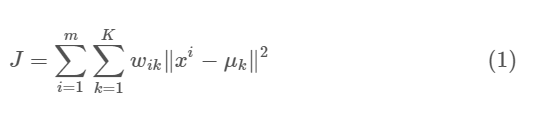What does your business do with the huge volumes of data collected daily? For business, the huge volumes of data collected daily can be demanding and time-consuming. Gathering, analyzing and reporting this type of information and discovering the most important data from the report can be supported through clustering it all.
Clustering can help businesses to manage their data better – image segmentation, grouping web pages, market segmentation, and information retrieval are four examples. For retail businesses, data clustering helps with customer shopping behaviour, sales campaigns, and customer retention. In the insurance industry, clustering is regularly employed in fraud detection, risk factor identification and customer retention efforts. In banking, clustering is used for customer segmentation, credit scoring and analyzing customer profitability.
In this blog, we will understand cluster analysis in detail. We will also look at implementing cluster analysis in python and visualise results in the end!
What is Cluster Analysis?
Clustering is the process of grouping observations of similar kinds into smaller groups within the larger population. It has a widespread application in business analytics. One of the questions facing businesses is how to organize the huge amounts of available data into meaningful structures. Or break a large heterogeneous population into smaller homogeneous groups. Cluster analysis is an exploratory data analysis tool which aims at sorting different objects into groups in a way that the degree of association between two objects is maximal if they belong to the same group and minimal otherwise.
For example, A grocer retailer used clustering to segment its 1.3MM loyalty card customers into 5 different groups based on their buying behaviour. It then adopted customized marketing strategies for each of these segments in order to target them more effectively.
Applications of Cluster Analysis
1. Marketing
Help marketers discover distinct groups in their customer bases and then use this knowledge to develop targeted marketing programs
2. Land Use
Identification of areas of similar land use in an earth observation database
3. Insurance
Identifying groups of motor insurance policyholders with a high average claim cost
4. City-Planning
Identifying groups of houses according to their house type, value, and geographical location
5. Earthquake Studies
Observed earthquake epicenters should be clustered along continent faults
Algorithms for Cluster Analysis
1. K- Means clustering
Kmeans algorithm is an iterative algorithm that tries to partition the dataset into Kpre-defined distinct non-overlapping subgroups (clusters) where each data point belongs to only one group. It tries to make the inter-cluster data points as similar as possible while also keeping the clusters as different (far) as possible. It assigns data points to a cluster such that the sum of the squared distance between the data points and the cluster’s centroid (arithmetic mean of all the data points that belong to that cluster) is at the minimum. The less variation we have within clusters, the more homogeneous (similar) the data points are within the same cluster.
The way the kmeans algorithm works is as follows:
Specify the number of clusters K.
Initialize centroids by first shuffling the dataset and then randomly selecting K data points for the centroids without replacement.
Keep iterating until there is no change to the centroids. i.e assignment of data points to clusters isn’t changing.
Compute the sum of the squared distance between data points and all centroids.
Assign each data point to the closest cluster (centroid).
Compute the centroids for the clusters by taking the average of all data points that belong to each cluster.
The approach the kmeans follows to solve the problem is called Expectation-Maximization. The E-step is assigning the data points to the closest cluster. The M-step is computing the centroid of each cluster. Below is a break down of how we can solve it mathematically (feel free to skip it).
The objective function is:
where wik=1 for data point xi if it belongs to cluster k; otherwise, wik=0. Also, μk is the centroid of xi’s cluster.
2. Hierarchical Clustering
Hierarchical clustering is a type of unsupervised machine learning algorithm used to cluster unlabeled data points. Like K-means clustering, hierarchical clustering also groups together the data points with similar characteristics. In some cases, the result of hierarchical and K-Means clustering can be similar.
Following are the steps involved in agglomerative clustering:
At the start, treat each data point as one cluster. Therefore, the number of clusters at the start will be K, while K is an integer representing the number of data points.
Form a cluster by joining the two closest data points resulting in K-1 clusters.
Form more clusters by joining the two closest clusters resulting in K-2 clusters.
Repeat the above three steps until one big cluster is formed.
Once a single cluster is formed, dendrograms are used to divide into multiple clusters depending upon the problem. We will study the concept of dendrogram in detail in an upcoming section.
