Reports suggest that around 2.5 quintillion bytes of data are generated every single day. As the online usage growth increases at a tremendous rate, there is a need for immediate Data Science professionals who can clean the data, obtain insights from it, visualize it, train model and eventually come up with solutions using Big data for the betterment of the world.
By 2020, experts predict that there will be more than 2.7 million data science and analytics jobs openings. Having a glimpse of the entire Data Science pipeline, it is definitely tiresome for a single human to perform and at the same time excel at all the levels. Hence, Data Science has a plethora of career options that require a spectrum set of skill sets.
Let us explore the top 5 data science career options in 2019 (In no particular order).
1. Data Scientist
Data Scientist is one of the ‘high demand’ job roles. The day to day responsibilities involves the examination of big data. As a result of the analysis of the big data, they also actively perform data cleaning and organize the big data. They are well aware of the machine learning algorithms and understand when to use the appropriate algorithm. During the due course of data analysis and the outcome of machine learning models, patterns are identified in order to solve the business statement.
The reason why this role is so crucial in any organisation is that the company tends to take business decisions with the help of the insights discovered by the Data Scientist to have an edge over the company’s competitors. It is to be noted that the Data Scientist role is inclined more towards the technical domain. As the role demands a wide range of skill set, Data Scientists are one among the highest paid jobs.
Core Skills of a Data Scientist
Communication
Business Awareness
Database and querying
Data warehousing solutions
Data visualization
Machine learning algorithms
2. Business Intelligence Developer
BI Developer is a job role inclined more towards the Non-Technical domain but has a fair share of Technical responsibilities as well (if required) as a part of their day to day responsibilities. BI developers are responsible for creating and implementing business policies as a result of the insights obtained from the Technical team.
Apart from being a policymaker involving the usage of dedicated (or custom) Business Intelligence analytics tools, they will also have a fair share of coding in order to explore the dataset, present the insights of the dataset in a non-verbal manner. They help in bridging the gap between the technical team that works with the deepest technical understanding and the clients that want the results in the most non-technical manner. They are expected to generate reports from the insights and make it ‘less technical’ for others in the organisation. It is noted that the BI Developers have a deep understanding of Business when compared to Data Scientist.
Core Skills of a Business Analytics Developer
Business model analysis
Data warehousing
Design of business workflow
Business Intelligence software integration
3. Machine Learning Engineer
Once the data is clean and ready for analysis, the machine learning engineers work on these big data to train a predictive model that predicts the target variable. These models are used to analyze the trends of the data in the future so that the organisation can take the right business decisions. As the dataset involved in a real-life scenario would involve a lot of dimensions, it is difficult for a human eye to interpret insights from it. This is one of the reasons for training machine learning algorithms as it easily deals with such complex dataset. These engineers carry out a number of tests and analyze the outcomes of the model.
The reason for conducting constant tests on the model using various samples is to test the accuracy of the developed model. Apart from the training models, they also perform exploratory data analysis sometimes in order to understand the dataset completely which will, in turn, help them in training better predictive models.
Core Skills of Machine Learning Engineers
Machine Learning Algorithms
Data Modelling and Evaluation
Software Engineering
4. Data Engineer
The pipeline of any data-oriented company begins with the collection of big data from numerous sources. That’s where the data engineers operate in any given project. These engineers integrate data from various sources and optimize them according to the problem statement. The work usually involves writing queries on big data for easy and smooth accessibility. Their day to day responsibility is to provide a streamlined flow of big data from various distributed systems. Data engineering differs from the other data science careers as in, it is concentrated on the system and hardware that aids the company’s data analysis, rather than the analysis of data itself. They provide the organisation with efficient warehousing methods as well.
Core Skills of Data Engineer
Database Knowledge
Data Warehousing
Machine Learning algorithm
5. Business Analyst
Business Analyst is one of the most essential roles in the Data Science field. These analysts are responsible for understanding the data and it’s related trend post the decision making about a particular product. They store a good amount of data about various domains of the organisation. These data are really important because if any product of the organisation fails, these analysts work on these big data to understand the reason behind the failure of the project. This type of analysis is vital for all the organisations as it makes them understand the loopholes in the company. The analysts not only backtrack the loophole and in turn provide solutions for the same making sure the organisation takes the right decision in the future. At times, the business analyst act as a bridge between the technical team and the rest of the working community.
