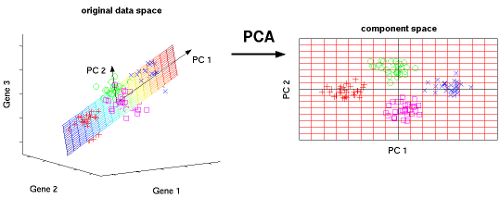
Principal Component Analysis or PCA is one of the simplest and fundamental techniques used in machine learning. It is perhaps one of the oldest techniques available for dimensionality reduction, and thus, its understanding is of paramount importance for any aspiring Data Scientist/Analyst. An in-depth understanding of PCA in R will not only help in the implementation of effective dimensionality reduction but also help to build the foundation for development and understanding of other advanced and modern techniques.
Examples of Dimension Reduction from 2-D space to 1-D space Courtesy: Bits of DNA
PCA aims to achieve two
primary goals:
1. Dimensionality
Reduction
Real-life data has several features generated from numerous resources. However, our machine learning algorithms are not adept enough to handle high dimensions efficiently. Feeding several features, all at once, almost always leads to poor results since the models cannot grasp and learn from such volume altogether. This is called the “Curse of Dimensionality” which leads to unsatisfactory results from the models implemented. Principal Component Analysis in R helps resolve this problem by projecting n dimensions to n-x dimensions (where x is a positive number), preserving as much variance as possible. In other words, PCA in R reduces the number of features by transforming the features into a lesser number of projections of themselves.
2. Visualization
Our visualization systems are limited to 2-dimensional space which prevents us from forming a visual idea of the high dimensional features in the dataset. PCA in R resolves this problem by projecting n dimensions to a 2-D environment, enabling sound visualization. These visualizations sometimes reveal a great deal about the data. For instance, the new feature projections may form clusters in the 2-D space which was previously not perceivable in higher dimensions.
Visualization with PCA (n-D to 2-D) Courtesy: nlpca.org
Intuition
Principal Component Analysis in R works with the simple idea of projection of a higher space to a lower space or dimension
The two alternate objectives of Principal Component Analysis are:
1. Variance Maximization
Formulation
2. Distance Minimization
Formulation
Let us demonstrate the above with the help of simple examples. If you have 2 features, and you wish to reduce the features to a 1-D feature set using PCA in R, you must lookout for the direction with maximal spread/variance. This becomes the new direction on which every data point is projected. The direction perpendicular to this direction has the least variance, and is thus, discarded.
Alternately, if one focuses on the perpendicular distance between a data point and the direction of maximum variance, our objective shifts to the minimization of that distance. This is because, lesser the distance, higher is the authenticity of the projection.
On completion of these projections, you would have successfully transformed your 2-D data to a 1-D dataset.
Mathematical Intuition
Principal Component Analysis in R locates the distance of maximal spread (or direction of minimal distance from data points) with the use of Eigen Vectors and Eigen Values. Every Eigen Vector (Vi) corresponds to an Eigen Value (Ei).
If X is a feature matrix (matrix with the feature values),
covariance matrix S = XT. X
If EiVi = SVi ,
Then Ei is an Eigen Value, and Vi becomes the corresponding Vector.
If there are d dimensions, there will be d Eigenvalues with d corresponding Eigen Vectors, such that:
E1>=E2>=E3>=E4>=…>=Ed
Each corresponding to V1, V2, V3, …., Vd
Here the vector corresponding to the largest Eigenvalue is the direction of Maximal spread since rotation occurs such that V1 is aligned with maximal variance in the feature space. Vd here has the least variance in its direction.
A very interesting property of Eigenvectors is the fact that if any two vectors are picked randomly from the set of d vectors, they will turn out to be perpendicular to each other. This happens because they align themselves such that they catch the most opposing directions in terms of variance.
When deciding between two Eigen Vector directions, Eigenvalues come into play. If V1 and V2 are two Eigen Vectors (perpendicular to each other), the values associated with these vectors, E1 and E2, help us identify the “percentage of variance explained” in either direction.
Percentage of variance explained Ei/(Sum(d Eigen Values)) where i is the direction we wish to calculate the percentage of variance explained for.
Implementation
Principal Component Analysis in R can either be applied with manual code using the above mathematical intuition, or it can be done using R’s inbuilt functions.
Even if the mathematical concept failed to leave a lasting impression on your mind, be assured that it is not of great consequence. On the other hand, understanding the basic high-level intuition counts. Without using the mathematical formulas, PCA in R can be easily applied using R’s prcomp() and princomp() functions which can be found here.
In order to demonstrate Principal Component Analysis, we will be using R, one of the most widely used languages in Data Science and Machine Learning. R was initially developed as a tool to aid researchers and scientists dealing with statistical problems in the academic field. With time, as more individuals from the academic spheres started seeping into the corporate and industrial sectors, they brought along R and its phenomenal uses along with them. As R got integrated into the IT sector, its popularity increased manifold and several revisions were made with the release of every new version. Today R has several packages and integrated libraries which enables developers and data scientists to instantly access statistical solutions without having to go into the complicated details of the operations. Principal Component Analysis is one such statistical approach which has been taken care of very well by R and its libraries.
