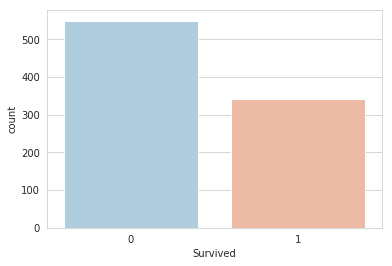I am so thrilled to welcome you to the absolutely awesome world of data science. It is an interesting subject, sometimes difficult, sometimes a struggle but always hugely rewarding at the end of your work. While data science is not as tough as, say, quantum mechanics, it is not high-school algebra either.
It requires knowledge of Statistics, some Mathematics (Linear Algebra, Multivariable Calculus, Vector Algebra, and of course Discrete Mathematics), Operations Research (Linear and Non-Linear Optimization and some more topics including Markov Processes), Python, R, Tableau, and basic analytical and logical programming skills.
.Now if you are new to data science, that last sentence might seem more like pure Greek than simple plain English. Don’t worry about it. If you are studying the Data Science course at Dimensionless Technologies, you are in the right place. This course covers the practical working knowledge of all the topics, given above, distilled and extracted into a beginner-friendly form by the talented course material preparation team.
This course has turned ordinary people into skilled data scientists and landed them with excellent placement as a result of the course, so, my basic message is, don’t worry. You are in the right place and with the right people at the right time.
What is Data Science?
To quote Wikipedia:
Data science is a multi-disciplinary field that uses scientific methods, processes, algorithms, and systems to extract knowledge and insights from structured and unstructured data. Data science is the same concept as data mining and big data: “use the most powerful hardware, the most powerful programming systems, and the most efficient algorithms to solve problems.”
Data Science is the art of extracting critical knowledge from raw data that provides significant increases in profits for your organization.
We are surrounded by data (Google ‘data deluge’ and you’ll see what I mean). More data has been created in the last two years that in the last 5,000 years of human existence.
The companies that use all this data to gain insights into their business and optimize their processing power will come out on top with the maximum profits in their market.
Companies like Facebook, Amazon, Microsoft, Google, and Apple (FAMGA), and every serious IT enterprise have realized this fact.
Hence the demand for talented data scientists.
I have much more to share with you on this topic, but to keep this article short, I’ll just share the links below which you can go through in your free time (everyone’s time is valuable because it is a strictly finite resource):
Now as I was planning this article a number of ideas came to my mind. I thought I could do a textbook-like reference to the field, with Python examples.
But then I realized that true competence in data science doesn’t come when you read an article.
True competence in data science begins when you take the programming concepts you have learned, type them into a computer, and run it on your machine.
And then; of course, modify it, play with it, experiment, run single lines by themselves, see for yourselves how Python and R work.
That is how you fall in love with coding in data science.
At least, that’s how I fell in love with simple C coding. Back in my UG in 2003. And then C++. And then Java. And then .NET. And then SQL and Oracle. And then… And then… And then… And so on.
If you want to know, I first started working in back-propagation neural networks in the year 2006. Long before the concept of data science came along! Back then, we called it artificial intelligence and soft computing. And my final-year project was coded by hand in Java.
Having come so far, what have I learned?
That it’s a vast massive uncharted ocean out there.
The more you learn, the more you know, the more you become aware of how little you know and how vast the ocean is.
But we digress!
To get back to my point –
My final decision was to construct a beginner project, explain it inside out, and give you source code that you can experiment with, play with, enjoy running, and modify here and there referring to the documentation and seeing what everything in the code actually does.
Kaggle – Your Home For Data Science
www.kaggle.com
If you are in the data science field, this site should be on your browser bookmark bar. Even in multiple folders, if you have them.
Kaggle is the go-to site for every serious machine learning practitioner. They hold competitions in data science (which have a massive participation), have fantastic tutorials for beginners, and free source code open-sourced under the Apache license (See this link for more on the Apache open source software license – don’t skip reading this, because as a data scientist this is something about software products that you must know).
As I was browsing this site the other day, a kernel that was attracting a lot of attention and upvotes caught my eye.
This kernel is by a professional data scientist by the name of Fatma Kurçun from Istanbul (the funny-looking ç symbol is called c with cedilla and is pronounced with an s sound).
It was quickly clear why it was so popular. It was well-written, had excellent visualizations, and a clear logical train of thought. Her professionalism at her art is obvious.
Since it is an open source Apache license released software, I have modified her code quite a lot (diff tool gives over 100 changes performed) to come up with the following Python classification example.
But before we dive into that, we need to know what a data science project entails and what classification means.
Let’s explore that next.
Classification and Data Science
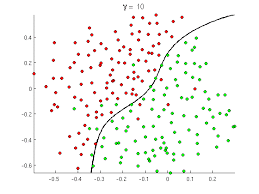
So supervised classification basically means mapping data values to a category defined in advance. In the image above, we have a set of customers who have certain data values (records). So one dot above corresponds with one customer with around 10-20 odd fields.
Now, how do we ascertain whether a customer is likely to default on a loan, and which customer is likely to be a non-defaulter? This is an incredibly important question in the finance field! You can understand the word, “classification”, here. We classify a customer into a defaulter (red dot) class (category) and a non-defaulter (green dot) class.
This problem is not solvable by standard methods. You cannot create and analyze a closed-form solution to this problem with classical methods. But – with data science – we can approximate the function that captures or models this problem, and give a solution with an accuracy range of 90-95%. Quite remarkable!