Core skills of Business Analyst
Business awareness
Communication
Process Modelling
Conclusion
The data science career options mentioned above are in no particular order. In my opinion, every career option in Data Science field works complimentary with one another. In any data-driven organization, regardless of the salary, every career role is important at the respective stages in a project.
There are a huge number of ML algorithms out there. Trying to classify them leads to the distinction being made in types of the training procedure, applications, the latest advances, and some of the standard algorithms used by ML scientists in their daily work. There is a lot to cover, and we shall proceed as given in the following listing:
Statistical Algorithms
Classification
Regression
Clustering
Dimensionality Reduction
Ensemble Algorithms
Deep Learning
Reinforcement Learning
AutoML (Bonus)
1. Statistical Algorithms
Statistics is necessary for every machine learning expert. Hypothesis testing and confidence intervals are some of the many statistical concepts to know if you are a data scientist. Here, we consider here the phenomenon of overfitting. Basically, overfitting occurs when an ML model learns so many features of the training data set that the generalization capacity of the model on the test set takes a toss. The tradeoff between performance and overfitting is well illustrated by the following illustration:
Overfitting – from Wikipedia
Here, the black curve represents the performance of a classifier that has appropriately classified the dataset into two categories. Obviously, training the classifier was stopped at the right time in this instance. The green curve indicates what happens when we allow the training of the classifier to ‘overlearn the features’ in the training set. What happens is that we get an accuracy of 100%, but we lose out on performance on the test set because the test set will have a feature boundary that is usually similar but definitely not the same as the training set. This will result in a high error level when the classifier for the green curve is presented with new data. How can we prevent this?
Cross-Validation
Cross-Validation is the killer technique used to avoid overfitting. How does it work? A visual representation of the k-fold cross-validation process is given below:
From Quora
The entire dataset is split into equal subsets and the model is trained on all possible combinations of training and testing subsets that are possible as shown in the image above. Finally, the average of all the models is combined. The advantage of this is that this method eliminates sampling error, prevents overfitting, and accounts for bias. There are further variations of cross-validation like non-exhaustive cross-validation and nested k-fold cross validation (shown above). For more on cross-validation, visit the following link.
There are many more statistical algorithms that a data scientist has to know. Some examples include the chi-squared test, the Student’s t-test, how to calculate confidence intervals, how to interpret p-values, advanced probability theory, and many more. For more, please visit the excellent article given below:
Classification refers to the process of categorizing data input as a member of a target class. An example could be that we can classify customers into low-income, medium-income, and high-income depending upon their spending activity over a financial year. This knowledge can help us tailor the ads shown to them accurately when they come online and maximises the chance of a conversion or a sale. There are various types of classification like binary classification, multi-class classification, and various other variants. It is perhaps the most well known and most common of all data science algorithm categories. The algorithms that can be used for classification include:
Logistic Regression
Support Vector Machines
Linear Discriminant Analysis
K-Nearest Neighbours
Decision Trees
Random Forests
and many more. A short illustration of a binary classification visualization is given below:
From openclassroom.stanford.edu
For more information on classification algorithms, refer to the following excellent links:
Regression is similar to classification, and many algorithms used are similar (e.g. random forests). The difference is that while classification categorizes a data point, regression predicts a continuous real-number value. So classification works with classes while regression works with real numbers. And yes – many algorithms can be used for both classification and regression. Hence the presence of logistic regression in both lists. Some of the common algorithms used for regression are
Linear Regression
Support Vector Regression
Logistic Regression
Ridge Regression
Partial Least-Squares Regression
Non-Linear Regression
For more on regression, I suggest that you visit the following link for an excellent article:
Both articles have a remarkably clear discussion of the statistical theory that you need to know to understand regression and apply it to non-linear problems. They also have source code in Python and R that you can use.
