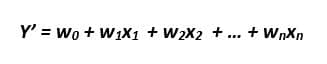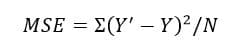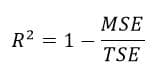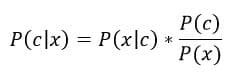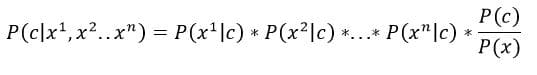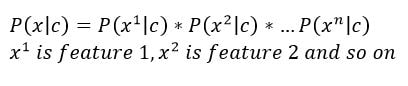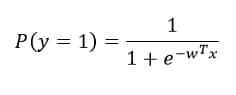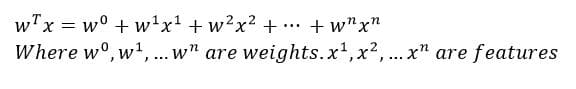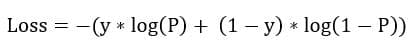When I started my Data Science journey, I casually Googled ‘Application of Machine Learning Algorithms’. For the next 10 minutes, I had my jaw hanging. Quite literally. Part of the reason was that they were all around me. That music video from YouTube recommendations that you ended up playing hundred times on loop? That’s Machine Learning for you. Ever wondered how Google keyboard completes your sentence better than your bestie ever could? Machine Learning again!
So how does this magic happen? What do you need to perform this witchcraft? Before you move further, let me tell you who would benefit from this article.
Someone who has just begun her/his Data Science journey and is looking for theory and application on the same platter.
Someone who has a basic idea of probability and linear algebra.
Someone who wants a brief mathematical understanding of ML and not just a small talk like the one you did with your neighbour this morning.
Someone who aims at preparing for a Data Science job interview.
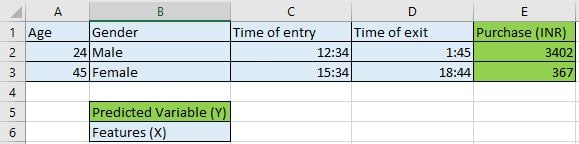
‘Machine Learning’ literally means that a machine (in this case an algorithm running on a computer) learns from the data it is fed. For example, you have customer data for a supermarket. The data consists of customers age, gender, time of entry and exit and the total purchase. You train a Machine Learning algorithm to learn the purchase pattern of customers and predict the purchase amount for a new customer by asking for his age, gender, time of entry and exit.
Now, Let’s dig deep and explore the workings of it.
Machine Learning (ML) Algorithms
Before we talk about the various classes, let us define some terms:
Seen data or Train Data –
This is all the information we have. For example, data of 1000 customers with their age, gender, time of entry and exit and their purchases.
Predicted Variable (or Y) –
The ML algorithm is trained to predict this variable. In our example, the ‘Purchase amount’. The predicted variable is usually called the dependent variable.
Features (or X) –
Everything in the data except for Y. Basically, the input that is fed to the model. Features are usually called the independent variable.
Model Parameters –
Parameters define our ML model. This will be understood later as we discuss each model. For now, remember that our main goal is to evaluate these parameters.
Unseen data or Test Data–
This is the data for which we have the X but not Y. The why has to be predicted using the ML model trained on the seen data.
Now that we have defined our terms, let’s move to the classes of Machine Learning or ML algorithms.
Supervised Learning Algorithms:
These algorithms require you to feed the data along with the predicted variable. The parameters of the model are then learned from this data in such a way that error in prediction is minimized. This will be more clear when individual algorithms are discussed.
Unsupervised Learning Algorithms:
These algorithms do not require data with predicted variables. Then what do we predict? Nothing. We just cluster these data points.
If you have any doubts about the things discussed above, keep on reading. It will get clearer as you see examples.
