The flux of data is increasing exponentially in this age of Digital awakening. Data has become so important to major industries and sectors around the globe that it can literally be referred to as digital gold! From simple company centric applications to major platforms interweaving people from all around the world, data has started to shape major decisions for not only autonomous machines, but also for the human race as a whole. This imagery is as intriguing as it is terrifying, but only if we make it so.
In order to handle this rapidly incoming data with relative ease, a competent system is required to act instantly and deliver results on the fly. Otherwise, such large-scale investments on data gathering and data generation will go to waste since the data will be left in its dormant state without any active or competent agent acting on it. This is where the concept of real time data streaming and processing comes up. So, what is real time data streaming?
As is already known, data is being generated from various sources at a lightening pace. If we stop to ingest enough data, process it in batches and then provide the results after enough time has passed, the results will tend to lose its relevance and will reflect outdated patterns and trends. This happens majorly because of the high rate of variance in incoming data and also because of time constraints.
For instance, suppose that you have a machine which tells you which horse to bet upon in a horse race. You have the option of changing your choice during the race until the last lap commences. In such a case, if your machine gives you predictions based on the first lap where horse A was showing promise, and predicts that horse A will win, where in fact, during the third lap, horse B shows further promise, you will lose your bet just because of a machine which lags behind by two laps. This problem can be avoided by processing incoming data instantly, or in other words, real time data streaming. A stack of old data or historical data is studied and incoming records are processed based on the studied patterns such that the results are delivered within milliseconds. For our example, the horse race prediction machine would have already studied data about the different horses in the race previously and then based on the incoming data (the horse number, position of the horse, time since beginning of race, number of contestants, etc.), will be able to instantly allocate a rank for the different participants with the help of real time data streaming.
How to Go About Real-Time Data Streaming?
In real time mission-critical applications, Apache Kafka has turned out to be one of the most widely used frameworks for implementation. Apache Kafka is integrated with efficient machine learning frameworks in order to enable model training and speedy deliverance by supporting real time data streaming.
What is Apache Kafka?
As per Kafka’s website, it defines itself and its tasks as follows:
“Kafka® is used for building real-time data pipelines and streaming apps. It is horizontally scalable, fault-tolerant, wicked fast, and runs in production in thousands of companies.”
“The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds. Its storage layer is essentially a “massively scalable pub/sub message queue designed as a distributed transaction log”, making it highly valuable for enterprise infrastructures to process streaming data.” – Wikipedia
These definitions might seem like a mouthful at first, but as we go through with this subject step by step in this discussion, one will easily get the hang of it in no time!
Why use Tensorflow as the machine learning platform which is to be integrated with Apache Kafka?
Tensorflow is one of the most popular and efficient open source machine learning platforms available. It has a beautiful and well-suited architecture which enables data flow with extreme grace and optimization. It enables users and developers to establish large-scale projects with minimal hassles and maximal resource optimization. It is thus, a very competent platform to integrate with Apache Kafka for the purpose of serving real-time data streaming.
Tensorflow’s tf.keras and tf.data are responsible for streaming data in and out. Previously however, these modules were limited in their usage and could only support a few data formats. Support for Kafka streaming was not included during the earlier versions of Tensorflow. It was also difficult to use Tensorflow supported modules like tf. Examples and TFRecord in Big data and the general community of Data Science as a whole and were, therefore, rarely spotted.
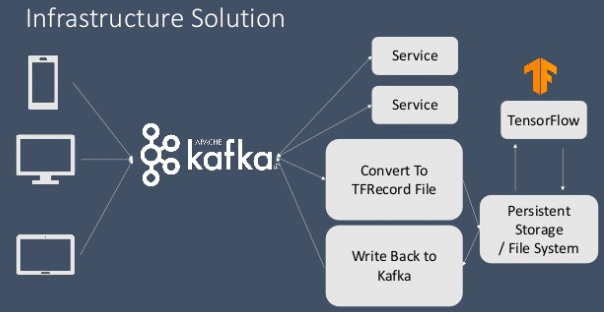
It was thus, a difficult task to integrate the Apache Kafka and Tensorflow frameworks. A lot of intermediary bridges had to be constructed in order to establish reliable handshakes between these two frameworks and ensure smooth integration. This was a burdensome process since it included designing of an entire infrastructure which turned out to be a fault prone mechanism most of the time. These were the steps which were required to be followed in order to establish a working data streaming flow:
Read data from the Kafka stream -> Convert to TFRecord format -> call Tensorflow’s function to read the TFRecord object from file system -> execute model and deliver result -> save the result in the file system again -> write results/ inference back to Kafka
Source: Kafka Summit NYC 2019, Yong Tang
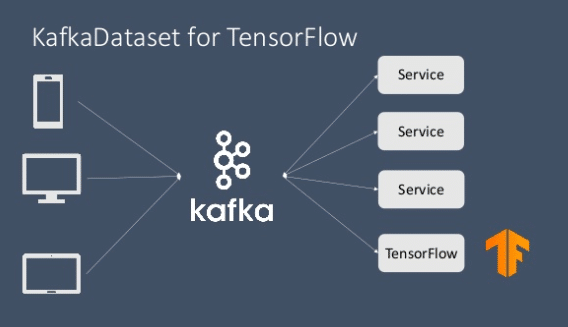
However, with the release of Tensorflow 2.0, the tables turned and the support for Apache Kafka data streaming module was issued along with support for a varied set of other data formats in the interest of the data science and statistics community (released in the IO package from Tensorflow: here).