4. Clustering
Clustering is an unsupervised learning algorithm category that divides the data set into groups depending upon common characteristics or common properties. A good example would be grouping the data set instances into categories automatically, the process being used would be any of several algorithms that we shall soon list. For this reason, clustering is sometimes known as automatic classification. It is also a critical part of exploratory data analysis (EDA). Some of the algorithms commonly used for clustering are:
Hierarchical Clustering – Agglomerative
Hierarchical Clustering – Divisive
K-Means Clustering
K-Nearest Neighbours Clustering
EM (Expectation Maximization) Clustering
Principal Components Analysis Clustering (PCA)
An example of a common clustering problem visualization is given below:
From Wikipedia
The above visualization clearly contains three clusters.
Another excellent article on clustering refer the link
Dimensionality Reduction is an extremely important tool that should be completely clear and lucid for any serious data scientist. Dimensionality Reduction is also referred to as feature selection or feature extraction. This means that the principal variables of the data set that contains the highest covariance with the output data are extracted and the features/variables that are not important are ignored. It is an essential part of EDA (Exploratory Data Analysis) and is nearly always used in every moderately or highly difficult problem. The advantages of dimensionality reduction are (from Wikipedia):
It reduces the time and storage space required.
Removal of multi-collinearity improves the interpretation of the parameters of the machine learning model.
It becomes easier to visualize the data when reduced to very low dimensions such as 2D or 3D.
It avoids the curse of dimensionality.
The most commonly used algorithm for dimensionality reduction is Principal Components Analysis or PCA. While this is a linear model, it can be converted to a non-linear model through a kernel trick similar to that used in a Support Vector Machine, in which case the technique is known as Kernel PCA. Thus, the algorithms commonly used are:
Ensembling means combining multiple ML learners together into one pipeline so that the combination of all the weak learners makes an ML application with higher accuracy than each learner taken separately. Intuitively, this makes sense, since the disadvantages of using one model would be offset by combining it with another model that does not suffer from this disadvantage. There are various algorithms used in ensembling machine learning models. The three common techniques usually employed in practice are:
Simple/Weighted Average/Voting: Simplest one, just takes the vote of models in Classification and average in Regression.
Bagging: We train models (same algorithm) in parallel for random sub-samples of data-set with replacement. Eventually, take an average/vote of obtained results.
Boosting: In this models are trained sequentially, where (n)th model uses the output of (n-1)th model and works on the limitation of the previous model, the process stops when result stops improving.
Stacking: We combine two or more than two models using another machine learning algorithm.
(from Amardeep Chauhan on Medium.com)
In all four cases, the combination of the different models ends up having the better performance that one single learner. One particular ensembling technique that has done extremely well on data science competitions on Kaggle is the GBRT model or the Gradient Boosted Regression Tree model.
We include the source code from the scikit-learn module for Gradient Boosted Regression Trees since this is one of the most popular ML models which can be used in competitions like Kaggle, HackerRank, and TopCoder.
GradientBoostingClassifier supports both binary and multi-class classification. The following example shows how to fit a gradient boosting classifier with 100 decision stumps as weak learners:
GradientBoostingRegressor supports a number of different loss functions for regression which can be specified via the argument loss; the default loss function for regression is least squares ('ls').
import numpy as np
from sklearn.metrics import mean_squared_error
from sklearn.datasets import make_friedman1
from sklearn.ensemble import GradientBoostingRegressor
X, y = make_friedman1(n_samples=1200, random_state=0, noise=1.0)
X_train, X_test = X[:200], X[200:]
y_train, y_test = y[:200], y[200:]
est = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1,
max_depth=1, random_state=0, loss='ls').fit(X_train, y_train)
mean_squared_error(y_test, est.predict(X_test))
You can also refer to the following article which discusses Random Forests, which is a (rather basic) ensembling method.
In the last decade, there has been a renaissance of sorts within the Machine Learning community worldwide. Since 2002, neural networks research had struck a dead end as the networks of layers would get stuck in local minima in the non-linear hyperspace of the energy landscape of a three layer network. Many thought that neural networks had outlived their usefulness. However, starting with Geoffrey Hinton in 2006, researchers found that adding multiple layers of neurons to a neural network created an energy landscape of such high dimensionality that local minima were statistically shown to be extremely unlikely to occur in practice. Today, in 2019, more than a decade of innovation later, this method of adding addition hidden layers of neurons to a neural network is the classical practice of the field known as deep learning.