There are different ways to find the distance between the clusters. The distance itself can be Euclidean or Manhattan distance. Following are some of the options to measure the distance between two clusters:
Measure the distance between the closest points of two clusters.
Find the distance between the farthest points of two clusters.
Measure the distance between the centroids of two clusters.
Find the distance between all possible combination of points between the two clusters and take the mean.
Code Implementation
We will implement the kmeans algorithm to visualise data to bucket it into different categories. We are using poker hand public data which is available here
Each record is an example of a hand consisting of five playing cards drawn from a standard deck of 52. Each card is described using two attributes (suit and rank), for a total of 10 predictive attributes. There is one Class attribute that describes the “Poker Hand”. The order of cards is important, which is why there are 480 possible Royal Flush hands as compared to 4!
We will be implementing the k-means algorithm using python and will be visualising the results in the end
Let us start by loading the required libraries for our task. We are using pandas and numpy for managing the data frame and mathematical calculations
# load libraries
from pandas import Series, DataFrame
import pandas as pd
import numpy as np
import matplotlib.pylab as plt
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
from sklearn.cluster import KMeans
import urllib.request
from pylab import rcParams
rcParams['figure.figsize'] = 9, 8
Let us focus on the data preparation aspect of our implementation. We will be preparing our test and train data in this section. Train data is the one on which we will be performing the clustering process!
Before proceeding with the segmentation, let us rescale our values within a certain range in order to bring all the numbers at the same scale. This helps in visualising different features on the same base.
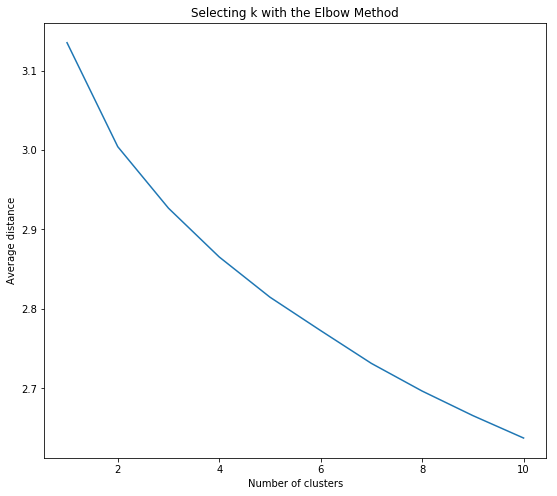
Also, before we start with clustering, we need to determine the number of clusters we are trying to identify. In most of the cases, you are looking for a particular k value for your k-means algorithm. If you select k=3, then the algorithm will try to find 3 different segments present in the data. In most of the cases, you will not be knowing the value of this k parameter. So how do you go about selecting the right “k” value for your model? The answer is “Elbow method”
The idea of the elbow method is to run k-means clustering on the dataset for a range of values of k, and for each value of k calculate the sum of squared errors (SSE).
Then, plot a line chart of the SSE for each value of k. If the line chart looks like an arm, then the “elbow” on the arm is the value of k that is the best. The idea is that we want a small SSE, but that the SSE tends to decrease toward 0 as we increase k (the SSE is 0 when k is equal to the number of data points in the dataset, because then each data point is its own cluster, and there is no error between it and the centre of its cluster). So our goal is to choose a small value of k that still has a low SSE, and the elbow usually represents where we start to have diminishing returns by increasing k
Let’s implement the elbow method to select our “k” value
clus_train = clustervar
from scipy.spatial.distance import cdist
clusters=range(1,11)
meandist=[]
# loop through each cluster and fit the model to the train set
# generate the predicted cluster assingment and append the mean distance my taking the sum divided by the shape
for k in clusters:
model=KMeans(n_clusters=k)
model.fit(clus_train)
clusassign=model.predict(clus_train)
meandist.append(sum(np.min(cdist(clus_train, model.cluster_centers_, 'euclidean'), axis=1))
clus_train.shape[0])
plt.plot(clusters, meandist)
plt.xlabel('Number of clusters')
plt.ylabel('Average distance')
plt.title('Selecting k with the Elbow Method')
Observing the elbow method,k=2 and k=3 are more reasonable options for our segmentation analysis
model3=KMeans(n_clusters=2)
model3.fit(clus_train)
# has cluster assingments based on using 3 clusters
clusassign=model3.predict(clus_train)
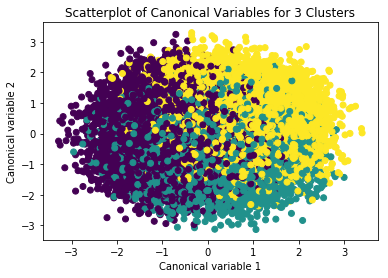
from sklearn.decomposition import PCA # CA from PCA function
pca_2 = PCA(2) # return 2 first canonical variables
plot_columns = pca_2.fit_transform(clus_train) # fit CA to the train dataset
plt.scatter(x=plot_columns[:,0], y=plot_columns[:,1], c=model3.labels_,)
# plot 1st canonical variable on x axis, 2nd on y-axis
plt.xlabel('Canonical variable 1')
plt.ylabel('Canonical variable 2')
# plt.zlabel('Canonical variable 3')
plt.title('Scatterplot of Canonical Variables for 2 Clusters')
plt.show()
Summary
In this blog, we implemented k-means clustering on poker hand dataset. Also, we understood about cluster analysis and different techniques in it. All the in-depth information was not covered in this blog, as it has been written for folks who are starting to explore data clustering in data science. Happy learning!!
