Launched back in 2006, AWS has succeeded in becoming the leading provider of on-demand cloud computing services. The cloud computing services provider secures a staggering 32% of the cloud computing market share up until the last quarter of 2018.
Every aspiring developer looking to make it big in the cloud computing ecosphere must have a stronghold on AWS. If you’re eyeing for the role of an AWS Developer, then these most important 20 AWS interview questions will help you take a step further towards your desired job avenue. So let us kickstart your AWS learning with Dimensionless!
AWS Interview Questions with Answers
1. What is AWS?
AWS attains as Amazon Web Service; this is a gathering of remote computing settings also identified as cloud computing policies. This unique realm of cloud computing is also recognized as IaaS or Infrastructure as a Service.
2. What are the Key Components of AWS?
The fundamental elements of AWS are
Route 53: A DNS web service
*Easy E-mail Service: It permits addressing e-mail utilizing RESTFUL API request or through normal SMTP
*Identity and Access Management: It gives heightened protection and identity control for your AWS account
*Simple Storage Device or (S3): It is warehouse equipment and the well-known widely utilized AWS service
*Elastic Compute Cloud (EC2): It affords on-demand computing sources for hosting purposes. It is extremely valuable in trouble of variable workloads
*Elastic Block Store (EBS): It presents persistent storage masses that connect to EC2 to enable you to endure data beyond the lifespan of a particular EC2
*CloudWatch: To observe AWS sources, It permits managers to inspect and obtain key Additionally, one can produce a notification alert in the state of crisis.
3. What is S3?
S3 holds for Simple Storage Service. You can utilize S3 interface to save and recover the unspecified volume of data, at any time and from everywhere on the web. For S3, the payment type is “pay as you go”.
4. What is the Importance of Buffer in Amazon Web Services?
An Elastic Load Balancer ensures that the incoming traffic is distributed optimally across various AWS instances. A buffer will synchronize different components and makes the arrangement additional elastic to a burst of load or traffic. The components are prone to work in an unstable way of receiving and processing the requests. The buffer creates the equilibrium linking various apparatus and crafts them effort at the identical rate to supply more rapid services.
5. What Does an AMI Include?
An AMI comprises the following elements:
A template to the source quantity concerning the instance
Launch authorities determine which AWS accounts can avail the AMI to drive instances
A base design mapping that defines the amounts to join to the instance while it is originated.
6. How Can You Send the Request to Amazon S3?
Amazon S3 is a REST service, you can transmit the appeal by applying the REST API or the AWS SDK wrapper archives that envelop the underlying Amazon S3 REST API.
7. How many Buckets can you Create in AWS by Default?
In each of your AWS accounts, by default, You can produce up to 100 buckets.
8. List the Component Required to Build Amazon VPC?
Subnet, Internet Gateway, NAT Gateway, HW VPN Connection, Virtual Private Gateway, Customer Gateway, Router, Peering Connection, VPC Endpoint for S3, Egress-only Internet Gateway.
9. What is the Way to Secure Data for Carrying in the Cloud?
One thing must be ensured that no one should seize the information in the cloud while data is moving from point one to another and also there should not be any leakage with the security key from several storerooms in the cloud. Segregation of information from additional companies’ information and then encrypting it by means of approved methods is one of the options.
10. Name the Several Layers of Cloud Computing?
Here is the list of layers of the cloud computing
PaaS — Platform as a Service
IaaS — Infrastructure as a Service
SaaS — Software as a Service
11. Explain- Can You Vertically Scale an Amazon Instance? How?
Surely, you can vertically estimate on Amazon instance.
Twist up a fresh massive instance than the one you are currently governing
Delay that instance and separate the source webs mass of server and dispatch
Next, quit your existing instance and separate its source quantity
Note the different machine ID and connect that source mass to your fresh server
12. What are the Components Involved in Amazon Web Services?
There are 4 components involved and areas below. Amazon S3: with this, one can retrieve the key information which are occupied in creating cloud structural design and amount of produced information also can be stored in this component that is the consequence of the key specified. Amazon EC2 instance: helpful to run a large distributed system on the Hadoop cluster. Automatic parallelization and job scheduling can be achieved by this component.
Amazon SQS: this component acts as a mediator between different controllers. Also worn for cushioning requirements those are obtained by the manager of Amazon.
Amazon SimpleDB: helps in storing the transitional position log and the errands executed by the consumers.
13. What is Lambda@edge in Aws?
In AWS, we can use Lambda@Edge utility to solve the problem of low network latency for end users.
In Lambda@Edge there is no need to provision or manage servers. We can just upload our Node.js code to AWS Lambda and create functions that will be triggered on CloudFront requests.
When a request for content is received by CloudFront edge location, the Lambda code is ready to execute.
This is a very good option for scaling up the operations in CloudFront without managing servers.
14. Distinguish Between Scalability and Flexibility?
The aptitude of any scheme to enhance the tasks on hand on its present hardware resources to grip inconsistency in command is known as scalability. The capability of a scheme to augment the tasks on hand on its present and supplementary hardware property is recognized as flexibility, hence enabling the industry to convene command devoid of putting in the infrastructure at all. AWS has several configuration management solutions for AWS scalability, flexibility, availability and management.
15. Name the Various Layers of the Cloud Architecture?
There are 5 layers and are listed below
CC- Cluster Controller
SC- Storage Controller
CLC- Cloud Controller
Walrus
NC- Node Controller
16. What is the Difference Between Azure and AWS?
AWS and Azure are subsets in terms of cloud computing. Both are used to build and host applications. Azure helped many companies, such as the platform, such as PaaS. … Storage: – AWS has temporary storage that is assigned when an instance is started and destroyed when the instance is terminated.
17. Explain- What is T2 Instances?
T2 instances are outlined to present average baseline execution and the ability to explode to powerful execution as needed by the workload.
18. In VPC with Private and Public Subnets, Database Servers should ideally be launched into which Subnet?
Among private and public subnets in VPC, database servers should ideally originate toward separate subnets.
19. What is AWS SageMaker?
Amazon SageMaker is a fully managed machine learning service. With Amazon SageMaker, data scientists and developers can quickly and easily build and train machine learning models, and then directly deploy them into a production-ready hosted environment. It provides an integrated Jupyter authoring notebook instance for easy access to your data sources for exploration and analysis, so you don’t have to manage servers. It also provides common machine learning algorithms that are optimized to run efficiently against extremely large data in a distributed environment.
20. While Connecting to your Instance What are the Possible Connection Issues one Might Face?
The feasible connection failures one might battle while correlating instances are
Consolidation timed out
User key not acknowledged by the server
Host key not detected, license denied
The unguarded private key file
Server rejected our key or No sustained authentication program available
Error handling Mind Term on Safari Browser
Error utilizing Mac OS X RDP Client
21. Explain Elastic Block Storage? What Type of Performance can you Expect? How do you Back itUp? How do you Improve Performance?
That indicates it is RAID warehouse to begin with, so it’s irrelevant and faults tolerant. If disks expire in the RAID you don’t miss data. Excellent! It is more virtualized, therefore you can provision and designate warehouse, and connect it to your server with multiple API appeals. No calling the storage specialist and asking him or her to operate specific requests from the hardware vendor.
Execution of EBS can manifest variability. Such signifies that can run above the SLA enforcement level, suddenly descend under it. The SLA gives you among a medium disk I/O speed you can foresee. That can prevent any groups particularly performance specialists who suspect stable and compatible disk throughput on a server. Common physically entertained servers perform that direction. Pragmatic AWS cases do not.
Backup EBS masses by utilizing the snap convenience through API proposal or by a GUI interface same elasticfox.
Progress execution by practising Linux software invasion and striping over four extents.
22. Which Automation Gears can Help with Spinup Services?
The API tools can be used for spinup services and also for the written scripts. Those scripts could be coded in Perl, bash or other languages of your preference. There is one more option that is patterned administration and stipulating tools such as a dummy or improved descendant. A tool called Scalr can also be used and finally, we can go with a controlled explanation like a RightScale.
23. What is an Ami? How Do I Build One?
AMI holds for Amazon Machine Image. It is efficiently a snap of the source filesystem. Products appliance servers have a bio that shows the master drive report of the initial slice on a disk. A disk form though can lie anyplace physically on a disc, so Linux can boot from an absolute position on the EBS warehouse interface.
Create a unique AMI at beginning rotating up and instance from a granted AMI. Later uniting combinations and components as needed. Comprise wary of setting delicate data over an AMI (learn salesforce online). For instance, your way credentials should be joined to an instance later spinup. Among a database, mount an external volume that carries your MySQL data next spinup actually enough.
24. What are the Main Features of Amazon Cloud Front?
Some of the main features of Amazon CloudFront are as follows: Device Detection Protocol Detection Geo Targeting Cache Behavior Cross-Origin Resource Sharing Multiple Origin Servers HTTP Cookies Query String Parameters Custom SSL.
25. What is the Relation Between an Instance and Ami?
AMI can be elaborated as Amazon Machine Image, basically, a template consisting software configuration part. For example an OS, applications, application server. If you start an instance, a duplicate of the AMI in a row as an unspoken attendant in the cloud.
26. What is Amazon Ec2 Service?
Amazon Elastic Compute Cloud (Amazon EC2) is a web service that provides resizable (scalable) computing capacity in the cloud. You can use Amazon EC2 to launch as many virtual servers you need. In Amazon EC2 you can configure security and networking as well as manage storage. Amazon EC2 service also helps in obtaining and configuring capacity using minimal friction.
27. What are the Features of the Amazon Ec2 Service?
As the Amazon EC2 service is a cloud service so it has all the cloud features. Amazon EC2 provides the following features:
The virtual computing environment (known as instances)
re-configured templates for your instances (known as Amazon Machine Images — AMIs)
Amazon Machine Images (AMIs) is a complete package that you need for your server (including the operating system and additional software)
Amazon EC2 provides various configurations of CPU, memory, storage and networking capacity for your instances (known as instance type)
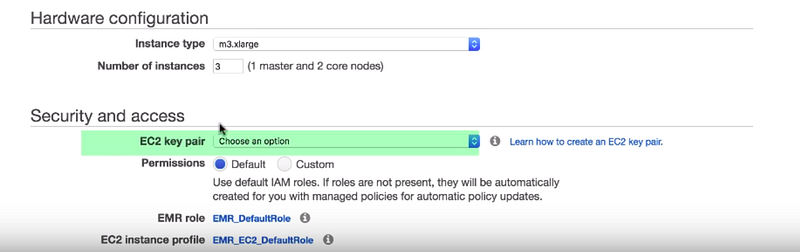
Secure login information for your instances using key pairs (AWS stores the public key and you can store the private key in a secure place)
Storage volumes of temporary data are deleted when you stop or terminate your instance (known as instance store volumes)
A firewall that enables you to specify the protocols, ports, and source IP ranges that can reach your instances using security groups
Static IP addresses for dynamic cloud computing (known as Elastic IP address)
Amazon EC2 provides metadata (known as tags)
Amazon EC2 provides virtual networks that are logically isolated from the rest of the AWS cloud, and that you can optionally connect to your own network (known as virtual private clouds — VPCs)
28. What is the AWS Kinesis
Amazon Kinesis Data Streams can collect and process large streams of data records in real time. You can create data-processing applications, known as Kinesis Data Streams applications. A typical Kinesis Data Streams application reads data from a data stream as data records. These applications can use the Kinesis Client Library, and they can run on Amazon EC2 instances. You can send the processed records to dashboards, use them to generate alerts, dynamically change pricing and advertising strategies, or send data to a variety of other AWS services
29. Distinguish Between Scalability and Flexibility?
The aptitude of any scheme to enhance the tasks on hand on its present hardware resources to grip inconsistency in command is known as scalability. The capability of a scheme to augment the tasks on hand on its present and supplementary hardware property is recognized as flexibility, hence enabling the industry to convene command devoid of putting in the infrastructure at all. AWS has several configuration management solutions for AWS scalability, flexibility, availability and management.
30. What are the Different Types of Events Triggered By Amazon Cloud Front?
Different types of events triggered by Amazon CloudFront are as follows:
Viewer Request: When an end user or a client program makes an HTTP/HTTPS request to CloudFront, this event is triggered at the Edge Location closer to the end user.
Viewer Response: When a CloudFront server is ready to respond to a request, this event is triggered.