Deep Learning has truly taken the computing world by storm and has been applied to nearly every field of computation, with great success. Now with advances in Computer Vision, Image Processing, Reinforcement Learning, and Evolutionary Computation, we have marvellous feats of technology like self-driving cars and self-learning expert systems that perform enormously complex tasks like playing the game of Go (not to be confused with the Go programming language). The main reason these feats are possible is the success of deep learning and reinforcement learning (more on the latter given in the next section below). Some of the important algorithms and applications that data scientists have to be aware of in deep learning are:
Long Short term Memories (LSTMs) for Natural Language Processing
Recurrent Neural Networks (RNNs) for Speech Recognition
Convolutional Neural Networks (CNNs) for Image Processing
Deep Neural Networks (DNNs) for Image Recognition and Classification
Hybrid Architectures for Recommender Systems
Autoencoders (ANNs) for Bioinformatics, Wearables, and Healthcare
Deep Learning Networks typically have millions of neurons and hundreds of millions of connections between neurons. Training such networks is such a computationally intensive task that now companies are turning to the 1) Cloud Computing Systems and 2) Graphical Processing Unit (GPU) Parallel High-Performance Processing Systems for their computational needs. It is now common to find hundreds of GPUs operating in parallel to train ridiculously high dimensional neural networks for amazing applications like dreaming during sleep and computer artistry and artistic creativity pleasing to our aesthetic senses.
Artistic Image Created By A Deep Learning Network. From blog.kadenze.com.
For more on Deep Learning, please visit the following links:
In the recent past and the last three years in particular, reinforcement learning has become remarkably famous for a number of achievements in cognition that were earlier thought to be limited to humans. Basically put, reinforcement learning deals with the ability of a computer to teach itself. We have the idea of a reward vs. penalty approach. The computer is given a scenario and ‘rewarded’ with points for correct behaviour and ‘penalties’ are imposed for wrong behaviour. The computer is provided with a problem formulated as a Markov Decision Process, or MDP. Some basic types of Reinforcement Learning algorithms to be aware of are (some extracts from Wikipedia):
1.Q-Learning
Q-Learning is a model-free reinforcement learning algorithm. The goal of Q-learning is to learn a policy, which tells an agent what action to take under what circumstances. It does not require a model (hence the connotation “model-free”) of the environment, and it can handle problems with stochastic transitions and rewards, without requiring adaptations. For any finite Markov decision process (FMDP), Q-learning finds a policy that is optimal in the sense that it maximizes the expected value of the total reward over any and all successive steps, starting from the current state. Q-learning can identify an optimal action-selection policy for any given FMDP, given infinite exploration time and a partly-random policy. “Q” names the function that returns the reward used to provide the reinforcement and can be said to stand for the “quality” of an action taken in a given state.
2.SARSA
State–action–reward–state–action (SARSA) is an algorithm for learning a Markov decision process policy. This name simply reflects the fact that the main function for updating the Q-value depends on the current state of the agent “S1“, the action the agent chooses “A1“, the reward “R” the agent gets for choosing this action, the state “S2” that the agent enters after taking that action, and finally the next action “A2” the agent choose in its new state. The acronym for the quintuple (st, at, rt, st+1, at+1) is SARSA.
3.Deep Reinforcement Learning
This approach extends reinforcement learning by using a deep neural network and without explicitly designing the state space. The work on learning ATARI games by Google DeepMind increased attention to deep reinforcement learning or end-to-end reinforcement learning. Remarkably, the computer agent DeepMind has achieved levels of skill higher than humans at playing computer games. Even a complex game like DOTA 2 was won by a deep reinforcement learning network based upon DeepMind and OpenAI Gym environments that beat human players 3-2 in a tournament of best of five matches.
