Data visualization is an important component of many company approaches due to the growing information quantity and its significance to the company. In this blog, we will be understanding in detail about visualisation in Big Data. Furthermore, we will be looking into the areas like why visualisation in big data is a tedious task or are there any tools available for visualising Big Data
What is Data Visualisation?
Data display represents data in a systematic manner, including information unit characteristics and variables. Data discovery techniques based on visualization enable company consumers to generate customized analytical opinions using disparate information sources. Advanced analytics can be incorporated into techniques for the development on desktop and laptop or mobile devices like tablets and smartphones of interactive and animated Graphics.
What is Big Data Visualisation?
Big data are large volumes, elevated speed and/or high-speed information sets that involve fresh types of handling to optimize processes, discover understanding and make choices. Data capture, storage, evaluation, sharing, searches and visualization face great challenges for big data. Visualization could be considered as “large information front end. There’s no data visualization myth.
It is important to visualize only excellent information: an easy and fast view can show something incorrect with information just like it helps to detect exciting patterns.
Visualization always manifests the correct choice or intervention: visualization is not a substitute for critical thinking.
Visualization brings assurance: data are displayed, not showing an exact image of what is essential. Visualization with various impacts can be manipulated.
Tables, diagrams, pictures and other intuitive display methods to represent the information are created using visualization methods. Visualizing large information is not as simple as conventional tiny information sets. The expansion of traditional methods to visualization was already evolved but far enough. Many scientists use feature extraction and geometrical modeling in large-scale data visualization to significantly decrease the volume of information before real information processing. When viewing big data, it is also very essential to select the correct representation of information.
Problems in Visualising Big Data
In the visual analysis, scalability and dynamics are two main difficulties. The visualization of big data (structured or unstructured) with diversity and heterogeneity is a big difficulty. For big data analysis, speed is the required variable. Big information does not make it simple to design a fresh visualization tool with effective indexing. In order to improve the handling of Big Data scalability factors that influence information viewing decisions, cloud computing, and the sophisticated graphical user interface can be combined with Big Data.
Unstructured information formats such as charts, lists, text, trees, and other information must be used by visualization schemes. Often large information has unstructured formats. Due to the constraints on bandwidth and power consumption, visualization should step nearer to the data to effectively obtain significant information. The software for visualization should be executed on location. Due to the large volume of the information, visualization requires huge parallelisation. The difficulty in simultaneous viewing algorithms is to break down an issue into autonomous functions that can be carried out at the same time.
There are also the following problems for big data visualization:
Visual noise: Most items on the dataset are too related to each other. There are also the following issues when viewing large-scale information. Users can not split them on the display as distinct items.
Info loss: Visible data sets may be reduced, but information loss may occur.
Broad perception of images: data display techniques are restricted not only by aspect ratio and device resolution but also by physical perception limitations.
The elevated pace of changes in the picture: users view information and are unable to respond to the amount of changes in information or its intensity.
High-performance requirements: In static visualization it is hard to notice because of reduced demands for display velocity— high performance demands.
Choice of visualization factors
Audience: The information depiction should be adjusted to the target audience. If clients are ending up in a fitness application and are looking at advancement, then simplicity is essential. On the other side, when information ideas are for scientists or seasoned decision-makers, you can and should often go beyond easy diagrams.
Satisfaction: The data type determines the strategies. For instance, when there are metrics that change over the moment, the dynamics will most likely be shown with line graphs. You will use a dispersion plot to demonstrate the connection between two components. Bar diagrams are ideal for comparison assessment, in turn.
Context: The way your graphs appear can be taken with distinct methods and therefore read according to the framework. For instance, you may want to use colors of one color to highlight a certain figure, which is a major profit increase relative to other years, and choose a shiny one as the most important component on the graph. Instead, contrast colors are used to distinguish components.
Dynamics: Dynamics. Data are distinct and each means a distinct pace of shift. For example, each month or year the financial results can be measured while time series and data tracking change continuously. Dynamic representation (steaming) or a static visualization can be considered, depending on the type of change.
Objective: The objective of viewing the information also has a major effect on the manner in which it is carried out. Visualizations are built into dashboards with checks and filters to carry out a complicated study of a scheme or merge distinct kinds of information for a deeper perspective. Dashboards are, however, not required to display one or more occasional information.
Visualization Techniques for Big Data
1. Word Clouds
Word clouds work easy: the larger and bolder the word is in the term cloud the more a particular word is displayed in a source of text information (such as a lecture, newspaper post or database).
Here is an instance of USA Today using the United States. State of Union Speech 2012 by President Barack Obama:
As you can see, words like “American,” “jobs,” “energy” and “every” stand out since they were used more frequently in the original text.
Now, compare that to the 2014 State of the Union address:
You can easily see the similarities and differences between the two speeches at a glance. “America” and “Americans” are still major words, but “help,” “work,” and “new” are more prominent than in 2012.
2. Symbol Maps
Symbol maps are merely maps shown over a certain length and latitude. You can rapidly create a strong visual with the “Marks” card at Tableau, which tells customers of their place information. You can also use the information to manage the form of the label on the map using the illustration in the Pie chart or forms for a different degree of detail.
These maps can be as simple or as complex as you need them to be
3. Line charts
Alternatively known as a row graph, a row graph is a graph of the information shown using a number of rows. Line diagrams show rows horizontally through the diagram, with the scores axis on the left hand of the diagram. An instance of a line chart displaying distinctive Computer Hope travelers can be seen in the image below.
As can be seen in this example, you can easily see the increases and decreases each year over different years.
4. Pie charts
A diagram is a circular diagram, split into sections like wedges, which shows the amount. The complete valuation of each coin is 100% and is a proportional portion of the whole.
The portion size can easily be understood on a look at pie charts. They are commonly used to demonstrate the proportion of expenditure, population sections or study responses across a big number of classifications.
5. Bar Charts
A bar graph is a visual instrument which utilizes bars to match information between cities. bars are also called a bar chart or bar diagram. A bar chart can be executed horizontally or vertically. What we need to understand is that the longer the bar is, the more valuable it is. Two axes are the bar graphs. The horizontal axis (or x-axis) is shown on a graph of the vertical bar, as shown above. They are years in this instance. The vertical axis is the magnitude. The information sequence is the colored rows.
Bar charts have three main attributes:
A bar character allows for a simple comparison of information sets among distinct organizations.
The graph shows classes on one axis and on the other a separate value. The objective is to demonstrate the connection between the two axes.
Bar diagrams can also display over moment large information modifications.
6. Heat Maps
A heat map represents information that are displayed two-dimensionally by color values. An instant visual overview of the data is provided by a straightforward heat chart.