For demonstrating PCA in R, we will be using the Breast Cancer Wisconsin Dataset which can be downloaded from here: Data Link
These code statements help to read data into the variables wdbc.
wdbc.pr <- prcomp(wdbc[c(3:32)], center = TRUE, scale = TRUE) summary(wdbc.pr)
The prcomp() function helps to apply PCA in R on the data variable wdbc. This function of R makes the entire process of implementing PCA as simple as writing just one line of code. The internal operations and functions are taken care of and are even optimized in terms of memory and performance to carry out the operations optimally. The range 3:32 is used to tell the function to apply PCA only on the features or columns which lie in the range of 3 to 32. This excludes the sample ID and diagnosis variables since they are identification columns and are invalid as features with no direct significance with regard to the target variable.
wdbc.pr
now stores the values of the principal components.
Let us now
visualize the different attributes of the resulting Principal Components for
the 30 features:
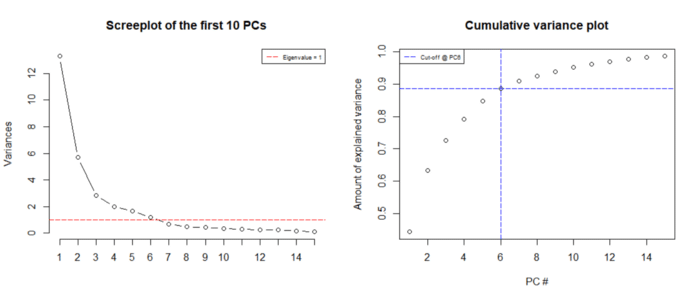
screeplot(wdbc.pr, type = "l", npcs = 15, main = "Screeplot of the first 10 PCs")
This plot
clearly demonstrates that the first 6 components account for 90% of the variance
in the dataset (with Eigen Value > 1). This means that one can easily
exclude 24 features out of 30 features in order to preserve 90% of the data.
Limitations of PCA
Even though Principal Component Analysis in R displays a highly intuitive technique, it hosts certain shocking limitations.
1. Loss of Variance: If the percentage of variance against the chosen axis is around 50-60%, it is evident that 40-50% of the information which contributes to the variance of the dataset is lost during dimensionality reduction. This happens often when the data is spherical or bulging in nature.
2. Loss of Clusters: If there are several clusters present in the original dataset, but most of them lie in the direction perpendicular to the chosen direction. Thus, all the points from different clusters will be projected to the same region on the line of chosen direction, leading to one cluster of data points which are in fact quite different in nature.
3. Loss of Data Patterns: If the dataset forms a nice wavy pattern in direction of maximal spread, PCA takes to project all the points on the line aligned against the direction. Thus, data points which formed a wave function are concentrated on one-dimensional space.
These demonstrate how PCA in R, even though very effective for certain datasets, is a weak instrument for dimensionality reduction or visualization. To resolve these limitations to a certain extent, t-SNE, which is another dimensionality reduction algorithm, is used. Stay tuned to our blogs for a similar and well-guided walkthrough in t-SNE.
Reports suggest that around 2.5 quintillion bytes of data are generated every single day. As the online usage growth increases at a tremendous rate, there is a need for immediate Data Science professionals who can clean the data, obtain insights from it, visualize it, train model and eventually come up with solutions using Big data for the betterment of the world.
By 2020, experts predict that there will be more than 2.7 million data science and analytics jobs openings. Having a glimpse of the entire Data Science pipeline, it is definitely tiresome for a single human to perform and at the same time excel at all the levels. Hence, Data Science has a plethora of career options that require a spectrum set of skill sets.
Let us explore the top 5 data science career options in 2019 (In no particular order).
1. Data Scientist
Data Scientist is one of the ‘high demand’ job roles. The day to day responsibilities involves the examination of big data. As a result of the analysis of the big data, they also actively perform data cleaning and organize the big data. They are well aware of the machine learning algorithms and understand when to use the appropriate algorithm. During the due course of data analysis and the outcome of machine learning models, patterns are identified in order to solve the business statement.
The reason why this role is so crucial in any organisation is that the company tends to take business decisions with the help of the insights discovered by the Data Scientist to have an edge over the company’s competitors. It is to be noted that the Data Scientist role is inclined more towards the technical domain. As the role demands a wide range of skill set, Data Scientists are one among the highest paid jobs.
Core Skills of a Data Scientist
Communication
Business Awareness
Database and querying
Data warehousing solutions
Data visualization
Machine learning algorithms
2. Business Intelligence Developer
BI Developer is a job role inclined more towards the Non-Technical domain but has a fair share of Technical responsibilities as well (if required) as a part of their day to day responsibilities. BI developers are responsible for creating and implementing business policies as a result of the insights obtained from the Technical team.