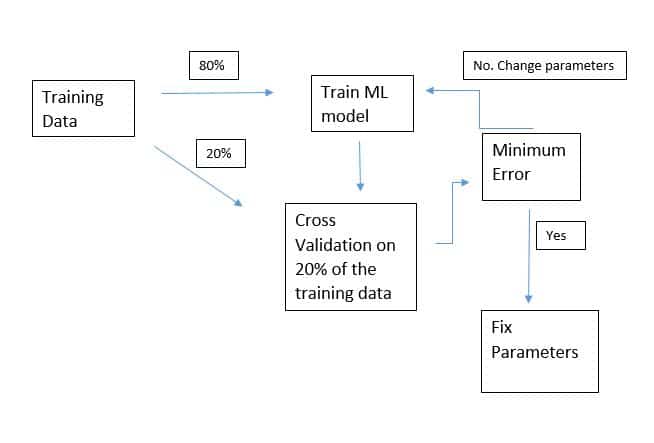
Cross-validation :
A general strategy used for setting parameters for any ML algorithm in general. You take out a small part of your training (seen) data, say 20%. You train an ML model on the 80% and then check it’s performance on that 20% of data (remember you have the Y values for this 20 %). You tweak the parameters until you get minimum error. Take a look at the flowchart below.
Supervised Learning Algorithms
In Supervised Machine Learning, there are two types of predictions – Regression or Classification. Classification means predicting classes of a data point. For example – Gender, Type of flower, Whether a person will pay his credit card bill or not. The predicted variable has 2 or more possible discrete values. Regression means predicting a numeric value of a data point. For example – Purchase amount, Age of a person, Price of a house, Amount of predicted rainfall, etc. The predicted class is a continuous variable. A few algorithms perform one of either task. Others can be used for both the tasks. I will mention the same for each algorithm we discuss. Let’s start with the most simple one and slowly move to more complex algorithms.
KNN: K-Nearest Neighbours
“You are the average of 5 people you surround yourself with”-John Rim
Congratulations! You just learned your first ML algorithm.
Don’t believe me? Let’s prove it!
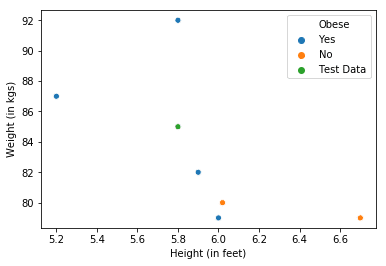
Consider the case of classification. Let’s set K, which is the number of closest neighbours to be considered equal to 3. We have 6 seen data points whose features are height and weight of individuals and predicted variable is whether or not they are obese.
Consider a point from the unseen data (in green). Our algorithm has to predict whether the person represented by the green data point is obese or not. If we consider it’s K(=3) nearest neighbours, we have 2 obese (blue) and one not obese (orange) data points. We take the majority vote of these 3 neighbours which is ‘Yes’. Hence, we predict this individual to be obese. In case of regression, everything remains the same, except that we take the average of the Y values of our K neighbours. How to set the value of K? Using cross-validation.
Key facts about KNN:
KNN performs poorly in higher dimensional data, i.e. data with too many features. (Curse of dimenstionality)
Euclidean distance is used for computing distance between continuous variables. If the data has categorical variables (gender, for example), Hamming distance is used for such variables. There are many popular distance measures used apart from these. You can find a detailed explanation here.
Linear Regression
This is yet another simple, but an extremely powerful model. It is only used for regression purposes. It is represented by
….(1)
Y’ is the value of the predicted variable according to the model. X1, X2,…Xn are input features. Wo, W1..Wn are the parameters (also called weights) of the model. Our aim is to estimate the parameters from the training data to completely define the model.
How do we do that? Let’s start with our objective which is to minimize the error in the prediction of our target variable. How do we define our error? The most common way is to use the MSE or Mean Squared Error –
For all N points, we sum the squares of the difference of the predicted value of Y by the model, i.e. Y’ and the actual value of the predicted variable for that point, i.e. Y.
We then replace Y’ with equation (1) and differentiate this MSE with respect to parameters W0,W1..Wn and equate it to 0 to get values of the parameters at which the error is minimum.
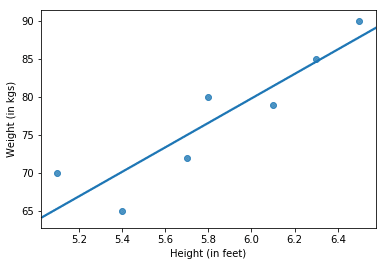
An example of how a linear regression might look like is shown below.
