touch whenever you need. They always listen to your problems and try to resolve them devotionally.
I am glad to be a part of Dimensionless and will always come back whenever I need any specific training in Data Science. I recommend this to everyone who is looking for Data Science career as an alternative.
All the best guys, wish you all the success!!read more