Apart from being a policymaker involving the usage of dedicated (or custom) Business Intelligence analytics tools, they will also have a fair share of coding in order to explore the dataset, present the insights of the dataset in a non-verbal manner. They help in bridging the gap between the technical team that works with the deepest technical understanding and the clients that want the results in the most non-technical manner. They are expected to generate reports from the insights and make it ‘less technical’ for others in the organisation. It is noted that the BI Developers have a deep understanding of Business when compared to Data Scientist.
Core Skills of a Business Analytics Developer
Business model analysis
Data warehousing
Design of business workflow
Business Intelligence software integration
3. Machine Learning Engineer
Once the data is clean and ready for analysis, the machine learning engineers work on these big data to train a predictive model that predicts the target variable. These models are used to analyze the trends of the data in the future so that the organisation can take the right business decisions. As the dataset involved in a real-life scenario would involve a lot of dimensions, it is difficult for a human eye to interpret insights from it. This is one of the reasons for training machine learning algorithms as it easily deals with such complex dataset. These engineers carry out a number of tests and analyze the outcomes of the model.
The reason for conducting constant tests on the model using various samples is to test the accuracy of the developed model. Apart from the training models, they also perform exploratory data analysis sometimes in order to understand the dataset completely which will, in turn, help them in training better predictive models.
Core Skills of Machine Learning Engineers
Machine Learning Algorithms
Data Modelling and Evaluation
Software Engineering
4. Data Engineer
The pipeline of any data-oriented company begins with the collection of big data from numerous sources. That’s where the data engineers operate in any given project. These engineers integrate data from various sources and optimize them according to the problem statement. The work usually involves writing queries on big data for easy and smooth accessibility. Their day to day responsibility is to provide a streamlined flow of big data from various distributed systems. Data engineering differs from the other data science careers as in, it is concentrated on the system and hardware that aids the company’s data analysis, rather than the analysis of data itself. They provide the organisation with efficient warehousing methods as well.
Core Skills of Data Engineer
Database Knowledge
Data Warehousing
Machine Learning algorithm
5. Business Analyst
Business Analyst is one of the most essential roles in the Data Science field. These analysts are responsible for understanding the data and it’s related trend post the decision making about a particular product. They store a good amount of data about various domains of the organisation. These data are really important because if any product of the organisation fails, these analysts work on these big data to understand the reason behind the failure of the project. This type of analysis is vital for all the organisations as it makes them understand the loopholes in the company. The analysts not only backtrack the loophole and in turn provide solutions for the same making sure the organisation takes the right decision in the future. At times, the business analyst act as a bridge between the technical team and the rest of the working community.
Core skills of Business Analyst
Business awareness
Communication
Process Modelling
Conclusion
The data science career options mentioned above are in no particular order. In my opinion, every career option in Data Science field works complimentary with one another. In any data-driven organization, regardless of the salary, every career role is important at the respective stages in a project.
Exploratory Data Analysis or EDA is that stage of Data Handling where the Data is intensely studied and the myriad limits are explored. EDA literally helps to unfold the mystery behind such data which might not make sense at first glance. However, with detailed analysis, we can use the same data to provide miraculous results which can help boost large scale business decisions with excellent accuracy. This not only helps business conglomerations to evade likely pitfalls in the future but also helps them to leverage from the best possible schemes that might emerge in the near future.
EDA employs three primary statistical techniques to go about this exploration:
Univariate Analysis
Bivariate Analysis
Multivariate Analysis
Univariate, as the name suggests, means ‘one variable’ and studies one variable at a time to help us formulate conclusions such as follows:
Outlier detection
Concentrated points
Pattern recognition
Required transformations
In order to understand these points, we will take up the iris dataset which is furnished by fundamental python libraries like scikit-learn.
The iris dataset is a very simple dataset and consists of just 4 specifications of iris flowers: sepal length and width, petal length and width (all in centimeters). The objective of this dataset is to identify the type of iris plant a flower belongs to. There are three such categories: Iris Setosa, Iris Versicolour, Iris Virginica).
So let’s dig right in then!
1. Description Based Analysis
The purpose of this stage is to get an initial idea about each variable independently. This helps to identify the irregularities and probable patterns in the variables. Python’s inbuilt panda’s library helps to execute this task with extreme ease by literally using just one line of code.
Code:
data = datasets.load_iris()
The iris dataset is in dictionary format and thus, needs to be changed to data frame format so that the panda’s library can be leveraged.
We will store the independent variables in ‘X’. ‘data’ will be extracted and converted as follows:
X = data[‘data’] #extract
X = pd.DataFrame(X) #convert
On conversion to the required format, we just need to run the following code to get the desired information:
X.describe() #One simple line to get the entire description for every column
Output:
Count refers to the number of records under each column.
Mean gives the average of all the samples combined. Also, it is important to note that the mean gets highly affected by outliers and skewed data and we will soon be seeing how to detect skewed data just with the help of the above information.