Now, again we can have a blog article on classification alone, but to keep this article short, I’ll refer you to the following excellent articles as references:
At some time in your machine learning career, you will need to go through the article above to understand what a machine learning project entails (the bread-and-butter of every data scientist).
Jupyter Notebooks
From Wikipedia
To run the exercises in this section, we use a Jupyter notebook. Jupyter is short for Julia, Python, and R. This environment uses kernels of any of these languages and has an interactive format. It is commonly used by data science professionals and is also good for collaboration and for sharing work.
To know more about Jupyter notebooks, I can suggest the following article (read when you are curious or have the time):
Data Science Libraries in Python
The standard data science stack for Python has the scikit-learn Python library as a basic lowest-level foundation.
The scikit-learn python library is the standard library in Python most commonly used in data science. Along with the libraries numpy, pandas, matplotlib, and sometimes seaborn as well this toolset is known as the standard Python data science stack. To know more about data science, I can direct you to the documentation for scikit-learn – which is excellent. The text is lucid, clear, and every file contains a working live example as source code. Refer to the following links for more:
This last link is like a bible for machine learning in Python. And yes, it belongs on your browser bookmarks bar. Reading and applying these concepts and running and modifying the source code can help you go a long way towards becoming a data scientist.
This is the classification standard data science beginner problem that we will consider. To quote Kaggle.com:
The sinking of the RMS Titanic is one of the most infamous shipwrecks in history. On April 15, 1912, during her maiden voyage, the Titanic sank after colliding with an iceberg, killing 1502 out of 2224 passengers and crew. This sensational tragedy shocked the international community and led to better safety regulations for ships.
One of the reasons that the shipwreck led to such loss of life was that there were not enough lifeboats for the passengers and crew. Although there was some element of luck involved in surviving the sinking, some groups of people were more likely to survive than others, such as women, children, and the upper-class.
In this challenge, we ask you to complete the analysis of what sorts of people were likely to survive. In particular, we ask you to apply the tools of machine learning to predict which passengers survived the tragedy.
We’ll be trying to predict a person’s category as a binary classification problem – survived or died after the Titanic sank.
So now, we go through the popular source code, explaining every step.
Import Libraries
These lines given below:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt;
import seaborn as sns
%matplotlib inline
Are standard for nearly every Python data stack problem. Pandas refers to the data frame manipulation library. NumPy is a vectorized implementation of Python matrix manipulation operations that are optimized to run at high speed. Matplotlib is a visualization library typically used in this context. Seaborn is another visualization library, at a little higher level of abstraction than matplotlib.
The Problem Data Set
We read the CSV file:
train = pd.read_csv('../input/train.csv')
Exploratory Data Analysis
Now, if you’ve gone through the links given in the heading ‘Steps involved in Data Science Projects’ section, you’ll know that real-world data is messy, has missing values, and is often in need of normalization to adjust for the needs of our different scikit-learn algorithms. This CSV file is no different, as we see below:
Missing Data
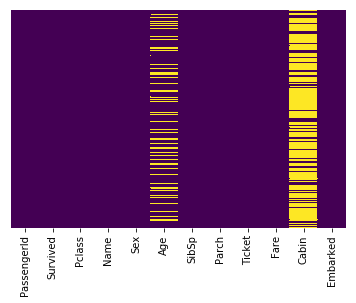
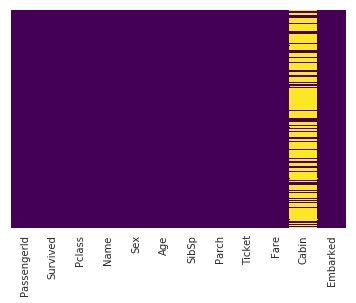
This line uses seaborn to create a heatmap of our data set which shows the missing values:
<matplotlib.axes._subplots.AxesSubplot at 0x7f3b5ed98ef0>
Interpretation
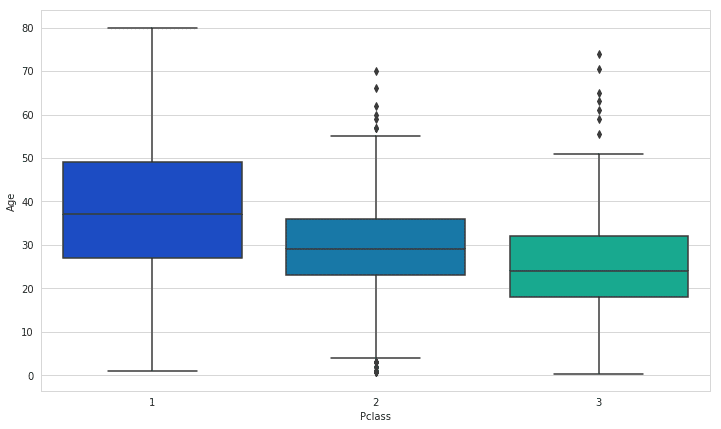
The yellow bars indicate missing data. From the figure, we can see that a fifth of the Age data is missing. And the Cabin column has so many missing values that we should drop it.
Graphing the Survived vs. the Deceased in the Titanic shipwreck:
<matplotlib.axes._subplots.AxesSubplot at 0x7f3b54fe2390>
As we can see, in our sample of the total data, more than 500 people lost their lives, and less than 350 people survived (in the sample of the data contained in train.csv).
