Machine learning paradigm is ruled by a simple theorem known as “No Free Lunch” theorem. According to this, there is no algorithm in ML which will work best for all the problems. To state, one can not conclude that SVM is a better algorithm than decision trees or linear regression. Selection of an algorithm is dependent on the problem at hand and other factors like the size and structure of the dataset. Hence, one should try different algorithms to find a better fit for their use case
In this blog, we are going to look into the top machine learning algorithms. You should know and implement the following algorithms to find out the best one for your use case
Top 10 Best Machine Learning Algorithms
1. Linear Regression
Regression is a method used to predict numerical numbers. Regression is a statistical measure which tries to determine the power of the relation between the label-related characteristics of a single variable and other factors called autonomous (periodic attributes) variable. Regression is a statistical measure. Just as the classification is used for categorical label prediction, regression is used for ongoing value prediction. For example, we might like to anticipate the salary or potential sales of a new product based on the prices of graduates with 5-year work experience. Regression is often used to determine how the cost of an item is affected by specific variables such as product cost, interest rates, specific industries or sectors.
The linear regression tries by a linear equation to model the connection between a scalar variable and one or more explaining factors. For instance, using a linear regression model, one might want to connect the weights of people to their heights
The driver calculates a linear pattern of regression. It utilizes the model selection criterion Akaike. A test of the comparative value of fitness to statistics is the Akaike information criterion. It is based on the notion of entropy, which actually provides a comparative metric of data wasted when a specified template is used to portray the truth. The compromise between bias and variance in model building or between the precision and complexity of the model can be described.
2. Logistic Regression
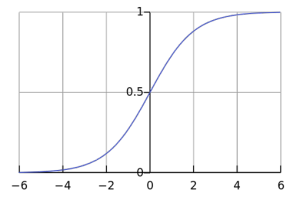
Logistic regression is a classification system that predicts the categorical results variable that may take one of the restricted sets of category scores using entry factors. A binomial logistical regression is restricted to 2 binary outputs and more than 2 classes can be achieved through a multinomial logistic regression. For example, classifying binary conditions as’ safe’/’don’t-healthy’ or’ bike’ /’ vehicle’ /’ truck’ is logistic regression. Logistic regression is used to create an information category forecast for weighted entry scores by the logistic sigmoid function.
The probability of a dependent variable based on separate factors is estimated by a logistic regression model. The variable depends on the yield that we want to forecast, whereas the indigenous variables or explaining variables may affect the performance. Multiple regression means an assessment of regression with two or more independent variables. On the other side, multivariable regression relates to an assessment of regression with two or more dependent factors.
3. Linear Discriminant Analysis
Logistic regression is traditionally a two-class classification problem algorithm. If you have more than two classes, the Linear Discriminant Analysis algorithm is the favorite technique of linear classification. It contains statistical information characteristics, which are calculated for each category.
For a single input variable this includes:
The mean value for each class.
The variance calculated across all classes.
The predictions are calculated by determining a discriminating value for each class and by predicting the highest value for each class. The method implies that the information is distributed Gaussian (bell curve) so that outliers are removed from your information in advance. It is an easy and strong way to classify predictive problem modeling.