There can be numerous methods to show thermal maps, but they all share one thing in common: to transmit interactions between information values in a tablet, they use a color that would be much difficult to comprehend.
Visualisation Tools for Big Data
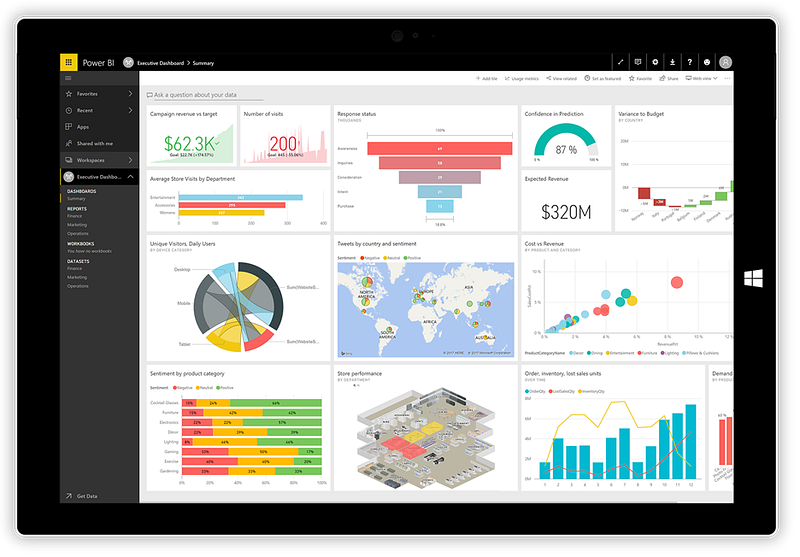
1. Power BI
Power BI is a company analysis option that enables you to view and share your information or integrate them into your app or blog. Connect to hundreds of information sources and live dashboards and accounts to take your information to life.
Microsoft Power BI is used to discover perspectives into the information of an organization. Power BI can communicate, convert and wash information into the data model and generate chart or diagram to display information graphics. All this can be communicated within the organisation with other consumers of Power BI.
Data models generated by Power BI can be used by organizations in many ways, including story telling through charts and views of data and “what if” scenarios inside the data. Power BI accounts can also respond to issues in real time and assist predict how departments will fulfill company criteria.
The Power BI can also provide executives or executives with corporate dashboards to provide them with an understanding of the agencies.
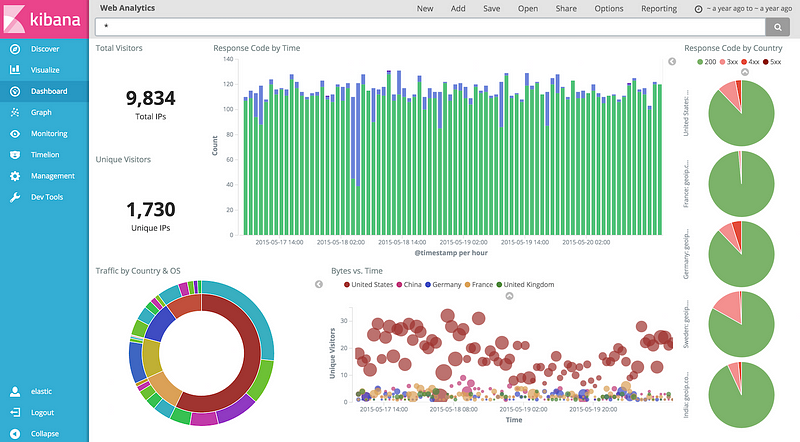
2. Kibana
Kibana is an open-source log analysis and time series analysis information visualization and exploring device for the surveillance of applications and operational intelligence instances. It provides strong and easy-to-use characteristics like histograms, diagrams, pie charts, thermal maps and integrated geospatial assistance. In addition, it ensures close inclusion with the famous analytics and search engine Elasticsearch, which makes Kibana the main option for viewing the information saved in Elasticsearch.
Kibana has been intended with Elasticsearch to render large and complicated information flows understandable by visual depiction more rapidly and smoothly. Elasticsearch analytics provide both information and improved aggregation mathematical transformations. The application produces a versatile, vibrant dashboard with PDF records on request or on timetable. The generated documents can depict information with customisable colors and highlighted search outcomes in the form of bar, row, scatter plot and paste graph sizes. Kibana also involves visualized data sharing instruments.
3. Grafana
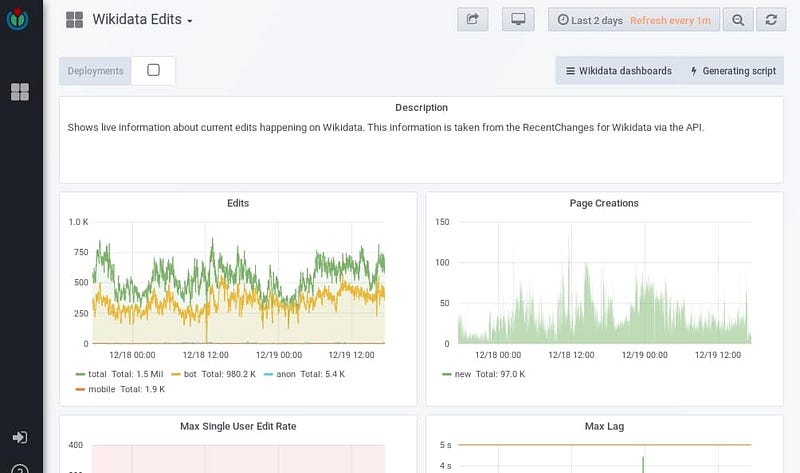
Grafana is a metrics & visualizing package of open source analysis. It is used most frequently for moment serial data visualization for infrastructure and implementation analysis, but many use it in other areas including agricultural equipment, domestic automation, climate, and process control.
Grafana is a temporary information sequence display instrument. A graphical description can be obtained from a lot of gathered information of the position of a business or organisation. How are they doing it? The collaborative editing of Wikidata, an extensive database of information, that increasingly builds papers in Wikipedia, utilizes the grafana.wikimedia.org to demonstrate openly (in our situation we do so on a regular basis) the publishings conducted out by associates and computers, in a certain span of moment produced and edited’ websites,’ or information sheets:
4. Tableau
Tableau has been utilized in the business intelligence industry as a strong and rapidly increasing information vision instrument. It makes it readily understandable to simplify raw information.
Data analysis with Tableau is very quick and the visualizations are in the shape of dashboards and tablets. The information produced using Tableau can be comprehended at every stage in an organisation by the specialist. It even enables a non-technical user a personalized dashboard to be created.
