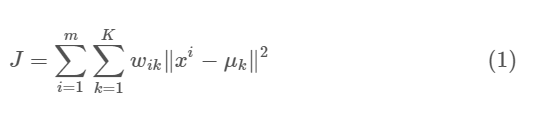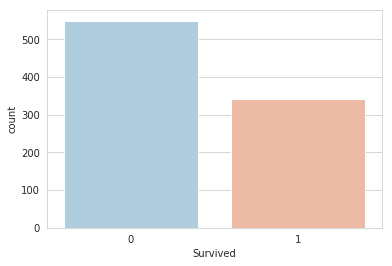What does your business do with the huge volumes of data collected daily? For business, the huge volumes of data collected daily can be demanding and time-consuming. Gathering, analyzing and reporting this type of information and discovering the most important data from the report can be supported through clustering it all.
Clustering can help businesses to manage their data better – image segmentation, grouping web pages, market segmentation, and information retrieval are four examples. For retail businesses, data clustering helps with customer shopping behaviour, sales campaigns, and customer retention. In the insurance industry, clustering is regularly employed in fraud detection, risk factor identification and customer retention efforts. In banking, clustering is used for customer segmentation, credit scoring and analyzing customer profitability.
In this blog, we will understand cluster analysis in detail. We will also look at implementing cluster analysis in python and visualise results in the end!
What is Cluster Analysis?
Clustering is the process of grouping observations of similar kinds into smaller groups within the larger population. It has a widespread application in business analytics. One of the questions facing businesses is how to organize the huge amounts of available data into meaningful structures. Or break a large heterogeneous population into smaller homogeneous groups. Cluster analysis is an exploratory data analysis tool which aims at sorting different objects into groups in a way that the degree of association between two objects is maximal if they belong to the same group and minimal otherwise.
For example, A grocer retailer used clustering to segment its 1.3MM loyalty card customers into 5 different groups based on their buying behaviour. It then adopted customized marketing strategies for each of these segments in order to target them more effectively.
Applications of Cluster Analysis
1. Marketing
Help marketers discover distinct groups in their customer bases and then use this knowledge to develop targeted marketing programs
2. Land Use
Identification of areas of similar land use in an earth observation database
3. Insurance
Identifying groups of motor insurance policyholders with a high average claim cost
4. City-Planning
Identifying groups of houses according to their house type, value, and geographical location
5. Earthquake Studies
Observed earthquake epicenters should be clustered along continent faults
Algorithms for Cluster Analysis
1. K- Means clustering
Kmeans algorithm is an iterative algorithm that tries to partition the dataset into Kpre-defined distinct non-overlapping subgroups (clusters) where each data point belongs to only one group. It tries to make the inter-cluster data points as similar as possible while also keeping the clusters as different (far) as possible. It assigns data points to a cluster such that the sum of the squared distance between the data points and the cluster’s centroid (arithmetic mean of all the data points that belong to that cluster) is at the minimum. The less variation we have within clusters, the more homogeneous (similar) the data points are within the same cluster.
The way the kmeans algorithm works is as follows:
Specify the number of clusters K.
Initialize centroids by first shuffling the dataset and then randomly selecting K data points for the centroids without replacement.
Keep iterating until there is no change to the centroids. i.e assignment of data points to clusters isn’t changing.
Compute the sum of the squared distance between data points and all centroids.
Assign each data point to the closest cluster (centroid).
Compute the centroids for the clusters by taking the average of all data points that belong to each cluster.
The approach the kmeans follows to solve the problem is called Expectation-Maximization. The E-step is assigning the data points to the closest cluster. The M-step is computing the centroid of each cluster. Below is a break down of how we can solve it mathematically (feel free to skip it).
The objective function is:
where wik=1 for data point xi if it belongs to cluster k; otherwise, wik=0. Also, μk is the centroid of xi’s cluster.
2. Hierarchical Clustering
Hierarchical clustering is a type of unsupervised machine learning algorithm used to cluster unlabeled data points. Like K-means clustering, hierarchical clustering also groups together the data points with similar characteristics. In some cases, the result of hierarchical and K-Means clustering can be similar.
Following are the steps involved in agglomerative clustering:
At the start, treat each data point as one cluster. Therefore, the number of clusters at the start will be K, while K is an integer representing the number of data points.
Form a cluster by joining the two closest data points resulting in K-1 clusters.
Form more clusters by joining the two closest clusters resulting in K-2 clusters.
Repeat the above three steps until one big cluster is formed.
Once a single cluster is formed, dendrograms are used to divide into multiple clusters depending upon the problem. We will study the concept of dendrogram in detail in an upcoming section.
There are different ways to find the distance between the clusters. The distance itself can be Euclidean or Manhattan distance. Following are some of the options to measure the distance between two clusters:
Measure the distance between the closest points of two clusters.
Find the distance between the farthest points of two clusters.
Measure the distance between the centroids of two clusters.
Find the distance between all possible combination of points between the two clusters and take the mean.
Code Implementation
We will implement the kmeans algorithm to visualise data to bucket it into different categories. We are using poker hand public data which is available here
Each record is an example of a hand consisting of five playing cards drawn from a standard deck of 52. Each card is described using two attributes (suit and rank), for a total of 10 predictive attributes. There is one Class attribute that describes the “Poker Hand”. The order of cards is important, which is why there are 480 possible Royal Flush hands as compared to 4!