For more information, go through the following links:
If reinforcement learning was cutting edge data science, AutoML is bleeding edge data science. AutoML (Automated Machine Learning) is a remarkable project that is open source and available on GitHub at the following link that, remarkably, uses an algorithm and a data analysis approach to construct an end-to-end data science project that does data-preprocessing, algorithm selection,hyperparameter tuning, cross-validation and algorithm optimization to completely automate the ML process into the hands of a computer. Amazingly, what this means is that now computers can handle the ML expertise that was earlier in the hands of a few limited ML practitioners and AI experts.
AutoML has found its way into Google TensorFlow through AutoKeras, Microsoft CNTK, and Google Cloud Platform, Microsoft Azure, and Amazon Web Services (AWS). Currently it is a premiere paid model for even a moderately sized dataset and is free only for tiny datasets. However, one entire process might take one to two or more days to execute completely. But at least, now the computer AI industry has come full circle. We now have computers so complex that they are taking the machine learning process out of the hands of the humans and creating models that are significantly more accurate and faster than the ones created by human beings!
The basic algorithm used by AutoML is Network Architecture Search and its variants, given below:
Network Architecture Search (NAS)
PNAS (Progressive NAS)
ENAS (Efficient NAS)
The functioning of AutoML is given by the following diagram:
If you’ve stayed with me till now, congratulations; you have learnt a lot of information and cutting edge technology that you must read up on, much, much more. You could start with the links in this article, and of course, Google is your best friend as a Machine Learning Practitioner. Enjoy machine learning!
Artificial Intelligence is growing at a rapid pace in the last decade. You have seen it all unfold before your eyes. From self-driving cars to Google Brain, artificial intelligence has been at the centre of these amazing huge-impact projects.
Artificial Intelligence (AI) made headlines recently when people started reporting that Alexa was laughing unexpectedly. Those news reports led to the usual jokes about computers taking over the world, but there’s nothing funny about considering AI as a career field. Just the fact that five out of six Americans use AI services in one form or another every day proves that this is a viable career option
Why AI?
Well, there can be many reasons for students selecting this as their career track or professionals changing their career track towards AI. Let us have a look at some of the points on discussing why AI!
Interesting and Exciting
AI offers applications in those domains which are challenging as well as exciting. Driverless cars, human behaviour prediction, chatbots etc are just a few examples, to begin with.
High Demand and Value
Lately, there has been a huge demand in the industry for the data scientists and AI specialists which has resulted in more jobs and higher value given at workplace
Well Paid
With high demand and loads of work to be done, this field is one of the well-paid career choices currently. In the era, when jobs were reducing and the market was saturating, AI has emerged as one of the most well-paid jobs
If you still have thoughts on why one should choose AI as their career then my answer will be as clear as the thought that “If you do not want AI to take your job, you have to take up AI”!
Level 0: Setting up the ground
If maths(too much) does not intimidate and furthermore you love to code, you can then only start looking at AI as your career. If you do enjoy optimizing algorithms and playing with maths or are passionate about it, Kudos! Level 0 is cleared and you are ready to start a career in AI.
Level 1: Treading into AI
At this stage, one should cover the basics first and when I say basics, it does not imply to get the knowledge of 4–5 concepts but indeed a lot of them(Quite a lot of them)
Cover Linear Algebra, Statistics, and ProbabilityMath is the first and foremost thing you need to cover. Start from the basics of math covering vectors, matrices, and their transformations. Then proceed to understand dimensionality, statistics and different statistical tests like z-test, chi-square tests etc. After this, you should focus on the concepts of probability like Bayes Theorem etc. Maths is the foundation step of understanding and building those complex AI algorithms which are making our life simpler!
Select a programming language
After learning and being profound in the basic maths, you need to select a programing language. I would rather suggest that you take up one or maximum two programming languages and understand it in depth. One can select from R, Python or even JAVA! Always remember, a programing language is just to make your life simpler and is not something which defines you. We can start with Python because it is abstract and provides a lot of libraries to work with. R is also evolving very fast so we can consider that too or else go with JAVA. (Only if we have a good CS background!)