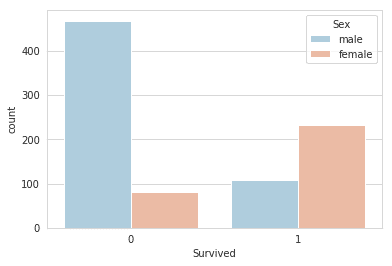
<matplotlib.axes._subplots.AxesSubplot at 0x7f3b54f49da0>
Over 400 men died, and around 100 survived. For women, less than a hundred died, and around 230 odd survived. Clearly, there is an imbalance here, as we expect.
Data Cleaning
The missing age data can be easily filled with the average of the age values of an arbitrary category of the dataset. This has to be done since the classification algorithm cannot handle missing values and will be error-ridden if the data values are not error-free.
<matplotlib.axes._subplots.AxesSubplot at 0x7f3b54d132e8>
We use these average values to impute the missing values (impute – a fancy word for filling in missing data values with values that allow the algorithm to run without affecting or changing its performance).
def impute_age(cols):
Age = cols[0]
Pclass = cols[1]
if pd.isnull(Age):
if Pclass == 1:
return 37
elif Pclass == 2:
return 29
else:
return 24
else:
return Age
We use one-hot encoding to convert the categorical attributes to numerical equivalents. One-hot encoding is yet another data preprocessing method that has various forms. For more information on it, see the link
sex = pd.get_dummies(train['Sex'],drop_first=True)
embark = pd.get_dummies(train['Embarked'],drop_first=True)
train.drop(['Embarked','Name','Ticket'],axis=1,inplace=True)
train = pd.concat([train,sex,embark],axis=1)
<matplotlib.axes._subplots.AxesSubplot at 0x7f3b54743ac8>
No missing data and all text converted accurately to a numeric representation means that we can now build our classification model.
Building a Gradient Boosted Classifier model
Gradient Boosted Classification Trees are a type of ensemble model that has consistently accurate performance over many dataset distributions. I could write another blog article on how they work but for brevity, I’ll just provide the link here and link 2 here:
We split our data into a training set and test set.
The performance of a classifier can be determined by a number of ways. Again, to keep this article short, I’ll link to the pages that explain the confusion matrix and the classification report function of scikit-learn and of general classification in data science:
A wonderful article by one of our most talented writers. Skip to the section on the confusion matrix and classification accuracy to understand what the numbers below mean.
For a more concise, mathematical and formulaic description, read here
from sklearn.metrics import classification_report,confusion_matrix
print(confusion_matrix(y_test,predictions))
[[89 16]
[29 44]]
So as not make this article too disjointed, let me explain at least the confusion matrix to you.
The confusion matrix has the following form:
[[ TP FP ]
[ FN TN ]]
The abbreviations mean:
TP – True Positive – The model correctly classified this person as deceased.
FP – False Positive – The model incorrectly classified this person as deceased.
FN – False Negative – The model incorrectly classified this person as a survivor
TN – True Negative – The model correctly classified this person as a survivor.
So, in this model published on Kaggle, there were:
So the model, when used with Gradient Boosted Classification Decision Trees, has a precision of 75% (the original used Logistic Regression).
Wrap-Up
I have attached the dataset and the Python program to this document, you can download it by clicking on these links. Run it, play with it, manipulate the code, view the scikit-learn documentation. As a starting point, you should at least:
Use other algorithms (say LogisticRegression / RandomForestClassifier a the very least)
Refer the following link for classifiers to use: Sections 1.1 onwards – every algorithm that has a ‘Classifier’ ending in its name can be used – that’s almost 30-50 odd models!
Try to compare performances of different algorithms
Try to combine the performance comparison into one single program, but keep it modular.
Make a list of the names of the classifiers you wish to use, apply them all and tabulate the results. Refer to the following link:
Use XGBoost instead of Gradient Boosting
Titanic Training Dataset (here used for training and testing):
Clone with Git (use TortoiseGit for simplicity rather than the command-line) and enjoy.
To use Git, take the help of a software engineer or developer who has worked with it before. I’ll try to cover the relevance of Git for data science in a future article.
Install Git and TortoiseGit (the latter only if necessary)
Open the command line with Run… cmd.exe
Create an empty directory.
Copy paste the following string into the command prompt and watch the magic after pressing Enter: “git clone https://github.com/thomascherickal/datasciencewithpython-article-src.git” without the double quotes, of course.
Use Anaconda (a common data science development environment with Python,, R, Jupyter, and much more) for best results.
Cheers! All the best into your wonderful new adventure of beginning and exploring data science!
Learning done right can be awesome fun! (Unsplash)
There are a huge number of ML algorithms out there. Trying to classify them leads to the distinction being made in types of the training procedure, applications, the latest advances, and some of the standard algorithms used by ML scientists in their daily work. There is a lot to cover, and we shall proceed as given in the following listing:
Statistical Algorithms
Classification
Regression
Clustering
Dimensionality Reduction
Ensemble Algorithms
Deep Learning
Reinforcement Learning
AutoML (Bonus)
1. Statistical Algorithms
Statistics is necessary for every machine learning expert. Hypothesis testing and confidence intervals are some of the many statistical concepts to know if you are a data scientist. Here, we consider here the phenomenon of overfitting. Basically, overfitting occurs when an ML model learns so many features of the training data set that the generalization capacity of the model on the test set takes a toss. The tradeoff between performance and overfitting is well illustrated by the following illustration:
Overfitting – from Wikipedia
Here, the black curve represents the performance of a classifier that has appropriately classified the dataset into two categories. Obviously, training the classifier was stopped at the right time in this instance. The green curve indicates what happens when we allow the training of the classifier to ‘overlearn the features’ in the training set. What happens is that we get an accuracy of 100%, but we lose out on performance on the test set because the test set will have a feature boundary that is usually similar but definitely not the same as the training set. This will result in a high error level when the classifier for the green curve is presented with new data. How can we prevent this?