Std or Standard Deviation is the measure of the “spread” of data in simple terms. With the help of std we can understand if a variable has values populated closely around the mean or if they are distributed over a wide range.
Min and Max give the minimum and maximum values of the columns across all records/samples.
25%, 50%, and 75% constitute the most interesting bit of the description. The percentiles refer to the respective percentage of records which behave a certain way. It can be interpreted in the following way:
25% of the flowers have sepal length equal to or less than 5.1 cm.
50% of the flowers have a sepal width equal to or less than 3.0 cm and so on.
50% is also interpreted as the median of the variable. It represents the data present centrally in the variable. For example, if a variable has values in the range 1 and 100 and its median is 80, it would mean that a lot of data points are inclined towards a higher value. In simpler terms, 50% or half of the data points have values greater than or equal to 80.
Now that the performance of mean and median is demonstrated, from the behavior of these numbers, one can conclude if the data is skewed. If the difference is high, it suggests that the distribution is skewed and if it is almost negligible, it is indicative of a normal distribution.
These options work well with continuous variables like the ones mentioned above. However, for categorical variables which have distinct values, such a description seldom makes any sense. For instance, the mean of a categorical variable would barely be of any value.
For such cases, we use yet another pandas operation called ‘value_counts()’. The usability of this function can be demonstrated through our target variable ‘y’. y was extracted in the following manner:
y = data[‘target’] #extract
This is done since the iris dataset is in dictionary format and stores the target variable in a list corresponding to the key named as ‘target’. After the extraction is completed, convert the data into a pandas Series. This must be done as the function value_counts() is only applicable to pandas Series.
y = pd.Series(y) #convert
y.value_counts()
On applying the function, we get the following result:
Output:
2 50
1 50
0 50
dtype: int64
This means that the categories, ‘0’, ‘1’ and ‘2’ have an equal number of counts which is 50. The equal representation means that there will be minimum bias during training. For example, if data tends to have more records representing one particular category ‘A’, the training model used will tend to learn that the category ‘A’ is the most recurrent and will have the tendency to predict a record as record ‘A’. When unequal representations are found, any one of the following must be followed:
Gather more data
Generate samples
Eliminate samples
Now let us move on to visual techniques to analyze the same data, but reveal further hidden patterns!
2. Visualization Based Analysis
Even though a descriptive analysis is highly informative, it does not quite furnish details with regard to the pattern that might arise in the variable. With the difference between the mean and median we may be able to figure out the presence of skewed data, but will not be able to pinpoint the exact reason owing to this skewness. This is where visualizations come into the picture and aid us to formulate solutions for the myriad patterns that might arise in the variables independently.
Lets start with observing the frequency distribution of sepal width in our dataset.
Std: 0.435 Mean: 3.057 Median (50%): 3.000
The red dashed line represents the median and the black dashed line represents the mean. As you must have observed, the standard deviation in this variable is the least. Also, the difference between the mean and the median is not significant. This means that the data points are concentrated towards the median, and the distribution is not skewed. In other words, it is a nearly Gaussian (or normal) distribution. This is how a Gaussian distribution looks like:
Normal Distribution generated from random data
The data of the above distribution is generated through the random. The normal function of the numpy library (one of the python libraries to handle arrays and lists).
It must always be one’s aim to achieve a Gaussian distribution before applying modeling algorithms. This is because, as has been studied, the most recurrent distribution in real life scenarios is the Gaussian curve. This has led to the designing of algorithms over the years in such a way that they mostly cater to this distribution and assume beforehand that the data will follow a Gaussian trend. The solution to handle this is to transform the distribution accordingly.
Let us visualize the other variables and understand what the distributions mean.
Sepal Length:
Std: 0.828 Mean: 5.843 Median: 5.80
As is visible, the distribution of Sepal Length is over a wide range of values (4.3cm to 7.9cm) and thus, the standard deviation for sepal length is higher than that of sepal width. Also, the mean and median have almost an insignificant difference between them. This clarifies that the data is not skewed. However, here visualization comes to great use because we can clearly see that distribution is not perfectly Gaussian since the tails of the distribution have ample data. In Gaussian distribution, approximately 5% of the data is present in the tailing regions. From this visualization, however, we can be sure that the data is not skewed.
Petal Length:
Std: 1.765 Mean: 3.758 Median: 4.350
This is a very interesting graph since we found an unexpected gap in the distribution. This can either mean that the data is missing or the feature does not apply to that missing value. In other words, the petal lengths of iris plants never have the length in the range 2 to 3! The mean is thus, justifiably inclined towards the left and the median shows the centralized value of the variable which is towards the right since most of the data points are concentrated in a Gaussian curve towards the right. If you move on to the next visual and observe the pattern of petal width, you will come across an even more interesting revelation.