Sifting through very large amounts of data for useful information. Data mining uses artificial intelligence techniques, neural networks, and advanced statistical tools. It reveals trends, patterns, and relationships, which might otherwise have remained undetected. In contrast to an expert system, data mining attempts to discover hidden rules underlying the data. Also called data surfing.
In this blog, we will be presenting a comprehensive detail about data mining. Additionally, this blog will help you to get into the details of data mining. Furthermore, it will help you to get the complete picture in one place!
What is Data Mining?
Data mining is not a new concept but a proven technology that has transpired as a key decision-making factor in business. There are numerous use cases and case studies, proving the capabilities of data mining and analysis. Yet, we have witnessed many implementation failures in this field, which can be attributed to technical challenges or capabilities, misplaced business priorities and even clouded business objectives. While some implementations battle through the above challenges, some fail in delivering the right data insights or their usefulness to the business. This article will guide you through guidelines for successfully implementing data mining projects.
Also, data mining is the process of uncovering patterns inside large sets of structured data to predict future outcomes. Structured data is data that is organized into columns and rows so that they can be accessed and modified efficiently. Using a wide range of machine learning algorithms, you can use data mining approaches for a wide variety of use cases to increase revenues, reduce costs, and avoid risks.
Also, at its core, data mining consists of two primary functions, description, for interpretation of a large database and prediction, which corresponds to finding insights such as patterns or relationships from known values. Before deciding on data mining techniques or tools, it is important to understand the business objectives or the value creation using data analysis. The blend of business understanding with technical capabilities is pivotal in making big data projects successful and valuable to its stakeholders.
Different Methods of Data Mining
Data mining commonly involves four classes of tasks [1]: (1) classification, arranges the data into predefined groups; (2) clustering, is like classification but the groups are not predefined, so the algorithm will try to group similar items together; (3) regression, attempting to find a function which models the data with the least error; and (4) association rule learning, searching for relationships between variables.
1. Association
Association is one of the best-known data mining technique. In association, a pattern is discovered based on a relationship between items in the same transaction. That’s is the reason why the association technique is also known as relation technique. The association technique is used in market basket analysis to identify a set of products that customers frequently purchase together.
Retailers are using association technique to research customer’s buying habits. Based on historical sale data, retailers might find out that customers always buy crisps when they buy beers, and, therefore, they can put beers and crisps next to each other to save time for the customer and increase sales.
2. Classification
Classification is a classic data mining technique based on machine learning. Basically, classification is used to classify each item in a set of data into one of a predefined set of classes or groups. Classification method makes use of mathematical techniques such as decision trees, linear programming, neural network, and statistics. In classification, we develop the software that can learn how to classify the data items into groups. For example, we can apply classification in the application that “given all records of employees who left the company, predict who will probably leave the company in a future period.” In this case, we divide the records of employees into two groups named “leave” and “stay”. And then we can ask our data mining software to classify the employees into separate groups.