Cross-Validation
Cross-Validation is the killer technique used to avoid overfitting. How does it work? A visual representation of the k-fold cross-validation process is given below:
From Quora
The entire dataset is split into equal subsets and the model is trained on all possible combinations of training and testing subsets that are possible as shown in the image above. Finally, the average of all the models is combined. The advantage of this is that this method eliminates sampling error, prevents overfitting, and accounts for bias. There are further variations of cross-validation like non-exhaustive cross-validation and nested k-fold cross validation (shown above). For more on cross-validation, visit the following link.
There are many more statistical algorithms that a data scientist has to know. Some examples include the chi-squared test, the Student’s t-test, how to calculate confidence intervals, how to interpret p-values, advanced probability theory, and many more. For more, please visit the excellent article given below:
Classification refers to the process of categorizing data input as a member of a target class. An example could be that we can classify customers into low-income, medium-income, and high-income depending upon their spending activity over a financial year. This knowledge can help us tailor the ads shown to them accurately when they come online and maximises the chance of a conversion or a sale. There are various types of classification like binary classification, multi-class classification, and various other variants. It is perhaps the most well known and most common of all data science algorithm categories. The algorithms that can be used for classification include:
Logistic Regression
Support Vector Machines
Linear Discriminant Analysis
K-Nearest Neighbours
Decision Trees
Random Forests
and many more. A short illustration of a binary classification visualization is given below:
From openclassroom.stanford.edu
For more information on classification algorithms, refer to the following excellent links:
Regression is similar to classification, and many algorithms used are similar (e.g. random forests). The difference is that while classification categorizes a data point, regression predicts a continuous real-number value. So classification works with classes while regression works with real numbers. And yes – many algorithms can be used for both classification and regression. Hence the presence of logistic regression in both lists. Some of the common algorithms used for regression are
Linear Regression
Support Vector Regression
Logistic Regression
Ridge Regression
Partial Least-Squares Regression
Non-Linear Regression
For more on regression, I suggest that you visit the following link for an excellent article:
Both articles have a remarkably clear discussion of the statistical theory that you need to know to understand regression and apply it to non-linear problems. They also have source code in Python and R that you can use.
4. Clustering
Clustering is an unsupervised learning algorithm category that divides the data set into groups depending upon common characteristics or common properties. A good example would be grouping the data set instances into categories automatically, the process being used would be any of several algorithms that we shall soon list. For this reason, clustering is sometimes known as automatic classification. It is also a critical part of exploratory data analysis (EDA). Some of the algorithms commonly used for clustering are:
Hierarchical Clustering – Agglomerative
Hierarchical Clustering – Divisive
K-Means Clustering
K-Nearest Neighbours Clustering
EM (Expectation Maximization) Clustering
Principal Components Analysis Clustering (PCA)
An example of a common clustering problem visualization is given below:
From Wikipedia
The above visualization clearly contains three clusters.
Another excellent article on clustering refer the link
Dimensionality Reduction is an extremely important tool that should be completely clear and lucid for any serious data scientist. Dimensionality Reduction is also referred to as feature selection or feature extraction. This means that the principal variables of the data set that contains the highest covariance with the output data are extracted and the features/variables that are not important are ignored. It is an essential part of EDA (Exploratory Data Analysis) and is nearly always used in every moderately or highly difficult problem. The advantages of dimensionality reduction are (from Wikipedia):
It reduces the time and storage space required.
Removal of multi-collinearity improves the interpretation of the parameters of the machine learning model.
It becomes easier to visualize the data when reduced to very low dimensions such as 2D or 3D.
It avoids the curse of dimensionality.
The most commonly used algorithm for dimensionality reduction is Principal Components Analysis or PCA. While this is a linear model, it can be converted to a non-linear model through a kernel trick similar to that used in a Support Vector Machine, in which case the technique is known as Kernel PCA. Thus, the algorithms commonly used are:
Ensembling means combining multiple ML learners together into one pipeline so that the combination of all the weak learners makes an ML application with higher accuracy than each learner taken separately. Intuitively, this makes sense, since the disadvantages of using one model would be offset by combining it with another model that does not suffer from this disadvantage. There are various algorithms used in ensembling machine learning models. The three common techniques usually employed in practice are:
Simple/Weighted Average/Voting: Simplest one, just takes the vote of models in Classification and average in Regression.
Bagging: We train models (same algorithm) in parallel for random sub-samples of data-set with replacement. Eventually, take an average/vote of obtained results.
Boosting: In this models are trained sequentially, where (n)th model uses the output of (n-1)th model and works on the limitation of the previous model, the process stops when result stops improving.
Stacking: We combine two or more than two models using another machine learning algorithm.