We will be implementing the k-means algorithm using python and will be visualising the results in the end
Let us start by loading the required libraries for our task. We are using pandas and numpy for managing the data frame and mathematical calculations
# load libraries
from pandas import Series, DataFrame
import pandas as pd
import numpy as np
import matplotlib.pylab as plt
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
from sklearn.cluster import KMeans
import urllib.request
from pylab import rcParams
rcParams['figure.figsize'] = 9, 8
Let us focus on the data preparation aspect of our implementation. We will be preparing our test and train data in this section. Train data is the one on which we will be performing the clustering process!
Before proceeding with the segmentation, let us rescale our values within a certain range in order to bring all the numbers at the same scale. This helps in visualising different features on the same base.
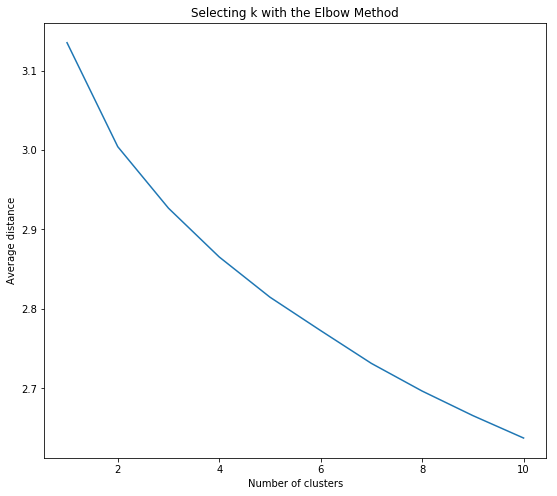
Also, before we start with clustering, we need to determine the number of clusters we are trying to identify. In most of the cases, you are looking for a particular k value for your k-means algorithm. If you select k=3, then the algorithm will try to find 3 different segments present in the data. In most of the cases, you will not be knowing the value of this k parameter. So how do you go about selecting the right “k” value for your model? The answer is “Elbow method”
The idea of the elbow method is to run k-means clustering on the dataset for a range of values of k, and for each value of k calculate the sum of squared errors (SSE).
Then, plot a line chart of the SSE for each value of k. If the line chart looks like an arm, then the “elbow” on the arm is the value of k that is the best. The idea is that we want a small SSE, but that the SSE tends to decrease toward 0 as we increase k (the SSE is 0 when k is equal to the number of data points in the dataset, because then each data point is its own cluster, and there is no error between it and the centre of its cluster). So our goal is to choose a small value of k that still has a low SSE, and the elbow usually represents where we start to have diminishing returns by increasing k
Let’s implement the elbow method to select our “k” value
clus_train = clustervar
from scipy.spatial.distance import cdist
clusters=range(1,11)
meandist=[]
# loop through each cluster and fit the model to the train set
# generate the predicted cluster assingment and append the mean distance my taking the sum divided by the shape
for k in clusters:
model=KMeans(n_clusters=k)
model.fit(clus_train)
clusassign=model.predict(clus_train)
meandist.append(sum(np.min(cdist(clus_train, model.cluster_centers_, 'euclidean'), axis=1))
clus_train.shape[0])
plt.plot(clusters, meandist)
plt.xlabel('Number of clusters')
plt.ylabel('Average distance')
plt.title('Selecting k with the Elbow Method')
Observing the elbow method,k=2 and k=3 are more reasonable options for our segmentation analysis
model3=KMeans(n_clusters=2)
model3.fit(clus_train)
# has cluster assingments based on using 3 clusters
clusassign=model3.predict(clus_train)
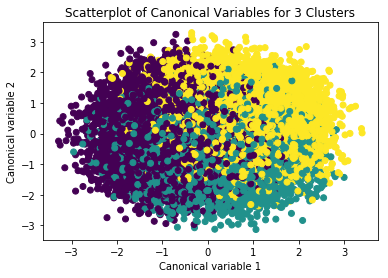
from sklearn.decomposition import PCA # CA from PCA function
pca_2 = PCA(2) # return 2 first canonical variables
plot_columns = pca_2.fit_transform(clus_train) # fit CA to the train dataset
plt.scatter(x=plot_columns[:,0], y=plot_columns[:,1], c=model3.labels_,)
# plot 1st canonical variable on x axis, 2nd on y-axis
plt.xlabel('Canonical variable 1')
plt.ylabel('Canonical variable 2')
# plt.zlabel('Canonical variable 3')
plt.title('Scatterplot of Canonical Variables for 2 Clusters')
plt.show()
Summary
In this blog, we implemented k-means clustering on poker hand dataset. Also, we understood about cluster analysis and different techniques in it. All the in-depth information was not covered in this blog, as it has been written for folks who are starting to explore data clustering in data science. Happy learning!!
I am so thrilled to welcome you to the absolutely awesome world of data science. It is an interesting subject, sometimes difficult, sometimes a struggle but always hugely rewarding at the end of your work. While data science is not as tough as, say, quantum mechanics, it is not high-school algebra either.
It requires knowledge of Statistics, some Mathematics (Linear Algebra, Multivariable Calculus, Vector Algebra, and of course Discrete Mathematics), Operations Research (Linear and Non-Linear Optimization and some more topics including Markov Processes), Python, R, Tableau, and basic analytical and logical programming skills.
.Now if you are new to data science, that last sentence might seem more like pure Greek than simple plain English. Don’t worry about it. If you are studying the Data Science course at Dimensionless Technologies, you are in the right place. This course covers the practical working knowledge of all the topics, given above, distilled and extracted into a beginner-friendly form by the talented course material preparation team.
This course has turned ordinary people into skilled data scientists and landed them with excellent placement as a result of the course, so, my basic message is, don’t worry. You are in the right place and with the right people at the right time.
What is Data Science?