The best feature Tableau are
Data Blending
Real-time analysis
Collaboration of data
Tableau software is fantastic because it does not require any technical or programming abilities to function. The instrument has attracted individuals from all sectors, such as company, scientists, various industries, etc.
Summary
Static or vibrant visualizations can be interactive viewing often results in discovery and works better than static information instruments. Interactive views can assist you to get an overview of big data. The scientific method can be facilitated by interactive brushing and connecting visualisation methods to networks or web-based instruments. The web-based display enables to ensure dynamic data is kept up to date and updated.
There is not sufficient room for extending some standard visualization methods to manage big data. More fresh Big Data viewing techniques and instruments for various Big Data apps should be created
Exploratory Data Analysis or EDA is that stage of Data Handling where the Data is intensely studied and the myriad limits are explored. EDA literally helps to unfold the mystery behind such data which might not make sense at first glance. However, with detailed analysis, we can use the same data to provide miraculous results which can help boost large scale business decisions with excellent accuracy. This not only helps business conglomerations to evade likely pitfalls in the future but also helps them to leverage from the best possible schemes that might emerge in the near future.
EDA employs three primary statistical techniques to go about this exploration:
Univariate Analysis
Bivariate Analysis
Multivariate Analysis
Univariate, as the name suggests, means ‘one variable’ and studies one variable at a time to help us formulate conclusions such as follows:
Outlier detection
Concentrated points
Pattern recognition
Required transformations
In order to understand these points, we will take up the iris dataset which is furnished by fundamental python libraries like scikit-learn.
The iris dataset is a very simple dataset and consists of just 4 specifications of iris flowers: sepal length and width, petal length and width (all in centimeters). The objective of this dataset is to identify the type of iris plant a flower belongs to. There are three such categories: Iris Setosa, Iris Versicolour, Iris Virginica).
So let’s dig right in then!
1. Description Based Analysis
The purpose of this stage is to get an initial idea about each variable independently. This helps to identify the irregularities and probable patterns in the variables. Python’s inbuilt panda’s library helps to execute this task with extreme ease by literally using just one line of code.
Code:
data = datasets.load_iris()
The iris dataset is in dictionary format and thus, needs to be changed to data frame format so that the panda’s library can be leveraged.
We will store the independent variables in ‘X’. ‘data’ will be extracted and converted as follows:
X = data[‘data’] #extract
X = pd.DataFrame(X) #convert
On conversion to the required format, we just need to run the following code to get the desired information:
X.describe() #One simple line to get the entire description for every column
Output:
Count refers to the number of records under each column.
Mean gives the average of all the samples combined. Also, it is important to note that the mean gets highly affected by outliers and skewed data and we will soon be seeing how to detect skewed data just with the help of the above information.
Std or Standard Deviation is the measure of the “spread” of data in simple terms. With the help of std we can understand if a variable has values populated closely around the mean or if they are distributed over a wide range.
Min and Max give the minimum and maximum values of the columns across all records/samples.
25%, 50%, and 75% constitute the most interesting bit of the description. The percentiles refer to the respective percentage of records which behave a certain way. It can be interpreted in the following way:
25% of the flowers have sepal length equal to or less than 5.1 cm.
50% of the flowers have a sepal width equal to or less than 3.0 cm and so on.
50% is also interpreted as the median of the variable. It represents the data present centrally in the variable. For example, if a variable has values in the range 1 and 100 and its median is 80, it would mean that a lot of data points are inclined towards a higher value. In simpler terms, 50% or half of the data points have values greater than or equal to 80.
Now that the performance of mean and median is demonstrated, from the behavior of these numbers, one can conclude if the data is skewed. If the difference is high, it suggests that the distribution is skewed and if it is almost negligible, it is indicative of a normal distribution.
These options work well with continuous variables like the ones mentioned above. However, for categorical variables which have distinct values, such a description seldom makes any sense. For instance, the mean of a categorical variable would barely be of any value.
For such cases, we use yet another pandas operation called ‘value_counts()’. The usability of this function can be demonstrated through our target variable ‘y’. y was extracted in the following manner:
y = data[‘target’] #extract
This is done since the iris dataset is in dictionary format and stores the target variable in a list corresponding to the key named as ‘target’. After the extraction is completed, convert the data into a pandas Series. This must be done as the function value_counts() is only applicable to pandas Series.
y = pd.Series(y) #convert
y.value_counts()
On applying the function, we get the following result:
Output:
2 50
1 50
0 50
dtype: int64
This means that the categories, ‘0’, ‘1’ and ‘2’ have an equal number of counts which is 50. The equal representation means that there will be minimum bias during training. For example, if data tends to have more records representing one particular category ‘A’, the training model used will tend to learn that the category ‘A’ is the most recurrent and will have the tendency to predict a record as record ‘A’. When unequal representations are found, any one of the following must be followed:
Gather more data
Generate samples
Eliminate samples
Now let us move on to visual techniques to analyze the same data, but reveal further hidden patterns!
2. Visualization Based Analysis
Even though a descriptive analysis is highly informative, it does not quite furnish details with regard to the pattern that might arise in the variable. With the difference between the mean and median we may be able to figure out the presence of skewed data, but will not be able to pinpoint the exact reason owing to this skewness. This is where visualizations come into the picture and aid us to formulate solutions for the myriad patterns that might arise in the variables independently.
Lets start with observing the frequency distribution of sepal width in our dataset.
Std: 0.435 Mean: 3.057 Median (50%): 3.000
The red dashed line represents the median and the black dashed line represents the mean. As you must have observed, the standard deviation in this variable is the least. Also, the difference between the mean and the median is not significant. This means that the data points are concentrated towards the median, and the distribution is not skewed. In other words, it is a nearly Gaussian (or normal) distribution. This is how a Gaussian distribution looks like:
Normal Distribution generated from random data
The data of the above distribution is generated through the random. The normal function of the numpy library (one of the python libraries to handle arrays and lists).
It must always be one’s aim to achieve a Gaussian distribution before applying modeling algorithms. This is because, as has been studied, the most recurrent distribution in real life scenarios is the Gaussian curve. This has led to the designing of algorithms over the years in such a way that they mostly cater to this distribution and assume beforehand that the data will follow a Gaussian trend. The solution to handle this is to transform the distribution accordingly.
Let us visualize the other variables and understand what the distributions mean.
Sepal Length:
Std: 0.828 Mean: 5.843 Median: 5.80
As is visible, the distribution of Sepal Length is over a wide range of values (4.3cm to 7.9cm) and thus, the standard deviation for sepal length is higher than that of sepal width. Also, the mean and median have almost an insignificant difference between them. This clarifies that the data is not skewed. However, here visualization comes to great use because we can clearly see that distribution is not perfectly Gaussian since the tails of the distribution have ample data. In Gaussian distribution, approximately 5% of the data is present in the tailing regions. From this visualization, however, we can be sure that the data is not skewed.