Petal Width:
std: 0.762 mean: 1.122 median: 1.3
In the case of Petal Width, most of the values in the same region as in the petal length diagram, relative to the frequency distribution, are missing. Here the values in the range 0.5 cm to 1.0 cm are almost absent (but not completely absent). A repetitive low value simultaneously in the same area corresponding to two different frequency distributions is indicative of the fact that the data is missing and also confirmatory of the fact that petals of the size of the missing values are present in nature, but went unrecorded.
This conclusion can be followed with further data gathering or one can simply continue to work with the limited data present since it is not always possible to gather data representing every element of a given subject.
Conclusively, using histograms we came to know about the following:
Data distribution/pattern
Skewed distribution or not
Missing data
Now with the help of another univariate analysis tool, we can find out if our data is inlaid with anomalies or outliers. Outliers are data points which do not follow the usual pattern and have unpredictable behavior. Let us find out how to find outliers with the help of simple visualizations!
We will use a plot called the Box plot to identify the features/columns which are inlaid with outliers.
Box Plot for Iris Dataset
The box plot is a visual representation of five important aspects of a variable, namely:
Minimum
Lower Quartile
Median
Upper Quartile
Maximum
As can be seen from the above graph, each variable is divided into four parts using three horizontal lines. Each section contains approximately 25% of the data. The area enclosed by the box is 50% of the data which is located centrally and the horizontal green line represents the median. One can identify an outlier if the point is spotted beyond the max and min lines.
From the plot, we can say that sepal_width has outlying points. These points can be handled in two ways:
Discard the outliers
Study the outliers separately
Sometimes outliers are imperative bits of information, especially in cases where anomaly detection is a major concern. For instance, during the detection of fraudulent credit card behavior, detection of outliers is all that matters.
Conclusion
Overall, EDA is a very important step and requires lots of creativity and domain knowledge to dig up maximum patterns from available data. Keep following this space to know more about bi-variate and multivariate analysis techniques. It only gets interesting from here on!
There are a huge number of ML algorithms out there. Trying to classify them leads to the distinction being made in types of the training procedure, applications, the latest advances, and some of the standard algorithms used by ML scientists in their daily work. There is a lot to cover, and we shall proceed as given in the following listing:
Statistical Algorithms
Classification
Regression
Clustering
Dimensionality Reduction
Ensemble Algorithms
Deep Learning
Reinforcement Learning
AutoML (Bonus)
1. Statistical Algorithms
Statistics is necessary for every machine learning expert. Hypothesis testing and confidence intervals are some of the many statistical concepts to know if you are a data scientist. Here, we consider here the phenomenon of overfitting. Basically, overfitting occurs when an ML model learns so many features of the training data set that the generalization capacity of the model on the test set takes a toss. The tradeoff between performance and overfitting is well illustrated by the following illustration:
Overfitting – from Wikipedia
Here, the black curve represents the performance of a classifier that has appropriately classified the dataset into two categories. Obviously, training the classifier was stopped at the right time in this instance. The green curve indicates what happens when we allow the training of the classifier to ‘overlearn the features’ in the training set. What happens is that we get an accuracy of 100%, but we lose out on performance on the test set because the test set will have a feature boundary that is usually similar but definitely not the same as the training set. This will result in a high error level when the classifier for the green curve is presented with new data. How can we prevent this?
Cross-Validation
Cross-Validation is the killer technique used to avoid overfitting. How does it work? A visual representation of the k-fold cross-validation process is given below:
From Quora
The entire dataset is split into equal subsets and the model is trained on all possible combinations of training and testing subsets that are possible as shown in the image above. Finally, the average of all the models is combined. The advantage of this is that this method eliminates sampling error, prevents overfitting, and accounts for bias. There are further variations of cross-validation like non-exhaustive cross-validation and nested k-fold cross validation (shown above). For more on cross-validation, visit the following link.
There are many more statistical algorithms that a data scientist has to know. Some examples include the chi-squared test, the Student’s t-test, how to calculate confidence intervals, how to interpret p-values, advanced probability theory, and many more. For more, please visit the excellent article given below:
Classification refers to the process of categorizing data input as a member of a target class. An example could be that we can classify customers into low-income, medium-income, and high-income depending upon their spending activity over a financial year. This knowledge can help us tailor the ads shown to them accurately when they come online and maximises the chance of a conversion or a sale. There are various types of classification like binary classification, multi-class classification, and various other variants. It is perhaps the most well known and most common of all data science algorithm categories. The algorithms that can be used for classification include:
Logistic Regression
Support Vector Machines
Linear Discriminant Analysis
K-Nearest Neighbours
Decision Trees
Random Forests
and many more. A short illustration of a binary classification visualization is given below:
From openclassroom.stanford.edu
For more information on classification algorithms, refer to the following excellent links:
Regression is similar to classification, and many algorithms used are similar (e.g. random forests). The difference is that while classification categorizes a data point, regression predicts a continuous real-number value. So classification works with classes while regression works with real numbers. And yes – many algorithms can be used for both classification and regression. Hence the presence of logistic regression in both lists. Some of the common algorithms used for regression are
Linear Regression
Support Vector Regression
Logistic Regression
Ridge Regression
Partial Least-Squares Regression
Non-Linear Regression
For more on regression, I suggest that you visit the following link for an excellent article:
Both articles have a remarkably clear discussion of the statistical theory that you need to know to understand regression and apply it to non-linear problems. They also have source code in Python and R that you can use.