(from Amardeep Chauhan on Medium.com)
In all four cases, the combination of the different models ends up having the better performance that one single learner. One particular ensembling technique that has done extremely well on data science competitions on Kaggle is the GBRT model or the Gradient Boosted Regression Tree model.
We include the source code from the scikit-learn module for Gradient Boosted Regression Trees since this is one of the most popular ML models which can be used in competitions like Kaggle, HackerRank, and TopCoder.
GradientBoostingClassifier supports both binary and multi-class classification. The following example shows how to fit a gradient boosting classifier with 100 decision stumps as weak learners:
GradientBoostingRegressor supports a number of different loss functions for regression which can be specified via the argument loss; the default loss function for regression is least squares ('ls').
import numpy as np
from sklearn.metrics import mean_squared_error
from sklearn.datasets import make_friedman1
from sklearn.ensemble import GradientBoostingRegressor
X, y = make_friedman1(n_samples=1200, random_state=0, noise=1.0)
X_train, X_test = X[:200], X[200:]
y_train, y_test = y[:200], y[200:]
est = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1,
max_depth=1, random_state=0, loss='ls').fit(X_train, y_train)
mean_squared_error(y_test, est.predict(X_test))
You can also refer to the following article which discusses Random Forests, which is a (rather basic) ensembling method.
In the last decade, there has been a renaissance of sorts within the Machine Learning community worldwide. Since 2002, neural networks research had struck a dead end as the networks of layers would get stuck in local minima in the non-linear hyperspace of the energy landscape of a three layer network. Many thought that neural networks had outlived their usefulness. However, starting with Geoffrey Hinton in 2006, researchers found that adding multiple layers of neurons to a neural network created an energy landscape of such high dimensionality that local minima were statistically shown to be extremely unlikely to occur in practice. Today, in 2019, more than a decade of innovation later, this method of adding addition hidden layers of neurons to a neural network is the classical practice of the field known as deep learning.
Deep Learning has truly taken the computing world by storm and has been applied to nearly every field of computation, with great success. Now with advances in Computer Vision, Image Processing, Reinforcement Learning, and Evolutionary Computation, we have marvellous feats of technology like self-driving cars and self-learning expert systems that perform enormously complex tasks like playing the game of Go (not to be confused with the Go programming language). The main reason these feats are possible is the success of deep learning and reinforcement learning (more on the latter given in the next section below). Some of the important algorithms and applications that data scientists have to be aware of in deep learning are:
Long Short term Memories (LSTMs) for Natural Language Processing
Recurrent Neural Networks (RNNs) for Speech Recognition
Convolutional Neural Networks (CNNs) for Image Processing
Deep Neural Networks (DNNs) for Image Recognition and Classification
Hybrid Architectures for Recommender Systems
Autoencoders (ANNs) for Bioinformatics, Wearables, and Healthcare
Deep Learning Networks typically have millions of neurons and hundreds of millions of connections between neurons. Training such networks is such a computationally intensive task that now companies are turning to the 1) Cloud Computing Systems and 2) Graphical Processing Unit (GPU) Parallel High-Performance Processing Systems for their computational needs. It is now common to find hundreds of GPUs operating in parallel to train ridiculously high dimensional neural networks for amazing applications like dreaming during sleep and computer artistry and artistic creativity pleasing to our aesthetic senses.
Artistic Image Created By A Deep Learning Network. From blog.kadenze.com.
For more on Deep Learning, please visit the following links:
In the recent past and the last three years in particular, reinforcement learning has become remarkably famous for a number of achievements in cognition that were earlier thought to be limited to humans. Basically put, reinforcement learning deals with the ability of a computer to teach itself. We have the idea of a reward vs. penalty approach. The computer is given a scenario and ‘rewarded’ with points for correct behaviour and ‘penalties’ are imposed for wrong behaviour. The computer is provided with a problem formulated as a Markov Decision Process, or MDP. Some basic types of Reinforcement Learning algorithms to be aware of are (some extracts from Wikipedia):
1.Q-Learning
Q-Learning is a model-free reinforcement learning algorithm. The goal of Q-learning is to learn a policy, which tells an agent what action to take under what circumstances. It does not require a model (hence the connotation “model-free”) of the environment, and it can handle problems with stochastic transitions and rewards, without requiring adaptations. For any finite Markov decision process (FMDP), Q-learning finds a policy that is optimal in the sense that it maximizes the expected value of the total reward over any and all successive steps, starting from the current state. Q-learning can identify an optimal action-selection policy for any given FMDP, given infinite exploration time and a partly-random policy. “Q” names the function that returns the reward used to provide the reinforcement and can be said to stand for the “quality” of an action taken in a given state.
2.SARSA
State–action–reward–state–action (SARSA) is an algorithm for learning a Markov decision process policy. This name simply reflects the fact that the main function for updating the Q-value depends on the current state of the agent “S1“, the action the agent chooses “A1“, the reward “R” the agent gets for choosing this action, the state “S2” that the agent enters after taking that action, and finally the next action “A2” the agent choose in its new state. The acronym for the quintuple (st, at, rt, st+1, at+1) is SARSA.
3.Deep Reinforcement Learning
This approach extends reinforcement learning by using a deep neural network and without explicitly designing the state space. The work on learning ATARI games by Google DeepMind increased attention to deep reinforcement learning or end-to-end reinforcement learning. Remarkably, the computer agent DeepMind has achieved levels of skill higher than humans at playing computer games. Even a complex game like DOTA 2 was won by a deep reinforcement learning network based upon DeepMind and OpenAI Gym environments that beat human players 3-2 in a tournament of best of five matches.