To quote Wikipedia:
Data science is a multi-disciplinary field that uses scientific methods, processes, algorithms, and systems to extract knowledge and insights from structured and unstructured data. Data science is the same concept as data mining and big data: “use the most powerful hardware, the most powerful programming systems, and the most efficient algorithms to solve problems.”
Data Science is the art of extracting critical knowledge from raw data that provides significant increases in profits for your organization.
We are surrounded by data (Google ‘data deluge’ and you’ll see what I mean). More data has been created in the last two years that in the last 5,000 years of human existence.
The companies that use all this data to gain insights into their business and optimize their processing power will come out on top with the maximum profits in their market.
Companies like Facebook, Amazon, Microsoft, Google, and Apple (FAMGA), and every serious IT enterprise have realized this fact.
Hence the demand for talented data scientists.
I have much more to share with you on this topic, but to keep this article short, I’ll just share the links below which you can go through in your free time (everyone’s time is valuable because it is a strictly finite resource):
Now as I was planning this article a number of ideas came to my mind. I thought I could do a textbook-like reference to the field, with Python examples.
But then I realized that true competence in data science doesn’t come when you read an article.
True competence in data science begins when you take the programming concepts you have learned, type them into a computer, and run it on your machine.
And then; of course, modify it, play with it, experiment, run single lines by themselves, see for yourselves how Python and R work.
That is how you fall in love with coding in data science.
At least, that’s how I fell in love with simple C coding. Back in my UG in 2003. And then C++. And then Java. And then .NET. And then SQL and Oracle. And then… And then… And then… And so on.
If you want to know, I first started working in back-propagation neural networks in the year 2006. Long before the concept of data science came along! Back then, we called it artificial intelligence and soft computing. And my final-year project was coded by hand in Java.
Having come so far, what have I learned?
That it’s a vast massive uncharted ocean out there.
The more you learn, the more you know, the more you become aware of how little you know and how vast the ocean is.
But we digress!
To get back to my point –
My final decision was to construct a beginner project, explain it inside out, and give you source code that you can experiment with, play with, enjoy running, and modify here and there referring to the documentation and seeing what everything in the code actually does.
Kaggle – Your Home For Data Science
www.kaggle.com
If you are in the data science field, this site should be on your browser bookmark bar. Even in multiple folders, if you have them.
Kaggle is the go-to site for every serious machine learning practitioner. They hold competitions in data science (which have a massive participation), have fantastic tutorials for beginners, and free source code open-sourced under the Apache license (See this link for more on the Apache open source software license – don’t skip reading this, because as a data scientist this is something about software products that you must know).
As I was browsing this site the other day, a kernel that was attracting a lot of attention and upvotes caught my eye.
This kernel is by a professional data scientist by the name of Fatma Kurçun from Istanbul (the funny-looking ç symbol is called c with cedilla and is pronounced with an s sound).
It was quickly clear why it was so popular. It was well-written, had excellent visualizations, and a clear logical train of thought. Her professionalism at her art is obvious.
Since it is an open source Apache license released software, I have modified her code quite a lot (diff tool gives over 100 changes performed) to come up with the following Python classification example.
But before we dive into that, we need to know what a data science project entails and what classification means.
Let’s explore that next.
Classification and Data Science
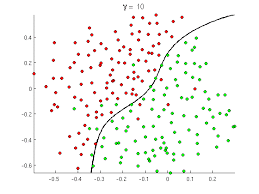
So supervised classification basically means mapping data values to a category defined in advance. In the image above, we have a set of customers who have certain data values (records). So one dot above corresponds with one customer with around 10-20 odd fields.
Now, how do we ascertain whether a customer is likely to default on a loan, and which customer is likely to be a non-defaulter? This is an incredibly important question in the finance field! You can understand the word, “classification”, here. We classify a customer into a defaulter (red dot) class (category) and a non-defaulter (green dot) class.
This problem is not solvable by standard methods. You cannot create and analyze a closed-form solution to this problem with classical methods. But – with data science – we can approximate the function that captures or models this problem, and give a solution with an accuracy range of 90-95%. Quite remarkable!
Now, again we can have a blog article on classification alone, but to keep this article short, I’ll refer you to the following excellent articles as references:
At some time in your machine learning career, you will need to go through the article above to understand what a machine learning project entails (the bread-and-butter of every data scientist).
Jupyter Notebooks
From Wikipedia
To run the exercises in this section, we use a Jupyter notebook. Jupyter is short for Julia, Python, and R. This environment uses kernels of any of these languages and has an interactive format. It is commonly used by data science professionals and is also good for collaboration and for sharing work.
To know more about Jupyter notebooks, I can suggest the following article (read when you are curious or have the time):
Data Science Libraries in Python
The standard data science stack for Python has the scikit-learn Python library as a basic lowest-level foundation.
The scikit-learn python library is the standard library in Python most commonly used in data science. Along with the libraries numpy, pandas, matplotlib, and sometimes seaborn as well this toolset is known as the standard Python data science stack. To know more about data science, I can direct you to the documentation for scikit-learn – which is excellent. The text is lucid, clear, and every file contains a working live example as source code. Refer to the following links for more:
This last link is like a bible for machine learning in Python. And yes, it belongs on your browser bookmarks bar. Reading and applying these concepts and running and modifying the source code can help you go a long way towards becoming a data scientist.
This is the classification standard data science beginner problem that we will consider. To quote Kaggle.com:
The sinking of the RMS Titanic is one of the most infamous shipwrecks in history. On April 15, 1912, during her maiden voyage, the Titanic sank after colliding with an iceberg, killing 1502 out of 2224 passengers and crew. This sensational tragedy shocked the international community and led to better safety regulations for ships.
