Data scientists are one of the most hirable specialists today, but it’s not so easy to enter this profession without a “Projects” field in your resume. Furthermore, you need the experience to get the job, and you need the job to get the experience. Seems like a vicious circle, right? Also, the great advantage of data science projects is that each of them is a full-stack data science problem. Additionally, this means that you need to formulate the problem, design the solution, find the data, master the technology, build a machine learning model, evaluate the quality, and maybe wrap it into a simple UI. Hence, this is a more diverse approach than, for example, Kaggle competition or Coursera lessons.
Hence, in this blog, we will look at 10 projects to undertake in 2019 to learn data science and improve your understanding of different concepts.
Projects
1. Match Career Advice Questions with Professionals in the Field
Problem Statement: The U.S. has almost 500 students for every guidance counselor. Furthermore, youth lack the network to find their career role models, making CareerVillage.org the only option for millions of young people in America and around the globe with nowhere else to turn. Also, to date, 25,000 create profiles and opt-in to receive emails when a career question is a good fit for them. This is where your skills come in. Furthermore, to help students get the advice they need, the team at CareerVillage.org needs to be able to send the right questions to the right volunteers. The notifications for the volunteers seem to have the greatest impact on how many questions are answered.
Your objective: Develop a method to recommend relevant questions to the professionals who are most likely to answer them.
Problem Statement: In this competition, you must create an algorithm to identify metastatic cancer in small image patches taken from larger digital pathology scans. Also, the data for this competition is a slightly different version of the PatchCamelyon (PCam) benchmark dataset. PCam is highly interesting for both its size, simplicity to get started on, and approachability.
Your objective: Identify metastatic tissue in histopathologic scans of lymph node sections
Problem Statement: To assess the impact of climate change on Earth’s flora and fauna, it is vital to quantify how human activities such as logging, mining, and agriculture are impacting our protected natural areas. Furthermore, researchers in Mexico have created the VIGIA project, which aims to build a system for autonomous surveillance of protected areas. Moreover, the first step in such an effort is the ability to recognize the vegetation inside the protected areas. In this competition, you are tasked with the creation of an algorithm that can identify a specific type of cactus in aerial imagery.
Your objective: Determine whether an image contains a columnar cactus
Problem Statement: In a world, where movies made an estimate of $41.7 billion in 2018, the film industry is more popular than ever. But what movies make the most money at the box office? How much does a director matter? Or the budget? For some movies, it’s “You had me at ‘Hello. In this competition, you’re presented with metadata on over 7,000 past films from The Movie Database to try and predict their overall worldwide box office revenue. Also, the data points provided include cast, crew, plot keywords, budget, posters, release dates, languages, production companies, and countries. Furthermore, you can collect other publicly available data to use in your model predictions.
Your objective: Can you predict a movie’s worldwide box office revenue?
Problem Statement: An existential problem for any major website today is how to handle toxic and divisive content. Furthermore, Quora wants to tackle this problem head-on to keep their platform a place where users can feel safe sharing their knowledge with the world. On Quora, people can ask questions and connect with others who contribute unique insights and quality answers. A key challenge is to weed out insincere questions — those founded upon false premises, or that intend to make a statement rather than look for helpful answers.
In this competition, you need to develop models that identify and flag insincere questions. Moreover, to date, Quora has employed both machine learning and manual review to address this problem. With your help, they can develop more scalable methods to detect toxic and misleading content.
Your objective: Detect toxic content to improve online conversations
Problem Statement: This competition is provided as a way to explore different time series techniques on a relatively simple and clean dataset. You are given 5 years of store-item sales data and asked to predict 3 months of sales for 50 different items at 10 different stores. What’s the best way to deal with seasonality? Should stores be modelled separately, or can you pool them together? Does deep learning work better than ARIMA? Can either beat xgboost? Also, this is a great competition to explore different models and improve your skills in forecasting.
Your Objective: Predict 3 months of item sales at different stores
Problem Statement: This competition focuses on the problem of forecasting the future values of multiple time series, as it has always been one of the most challenging problems in the field. More specifically, we aim the competition at testing state-of-the-art methods designed by the participants, on the problem of forecasting future web traffic for approximately 145,000 Wikipedia articles. Also, the sequential or temporal observations emerge in many key real-world problems, ranging from biological data, financial markets, weather forecasting, to audio and video processing. Moreover, the field of time series encapsulates many different problems, ranging from analysis and inference to classification and forecast. What can you do to help predict future views?