3. Clustering
Clustering is a data mining technique that makes a meaningful or useful cluster of objects. These objects have similar characteristics using the automatic technique. Furthermore, the clustering technique defines the classes and puts objects in each class. But classification techniques, assignes objects into known classes. To make the concept clearer, we can take book management in the library as an example. In a library, there is a wide range of books on various topics available. The challenge is how to keep those books in a way that readers can take several books on a particular topic without hassle. By using the clustering technique, we can keep books that have some kinds of similarities in one cluster or one shelf and label it with a meaningful name.
4. Regression
In statistical terms, a regression analysis is a process of identifying and analyzing the relationship among variables. it can help you understand the characteristic value of the dependent variable changes if any one of the independent variables is varied. this means one variable is dependent on another, but it is not vice versa.it is generally used for prediction and forecasting.
Data Mining Process and Tools
The Cross-Industry Standard Process for Data Mining (CRISP-DM) is a conceptual tool that exists as a standard approach to data mining. The process outlines six phases:
Business understanding
Data understanding
Data preparation
Modelling
Evaluation
Deployment
The first two phases, business understanding and data understanding, are both preliminary activities. It is important to first define what you would like to know and what questions you would like to answer and then make sure that your data is centralized, reliable, accurate, and complete.
Once you’ve defined what you want to know and gathered your data, it’s time to prepare your data — this is where you can start to use data mining tools. Data mining software can assist in data preparation, modelling, evaluation, and deployment. Data preparation includes activities like joining or reducing data sets, handling missing data, etc.
The modelling phase in data mining is when you use a mathematical algorithm to find a pattern(s) that may be present in the data. This pattern is a model that can be applied to new data. Data mining algorithms, at a high level, fall into two categories — supervised learning algorithms and unsupervised learning algorithms. Supervised learning algorithms require a known output, sometimes called a label or target. Supervised learning algorithms include Naïve Bayes, Decision Tree, Neural Networks, SVMs, Logistic Regression, etc. Unsupervised learning algorithms do not require a predefined set of outputs but rather look for patterns or trends without any label or target. These algorithms include k-Means Clustering, Anomaly Detection, and Association Mining.
Data evaluation is the phase that will tell you how good or bad your model is. Cross-validation and testing for false positives are examples of evaluation techniques available in data mining tools. The deployment phase is the point at which you start using the results.
Importance of Data Mining
1. Marketing / Retail
Data mining helps marketing companies build models based on historical data to predict who will respond to the new marketing campaigns such as direct mail, online marketing campaign…etc. Through the results, marketers will have an appropriate approach to selling profitable products to targeted customers.
Data mining brings a lot of benefits to retail companies in the same way as marketing. Through market basket analysis, a store can have an appropriate production arrangement in a way that customers can buy frequent buying products together with pleasant. In addition, it also helps retail companies offer certain discounts for particular products that will attract more customers.
2. Finance / Banking
Data mining gives financial institutions information about loan information and credit reporting. By building a model from historical customer’s data, the bank, and financial institution can determine good and bad loans. In addition, data mining helps banks detect fraudulent credit card transactions to protect the credit card’s owner.
3. Manufacturing
By applying data mining in operational engineering data, manufacturers can detect faulty equipment and determine optimal control parameters. For example, semiconductor manufacturers have a challenge that even the conditions of manufacturing environments at different wafer production plants are similar, the quality of wafer are a lot the same and some for unknown reasons even has defects. Also, data mining has been applying to determine the ranges of control parameters that lead to the production of the golden wafer.
4. Governments
Data mining helps government agency by digging and analyzing records of the financial transaction to build patterns that can detect money laundering or criminal activities.
Applications of Data Mining
There are approximately 100,000 genes in the human body. Each gene is composed of hundreds of individual nucleotides which are arranged in a particular order. Ways of these nucleotides being ordered and sequenced are infinite to form distinct genes. Data mining technology can be used to analyze the sequential pattern. You can use it to search similarity and to identify particular gene sequences. In the future, data mining technology will play a vital role in the development of new pharmaceuticals. Also, it may provide advances in cancer therapies.
Financial data collected in the banking and financial industry is often relatively complete, reliable, and of high quality. This facilitates systematic data analysis and data mining. Typical cases include classification and clustering of customers for targeted marketing. It can also include detection of money laundering and other financial crimes. Furthermore, we can look into the design and construction of data warehouses for multidimensional data analysis.