Sometimes it is not necessary that our dependent variable follows linear dependency on our independent variable. For example, Weight in the above graph may vary with the square of Height. This is called polynomial regression (Y varies with some power of X).
Good news is that any polynomial regression can be transformed to linear regression. How?
We transform the independent variable. Take a look at the Height variable in both the tables.
Table 1
table 2
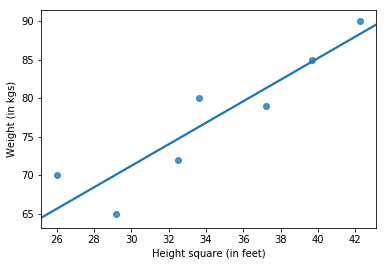
We will forget about Table 1 and treat the polynomial regression problem like a linear regression problem. Only this time, Weight will be linear in Height squared (notice the x-axis in the figure below).
A very important question about every ML model one should ask is – How do you measure the performance of the model? One popular measure is R-squared
R-squared: Intuitively, it measures how well the data and hence the model explains the variation in the dependent variable. How? Consider the following question – If you had just the Y values and no X values in your data, and someone asks you, “Hey! For this X, what would you predict the Y to be?” What would be your best guess? The average of all the Y values you have! In this scenario of limited information, you are better off guessing the average of Y for any X than anything other value of Y.
But, now that you have X and Y values, you want to see how well your linear regression model predicts Y for any unseen X. R-squared quantifies the performance of your linear regression model over this ‘baseline model’
MSE is the mean squared error as discussed before. TSE is the total squared error or the baseline model error.
Naive Bayes
Naive Bayes is a classification algorithm. As the name suggests, it is based on Bayes rule.
Intuitive Breakdown of Bayes rule: Consider a classification problem where we are asked to predict the class of a data point x. We have two classes and the classes are denoted by letter C.
Now, P(c), also known as the ‘Prior Probability’ is the probability of a data point belonging to class C, when we don’t have any data. For example, if we have 100 roses and 200 sunflowers and someone asks you to classify an unseen flower while providing you with no information, what would you say?
P(rose) = 100/300 = ⅓ P(sunflower) = 200/300 = ⅔
Since P(sunflower) is higher, your best guess would be a sunflower. P(rose) and P(sunflower) are prior probabilities of the two classes.
Now, you have additional information about your 300 flowers. The information is related to thorns on their stem. Look at the table below.
Flower\Thorns
Thorns
No Thorns
Rose (Total 100)
90
10
Sunflower (Total 200)
50
150
Now come back to the unseen flower. You are told that this unseen flower has thorns. Let this information about thorns be X.
Now according to Bayes rule, the numerator for the two classes are as follows –
Rose = 1/3*9/10 = 3/10 = 0.3
Sunflower = 2/3*1/3 = 2/9 = 0.22
The denominator, P(x), called the evidence is the cumulative probability of seeing the data point itself. In this case it is equal to 0.3 + 0.22 = 0.52. Since it does not depend on the class, it won’t affect our decision-making process. We will ignore it for our purposes.
Since, 0.3>0.22
P(Rose|X) > P(sunflower|X)
Therefore, our prediction would be that the unseen flower is a Rose. Notice that our prior probabilities of both the classes favoured Sunflower. But as soon as we factored the data about thorns, our decision changed.
If you understood the above example, you have a fair idea of the Naive Bayes Algorithm.
This simple example where we had only one feature (information about thorns) can be extended to multiple features. Let these features be x1, x2, x3 … xn. Bayes Rule would look like –
Note that we assume the features to be independent. Meaning,
The algorithm is called ‘Naive’ because of the above assumption
Logistic Regression
Logistic regression, unlike its name, is used for classification purposes. The mathematical model used for logistic regression is called the logit function. Consider two classes 0 and 1.