Origin Request: When CloudFront server does not have the requested object in its cache, the request is forwarded to the Origin server. At this time this event is triggered.
Origin Response: When CloudFront server at an Edge location receives the response from the Origin server, this event is triggered.
31. Explain Storage for Amazon Ec2 Instance.?
Amazon EC2 provides many data storage options for your instances. Each option has a unique combination of performance and durability. These storages can be used independently or in combination to suit your requirements.
There are mainly four types of storages provided by AWS:
Amazon EBS: Its durable, block-level storage volumes can be attached in running Amazon EC2 instance. The Amazon EBS volume persists independently from the running life of an Amazon EC2 instance. After an EBS volume is attached to an instance, you can use it like any other physical hard drive. Amazon EBS encryption feature supports encryption feature.
Amazon EC2 Instance Store: Storage disk that is attached to the host computer is referred to as instance store. The instance storage provides temporary block-level storage for Amazon EC2 instances. The data on an instance store volume persists only during the life of the associated Amazon EC2 instance; if you stop or terminate an instance, any data on instance store volumes is lost.
Amazon S3: Amazon S3 provides access to reliable and inexpensive data storage infrastructure. It is designed to make web-scale computing easier by enabling you to store and retrieve any amount of data, at any time, from within Amazon EC2 or anywhere on the web.
Adding Storage: Every time you launch an instance from an AMI, a root storage device is created for that instance. The root storage device contains all the information necessary to boot the instance. You can specify storage volumes in addition to the root device volume when you create an AMI or launch an instance using block device mapping.
32. What are the Security Best Practices for Amazon Ec2?
There are several best practices for secure Amazon EC2. Following are a few of them.
Use AWS Identity and Access Management (AM) to control access to your AWS resources.
Restrict access by only allowing trusted hosts or networks to access ports on your instance.
Review the rules in your security groups regularly, and ensure that you apply the principle of least
Privilege — only open up permissions that you require.
Disable password-based logins for instances launched from your AMI. Passwords can be found or cracked, and are a security risk.
33. Explain Stopping, Starting, and Terminating an Amazon Ec2 Instance?
Stopping and Starting an instance: When an instance is stopped, the instance performs a normal shutdown and then transitions to a stopped state. All of its Amazon EBS volumes remain attached, and you can start the instance again at a later time. You are not charged for additional instance hours while the instance is in a stopped state.
Terminating an instance: When an instance is terminated, the instance performs a normal shutdown, then the attached Amazon EBS volumes are deleted unless the volume’s deleteOnTermination attribute is set to false. The instance itself is also deleted, and you can’t start the instance again at a later time.
34. What is S3? What is it used for? Should Encryption be Used?
S3 implies for Simple Storage Service. You can believe it similar ftp warehouse, wherever you can transfer records to and from beyond, merely not uprise it similar to a filesystem. AWS automatically places your snaps there, at the same time AMIs there. sensitive data is treated with Encryption, as S3 is an exclusive technology promoted by Amazon themselves, and as still unproven vis-a-vis a protection viewpoint.
35. What is AWS Cloud Search
Amazon CloudSearch is a managed service in the AWS Cloud that makes it simple and cost-effective to set up, manage, and scale a search solution for your website or application.
Amazon CloudSearch supports 34 languages and popular search features such as highlighting, autocomplete, and geospatial search
36. What is Qlik Sense Charts?
Qlik Sense Charts is another software as a service (SaaS) offering from Qlik which allows Qlik Sense visualizations to be easily shared on websites and social media. Charts have limited interaction and allow users to explore and discover.
37. Define Auto Scaling?
Answer: Auto-scaling is one of the conspicuous characteristics feature of AWS anywhere it authorizes you to systematize and robotically obligation and twist up new models externally that necessary for your entanglement. This can be accomplished by initiating brims and metrics to view. If these proposals are demolished, the latest model of your preference will be configured, wrapped up and cloned into the weight administrator panel.
38. Which Automation Gears can Help with Spinup Services?
For the written scripts we can use spinup services with the help of API tools. These scripts could be coded in bash, Perl, or any another language of your choice. There is one more alternative that is patterned control and stipulating devices before-mentioned as a dummy or advanced descendant. A machine termed as Scalar can likewise be utilized and ultimately we can proceed with a constrained expression like a RightScale.
39. Explain what EC2 Instance Metadata is. How does an EC2 instance get its IAM access key and Secret key?
EC2 instance metadata is a service accessible from within EC2 instances, which allows querying or managing data about a given running instance.
It is possible to retrieve an instance’s IAM access key by accessing the iam/security-credentials/role-name metadata category. This returns a temporary set of credentials that the EC2 instance automatically uses for communicating with AWS services.
40. What is AWS snowball?
Snowball is a petabyte-scale data transport solution that uses devices designed to be secure to transfer large amounts of data into and out of the AWS Cloud. Using Snowball addresses common challenges with large-scale data transfers including high network costs, long transfer times, and security concerns. Customers today use Snowball to migrate analytics data, genomics data, video libraries, image repositories, backups, and to archive part of data center shutdowns, tape replacement or application migration projects. Transferring data with Snowball is simple, fast, more secure, and can be as little as one-fifth the cost of transferring data via high-speed Internet.
41. Explain in Detail the Function of Amazon Machine Image (AMI)?
An Amazon Machine Image AMI is a pattern that comprises a software conformation (for instance, an operating system, a request server, and applications). From an AMI, we present an example, which is a duplicate of the AMI successively as a virtual server in the cloud. We can even offer plentiful examples of an AMI.
42. If I’m expending Amazon Cloud Front, can I custom Direct Connect to handover objects from my own data center?
Certainly. Amazon Cloud Front stipulations culture rises computing sources of separate AWS. By AWS Direct Connect, you will be accelerating with the appropriate information substitution rates. AWS Training Free Demo
43. If My AWS Direct Connect flops, will I lose my Connection?
If a gridlock AWS Direct connects has been transposed, in the event of a let-down, it will convert over to the next one. It is voluntary to allow Bidirectional Forwarding Detection (BFD) while systematizing your rules to safeguard quicker identification and failover. Proceeding the opposite hand, if you have built a backup IPsec VPN connecting as an option, all VPC transactions will failover to the backup VPN association routinely.
44. What is AWS Certificate Manager?
AWS Certificate Manager (ACM) manages the complexity of extending, provisioning, and regulating certificates granted over ACM (ACM Certificates) to your AWS-based websites and forms. You work ACM to petition and maintain the certificate and later practice other AWS services to provision the ACM Certificate for your website or purpose. As designated in the subsequent instance, ACM Certificates are currently ready for performance with only Elastic Load Balancing and Amazon CloudFront. You cannot handle ACM Certificates outside of AWS.
45. Explain What is Redshift?
The executes it easy and cost-effective to efficiently investigate all your data employing your current marketing intelligence devices which is a completely controlled, high-speed, it is petabyte-scale data repository service known as Redshift.
46. Mention What are the Differences Between Amazon S3 and EC2?
S3: Amazon S3 is simply a storage aid, typically applied to save huge binary records. Amazon too has additional warehouse and database settings, same as RDS to relational databases and DynamoDB concerning NoSQL.
EC2: An EC2 instance is similar to a foreign computer working Linux or Windows and on which you can install whatever software you need, including a Network server operating PHP code and a database server.
47. Explain What is C4 Instances?
C4 instances are absolute for compute-bound purposes that serve from powerful-performance processors. AWS Interview Questions and Answers
48. Explain What is DynamoDB in AWS?
Amazon DynamoDB is a completely controlled NoSQL database aid that renders quick and anticipated execution with seamless scalability. You can perform Amazon DynamoDB to formulate a database table that can save and reclaim any quantity of data, and help any level of application transactions. Amazon DynamoDB automatically increases the data and transactions for the table above an adequate number of servers to supervise the inquiry function designated by the customer and the volume of data saved, while keeping constant and quick execution.
49. Explain What is ElastiCache?
A web service that executes it comfortable to set up, maintain, and scale classified in-memory cache settings in the cloud is known as ElastiCache.
50. What is the AWS Key Management Service?
A managed service that makes it easy for you to create and control the encryption keys used to encrypt your data is known as the AWS Key Management Service (AWS KMS).
Summary
The above questions will provide you with a fair idea of how to get ready for an AWS interview. You are required to have all the concepts relating to AWS in your fingertips to crack the interview with ease. These questions and Answers will boost your confidence level in attending the interviews.
One of the major reasons organizations migrate to the AWS cloud is to gain the elasticity that can grow and shrink on demand, allowing them to pay only for resources they use. But the freedom to provide on-demand resources can sometimes lead to very high costs if they aren’t carefully monitored. Cost Optimization is one of the five pillars of the AWS Well-Architected Framework, and with good reason. When you optimize your costs, you build a more efficient cloud that helps focus your cloud spend where it’s needed most while freeing up resources to invest in things like more headcount, innovative projects or developing competitive differentiators.
Additionally, considering the cost implementation in mind, we will try to optimise our own cost of AWS usage by visualising it with AWS Quicksight. We will look into the complete setup of viewing the AWS cost and usage reports. Furthermore, we will look to implement our goal using S3 and Athena.
What is AWS Cost and Usage Service?
The AWS Cost and Usage report tracks your AWS usage and provides estimated charges associated with your AWS account. The report contains line items for each unique combination of AWS product, usage type, and operation that your AWS account uses. You can customize the AWS Cost and Usage report to aggregate the information either by the hour or by the day. AWS delivers the report files to an Amazon S3 bucket that you specify in your account and updates the report up to three times a day. You can also call the AWS Billing and Cost Management API Reference to create, retrieve, or delete your reports. You can download the report from the Amazon S3 console, upload the report into Amazon Redshift or Amazon QuickSight, or query the report in Amazon S3 using Amazon Athena.
What is AWS QuickSight?
Amazon QuickSight is an Amazon Web Services utility that allows a company to create and analyze visualizations of its customers’ data. The business intelligence service uses AWS’ Super-fast, Parallel, In-memory Calculation Engine (SPICE) to quickly perform data calculations and create graphs. Amazon QuickSight reads data from AWS storage services to provide ad-hoc exploration and analysis in minutes. Amazon QuickSight collects and formats data, moves it to SPICE and visualizes it. By quickly visualizing data, QuickSight removes the need for AWS customers to perform manual Extract, Transform, and Load operations.
Amazon QuickSight pulls and reads data from Amazon Aurora, Amazon Redshift, Amazon Relational Database Service, Amazon Simple Storage Service (S3), Amazon DynamoDB, Amazon Elastic MapReduce and Amazon Kinesis. The service also integrates with on-premises databases, file uploads and API-based data sources, such as Salesforce. QuickSight allows an end user to upload incremental data in a file or an S3 bucket. The service can also transform unstructured data using a Prepare Data option
What is AWS Athena?
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. Athena is easy to use. Simply point to your data in Amazon S3, define the schema, and start querying using standard SQL. Most results are delivered within seconds. With Athena, there’s no need for complex ETL jobs to prepare your data for analysis. This makes it easy for anyone with SQL skills to quickly analyze large-scale datasets.
Athena is out-of-the-box integrated with AWS Glue Data Catalog, allowing you to create a unified metadata repository across various services, crawl data sources to discover schemas and populate your Catalog with new and modified table and partition definitions, and maintain schema versioning. You can also use Glue’s fully-managed ETL capabilities to transform data or convert it into columnar formats to optimize cost and improve performance.