Petal Length:
Std: 1.765 Mean: 3.758 Median: 4.350
This is a very interesting graph since we found an unexpected gap in the distribution. This can either mean that the data is missing or the feature does not apply to that missing value. In other words, the petal lengths of iris plants never have the length in the range 2 to 3! The mean is thus, justifiably inclined towards the left and the median shows the centralized value of the variable which is towards the right since most of the data points are concentrated in a Gaussian curve towards the right. If you move on to the next visual and observe the pattern of petal width, you will come across an even more interesting revelation.
Petal Width:
std: 0.762 mean: 1.122 median: 1.3
In the case of Petal Width, most of the values in the same region as in the petal length diagram, relative to the frequency distribution, are missing. Here the values in the range 0.5 cm to 1.0 cm are almost absent (but not completely absent). A repetitive low value simultaneously in the same area corresponding to two different frequency distributions is indicative of the fact that the data is missing and also confirmatory of the fact that petals of the size of the missing values are present in nature, but went unrecorded.
This conclusion can be followed with further data gathering or one can simply continue to work with the limited data present since it is not always possible to gather data representing every element of a given subject.
Conclusively, using histograms we came to know about the following:
Data distribution/pattern
Skewed distribution or not
Missing data
Now with the help of another univariate analysis tool, we can find out if our data is inlaid with anomalies or outliers. Outliers are data points which do not follow the usual pattern and have unpredictable behavior. Let us find out how to find outliers with the help of simple visualizations!
We will use a plot called the Box plot to identify the features/columns which are inlaid with outliers.
Box Plot for Iris Dataset
The box plot is a visual representation of five important aspects of a variable, namely:
Minimum
Lower Quartile
Median
Upper Quartile
Maximum
As can be seen from the above graph, each variable is divided into four parts using three horizontal lines. Each section contains approximately 25% of the data. The area enclosed by the box is 50% of the data which is located centrally and the horizontal green line represents the median. One can identify an outlier if the point is spotted beyond the max and min lines.
From the plot, we can say that sepal_width has outlying points. These points can be handled in two ways:
Discard the outliers
Study the outliers separately
Sometimes outliers are imperative bits of information, especially in cases where anomaly detection is a major concern. For instance, during the detection of fraudulent credit card behavior, detection of outliers is all that matters.
Conclusion
Overall, EDA is a very important step and requires lots of creativity and domain knowledge to dig up maximum patterns from available data. Keep following this space to know more about bi-variate and multivariate analysis techniques. It only gets interesting from here on!
Visualizing the data is important as it makes it easier to understand large amount of complex data using charts and graphs than studying documents and reports. It helps the decision makers to grasp difficult concepts, identify new patterns and get a daily or intra-daily view of their performance. Due to the benefits it possess, and the rapid growth in analytics industry, businesses are increasingly using data visualizations; which can be assessed from the prediction that the data visualization market is expected to grow annually by 9.47% to $7.76 billion by 2023 from $4.51 billion in 2017.
R is a programming language and a software environment for statistical computing and graphics. It offers inbuilt functions and libraries to present data in the form of visualizations. It excels in both basic and advanced visualizations using minimum coding and produces high quality graphs on large datasets.
This article will demonstrate the use of its packages ggplot2 and plotly to create visualizations such as scatter plot, boxplot, histogram, line graphs, 3D plots and Maps.
1. ggplot2
#install package ggplot2
install.packages("ggplot2")
#load the package
library(ggplot2)
There are a lot of datasets available in R in package ‘datasets’, you can run the command data() to list those datasets and use any dataset to work upon. Here I have used the dataset named ‘economics’ which gives the monthly U.S. data of various economic variables like unemployment for the time period 1967-2015.
You can view the data using view function-
view(economics)
Scatter Plot
We’ll make a simple scatter plot to view how unemployment has fluctuated over the years by using plot function-
plot(x = economics$date, y = economics$unemploy)
ggplot() is used to initialize the ggplot object which can be used to declare the input dataframe and set of plot aesthetics. We can add geom components to it that acts as its layer and are used to specify the plot’s features.
We would use its feature geom point which is used to create scatter plots.
ggplot(data = economics, aes(x = date , y = unemploy)) + geom_point()
Modifying Plots
We can modify the plot like its color, shape, size etc. using geom_point aesthetics.
ggplot(data = economics, aes(x = date , y = unemploy)) + geom_point(size = 3)
Lets view the graph by modifying its color-
ggplot(data = economics, aes(x = date , y = unemploy)) + geom_point(size = 3, color = "blue")
Boxplot
Boxplot is a method of graphically depicting groups of numerical data through their quartiles. a geom boxplot layer of ggplot is used to create boxplot of the data.
ggplot(data = economics, aes(x = date , y = unemploy)) + geom_boxplot()
When there is overplotting, one or more points are in the same place and we can’t tell by looking at the plot that how many points are there. In that case, we can use the jitter geom which adds a small amount of variation to the location of each point that is it slightly moves the point, which is used to spread out the points that would otherwise be overplotted.
ggplot(data = economics, aes(x = date , y = unemploy)) +
geom_jitter(alpha = 0.5, color = "red") + geom_boxplot(alpha = 0)
Line Graph
We can view the data in the form of a line graph as well using geom_line.
To change the names of the axis and to give a title to the graph, use labs feature-
ggplot(data = economics, aes(x = date, y = unemploy)) + geom_line()
+ labs(title = "Number of unemployed people in U.S.A. from 1967 to 2015",
x = "Year", y = "Number of unemployed people")
Let’s group the data according to year and view how average unemployment fluctuated through these years.
We will load dplyr package to manipulate our data and lubridate package to work with date column.
library(dplyr)
library(lubridate)
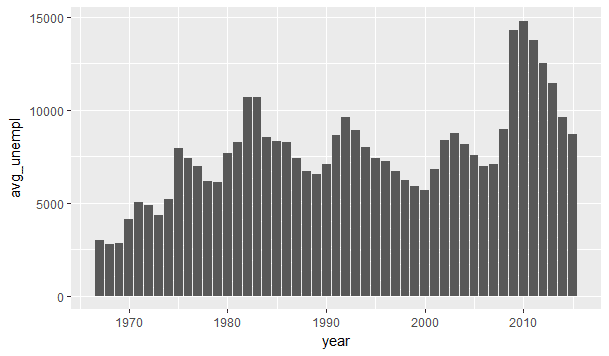
Now we will use mutate function to create a column year from the date column given in economics dataset by using the year function of lubridate package. And then we will group the data according to year and summarise it according to average unemployment-
Now, lets view the data as a line plot using line geom of ggplot2
ggplot(data = economics_update, aes(x = year , y = avg_unempl)) + geom_bar(stat = “identity”)
(Since here we want the height of the bar be equal to avg_unempl, so we need to specify stat equal to identity)
This graph shows the average unemployment in each year
Plotting Time Series Data
In this section, I’ll be using a dataset that records the number of tourists who visited India from 2001 to 2015 which I have rearranged such that it has 3 columns, country, year and number of tourists arrived.