P(y=1) denotes the probability of belonging to class 1 and 1-P(y=1) is thus the probability of the data point belonging to class 0 (notice that the range of the function for all WT*X is between 0 and 1). Like other models, we need to learn the parameters w0, w1, w2, … wn to completely define the model. Like linear regression has MSE to quantify the loss for any error made in the prediction, logistic regression has the following loss function –
P is the probability of a data point belonging to class 1 as predicted by the model. Y is the actual class of the model.
Think about this – If the actual class of a data point is 1 and the model predicts P to be 1, we have 0 loss. This makes sense. On the other hand, if P was 0 for the same data point, the loss would be -infinity. This is the worst case scenario. This loss function is used in the Gradient Descent Algorithm to reach the parameters at which the loss is minimum.
Okay! So now we have a model that can predict the probability of an unseen data point belonging to class 1. But how do we make a decision for that point? Remember that our final goal is to assign classes, not just probabilities.
At what probability threshold do we say that the point belongs to class 1. Well, the model assigns the class according to the probabilities. If P>0.5, the class if obviously 1. However, we can change this threshold to maximize the metric of our interest ( precision, recall…), we can choose the best threshold using cross-validation.
This was Logistic Regression for you. Of course, do follow the coding tutorial!
Decision Tree
“Suppose there exist two explanations for an occurrence. In this case, the one that requires the least speculation is usually better.” – Occam’s Razor
The above philosophical principle precisely guides one of the most popular supervised ML algorithm. Decision trees, unlike other algorithms, are non-parametric algorithms. We don’t necessarily need to specify any parameter to completely define the model unlike KNN (where we need to specify K).
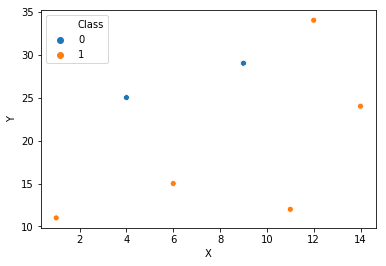
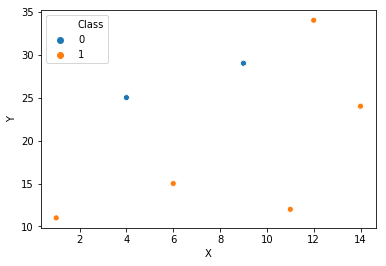
Let’s take an example to understand this algorithm. Consider a classification problem with two classes 1 and 0. The data has 2 features X and Y. The points are scattered on the X-Y plane as
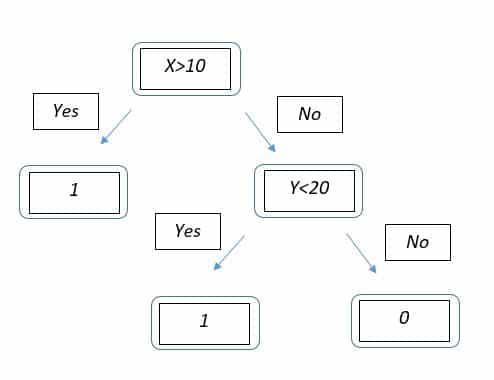
Our job is to make a tree that asks yes or no questions to a feature in order to create classification boundaries. Consider the tree below:
The tree has a ‘Root Node’ which is ‘X>10’. If yes, then the point lands at the leaf node with class 1. Else it goes to the other node where it is asked if its Y value is <20. Depending on the answer, it goes to either of the leaf nodes. Boundaries would look something like –
How to decide which feature should be chosen to bifurcate the data? The concept of ‘Purity ‘ is used here. Basically, we measure how pure (pure in 0s or pure in 1s) our data becomes on both the sides as compared to the node from where it was split. For example, if we have 50 1s and 50 0s at some node. After splitting, we have 40 1s and 10 0s on one side and 10 1s and 40 0s on the other, then we have a good splitting (one node is purer in 1s and the other in 0s). This goodness of splitting is quantified using the concept of Information Gain. Details can be found here.
Conclusion
If you have come so far, awesome job! You now have a fair level of understanding of basic ML algorithms along with their applications in Python. Now that you have a solid foundation, you can easily tackle advanced algorithms like Neural Nets, SVMs, XGBoost and many others.