Setting up AWS S3 and Cost Service
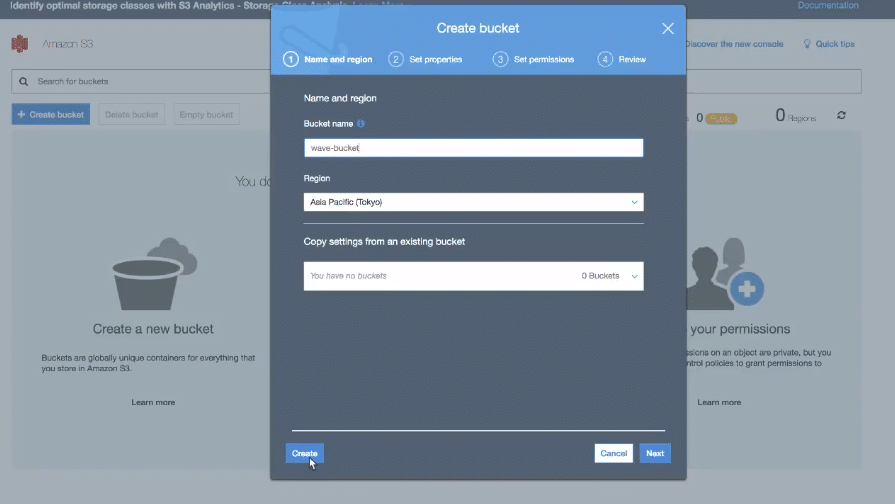
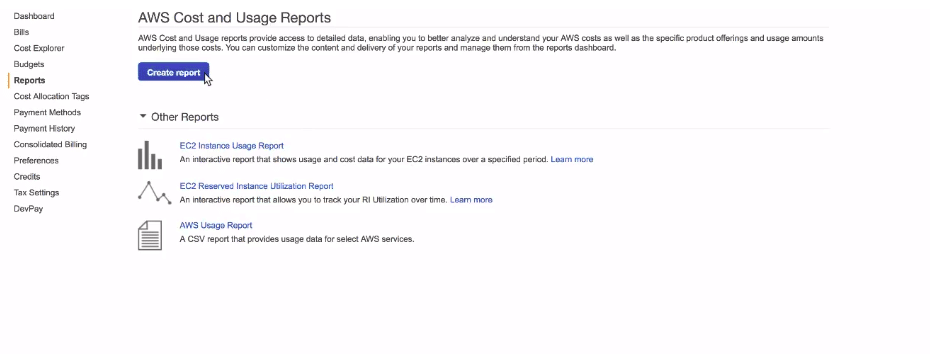
The very first task requires you to set up an S3 bucket. S3 bucket is the location where we will be putting our amazon cost and usage data. Go to your Amazon console and select S3. Click on create bucket button to initialise the setup
Once the create bucket menu pops up, you will see the different options to fill. You need to write the bucket name, mention region and select access settings for the bucket in this step.
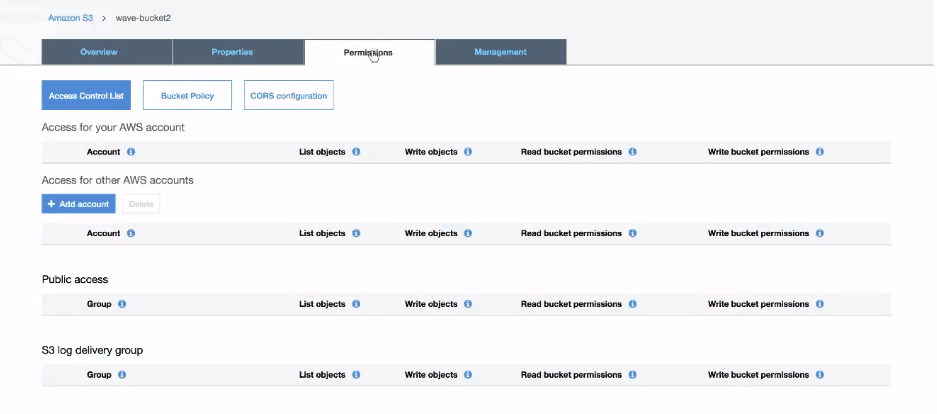
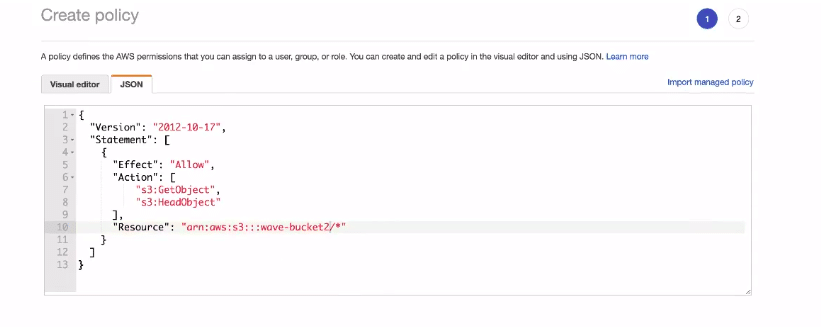
Click on create after filling all the fields. Open S3 and navigate to the Permissions tab in the console. We need to copy the access policy from here to access this bucket from quicksight. Furthermore, this policy will help in connecting the bucket with AWS cost and usage service.
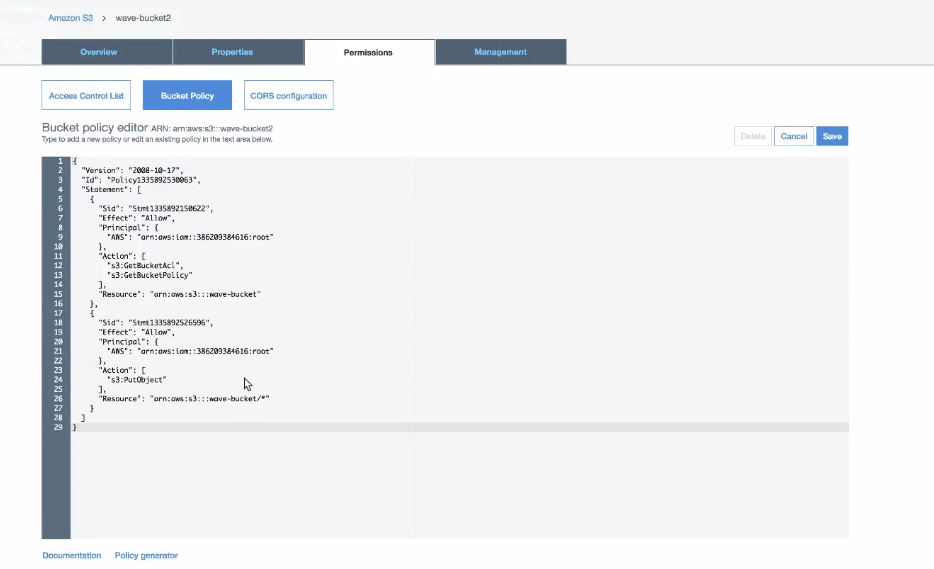
Click on bucket policy. A JSON file will come up with some default settings. We do not need to change much of the things in this file. You can directly copy the code their
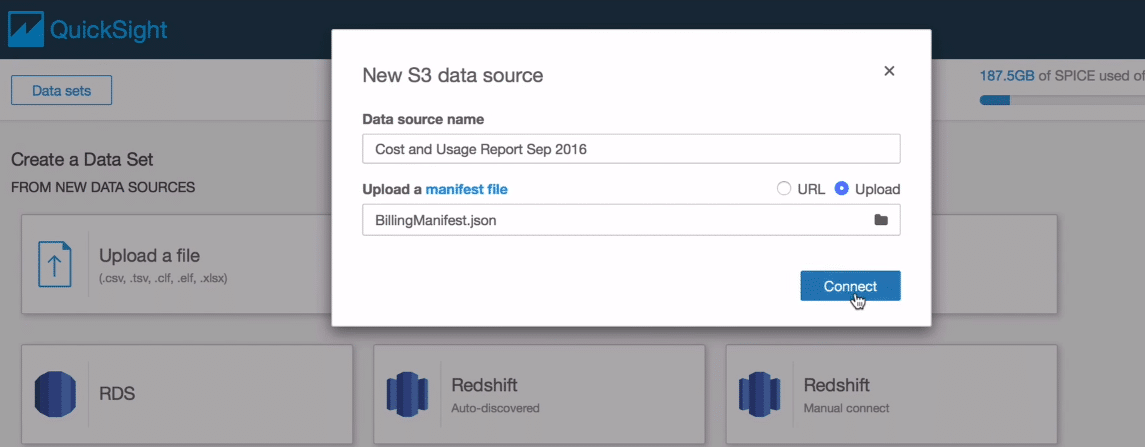
We are able to set up our S3 bucket till now. Additionally, we need to create our cost and usage report now. Go to AWS Cost and usage reports tab from the console. Click on create the report to create a new report on cost and usage.
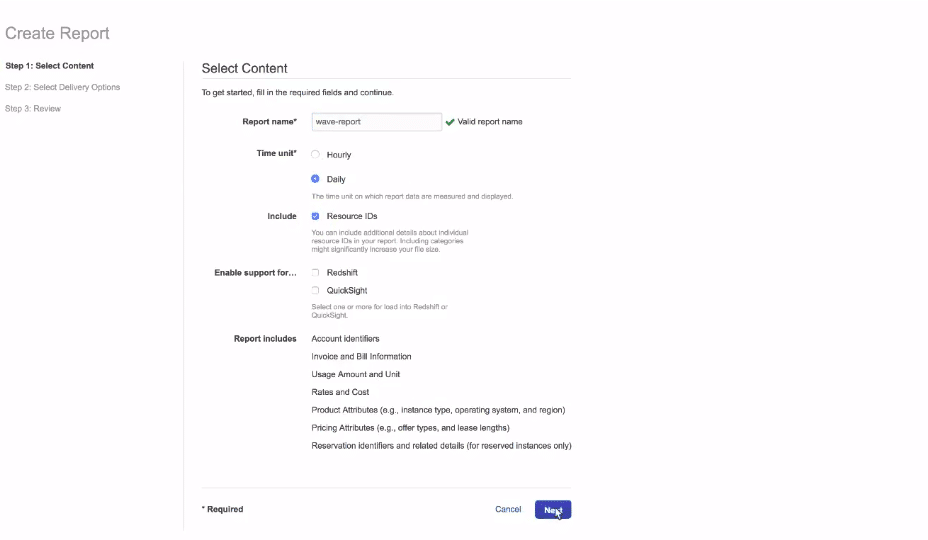
After clicking on create report, a form will pop up. Mention all the necessary details here. The form includes the report name, cost and usage time level. You can directly access these reports for Redshift and Quicksight. In this tutorial, we are storing the data in the S3 bucket first. After storing it in S3 bucker, we will connect it with AWS Quicksight.
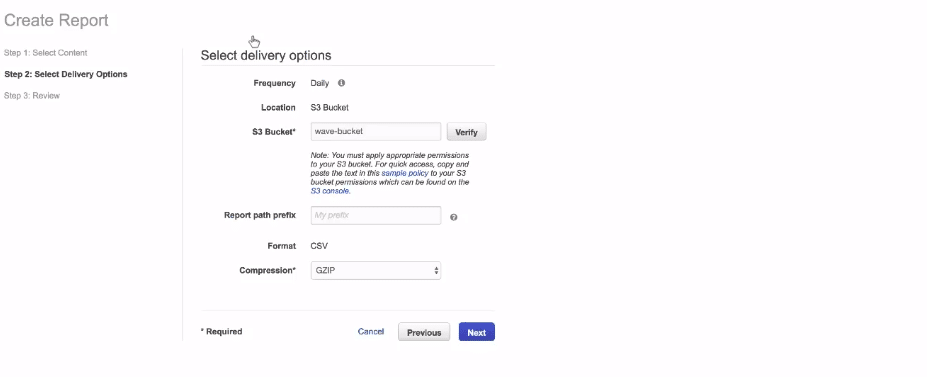
In the second part, we need to select a delivery option. I will mention the name of the final delivery S3 bucket which we created in the previous step.
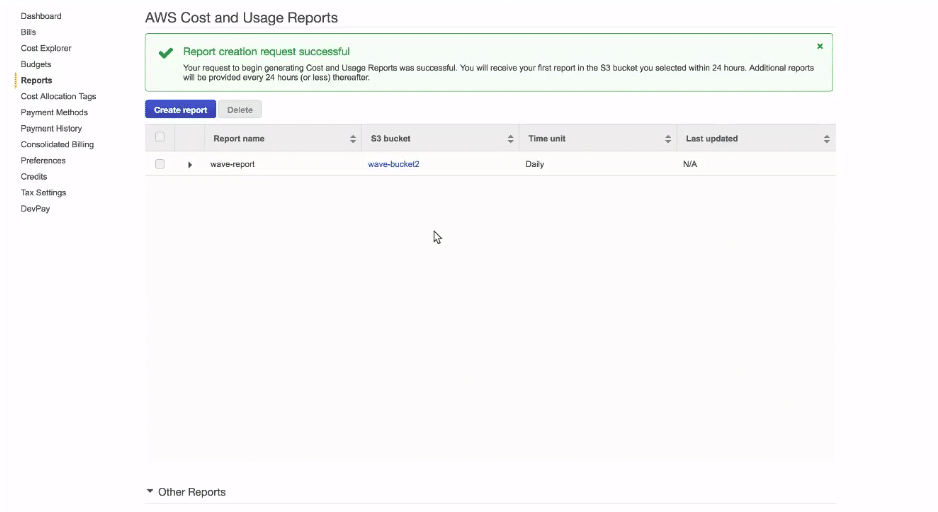
Fill the form and click next. After clicking the next, we have created a report on AWS cost and billing. Click on the newly generated report now.