4. Clustering
Clustering is an unsupervised learning algorithm category that divides the data set into groups depending upon common characteristics or common properties. A good example would be grouping the data set instances into categories automatically, the process being used would be any of several algorithms that we shall soon list. For this reason, clustering is sometimes known as automatic classification. It is also a critical part of exploratory data analysis (EDA). Some of the algorithms commonly used for clustering are:
Hierarchical Clustering – Agglomerative
Hierarchical Clustering – Divisive
K-Means Clustering
K-Nearest Neighbours Clustering
EM (Expectation Maximization) Clustering
Principal Components Analysis Clustering (PCA)
An example of a common clustering problem visualization is given below:
From Wikipedia
The above visualization clearly contains three clusters.
Another excellent article on clustering refer the link
Dimensionality Reduction is an extremely important tool that should be completely clear and lucid for any serious data scientist. Dimensionality Reduction is also referred to as feature selection or feature extraction. This means that the principal variables of the data set that contains the highest covariance with the output data are extracted and the features/variables that are not important are ignored. It is an essential part of EDA (Exploratory Data Analysis) and is nearly always used in every moderately or highly difficult problem. The advantages of dimensionality reduction are (from Wikipedia):
It reduces the time and storage space required.
Removal of multi-collinearity improves the interpretation of the parameters of the machine learning model.
It becomes easier to visualize the data when reduced to very low dimensions such as 2D or 3D.
It avoids the curse of dimensionality.
The most commonly used algorithm for dimensionality reduction is Principal Components Analysis or PCA. While this is a linear model, it can be converted to a non-linear model through a kernel trick similar to that used in a Support Vector Machine, in which case the technique is known as Kernel PCA. Thus, the algorithms commonly used are:
Ensembling means combining multiple ML learners together into one pipeline so that the combination of all the weak learners makes an ML application with higher accuracy than each learner taken separately. Intuitively, this makes sense, since the disadvantages of using one model would be offset by combining it with another model that does not suffer from this disadvantage. There are various algorithms used in ensembling machine learning models. The three common techniques usually employed in practice are:
Simple/Weighted Average/Voting: Simplest one, just takes the vote of models in Classification and average in Regression.
Bagging: We train models (same algorithm) in parallel for random sub-samples of data-set with replacement. Eventually, take an average/vote of obtained results.
Boosting: In this models are trained sequentially, where (n)th model uses the output of (n-1)th model and works on the limitation of the previous model, the process stops when result stops improving.
Stacking: We combine two or more than two models using another machine learning algorithm.
(from Amardeep Chauhan on Medium.com)
In all four cases, the combination of the different models ends up having the better performance that one single learner. One particular ensembling technique that has done extremely well on data science competitions on Kaggle is the GBRT model or the Gradient Boosted Regression Tree model.
We include the source code from the scikit-learn module for Gradient Boosted Regression Trees since this is one of the most popular ML models which can be used in competitions like Kaggle, HackerRank, and TopCoder.
GradientBoostingClassifier supports both binary and multi-class classification. The following example shows how to fit a gradient boosting classifier with 100 decision stumps as weak learners:
GradientBoostingRegressor supports a number of different loss functions for regression which can be specified via the argument loss; the default loss function for regression is least squares ('ls').
import numpy as np
from sklearn.metrics import mean_squared_error
from sklearn.datasets import make_friedman1
from sklearn.ensemble import GradientBoostingRegressor
X, y = make_friedman1(n_samples=1200, random_state=0, noise=1.0)
X_train, X_test = X[:200], X[200:]
y_train, y_test = y[:200], y[200:]
est = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1,
max_depth=1, random_state=0, loss='ls').fit(X_train, y_train)
mean_squared_error(y_test, est.predict(X_test))
You can also refer to the following article which discusses Random Forests, which is a (rather basic) ensembling method.
In the last decade, there has been a renaissance of sorts within the Machine Learning community worldwide. Since 2002, neural networks research had struck a dead end as the networks of layers would get stuck in local minima in the non-linear hyperspace of the energy landscape of a three layer network. Many thought that neural networks had outlived their usefulness. However, starting with Geoffrey Hinton in 2006, researchers found that adding multiple layers of neurons to a neural network created an energy landscape of such high dimensionality that local minima were statistically shown to be extremely unlikely to occur in practice. Today, in 2019, more than a decade of innovation later, this method of adding addition hidden layers of neurons to a neural network is the classical practice of the field known as deep learning.