Problem Statement: Forecast future traffic to Wikipedia pages
Problem Statement: What does physics have in common with biology, cooking, cryptography, diy, robotics, and travel? If you answer “all pursuits are under the immutable laws of physics” we’ll begrudgingly give you partial credit. Also, If you answer “people chose randomly for a transfer learning competition”, congratulations, we accept your answer and mark the question as solved.
In this competition, we provide the titles, text, and tags of Stack Exchange questions from six different sites. We then ask for tag predictions on unseen physics questions. Solving this problem via a standard machine approach might involve training an algorithm on a corpus of related text. Here, you are challenged to train on material from outside the field. Can an algorithm learn appropriate physics tags from “extreme-tourism Antarctica”? Let’s find out.
Your objective: Predict tags from models trained on unrelated topics
Problem Statement: MNIST (“Modified National Institute of Standards and Technology”) is the de facto “hello world” dataset of computer vision. Since its release in 1999, this classic dataset of handwritten images has served as the basis for benchmarking classification algorithms. As new machine learning techniques emerge, MNIST remains a reliable resource for researchers and learners alike. Furthermore, in this competition, your goal is to correctly identify digits from a dataset of tens of thousands of handwritten images.
Your objective: Learn computer vision fundamentals with the famous MNIST data
Problem Statement: The sinking of the RMS Titanic is one of the most infamous shipwrecks in history. On April 15, 1912, during her maiden voyage, the Titanic sank after colliding with an iceberg, killing 1502 out of 2224 passengers and crew. Furthermore, this sensational tragedy shocked the international community and led to better safety regulations for ships. Also, one of the reasons that the shipwreck led to such loss of life was that there were not enough lifeboats for the passengers and crew. Although there was some element of luck involved in surviving the sinking, some groups of people were more likely to survive than others, such as women, children, and the upper-class. In this challenge, we ask you to complete the analysis of what sorts of people were likely to survive.
Your objective: Predict survival on the Titanic and get familiar with ML basics
In the last blog, we had a look over visualizing text data and understood some basic concepts of tokenization and lemmatization. We wrote python function to perform all the operations for us. If you are directly jumping to this blog, I will highly recommend you to go through the previous blog post in which we have discussed the problem statement and some founding concepts of NLP.
We will be covering the following topics
Understanding Tf-IDF
Finding Important words using Tf-IDF
Understanding Bag of Words
Understanding Word Embedding
Different Types of word embeddings
Difference between word embeddings and Bag of words model
Preparing a word embedding for SPAM classifier
Introduction
Previously, we found out the most occurring/common words, bigrams, and trigrams from the messages separately for spam and non-spam messages. Now we need to also find out some important words that can themselves define whether a message is a spam or not. Take a note here that most occurring/common word in a set of messages may not be a keyword that determines what the entire sentence is all about.
For example, in a business article words like business, investment, acquisition are important words that may relate a sentence to a business article. Other words like money, good, building etc may be the frequent words in the messages but they do not have much relevant information to provide.
To find the important words, we will be using the method known as Term Frequency-Inverse Document Frequency (TF-IDF)
What is TF-IDF?
Tf-idf stands for term frequency-inverse document frequency, and the tf-idf weight is a weight often used in information retrieval and text mining.
TF means Term Frequency. It measures how frequently a term occurs in a document. Since every document is different in length, it is possible that a term would appear much more times in long documents than shorter ones. Thus, the term frequency is often divided by the document length as a way of normalization.
TF = (Number of times term w appears in a document) / (Total number of terms in the document)
Second part idf stands for Inverse Document Frequency. It measures how important a term is. While computing TF, all terms are equally important. However, it is known that certain terms, such as “is”, “of”, and “that”, may appear a lot of times but have little importance. Thus we need to weigh down the frequent terms while scaling up the rare ones.
IDF = log_e(Total number of documents / Number of documents with term w in it)
We calculate a final tf-idf score by multiplying TF score with IDF score for every word and then finally, we can filter out important words by selecting words with a higher Tf-Idf score.