The Nearest Neighbours algorithm is an optimization problem that was initially formulated in tech literature by Donald Knuth. The key behind the idea was to find out into which group of classes a random point in the search space belongs to, in a binary class, multiclass, continuous. unsupervised, or semi-supervised algorithm. Sounds mathematical? Let’s make it simple.
Imagine you are a shopkeeper who sells online. And you are trying to group your customers in such a way that products that are recommended for them come on the same page. Thus, a customer in India who buys a laptop will also buy a mouse, a mouse-pad, speakers, laptop sleeves, laptop bags, and so on. Thus you are trying to group this customer into a category. A class. How do you do this if you have millions of customers and over 100,000 products? Manual programming would not be the way to go. Here, the nearest neighbours method comes to the rescue.
You can group your customers into classes (for e.g. Laptop-Buyer, Gaming-Buyer, New-Mother, Children~10-years-old) and based upon what other people in those classes have bought in the past, you can choose to show them the items that they are the most likely to buy next, making their online shopping experience much easier and much more streamlined. How will you choose that? By grouping your customers into classes, and when a new customer comes, choosing which class he belongs to and showing him the products relevant for his class.
This is the essence of the ML algorithm that platforms such as Amazon and Flipkart use for every customer. Their algorithms are much more complex, but this is their essence.
The Nearest Neighbours topic can be divided into the following sub-topics:
Brute-Force Search
KD-Trees
Ball-Trees
K-Nearest Neighbours
Out of all of these, K-Nearest Neighbours (always referred to as KNNs) is by far the most commonly used.
K-Nearest Neighbours (KNNs)
A KNN algorithm is very simple, yet it can be used for some very complex applications and arcane dataset distributions. It can be used for binary classification, multi-class classification, regression, clustering, and even for creating new-algorithms that are state-of-the-art research techniques (e.g. https://www.hindawi.com/journals/aans/2010/597373/ – A Research Paper on a fusion of KNNs and SVMs). Here, we will describe an application of KNNs known as binary classification. On an extremely interesting dataset from the UCI-Repository (sonar.mines-vs-rocks).
Implementation
The algorithm of a KNN ML model is given below:
K-Nearest Neighbours
Again, mathematical! Let’s break it into small steps one at a time:
How the Algorithm Works
This explanation is for supervised learning binary classification.
Here we have two classes. We’ll call them A and B.
So the dataset is a collection of values which belong either to class A or class B.
A visual plot of the (arbitrary) data might look something like this:
Now, look at the star data point in the centre. To which class does it belong? A or B?
The answer? It varies according to the hyperparameters we use. In the above diagram, k is a hyperparameter.
They significantly affect the output of a machine learning (ML) algorithm when correctly tuned (set to the right values).
The algorithm then computes the ‘k’ points closest to the new point. The output is shown above when k = 3 and when k = 6 (k being the number of closest neighbouring points to indicate which class the new point belongs to).
Finally, we return a class as output which is closest to the new data point, according to various measures. The measures used include Euclidean distance among others.
This is how the K Nearest Neighbours algorithm works in principle. As you can see, visualizing the data is a big help to get an intuitive picture of what the k values should be.
Now, let’s see the K-Nearest-Neighbours Algorithm work in practice.
Note: This algorithm is powerful and highly versatile. It can be used for binary classification, multi-class classification, regression, clustering, and so on. Many use-cases are available for this algorithm which is quite simple but remarkably powerful, so make sure you learn it well so that you can use it in your projects.
Obtain the Data and Preprocess it
We shall use the data from the UCI Repository, available at the following link:
This data is a set of 207 sonar underwater readings by a submarine that have to be classified as rocks or underwater mines. Save the CSV file in the same directory as your Python source file and perform the following operations:
Import the required packages first:
import numpy as np
import pandas as pd
import scipy as sp
from datetime import datetime
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics.classification import accuracy_score
from sklearn.metrics.classification import confusion_matrix
from sklearn.metrics.classification import classification_report
Read the CSV dataset into your Python environment. And check out the top 5 rows using the head() Pandas DataFrame function.