To visualize the plot of the number of tourists that visited the countries over the years in the form of line graph, we use geom_line-
Unfortunately, we get this graph which looks weird because we have plotted all the countries data together.
So, we group the graph by country by specifying it in aesthetics-
ggplot(data = tourist1, aes(x = year, y = number_tourist, group = Country)) + geom_line()
This graph is showing the country wise line graph which shows the trend of a number of tourists arrived from these countries over the years.
To better view the graph that distinguishes countries and is bigger in size, we can specify color and size-
ggplot(data = tourist1, aes(x = year, y = number_tourist, group = Country,
color = Country)) + geom_line(size = 1)
Faceting
Faceting is a feature in ggplot which enables us to split one plot into multiple plots based on some factor. We can use it to visualize one-time series for each factor separately-
ggplot(data = tourist1, aes(x = year, y = number_tourist, group =
Country, color = Country)) + geom_line(size = 1) + facet_wrap(~Country)
For convenience purpose, you can change the theme of the background as well, here I am keeping the theme as white-
ggplot(data = tourist1, aes(x = year, y = number_tourist,
group = Country, color = Country)) + geom_line(size = 1) +
facet_wrap(~Country) + theme_bw()
These were some basic functions of ggplot2, for more functions, check out the official guide.
2. Plotly
Plotly is deemed to be one of the best data visualization tools in the industry.
Line graph
Lets construct a simple line graph of two vectors by using plot_ly function that initiates a visualization in plotly. Since we are creating a line graph, we have to specify type as ‘scatter’ and mode as ‘lines’.
plot_ly(x = c(1,2,3), y = c(10,20,30), type = "scatter", mode = "lines")
Now let’s create a line graph using the economics dataset that we used earlier-
plot_ly(x = economics$date, y = economics$unemploy, type = "scatter", mode = "lines")
Now, we’ll use the dataset ‘women’ that is available in R which records the average height and weight of American women.
Scatter Plot
Now lets create a scatter plot for which we need to specify mode as ‘markers’ –
plot_ly(x = women$height, y = women$weight, type = "scatter", mode = "markers")
Bar Chart
Now, to create a bar chart, we need to specify the type as ‘bar’.
plot_ly(x = women$height, y = women$weight, type = "bar")
Histogram
To create a histogram in plotly, we need to specify the type as ‘histogram’ in plot_ly.
1. Normal distribution
Let x follow a normal distribution with n=200
X < -rnorm(200)
We then plot this normal distribution in histogram,
plot_ly(x = x, type = "histogram")
Since its a normally distributed data, so the shape of this histogram is bell-shaped.
2. Chi-Square Distribution
Let y follow a chi square distribution with n = 200 and df = 4,
y = rchisq(200, 4)
Then, we construct a histogram of y-
plot_ly(x = y, type = "histogram")
This histogram represents a chi square distribution, so it is positively skewed
Boxplot
We will build a boxplot of a normally distributed data, fr that we need to specify the type as ‘box’.
plot_ly(x = rnorm(200, 0, 1), type = "box")
here x follows a normal distribution with mean 0 and sd 1,
So in this box plot, the median is at 0 as in normal distribution, median is equal to mean.
Adding Traces
We can add multiple traces to the plot using pipelines and add_trace feature-
plot_ly(x = iris$Sepal.Length, y = iris$Sepal.Width,
type = "scatter", mode = "markers")%>%
add_trace(x = iris$Petal.Length, y = iris$Petal.Width)
Now let’s construct two boxplots from two normally distributed datasets, one with mean 0 and other with mean 1-
Now, let’s modify the size and color of the plot, since the mode is a marker, so we would specify the marker as a list with the modifications that we require.
plot_ly(x = women$height, y = women$weight, type = "scatter",
mode = "markers", marker = list(size = 10, color = "red"))
We can modify points individually as well if we know the number of points in the graph-
We can modify the plot using the layout function as well which allows us to customize the x-axis and y-axis. We can specify the modifications in the form of a list-
plot_ly(x = women$height, y = women$weight, type = "scatter", mode = "markers",
marker = list(size = 10, color = "red"))%>%
layout(title = "scatter plot", xaxis = list(showline = T, title = "Height"),
yaxis = list(showline = T, title = "Weight"))
Here, we have given a title to the graph and the x-axis and y-axis as well. Also, we have the X-axis line and Y-axis line
Let’s say we want to distinguish the points in the plot according to a factor-
plot_ly(x = iris$Sepal.Length, y = iris$Sepal.Width, type = "scatter",
color = ~iris$Species, colors = "Set1")
here, if we don’t specify the mode, it will set the mode to ‘markers’ by default
Mapping Data to Symbols
We can map the data into differentiated symbols so that we can view the graph better for different factors-
plot_ly(x = iris$Sepal.Length, y = iris$Sepal.Width, type = "scatter",
mode = “markers”, symbol = ~iris$Species)
here, the points pertaining to 3 factors are distinguished by symbols that R assigned to it.
We can customize the symbols as well-
plot_ly(x = iris$Sepal.Length, y = iris$Sepal.Width, type = "scatter",
mode = “makers”, symbol = ~iris$Species, symbols = c("circle", "x", "o"))
3D Line Plot
We can construct a 3D plot as well by specifying it in type. Here we are constructing a 3D line plot-
plot_ly(x = c(1,2,3), y = c(2,4,6), z = c(3,6,9), type = "scatter3d",
mode = "lines")
Map Visualization
We can visualize map as well by specifying in type as ‘scattergeo’. Since its a map, so we need to specify lattitude and longitude.
plot_ly(lon = c(40, 50), lat = c(10, 20), type = "scattergeo", mode = "markers")
We can modify the map as well. Here we have increased the size of the points and changed its color. We have also added text that is the location of the point which would show the location name when the cursor is placed on it.
plot_ly(lon = c(-95, 80), lat = c(30, 20), type = "scattergeo",
mode = "markers", size = 10, color = "Set2", text = c("U.S.A.", "India"))
These were some of the visualizations from package ggplot2 and plotly. R has various other packages for visualizations like graphics and lattice. Refer to the official documentation of R to know more about these packages.