Understand data structures
Try to understand the data structure i.e. how you can design a system for solving problems involving data. It will help you in designing a system which is accurate and optimized. AI is more about reaching an accurate and optimized result. Learn about the Stacks, linked lists, dictionaries and other data structures that your selected programing language has to offer
Understand Regression in complete detail
Well, this is one advice you will get from everyone. Regression is the basic implementation of maths which you have learned so far. It depicts how this knowledge can be used to make predictions in real-life applications. Having a strong grasp over regression will help you greatly in understanding the basics of machine learning. This will prepare you well for your AI career.
Move on to understand different Machine Learning models and their working
After learning regression, one should get their hands dirty with other legacy machine learning algorithms like Decision Trees, SVM, KNN, Random Forests etc. You should implement them over different problems in day to day life. One should know the working math behind every algorithm. Well, this may initially be little tough, but once you get going everything will fall in its place. Aim to be a master in AI and not just any random practitioner!
Understand the problems that machine learning solves
You should understand the use cases of different machine learning algorithms. Focus on why a certain algorithm fits one case more than the other. Then only then you will be able to appreciate the mathematical concepts which help in making any algorithm more suitable to a particular business need or a use case. Machine learning is itself divided into 3 broad categories i.e. Supervised Learning, Unsupervised Learning, and Reinforcement Learning. One needs to be better than average in all the 3 cases before you can actually step into the world of Deep Learning!
Level 2: Moving deeper into AI
This is level 2 of your journey/struggle to be an AI specialist. At this level, we deal with moving into Deep Learning but only when you have mastered the legacy of machine learning!
Understanding Neural Networks
A neural network is a type of machine learning which models itself after the human brain. This creates an artificial neural network that via an algorithm allows the computer to learn by incorporating new data. At this stage, you need to start your deep learning by understanding neural networks in great detail. You need to understand how these networks are intelligent and make decisions. Neural nets are the backbone of AI and you need to learn it thoroughly!
Unrolling the maths behind neural networks
Neural networks are typically organized in layers. Layers are made up of a number of interconnected ‘nodes’ which contain an ‘activation function’. Patterns are presented to the network via the ‘input layer’, which communicates to one or more ‘hidden layers’ where the actual processing is done via a system of weighted ‘connections’. The hidden layers then link to an ‘output layer’ where the answer is output. You need to learn about the maths which happens in the backend of it. Learn about weights, activation functions, loss reduction, backpropagation, gradient descent approach etc. These are some of the basic mathematical keywords used in neural networks. Having a strong knowledge of them will enable you to design your own networks. You will also actually understand from where and how neural network borrows its intelligence! It’s all maths mate.. all maths!
Mastering different types of neural networks
As we did in ML, that we learned regression first and then moved onto the other ML algos, same is the case here. Since you have learned all about basic neural networks, you are ready to explore the different types of neural networks which are suited for different use cases. Underlying maths may remain the same, the difference may lie in few modifications here and there and pre-processing of the data. Different types of Neural nets include Multilayer perceptrons, Recurrent Neural Nets, Convolutional Neural Nets, LSTMS etc
Understanding AI in different domains like NLP and Intelligent Systems
With knowledge of different neural networks, you are now better equipped to master the application of these networks to different applications in Business. You may need to build a driverless car module or a human-like chatbot or even an intelligent system which can interact with its surrounding and self-learn to carry out tasks. Different use cases require different approaches and different knowledge. Surely you can not master every field in AI as it is a very large field indeed hence I will suggest you pick up a single field in AI say Natural Language processing and work on getting the depth in that field. Once your knowledge has a good depth, then only you should think of expanding your knowledge across different domains
Getting familiar with the basics of Big Data
Although, acquiring the knowledge of Big Data is not a mandatory task but I will suggest you equip yourself with basics of Big Data because all your AI systems will be handling Big Data only and it will be a good plus to have basics of Big Data knowledge as it will help you in making more optimized and realistic algorithms
Level 3: Mastering AI
This is the final stage where you have to go all guns blazing and is the point where you need to learn less but apply more whatever you have learned till now!