Source: Kafka Summit NYC 2019, Yong Tang
With this development, it is now possible to enable real time streaming with Kafka and Tensorflow with relative ease and minimized error. This process is implemented with the use of KafkaDataset module (written in C++) which is a part of the new release of the Tensorflow IO package. KafkaDataset module has been integrated as a subclass of tf.data.Dataset module. This module works just like any other data streaming module where users can simply read data from a kafka stream and use it in a Tensorflow graph or feed it to tf.keras and other Tensorflow specific modules for model training and evaluation purpose. The option of writing back through output stream is also possible of course.
Here is how to implement data streaming, processing, model training and inference gathering in just a few lines of code with Kafka support on Tensorflow:
Line 2 simply streams in data with the help of the KafkaDataset module and data processing and modeling are immediately commenced as can be seen in lines 3 and 4. Thereafter, we move on to the keras callback stage. Keras callbacks are very informative since they provide an overview of the internal stages and statistical details of the model during the training or prediction process. The callback function is written in the 7th line. The KafkaOutputSequence is responsible for writing the results to the output stream (with so much relative ease!). In line 13 the predict function is called to get the model details and inference on the test dataset.
Source: Kafka Summit NYC 2019, Yong Tang
Real time data streaming with Kafka and Tensorflow has not only helped in the elimination of the complicated infrastructure which previously bridged the wide gap between the two popular platforms, but has also made the process less error prone and more approachable for real time mission critical systems with respect to machine learning and data science. The above picture shows how easy it is now to implement Kafka along with Tensorflow with just one call for data streaming. Further development in this area looks highly promising and is sure to contribute manifold in the ease of scalability and smooth integration when it comes to Big Data, live or real time data streaming, machine learning and deep learning techniques to develop smart and autonomous systems across the globe!
Get a grip on the machine learning, data science, big data and several other intriguing topics by following our blogs or even our detailed courses provided in the links below:
In a world where we generate data at an extremely fast rate, the correct analysis of the data and providing useful and meaningful results at the right time can provide helpful solutions for many domains dealing with data products. We can apply this in Health Care and Finance to Media, Retail, Travel Services and etc. some solid examples include Netflix providing personalized recommendations at real-time, Amazon tracking your interaction with different products on its platform and providing related products immediately, or any business that needs to stream a large amount of data at real-time and implement different analysis on it.
One of the amazing frameworks that can handle big data in real-time and perform different analysis, is Apache Spark. In this blog, we are going to use spark streaming to process high-velocity data at scale. We will be using Kafka to ingest data into our Spark code
What is Spark?
Apache Spark is a lightning-fast cluster computing technology, designed for fast computation. It is based on Hadoop MapReduce and it extends the MapReduce model to efficiently use it for more types of computations, which includes interactive queries and stream processing. The main feature of Spark is its in-memory cluster computing that increases the processing speed of an application.
Spark is designed to cover a wide range of workloads such as batch applications, iterative algorithms, interactive queries and streaming. Apart from supporting all these workloads in a respective system, it reduces the management burden of maintaining separate tools.
What is Spark Streaming?
Spark Streaming is an extension of the core Spark API that enables high-throughput, fault-tolerant stream processing of live data streams. Data can be ingested from many sources like Kafka, Flume, Twitter, ZeroMQ or TCP sockets and processed using complex algorithms expressed with high-level functions like map, reduce, join and window. Finally, processed data can be pushed out to file systems, databases, and live dashboards. Since Spark Streaming is built on top of Spark, users can apply Spark’s in-built machine learning algorithms (MLlib), and graph processing algorithms (GraphX) on data streams. Compared to other streaming projects, Spark Streaming has the following features and benefits:
Ease of Use: Spark Streaming brings Spark’s language-integrated API to stream processing, letting users write streaming applications the same way as batch jobs, in Java, Python and Scala.