The retail industry is a major application area for data mining since it collects huge amounts of data on customer shopping history, consumption, and sales and service records. Data mining on retail is able to identify customer buying habits, to discover customer purchasing pattern and to predict customer consuming trends. This technology helps design effective goods transportation, distribution policies, and less business cost.
Also, data mining in the telecommunication industry can help understand the business involved, identify telecommunication patterns, catch fraudulent activities, make better use of resources and improve service quality. Moreover, the typical cases include multidimensional analysis of telecommunication data, fraudulent pattern analysis and the identification of unusual patterns as well as multidimensional association and sequential pattern analysis.
Summary
The more data you collect…the more value you can deliver. And the more value you can deliver…the more revenue you can generate.
Data mining is what will help you do that. So, if you are sitting on loads of customer data and not doing anything with it…I want to encourage you to make a plan to start diving into it this week. Do it yourself or hire someone else…whatever it takes. Your bottom line will thank you.
Always query yourself how are you bringing value to your business with data mining!
Recommender systems use algorithms to provide users with product or service recommendations. Recently, these systems have been using machine learning algorithms from the field of artificial intelligence. An increasing number of online companies are utilizing recommendation systems to increase user interaction and enrich shopping potential. Use cases of recommendation systems have been expanding rapidly. They across many aspects of eCommerce and online media, and we expect this trend to continue.
Recommendation systems (often called “recommendation engines”) have the potential to change the way websites communicate with users. They allow companies to maximize their ROI based on the information they have on each customer’s preferences and purchases.
In this article, we will be looking upon machine learning methods which provide the personalized experiences. This matters most to the customers on different websites and end-consumers of the different business lines
What is Machine Learning?
Before we begin our journey of understanding how machine learning enhances personalization across various businesses, let us try to get a little idea about machine learning first. Machine learning mainly focuses on the development of computer programs which can teach themselves to grow and change when exposed to new data. Machine learning studies algorithms for self-learning to do stuff. It can process massive data faster with the learning algorithm.
Data is growing day by day, and it is impossible to understand all of the data with higher speed and higher accuracy. More than 80% of the data is unstructured that is audios, videos, photos, documents, graphs, etc. Finding patterns in data on planet earth is impossible for human brains. The data has been very massive and the time taken to compute would increase only. This is where Machine Learning comes into action, to help people with significant data in minimum time.
ML methods for personalization
In this section, we will introduce you to different techniques in machine learning that can help in the personalization of your business services for your end user. User experience and conversion(eventually) are the prime goals of a business. The following algorithms are the means which will help you in achieving personalization