For more information, go through the following links:
If reinforcement learning was cutting edge data science, AutoML is bleeding edge data science. AutoML (Automated Machine Learning) is a remarkable project that is open source and available on GitHub at the following link that, remarkably, uses an algorithm and a data analysis approach to construct an end-to-end data science project that does data-preprocessing, algorithm selection,hyperparameter tuning, cross-validation and algorithm optimization to completely automate the ML process into the hands of a computer. Amazingly, what this means is that now computers can handle the ML expertise that was earlier in the hands of a few limited ML practitioners and AI experts.
AutoML has found its way into Google TensorFlow through AutoKeras, Microsoft CNTK, and Google Cloud Platform, Microsoft Azure, and Amazon Web Services (AWS). Currently it is a premiere paid model for even a moderately sized dataset and is free only for tiny datasets. However, one entire process might take one to two or more days to execute completely. But at least, now the computer AI industry has come full circle. We now have computers so complex that they are taking the machine learning process out of the hands of the humans and creating models that are significantly more accurate and faster than the ones created by human beings!
The basic algorithm used by AutoML is Network Architecture Search and its variants, given below:
Network Architecture Search (NAS)
PNAS (Progressive NAS)
ENAS (Efficient NAS)
The functioning of AutoML is given by the following diagram:
If you’ve stayed with me till now, congratulations; you have learnt a lot of information and cutting edge technology that you must read up on, much, much more. You could start with the links in this article, and of course, Google is your best friend as a Machine Learning Practitioner. Enjoy machine learning!
Python and R have been around for well over 20 years. Python was developed in 1991 by Guido van Rossum, and R in 1995 by Ross Ihaka and Robert Gentleman. Both Python and R have seen steady growth year after year in the last two decades. Will that trend continue, or are we coming to an end of an era of the Python-R dominance in the data science segment? Let’s find out!
Python
Python in the last decade has grown from strength to strength. In 2013, Python overtook R as the most popular language used fordata science, according to the Stack Overflow developer survey (Link).
In the last three years, Python was the most wanted language according to this survey (25% in 2018, JavaScript was second with 19%). It is by far the easiest programming language to learn, the Julia and the Go programming languages being honorable mentions in this regard.
Python shines in its versatility, being easy to use for data science, web development, utility programming, and as a general-purpose programming language. Even full-stack development can be done in Python, the only area where it is not used being mobile (although that may change if the Kivy mobile programming framework comes of age and stops stalling all the time). It was also ranked higher than JavaScript in the most loved programming languages for the last three years (Node.js and React.js have ranked below it consistently).
Will Python’s Dominance Continue?
We believe, yes, definitely. Two words – data science.
From https://www.digitaldesignjournal.com
Data science is such a hot and happening field right now, and the data scientist job is hyped as the ‘sexiest job of the 21st century‘, according to Forbes. Python is by far the most popular language for data science. The only close competitor is R, which Python overtook in the KDNuggets data science survey of 2016 . As shown in the link, in 2018, Python held 65.6% of the data science market, and R was actually below RapidMiner, at 48.5%. From the graphs, it is easy to see that Python is eating away at R’s share in the market. But why?
Deep Learning
In 2018, we say a huge push towards advancement across all verticals in the industry due to deep learning. And what is the most famous tool for deep learning? TensorFlow and Keras – both Python-based frameworks! While we have Keras and TensorFlow interfaces in R and RStudio now, Python was the initial choice and is still the native library – kerasR and tensorflow in RStudio being interfaces to the Python packages. Also, a real-life implementation of a deep learning project contains more than the deep learning model preparation and data analysis.
There is the data preprocessing, data cleaning, data wrangling, data preparation, outlier detection and missing data values management section which is infamous for taking up 99% of the time of a data scientist, with actual deep learning model work taking just 1% or less of their on-duty time! And what language is used for this commonly? For general purpose programming, Python is the goto language in most cases. I’m not saying that R doesn’t have data preprocessing packages. I’m saying that standard data science operations like web scraping are easier in Python than in R.And hence Python will be the language used in most cases, except in the statistics and the university or academic fields.
Our prediction for Python – growth – even to 70% of the data science market as more and more research-level projects like AutoML keep using Python as a first language of choice.
What About R?
In 2016, the use of R for data science in the industry was 55%, and Python stood at 51%. Python increased by 33% and R decreased by 25% in 2 years. Will that trend continue and will R continue on its downward spiral? I believe perhaps in figures, but not in practice. Here’s why.
Data science is at its heart, the field of the statistician. Unless you have a strong background in statistics, you will be unable to process the results of your experiments, especially in concepts like p-values, tests of significance, confidence intervals, and analysis of experiments. And R is the statistician’s language.Statistics and mathematics students will always find working in R remarkably easy and simple, which explains its popularity in academia. R programming lends itself to statistics. Python lends itself to model building and decent execution performance (R can be 4x slower). R, however, excels in statistical analysis. So what is the point that I am trying to express?
Simple – Python and R are complementary. They are best used together. You will find that knowledge of both Python and R will suit you best for most projects. You need to learn both. You can find this trend expressed in every article that speaks about becoming a data science unicorn – knowledge of both Python and R is required as a norm.