Code Implementation
An example to calculate Tf-idf score for different words
Sentences = ["Ironman movie is really good. Ironman is always my favourite", "Titanic movie is very boring","Thor movie is really good"]
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
tfidf = TfidfVectorizer()
features = tfidf.fit_transform(Sentences)
pd.DataFrame(features.todense(),columns=tfidf.get_feature_names())
Finding Important words using Tf-IDF
Now we will need to find out which are the most important words in both spam and non-spam messages and then we will have a look at those words in the form of the word cloud. We will analyse those words and that will help us to relate why a particular message has been marked as a spam and other as a non-spam message.
First, we import the necessary libraries. Then I have a written a function that returns a TF-IDF score for all words in the corpus
from gensim.models import TfidfModel
from gensim.corpora import Dictionary
from gensim import corpora
from gensim import models
def get_tfidf_matrix(documents):
documents=[my_tokeniser(document) for document in documents]
dictionary = corpora.Dictionary(documents)
n_items = len(dictionary)
corpus = [dictionary.doc2bow(text) for text in documents]
tfidf = models.TfidfModel(corpus)
corpus_tfidf = tfidf[corpus]
return corpus_tfidf
Then we need to map all the scores to the words in the corpus in order to find the most important words
def get_tfidf_score_dataframe(sentiment_label):
frames = get_tfidf_matrix(training_dataset[training_dataset["Sentiment"]==sentiment_label]["Phrase"])
all_score=[]
all_words=[]
sentence_count=0
for frame in frames:
words=my_tokeniser(training_dataset[training_dataset["Sentiment"]==sentiment_label]["Phrase"].iloc[sentence_count])
sentence_count=sentence_count+1
for i in range(0,len(frame)):
all_score.append(frame[i])
all_words.append(words[i])
tf_idf_frame=pd.DataFrame({
'Words': all_words,
'Score': all_score
})
count=0
for key, val in tf_idf_frame["Score"]:
tf_idf_frame["Score"][count] = val
count=count+1
return tf_idf_frame
Finally, we plot all the important words in the form of a word cloud
We need a way to represent text data for the machine learning algorithm and the bag-of-words model helps us to achieve that task. The bag-of-words model is simple to understand and implement. It is a way of extracting features from the text for use in machine learning algorithms.
A bag-of-words is a representation of text that describes the occurrence of words within a document. It involves two things:
A vocabulary of known words.
A measure of the presence of known words.
Vocabulary can be attained by tokenising the messages into different unique tokens. After getting each token, we need to score that token. This can be done in the following ways
Counts. Count the number of times each word appears in a document.
Frequencies. Calculate the frequency that each word appears in a document out of all the words in the document.
TF-IDF : TF score * IDF score
How BoW works
Forming the vector
Take for example 2 text samples: The quick brown fox jumps over the lazy dogand.Never jump over the lazy dog quickly
Vectors are then formed to represent the count of each word. In this case, each text (i.e. the sentences) will generate a 10-element vector like so:
[1,1,1,0,1,1,0,1,1,0,2]
[0,1,0,1,0,1,1,1,0,1,1]
Each element represents the number of occurrence for each word in the corpus(text sample). So, in the first sentence, there is 1 count for “brown”, 1 count for “dog”, 1 count for “fox” and so on (represented by the first array). Whereas, the vector shows that there is 0 count of “brown”, 1 count for “dog” and 0 counts for “fox”, so on and so forth
Understanding Word Vectors
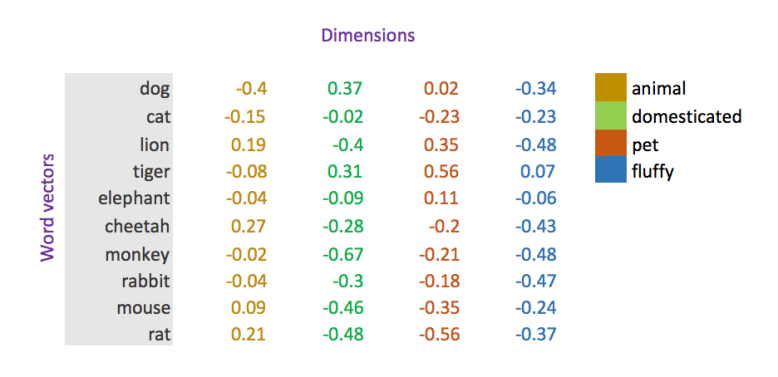
Word vectors are simply vectors of numbers that represent the meaning of a word.