We need to set up access policies for the report. Click on create a new policy and sample editor will pop up
You can choose to edit the policy depending upon your requirement. Edit the resource section here and mention the correct name of your S3 bucket here. Click on done to complete the policy initialisation
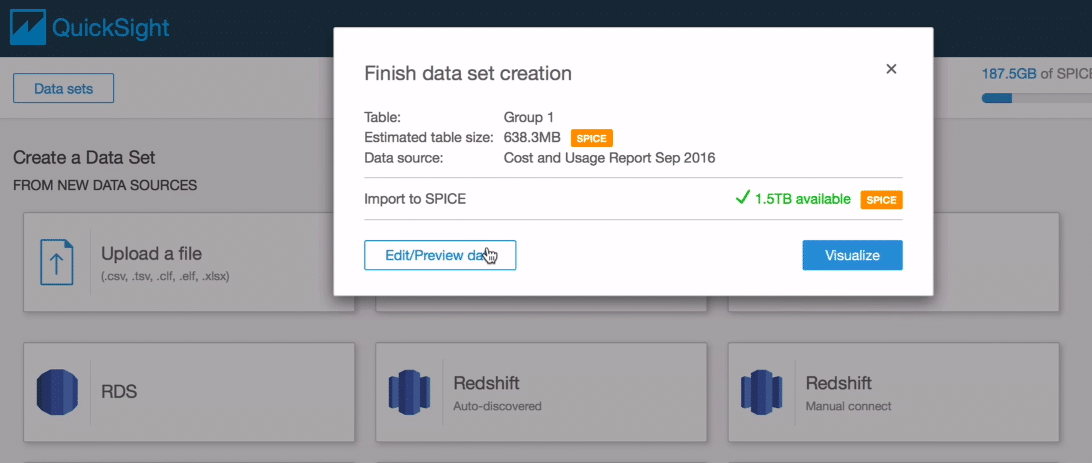
Congratulations! Till this part, we have done most of our work. We have an S3 bucket to store cost and usage data. Also, we have set up cost and usage reports to access our S3 bucket and store the results there.
Setting up Athena (Cloud formation template) and Running Queries
Now we need to setup Athena using a cloud formation template. Go to cloud formation console and click on select “Create New Stack”. Once you click on create a new stack, a sample popup will come.
Here you need to fill the form for creating the template. You can choose to select an existing Amazon S3 or can mention a template URL. Once you fill all the fields, click on next. This will create the Athena stack for you using cloud formation template.
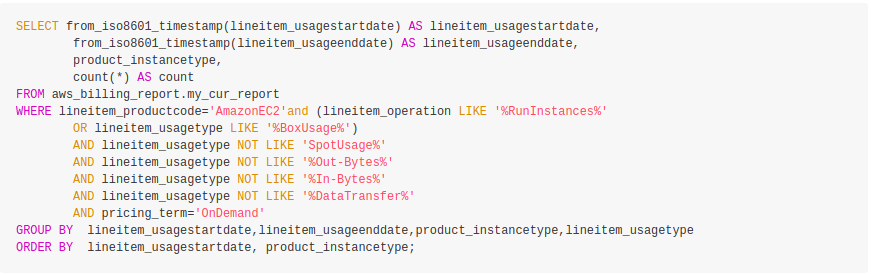
Following is the query command, to access the cost and usage statistics. Also, you can try running the following code on the Athena editor to view the results.
Setting up Quicksight
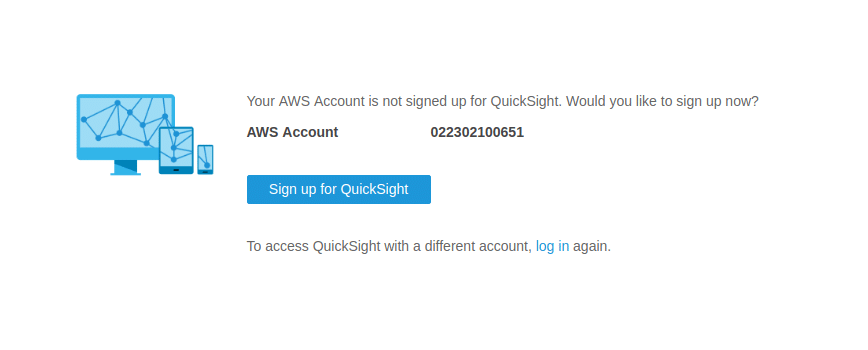
Now we have our Athena and S3 setup completely. We need to setup Quicksight now. Go to Quicksight section, and click on setup. There can be the case when you need to enable or signup for the Quicksight again. In case the below pop up appears, click on signup to create the QuickSight account
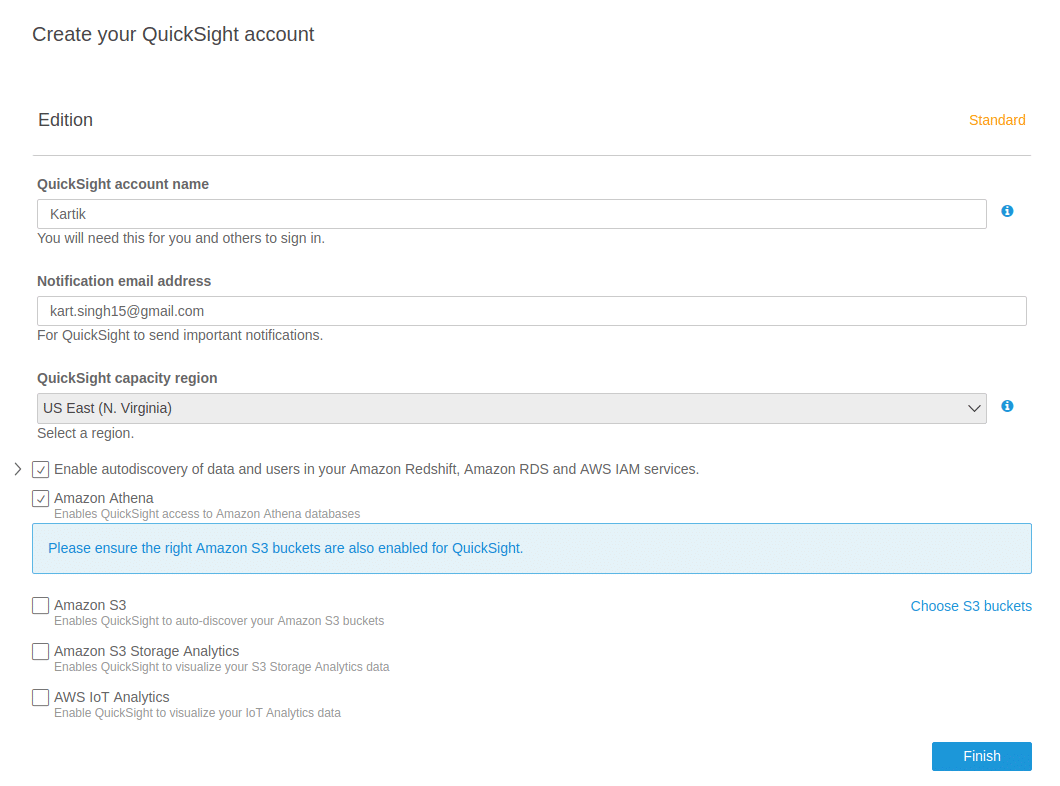
A sample form like below will pop up for you. Mention the account name, email address and the services you want to enable for Quicksight. Once you have filled all the entries, click on Finish to complete the setup
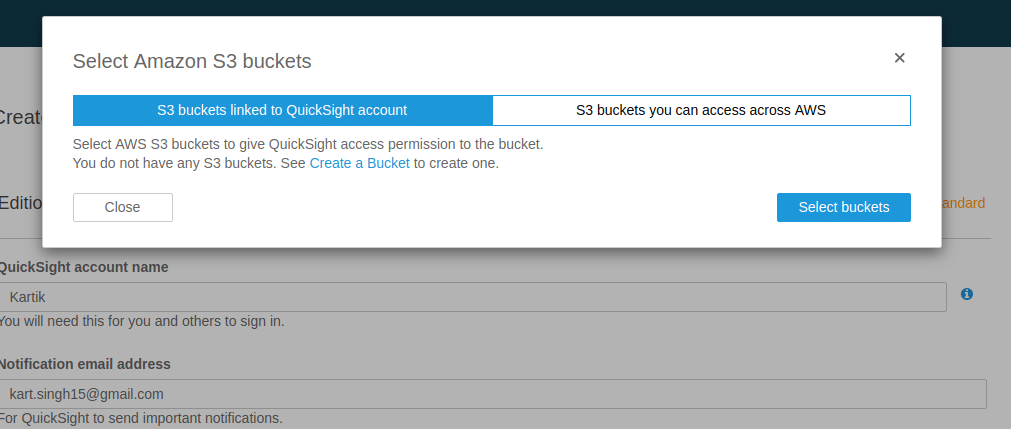
You can choose to connect your s3 account with Quicksight. In the following popup, a sample of already existing buckets will pop for you. You can select the pre-existing buckets and it will automatically get connected with your Quicksight. Here you can easily connect the bucket which holds your AWS cost and usage report. With bucket already connected, you can easily pull the cost and usage report into Quicksight and analyse it.
After setting up the Quicksight, a sample popup will come. You can click on Next to finish the setup.
Now the basic setup of Quicksight is complete. All you want to do now is connect your S3 bucket with Quicksight using Athena. Click the Athena option and run the code to extract the usage report into the AWS S3 storage.
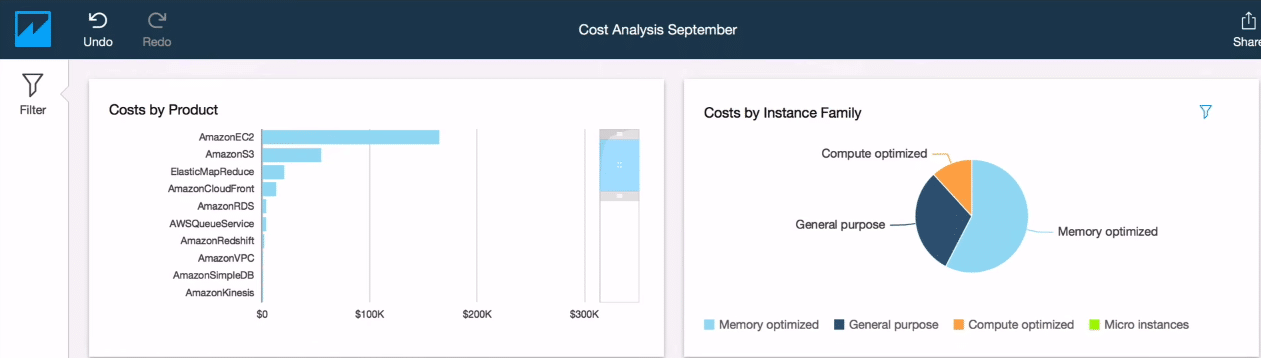
You can then select the column names present in the left sidebar panel to plot the charts in the right panel. Quick sight is a drag-and-drop visualisation tool. You can search for the columns and quick sight will show you the suggested visualisations. You can choose the visualisation and drop it onto the right canvas.
It will automatically plot the charts for you. As you can see, below image contains cost by product visualisation of the AWS services. It also depicts the costs distribution of different instances running on AWS.
Summary
Data-driven decision making is essential throughout an organization. It is no longer prohibitively expensive to ensure access to BI to employees at all levels. Amazon’s QuickSight lets you create and publish interactive dashboards that can be accessed from browsers or mobile devices. You can embed dashboards into your applications, providing your customers with powerful self-service analytics. It easily scales to tens of thousands of users without any software to install, servers to deploy, or infrastructure to manage.