One of the reasons that the shipwreck led to such loss of life was that there were not enough lifeboats for the passengers and crew. Although there was some element of luck involved in surviving the sinking, some groups of people were more likely to survive than others, such as women, children, and the upper-class.
In this challenge, we ask you to complete the analysis of what sorts of people were likely to survive. In particular, we ask you to apply the tools of machine learning to predict which passengers survived the tragedy.
We’ll be trying to predict a person’s category as a binary classification problem – survived or died after the Titanic sank.
So now, we go through the popular source code, explaining every step.
Import Libraries
These lines given below:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt;
import seaborn as sns
%matplotlib inline
Are standard for nearly every Python data stack problem. Pandas refers to the data frame manipulation library. NumPy is a vectorized implementation of Python matrix manipulation operations that are optimized to run at high speed. Matplotlib is a visualization library typically used in this context. Seaborn is another visualization library, at a little higher level of abstraction than matplotlib.
The Problem Data Set
We read the CSV file:
train = pd.read_csv('../input/train.csv')
Exploratory Data Analysis
Now, if you’ve gone through the links given in the heading ‘Steps involved in Data Science Projects’ section, you’ll know that real-world data is messy, has missing values, and is often in need of normalization to adjust for the needs of our different scikit-learn algorithms. This CSV file is no different, as we see below:
Missing Data
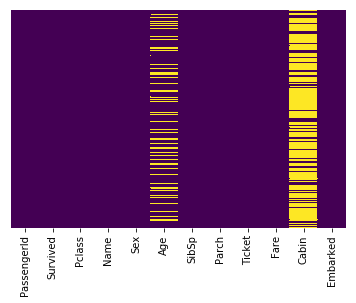
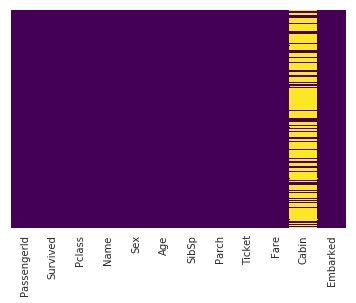
This line uses seaborn to create a heatmap of our data set which shows the missing values:
<matplotlib.axes._subplots.AxesSubplot at 0x7f3b5ed98ef0>
Interpretation
The yellow bars indicate missing data. From the figure, we can see that a fifth of the Age data is missing. And the Cabin column has so many missing values that we should drop it.
Graphing the Survived vs. the Deceased in the Titanic shipwreck:
<matplotlib.axes._subplots.AxesSubplot at 0x7f3b54fe2390>
As we can see, in our sample of the total data, more than 500 people lost their lives, and less than 350 people survived (in the sample of the data contained in train.csv).
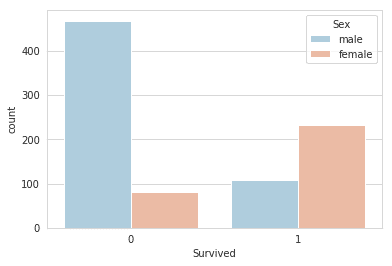
<matplotlib.axes._subplots.AxesSubplot at 0x7f3b54f49da0>
Over 400 men died, and around 100 survived. For women, less than a hundred died, and around 230 odd survived. Clearly, there is an imbalance here, as we expect.
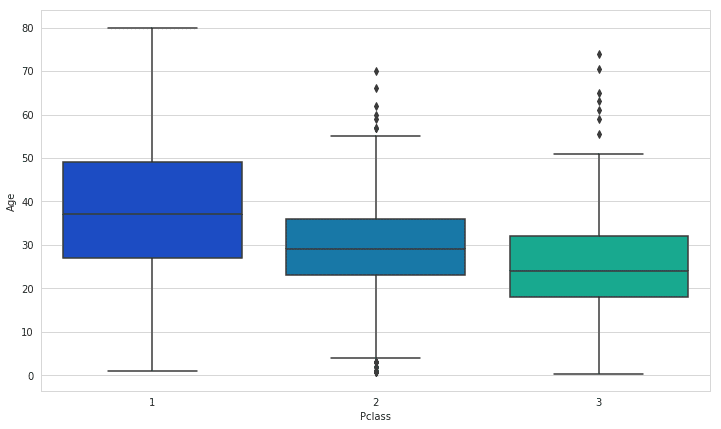
Data Cleaning
The missing age data can be easily filled with the average of the age values of an arbitrary category of the dataset. This has to be done since the classification algorithm cannot handle missing values and will be error-ridden if the data values are not error-free.
<matplotlib.axes._subplots.AxesSubplot at 0x7f3b54d132e8>
We use these average values to impute the missing values (impute – a fancy word for filling in missing data values with values that allow the algorithm to run without affecting or changing its performance).
def impute_age(cols):
Age = cols[0]
Pclass = cols[1]
if pd.isnull(Age):
if Pclass == 1:
return 37
elif Pclass == 2:
return 29
else:
return 24
else:
return Age
We use one-hot encoding to convert the categorical attributes to numerical equivalents. One-hot encoding is yet another data preprocessing method that has various forms. For more information on it, see the link
sex = pd.get_dummies(train['Sex'],drop_first=True)
embark = pd.get_dummies(train['Embarked'],drop_first=True)
train.drop(['Embarked','Name','Ticket'],axis=1,inplace=True)
train = pd.concat([train,sex,embark],axis=1)
<matplotlib.axes._subplots.AxesSubplot at 0x7f3b54743ac8>
No missing data and all text converted accurately to a numeric representation means that we can now build our classification model.