Fault Tolerance: Spark Streaming is able to detect and recover from data loss mid-stream due to node or process failure.
How Does Spark Streaming Work?
Spark Streaming processes a continuous stream of data by dividing the stream into micro-batches called a Discretized Stream or DStream. DStream is an API provided by Spark Streaming that creates and processes micro-batches. DStream is nothing but a sequence of RDDs processed on Spark’s core execution engine like any other RDD. It can be created from any streaming source such as Flume or Kafka.
Difference Between Spark Streaming and Spark Structured Streaming
Spark Streaming is based on DStream. A DStream is represented by a continuous series of RDDs, which is Spark’s abstraction of an immutable, distributed dataset. Spark Streaming has the following problems.
Difficult — it was not simple to built streaming pipelines supporting delivery policies: exactly once guarantee, handling data arrival in late or fault tolerance. Sure, all of them were implementable but they needed some extra work from the part of programmers.
Inconsistent — API used to generate batch processing (RDD, Dataset) was different than the API of streaming processing (DStream). Sure, nothing blocker to code but it’s always simpler (maintenance cost especially) to deal with at least abstractions as possible.
Spark Structured Streaming be understood as an unbounded table, growing with new incoming data, i.e. can be thought as stream processing built on Spark SQL.
More concretely, structured streaming brought some new concepts to Spark.
Exactly-once guarantee — structured streaming focuses on that concept. It means that data is processed only once and output doesn’t contain duplicates.
Event time — one of the observed problems with DStream streaming was processing order, i.e the case when data generated earlier was processed after later generated data. Structured streaming handles this problem with a concept called event time that, under some conditions, allows to correctly aggregate late data in processing pipelines.
sink, Result Table, output mode and watermark are other features of spark structured-streaming.
Implementation Goal
In this blog, we will try to find the word count present in the sentences. The major point here will be that this time sentences will not be present in a text file. Sentences will come through a live stream as flowing data points. We will be counting the words present in the flowing data. Data, in this case, is not stationary but constantly moving. It is also known as high-velocity data. We will be calculating word count on the fly in this case! We will be using Kafka to move data as a live stream. Spark has different connectors available to connect with data streams like Kafka
Word Count Example Using Kafka
There are few steps which we need to perform in order to find word count from data flowing in through Kafka.
The initialization of Spark and Kafka Connector
Our main task is to create an entry point for our application. We also need to set up and initialise Spark Streaming in the environment. This is done through the following code
val sparkConf = new SparkConf().setAppName("DirectKafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
Since we have Spark Streaming initialised, we need to connect our application with Kafka to receive the flowing data. Spark has inbuilt connectors available to connect your application with different messaging queues. We need to put information here like a topic name from where we want to consume data. We need to define bootstrap servers where our Kafka topic resides. Once we provide all the required information, we will establish a connection to Kafka using the createDirectStream function. You can find the implementation below
Now, we need to process the sentences. We need to map through all the sentences as and when we receive them through Kafka. Upon receiving them, we will split the sentences into the words by using the split function. Now we need to calculate the word count. We can do this by using the map and reduce function available with Spark. For every word, we will create a key containing index as word and it’s value as 1. The key will look something like this <’word’, 1>. After that, we will group all the tuples using the common key and sum up all the values present for the given key. This will, in turn, return us the word count for a given specific word. You can have a look at the implementation for the same below
val lines = messages.map(_.value)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
wordCounts.print()
Finally, the processing will not start unless you invoke the start function with the spark streaming instance. Also, remember that you need to wait for the shutdown command and keep your code running to receive data through live stream. For this, we use the awaitTermination method. You can implement the above logic through the following two lines
ssc.start()
ssc.awaitTermination()
Full Code
package org.apache.spark.examples.streaming
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka010._
object DirectKafkaWordCount {
def main(args: Array[String]) {
if (args.length < 3) {
System.err.println(s"""
|Usage: DirectKafkaWordCount <brokers> <topics>
| <brokers> is a list of one or more Kafka brokers
| <groupId> is a consumer group name to consume from topics
| <topics> is a list of one or more kafka topics to consume from
|
""".stripMargin)
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
val Array(brokers, groupId, topics) = args
// Create context with 2 second batch interval
val sparkConf = new SparkConf().setAppName("DirectKafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
// Create direct kafka stream with brokers and topics
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,
ConsumerConfig.GROUP_ID_CONFIG -> groupId,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer])
val messages = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams))
// Get the lines, split them into words, count the words and print
val lines = messages.map(_.value)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
wordCounts.print()
// Start the computation
ssc.start()
ssc.awaitTermination()
}
}
// scalastyle:on println
Summary
Earlier, as Hadoop have high latency that is not right for near real-time processing needs. In most cases, we use Hadoop for batch processing while used Storm for stream processing. It leads to an increase in code size, a number of bugs to fix, development effort, and causes other issues, which makes the difference between Big data Hadoop and Apache Spark.