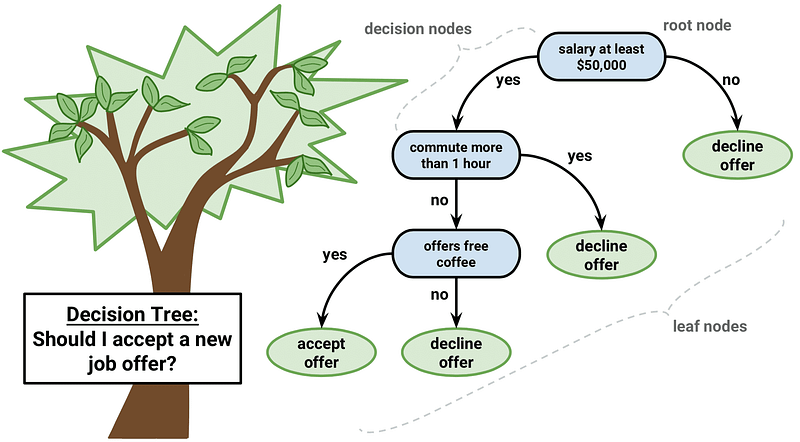
4. Classification and Regression Trees
Prediction Trees are used to forecast answer or YY class of X1, X2,…, XnX1,X2,… ,Xn entry. If the constant reaction is called a regression tree, it is called a ranking tree, if it is categorical. We inspect the significance of one entry XiXi at any point of the tree and proceed to the left or to the correct subbranch, based on the (binary) response. If we hit a tree, we will discover the forecast (generally the leaves as the most popular value of the accessible courses is a straightforward statistical figure of the dataset). In contrast to global model linear or polynomial regression (a predictive formula should be contained in the whole data space), trees attempt to split the data space in a sufficiently small part, where a simply different model can be applied on each side. For each xx information, the non-leaf portion of the tree is simply the process to determine what model we use for the classification of each information (i.e. which leaf).
5. Naive Bayes
A Naive Bayes classification is a supervised algorithm for machinery-learning which utilizes the theorem of Bayes, which implies statistical independence of its characteristics. The theorem depends on the naive premise that input factors are autonomous from each other, that is, that when an extra variable is provided there is no way to understand anything about other factors. It has demonstrated to be a classifier with excellent outcomes regardless of this hypothesis. The Bavarian Theorem, relying on a conditional probability, or in easy words, is used for the Naive Bayes classifications as a probability of a case (A) occurring considering that another incident (B) has already occurred. In essence, the theorem enables an update of the hypothesis every moment fresh proof is presented.
The equation below expresses Bayes’ Theorem in the language of probability:
Let’s explain what each of these terms means.
“P” is the symbol to denote probability.
P(A | B) = The probability of event A (hypothesis) occurring given that B (evidence) has occurred.
P(B | A) = The probability of the event B (evidence) occurring given that A (hypothesis) has occurred.
P(A) = The probability of event B (hypothesis) occurring.
P(B) = The probability of event A (evidence) occurring.
6. K-Nearest Neighbors
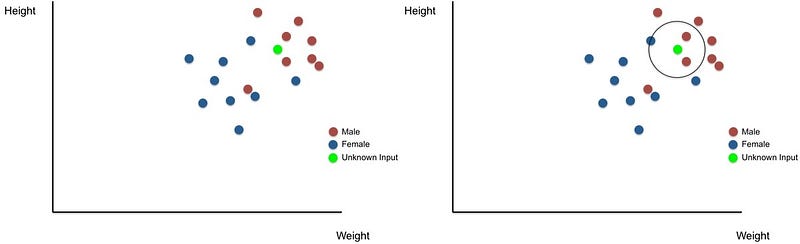
The KNN is a simple machine study algorithm which classifies an entry using its closest neighbours. The input of information points of particular males and women’s height and weight as shown below should be provided, for instance, by a k-NN algorithm. K-NN can peer into the closest k neighbour (personal) and determine if the entry gender is masculine in order to determine the gender of an unidentified object (green point). This technique is extremely easy and logical, with a strong achievement level for labelling unidentified input.