Traditional approaches to NLP, such as one-hot encodings, do not capture syntactic (structure) and semantic (meaning) relationships across collections of words and, therefore, represent language in a very naive way.
Word vectors represent words as multidimensional continuous floating point numbers where semantically similar words are mapped to proximate points in geometric space. In simpler terms, a word vector is a row of real-valued numbers (as opposed to dummy numbers) where each point captures a dimension of the word’s meaning and where semantically similar words have similar vectors. This means that words such as wheel and engine should have similar word vectors to the word car (because of the similarity of their meanings), whereas the word banana should be quite distant.
A simple representation of word vectors
Now we will look at an example of using word vectors where we will group words of similar semantics together
import numpy as np
import spacy
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
nlp = spacy.load("en")
sentence = "Tiger was driving a car when he saw a fox taking the charge on a bike but in the end giraffe won the race using his aircraft"
tokens = nlp(sentence)
vectors = np.vstack([word.vector for word in tokens if word.has_vector])
pca = PCA(n_components=2)
vecs_transformed = pca.fit_transform(vectors)
vecs_transformed = np.c_[sentence.split(), vecs_transformed]
plt.figure(figsize = (16, 10), facecolor = None)
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
vectoriser = TfidfVectorizer(decode_error="ignore")
X = vectoriser.fit_transform(list(training_dataset["comment"]))
y = training_dataset["b_labels"]
d = pd.DataFrame(vecs_transformed)
d.columns=["Name","V1", "V2"]
v1 = [float(x) for x in d['V1']]
v2 = [float(x) for x in d['V2']]
plt.scatter(v1, v2)
for i, txt in enumerate(d['Name']):
plt.annotate(txt, (v1[i], v2[i]))
plt.show()
Preparing a bag of words model for Analysis
Below is the code snippet for converting our messages into a table which has numerical word vectors. After achieving this only, we can build our classifier using machine learning since machine learning always needs numerical inputs!
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
vectoriser = TfidfVectorizer(decode_error="ignore")
X = vectoriser.fit_transform(list(training_dataset["comment"]))
y = training_dataset["b_labels"]
## Ouput
print(X)
## <5572x8672 sparse matrix of type '<class 'numpy.float64'>'
## with 73916 stored elements in Compressed Sparse Row format>
Conclusion and Further steps
Till now we have learnt to perform EDA over text data. We have also learnt about important terms in NLP like tokenization, lemmatization, stop-words, tf-idf, the bag of words, and word-vectors. These terms are essential to master NLP. After having out word embedding ready, we will proceed to actually build machine learning models. They will help us to predict whether a message is a spam or not. In the next blog, we will build machine learning and neural network models and compare their performance. We will understand shortcomings of the neural net in the case of text mining. Finally, we will move to recurrent neural networks and LSTM to wrap up the series!
Part 1: Data Cleaning and Exploratory Data Analysis
Predicting whether an SMS is a spam
Natural language processing (NLP) is a subfield of computer science and artificial intelligence concerned with the interactions between computers and human (natural) languages.
When I first began learning NLP, it was difficult for me to process text and generate insights out of it. Before actually diving deep into NLP, I knew some of the basic techniques in NLP before but never could connect them together to view it as an end to end process of generating insights out of the text data.
In this blog, we will try to build a simple classifier using machine learning which will help in identifying whether a given SMS is a spam or not. Parallely, we will also be understanding a few basic components of Natural Language Processing (NLP) for the readers who are new to natural language processing.
Building SMS SPAM Classifier
In this section, we will be building a spam classifier step by step.