QuickSight is an innovative and cloud-hosted BI platform that addresses the shortfalls of traditional BI systems. Furthermore, its low pay-per-session pricing is a great alternative to the competition. QuickSight can get data from various sources including relational databases, files, streaming, and NoSQL databases. QuickSight also comes with an in-memory caching layer that can cache and calculate aggregates on the fly. With QuickSight, data analysts are truly empowered and can build intuitive reports in minutes without any significant set up by IT.
Amazon Web Services (AWS) was the first significant player to offer reasonably priced cloud infrastructure and services, and it continues to be the single largest vendor in the cloud market. With AWS, businesses have access to extremely durable storage, cost-effective compute power, high-performing databases and more without the hassle of provisioning and managing infrastructure. AWS services are available without any up-front investments, and you pay for only what you use.
ETL is one of the primary tasks in the analytics industry. You can do ETL in AWS in a few different ways:
AWS Glue
Data pipeline
A custom solution, e.g. a Docker
In this blog, we are going to focus the ETL part through AWS Glue. We will also look at components of AWS Glue. Furthermore, we will try to play with AWS glue a bit in order to understand it in depth.
What is AWS Glue?
AWS Glue is a fully managed ETL (extract, transform, and load) service that makes it simple and cost-effective to categorize your data, clean it, enrich it, and move it reliably between various data stores. It consists of a central metadata repository known as the AWS Glue Data Catalog, an ETL engine that automatically generates Python or Scala code, and a flexible schedule that handles dependency resolution, job monitoring, and retries. Also, AWS Glue is serverless, so there’s no infrastructure to set up or manage.
Use the AWS Glue console to discover data, transform it, and make it available for search and querying. The console calls the underlying services to orchestrate the work required to transform your data. You can also use the AWS Glue API operations to interface with AWS Glue services. Edit, debug and test your Python or Scala Apache Spark ETL code using a familiar development environment.
AWS Glue Components
AWS Glue provides a console and API operations to set up and manage your extract, transform, and load (ETL) workload. You can use API operations through several language-specific SDKs and the AWS Command Line Interface (AWS CLI)
AWS Glue uses the AWS Glue Data Catalog to store metadata about data sources, transforms, and targets. The Data Catalog is a drop-in replacement for the Apache Hive Metastore. The AWS Glue Jobs system provides a managed infrastructure for defining, scheduling, and running ETL operations on your data.
AWS Glue Console
You use the AWS Glue console to define and orchestrate your ETL workflow. The console calls several API operations in the AWS Glue Data Catalog and AWS Glue Jobs system to perform the following tasks:
Define AWS Glue objects such as jobs, tables, crawlers, and connections.
Schedule when crawlers run.
Define events or schedules for job triggers.
Search and filter lists of AWS Glue objects.
Edit transformation scripts.
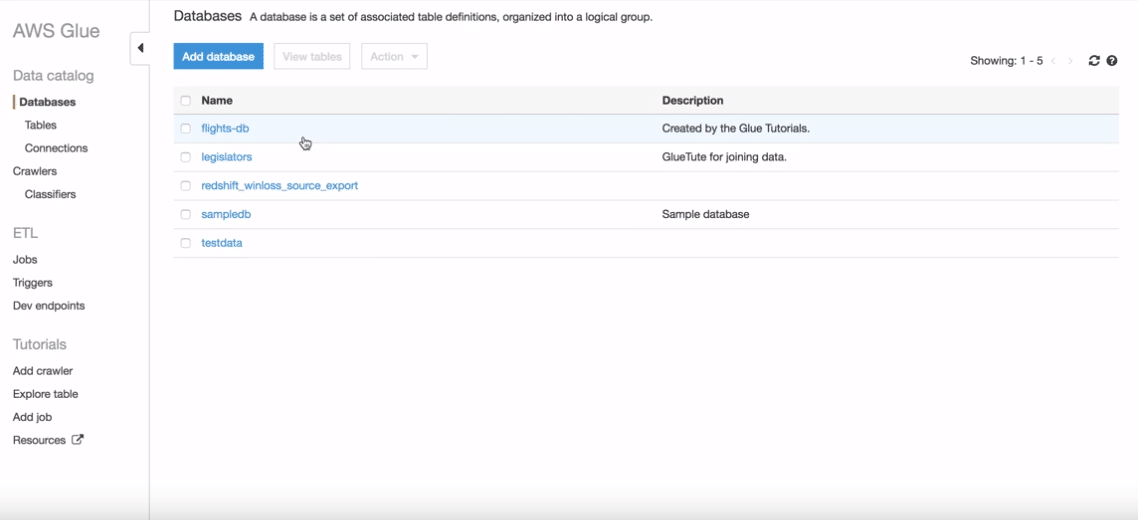
AWS Glue Data Catalog
The AWS Glue Data Catalog is your persistent metadata store. It is a managed service that lets you store, annotate, and share metadata in the AWS Cloud in the same way you would in an Apache Hive metastore.
Each AWS account has one AWS Glue Data Catalog. It provides a uniform repository where disparate systems can store and find metadata to keep track of data in data silos and use that metadata to query and transform the data.
You can use AWS Identity and Access Management (IAM) policies to control access to the data sources managed by the AWS Glue Data Catalog. These policies allow different groups in your enterprise to safely publish data to the wider organization while protecting sensitive information. IAM policies let you clearly and consistently define which users have access to which data, regardless of its location.
AWS Glue Crawlers and Classifiers
AWS Glue also lets you set up crawlers that can scan data in all kinds of repositories, classify it, extract schema information from it, and store the metadata automatically in the AWS Glue Data Catalog. From there it can be used to guide ETL operations.
AWS Glue ETL Operations
Using the metadata in the Data Catalog, AWS Glue can autogenerate Scala or PySpark (the Python API for Apache Spark) scripts with AWS Glue extensions that you can use and modify to perform various ETL operations. For example, you can extract, clean, and transform raw data, and then store the result in a different repository, where it can be queried and analyzed. Such a script might convert a CSV file into a relational form and save it in Amazon Redshift.
The AWS Glue Jobs System
The AWS Glue Jobs system provides managed infrastructure to orchestrate your ETL workflow. You can create jobs in AWS Glue that automate the scripts you use to extract, transform, and transfer data to different locations. Jobs can be scheduled and chained, or they can be triggered by events such as the arrival of new data.
Importing Metadata and Running Crawlers
In this section, we will be importing data table and it’s metadata from Amazon redshift to Glue. We will be using the crawler features present in the Amazon Glue to import the data. So let us start importing!
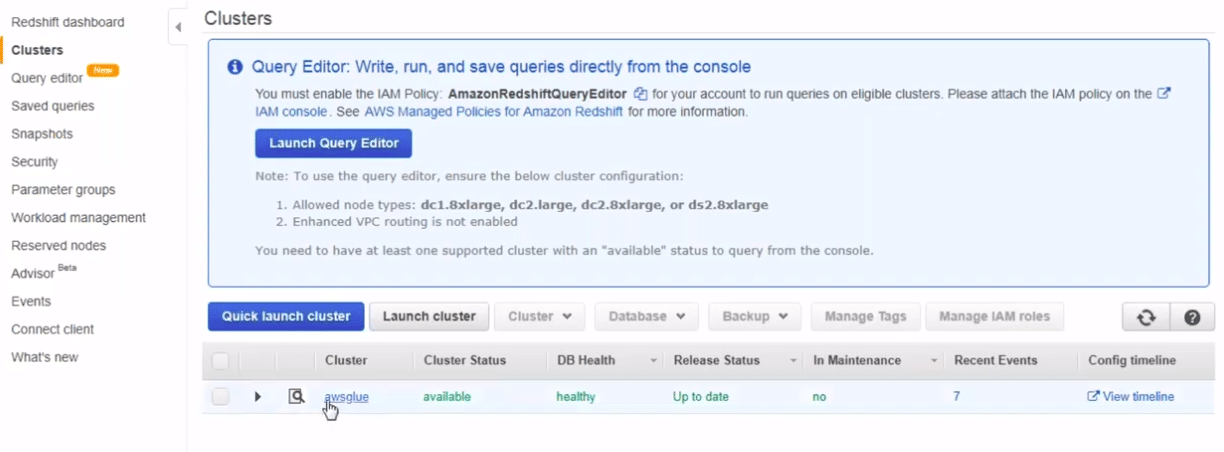
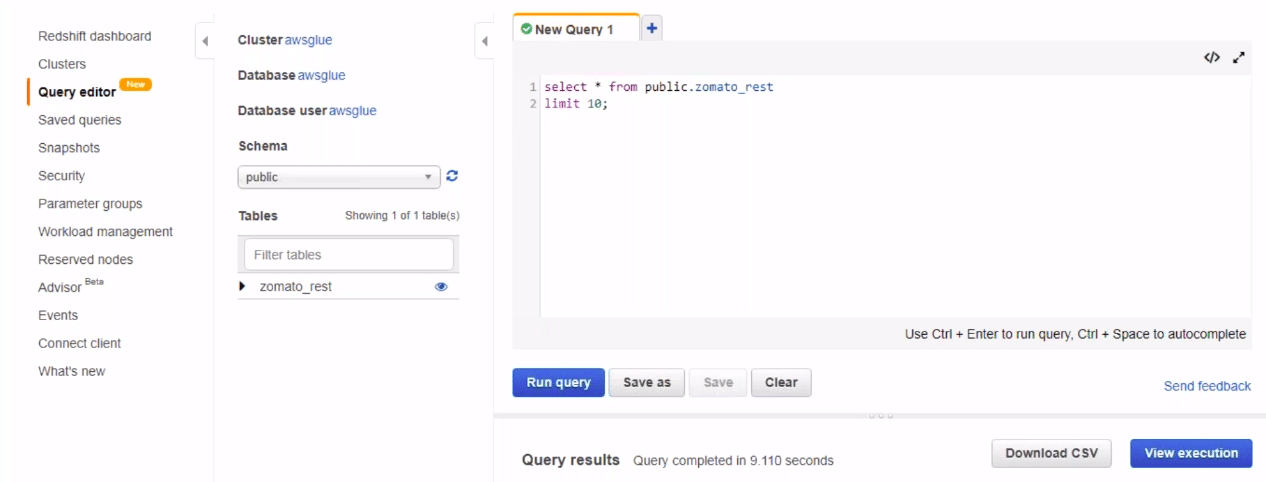
First, we will go to our redshift cluster and navigate to the database. From there, we will navigate to our final table.
We can try running the query to view the data. We will view all the components of the data which we need to export to Glue.
Once we have our data, we can go to AWS Glue and select add connection feature.