Mastering Optimisation Techniques
Level 1 and 2 focus on achieving accuracy in your work but now we have to talk about optimizing it. Deep learning algorithms consume a lot of resources of the system and you need to optimize every part of it. Optimization algorithms help us to minimize (or maximize) an Objective function (another name for Error function) E(x) which is simply a mathematical function dependent on the Model’s internal learnable parameters. The internal parameters of a Model play a very important role in efficiently and effectively training a Model and produce accurate results. This is why we use various Optimization strategies and algorithms to update and calculate appropriate and optimum values of such model’s parameters which influence our Model’s learning process and the output of a Model.
Taking part in competitions
You should actually take part in hackathons and data science competitions on kaggle as it will enhance your knowledge more and will give you more opportunities to implement your knowledge
Publishing and Reading lot of Research Papers
Research — Implement — Innovate — Test. Keep repeating this cycle by reading on a lot of research papers related to AI. This will help you in understanding how you can just not be a practitioner but be an thrive to be an innovator. AI is still nascent and needs masters who can innovate and bring revolution to this field
Tweaking maths to roll out your own algorithms
Innovation needs a lot of research and knowledge. This is the final place where you want yourself to be to actually fiddle with the maths which powers this entire AI. Once you are able to master this art, you will be one step away in bringing a revolution!
Conclusion
Mastering AI is not something one can achieve in a short time. AI requires hard work, persistence, consistency, patience and a lot of knowledge indeed! It may be one of the hottest jobs in the industry currently. Being a practitioner or enthusiast in AI is not difficult but if you are looking at the being a master at this, one has to be as good as those who created it! It takes years and skill to be a master at anything and same is the case with AI. If you are motivated, nothing can stop you in this entire world. ( Not even an AI :P)
Are you intrigued by buzzwords Machine Learning and Deep learning but you have always found them to be ambiguous and often used interchangeably?
If yes, you are at right platform.
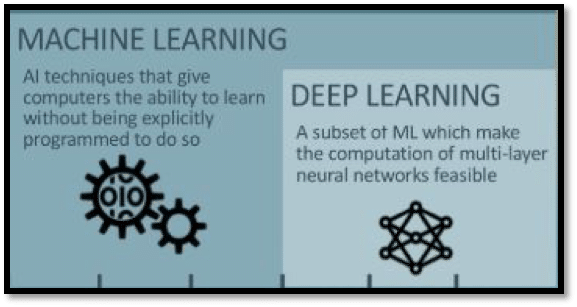
Let’s discuss the terms Machine Learning (ML) and Deep Learning (DL) and understand the subtle differences between them.
The formal definition of ML given by Arthur Samuel says “It provides computers with the capability to learn and take decisions without being explicitly programmed”.
Applications of ML includes Fraud Detection, Netflix Movie Recommendation etc. whereas Deep Learning can be defined as “Advanced Subset of Machine Learning” in which neural networks adapts and learns from vast amounts of data. It can be used to solve complex real-world problems such as self-driving cars, cancer detection. Let’s discuss each of them in detail.
What is Machine Learning?
As the name suggests, Machine Learning is all about the machine that learns. The question here is How do they learn? Machine Learning uses a mathematical function to construct a model based on training data which is then used to make predictions for the unknown data.
ML can be applied to a variety of domains such as finance, HR, Aerospace, pharmaceutical etc. There is a huge number of sophisticated algorithms available today to train the computers depending on the business problem. Some of them are Linear Regression, Logistic Regression, Random Forests, Support Vector Machines, neural networks. When there is a humongous amount of data available, the most intricate part is to select the correct algorithm to solve the problem. Each model has its own pros and cons and should be selected depending on the type of problem at hand and data available. We will not go into nitty gritty of each one of them.
Let’s try to build the predictive model for the HR department of XYZ company to understand the concept of Machine Learning in a better way. The aim of the model is to predict the number of employees who will leave the company in next five years based on factors such as Work satisfaction, Salary Increment, Number of hours spent in the office, promotion rate, last evaluation etc. The model also predicts the major cause due to which employees are leaving the company. In this way, the machine learning model will help the company to take the best measures to retain their employees in the next five years.