Step 1: Importing Libraries
We will be using pandas, numpy and Multinomial naive Bayes classifier for building a spam detector. Pandas will be used for performing operations on data frames. Furthermore using numpy, we will perform necessary mathematical operations.
from sklearn.naive_bayes import MultinomialNB
import pandas as pd
import numpy as np
Step 2: Reading the dataset and preparing it for basic processing in NLP
First, we read the csv using pandas read_csv function. We then modify the column names for easy references. In this dataset, the target variable is categorical (ham, spam) and we need to convert into a binary variable. Remember, machine learning models always take numbers as input and not the text hence we need to convert all categorical variables into numerical ones.
We replace ham with 0 (meaning not a spam) and spam with 1 (meaning that the SMS is a spam)
## Reading the dataset as a csv file
training_dataset = pd.read_csv("spam.csv", encoding="ISO-8859-1")
## Renaming columns
training_dataset.columns=["labels","comment"]
## Adding a new column to contain target variable
training_dataset["b_labels"] = [0 if x=="ham" else 1 for x in final_data["labels"] ]
Y = training_dataset["b_labels"].as_matrix()
training_dataset.head()
Step 3: Cleaning Data
Well, Cleaning text is one of the interesting and very important steps before performing any kind of analysis over it. Text from social media and another platform may contain many irregularities in it. People tend to express their feeling while writing and you may end up with words like gooood or goood or goooooooooooood in your dataset. Essentially all are same but we need to regularize this data first. I have made a function below which works fairly well in removing all the inconsistencies from the data.
Clean_data() function takes a sentence as it’s input and returns a cleaned sentence. This function takes care of the following
Removing web links from the text data as they are not pretty much useful
Correcting words like poooor and baaaaaad to poor and bad
Removing punctuations from the text
Removing apostrophes from the text to correct words like I’m to I am
Correcting spelling mistakes
Below is the snippet for clean_data function
def clean_data(sentence):
## removing web links
s = [ re.sub(r'http\S+', '', sentence.lower())]
## removing words like gooood and poooor to good and poor
s = [''.join(''.join(s)[:2] for _, s in itertools.groupby(s[0]))]
## removing appostophes
s = [remove_appostophes(s[0])]
## removing punctuations from the code
s = [remove_punctuations(s[0])]
return s[0]
Function to remove punctuations from the sentence
def remove_punctuations(my_str):
punctuations = '''!()-[]{};:'"\,./?@#$%^&@*_~'''
no_punct = ""
for char in my_str:
if char not in punctuations:
no_punct = no_punct + char
return no_punct
Function to remove apostrophes from the sentences
def remove_appostophes(sentence):
APPOSTOPHES = {"s" : "is", "re" : "are", "t": "not", "ll":"will","d":"had","ve":"have","m": "am"}
words = nltk.tokenize.word_tokenize(sentence)
final_words=[]
for word in words:
broken_words=word.split("'")
for single_words in broken_words:
final_words.append(single_words)
reformed = [APPOSTOPHES[word] if word in APPOSTOPHES else word for word in final_words]
reformed = " ".join(reformed)
return reformed
Example of using the clean_data function
## Sample Sentence to be cleaned
sentence="Goooood Morning! My Name is Joe & I'm going to watch a movie today https://youtube.com. ##"
## Using clean_data function
clean_data(sentence)
## Output
## good morning my name is joe i am going to watch a movie today
Now in order to process and clean all the text data in our dataset, we iterate over every text in the dataset and apply the clean_data function to retriever cleaner texts
for index in range(0,len(training_dataset["comment"])):
training_dataset.loc[index,"comment"] = clean_data(training_dataset["comment"].iloc[index])
Step 4: Understanding text data and finding Important words
After cleaning our text data, we want to analyze it but how de analyze text data? In the case of numbers, we could have gone with finding out mean, median, standard deviation, and other statistics to understand the data but how do we go about here?
We can not take a whole sentence up and generate meaning from it. Although, we can take words from those sentences and try to find out words that are frequently occurring in the text document or finding out the words which hold relatively higher importance in helping us understand what the complete sentence is about. In case of identifying a message as spam, we need to understand that are there any specific words or sequence of words that determine whether an SMS is a spam or not.