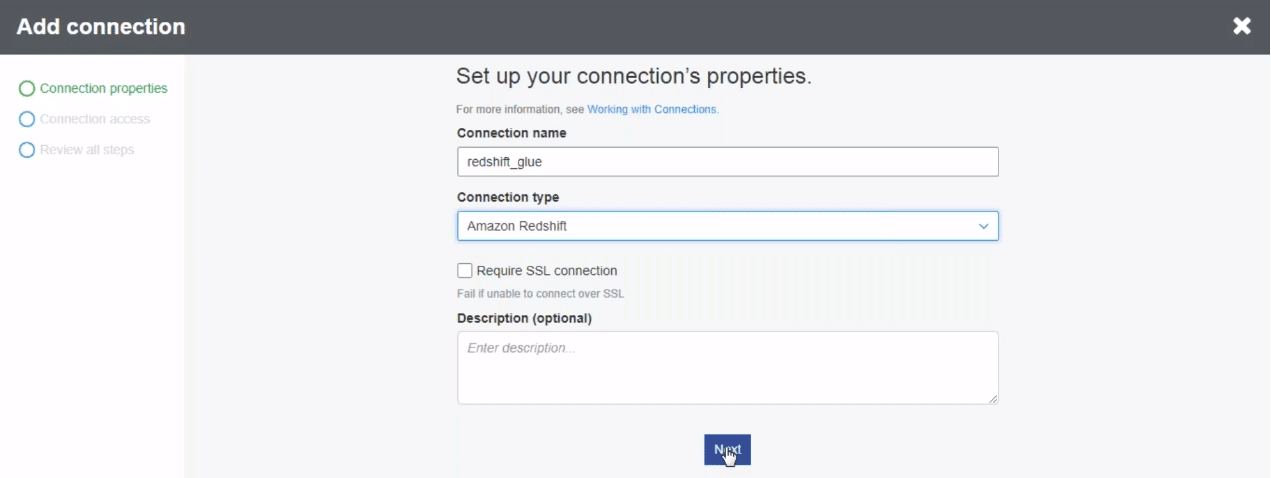
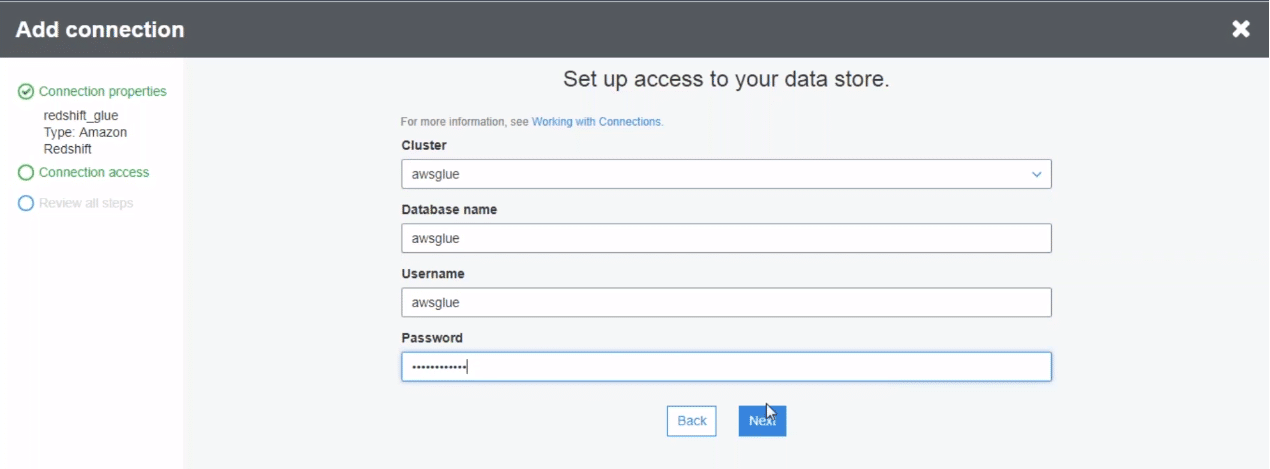
After clicking add the connection, we need to mention the various attributes to set up the connection. You need to mention the connection name and type. Since we are importing from redshift, we mention redshift here. We follow a similar process to fill the remaining setup.
Click next to set up the connection!
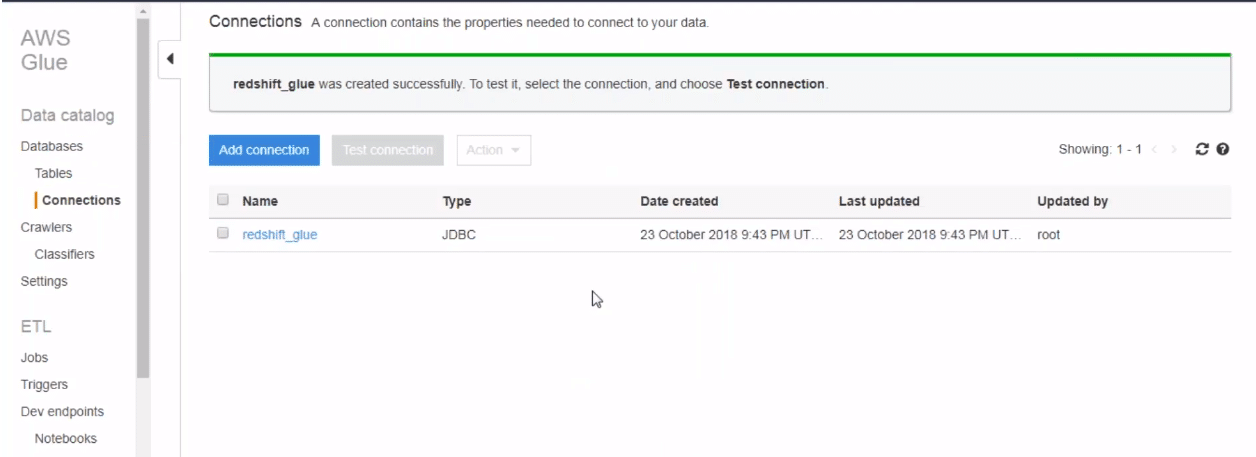
Once, you click next, AWS starts setting up the connection to the redshift. Once the connection is there, you can see it on your console.
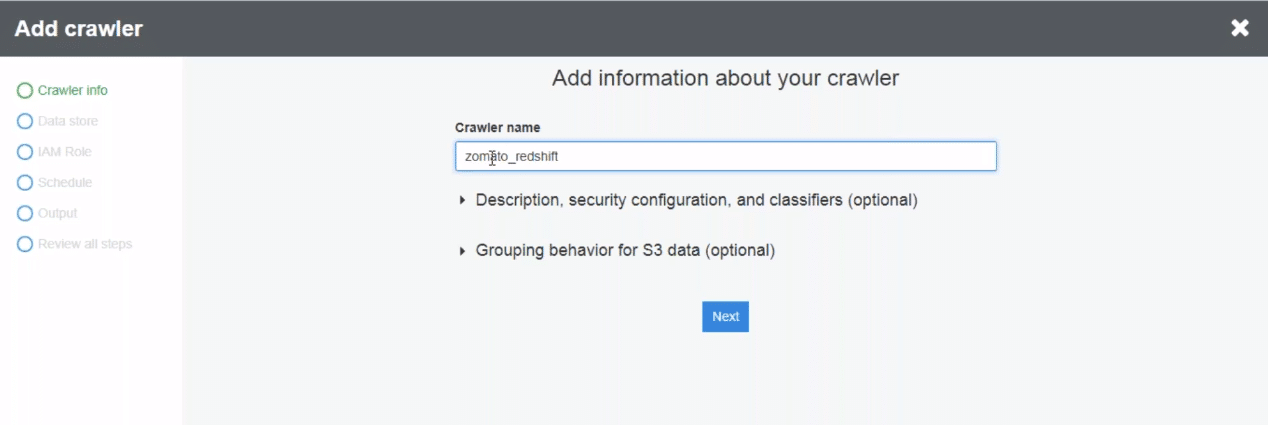
Now we need to set up a crawler to get the data from redshift to the Glue. Similar to add a connection, we fill different attributes of the crawler here
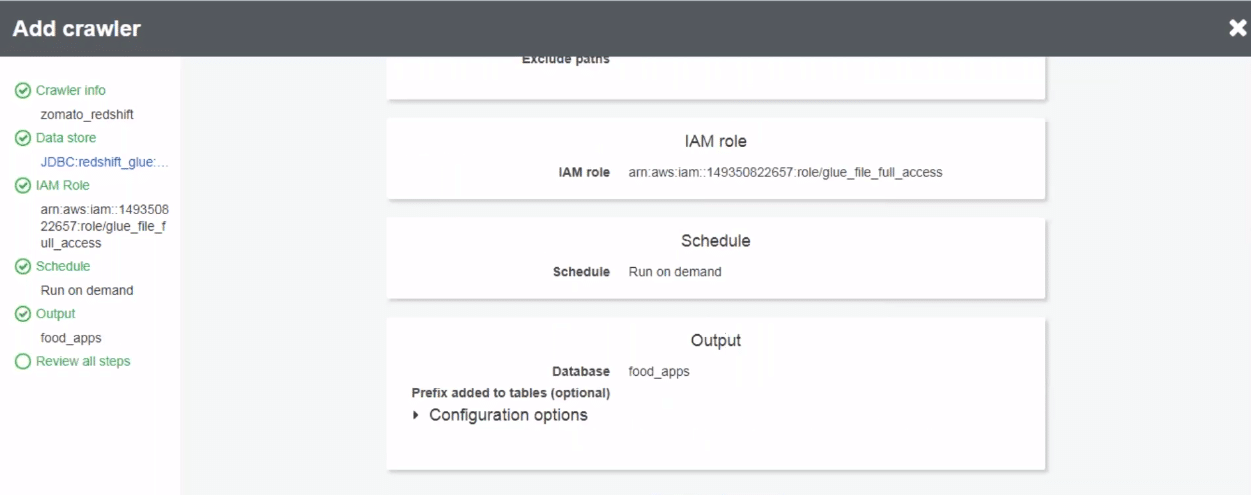
You need to mention parameters like the database to read, the table to read, connection type etc to set up the crawler. Once we have all the parameters filled, we can click next to set up the crawler.
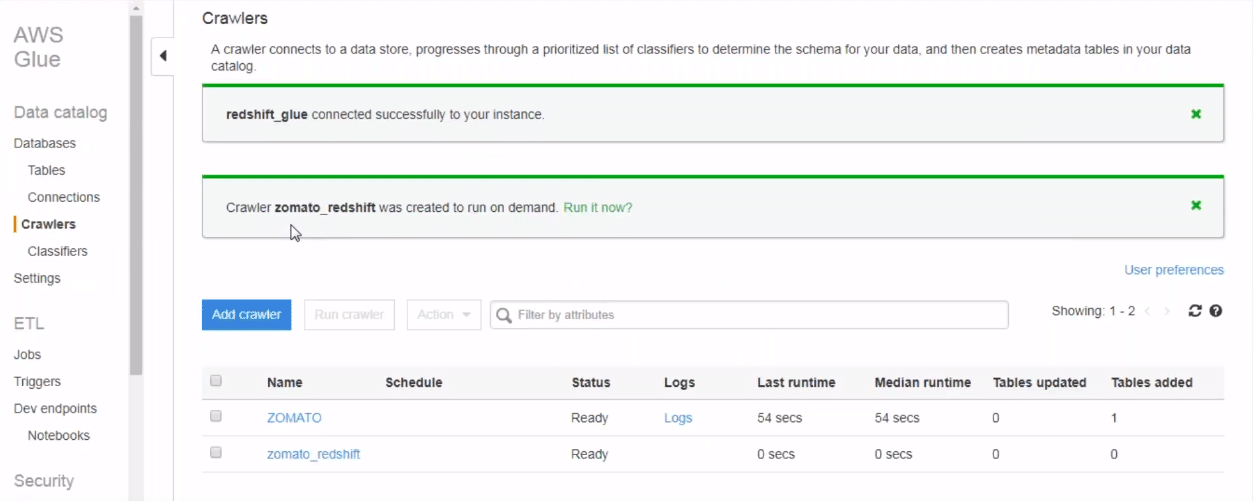
As you can see in the below screenshot, after clicking next, the crawler is setup. All we need to do now is run it. Click on “run it now” button. Upon clicking the button, AWS runs the crawler. Once the crawler task finishes, it stores all the data from redshift to Glue.