Neural Networks
One of the most important concepts of Machine Learning is Neural Networks. Let’s talk a bit about the Neural Network to go one step ahead towards the term “Deep Learning”. The idea of neural networks evolved from the dream to develop the algorithms that try to mimic the human brain. The simplest definition of a neural network is provided by Dr. Robert Hecht-Nielsen says a computing system made up of number of simple, highly interconnected processing elements, which process information by their dynamic state response to external inputs.
Why we need Neural Networks?
ML algorithms such as Linear Regression and Logistic Regression becomes convoluted while learning complex non-linear hypothesis. Above algorithms hold good when the number of features is less which is a rare case while solving real-world ML problems. Usually, the number of features in ML problems are more than 100 so we end up having the algorithm with an order of 5000 or more for a quadratic polynomial. It becomes computationally expensive. Moreover, the problem of overfitting arises because of which hypothesis presented by these algorithms couldn’t be generalized for new inputs. In such cases, these machine learning algorithms could be destructive.
Let’s understand the big picture of Neuron model:
Machine Learning Mode
Deep Learning Mode
Neuron Model:
The neuron model basically consists of 3 layers: an Input layer, Hidden Layer and Output Layer. Training data is provided to the input layer. Hidden layer is the computational unit which is called as “Sigmoid activationfunction”. Computation unit is nothing but the model which takes the input from the input layer and develops the hypothesis which is channeled down to the output layer. Aggregation of a large number of neuron models collectively known as Neural Networks.
Let’s refer to the model which predicts the number of employees who will leave the company in the next five years. Machine Learning algorithms such as Linear Regression, Logistic Regression holds good in this case because we have a limited number of features such as Work satisfaction, Salary increment, and limited training data available. But if we add the hundred more features such as department, Time spent in company, work accidents. Addition of these features will make the model nonlinear which can’t be solved by above-stated algorithms. This limitation can be overcome by the implementation of neural networks.
The complexity of the problem increases with a tremendous number of features and training data coming into picture due to which the efficiency of neural networks starts degrading. To improve the performance and capabilities of neural networks, the number of hidden layers in a neural network is increased. That’s where the Buzzword, “Deep Learning” comes into the picture.
Deep Learning Models:
Artificial Neural Networks are Machine Learning algorithms with one or two hidden layers whereas Deep Learning models consist of multiple hidden layers which help to improve the state of art technology to great extent. Addition of multiple hidden layers will make the network deep and is called Deep Learning.
Another major difference between Machine Learning and Deep Learning is Feature abstraction for a model. Domain expertise is critical in machine learning algorithm since a lot of preprocessing is required to clean the data and extracting the useful features which can be used to train the Machine Learning model. On the contrary, Deep Learning models learn in a more structured way to extract the features from raw data. As discussed in the above point, DL models consist of multiple hidden layers. Each hidden layer is used to identify one unique feature. DL models cut down the time consuming and arduous task of feature extraction.
There are a huge number of ML algorithms available which can be applied in a wide range of domains. Some of them are K means clustering, K nearest neighbors etc. The use of algorithms varies widely in ML depending on the application whereas, in the case of DL, the same piece of software can be trained for language translation as well as voice cloning. It all depends on the type of data that is fed to computers.
Let’s talk about real world example “Language Translators” to compare the efficiency of ML and DL models. Google launched the Chinese to English translator which used to translate the sentences phrase by phrase. This is far away from how humans translate. The efficiency of a model is around 78%. An upgraded version of language translators was launched recently which was based on Deep Learning model. This language translator model translates sentence by sentence rather than phrase by phrase which increased the efficiency of the model to 91%. DL models have also helped to increase the efficiency in areas of Image Recognition. The efficiency of ML based model for image recognition is 89% which increased up to 93% in the case of Deep Learning model.
The high efficiency comes at expense of stringent requirements:
Requirement of a huge amount of data to train the neural network with multiple layers.
Computationally expensive to train large scale neural networks.
It takes hours to train Deep Learning model since they process a large amount of data to parameterize the model.
Although the above requirements can be easily met with technological advancements, it is very important to choose the optimal model depending upon business problem and data available. Otherwise, DL models could be overkill for trivial application such as detection of spam email or movie recommendations.