To know more about our Data Science course, click below
Data science is a rapidly growing career path in the 21 century. The leaders across all industries, fields, and governments are putting their best minds to the task of harnessing the power of data.
As organizations seek to derive greater insights and to present their findings with greater clarity, the premium placed on high-quality data visualization will only continue to increase.
What are Data Visualisation tools?
Data visualization is a general term that describes an effort to help people understand the significance of data by placing it in a visual context. Patterns, trends and correlations that might go undetected in text-based data can be exposed and recognized easier with data visualization software.
Furthermore, today’s data visualization tools go beyond the standard charts and graphs used in Microsoft Excel spreadsheets, displaying data in more sophisticated ways such as infographics, dials and gauges, geographic maps, sparklines, heat maps, and detailed bar, pie and fever charts.
What is Tableau?
Tableau is a powerful and fastest growing data visualization tool used in the Business Intelligence Industry. It helps in simplifying raw data into the very easily understandable format.
Also, data analysis is very fast with Tableau and the visualizations created are in the form of dashboards and worksheets. The data that is created using Tableau can be understood by professional at any level in an organization. Furthermore, It even allows a non-technical user to create a customized dashboard.
Why Tableau?
1. Tableau makes interacting with your data easy
Tableau is a very effective tool to create interactive data visualizations very quickly. It is very simple and user-friendly. Tableau can create complex graphs giving a similar feel as the pivot table graphs in Excel. Moreover, it can handle a lot more data and quickly provide calculations on datasets.
2. Extensive Data analytics
Tableau allows the user to plot varied graphs which can help in making detailed data visualisations. There are 21 different types of graph among which users can mix match and dish out appealing and informative visualisations. From heat maps, pie chart and bar charts to bubbe graph, Gantt chart and bullet graphs, Tableau has way more lot of visualisations to offer than other data visualisations tool out there
3. Easy Data discovery
Tableau is capable of handling large datasets really well. Handling large dataset is one problem where tools like MS Excel and even R shiny fails to generate visualisation dashboards. Ability to handle such large chunks of data empowers tableau to generate insights out of it. This, in turn, allows users to find patterns and trends in their data. Furthermore, tableau can be connected to multiple data sources be it different cloud providers or databases or data warehouses.
4. No Coding
The one great thing about tableau is that you do not need to code at all to generate powerful and meaningful visualisations. It is all a game of selecting a chart and drag and drop! Being user-friendly allows the user to focus more on visualisations and storytelling through it rather than handling all the coding aspects around it.
5. Huge Community
Tableau boasts of a large user community which works for solving doubts and problems faced while using Tableau. Having such large community support helps users to find answers to their queries and issues faced while using Tableau. One does not need to worry about having less learning material too.
6. Proved to have satisfied customers
Tableau users are genuinely happy with the product. For example, the yearly Gartner research about Business Intelligence and Analytics Platforms, based on the user feedback, indicates Tableau´s success and ability to deliver a genuinely user-friendly solution for the customers. We have noticed the same enthusiasm and positive feedback about Tableau among our customers.
7. Mobile support
Tableau provides mobile support for the dashboards. So you do not need to confine to just desktop and laptops but can develop visualisations on the fly using Tableau
Tableau in fortune 500 companies
LinkedIn
LinkedIn has over 460 million users. The business analytics team of LinkedIn’s salesforce is massively using Tableau to process petabytes of customer data. They access Tableau server on a weekly basis by 90% of LinkedIn’s salesforce. Furthermore, sales analytics can measure performance and gauge the churn using Tableau dashboards. Higher revenue, therefore, results due to a more proactive sales cycle. Michael Li, Senior Director of Business Analytics at LinkedIn believes that LinkedIn’s analytics portal is the go-to destination for salespeople to get what they require to convey that information that is exactly required by the clients.
Cisco
Cisco uses Tableau software to work with 14,000 items to evaluate Product Demand Variability, match distribution centres with customers, depict the flow of goods through the supply chain network, assess the location and spend within the supply chain. Tableau strikes a balance of a sophisticated network of suppliers to the end customer. This looks after inventory and reduces order-to-ship cycle. Also, Cisco uses Tableau server to spread the content gracefully. It helps to create the right message, streamline the data, drive the conception and also in the scaling of data.
Deloitte
Deloitte uses Tableau to help customers implement self-reliant data-driven culture which is also agile which can garner high business value from enterprise data. Higher signal detection abilities and real-time interactive dashboards are available to an enterprise by Deloitte that allow their clients to assess huge complex datasets with high efficiency and greater ease of use. Furthermore, there are more than 5000 Deloitte employees who are trained in Tableau and are successfully delivering high-end projects.
Walmart
Walmart considers it was a good move shifting to rich vivid visualizations that can be modified in real time and shared easily from Excel sheets. Furthermore, they found that people responded better when there is more creativity, the presentation would turn to be good, and executives receive it better. Rather than a datasheet, Tableau is used to convey data story more effectively. Also, they had built dashboards which could be accessible to the entire organization. Over 5000 systems have Tableau desktop in Walmart and it is doing great with this BI tool.
Conclusion
After reading this list we hope you are ready to conquer the world of data with Tableau. To help you to just do it, we offer data science courses including Tableau. Also, you can view the course here.
Additionally, if you are interested in learning Big Data and NLP, click here to get started
Furthermore, if you want to read more about data science, you can read our blogs here
Also, the following are some suggested blogs you may like to read
What if I say that there is a way for you to become a data scientist, regardless of your programming skills! Furthermore, most people think that being proficient in a programming knowledge is a must-have for becoming a data scientist. Well, this statement is not completely true! Data science is not all about programming anymore.