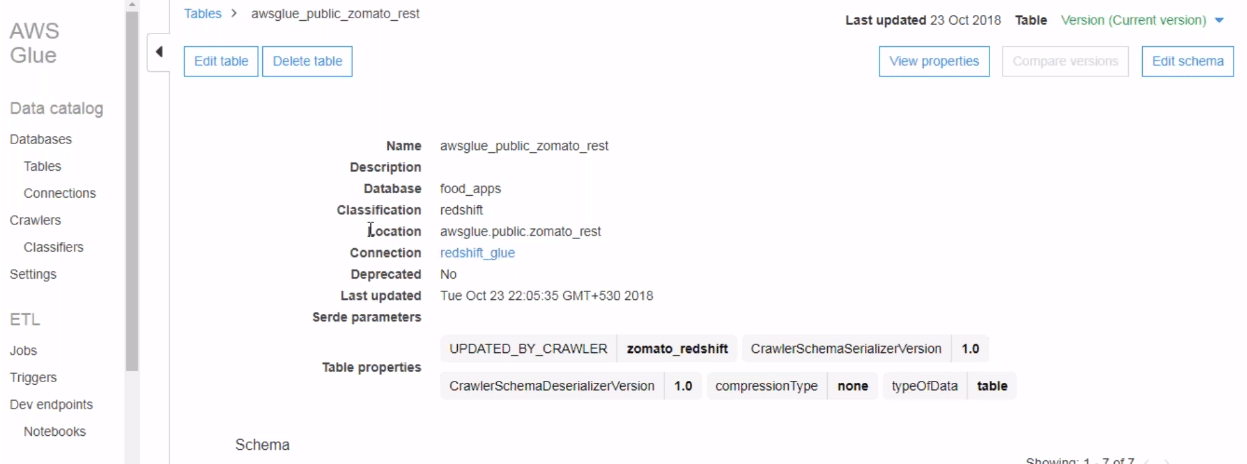
You can actually view the imported tables. Also, you can go to the tables and then you can see your specific table created there. Now click on the table to view the properties and the schema
Writing and Triggering Scripts in Glue
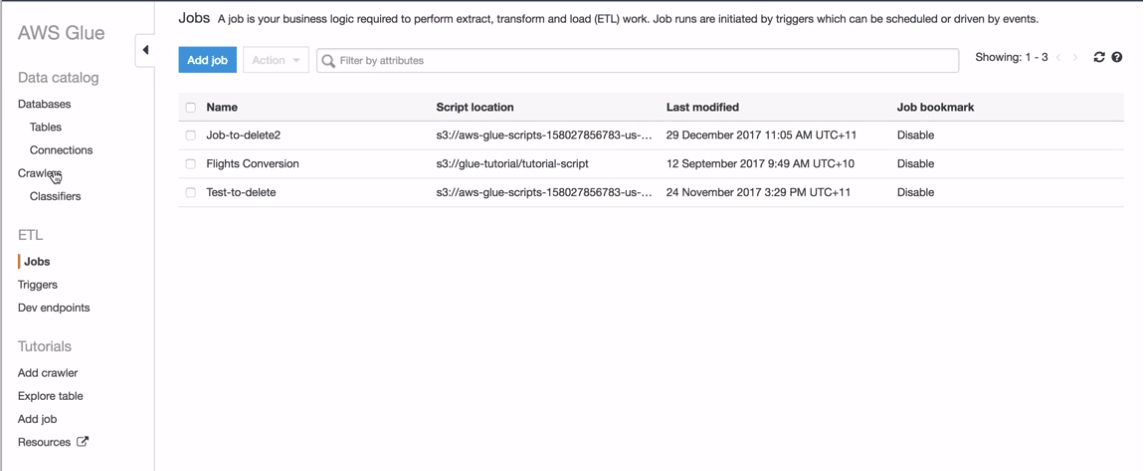
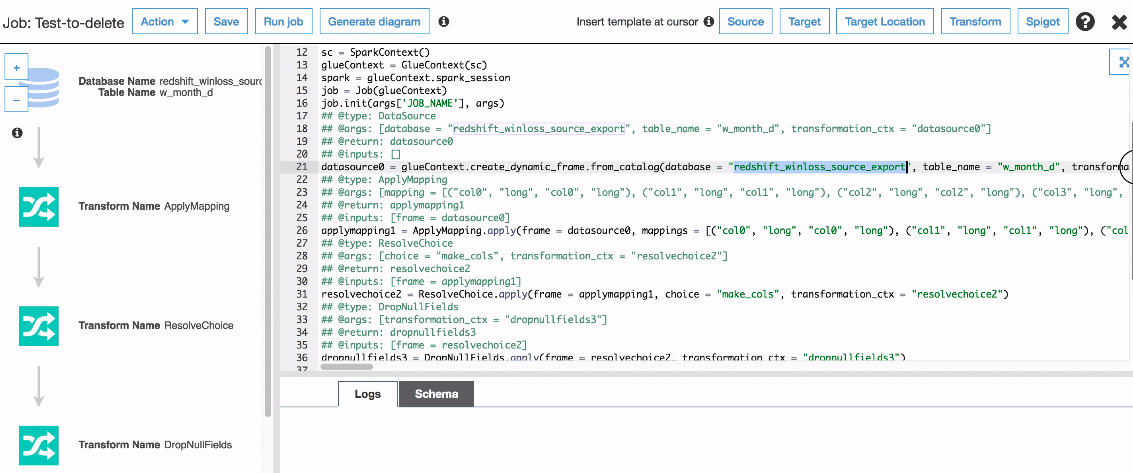
A script contains the code that extracts data from sources, transforms it, and loads it into targets. AWS Glue runs a script when it starts a job.
AWS Glue ETL scripts can be coded in Python or Scala. Python scripts use a language that is an extension of the PySpark Python dialect for extract, transform, and load (ETL) jobs. The script contains extended constructs to deal with ETL transformations. When you automatically generate the source code logic for your job, a script is created. You can edit this script, or you can provide your own script to process your ETL work.
To make a script, click on jobs in AWS Glue. You can make a new script here. In this case, we are editing our old one. Click on the script/job and a sample pop up will come. To edit the script, you can click “edit script”.
Edit script option gives you a full editor view to manage the job. The job is more again like ETL operations which you want to perform on the moving data.
There can be cases when you want your jobs to happen in a sequence. you can use triggers. Triggers can run the code upon receiving some action. For example, you may want a script to run once a prev script has finished the execution. In the screenshot below too, you can see how delete job is mapped to completion trigger of some other job. Once that previous job finishes execution, only then delete job will start the execution
Summary
I’ve used a custom solution for a while but recently decided to move to Glue, gradually. Why? Because when it is set up, you have so much less to worry about. Glue is the preferred choice when you need to move data around. If you’re unsure what route to take, stick to Glue. If you find it doesn’t fit your needs well, only then look elsewhere.
Follow this link, if you are looking to learn more about data science online!
Apache Spark has become one of the most popular tools for running analytics jobs. This popularity is due to its ease of use, fast performance, utilization of memory and disk, and built-in fault tolerance. These features strongly correlate with the concepts of cloud computing, where instances can be disposable and ephemeral.
In this lecture, we’re going to run our spark application on Amazon EMR cluster. Also, we’re going to run spark application on top of the Hadoop cluster and we’ll put the input data source into the s3. Furthermore, you might want to ask why we need to save our input source file into s3 instead of local disk this is because in the real world we want to make sure that our data is coming from some distributed file system that can be accessed by every node on our spark cluster.
What is Amazon EMR
EMR stands for elastic Map Reduce. Amazon EMR cluster provides up managed Hadoop framework that makes it easy fast and cost-effective to process vast amounts of data across dynamically scalable Amazon ec2 instances. Also, we can also run other popular distributed frameworks such as Apache spark and HBase in Amazon EMR and interact with data and other AWS data stores such as Amazon s3 and Amazon DynamoDB.
In other words, Amazon EMR is a managed cluster platform that simplifies running big data frameworks, such as Apache Hadoop and Apache Spark, on AWS to process and analyze vast amounts of data. By using these frameworks and related open-source projects, such as Apache Hive and Apache Pig, you can process data for analytics purposes and business intelligence workloads
Our Goal
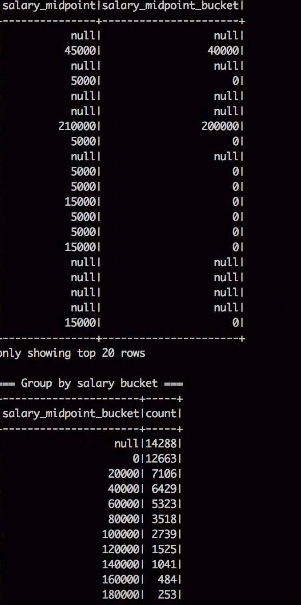
Our goal is to parse a couple of log files amounting to several thousands of records. This will be done using a hive script/spark program. An SQL table will be created with this structure then the file will be parsed based on this regular expression. Finally, the query will output the number of total requests per operating system
Processing Pipeline
Before diving into the task, let us set up a small pipeline to achieve our goal.
Setting up EMR clusters: We will create an EMR cluster first running different EC2 instances. These clusters will have the capability of providing a scalable and distributed platform for running our code to process big data
Attaching a Data Source
Setting up the Runner Task
Viewing Results and Terminating the EMR Cluster
Step 1: Creating an EMR Cluster
You need to go to the AWS management console. After then, click services on the top left. Then you need to select EMR.
Now we’re at the EMR page. You need to click create a cluster.
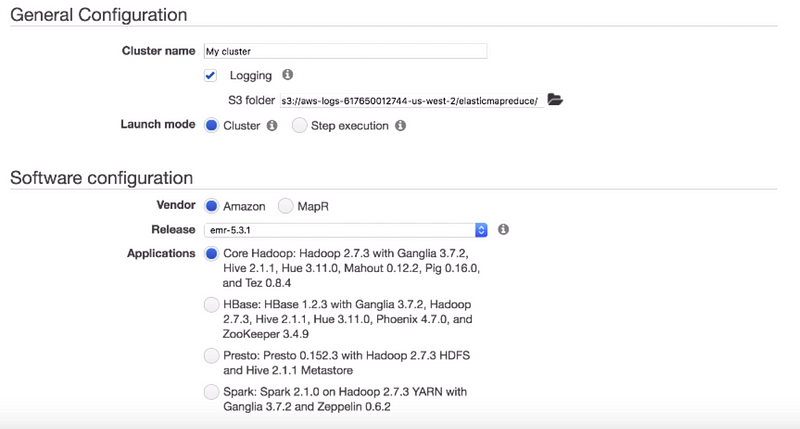
We can leave the cluster name as default. There are two launch modes i.e cluster mode and step execution. With cluster mode, EMR will create a cluster with a set of specified applications. You can add steps to the cluster. After it’s launched, the cluster continues running until you terminate it with stop execution. In our case, we want to install SPARK on top of the Hadoop cluster and we don’t want the cluster to terminate automatically after the job is done so we choose the cluster mode.
This vendor option sets the vendor from which you want to select the software release and applications for your cluster. This release option specifies the software and Amazon EMR platform components to install on the cluster. Amazon EMR uses the release to initialize the Amazon ec2 instances on which your cluster runs. The latest release label is selected by default. We will leave it as default. The application option determines the applications to install on your cluster. Here, we want to install SPARK on top of it.
The instant type option determines the Amazon ec2 instance type that Amazon EMR initializes for the instances that run in your cluster. We will use the default. The ec2 key pair option specifies the Amazon ec2 key pair to use when connecting to the nodes in your cluster using SSH. if we do not select the key pair you cannot connect to the cluster. For the rest of the permissions, we go with the default options. After that, we click to create a cluster to start the provisioning now as you see the cluster is in starting state which means the cluster is been provisioned this process takes about 10 to 15 minutes to complete after the cluster is successfully created the state will turn from starting to waiting
Step 2: Preparing Datasource
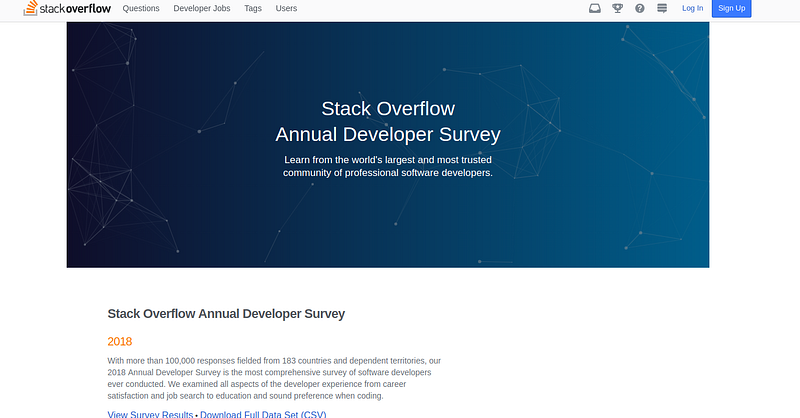
Next, let’s prepare our input data source. We will be using the StackOverflow survey data for this demo. You can find it here. Since we’re going to run our SPARK application on a much large cluster on AWS we can analyze the full stack overflow server data source.
Here on stack overflow research page, we can download data source. After the download is complete, you see the full stack overflow server data source is in CSV format. Next, we’ll be uploading this file to s3.