Building a Gradient Boosted Classifier model
Gradient Boosted Classification Trees are a type of ensemble model that has consistently accurate performance over many dataset distributions. I could write another blog article on how they work but for brevity, I’ll just provide the link here and link 2 here:
We split our data into a training set and test set.
The performance of a classifier can be determined by a number of ways. Again, to keep this article short, I’ll link to the pages that explain the confusion matrix and the classification report function of scikit-learn and of general classification in data science:
A wonderful article by one of our most talented writers. Skip to the section on the confusion matrix and classification accuracy to understand what the numbers below mean.
For a more concise, mathematical and formulaic description, read here
from sklearn.metrics import classification_report,confusion_matrix
print(confusion_matrix(y_test,predictions))
[[89 16]
[29 44]]
So as not make this article too disjointed, let me explain at least the confusion matrix to you.
The confusion matrix has the following form:
[[ TP FP ]
[ FN TN ]]
The abbreviations mean:
TP – True Positive – The model correctly classified this person as deceased.
FP – False Positive – The model incorrectly classified this person as deceased.
FN – False Negative – The model incorrectly classified this person as a survivor
TN – True Negative – The model correctly classified this person as a survivor.
So, in this model published on Kaggle, there were:
So the model, when used with Gradient Boosted Classification Decision Trees, has a precision of 75% (the original used Logistic Regression).
Wrap-Up
I have attached the dataset and the Python program to this document, you can download it by clicking on these links. Run it, play with it, manipulate the code, view the scikit-learn documentation. As a starting point, you should at least:
Use other algorithms (say LogisticRegression / RandomForestClassifier a the very least)
Refer the following link for classifiers to use: Sections 1.1 onwards – every algorithm that has a ‘Classifier’ ending in its name can be used – that’s almost 30-50 odd models!
Try to compare performances of different algorithms
Try to combine the performance comparison into one single program, but keep it modular.
Make a list of the names of the classifiers you wish to use, apply them all and tabulate the results. Refer to the following link:
Use XGBoost instead of Gradient Boosting
Titanic Training Dataset (here used for training and testing):
Clone with Git (use TortoiseGit for simplicity rather than the command-line) and enjoy.
To use Git, take the help of a software engineer or developer who has worked with it before. I’ll try to cover the relevance of Git for data science in a future article.
Install Git and TortoiseGit (the latter only if necessary)
Open the command line with Run… cmd.exe
Create an empty directory.
Copy paste the following string into the command prompt and watch the magic after pressing Enter: “git clone https://github.com/thomascherickal/datasciencewithpython-article-src.git” without the double quotes, of course.
Use Anaconda (a common data science development environment with Python,, R, Jupyter, and much more) for best results.
Cheers! All the best into your wonderful new adventure of beginning and exploring data science!
Learning done right can be awesome fun! (Unsplash)
In a world where we generate data at an extremely fast rate, the correct analysis of the data and providing useful and meaningful results at the right time can provide helpful solutions for many domains dealing with data products. We can apply this in Health Care and Finance to Media, Retail, Travel Services and etc. some solid examples include Netflix providing personalized recommendations at real-time, Amazon tracking your interaction with different products on its platform and providing related products immediately, or any business that needs to stream a large amount of data at real-time and implement different analysis on it.
One of the amazing frameworks that can handle big data in real-time and perform different analysis, is Apache Spark. In this blog, we are going to use spark streaming to process high-velocity data at scale. We will be using Kafka to ingest data into our Spark code
What is Spark?
Apache Spark is a lightning-fast cluster computing technology, designed for fast computation. It is based on Hadoop MapReduce and it extends the MapReduce model to efficiently use it for more types of computations, which includes interactive queries and stream processing. The main feature of Spark is its in-memory cluster computing that increases the processing speed of an application.
Spark is designed to cover a wide range of workloads such as batch applications, iterative algorithms, interactive queries and streaming. Apart from supporting all these workloads in a respective system, it reduces the management burden of maintaining separate tools.
What is Spark Streaming?
Spark Streaming is an extension of the core Spark API that enables high-throughput, fault-tolerant stream processing of live data streams. Data can be ingested from many sources like Kafka, Flume, Twitter, ZeroMQ or TCP sockets and processed using complex algorithms expressed with high-level functions like map, reduce, join and window. Finally, processed data can be pushed out to file systems, databases, and live dashboards. Since Spark Streaming is built on top of Spark, users can apply Spark’s in-built machine learning algorithms (MLlib), and graph processing algorithms (GraphX) on data streams. Compared to other streaming projects, Spark Streaming has the following features and benefits:
Ease of Use: Spark Streaming brings Spark’s language-integrated API to stream processing, letting users write streaming applications the same way as batch jobs, in Java, Python and Scala.
Fault Tolerance: Spark Streaming is able to detect and recover from data loss mid-stream due to node or process failure.
How Does Spark Streaming Work?
Spark Streaming processes a continuous stream of data by dividing the stream into micro-batches called a Discretized Stream or DStream. DStream is an API provided by Spark Streaming that creates and processes micro-batches. DStream is nothing but a sequence of RDDs processed on Spark’s core execution engine like any other RDD. It can be created from any streaming source such as Flume or Kafka.
Difference Between Spark Streaming and Spark Structured Streaming
Spark Streaming is based on DStream. A DStream is represented by a continuous series of RDDs, which is Spark’s abstraction of an immutable, distributed dataset. Spark Streaming has the following problems.
Difficult — it was not simple to built streaming pipelines supporting delivery policies: exactly once guarantee, handling data arrival in late or fault tolerance. Sure, all of them were implementable but they needed some extra work from the part of programmers.