k-NN is used in a range of machine learning tasks; k-NN, for example, can help in computer vision in hand-written letters and the algorithm is used to identify genes that are contributing to a specific characteristic of the gene expression analysis. Overall, neighbours close to each other offer a mixture of ease and efficiency that makes it an appealing algorithm for many teaching machines.7. Learning Vector Quantization
8. Bagging and Random Forest
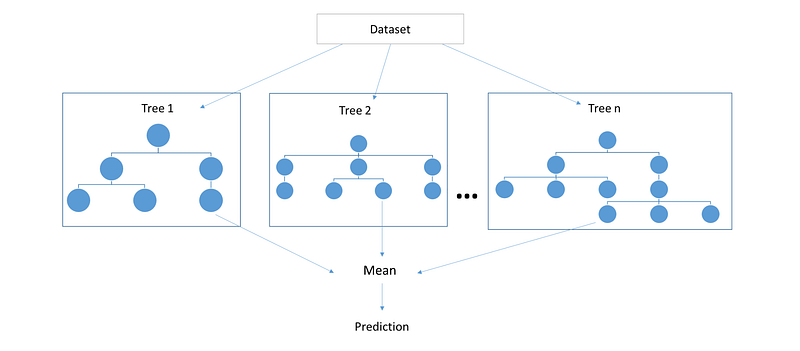
A Random Forest is a group of easy tree predictors, each of which is capable of generating an answer when it has a number of predictor values. This reaction requires the form of a class affiliation for classification issues, which combines or classifies a number of indigenous predictor scores with one of the classifications in the dependent variable. Otherwise, the tree reaction is an assessment of the dependent variable considering the predictors for regression difficulties. Breiman has created the Random Forest algorithm.
An arbitrary amount of plain trees are a random forest used to determine the ultimate result. The ensemble of easy trees votes for the most common category for classification issues. Their answers are averaged to get an assessment of the dependent variable for regression problems. With tree assemblies, the forecast precision (i.e. greater capacity to detect fresh information instances) can improve considerably.
9. SVM
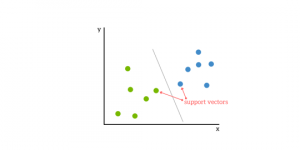
The support vector machine(SVM) is a supervised, classifying, and regressing machine learning algorithm. In classification issues, SVMs are more common, and as such, we shall be focusing on that article.SVMs are based on the idea of finding a hyperplane that best divides a dataset into two classes, as shown in the image below.
You can think of a hyperplane as a line that linearly separates and classifies a set of data.
The more our information points are intuitively located from the hyperplane, the more assured that they have been categorized properly. We would, therefore, like to see as far as feasible from our information spots on the right hand of the hyperplane.
So when new test data are added, the class we assign to it will be determined on any side of the hyperplane.
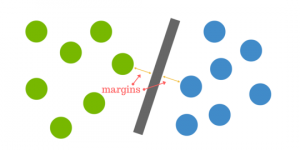
The distance from the hyperplane to the nearest point is called the margin. The aim is to select a hyperplane with as much margin as feasible between the hyperplane and any point in the practice set to give fresh information a higher opportunity to be properly categorized.
But the data is rarely ever as clean as our simple example above. A dataset will often look more like the jumbled balls below which represent a linearly non-separable dataset.
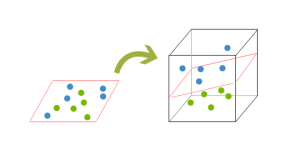
It is essential to switch from a 2D perspective to a 3D perspective to classify a dataset like the one above. Another streamlined instance makes it easier to explain this. Imagine our two balls stood on a board and this booklet is raised abruptly, throwing the balls into the air. You use the cover to distinguish them when the buttons are up in the air. This “raising” of the balls reflects a greater identification of the information. This is known as kernelling.
Our hyperplanes can be no longer a row because we are in three dimensions. It should be a flight now, as shown in the above instance. The concept is to map the information into greater and lower sizes until a hyperplane can be created to separate the information.
10. Boosting and AdaBoost
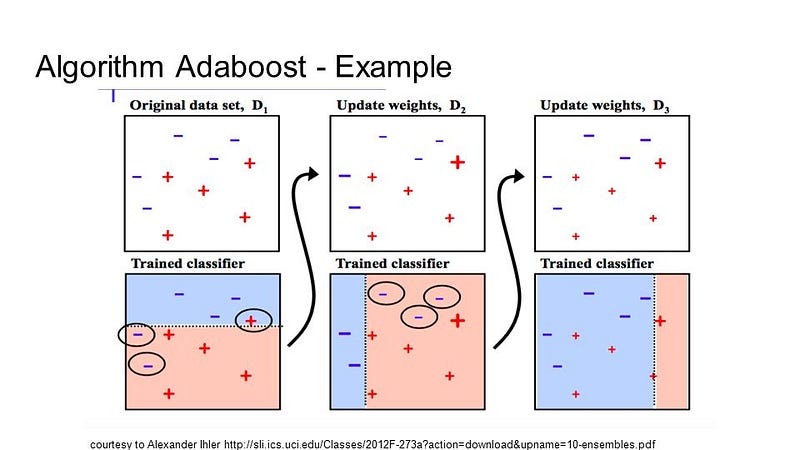
Boosting is an ensemble technology which tries to build a powerful classification of a set of weak classifiers. This is done using a training data model and then a second model has created that attempts the errors of the first model to be corrected. Until the training set is perfectly predicted or a maximum number of models are added, models are added.
AdaBoost was the first truly effective binary classification boosting algorithm. It is the best point of start for improvement. Most of them are stochastic gradient boosters, based on AdaBoost modern boosting techniques.
With brief choice trees, AdaBoost is used. After the creation of the first tree, each exercise instance uses the performance of the tree to weigh how much attention should be given to the next tree to be built. Data that are difficult to forecast will be provided more weight, while cases that are easily predictable will be less important. Sequentially, models are produced one by one to update each of the weights on the teaching sessions which impact on the study of the next tree. After all, trees have been produced, fresh information are predicted and how precise it was on the training data weighs the efficiency of each tree.
Since the algorithm is so careful about correcting errors, it is essential that smooth information is deleted with outliers.
Summary
In the end, every beginner in data science has one basic starting questions that which algorithm is best for all the cases. The response to the issue is not straightforward and depends on many factors like information magnitude, quality and type of information; time required for computation; the importance of the assignment; and purpose of information
Even an experienced data scientist cannot say which algorithm works best before distinct algorithms are tested. While many other machine learning algorithms exist, they are the most common. This is a nice starting point to understand if you are a beginner for machine learning.
There are a huge number of ML algorithms out there. Trying to classify them leads to the distinction being made in types of the training procedure, applications, the latest advances, and some of the standard algorithms used by ML scientists in their daily work. There is a lot to cover, and we shall proceed as given in the following listing:
Statistical Algorithms
Classification
Regression
Clustering
Dimensionality Reduction
Ensemble Algorithms
Deep Learning
Reinforcement Learning
AutoML (Bonus)
1. Statistical Algorithms
Statistics is necessary for every machine learning expert. Hypothesis testing and confidence intervals are some of the many statistical concepts to know if you are a data scientist. Here, we consider here the phenomenon of overfitting. Basically, overfitting occurs when an ML model learns so many features of the training data set that the generalization capacity of the model on the test set takes a toss. The tradeoff between performance and overfitting is well illustrated by the following illustration:
Overfitting – from Wikipedia
Here, the black curve represents the performance of a classifier that has appropriately classified the dataset into two categories. Obviously, training the classifier was stopped at the right time in this instance. The green curve indicates what happens when we allow the training of the classifier to ‘overlearn the features’ in the training set. What happens is that we get an accuracy of 100%, but we lose out on performance on the test set because the test set will have a feature boundary that is usually similar but definitely not the same as the training set. This will result in a high error level when the classifier for the green curve is presented with new data. How can we prevent this?
Cross-Validation
Cross-Validation is the killer technique used to avoid overfitting. How does it work? A visual representation of the k-fold cross-validation process is given below:
From Quora
The entire dataset is split into equal subsets and the model is trained on all possible combinations of training and testing subsets that are possible as shown in the image above. Finally, the average of all the models is combined. The advantage of this is that this method eliminates sampling error, prevents overfitting, and accounts for bias. There are further variations of cross-validation like non-exhaustive cross-validation and nested k-fold cross validation (shown above). For more on cross-validation, visit the following link.
There are many more statistical algorithms that a data scientist has to know. Some examples include the chi-squared test, the Student’s t-test, how to calculate confidence intervals, how to interpret p-values, advanced probability theory, and many more. For more, please visit the excellent article given below:
Classification refers to the process of categorizing data input as a member of a target class. An example could be that we can classify customers into low-income, medium-income, and high-income depending upon their spending activity over a financial year. This knowledge can help us tailor the ads shown to them accurately when they come online and maximises the chance of a conversion or a sale. There are various types of classification like binary classification, multi-class classification, and various other variants. It is perhaps the most well known and most common of all data science algorithm categories. The algorithms that can be used for classification include:
Logistic Regression
Support Vector Machines
Linear Discriminant Analysis
K-Nearest Neighbours
Decision Trees
Random Forests
and many more. A short illustration of a binary classification visualization is given below:
From openclassroom.stanford.edu
For more information on classification algorithms, refer to the following excellent links:
Regression is similar to classification, and many algorithms used are similar (e.g. random forests). The difference is that while classification categorizes a data point, regression predicts a continuous real-number value. So classification works with classes while regression works with real numbers. And yes – many algorithms can be used for both classification and regression. Hence the presence of logistic regression in both lists. Some of the common algorithms used for regression are
Linear Regression
Support Vector Regression
Logistic Regression
Ridge Regression
Partial Least-Squares Regression
Non-Linear Regression
For more on regression, I suggest that you visit the following link for an excellent article:
Both articles have a remarkably clear discussion of the statistical theory that you need to know to understand regression and apply it to non-linear problems. They also have source code in Python and R that you can use.
4. Clustering
Clustering is an unsupervised learning algorithm category that divides the data set into groups depending upon common characteristics or common properties. A good example would be grouping the data set instances into categories automatically, the process being used would be any of several algorithms that we shall soon list. For this reason, clustering is sometimes known as automatic classification. It is also a critical part of exploratory data analysis (EDA). Some of the algorithms commonly used for clustering are:
Hierarchical Clustering – Agglomerative
Hierarchical Clustering – Divisive
K-Means Clustering
K-Nearest Neighbours Clustering
EM (Expectation Maximization) Clustering
Principal Components Analysis Clustering (PCA)
An example of a common clustering problem visualization is given below:
From Wikipedia
The above visualization clearly contains three clusters.
Another excellent article on clustering refer the link
Dimensionality Reduction is an extremely important tool that should be completely clear and lucid for any serious data scientist. Dimensionality Reduction is also referred to as feature selection or feature extraction. This means that the principal variables of the data set that contains the highest covariance with the output data are extracted and the features/variables that are not important are ignored. It is an essential part of EDA (Exploratory Data Analysis) and is nearly always used in every moderately or highly difficult problem. The advantages of dimensionality reduction are (from Wikipedia):
It reduces the time and storage space required.
Removal of multi-collinearity improves the interpretation of the parameters of the machine learning model.
It becomes easier to visualize the data when reduced to very low dimensions such as 2D or 3D.
It avoids the curse of dimensionality.
The most commonly used algorithm for dimensionality reduction is Principal Components Analysis or PCA. While this is a linear model, it can be converted to a non-linear model through a kernel trick similar to that used in a Support Vector Machine, in which case the technique is known as Kernel PCA. Thus, the algorithms commonly used are:
Ensembling means combining multiple ML learners together into one pipeline so that the combination of all the weak learners makes an ML application with higher accuracy than each learner taken separately. Intuitively, this makes sense, since the disadvantages of using one model would be offset by combining it with another model that does not suffer from this disadvantage. There are various algorithms used in ensembling machine learning models. The three common techniques usually employed in practice are:
Simple/Weighted Average/Voting: Simplest one, just takes the vote of models in Classification and average in Regression.
Bagging: We train models (same algorithm) in parallel for random sub-samples of data-set with replacement. Eventually, take an average/vote of obtained results.
Boosting: In this models are trained sequentially, where (n)th model uses the output of (n-1)th model and works on the limitation of the previous model, the process stops when result stops improving.
Stacking: We combine two or more than two models using another machine learning algorithm.
(from Amardeep Chauhan on Medium.com)
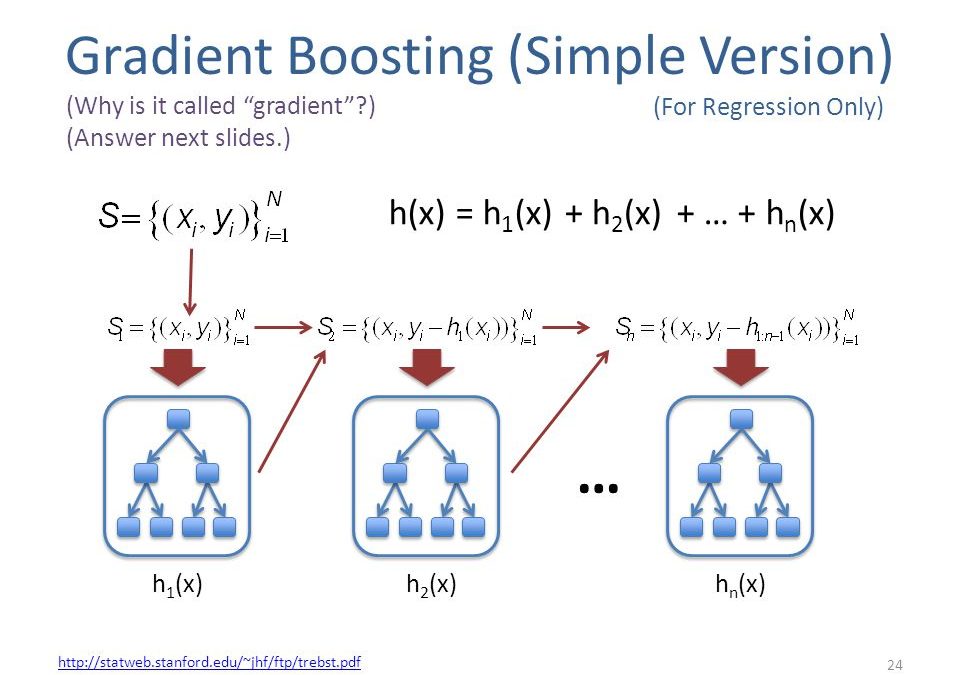
In all four cases, the combination of the different models ends up having the better performance that one single learner. One particular ensembling technique that has done extremely well on data science competitions on Kaggle is the GBRT model or the Gradient Boosted Regression Tree model.
We include the source code from the scikit-learn module for Gradient Boosted Regression Trees since this is one of the most popular ML models which can be used in competitions like Kaggle, HackerRank, and TopCoder.
GradientBoostingClassifier supports both binary and multi-class classification. The following example shows how to fit a gradient boosting classifier with 100 decision stumps as weak learners:
GradientBoostingRegressor supports a number of different loss functions for regression which can be specified via the argument loss; the default loss function for regression is least squares ('ls').
import numpy as np
from sklearn.metrics import mean_squared_error
from sklearn.datasets import make_friedman1
from sklearn.ensemble import GradientBoostingRegressor
X, y = make_friedman1(n_samples=1200, random_state=0, noise=1.0)
X_train, X_test = X[:200], X[200:]
y_train, y_test = y[:200], y[200:]
est = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1,
max_depth=1, random_state=0, loss='ls').fit(X_train, y_train)
mean_squared_error(y_test, est.predict(X_test))
You can also refer to the following article which discusses Random Forests, which is a (rather basic) ensembling method.
In the last decade, there has been a renaissance of sorts within the Machine Learning community worldwide. Since 2002, neural networks research had struck a dead end as the networks of layers would get stuck in local minima in the non-linear hyperspace of the energy landscape of a three layer network. Many thought that neural networks had outlived their usefulness. However, starting with Geoffrey Hinton in 2006, researchers found that adding multiple layers of neurons to a neural network created an energy landscape of such high dimensionality that local minima were statistically shown to be extremely unlikely to occur in practice. Today, in 2019, more than a decade of innovation later, this method of adding addition hidden layers of neurons to a neural network is the classical practice of the field known as deep learning.
Deep Learning has truly taken the computing world by storm and has been applied to nearly every field of computation, with great success. Now with advances in Computer Vision, Image Processing, Reinforcement Learning, and Evolutionary Computation, we have marvellous feats of technology like self-driving cars and self-learning expert systems that perform enormously complex tasks like playing the game of Go (not to be confused with the Go programming language). The main reason these feats are possible is the success of deep learning and reinforcement learning (more on the latter given in the next section below). Some of the important algorithms and applications that data scientists have to be aware of in deep learning are:
Long Short term Memories (LSTMs) for Natural Language Processing
Recurrent Neural Networks (RNNs) for Speech Recognition
Convolutional Neural Networks (CNNs) for Image Processing
Deep Neural Networks (DNNs) for Image Recognition and Classification
Hybrid Architectures for Recommender Systems
Autoencoders (ANNs) for Bioinformatics, Wearables, and Healthcare
Deep Learning Networks typically have millions of neurons and hundreds of millions of connections between neurons. Training such networks is such a computationally intensive task that now companies are turning to the 1) Cloud Computing Systems and 2) Graphical Processing Unit (GPU) Parallel High-Performance Processing Systems for their computational needs. It is now common to find hundreds of GPUs operating in parallel to train ridiculously high dimensional neural networks for amazing applications like dreaming during sleep and computer artistry and artistic creativity pleasing to our aesthetic senses.
Artistic Image Created By A Deep Learning Network. From blog.kadenze.com.
For more on Deep Learning, please visit the following links:
In the recent past and the last three years in particular, reinforcement learning has become remarkably famous for a number of achievements in cognition that were earlier thought to be limited to humans. Basically put, reinforcement learning deals with the ability of a computer to teach itself. We have the idea of a reward vs. penalty approach. The computer is given a scenario and ‘rewarded’ with points for correct behaviour and ‘penalties’ are imposed for wrong behaviour. The computer is provided with a problem formulated as a Markov Decision Process, or MDP. Some basic types of Reinforcement Learning algorithms to be aware of are (some extracts from Wikipedia):
1.Q-Learning
Q-Learning is a model-free reinforcement learning algorithm. The goal of Q-learning is to learn a policy, which tells an agent what action to take under what circumstances. It does not require a model (hence the connotation “model-free”) of the environment, and it can handle problems with stochastic transitions and rewards, without requiring adaptations. For any finite Markov decision process (FMDP), Q-learning finds a policy that is optimal in the sense that it maximizes the expected value of the total reward over any and all successive steps, starting from the current state. Q-learning can identify an optimal action-selection policy for any given FMDP, given infinite exploration time and a partly-random policy. “Q” names the function that returns the reward used to provide the reinforcement and can be said to stand for the “quality” of an action taken in a given state.
2.SARSA
State–action–reward–state–action (SARSA) is an algorithm for learning a Markov decision process policy. This name simply reflects the fact that the main function for updating the Q-value depends on the current state of the agent “S1“, the action the agent chooses “A1“, the reward “R” the agent gets for choosing this action, the state “S2” that the agent enters after taking that action, and finally the next action “A2” the agent choose in its new state. The acronym for the quintuple (st, at, rt, st+1, at+1) is SARSA.
3.Deep Reinforcement Learning
This approach extends reinforcement learning by using a deep neural network and without explicitly designing the state space. The work on learning ATARI games by Google DeepMind increased attention to deep reinforcement learning or end-to-end reinforcement learning. Remarkably, the computer agent DeepMind has achieved levels of skill higher than humans at playing computer games. Even a complex game like DOTA 2 was won by a deep reinforcement learning network based upon DeepMind and OpenAI Gym environments that beat human players 3-2 in a tournament of best of five matches.
For more information, go through the following links:
If reinforcement learning was cutting edge data science, AutoML is bleeding edge data science. AutoML (Automated Machine Learning) is a remarkable project that is open source and available on GitHub at the following link that, remarkably, uses an algorithm and a data analysis approach to construct an end-to-end data science project that does data-preprocessing, algorithm selection,hyperparameter tuning, cross-validation and algorithm optimization to completely automate the ML process into the hands of a computer. Amazingly, what this means is that now computers can handle the ML expertise that was earlier in the hands of a few limited ML practitioners and AI experts.
AutoML has found its way into Google TensorFlow through AutoKeras, Microsoft CNTK, and Google Cloud Platform, Microsoft Azure, and Amazon Web Services (AWS). Currently it is a premiere paid model for even a moderately sized dataset and is free only for tiny datasets. However, one entire process might take one to two or more days to execute completely. But at least, now the computer AI industry has come full circle. We now have computers so complex that they are taking the machine learning process out of the hands of the humans and creating models that are significantly more accurate and faster than the ones created by human beings!
The basic algorithm used by AutoML is Network Architecture Search and its variants, given below:
Network Architecture Search (NAS)
PNAS (Progressive NAS)
ENAS (Efficient NAS)
The functioning of AutoML is given by the following diagram:
If you’ve stayed with me till now, congratulations; you have learnt a lot of information and cutting edge technology that you must read up on, much, much more. You could start with the links in this article, and of course, Google is your best friend as a Machine Learning Practitioner. Enjoy machine learning!
Gradient Boosting Model is a machine learning technique, in league of models like Random forest, Neural Networks etc.It can be used over regression when there is non-linearity in data, data is sparsely populated, has low fil rate or simply when regression is just unable to give expected results.Must Read:First step to exploring data: Univariate AnalysisThough GBM is a black box modeling technique with relatively complicated mathematics behind it, this blog aims to present it in a way which helps easy visualization while staying true to the basic nature of the model.Let us assume a simple classification problem where one has to classify positives and negatives.A simple classification model (with errors associated with it) eg.Regression trees, can be run to acheive it.The Box 1 in the diagram below represents such a model.
Understanding GBM
Understanding GBMThe following observations can be made from the above diagram:Box 1: Output of First Weak Learner (From the left)*Initially all points have same weight (denoted by their size).
The decision boundary predicts 2 +ve and 5 -ve points correctly.
The points classified correctly in box 1 are given a lower weight and vice versa.
The model focuses on high weight points now and classifies them correctly. But, others are misclassified now.
Similar trend can be seen in box 3 as well.This continues for many iterations.In the end, all models (e.g.regression trees) are given a weight depending on their accuracy and a consolidated result is generated.In a simple notational form if M(x) is our first model say with an 80% accuracy.Instead of building new models altogether, a simpler way would be followingY= M(x) + errorIf the error is white noise i.e it has correlation with the target variable, a model can be built on iterror = G(x) + error2error2 = H(x) + error3combining these three:Y = M(x) + G(x) + H(x) + error3 This probably will have a accuracy of even more than 84%.Now , optimal weights are given to each of the three learners, Y = alpha * M(x) + beta * G(x) + gamma * H(x) + error4This was a broad overview just touching the tip of a more complex iceberg behind Gradient Boosting technique.Keep watching the space as we dig some deeper into it.