Yes, R is having a downturn in popularity. However, due to the complementary nature of the tools, I believe that R will have a part to play in the data scientist’s toolbox, even if it does dip a bit in growth in the years to come. Very simply, R is too convenient for a statistician to be neglected by the industry completely. It will continue to have its place in the toolbox. And yes; deep learning is now practical in R with support for Keras and AutoML as well as of right now.
Dimensionless Technologies
Dimensionless Technologies
Dimensionless Technologies is the market leader as far as training in AI, cloud, deep learning and data science in Python and R is concerned. Of course, you don’t have to spend 40k for a data science certification, you could always go for its industry equivalent – 100-120 lakhs for a US university’s Ph.D. research doctorate! What Dimensionless Technologies has as an advantage over its closest rival – (Coursera’s John Hopkins University’s Data Science Specialization) – is:
Live Video Training
The videos that you get on Coursera, edX, Dataquest, MIT OCW (MIT OpenCourseWare), Udacity, Udemy, and many other MOOCs have a fundamental flaw – they are NOT live! If you have a doubt in a video lecture, you only have the comments as a communication tool to the lectures. And when over 1,000 students are taking your class, it is next to impossible to respond to every comment. You will not and cannot get personalized attention for your doubts and clarifications. This makes it difficult for many, especially Indian students who may not be used to foreign accents to have a smooth learning curve in the popular MOOCs available today.
Try Before You Buy Fully
Dimensionless Technologies offers 20 hours of the course for Rs 5000, with the remaining 35k (10k of 45k waived if you qualify for the scholarship) payable after 2 weeks / 20 hours of taking the course on a trial basis. You get to evaluate the course for 20 hours before deciding whether you want to go through the entire syllabus with the highly experienced instructors who are strictly IIT alumni.
Instructors with 10 years Plus Industry Experience
In Coursera or edX, it is more common for Ph.D. professors than industry experienced professionals to teach the course. If you are good with American accents and next to zero instructor support, you will be able to learn a little bit about the scholastic side of your field. However, if you want to prepare for a 100K USD per year US data scientist job, you would be better off learning from professionals with industry experience. I am Not criticizing the Coursera instructors here, most have industry experience as well in the USA. However, if you want connections and contacts in the data science industry in India and the US, you might be a bit lost in the vast numbers of student who take those courses. Industry experience in instructors is rare in a MOOC and critically important to your landing a job.
Personalized Attention and Job Placement Guarantee
Dimensionless has a batch size of strictly not more than 25 per batch. This means that unlike other MOOCs with hundreds or thousands of students, every student in a class will get individual attention and training. This is the essence of what makes this company the market leader in this space. No other course provider has this restriction, which makes it certain that when you pay the money, you are 100% certain of completing your course, unlike all the other MOOCs out there. You are also given training for creating a data science portfolio, and how to prepare for data science interviews when you start applying to companies. The best part of this entire process is the 100% job placement guarantee.
If this has got your attention, and you are highly interested in data science, I encourage you to go to the following link to see more about the Data Science Using Python and R course, a strong foundation for a data science career:
Everyone is talking about data science as the dream job that they want to have!
Yes, the “100K $USD annual package” is a big draw.
Furthermore, the key focus of self-help and self-improvement literature coming out in the last decade speak about doing what you enjoy and care about – in short, a job you love to do – since there is the greatest possibility that you will shine the brightest in those areas.
Hence many students and many adventurous challenge-hunting individuals from other professions and other (sometimes related) roles are seeking jobs that involve problem-solving. Data science is one solution since it offers both the chance to disrupt a company’s net worth and profits for the better by focusing on analytics from the data they already have as well as solving problems that are challenging and interesting. Especially for the math nerds and computer geeks with experience in problem-solving and a passionate thirst to solve their next big challenge.
So what can you do to land yourself in this dream role?
Fundamentals of Data Science
Data science comprises of several roles. Some involve data wrangling. Some involve heavy coding expertise. And all of them involve expert communication and presentation skills. If you focus on just one of these three aspects, you’re already putting yourself at a disadvantage. What you need is to follow your own passion. And then integrate it into your profession. That way you earn a high amount while still doing work you love to do, even at the level of going above and beyond all the expectations that your employer has of you. So if you’re reading this article, I assume that you are either a student who is intrigued by data science or a working professional who is looking for a more lucrative profession. In such a case, you need to understand what the industry is looking for.
From http://news.mit.edu/2018/mitx-micromasters-program-statistics-and-data-science
a) Coding Expertise
If you want to land a job in the IT or data science fields, understand that you will have to deal with code. Usually, that code will already have been written by some other people or company in the first place. So being intimate with programming and readiness to spend hours and hours of your life sitting before a computer and writing code is something you have to get used to. The younger you start, the better. Children pick up coding fastest compared to all other age groups so there is a very real use-case for getting your kids to code and to see if they seem to like it as young as possible. And there is not just coding – the best choices in these cases will involve people who know software engineering basics and even source control tools and platforms (like Git and GitHub) and have already started their career in coding by contributing to open source projects.