Deep Learning has truly taken the computing world by storm and has been applied to nearly every field of computation, with great success. Now with advances in Computer Vision, Image Processing, Reinforcement Learning, and Evolutionary Computation, we have marvellous feats of technology like self-driving cars and self-learning expert systems that perform enormously complex tasks like playing the game of Go (not to be confused with the Go programming language). The main reason these feats are possible is the success of deep learning and reinforcement learning (more on the latter given in the next section below). Some of the important algorithms and applications that data scientists have to be aware of in deep learning are:
Long Short term Memories (LSTMs) for Natural Language Processing
Recurrent Neural Networks (RNNs) for Speech Recognition
Convolutional Neural Networks (CNNs) for Image Processing
Deep Neural Networks (DNNs) for Image Recognition and Classification
Hybrid Architectures for Recommender Systems
Autoencoders (ANNs) for Bioinformatics, Wearables, and Healthcare
Deep Learning Networks typically have millions of neurons and hundreds of millions of connections between neurons. Training such networks is such a computationally intensive task that now companies are turning to the 1) Cloud Computing Systems and 2) Graphical Processing Unit (GPU) Parallel High-Performance Processing Systems for their computational needs. It is now common to find hundreds of GPUs operating in parallel to train ridiculously high dimensional neural networks for amazing applications like dreaming during sleep and computer artistry and artistic creativity pleasing to our aesthetic senses.
Artistic Image Created By A Deep Learning Network. From blog.kadenze.com.
For more on Deep Learning, please visit the following links:
In the recent past and the last three years in particular, reinforcement learning has become remarkably famous for a number of achievements in cognition that were earlier thought to be limited to humans. Basically put, reinforcement learning deals with the ability of a computer to teach itself. We have the idea of a reward vs. penalty approach. The computer is given a scenario and ‘rewarded’ with points for correct behaviour and ‘penalties’ are imposed for wrong behaviour. The computer is provided with a problem formulated as a Markov Decision Process, or MDP. Some basic types of Reinforcement Learning algorithms to be aware of are (some extracts from Wikipedia):
1.Q-Learning
Q-Learning is a model-free reinforcement learning algorithm. The goal of Q-learning is to learn a policy, which tells an agent what action to take under what circumstances. It does not require a model (hence the connotation “model-free”) of the environment, and it can handle problems with stochastic transitions and rewards, without requiring adaptations. For any finite Markov decision process (FMDP), Q-learning finds a policy that is optimal in the sense that it maximizes the expected value of the total reward over any and all successive steps, starting from the current state. Q-learning can identify an optimal action-selection policy for any given FMDP, given infinite exploration time and a partly-random policy. “Q” names the function that returns the reward used to provide the reinforcement and can be said to stand for the “quality” of an action taken in a given state.
2.SARSA
State–action–reward–state–action (SARSA) is an algorithm for learning a Markov decision process policy. This name simply reflects the fact that the main function for updating the Q-value depends on the current state of the agent “S1“, the action the agent chooses “A1“, the reward “R” the agent gets for choosing this action, the state “S2” that the agent enters after taking that action, and finally the next action “A2” the agent choose in its new state. The acronym for the quintuple (st, at, rt, st+1, at+1) is SARSA.
3.Deep Reinforcement Learning
This approach extends reinforcement learning by using a deep neural network and without explicitly designing the state space. The work on learning ATARI games by Google DeepMind increased attention to deep reinforcement learning or end-to-end reinforcement learning. Remarkably, the computer agent DeepMind has achieved levels of skill higher than humans at playing computer games. Even a complex game like DOTA 2 was won by a deep reinforcement learning network based upon DeepMind and OpenAI Gym environments that beat human players 3-2 in a tournament of best of five matches.
For more information, go through the following links:
If reinforcement learning was cutting edge data science, AutoML is bleeding edge data science. AutoML (Automated Machine Learning) is a remarkable project that is open source and available on GitHub at the following link that, remarkably, uses an algorithm and a data analysis approach to construct an end-to-end data science project that does data-preprocessing, algorithm selection,hyperparameter tuning, cross-validation and algorithm optimization to completely automate the ML process into the hands of a computer. Amazingly, what this means is that now computers can handle the ML expertise that was earlier in the hands of a few limited ML practitioners and AI experts.
AutoML has found its way into Google TensorFlow through AutoKeras, Microsoft CNTK, and Google Cloud Platform, Microsoft Azure, and Amazon Web Services (AWS). Currently it is a premiere paid model for even a moderately sized dataset and is free only for tiny datasets. However, one entire process might take one to two or more days to execute completely. But at least, now the computer AI industry has come full circle. We now have computers so complex that they are taking the machine learning process out of the hands of the humans and creating models that are significantly more accurate and faster than the ones created by human beings!
The basic algorithm used by AutoML is Network Architecture Search and its variants, given below:
Network Architecture Search (NAS)
PNAS (Progressive NAS)
ENAS (Efficient NAS)
The functioning of AutoML is given by the following diagram:
If you’ve stayed with me till now, congratulations; you have learnt a lot of information and cutting edge technology that you must read up on, much, much more. You could start with the links in this article, and of course, Google is your best friend as a Machine Learning Practitioner. Enjoy machine learning!