Ultimately, Spark Streaming fixed all those issues. It provides the scalable, efficient, resilient, and integrated system. This model offers both execution and unified programming for batch and streaming. Although there is a major reason for its rapid adoption, is the unification of distinct data processing capabilities. It becomes a hot cake for developers to use a single framework to attain all the processing needs. In addition, through Spark SQL streaming data can combine with static data sources.
Follow this link, if you are looking to learn more about data science online!
The amount of data produced by humans has exploded to unheard-of levels, with nearly 2.5 quintillion bytes of data created daily. With advances in the Internet of Things and mobile technology, data has become a central interest for most organizations. More importantly than simply collecting it, though, is the real need to properly analyze and interpret the data that is being gathered. Also, most businesses collect data from a variety of sources, and each data stream provides signals that ideally come together to form useful insights. However, getting the most out of your data depends on having the right tools to clean it, prepare it, merge it and analyze it properly.
Here are ten of the best analytics tools your company can take advantage of in 2019, so you can get the most value possible from the data you gather.
What is Big Data?
Big data is high-volume, high-velocity and/or high-variety information assets that demand cost-effective, innovative forms of information processing that enable enhanced insight, decision making, and process automation.
Furthermore, Big Data is nothing but any data which is very big to process and produce insights from it. Also, data being too large does not necessarily mean in terms of size only. There are 3 V’s (Volume, Velocity and Veracity) which mostly qualifies any data as Big Data. The volume deals with those terabytes and petabytes of data which is too large to process quickly. Velocity deals with data moving with high velocity. Continuous streaming data is an example of data with velocity and when data is streaming at a very fast rate may be like 10000 of messages in 1 microsecond. Veracity deals with both structured and unstructured data. Data that is unstructured or time-sensitive or simply very large cannot be processed by relational database engines. This type of data requires a different processing approach called big data, which uses massive parallelism on readily-available hardware.
Trending Big Data Tools in 2019
1. Apache Spark
Apache Spark is a fast and general-purpose cluster computing system. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.
Spark is designed to cover a wide range of workloads such as batch applications, iterative algorithms, interactive queries and streaming. Apart from supporting all these workloads in a respective system, it reduces the management burden of maintaining separate tools.
Apache Spark has the following features.
Speed − Spark helps to run an application in Hadoop cluster, up to 100 times faster in memory, and 10 times faster when running on disk. This is possible by reducing the number of reading/write operations to disk. It stores the intermediate processing data in memory.
Supports Multiple languages − Spark provides built-in APIs in Java, Scala, or Python. Therefore, you can write applications in different languages. Spark comes up with 80 high-level operators for interactive querying.
Advanced Analytics − Spark not only supports ‘Map’ and ‘reduce’. It also supports SQL queries, Streaming data, Machine learning (ML), and Graph Algorithms.
2. Apache Kafka
Apache Kafka is a community distributed event streaming platform capable of handling trillions of events a day. Initially conceived as a messaging queue, Kafka is based on an abstraction of a distributed commit log. Since being created and open sourced by LinkedIn in 2011, Kafka has quickly evolved from messaging queue to a full-fledged event streaming platform.
Following are a few benefits of Kafka −
Reliability − Kafka is distributed, partitioned, replicated and fault tolerance
Scalability − Kafka messaging system scales easily without downtime
Durability − Kafka uses Distributed commit log which means messages persists on disk as fast as possible, hence it is durable
Performance − Kafka has high throughput for both publishing and subscribing messages. It maintains stable performance even many TB of messages are stored.
Kafka is very fast and guarantees zero downtime and zero data loss.
3. Flink
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
It provides a high-throughput, low-latency streaming engine as well as support for event-time processing and state management. Flink applications are fault-tolerant in the event of machine failure and support exactly-once semantics. Programs can be written in Java, Scala, Python and SQL and are automatically compiled and optimized into dataflow programs that are executed in a cluster or cloud environment. Flink does not provide its own data storage system, but provides data source and sink connectors to systems such as Amazon Kinesis, Apache Kafka, Alluxio, HDFS, Apache Cassandra, and ElasticSearch.