Inconsistent — API used to generate batch processing (RDD, Dataset) was different than the API of streaming processing (DStream). Sure, nothing blocker to code but it’s always simpler (maintenance cost especially) to deal with at least abstractions as possible.
Spark Structured Streaming be understood as an unbounded table, growing with new incoming data, i.e. can be thought as stream processing built on Spark SQL.
More concretely, structured streaming brought some new concepts to Spark.
Exactly-once guarantee — structured streaming focuses on that concept. It means that data is processed only once and output doesn’t contain duplicates.
Event time — one of the observed problems with DStream streaming was processing order, i.e the case when data generated earlier was processed after later generated data. Structured streaming handles this problem with a concept called event time that, under some conditions, allows to correctly aggregate late data in processing pipelines.
sink, Result Table, output mode and watermark are other features of spark structured-streaming.
Implementation Goal
In this blog, we will try to find the word count present in the sentences. The major point here will be that this time sentences will not be present in a text file. Sentences will come through a live stream as flowing data points. We will be counting the words present in the flowing data. Data, in this case, is not stationary but constantly moving. It is also known as high-velocity data. We will be calculating word count on the fly in this case! We will be using Kafka to move data as a live stream. Spark has different connectors available to connect with data streams like Kafka
Word Count Example Using Kafka
There are few steps which we need to perform in order to find word count from data flowing in through Kafka.
The initialization of Spark and Kafka Connector
Our main task is to create an entry point for our application. We also need to set up and initialise Spark Streaming in the environment. This is done through the following code
val sparkConf = new SparkConf().setAppName("DirectKafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
Since we have Spark Streaming initialised, we need to connect our application with Kafka to receive the flowing data. Spark has inbuilt connectors available to connect your application with different messaging queues. We need to put information here like a topic name from where we want to consume data. We need to define bootstrap servers where our Kafka topic resides. Once we provide all the required information, we will establish a connection to Kafka using the createDirectStream function. You can find the implementation below
Now, we need to process the sentences. We need to map through all the sentences as and when we receive them through Kafka. Upon receiving them, we will split the sentences into the words by using the split function. Now we need to calculate the word count. We can do this by using the map and reduce function available with Spark. For every word, we will create a key containing index as word and it’s value as 1. The key will look something like this <’word’, 1>. After that, we will group all the tuples using the common key and sum up all the values present for the given key. This will, in turn, return us the word count for a given specific word. You can have a look at the implementation for the same below
val lines = messages.map(_.value)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
wordCounts.print()
Finally, the processing will not start unless you invoke the start function with the spark streaming instance. Also, remember that you need to wait for the shutdown command and keep your code running to receive data through live stream. For this, we use the awaitTermination method. You can implement the above logic through the following two lines
ssc.start()
ssc.awaitTermination()
Full Code
package org.apache.spark.examples.streaming
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka010._
object DirectKafkaWordCount {
def main(args: Array[String]) {
if (args.length < 3) {
System.err.println(s"""
|Usage: DirectKafkaWordCount <brokers> <topics>
| <brokers> is a list of one or more Kafka brokers
| <groupId> is a consumer group name to consume from topics
| <topics> is a list of one or more kafka topics to consume from
|
""".stripMargin)
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
val Array(brokers, groupId, topics) = args
// Create context with 2 second batch interval
val sparkConf = new SparkConf().setAppName("DirectKafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
// Create direct kafka stream with brokers and topics
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,
ConsumerConfig.GROUP_ID_CONFIG -> groupId,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer])
val messages = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams))
// Get the lines, split them into words, count the words and print
val lines = messages.map(_.value)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
wordCounts.print()
// Start the computation
ssc.start()
ssc.awaitTermination()
}
}
// scalastyle:on println
Summary
Earlier, as Hadoop have high latency that is not right for near real-time processing needs. In most cases, we use Hadoop for batch processing while used Storm for stream processing. It leads to an increase in code size, a number of bugs to fix, development effort, and causes other issues, which makes the difference between Big data Hadoop and Apache Spark.
Ultimately, Spark Streaming fixed all those issues. It provides the scalable, efficient, resilient, and integrated system. This model offers both execution and unified programming for batch and streaming. Although there is a major reason for its rapid adoption, is the unification of distinct data processing capabilities. It becomes a hot cake for developers to use a single framework to attain all the processing needs. In addition, through Spark SQL streaming data can combine with static data sources.
Follow this link, if you are looking to learn more about data science online!
Machine Learning is the word of the mouth for everyone involved in the analytics world. Gone are those days of the traditional manual approach of taking key business decisions. Machine Learning is the future and is here to stay.
However, the term Machine Learning is not a new one. It was there since the advent of computers but has grown tremendously in the last decade due to the massive amounts of data that’s getting generated, and the enormous computational power that modern-day system possesses.
Machine Learning is the art of Predictive Analytics where a system is trained on a set of data to learn patterns from it and then tested to make predictions on a new set of data. The more accurate the predictions are, the better the model performs. However, the metric for the accuracy of the model varies based on the domain one is working in.
Predictive Analytics has several usages in the modern world. It has been implemented in almost all sectors to make better business decisions and to stay ahead in the market. In this blog post, we would look into one of the key areas where Machine Learning has made its mark is the Customer Churn Prediction.
What is Customer Churn?
For any e-commerce business or businesses in which everything depends on the behavior of customers, retaining them is the number one priority for the organization. Customer churn is the process in which the customers stop using the products or services of a business.
Customer Churn or Customer Attrition is a better business strategy than acquiring the services of a new customer. Retaining the present customers is cost-effective, and a bit of effort could regain the trust that the customers might have lost on the services.