Regression
Regression analysis is a form of predictive modeling technique which investigates the relationship between a dependent and independent variable. Regression(linear) aims at finding a straight line which can accurately depict the actual relationship between the two variables.
Regression can help finance and investment professionals as well as professionals in other businesses. Regression can help predict sales for a company based on weather, previous sales, GDP growth or other conditions. The capital asset pricing model (CAPM) is an often-used regression model in finance for pricing assets and discovering costs of capital. The general form of each type of regression is:
Linear Regression: Y = a + bX + u
Where:
Y = the variable that you are trying to predict (dependent variable)
X = the variable that you are using to predict Y (independent variable)
a = the intercept
b = the slope
u = the regression residual
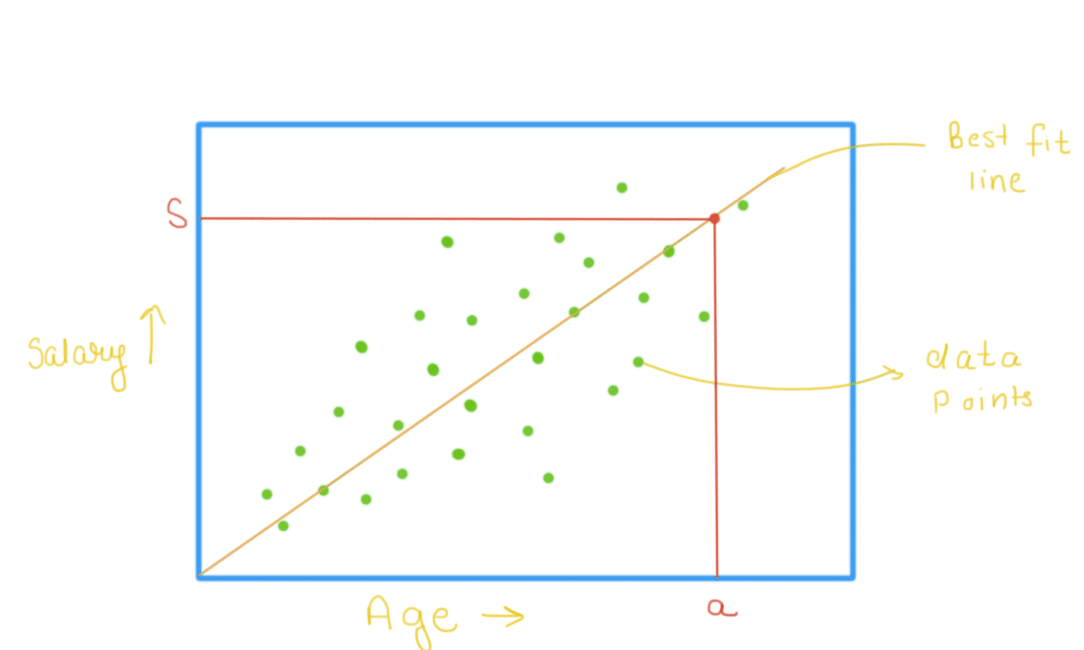
Let us take one example here. A firm X is trying to predict the salary of individuals using their age as the deciding parameter. One can plot all the available data points and find out a “best-fit line” which will describe the relationship between your age and salary parameter. In the following picture, green dots are all the available data points and the straight line passing through these points is the best fit line. Using this line, we can make predictions of salary for the other customers. Say we want to predict the salary of a person with age a. Using the best fit line, we will look at the corresponding value of salary when age is a(given parameter). Using such predictions, businesses like retail can offer different products(based on pricing) to different customers in personalizing their experience on the platform
Classifiers
In machine learning and statistics, classification is an important supervised learning approach in which the computer program learns from the data input given to it and then uses this learning to classify new observation. This data set may simply be bi-class (like identifying whether the person is male or female or that the mail is spam or non-spam) or it may be multi-class too. Some examples of classification problems are speech recognition, handwriting recognition, biometric identification, document classification etc.
K-Nearest Neighbors is one of the most basic yet essential classification algorithms in Machine Learning. It belongs to the supervised learning domain and finds intense application in pattern recognition, data mining and intrusion detection.
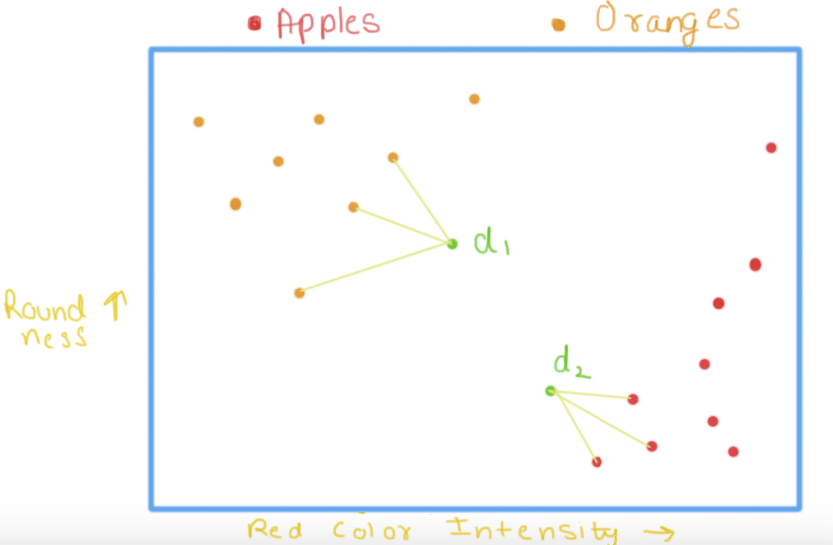
Let us take an illustration here. Suppose you want to classify apples from oranges. Our data contains 2 parameters i.e. roundness of fruit and intensity of the red color of the fruit. We then proceed to plot them. As we can see, the upper left corner contains the oranges(one with less red color intensity and more roundness) and lower right contain all the data points that represent an apple. Suppose we have a fruit whose roundness and red color intensity we know, say d1 and d2. We check the nearest neighbors of d1 and d2 and assign the class accordingly to the new data points. Nearest points to d1 are all oranges hence d1 is classified as an orange and closest points to d2 are all apples hence d2 is classified as apple.