4. Hadoop
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
Following are the few advantages of using Hadoop:
Hadoop framework allows the user to quickly write and test distributed systems. It is efficient, and it automatic distributes the data and work across the machines and in turn, utilizes the underlying parallelism of the CPU cores
Hadoop does not rely on hardware to provide fault-tolerance and high availability
You can add or remove the cluster dynamically and Hadoop continues to operate without interruption
Another big advantage of Hadoop is that apart from being open source, it is compatible with all the platforms
5. Cassandra
The Apache Cassandra database is the right choice when you need scalability and high availability without compromising performance. Linear scalability and proven fault-tolerance on commodity hardware or cloud infrastructure make it the perfect platform for mission-critical data. Cassandra’s support for replicating across multiple datacenters is best-in-class, providing lower latency for your users and the peace of mind of knowing that you can survive regional outages.
Cassandra has become so popular because of its outstanding technical features. Given below are some of the features of Cassandra:
Elastic Scalability — Cassandra is highly scalable; it allows to add more hardware to accommodate more customers and more data as per requirement
Always on Architecture — Cassandra has no single point of failure and it is continuously available for business-critical applications that cannot afford a failure
Fast linear-scale Performance — Cassandra is linearly scalable, i.e., it increases your throughput as you increase the number of nodes in the cluster. Therefore it maintains a quick response time
Flexible Data Storage — Cassandra accommodates all possible data formats including: structured, semi-structured, and unstructured. It can dynamically accommodate changes to your data structures according to your need
Easy Data Distribution — Cassandra provides the flexibility to distribute data where you need by replicating data across multiple data centers
Transaction Support — Cassandra supports properties like Atomicity, Consistency, Isolation, and Durability (ACID)
Fast Writes — Cassandra was designed to run on cheap commodity hardware. It performs blazingly fast writes and can store hundreds of terabytes of data, without sacrificing the read efficiency
6. Apache Storm
Apache Storm is a free and open source distributed real-time computation system. Storm makes it easy to reliably process unbounded streams of data, doing for real-time processing what Hadoop did for batch processing. The storm is simple, can be used with any programming language, and is a lot of fun to use!
It has many use cases: real-time analytics, online machine learning, continuous computation, distributed RPC, ETL, and more. The storm is fast: a benchmark clocked it at over a million tuples processed per second per node. It is scalable, fault-tolerant guarantees your data will be processed, and is easy to set up and operate.
7. RapidMiner
RapidMiner is a data science software platform by the company of the same name that provides an integrated environment for data preparation, machine learning, deep learning, text mining, and predictive analytics.
8. Graph Databases (Neo4J and GraphX)
Graph databases are NoSQL databases which use the graph data model comprised of vertices, which is an entity such as a person, place, object or relevant piece of data and edges, which represent the relationship between two nodes.
They are particularly helpful because they highlight the links and relationships between relevant data similarly to how we do so ourselves.
Even though graph databases are awesome, they’re not enough on their own.
Advanced second-generation NoSQL products like OrientDB, Neo4j are the future. The modern multi-model database provides more functionality and flexibility while being powerful enough to replace traditional DBMSs.
9. Elastic Search
Elasticsearch is a search engine based on the Lucene library. It provides a distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents.
Following are advantages of using elastic search:
Elasticsearch is over Java, which makes it compatible on almost every platform.
It is real time, in other words, after one second the added document is searchable in this engine.
Also, it is distributed, which makes it easy to scale and integrate into any big organization.
Creating full backups are easy by using the concept of the gateway, which is present in Elasticsearch.
Handling multi-tenancy is very easy in Elasticsearch
Elasticsearch uses JSON objects as responses, which makes it possible to invoke the Elasticsearch server with a large number of different programming languages.
Elasticsearch supports almost every document type except those that do not support text rendering.
10. Tableau
Exploring and analyzing big data translates information into insight. However, the massive scale, growth and variety of data are simply too much for traditional databases to handle. For this reason, businesses are turning towards technologies such as Hadoop, Spark and NoSQL databases to meet their rapidly evolving data needs. Tableau works closely with the leaders in this space to support any platform that our customers choose. Tableau lets you find that value in your company’s data and existing investments in those technologies so that your company gets the most out of its data. From manufacturing to marketing, finance to aviation– Tableau helps businesses see and understand Big Data.
Summary
Understanding your company’s data is a vital concern. Deploying any of the tools listed above can position your business for long-term success by focusing on areas of achievement and improvement.
Follow this link, if you are looking to learn more about data science online!