Now, the last column is a letter. We need to encode it into a numerical value. For this, we can use LabelEncoder, as below:
#Inputs (data values) sonar readings from an underground submarine. Cool!
X = df.values[:,0:-1].astype(float)
# Convert classes M (Mine) and R to numbers, since they're categorical values
le = LabelEncoder()
#Classification target
target = df.R
# Do conversion
le = LabelEncoder.fit(le, y = ["R", "M"])
y = le.transform(target)
›
Now have a look at your target dataset. R (rock) and M (mine) has been converted into 1 and 0.
Execute the train_test_split partition function. This splits the inputs into 4 separate numpy arrays. We can control how the input data is split using the test_size or train_size parameters. Here the test size parameter is set to 0.3. Thus, 30% of the data goes into the test set and the remaining 70% (the complement) into the training set. We train (fit) the ML model on the training arrays and see how accurate our modes are on the test set. By default, the value is set to 0.25 (25%, 75%). Normally this sampling is randomized, so different results appear while being run each time. Setting random_state to a fixed value (any fixed value) makes sure that the same values are obtained every time we execute the model.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
Fit the KNN classifier to the dataset.
#Train kneighbors classifier
from sklearn.neighbors.classification import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors = 5, metric = "minkowski", p = 1)
# Fit the model
clf.fit(X_train, y_train)
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=5, p=1,
weights='uniform')
As of now , it is all right (at this level) to leave the defaults as they are. The output of the KNeighborClassifier has two values that you do need to know: metric and p. Right now we just need the Manhattan Distance, specified by p = 1 and metric = “minkowski“, so we’ll go with that, which specifies Manhattan distance, which is, the distance between two points measured along axes at right angles. In a plane with p1 at (x1, y1) and p2 at (x2, y2), it is |x1 – x2| + |y1 – y2|. (Source: https://xlinux.nist.gov/dads/HTML/manhattanDistance.html)
Output the statistical scoring of this classification model.
Accuracy on the set was 82%. Not bad, since my first implementation was on random forests classifier and top score was just 72%!
The entire program as source code in Python is available here as a downloadable sonar-classification.txt file (rename *.txt to *.py and you’re good to go.):
K-Nearest-Neighbours is a powerful algorithm to have in your machine learning classification arsenal. It is used so frequently that most clustering models always start with KNNs first. Use it, learn it in depth, and it will be incredibly useful to you in your entire data science career. I highly recommend the Wikipedia article since it covers nearly all applications of KNNs and much more.
Finally, Understand the Power of Machine Learning
Imagine trying to create a classical reading of this sonar-reading with 60 features, trying to solve this reading from a non-machine learning environment. You would have to load a 207 X 61 ~ 12k samples. Then you would have to develop an algorithm by hand to analyze the data!
Scikit-Learn, TensorFlow, Keras, PyTorch, AutoKeras bring such fantastic abilities to computers with respect to problems that could not be solved in the past before ML came along.
And this is just the beginning!
Automation is the Future
As ML and AI applications take root in our world more and more, humanity will be replaced by ‘intelligent’ software programs that perform operations like a human. We have chatbots in many companies already. Self-driving cars daily push the very limits of what we think a machine can do. The only question is, will you be on the side that is being replaced or will you be on the new forefront of technological progress? Get reskilled. Or just, start learning! Today, as soon as you can.
Building spam detection classifier using Machine learning and Neural Networks
Introduction
On our path of building an SMS SMAP classifier, we have till now converted our text data into a numeric form with help of a bag of words model. Using TF-IDF approach, we have now numeric vectors that describe our text data.