If you are a student, and you want to know what all the hype is about, I suggest that you visit a site that teaches programming – preferably in Python – and start developing your own projects and apps. Yes – apps. The IT world is now mobile, and anyone without knowledge of how to build a mobile app for his product will be left in the dust as far as the highest level of earningis concerned. Even deep learning frameworks, that were once academic, have migrated to the mobile and app ecosystem. That was unthinkable a mere five years ago. If you already know the basics of programming, then learn source control (Git), and how to build programs for open source projects. And then contribute to those projects while you’re still a student. In this case, you will actually become an individual that companies go hunting for before you even complete your schooling or college education. Instead of the other way around!
Mentoring
If you are a student or a professional who is interested in this domain, but don’t know where to start – well – the best thing to do is to find a mentor. You can define a mentor or a coach as someone who has achieved what you aim to achieve in your life. You learn from their experience, their networking capabilities, and their tough sides – the way to keep up your ambition and motivation when you feel the least motivated. If you want to learn data science, what better way than to learn from someone who has done that already? And you will gain a lot of traction when you show promise, especially on your networking side for job placement. For more on that topic (mentoring) – I highly recommend that you study the following article:
b) Cogent Communication (Writing and Speaking skills)
Even if you have the world’s best programming expertise, ACM awards, Mathematics Olympiad winning background, you name it – even if you are the best data scientist available in the industry today for your domain – you will go nowhere without communication skills. Communication is more than speaking, reading and typing English – it is the way you present yourself to others in the digital world. That is why blogging, content creation, and focused interaction with your target industry – say, on StackOverflow.com – are so important. A blog really resonates with those to whom you seek a job. It shows that you have genuine, original knowledge about your industry. And if your blog receives critical acclaim through several incoming links from the industry, expect a job interview offer in your email before too long. In many countries but especially in India, the market is flooded with graduates, postgraduates, and PhDs who might have top marks on paper but have no marketable skills as far as their job requirements demand.
Overcome your fears!
Right now it is difficult to see the difference between a 100th percentile skilled data scientist and a 30th percentile skill level by just looking at documents that you submit to a company. A blog testifies that you know your field authoritatively. It also means that you have gained attention from industry leaders (when you receive comments). A StackOverflow answer that is highly rated or even a mention in technology sites like GitHub indicate that you are an expert in your field. Communication is so critical that I recommend that you try to make the best use of every chance you get to speak in public. This is the window the world has on you. Make yourself heard. Be original. Be creative. And the best data scientist in the world will go nowhere unless he or she knows how to communicate effectively. In the industry, this capacity is known as soft skills. And it can be your single biggest advantage over the competition.If you are planning to join a training course for your dream job, make sure the syllabus covers it!
c) Social Networking and Building Industry Connections through LinkedIn
Many sources of information don’t focus on this issue, but it is an absolute must. Your next job could be waiting for you on LinkedIn through a connection. Studies show that less than 1% of resume submissions are selected for the final job offer and lucrative placement. But the same studies show that at least 30% of internal referrals from within a company get placed into the job of their dreams. Networking is important – so important that if you know the job you’re after, please reach out and research. Understand the company’s problems. Try to address some of their key issues. The more focused, you are the more likely it is that you will get placed in the company you aim for. But always have a plan B – a fallback system, so that in case you do not get placed, you will know what to do. This is especially important today with the competition being so intense.
The Facebook of the Workplace
One place where you can be noticed is through industry connections in social networks. You might miss this, even if you are an M.S. from a college in the US. LinkedIn profiles – the Facebook of the technology world – are especially important today. More and more, in an environment saturated with high-quality talent, who you know can sometimes be even more important as what you know. Connecting to professionals in the industry you plan to work in is critical. This can occur through meetups, through conferences, through technological symposiums and even through paid courses. Courses who have instructors with industry connections are worth their weight in gold – even platinum. Students of such courses who show outstanding promises will be directed to their industry leaders early. If you have a decent GitHub profile but don’t know where to go after that, one way is to go for a course with industry experienced experts. These are the people who are the most likely to be able to land you a job in such a competitive environment. Because the market for data scientists – in fact for IT professionals in general – is highly saturated, including locations like the US.
Conclusion
We have not covered all topics required on this issue, there is much more to speak about. You need to know Statistics – even at PhD levels sometimes, especially Inferential Statistics, Bayes Theorem, Probability and Analysis of Experiments. You should know Linear Algebra in-depth. Indeed, there is a lot to cover. But the best place to learn can be courses tailored to produce Data Scientists. Some firms have really gone the extra mile to convert industry knowledge and key results in each subtopic to create noteworthy training courses specially designed for data science students. In the end, no college degree alone will land you a dream job. What will land you a dream job is hard work and experience through internships and industry projects. Some courses like the ones offered by www.Dimensionless.in have resulted in stellar placement and guidance even after the course duration is finished and when you are a working professional in the job of your dreams. These courses offer –
Instructors with Industry Experience (not academic professors!)
It’s a simple yet potent formula to land you the job of your dreams. Compare the normal route to a data science dream job – a PhD from the US (starting cost Rs. 1,40,28,000.00 INR for five years total, as a usual range) – to a simple course at Rs. 50K to Rs. 25K (yes, INR) from the comfort of taking the course from wherever you may be in the world (remote but live tuition – not recorded videos) with a mic on your end to ask the instructor every doubt you have – and you have a remarkable product guaranteed to land you a dream job within six months. Think the offer’s too good to be true? Well; visit the link below, and pay special attention to the feedback from past students of these same courses on the home page.
Last words – you never know what the future holds – economy and convenience are both prudent and praiseworthy. All the best!