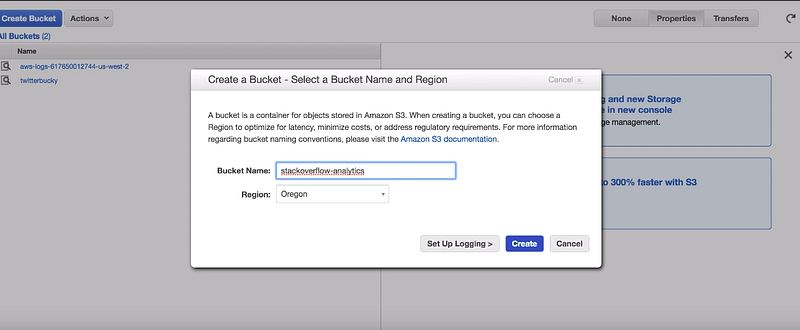
You need to log into the AWS management console again and select s3. Let’s create a new s3 bucket for our spark job. A bucket is a logical unit of storage in s3. Objects are created under buckets. Here, we name our s3 bucket StackOverflow — analytics and then click create.
Now we can just select the newly created bucket name then click upload. After the uploading is complete we can see the CSV file appears under the bucket.
Step 3: Setting up the task
Since data source is ready on s3 let’s login into the spark master machine via SSH. You can find the ssh command by clicking the SSH link under our cluster page. Copy the SSH command and paste it into a terminal. Furthermore, make sure there is an ec2 private key file at the path to the private key file.
Let’s fetch the jar file from s3 to the master machine here for execution. We run AWS s3 CP command which can copy files from or to s3 then supply the source file path which is the s3 file path.
Now we can just run sparks emit and put the jar file name as an argument and hit enter.
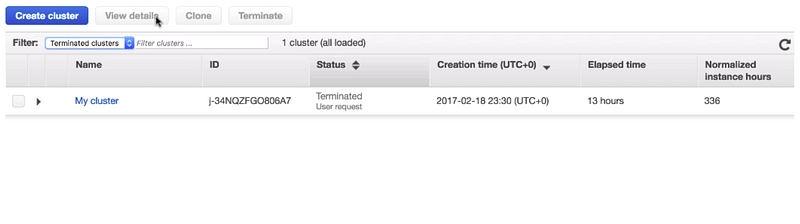
Step 4: Terminating the clusters
By running it, we get all the job outputs now we have seen how to run our spark application on a remote cluster.
Make sure you delete all the files from s3 and terminate your EMR cluster if you don’t need them anymore otherwise it would cost money that’s it
Summary
Amazon EC2 Spot Instances offer spare compute capacity available in the AWS Cloud at steep discounts compared to On-Demand prices. EC2 can interrupt Spot Instances with two minutes of notification when EC2 needs the capacity back. You can use Spot Instances for various fault-tolerant and flexible applications. Some examples are analytics, containerized workloads, high-performance computing (HPC), stateless web servers, rendering, CI/CD, and other test and development workloads.
Amazon EMR provides a managed Hadoop framework that makes it easy, fast, and cost-effective to process vast amounts of data using EC2 instances. When using Amazon EMR, you don’t need to worry about installing, upgrading, and maintaining Spark software (or any other tool from the Hadoop framework). You also don’t need to worry about installing and maintaining underlying hardware or operating systems. Instead, you can focus on your business applications and use Amazon EMR to remove the undifferentiated heavy lifting.
Follow this link, if you are looking to learn more about data science online!
In very simple words, Amazon Web Services is a subsidiary of Amazon that provides on-demand cloud computing platforms to individuals, companies and governments, on a paid subscription basis. The technology allows subscribers to have at their disposal a virtual cluster of computers, available all the time, through the Internet.
Let us give a shot at a very technical description of AWS. Amazon Web Services (AWS) is a secure cloud services platform, offering computing power, database storage, content delivery and other functionality to help businesses scale and grow. Explore how millions of customers are currently leveraging AWS cloud products and solutions to build sophisticated applications with increased flexibility, scalability and reliability.
Capabilities?
Websites & Website Hosting: Amazon Web Services offers cloud web hosting solutions that provide businesses, non-profits, and governmental organizations with low-cost ways to deliver their websites and web applications. Whether you’re looking for marketing, rich media, or e-commerce website, AWS offers a wide range of website hosting options, and we’ll help you select the one that is right for you.
Backup & Recovery: AWS offers the most storage services, data-transfer methods, and networking options to build solutions that protect your data with unmatched durability and security
Data Archive: Amazon Web Services offers a complete set of cloud storage services for archiving. You can choose Amazon Glacier for affordable, non-time sensitive cloud storage, or Amazon Simple Storage Service (S3) for faster storage, depending on your needs. With AWS Storage Gateway and our solution provider ecosystem, you can build a comprehensive, storage solution.
DevOps: AWS provides a set of flexible services designed to enable companies to more rapidly and reliably build and deliver products using AWS and DevOps practices. These services simplify provisioning and managing infrastructure, deploying application code, automating software release processes, and monitoring your application and infrastructure performance.
Big Data: AWS delivers an integrated suite of services that provide everything needed to quickly and easily build and manage a data lake for analytics. AWS-powered data lakes can handle the scale, agility, and flexibility required to combine different types of data and analytics approaches to gain deeper insights, in ways that traditional data silos and data warehouses cannot. AWS gives customers the widest array of analytics and machine learning services, for easy access to all relevant data, without compromising on security or governance.
Why learn AWS?
DevOps Automation
You don’t want your data scientists spending time on DevOps tasks like creating AMIs, defining Security Groups, and creating EC2 instances. Data science workloads benefit from large machines for exploratory analysis in tools like Jupyter or RStudio, as well as elastic scalability to support bursty demand from teams, or parallel execution of data science experiments, which are often computationally intensive.
Cost controls, resource monitoring, and reporting
Data science workloads often benefit from high-end hardware, which can be expensive. When data scientists have more access to scalable compute, how do you mitigate the risk of runaway costs, enforce limits, and attribute across multiple groups or teams?
Environment management
Data scientists need agility to experiment with new open source tools and packages, which are evolving faster than ever before. System administrators must ensure stability and safety of environments. How can you balance these two points in tension?
GPUs
Neural networks and other effective data science techniques benefit from GPU acceleration, but configuring and utilizing GPUs remains easier said than done. How can you provide efficient access to GPUs for your data scientists without miring them in DevOps configuration tasks?
Security
AWS offers world-class security in their environment — but you must still make choices about how you configure security for your applications running on AWS. These choices can make a significant difference in mitigating risk as your data scientists transfer logic (source code) and data sets that may represent your most valuable intellectual property.
Our AWS Course
1. AWS Introduction
This section covers the basic and different concepts and terms which are AWS specific. This lays out the basic setting where learners are fed with all the AWS specific terms and are prepared for the deep dive.
2. VPC Subnet
A virtual private cloud (VPC) is a virtual network dedicated to your AWS account. It is logically isolated from other virtual networks in the AWS Cloud. You can launch your AWS resources, such as Amazon EC2 instances, into your VPC.
3. Route
A route table contains a set of rules, called routes, that are used to determine where network traffic is directed. Each subnet in your VPC must be associated with a route table; the table controls the routing for the subnet. A subnet can only be associated with one route table at a time, but you can associate multiple subnets with the same route table.
4. EC2
Amazon Elastic Compute Cloud (Amazon EC2) is a web service that provides secure, resizable compute capacity in the cloud. It is designed to make web-scale cloud computing easier for developers.
5. IAM
AWS Identity and Access Management (IAM) is a web service that helps you securely control access to AWS resources. You use IAM to control who is authenticated (signed in) and authorized (has permissions) to use resources.
6. S3
Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance. This means customers of all sizes and industries can use it to store and protect any amount of data for a range of use cases, such as websites, mobile applications, backup and restore, archive, enterprise applications, IoT devices, and big data analytics.
7. Lambda
AWS Lambda is a ‘compute’ service that lets you run code without provisioning or managing servers. AWS Lambda executes your code only when needed and scales automatically, from a few requests per day to thousands per second
8. SNS
Amazon Simple Notification Service (SNS) is a highly available, durable, secure, fully managed pub/sub messaging service that enables you to decouple microservices, distributed systems, and serverless applications. Amazon SNS provides topics for high-throughput, push-based, many-to-many messaging.
9. SQS
Amazon Simple Queue Service (SQS) is a fully managed message queuing service that enables you to decouple and scale microservices, distributed systems, and serverless applications. SQS eliminates the complexity and overhead associated with managing and operating message-oriented middleware and empowers developers to focus on differentiating work.
10. RDS
Amazon Relational Database Service (Amazon RDS) makes it easy to set up, operate, and scale a relational database in the cloud. It provides cost-efficient and resizable capacity while automating time-consuming administration tasks such as hardware provisioning, database setup, patching and backups.
11. Dynamo DB
Amazon DynamoDB is a key-value and document database that delivers single-digit millisecond performance at any scale. It’s a fully managed, multi-region, multi-master database with built-in security, backup and restores, and in-memory caching for internet-scale applications. DynamoDB can handle more than 10 trillion requests per day and support peaks of more than 20 million requests per second.
13. Cloud Formation
AWS CloudFormation provides a common language for you to describe and provision all the infrastructure resources in your cloud environment. CloudFormation allows you to use a simple text file to model and provision, in an automated and secure manner, all the resources needed for your applications across all regions and accounts. This file serves as the single source of truth for your cloud environment.
14. Projects
No learning can happen without doing any project. This is our mantra at Dimensionless Technologies. We have different projects planned for our learners which will help in implementing all the learners during the course.
Why Dimensionless as your learning partner?
Dimensionless Technologies provide instructor-led LIVE online training with hands-on different problems. We do not provide classroom training but we deliver more as compared to what a classroom training could provide you with
Are you sceptical of online training or you feel that online mode is not the best platform to learn? Let us clear your insecurities about online training!
Live and Interactive sessions
We conduct classes through live sessions and not pre-recorded videos. The interactivity level is similar to classroom training and you get it in the comfort of your home.
Highly Experienced Faculty
We have very highly experienced faculty with us (IIT`ians) to help you grasp complex concepts and kick-start your career success journey
Up to Data Course content
Our course content is up to date which involves all the latest technologies and tools. Our course is well equipped for learners to grasp the knowledge required to solve real-world problems through their data analytical skills
Availability of software and computing resource
Any laptop with 2GB RAM and Windows 7 and above is perfectly fine for this course. All the software used in this course are Freely downloadable from the Internet. The trainers help you set it up in your systems. We also provide access to our Cloud-based online lab where these are already installed.
Industry-Based Projects
During the training, you will be solving multiple case studies from different domains. Once the LIVE training is done, you will start implementing your learnings on Real Time Datasets. You can work on data from various domains like Retail, Manufacturing, Supply Chain, Operations, Telecom, Oil and Gas and many more.
Course Completion Certificate
Yes, we will be issuing a course completion certificate to all individuals who successfully complete the training.
Placement Assistance
We provide you with real-time industry requirements on a daily basis through our connection in the industry. These requirements generally come through referral channels, hence the probability to get through increases manifold
Conclusion
Dimensionless technologies have the right courses for you if you are aiming to kick-start your career in the field of data science. Not only we cover all the important concepts and technologies but also focus on their implementation and usage in real-world business problems. Follow the link to register yourself for the free demo of the courses!

;" src="https://dimensionless.in/how-to-visualize-aws-cost-and-usage-data-using-amazon-athena-and-quicksight/embed/#?secret=2MIISNr341" data-secret="2MIISNr341" width="600" height="338" title="“How to Visualize AWS Cost and Usage Data Using Amazon Athena and QuickSight” — DIMENSIONLESS TECHNOLOGIES PVT.LTD." frameborder="0" marginwidth="0" marginheight="0" scrolling="no"></iframe>)
;" src="https://dimensionless.in/how-to-discover-and-classify-metadata-using-apache-atlas-on-amazon-emr/embed/#?secret=uQZUBd9j4w" data-secret="uQZUBd9j4w" width="600" height="338" title="“How to Discover and Classify Metadata using Apache Atlas on Amazon EMR” — DIMENSIONLESS TECHNOLOGIES PVT.LTD." frameborder="0" marginwidth="0" marginheight="0" scrolling="no"></iframe>)



;" src="https://dimensionless.in/how-to-discover-and-classify-metadata-using-apache-atlas-on-amazon-emr/embed/#?secret=dsDpxQUGMT" data-secret="dsDpxQUGMT" width="600" height="338" title="“How to Discover and Classify Metadata using Apache Atlas on Amazon EMR” — DIMENSIONLESS TECHNOLOGIES PVT.LTD." frameborder="0" marginwidth="0" marginheight="0" scrolling="no"></iframe>)