Classification techniques are used when we have a set of predefined classes for personalization scheme. Suppose we want to classify customers on the basis of movie categories they watch on Netflix to provide movie recommendations from that particular genre, then classification techniques come really handy!
Clustering Methods
Clustering is one of the most important unsupervised learning problems; so, like every other problem of this kind, it deals with finding a structure in a collection of unlabeled data.
A loose definition of clustering could be “the process of organizing objects into groups whose members are similar in some way”.
A cluster is, therefore, a collection of objects which are “similar” between them and are “dissimilar” to the objects belonging to other clusters.
The goal of clustering is to determine the intrinsic grouping in a set of unlabeled data. But how to decide what constitutes a good clustering? It can be shown that there is no absolute “best” criterion which would be independent of the final aim of the clustering. Consequently, it is the user which must supply this criterion, in such a way that the result of the clustering will suit their needs.
For instance, we might need to find representatives for homogeneous groups (data reduction), in finding “natural clusters” and describe their unknown properties (“natural” data types), in finding useful and suitable groupings (“useful” data classes) or in finding unusual data objects (outlier detection).
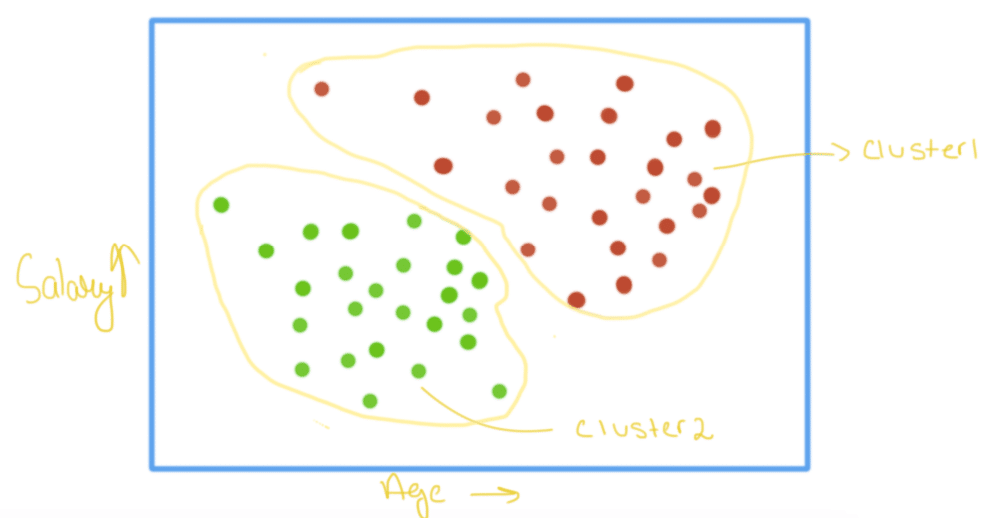
Given below is an age vs salary plot, where we can identify two sets of individuals in the data. One set is those who are younger in age and purchased the new budget smartphone whereas another cluster represents the people who are much more mature and earning high salaries but didn’t buy the product. It was easily inferred that the product was hit among the younger generation with income falling in the middle-class level
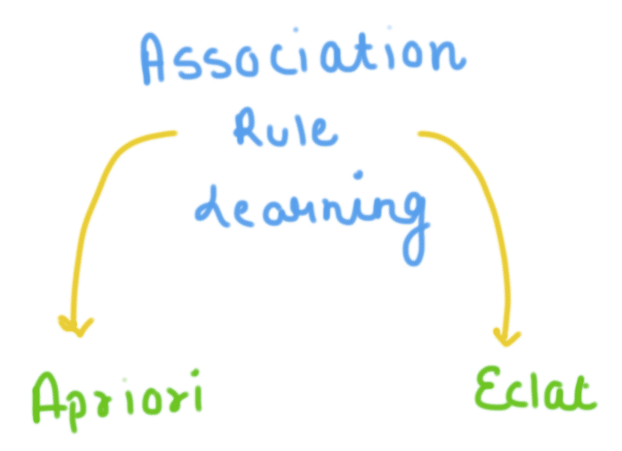
Association Rule Learning Methods
In basic terms, association rules present relations between items. They are statements that help to discover relationships between data in a database. An association rule is an implication of the form A → B. Here ‘A’ is a premise, which represents a condition that must be true for ‘B’ to hold. ‘B’ is a conclusion that happens when ‘A’ is true. An antecedent is an element found in data whereas a consequent is found in combination with the antecedent.