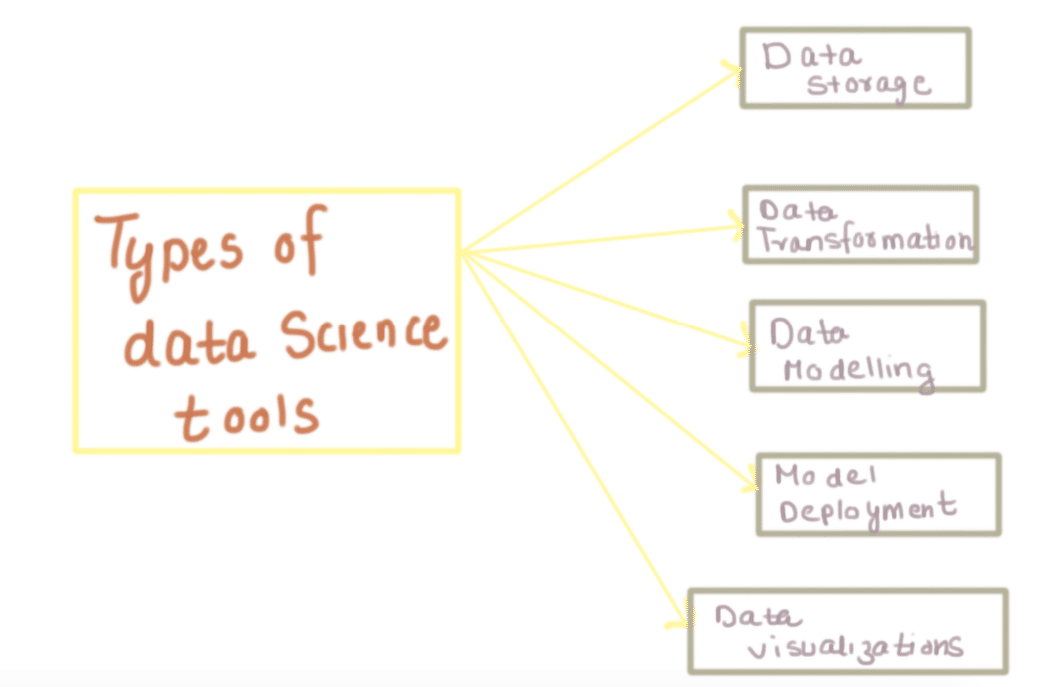
In this article, we will be looking at different tools for data scientists. Different tools cover different aspects of data science, hence data scientists can make their work easy by employing these tools for different tasks. Let us understand more about these tools in detail.
What are data science tools?
These are tools that typically obviate the programming aspect and provide user-friendly GUI (Graphical User Interface) hence anyone with minimal knowledge of algorithms can simply use them to build high-quality machine learning models.
Many companies (especially startups) have recently launched GUI driven data science tools. These tools cover different aspects of data science like data storage, data manipulation, data modeling etc.
Why data science tools?
No programming experience required
Better work management
Faster results
Better quality check mechanism
Process Uniformity
Different Data science tools
Data Storage
1. Apache Hadoop
Apache Hadoop is a java based free software framework that can effectively store a large amount of data in a cluster. This framework runs in parallel on a cluster. Hence, it has the ability to allow us to process data across all nodes. Also, Hadoop Distributed File System (HDFS) is the storage system of Hadoop which splits big data and distribute across many nodes in a cluster. This also replicates data in a cluster thus providing high availability.
2. Microsoft HDInsight
It is a Big Data solution from Microsoft powered by Apache Hadoop which is available as a service in the cloud. HDInsight uses Windows Azure Blob storage as the default file system. Also, this also provides high availability with low cost.
3. NoSQL
While the traditional SQL can be effectively used to handle a large amount of structured data, we need NoSQL (Not Only SQL) to handle unstructured data. Also, NoSQL databases store unstructured data with no particular schema. Furthermore, each row can have its own set of column values. Hence, NoSQL gives better performance in storing a massive amount of data. There are many open-source NoSQL DBs available to analyze Big Data.
4. Hive
This is a distributed data management for Hadoop. Also, this supports SQL-like query option HiveSQL (HSQL) to access big data. This can be primarily used for Data mining purpose. Furthermore, this runs on top of Hadoop.
5. Sqoop
This is a tool that connects Hadoop with various relational databases to transfer data. This can be effectively used to transfer structured data to Hadoop or Hive.
6. PolyBase
This works on top of SQL Server 2012 Parallel Data Warehouse (PDW) and is used to access data stored in PDW. Furthermore, PDW is a data warehousing appliance built for processing any volume of relational data and provides integration with Hadoop allowing us to access non-relational data as well.
Data transformation
1. Informatica — PowerCenter
Informatica is a leader in Enterprise Cloud Data Management with more than 500 global partners and more than 1 trillion transactions per month. It is a software Development Company that was found in 1993 with its headquarters in California, United States. In addition, It has a revenue of $1.05 billion and a total employee headcount of around 4,000.
PowerCenter is a product which was developed by Informatica for data integration. It supports data integration lifecycle and also delivers critical data and values to the business. Furthermore, PowerCenter supports a huge volume of data and any data type and any source for data integration.
2. IBM — Infosphere Information Server
IBM is a multinational Software Company found in 1911 with its headquarters in New York, U.S. and it has offices across more than 170 countries. It has a revenue of $79.91 billion as of 2016 and total employees currently working are 380,000.
Infosphere Information Server is a product by IBM that was developed in 2008. It is a leader in the data integration platform which helps to understand and deliver critical values to the business. It is mainly designed for Big Data companies and large-scale enterprises.
3. Oracle Data Integrator
Oracle is an American multinational company with its headquarters in California and was found in 1977. It has a revenue of $37.72 billion as of 2017 and a total employee headcount of 138,000.
Oracle Data Integrator (ODI) is a graphical environment to build and manage data integration. This product is suitable for large organizations which have frequent migration requirement. It is a comprehensive data integration platform which supports high volume data, SOA enabled data services.
Key Features:
Oracle Data Integrator is a commercial licensed RTL tool.
Improves user experience with re-design of flow based interface.
It supports declarative design approach for data transformation and integration process.
Faster and simpler development and maintenance.
4. AB Initio
Ab Initio is an American private enterprise Software Company in Massachusetts, USA. It has offices worldwide in the UK, Japan, France, Poland, Germany, Singapore and Australia. Ab Initio specialises in application integration and high volume data processing.
It contains six data processing products such as Co>Operating System, The Component Library, Graphical Development Environment, Enterprise Meta>Environment, Data Profiler, and Conduct>It. “Ab Initio Co>Operating System” is a GUI based ETL tool with a drag and drop feature.
Key Features:
Ab Initio has a commercial license and a most costlier tool in the market.
The basic features of Ab Initio are easy to learn.
Ab Initio Co>Operating system provides a general engine for data processing and communication between rest of the tools.
Ab Initio products are provided on a user-friendly platform for parallel data processing applications.
5. Clover ETL
CloverETL, by a company named Javlin, with offices across the globe like USA, Germany, and the UK provides services like data processing and data integration.
In addition, CloverETL is a high-performance data transformation and robust data integration platform. Therefore, It can process a huge volume of data and transfers the data to various destinations. Also, it consists of three packages such as — CloverETL Engine, CloverETL Designer, and CloverETL Server.
Key Features:
CloverETL is a commercial ETL software.
CloverETL has a Java-based framework.
Easy to install and simple user interface.