Tokenization and Lemmatization
We start by breaking each sentence into individual words. So a sentence like “Hey, You are awesome” will be broken into individual words into an array [‘hey’, ‘you’, ‘are’, ‘awesome’]. This process is known as tokenization and every single word is known as tokens. After getting each token, we try to get each token into its most basic form. For example, words like studies and goes will become study and go respectively. Also, remember that we need to remove stopwords like I, you, her, him etc as these words are very frequent in the text and hardly lead to any interpretation about any message being a spam or not!
Given below, I have made a tokenizer function which will take each sentence as input. It splits the sentence into individual tokens and then lemmatizes those words. In the end, we remove stop words from the tokens we have and return these tokens as an array.
def my_tokeniser(s):
s = clean_data(s)
s = s.lower()
tokens = nltk.tokenize.word_tokenize(s)
tokens = [t for t in tokens if len(t)>2]
tokens = [wordnet_lemmatizer.lemmatize(t) for t in tokens]
tokens = [t for t in tokens if t not in stopwords]
return tokens
Example showing the working of my_tokeniser function
## Sample Sentence
sentence="The car is speeding down the hill"
## Tokenising the sentence
my_tokeniser(sentence)
## Output
Array: ["car", "speed", "down", "hill"]
Understanding n-grams
An n-gram is a contiguous sequence of n items from a given sequence of text. Given a sentence, swe can construct a list of n-grams from s finding pairs of words that occur next to each other. For example, given the sentence “I am Kartik” you can construct bigrams (n-grams of length 2) by finding consecutive pairs of words which will be (“I”, “am”), (“am”, “Kartik”).
A consecutive pair of three words is known as tri-grams. This will help us to understand how exactly a sequence of tokens together determines whether an incoming message is a spam or not. In natural language processing (NLP), n-grams hold a lot of importance as they determine how sequences of words affect the meaning of a sentence.
We will be finding out most common bi-grams and tri-grams from the messages we have in the dataset separately for both spam and non-spam messages and consecutively will have a look at most commonly occurring sequences of text in each category.
Code for finding out bi-grams and tri-grams
Below is a python function which takes two input parameters i.e. label and n. The “label” parameter is the target label of the message. For spam messages, it is 1 whereas for non-spam messages it is 0. The “n” parameter is for selecting whether we want to extract bi-grams out or tri-grams out from the sentences. A too much high value for n will not make any sense as long sequences of text are majorly not common throughout the data
def get_grams(label,n):
bigrams = []
for sentence in training_dataset[training_dataset["Sentiment"]==sentiment_label]["Phrase"]:
tokens = my_tokeniser(sentence)
bigrams.append(tokens)
bigrams_final=[]
bigrams_values=0
bigrams_labels=0
if(n==2):
for bigram in bigrams:
for i in range(0,len(bigram)-1):
bigram_list_basic=bigram[i]+" "+bigram[i+1]
bigrams_final.append(bigram_list_basic)
else:
for bigram in bigrams:
for i in range(0,len(bigram)-2):
bigram_list_basic=bigram[i]+" "+bigram[i+1]+" "+bigram[i+2]
bigrams_final.append(bigram_list_basic)
bigrams_final = pd.DataFrame(bigrams_final)
bigrams_final.columns=["bigrams"]
bigrams_values=bigrams_final.groupby("bigrams")["bigrams"].count()
bigrams_labels=bigrams_final.groupby("bigrams").groups.keys()
bigrams_final_result = pd.DataFrame(
{
"bigram":[*bigrams_labels],
"count":bigrams_values
}
)
return bigrams_final_result
We will call the below function to directly plot all the common bigrams or trigrams as a word cloud. This function calls the above function to get all the bi_grams or tri_grams from the messages we have and will then plot it
Visualizing most frequent trigrams for non-spam messages
plot_grams(spam_label=0, gram_n=3)
Visualizing most frequent trigrams for spam messages
plot_grams(spam_label=1, gram_n=3)
Conclusion
Till now we have learned how to start with cleaning and understanding data. This process needs to be done before any kind of text analysis. One should always start with cleaning the text and then move on to fetch tokens out of the text. Getting tokens out of the text also requires to exclude stop words. Also, we need to get all the other words into their basic morphological form using lemmatization. In the next blog, we will have a look at finding out important words from the text data. We will also learn the word embeddings. In the end, we will finally build a classifier to segregate spam SMS out.