All the best dataset, Artificial Intelligence, Machine Learning, and Business Intelligence tools are useless without effective visualization capabilities. In the end, data science is all about presentation, Whether you are a chief data scientist at Google or an all-in-one ‘many-hats’ data scientist at a start-up, you still have to show the results of your algorithm to a management executive for approval. We have all heard the adage, “a picture is worth a thousand words”. I would rephrase that for data science as “An effective infographic is worth an infinite amount of data”. Because even if you present the most amazing algorithms and statistics in the universe to your management, they will be unable to comprehend it. But present even a simple infographic – and everyone in the boardroom, from the CEO to your personnel manager, will be able to understand what your findings mean for your business enterprise.
Tools for Visualization
Because of the fundamental truth stated above, there are a ton of data visualization tools out there for the needs of every data scientist on the planet. There is a wide variety available. From premium and power-user based, to products from giants like Microsoft and Google, to free offerings for developers like Plot.ly across multiple languages and bokeh for Python developers, to DataWrapper for non-technical users. So I have picked five tools that vary widely but are all very effective and worth learning in depth. So let’s get started!
Tableau Sample Email Marketing ReportTableau is the market leader for visualization as far as data science is concerned. The statistics speak for themselves. Over 32,000 companies use Tableau around the world and this tool is by far the most popular choice among top companies like Facebook and Amazon. What is more, once you learn Tableau, you will know visualization well enough to handle every other tool in the market. This tool is the most popular, the most powerful, and yet surprisingly intuitive to use. If you wanted to learn one single tool for data science, this is It.
Qlikview is another solution like Tableau that requires payment for a commercial user, yet it is so powerful that I couldn’t help but include it in my article. This tool is situated more for the power-user and the well-experienced data scientists. While not as intuitive as Tableau, this tool boasts of powerful features that can be used by large-scale users. This is a very powerful choice for many companies all over the world.
Unlike the first two tools, Microsoft Power BI (Business Intelligence) is completely free to use and download. It integrates beautifully with Microsoft tools. If you’re on Microsoft Azure as a cloud computing solution, you will enjoy this tool’s seamless integration with Microsoft products. Contrary to popular business ethos at Microsoft, this tool is both free to download (full-featured) and free to use, even the Desktop version. If you use Microsoft tools, then this could be a solution that fits you well. (Although Tableau is the tool used the most by software companies).
This tool is strictly cloud-based and its highest USP is that it tightly integrates with the Google Internet Website Ecosystem. In fact, it is better that the solution be cloud-based and not on your desktop since a copy on your desktop would have to be continually resynchronized, whereas a cloud solution manages all requirements as required with the latest Internet datasets, refreshed every time you load the page. Nearly every single tool you need is at your fingertips, and this is one way to learn the Google-based way to manage your website or company. And did I mention – like Microsoft Power BI, it is completely free of cost! But again, Tableau is still the preferred solution for mainstream software companies.
This is by far the most user-friendly visualization tool for data science available on the Internet today. And while I was skeptical, this tool can be used by completely non-technical users. And the version I used was free up to to a massive 10,000 chart views. So if you want to create a visualization and don’t have technical skills in coding or Python, this may be your best way to get started. In case you’re feeling skeptical (as I was), visit the website above and view the instructions video (100 seconds – less than 2 minutes). If you are a beginner to data visualization, this is where to go first.
This is an article on visualization and communicating concepts and analysis through graphics, so it would not be complete without this free gallery of samples at www.informationisbeautiful.net. What do we plan to communicate but information? Information is processed data. Data scientists deal with data but produce as output information. This website has opened my eyes as to how data can be presented effectively. While this is not something you would use for an industrial report, do visit the site for inspiration for ways to make your data visualization more good-looking. If you have business transformational data, it requires the best presentation available. This is a post for five data visualization tools, but consider this sixth one as a bonus for inspiration and all the times you wished your dashboard or charts could be more effective graphically.
Conclusion
While there is a ton of information out there, choose tools that cater to your domain. If you are a large scale enterprise, Tableau could be your best option. If you are a student or want a high-quality free solution, go for DataWrapper. QlikView can be used by companies who want to save on their budget and have plenty of experienced professionals (although this is also a use-case for Tableau). For convenient tools, you can’t go wrong with Microsoft Power BI if your company uses Microsoft ecosystem and Google Data Studio is you are integrated into the Google ecosystem instead. Finally, if you are a student of data visualization or just want to improve your data presentation, please visit informationisbeautiful.net. Trust me, it will be an eye-opener.
Finally, Tableau is what you need to learn to be a true data science professional, especially in FAMGA (Facebook, Apple, Microsoft, Google, and Amazon).
Also, remember to enjoy your work. This adds a fun element to your current job and ensures against burnout and other such problems. This is, in the end, artistry. Even if you are into coding. All the best!
For more on Data Visualization, I strongly recommend the articles below: