There are a huge number of ML algorithms out there. Trying to classify them leads to the distinction being made in types of the training procedure, applications, the latest advances, and some of the standard algorithms used by ML scientists in their daily work. There is a lot to cover, and we shall proceed as given in the following listing:
Statistical Algorithms
Classification
Regression
Clustering
Dimensionality Reduction
Ensemble Algorithms
Deep Learning
Reinforcement Learning
AutoML (Bonus)
1. Statistical Algorithms
Statistics is necessary for every machine learning expert. Hypothesis testing and confidence intervals are some of the many statistical concepts to know if you are a data scientist. Here, we consider here the phenomenon of overfitting. Basically, overfitting occurs when an ML model learns so many features of the training data set that the generalization capacity of the model on the test set takes a toss. The tradeoff between performance and overfitting is well illustrated by the following illustration:
Overfitting – from Wikipedia
Here, the black curve represents the performance of a classifier that has appropriately classified the dataset into two categories. Obviously, training the classifier was stopped at the right time in this instance. The green curve indicates what happens when we allow the training of the classifier to ‘overlearn the features’ in the training set. What happens is that we get an accuracy of 100%, but we lose out on performance on the test set because the test set will have a feature boundary that is usually similar but definitely not the same as the training set. This will result in a high error level when the classifier for the green curve is presented with new data. How can we prevent this?
Cross-Validation
Cross-Validation is the killer technique used to avoid overfitting. How does it work? A visual representation of the k-fold cross-validation process is given below:
From Quora
The entire dataset is split into equal subsets and the model is trained on all possible combinations of training and testing subsets that are possible as shown in the image above. Finally, the average of all the models is combined. The advantage of this is that this method eliminates sampling error, prevents overfitting, and accounts for bias. There are further variations of cross-validation like non-exhaustive cross-validation and nested k-fold cross validation (shown above). For more on cross-validation, visit the following link.
There are many more statistical algorithms that a data scientist has to know. Some examples include the chi-squared test, the Student’s t-test, how to calculate confidence intervals, how to interpret p-values, advanced probability theory, and many more. For more, please visit the excellent article given below:
Classification refers to the process of categorizing data input as a member of a target class. An example could be that we can classify customers into low-income, medium-income, and high-income depending upon their spending activity over a financial year. This knowledge can help us tailor the ads shown to them accurately when they come online and maximises the chance of a conversion or a sale. There are various types of classification like binary classification, multi-class classification, and various other variants. It is perhaps the most well known and most common of all data science algorithm categories. The algorithms that can be used for classification include:
Logistic Regression
Support Vector Machines
Linear Discriminant Analysis
K-Nearest Neighbours
Decision Trees
Random Forests
and many more. A short illustration of a binary classification visualization is given below:
From openclassroom.stanford.edu
For more information on classification algorithms, refer to the following excellent links:
Regression is similar to classification, and many algorithms used are similar (e.g. random forests). The difference is that while classification categorizes a data point, regression predicts a continuous real-number value. So classification works with classes while regression works with real numbers. And yes – many algorithms can be used for both classification and regression. Hence the presence of logistic regression in both lists. Some of the common algorithms used for regression are
Linear Regression
Support Vector Regression
Logistic Regression
Ridge Regression
Partial Least-Squares Regression
Non-Linear Regression
For more on regression, I suggest that you visit the following link for an excellent article:
Both articles have a remarkably clear discussion of the statistical theory that you need to know to understand regression and apply it to non-linear problems. They also have source code in Python and R that you can use.
4. Clustering
Clustering is an unsupervised learning algorithm category that divides the data set into groups depending upon common characteristics or common properties. A good example would be grouping the data set instances into categories automatically, the process being used would be any of several algorithms that we shall soon list. For this reason, clustering is sometimes known as automatic classification. It is also a critical part of exploratory data analysis (EDA). Some of the algorithms commonly used for clustering are:
Hierarchical Clustering – Agglomerative
Hierarchical Clustering – Divisive
K-Means Clustering
K-Nearest Neighbours Clustering
EM (Expectation Maximization) Clustering
Principal Components Analysis Clustering (PCA)
An example of a common clustering problem visualization is given below:
From Wikipedia
The above visualization clearly contains three clusters.
Another excellent article on clustering refer the link
Dimensionality Reduction is an extremely important tool that should be completely clear and lucid for any serious data scientist. Dimensionality Reduction is also referred to as feature selection or feature extraction. This means that the principal variables of the data set that contains the highest covariance with the output data are extracted and the features/variables that are not important are ignored. It is an essential part of EDA (Exploratory Data Analysis) and is nearly always used in every moderately or highly difficult problem. The advantages of dimensionality reduction are (from Wikipedia):
It reduces the time and storage space required.
Removal of multi-collinearity improves the interpretation of the parameters of the machine learning model.
It becomes easier to visualize the data when reduced to very low dimensions such as 2D or 3D.
It avoids the curse of dimensionality.
The most commonly used algorithm for dimensionality reduction is Principal Components Analysis or PCA. While this is a linear model, it can be converted to a non-linear model through a kernel trick similar to that used in a Support Vector Machine, in which case the technique is known as Kernel PCA. Thus, the algorithms commonly used are:
Ensembling means combining multiple ML learners together into one pipeline so that the combination of all the weak learners makes an ML application with higher accuracy than each learner taken separately. Intuitively, this makes sense, since the disadvantages of using one model would be offset by combining it with another model that does not suffer from this disadvantage. There are various algorithms used in ensembling machine learning models. The three common techniques usually employed in practice are:
Simple/Weighted Average/Voting: Simplest one, just takes the vote of models in Classification and average in Regression.
Bagging: We train models (same algorithm) in parallel for random sub-samples of data-set with replacement. Eventually, take an average/vote of obtained results.
Boosting: In this models are trained sequentially, where (n)th model uses the output of (n-1)th model and works on the limitation of the previous model, the process stops when result stops improving.
Stacking: We combine two or more than two models using another machine learning algorithm.
(from Amardeep Chauhan on Medium.com)
In all four cases, the combination of the different models ends up having the better performance that one single learner. One particular ensembling technique that has done extremely well on data science competitions on Kaggle is the GBRT model or the Gradient Boosted Regression Tree model.
We include the source code from the scikit-learn module for Gradient Boosted Regression Trees since this is one of the most popular ML models which can be used in competitions like Kaggle, HackerRank, and TopCoder.
GradientBoostingClassifier supports both binary and multi-class classification. The following example shows how to fit a gradient boosting classifier with 100 decision stumps as weak learners:
GradientBoostingRegressor supports a number of different loss functions for regression which can be specified via the argument loss; the default loss function for regression is least squares ('ls').
import numpy as np
from sklearn.metrics import mean_squared_error
from sklearn.datasets import make_friedman1
from sklearn.ensemble import GradientBoostingRegressor
X, y = make_friedman1(n_samples=1200, random_state=0, noise=1.0)
X_train, X_test = X[:200], X[200:]
y_train, y_test = y[:200], y[200:]
est = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1,
max_depth=1, random_state=0, loss='ls').fit(X_train, y_train)
mean_squared_error(y_test, est.predict(X_test))
You can also refer to the following article which discusses Random Forests, which is a (rather basic) ensembling method.
In the last decade, there has been a renaissance of sorts within the Machine Learning community worldwide. Since 2002, neural networks research had struck a dead end as the networks of layers would get stuck in local minima in the non-linear hyperspace of the energy landscape of a three layer network. Many thought that neural networks had outlived their usefulness. However, starting with Geoffrey Hinton in 2006, researchers found that adding multiple layers of neurons to a neural network created an energy landscape of such high dimensionality that local minima were statistically shown to be extremely unlikely to occur in practice. Today, in 2019, more than a decade of innovation later, this method of adding addition hidden layers of neurons to a neural network is the classical practice of the field known as deep learning.
Deep Learning has truly taken the computing world by storm and has been applied to nearly every field of computation, with great success. Now with advances in Computer Vision, Image Processing, Reinforcement Learning, and Evolutionary Computation, we have marvellous feats of technology like self-driving cars and self-learning expert systems that perform enormously complex tasks like playing the game of Go (not to be confused with the Go programming language). The main reason these feats are possible is the success of deep learning and reinforcement learning (more on the latter given in the next section below). Some of the important algorithms and applications that data scientists have to be aware of in deep learning are:
Long Short term Memories (LSTMs) for Natural Language Processing
Recurrent Neural Networks (RNNs) for Speech Recognition
Convolutional Neural Networks (CNNs) for Image Processing
Deep Neural Networks (DNNs) for Image Recognition and Classification
Hybrid Architectures for Recommender Systems
Autoencoders (ANNs) for Bioinformatics, Wearables, and Healthcare
Deep Learning Networks typically have millions of neurons and hundreds of millions of connections between neurons. Training such networks is such a computationally intensive task that now companies are turning to the 1) Cloud Computing Systems and 2) Graphical Processing Unit (GPU) Parallel High-Performance Processing Systems for their computational needs. It is now common to find hundreds of GPUs operating in parallel to train ridiculously high dimensional neural networks for amazing applications like dreaming during sleep and computer artistry and artistic creativity pleasing to our aesthetic senses.
Artistic Image Created By A Deep Learning Network. From blog.kadenze.com.
For more on Deep Learning, please visit the following links:
In the recent past and the last three years in particular, reinforcement learning has become remarkably famous for a number of achievements in cognition that were earlier thought to be limited to humans. Basically put, reinforcement learning deals with the ability of a computer to teach itself. We have the idea of a reward vs. penalty approach. The computer is given a scenario and ‘rewarded’ with points for correct behaviour and ‘penalties’ are imposed for wrong behaviour. The computer is provided with a problem formulated as a Markov Decision Process, or MDP. Some basic types of Reinforcement Learning algorithms to be aware of are (some extracts from Wikipedia):
1.Q-Learning
Q-Learning is a model-free reinforcement learning algorithm. The goal of Q-learning is to learn a policy, which tells an agent what action to take under what circumstances. It does not require a model (hence the connotation “model-free”) of the environment, and it can handle problems with stochastic transitions and rewards, without requiring adaptations. For any finite Markov decision process (FMDP), Q-learning finds a policy that is optimal in the sense that it maximizes the expected value of the total reward over any and all successive steps, starting from the current state. Q-learning can identify an optimal action-selection policy for any given FMDP, given infinite exploration time and a partly-random policy. “Q” names the function that returns the reward used to provide the reinforcement and can be said to stand for the “quality” of an action taken in a given state.
2.SARSA
State–action–reward–state–action (SARSA) is an algorithm for learning a Markov decision process policy. This name simply reflects the fact that the main function for updating the Q-value depends on the current state of the agent “S1“, the action the agent chooses “A1“, the reward “R” the agent gets for choosing this action, the state “S2” that the agent enters after taking that action, and finally the next action “A2” the agent choose in its new state. The acronym for the quintuple (st, at, rt, st+1, at+1) is SARSA.
3.Deep Reinforcement Learning
This approach extends reinforcement learning by using a deep neural network and without explicitly designing the state space. The work on learning ATARI games by Google DeepMind increased attention to deep reinforcement learning or end-to-end reinforcement learning. Remarkably, the computer agent DeepMind has achieved levels of skill higher than humans at playing computer games. Even a complex game like DOTA 2 was won by a deep reinforcement learning network based upon DeepMind and OpenAI Gym environments that beat human players 3-2 in a tournament of best of five matches.
For more information, go through the following links:
If reinforcement learning was cutting edge data science, AutoML is bleeding edge data science. AutoML (Automated Machine Learning) is a remarkable project that is open source and available on GitHub at the following link that, remarkably, uses an algorithm and a data analysis approach to construct an end-to-end data science project that does data-preprocessing, algorithm selection,hyperparameter tuning, cross-validation and algorithm optimization to completely automate the ML process into the hands of a computer. Amazingly, what this means is that now computers can handle the ML expertise that was earlier in the hands of a few limited ML practitioners and AI experts.
AutoML has found its way into Google TensorFlow through AutoKeras, Microsoft CNTK, and Google Cloud Platform, Microsoft Azure, and Amazon Web Services (AWS). Currently it is a premiere paid model for even a moderately sized dataset and is free only for tiny datasets. However, one entire process might take one to two or more days to execute completely. But at least, now the computer AI industry has come full circle. We now have computers so complex that they are taking the machine learning process out of the hands of the humans and creating models that are significantly more accurate and faster than the ones created by human beings!
The basic algorithm used by AutoML is Network Architecture Search and its variants, given below:
Network Architecture Search (NAS)
PNAS (Progressive NAS)
ENAS (Efficient NAS)
The functioning of AutoML is given by the following diagram:
If you’ve stayed with me till now, congratulations; you have learnt a lot of information and cutting edge technology that you must read up on, much, much more. You could start with the links in this article, and of course, Google is your best friend as a Machine Learning Practitioner. Enjoy machine learning!
The amount of data that is generated every day is mind-boggling. There was an article on Forbes by Bernard Marr that blew my mind. Here are some excerpts. For the full article, go to Link
There are 2.5 quintillion bytes of data created each day. Over the last two years alone 90 percent of the data in the world was generated.
Europe has more than 307 million people on Facebook
There are five new Facebook profiles created every second!
More than 300 million photos get uploaded per day
Every minute there are 510,000 comments posted and 293,000 statuses updated (on Facebook)
And all this data was gathered 21st May, last year!
Photo by rawpixel on Unsplash
So I decided to do a more up to date survey. The data below was from an article written on 25th Jan 2019, given at the following link:
By 2020, the accumulated volume of big data will increase from 4.4 zettabytes to roughly 44 zettabytes or 44 trillion GB.
Originally, data scientists maintained that the volume of data would double every two years thus reaching the 40 ZB point by 2020. That number was later bumped to 44ZB when the impact of IoT was brought into consideration.
The rate at which data is created is increased exponentially. For instance, 40,000 search queries are performed per second (on Google alone), which makes it 3.46 million searches per day and 1.2 trillion every year.
The data gathered is no more text-only. An exponential growth in videos and photos is equally prominent. On YouTube alone, 300 hours of video are uploaded every minute.
IDC estimates that by 2020, business transactions (including both B2B and B2C) via the internet will reach up to 450 billion per day.
Globally, the number of smartphone users will grow to 6.1 billion by 2020 (this will overtake the number of basic fixed phone subscriptions).
In just 5 years the number of smart connected devices in the world will be more than 50 billion – all of which will create data that can be shared, collected and analyzed.
Photo by Fancycrave on UnsplashSo what does that mean for us, as data scientists?
Data = raw information. Information = processed data.
Theoretically, inside every 100 MB of the 44,000,000,000,000,000 GB available in the world, today produced as data there lies a possible business-sector disrupting insight!
But who has the skills to look through 44 trillion GB of data?
The answer: Data Scientists! WithCreativity and Originality in their Out-of-the-Box Thinking, as well as DisciplinedFocus.
Here is a description estimating the salaries for data scientists followed by a graphic which shows you why data science is so hyped right now:
Freshers in Analytics get paid more than then any other field, they can be paid up-to 6-7 Lakhs per annum (LPA) minus any experience, 3-7 years experienced professional can expect around 10-11 LPA and anyone with more than 7-10 years can expect, 20-30 LPA.
Opportunities in tier 2 cities can be higher, but the pay-scale of Tier 1 cities is much higher.
E-commerce is the most rewarding career with great pay-scale especially for Fresher’s, offering close to 7-8 LPA, while Analytics service provider offers the lowest packages, 6 LPA.
It is advised to combine your skills to attract better packages, skills such as SAS, R Python, or any open source tools, offers around 13 LPA.
Machine Learning is the new entrant in analytics field, attracting better packages when compared to the skills of big data, however for a significant leverage, acquiring the skill sets of both Big Data and Machine Learning will fetch you a starting salary of around 13 LPA.
Combination of knowledge and skills makes you unique in the job market and hence attracts high pay packages.
Picking up the top five tools of big data analytics, like R, Python, SAS, Tableau, Spark along with popular Machine Learning Algorithms, NoSQL Databases, Data Visualization, will make you irresistible for any talent hunter, where you can demand a high pay package.
As a professional, you can upscale your salary by upskilling in the analytics field.
So there is no doubt about the demand or the need for data scientists in the 21st century.
Now we have done a survey for India. but what about the USA?
The following data is an excerpt from an article by IBM< which tells the story much better than I ever could:
Jobs requiring machine learning skills are paying an average of $114,000.
Advertised data scientist jobs pay an average of $105,000 and advertised data engineering jobs pay an average of $117,000.59% of all Data Science and Analytics (DSA) job demand is in Finance and Insurance, Professional Services, and IT.
Annual demand for the fast-growing new roles of data scientist, data developers, and data engineers will reach nearly 700,000 openings by 2020.
By 2020, the number of jobs for all US data professionals will increase by 364,000 openings to 2,720,000 according to IBM.
Data Science and Analytics (DSA) jobs remain open an average of 45 days, five days longer than the market average.
And yet still more! Look below:
By 2020 the number of Data Science and Analytics job listings is projected to grow by nearly 364,000 listings to approximately 2,720,000 The following is the summary of the study that highlights how in-demand data science and analytics skill sets are today and are projected to be through 2020.
There were 2,350,000 DSA job listings in 2015
By 2020, DSA jobs are projected to grow by 15%
Demand for Data scientists and data engineers is projectedto grow byneary40%
DSA jobs advertise average salaries of 80,265 USD$
81% of DSA jobs require workers with 3-5 years of experience or more.
Machine learning, big data, and data science skills are the most challenging to recruit for and potentially can create the greatest disruption to ongoing product development and go-to-market strategies if not filled.
So where does Dimensionless Technologies, with courses in Python, R, Deep Learning, NLP, Big Data, Analytics, and AWS coming soon, stand in the middle of all the demand?
The answer: right in the epicentre of the data science earthquake that is no hitting our IT sector harder than ever.The main reason I say this is because of the salaries increasing like your tummy after you finish your fifth Domino’s Dominator Cheese and Pepperoni Pizza in a row everyday for seven days! Have a look at the salaries for data science:
Do you know which city in India pays highest salaries to data scientist?
Mumbai pays the highest salary in India around 12.19L p.a.
Report of Data Analytics Salary of the Top Companies in India
Accenture’s Data Analytics Salary in India: 90% gets a salary of about Rs 980,000 per year
Tata Consultancy Services Limited Data Analytics Salary in India: 90% of the employees get a salary of about Rs 550,000 per year. A bonus of Rs 20,000 is paid to the employees.
EY (Ernst & Young) Data Analytics Salary in India: 75% of the employees get a salary of Rs 620,000 and 90% of the employees get a salary of Rs 770,000.
HCL Technologies Ltd. Data Analytics Salary in India: 90% of the people are paid Rs 940,000 per year approximately.
In the USA
From glassdoor.com
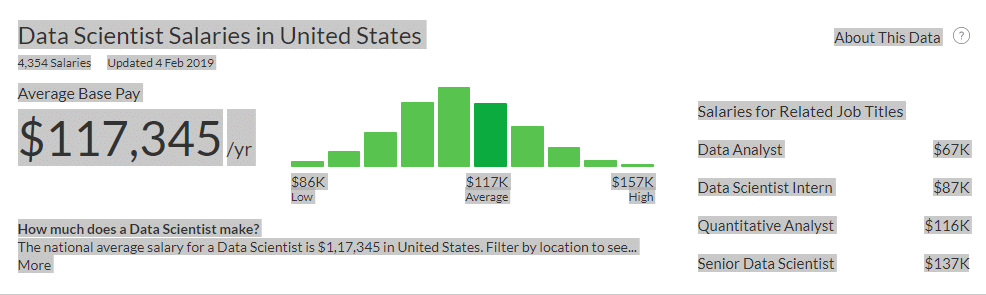
To convert into INR, in the US, the salaries of a data scientist stack up as follows:
Lowest: 86,000 USD = 6,020,000 INR per year (60 lakh per year)
Average: 117,00 USD = 8,190,000 INR per year (81 lakh per year)
Highest: 157,000 USD = 10,990,000 INR per year(109 lakh per year or approximately one crore)
at the exchange rate of 70 INR = 1 USD.
By now you should be able to understand why everyone is running after data science degrees and data science certifications everywhere.
The only other industry that offers similar salaries is cloud computing.
A Personal View
On my own personal behalf, I often wondered – why does everyone talk about following your passion and not just about the money. The literature everywhere advertises“Follow your heart and it will lead you to the land of your dreams”. But then I realized – passion is more than your dreams. A dream, if it does not serve others in some way, is of no inspirational value. That is when I found the fundamental role – focus on others achieving their hearts desires, and you will automatically discover your passion. I have many interests, and I found my happiness doing research in advanced data science and quantum computing and dynamical systems, focusing on experiments that combine all three of them together as a single unified theory. I found that that was my dream. But, however, I have a family and I need to serve them. I need to earn.
Thus I relegated my dreams of research to a part-time level and focused fully on earning for my extended family, and serving them as best as I can. Maybe you will come to your own epiphany moment yourself reading this article. What do you want to do with your life? Personally, I wish to improve the lives of those around me, especially the poor and the malnourished. That feeds my heart. Hence my career decision – invest wisely in the choices that I make to garner maximum benefit for those around me. And work on my research papers in the free time that I get.
So my hope for you today is: having read this article, understand the rich potential that lies before you if you can complete your journey as a data scientist. The only reason that I am not going into data science myself is that I am 34 years old and no longer in the prime of my life to follow this American dream. Hence I found my niche in my interest in research. And further, I realized that a fundamental ‘quantum leap’ would be made if my efforts were to succeed. But as for you, the reader of this article, you may be inspired or your world-view expanded by reading this article and the data contained within. My advice to you is: follow your heart. It knows you best and will not betray you into any false location. Data science is the future for the world. make no mistake about that. And – from whatever inspiration you have received go forward boldly and take action. Take one day at a time. Don’t look at the final goal. Take one day at a time. If you can do that, you will definitely achieve your goals.
The salary at the top, per year. From glassdoor.com. Try not to drool. 🙂
Finding Your Passion
Many times when you’re sure you’ve discovered your passion and you run into a difficult topic, that leaves you stuck, you are prone to the famous impostor syndrome. “Maybe this is too much for me. Maybe this is too difficult for me. Maybe this is not my passion. Otherwise, it wouldn’t be this hard for me.” My dear friend, this will hit you. At one point or the other. At such moments, what I do, based upon lessons from the following course, which I highly recommend to every human being on the planet, is: Take a break. Do something different that completely removes the mind from your current work. Be completely immersed in something else. Or take a nap. Or – best of all – go for a run or a cycle. Exercise. Workout. This gives your brain cells rest and allows them to process the data in the background. When you come back to your topic, fresh, completely free of worry and tension, completely recharged, you will have an insight into the problem for you that completely solves it. Guaranteed. For more information, I highly suggest the following two resources:
or the most popular MOOC of all time, based on the same topic: Coursera
Learning How to Learn – Coursera and IEEE
This should be your action every time you feel stuck. I have completely finished this MOOC and the book and it has given me the confidence to tackle any subject in the world, including quantum mechanics, topology, string theory, and supersymmetry theory. I strongly recommend this resource (from experience).
So Dimensionless Technologies (link given above) is your entry point to all things data science. Before you go to TensorFlow, Hadoop, Keras, Hive, Pig, MapReduce, BigQuery, BigTable, you need to know the following topics first:
All the best. Your passion is not just a feeling. It is a choice you make the day in and a day out whether you like it or not. That is the definition of character – to do what must be done even if you don’t feel like it. Internalize this advice, and there will be no limits to how high you can go.All the best!
Now unless you’ve been a hermit or a monk living in total isolation, you will have heard of Amazon Web Services and AWS Big Data. It’s a sign of an emerging global market and the entire world becoming smaller and smaller every day. Why? The current estimate for the cloud computing market in 2020, according to Forbes (a new prediction, highly reliable), is a staggering 411 Billion USD$! Visit the following link to read more and see the statistics for yourself:
To know more, refer to Wikipedia for the following terms by clicking on them, which mark, in order the evolution of cloud computing (I will also provide the basic information to keep this article as self-contained as possible):
This was the beginning of the revolution called cloud computing. Companies and industries across verticals understood that they could let experts manage their software development, deployment, and management for them, leaving them free to focus on their key principle – adding value to their business sector. This was mostly confined to the application level. Follow the heading link for more information, if required.
PaaS began when companies started to understand that they could outsource both software management and operating systems and maintenance of these platforms to other companies that specialized in taking care of them. Basically, this was SaaS taken to the next level of virtualization, on the Internet. Amazon was the pioneer, offering SaaS and PaaS services worldwide from the year 2006. Again the heading link gives information in depth.
After a few years in 2011, the big giants like Microsoft, Google, and a variety of other big names began to realize that this was an industry starting to boom beyond all expectations, as more and more industries spread to the Internet for worldwide visibility. However, Amazon was the market leader by a big margin, since it had a five-year head start on the other tech giants. This led to unprecedented disruption across verticals, as more and more companies transferred their IT requirements to IaaS providers like Amazon, leading to (in some cases) savings of well over 25% and per-employee cost coming down by 30%.
After all, why should companies set up their own servers, data warehouse centres, development centres, maintenance divisions, security divisions, and software and hardware monitoring systems if there are companies that have the world’s best experts in every one of these sectors and fields that will do the job for you at less than 1% of the cost the company would incur if they had to hire staff, train them, monitor them, buy their own hardware, hire staff for that as well – the list goes on-and-on. If you are already a tech giant like, say Oracle, you have everything set up for you already. But suppose you are a startup trying to save every penny – and there and tens of thousands of such startups right now – why do that when you have professionals to do it for you?
There is a story behind how AWS got started in 2006 – I’m giving you a link, so as to not make this article too long:
OK. So now you may be thinking, so this is cloud computing and AWS – but what does it have to do with Big Data Speciality, especially for startups? Let’s answer that question right now.
A startup today has a herculean task ahead of them.
Not only do they have to get noticed in the big booming startup industry, they also have to scale well if their product goes viral and receives a million hits in a day and provide security for their data in case a competitor hires hackers from the Dark Web to take down their site, and also follow up everything they do on social media with a division in their company managing only social media, and maintain all their hardware and software in case of outages. If you are a startup counting every penny you make, how much easier is it for you to outsource all your computing needs (except social media) to an IaaS firm like AWS.
You will be ready for anything that can happen, and nothing will take down your website or service other than your own self. Oh, not to mention saving around 1 million USD$ in cost over the year!If you count nothing but your own social media statistics, every company that goes viral has to manage Big Data! And if your startup disrupts an industry, again, you will be flooded with GET requests, site accesses, purchases, CRM, scaling problems, avoiding downtime, and practically everything a major tech company has to deal with!
Bro, save your grey hairs, and outsource all your IT needs (except social media – that you personally need to do) to Amazon with AWS!
And the Big Data Speciality?
Having laid the groundwork, let’s get to the meat of our article. The AWS certified Big Data Speciality website mentions the following details:
The AWS Certified Big Data – Specialty exam validates technical skills and experience in designing and implementing AWS services to derive value from data. The examination is for individuals who perform complex Big Data analyses and validates an individual’s ability to:
Implement core AWS Big Data services according to basic architecture best practices
Design and maintain Big Data
Leverage tools to automate data analysis
So, what is an AWS Big Data Speciality certified expert? Nothing more than an internationally recognized certification that says that you, as a data scientist can work professionally in AWS and Big Data’s requirements in Data Science.
Please note: the eligibility criteria for an AWS Big Data Speciality Certification is:
Minimum five years hands-on experience in a data analytics field
Background in defining and architecting AWS Big Data services with the ability to explain how they fit in the data life cycle of collection, ingestion, storage, processing, and visualization
Experience in designing a scalable and cost-effective architecture to process data
To put it in layman’s terms, if you, the data scientist, were Priyanka Chopra, getting the AWS Big Data Speciality certification passed successfully is the equivalent of going to Hollywood and working in the USA starring in Quantico!
Suddenly, a whole new world is open at your feet!
But don’t get too excited: unless you already have five years experience with Big Data, there’s a long way to go. But work hard, take one step at a time, don’t look at the goal far ahead but focus on every single day, one day, one task at a time, and in the end you will reach your destination. Persistence, discipline and determination matters. As simple as that.
From whizlabs.org
Five Advantages of an AWS Big Data Speciality
1. Massive Increase in Income as a Certified AWS Big Data Speciality Professional (a long term 5 years plus goal)
Everyone who’s anyone in data science knows that a data scientist in the US earns an average of 100,000 USD$ every year. But what is the average salary of an AWS Big Data Speciality Certified professional? Hold on to your hat’s folks; it’s 160,000 $USD starting salary. And with just two years of additional experience, that salary can cross 250,000 USD$ every year if you are a superstar at your work. Depending upon your performance on the job! Do you still need a push to get into AWS? The following table shows the average starting salaries for specialists in the following Amazon products: (from www.dezyre.com)
Top Paying AWS Skills According to Indeed.com
AWS Skill
Salary
DynamoDB
$141,813
Elastic MapReduce (EMR)
$136,250
CloudFormation
$132,308
Elastic Cache
$125,625
CloudWatch
$121,980
Lambda
$121,481
Kinesis
$121,429
Key Management Service
$117,297
Elastic Beanstalk
$114,219
Redshift
$113,950
2. Wide Ecosystem of Tools, Libraries, and Amazon Products
From slideshare.net
Amazon Web Services, compared to other Cloud IaaS services, has by far the widest ecosystem of products and tools. As a Big Data specialist, you are free to choose your career path. Do you want to get into AI? Do you have an interest in ES3 (storage system) or HIgh-Performance Serverless computing (AWS Lambda). You get to choose, along with the company you work for. I don’t know about you, but I’m just writing this article and I’mseriouslyexcited!
3. Maximum Demand Among All Cloud Computing jobs
If you manage to clear the certification in AWS, then guess what – AWS certified professionals have by far the maximum market demand! Simply because more than half of all Cloud Computing IaaS companies use AWS. The demand for AWS certifications is the maximum right now. To mention some figures: in 2019, 350,000 professionals will be required for AWS jobs. 60% of cloud computing jobs ask for AWS skills (naturally, considering that it has half the market share).
4. Worldwide Demand In Every Country that Has IT
It’s not just in the US that demand is peaking. There are jobs available in England, France, Australia, Canada, India, China, EU – practically every nation that wants to get into IT will welcome you with open arms if you are an AWS certified professional. And look no further than this site. AWS training will be offered soon, here: on Dimensionless.in. Within the next six months at the latest!
5. Affordable Pricing and Free One Year Tier to Learn AWS
Amazon has always been able to command the lowest prices because of its dominance in the market share. AWS offers you a free 1 year of paid services on its cloud IaaS platform. Completely free for one year. AWS training materials are also less expensive compared to other offerings. The following features are offered free for one single year under Amazon’s AWS free tier system:
The following is a web-scrape of their free-tier offering:
AWS Free Tier One Year Resources Available
There were initially seven pages in the Word document that I scraped from www.aws.com/free. To really have a look, go to the website on the previous link and see for yourself on the following link (much more details in much higher resolution). Please visit this last mentioned link. That alone will show you why AWS is sitting pretty on top of the cloud – literally.
Final Words
Right now, AWS rules the roost in cloud computing. But there is competition from Microsoft, Google, and IBM. Microsoft Azure has a lot of glitches which costs a lot to fix. Google Cloud Platform is cheaper but has very high technical support charges. A dark horse here: IBM Cloud. Their product has a lot of offerings and a lot of potential. Third only to Google and AWS. If you are working and want to go abroad or have a thirst for achievement, go for AWS. Totally. Finally, good news, all Dimensionless current students and alumni, the languages that AWS is built on has 100% support for Python! (It also supports, Go, Ruby, Java, Node.js, and many more – but Python has 100% support).
Keep coming to this website – expect to see AWS courses here in the near future!