In this blog, we will be building a classifier that will help us to identify whether an incoming message is a spam or not. We will be using both machine learning and neural network approach to accomplish building classifier. If you are directly jumping to this blog then I will recommend you to go through part 1 and part 2 of building SPAM classifier series. Data used can be found here
Assessing the problem
Before jumping to machine learning, we need to identify what do we actually wish to do! We need to build a binary classifier which will look at a text message and will tell us whether that message is a spam or not. So we need to pick up those machine learning models which will help us to perform a classification task! Also note that this problem is a case of binary classification problem, as we have only two output classes into which texts will be classified by our model (0 – Message is not a spam, 1- Message is a spam)
We will build 3 machine learning classifiers namely SVM, KNN, and Naive Bayes! We will be implementing each of them one by one and in the end, have a look at the performance of each
Building an SVM classifier (Support Vector Machine)
A Support Vector Machine (SVM) is a discriminative classifier which separates classes by forming hyperplanes. In other words, given labeled training data (supervised learning), the algorithm outputs an optimal hyperplane which categorizes new examples. In two dimensional space, this hyperplane is a line dividing a plane into two parts wherein each class lay in either side.
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
vectoriser = TfidfVectorizer(decode_error="ignore")
X = vectoriser.fit_transform(list(training_dataset["comment"]))
y = training_dataset["b_labels"]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.30)
Till now, we have trained our model on the training dataset and have evaluated on a test set ( a data which our model has not seen ever). We have also performed a cross-validation over the classifier to make sure over trained model is free from any bias and variance issues!
Our SVM model with the linear kernel on this data will have a mean accuracy of 97.61% with 0.85 standard deviations. Cross-validation is important to tune the parameters of the model. In this case, we will select different kernels available with SVM and find out the best working kernel in terms of accuracy. We have reserved a separate test set to measure how well the tuned model is working on the never seen before data points.
Building a KNN classifier (K- nearest neighbor)
K-Nearest Neighbors (KNN) is one of the simplest algorithms which we use in Machine Learning for regression and classification problem. KNN algorithms use data and classify new data points based on similarity measures (e.g. distance function). Classification is done by a majority vote to its neighbors. The data is assigned to the class which has the most number of nearest neighbors. As you increase the number of nearest neighbors, the value of k, accuracy might increase.
Naive Bayes Classifiers rely on the Bayes’ Theorem, which is based on conditional probability or in simple terms, the likelihood that an event (A) will happen given that another event (B) has already happened. Essentially, the theorem allows a hypothesis to be updated each time new evidence is introduced. The equation below expresses Bayes’ Theorem in the language of probability:
Let’s explain what each of these terms means.
“P” is the symbol to denote probability.
P(A | B) = The probability of event A (hypothesis) occurring given that B (evidence) has occurred.
P(B | A) = The probability of event B (evidence) occurring given that A (hypothesis) has occurred.
P(A) = The probability of event B (hypothesis) occurring.
P(B) = The probability of event A (evidence) occurring.
Below is the code snippet for multinomial Naive Bayes classifier
We have till now implemented 3 classification algorithms for finding out the SPAM messages
SVM (Support Vector Machine)
KNN (K nearest neighbor)
Multinomial Naive Bayes
SVM, with the highest accuracy (97%), looks like the most promising model which will help us to identify SPAM messages. Anyone can say this by just looking at the accuracy right? But this may not be the actual case. In the case of classification problems, accuracy may not be the only metric you may want to have a look at. Feeling confused? I am sure you will be and allow me to introduce you to our friend Confusion Matrix which will eventually sort all your confusion out
Confusion Matrix
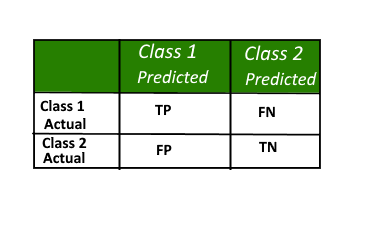
A confusion matrix, also known as error matrix, is a table which we use to describe the performance of a classification model (or “classifier”) on a set of test data for which the true values are known. It allows the visualization of the performance of an algorithm.
It allows easy identification of confusion between classes e.g. one class is commonly mislabeled as the other. Most performance measures are computed from the confusion matrix.
A confusion matrix is a summary of prediction results on a classification problem. The number of correct and incorrect predictions are summarized with count values and broken down by each class. This is the key to the confusion matrix. The confusion matrix shows the ways in which your classification model is confused when it makes predictions. It gives us insight not only into the errors being made by a classifier but more importantly the types of errors that are being made.