On the other hand, to get the service of the new customer, a business needs to spend a lot of time, and money on to the sales, and marketing department, more lucrative offers, and most importantly earning their trust. It would take more recourses to earn the trust of a new customer than to retain the existing one.
What are the Causes of Customer Churn?
There is a multitude of reasons why a customer could decide to stop using the services of a company. However, a couple of such reasons overwhelms others in the market.
Customer Service – This is one of the most important aspects on which business the growth of a business depends. Any customer could leave the services of a company if it’s poor or doesn’t live up to the expectations. A study showed that nearly ninety percent of the customer leave due to poor experience as modern era deems exceptional services, and experiences.
When a customer doesn’t receive such eye-catching experience from a business, it tends to lean towards its competitors leaving behind negative reviews in various social media from their past experiences which also stops potential new customers from using the service. Another study showed that almost fifty-nine percent of the people aged between twenty-five, and thirty share negative client experiences online.
Thus, poor customer experience not only results in the loss of a single customer but multiple customers as well which hinders the growth of the business in the process.
Onboarding Process – Whenever the business is looking to attract a new customer to use their service, it is necessary that the on-boarding process which includes timely follow-ups, regular communications, updates about new products, and so on are being followed, and maintained consistently over a period of time.
What are some of the Disadvantages of Customer Churn?
A customer’s lifetime value and the growth of the business maintains a direct relationship between each other i.e., more chances that the customer would churn, the less is the potential for the business to grow. Even a good marketing strategy would not save a business if it continues to lose customers at regular intervals due to other reasons and spend more money on acquiring new customers who are not guaranteed to be loyal.
There is a lot of debate surrounding customer churn and acquiring new customers because the former is much more cost-effective and ensures business growth. Thus companies spend almost seven times more effort, and time to retain old customers than acquire a new one. The global value of a customer lost is nearly two hundred, and forty-three dollars which makes churning a costly affair for any business.
What Strategies could a Business Undertake to prevent Customer Churn?
Customer Churn hinders or prevents the growth of an organization. Thus it is necessary that any business or organization has a flexible system in place to prevent the churn of customers and ensure its growth in the process. The companies need to find the metrics to identify the probability of a customer leaving, and chalk out strategies for improvement of its services, and products.
The calculation of the possibility of the customer churning varies from one business to another. There is no one fixed methodology that every organization uses to prevent churn. A churn rate could represent a variety of things such as – the total number of customers lost, the cost of the business loss, what percentage of the customers left in comparison to the total customer count of the organization, and so on.
Improving the customer experience should be the first strategy on the agenda of any business to prevent churn. Apart from that, marinating customer loyalty by providing better, personalized services is another important step one could undertake. Additionally, many organizations sent out customer survey time, and again to keep track of their customer experiences, and also seek reasons from them who have already churned.
A company should understand and learn about its customers beforehand. The amount of data that’s available all over the internet is sufficient to analyze a customer’s behavior, his likes, and dislikes, and improve the services based on their needs. All these measures, if taken with utmost care could help a business prevent its customers from churning.
Telecom Customer Churn Prediction
Previously, we learned how Predictive Analytics is being employed by various businesses to prevent any event from occurring and reduce the chances of losing by putting the right system in place. As customer churn is a global issue, we would now see how Machine Learning could be used to predict the customer churn of a telecom company.
Gender – Determines whether the customer is a male or a female.
Senior Citizen – A binary variable with values as 1 for senior citizen and 0 for not a senior citizen.
Partner – Values as ‘yes’ or ‘no based on whether the customer has a partner.
Dependents – Values as ‘yes’ or ‘no’ based on whether the customer has dependents.
Tenure – A numerical feature which gives the total number of months the customer stayed with the company.
Phone Service – Values as ‘yes’ or ‘no’ based on whether the customer has phone service.
Multiple Lines – Values as ‘yes’ or ‘no’ based on whether the customer has multiple lines.
Internet Service – The internet service providers the customer has. The value is ‘No’ if the customer doesn’t have internet service.
Online Security – Values as ‘yes’ or ‘no’ based on whether the customer has online security.
Online Backup – Values as ‘yes’ or ‘no’ based on whether the customer has online backup.
Device Protection – Values as ‘yes’ or ‘no’ based on whether the customer has device protection.
Tech Support – Values as ‘yes’ or ‘no’ based on whether the customer has tech support.
Streaming TV – Values as ‘yes’ or ‘no’ based on whether the customer has a streaming TV.
Streaming Movies – Values as ‘yes’ or ‘no’ based on whether the customer has streaming movies.
Contract – This column gives the term of the contract for the customer which could be a year, two years or month-to-month.
Paperless Billing – Values as ‘yes’ or ‘no’ based on whether the customer has a paperless billing.
Payment Method – It gives the payment method used by the customer which could be a credit card, Bank Transfer, Mailed Check, or Electronic Check.
Monthly Charges – This is the total charge incurred by the customer monthly.
Total Charges – The value of the total amount charged.
Churn – This is our target variable which needs to be predicted. Its values are either Yes (if the customer has churned), or No (if the customer is still with the company)
The following steps are the walkthrough of the code which we have written to predict the customer churn.