Combines business data in a single format from various sources.
It also supports Windows, Linux, Solaris, AIX and OSX platforms.
It is for data transformation, data migration, data warehousing and data cleansing.
Modelling Tools
1. Infosys Nia
Infosys Nia is a knowledge-based AI platform, built by Infosys in 2017 to collect and aggregate organisational data from people, processes and legacy systems into a self-learning knowledge base.
It is to tackle difficult business tasks such as forecasting revenues and what products need to be built, understanding customer behaviour and more.
Infosys Nia enables businesses to manage customer inquiries easily, with a secure order-to-cash process with risk awareness delivered in real-time.
2. H20 Driverless
H2O is an open source software tool, consisting of a machine learning platform for businesses and developers.
H2O.ai is in the Java, Python and R programming languages. The platform is built with the languages with which developers are familiar with in order to make it easy for them to apply machine learning and predictive analytics.
Also, H2O can analyze datasets in the cloud and Apache Hadoop file systems. It is available on Linux, MacOS and Microsoft Windows operating systems.
3. Eclipse Deep learning 4j
Eclipse Deeplearning4j is an open-source deep-learning library for the Java Virtual Machine. It can serve as a DIY tool for Java, Scala and Clojure programmers working on Hadoop and other file systems. It also allows developers to configure deep neural networks and is suitable for use in business environments on distributed GPUs and CPUs.
The project, by a San Francisco company called Skymind, offers paid support, training and enterprise distribution of Deeplearning4j.
4. Torch
Torch is a scientific computing framework, an open source machine learning library and a scripting language over the Lua programming language. It also provides an array of algorithms for deep machine learning. Furthermore, the torch is used by the Facebook AI Research Group and was previously used by DeepMind before it was acquired by Google and moved to TensorFlow.
5. IBM Watson
IBM is a big player in the field of AI, with its Watson platform housing an array of tools designed for both developers and business users.
Available as a set of open APIs, Watson users will have access to lots of sample code, starter kits and can build cognitive search engines and virtual agents.
Watson also has a chatbot building platform aimed at beginners, which requires little machine learning skills. Watson will even provide pre-trained content for chatbots to make training the bot much quicker.
Model Deployment
1. ML Flow
MLflow is an open source platform for managing the end-to-end machine learning lifecycle. It tackles three primary functions:
Tracking experiments to record and compare parameters and results (MLflow Tracking).
Packaging ML code in a reusable, reproducible form in order to share with other data scientists or transfer to production (MLflow Projects).
Managing and deploying models from a variety of ML libraries to a variety of model serving and inference platforms (MLflow Models).
MLflow is library-agnostic. Also, you can use it with any machine learning library, and in any programming language, since all functions are accessible through a REST API and CLI. For convenience, the project also includes a Python API, R API, and Java API.2. Kubeflow
2. Kubeflow
The Kubeflow project is for making deployments of machine learning (ML) workflows on Kubernetes simple, portable and scalable. The goal is not to recreate other services, but also to provide a straightforward way to deploy best-of-breed open-source systems for ML to diverse infrastructures.
The basic workflow is:
Download the Kubeflow scripts and configuration files.
Customize the configuration.
Run the scripts to deploy your containers to your chosen environment.
In addition, you adapt the configuration to choose the platforms and services that you want to use for each stage of the ML workflow: data preparation, model training, prediction serving, and service management.
3. H20 AI
H2O is a fully open source, distributed in-memory machine learning platform with linear scalability. H2O’s supports the most widely used statistical & machine learning algorithms including gradient boosted machines, generalized linear models, deep learning and more. Also, H2O has an industry leading AutoML functionality that automatically runs through all the algorithms and their hyperparameters to produce a leaderboard of the best models. Furthermore, the H2O platform is used by over 14,000 organizations globally and is extremely popular in both the R & Python communities.
4. Domino Data Lab
Domino provides an open, unified data science platform to build, validate, deliver, and monitor models at scale. This accelerates research, sparks collaboration, increases iteration speed, and removes deployment friction to deliver impactful models.
5. Dataiku
Dataiku DSS is the collaborative data science software platform for teams of data scientists, data analysts, and engineers to explore, prototype, build and deliver their own data products more efficiently. Dataiku’s single, collaborative platform powers both self-service analytics and also the operationalization of machine learning models in production. Hence, in simple words, Data Science Studio (DSS) is a software platform that aggregates all the steps and big data tools necessary to get from raw data to production-ready applications. Furthermore, it shortens the load-prepare-test-deploy cycles required to create data-driven applications. Also, thanks to its visual and interactive workspace, it is accessible to both Data Scientists and Business Analysts
Data Visualisation
1. Tableau
One of the major tool in this category. Tableau is famous for his drag and drops features in User Interface. In addition, this data visualization tool is free for some basic versions. Also, it supports multi-format data like xls,csv, XML , database connections etc . Furthermore, for more information on Tableau, You can reach out at Tableau official website.
The Qlik view is again a powerful BI tool for decision making. In addition, It is easily configurable and Deployable. Also, it is scalable with few constraints of RAM. The most loving features of Qlik view is visual drill down. In case you want to read more about Qlik View, You can reach out Qlik View official website. Here you can find all installation guide with other details.
Another powerful tool from Qlik family. Its popularity is because of its user-friendly features like drag and drop. Also, it is designed in such a manner that even a business user can use it. Furthermore, its cloud-based infrastructure makes it strong among other data visualizations tool. You can download the free desktop version of Qlik Sense and use it.
SAS VA is not only a data visualization tool but also it is capable of predictive modeling and forecasting. It is easy to operate with drag and drop features. Also, there is awesome community support for SAS Visual Analytics. In addition, you can directly reach SAS Visual Analytics from here.
D3 is a javascript library. Furthermore, It is an open source library. You can use to bind arbitrary data with the Document Object Model. As it is an open source library so you can find a rich tutorial on D3.js. Also, here is the link for the home page of D3.js.
Conclusion
The success of any modern data analytics strategy depends on full access to all data. Solutions like above simplify and accelerate decision making from massive amounts of data from any data source. Furthermore, we can execute any machine learning models you’ve developed to deepen your knowledge of and engagement with your customers, or other important initiatives.
Whether you are a scientist, a developer or, simply, a data enthusiast, these tools provide features that can cover your every need.

































 This histogram represents a chi square distribution, so it is positively skewed
This histogram represents a chi square distribution, so it is positively skewed So in this box plot, the median is at 0 as in normal distribution, median is equal to mean.
So in this box plot, the median is at 0 as in normal distribution, median is equal to mean.