A sample confusion matrix for 2 classes
Definition of the Terms:
• Positive (P): Observation is positive (for example: is a SPAM).
• Negative (N): Observation is not positive (for example: is not a SPAM).
• True Positive (TP): Observation is positive, and the model predicted positive.
• False Negative (FN): Observation is positive, but the model predicted negative.
• True Negative (TN): Observation is negative, and the model predicted negative.
• False Positive (FP): Observation is negative, but the model predicted positive.
Let us bring two other metrics apart from accuracy which will help us to have a better look at our 3 models
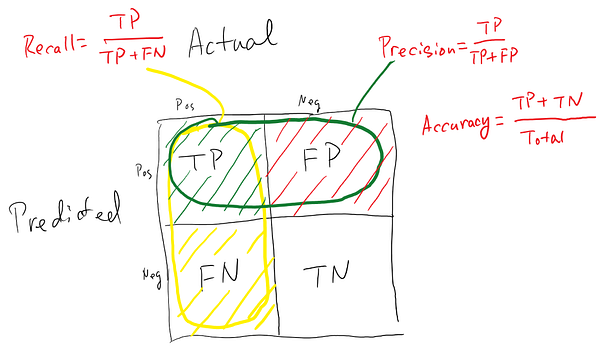
Recall:
The recall is the ratio of the total number of correctly classified positive examples divided to the total number of positive examples. High Recall indicates the class is correctly recognized (small number of FN).
Precision:
To get the value of precision we divide the total number of correctly classified positive examples by the total number of predicted positive examples. High Precision indicates an example labelled as positive is indeed positive (small number of FP).
Let us have a look at the confusion matrix of our SVM classifier and try to understand it. Consecutively, we will be summarising confusion matrix of all our 3 classifiers
Given below is the confusion matrix of the results which our SVM model has predicted on the test data. Let us find out accuracy, precision and recall in this case.
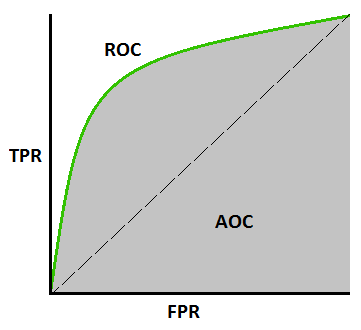
In Machine Learning, performance measurement is an essential task. So when it comes to a classification problem, we can count on an AUC – ROC Curve. It is one of the most important evaluation metrics for checking any classification model’s performance. It is also written as AUROC (Area Under theReceiver Operating Characteristics)
AUC – ROC curve is a performance measurement for classification problem at various thresholds settings. ROC is a probability curve and AUC represents the degree or measure of separability. It tells how much model is capable of distinguishing between classes. Higher the AUC, better the model is at predicting 0s as 0s and 1s as 1s. By analogy, Higher the AUC, better the model is at distinguishing between patients with disease and no disease.
We plot a ROC curve with TPR against the FPR where TPR is on y-axis and FPR is on the x-axis.
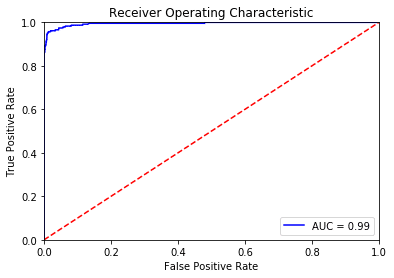
Let us have a look at the ROC curve of our SVM classifier
Always remember that the closer AUC (Area under the curve) is to value 1, the better the classification ability of the classifier. Furthermore, let us also have a look at the ROC curve of our KNN and Naive Bayes classifier too!
The graph on the left is for KNN and on the right is for Naive Bayes classifier. This clearly indicates that Naive Bayes classifier, in this case, is much more efficient than our KNN classifier as it has a higher AUC value!
Conclusion
In this series, we looked at understanding NLP from scratch to building our own SPAM classifier over text data. This is an ideal way to start learning NLP as it covers basics of NLP, word embeddings and numeric representations of text data and modeling over those numeric representations. You can also try neural networks for NLP as they are able to achieve good performance! Stay tuned for more on NLP in coming blogs.