It is a popular technique for uncovering interesting relationships between different variables in huge databases. The association rules are suitable to build recommendation engines, like those of Amazon or Netflix. Simply put, this method allows one to thoroughly analyze the items bought by different users. With this analysis, one can easily find relations between them
To understand the strength of associations among these transactions, the algorithm uses various metrics:
Support helps to choose from billions of records only the most important and interesting itemsets for further analysis. You can set a specific condition here, for example, analyze itemsets that occur 40 times out of 12,000 transactions.
Confidence tells us how likely a consequent is when the antecedent has occurred. Example — how likely it is for a user to buy a biography book of Agassi when they’ve already bought that of Sampras.
Lift controls the consequent frequency to avoid a negative dependence or a substitution effect. The rule may show a high confidence value for products that have a weak association. The lift considerst the support of both antecedent and consequent to calculate the conditional probability and avoid fluke.
Reinforcement Methods
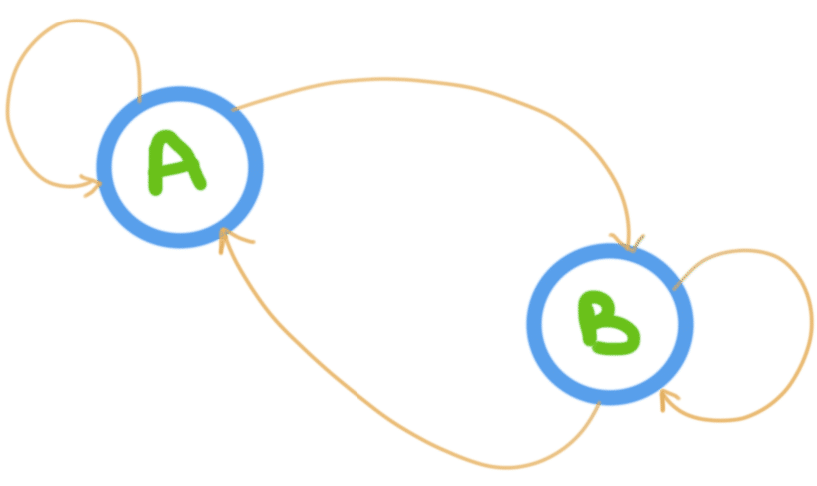
A Markov chain is a mathematical system that experiences transitions from one state to another according to certain probabilistic rules. The defining characteristic of a Markov chain is that no matter how the process arrived at its present state, the possible future states are fixed. In other words, the probability of transitioning to any particular state is dependent solely on the current state and time elapsed. The state space, or set of all possible states, can be anything: letters, numbers, weather conditions, baseball scores, or stock performances.
Markov chains are similar as finite state machines, and random walks provide a prolific example of their usefulness in mathematics. They arise broadly in statistical and information-theoretical contexts. Their application lies in economics, game theory, queueing (communication) theory, genetics, and finance. While it is possible to discuss Markov chains with any size of state space, the initial theory and most applications should focus on cases with a finite (or countably infinite) number of states.
Considering the fact that Markov chains make use of just real-time data without taking into account historical information, this method is not one-size-fits-all. An example of a good use case is PageRank, Google’s algorithm that determines the order of search results.
However, when building, for instance, an AI-driven recommendation engine, you’ll have to combine Markov chains with other ML methods, including the above-mentioned ones. To wit, Netflix uses a slew of ML approaches to providing users with hyper-personalized offerings.
Conclusion
In this blog, we looked at different techniques in ML through which one can provide personalization to end users of their respective businesses. Consumers are connecting with brands via multiple channels, which means retailers must do more to drive customer loyalty. Marketing teams need to harness actionable insights from the multiple data channels available to them to create engaging and relevant conversations with the customers. The more personalized the experience, the happier the customer.