First, we have imported all the necessary libraries we would need to proceed further in our code
Just to get an idea of how our data looks likes, we have read the CSV file and printed out the first five rows of our data in the form of a data frame
Once, the data is read, some pre-processing needed to be done to check for null, outliers, and so on
Once the pre-processing is done, the next step is to get the relevant features to use in our model for the prediction. For that, we have done some data visualization to find out the relevancy of each predictor variables
After the data has been plotted, it is observed that Gender doesn’t have much influence on churn, whereas senior citizens are more likely to leave the company. Also, Phone Service has more influence on Churn than Multiple Lines
A model cannot take categorical data as input, hence those features are encoded into numbers to be used in our prediction
Based on our observation, we have taken the features which have more influence on churn prediction
The data is scaled, and split it into train and test set
We have fitted the Random Forest classifier to our new scaled data
Predicted the result and using the confusion matrix as the metric for our model
The model gives us (1155 + 190 = 1345) correct predictions and (273 + 143 = 416) incorrect predictions
The entire code could be found in this GitHub link
Conclusion
We have built a basic Random Forest Classifier model to predict the Customer Churn for a telecom company. The model could be improved with further manipulation of the parameters of the classifier and also by applying different algorithms.
Dimensionless has several resources to get started with.
There are a huge number of ML algorithms out there. Trying to classify them leads to the distinction being made in types of the training procedure, applications, the latest advances, and some of the standard algorithms used by ML scientists in their daily work. There is a lot to cover, and we shall proceed as given in the following listing:
Statistical Algorithms
Classification
Regression
Clustering
Dimensionality Reduction
Ensemble Algorithms
Deep Learning
Reinforcement Learning
AutoML (Bonus)
1. Statistical Algorithms
Statistics is necessary for every machine learning expert. Hypothesis testing and confidence intervals are some of the many statistical concepts to know if you are a data scientist. Here, we consider here the phenomenon of overfitting. Basically, overfitting occurs when an ML model learns so many features of the training data set that the generalization capacity of the model on the test set takes a toss. The tradeoff between performance and overfitting is well illustrated by the following illustration:
Overfitting – from Wikipedia
Here, the black curve represents the performance of a classifier that has appropriately classified the dataset into two categories. Obviously, training the classifier was stopped at the right time in this instance. The green curve indicates what happens when we allow the training of the classifier to ‘overlearn the features’ in the training set. What happens is that we get an accuracy of 100%, but we lose out on performance on the test set because the test set will have a feature boundary that is usually similar but definitely not the same as the training set. This will result in a high error level when the classifier for the green curve is presented with new data. How can we prevent this?
Cross-Validation
Cross-Validation is the killer technique used to avoid overfitting. How does it work? A visual representation of the k-fold cross-validation process is given below:
From Quora
The entire dataset is split into equal subsets and the model is trained on all possible combinations of training and testing subsets that are possible as shown in the image above. Finally, the average of all the models is combined. The advantage of this is that this method eliminates sampling error, prevents overfitting, and accounts for bias. There are further variations of cross-validation like non-exhaustive cross-validation and nested k-fold cross validation (shown above). For more on cross-validation, visit the following link.
There are many more statistical algorithms that a data scientist has to know. Some examples include the chi-squared test, the Student’s t-test, how to calculate confidence intervals, how to interpret p-values, advanced probability theory, and many more. For more, please visit the excellent article given below:
Classification refers to the process of categorizing data input as a member of a target class. An example could be that we can classify customers into low-income, medium-income, and high-income depending upon their spending activity over a financial year. This knowledge can help us tailor the ads shown to them accurately when they come online and maximises the chance of a conversion or a sale. There are various types of classification like binary classification, multi-class classification, and various other variants. It is perhaps the most well known and most common of all data science algorithm categories. The algorithms that can be used for classification include:
Logistic Regression
Support Vector Machines
Linear Discriminant Analysis
K-Nearest Neighbours
Decision Trees
Random Forests
and many more. A short illustration of a binary classification visualization is given below:
From openclassroom.stanford.edu
For more information on classification algorithms, refer to the following excellent links:
Regression is similar to classification, and many algorithms used are similar (e.g. random forests). The difference is that while classification categorizes a data point, regression predicts a continuous real-number value. So classification works with classes while regression works with real numbers. And yes – many algorithms can be used for both classification and regression. Hence the presence of logistic regression in both lists. Some of the common algorithms used for regression are
Linear Regression
Support Vector Regression
Logistic Regression
Ridge Regression
Partial Least-Squares Regression
Non-Linear Regression
For more on regression, I suggest that you visit the following link for an excellent article:
Both articles have a remarkably clear discussion of the statistical theory that you need to know to understand regression and apply it to non-linear problems. They also have source code in Python and R that you can use.
4. Clustering
Clustering is an unsupervised learning algorithm category that divides the data set into groups depending upon common characteristics or common properties. A good example would be grouping the data set instances into categories automatically, the process being used would be any of several algorithms that we shall soon list. For this reason, clustering is sometimes known as automatic classification. It is also a critical part of exploratory data analysis (EDA). Some of the algorithms commonly used for clustering are:
Hierarchical Clustering – Agglomerative
Hierarchical Clustering – Divisive
K-Means Clustering
K-Nearest Neighbours Clustering
EM (Expectation Maximization) Clustering
Principal Components Analysis Clustering (PCA)
An example of a common clustering problem visualization is given below:
From Wikipedia
The above visualization clearly contains three clusters.
Another excellent article on clustering refer the link
Dimensionality Reduction is an extremely important tool that should be completely clear and lucid for any serious data scientist. Dimensionality Reduction is also referred to as feature selection or feature extraction. This means that the principal variables of the data set that contains the highest covariance with the output data are extracted and the features/variables that are not important are ignored. It is an essential part of EDA (Exploratory Data Analysis) and is nearly always used in every moderately or highly difficult problem. The advantages of dimensionality reduction are (from Wikipedia):
It reduces the time and storage space required.
Removal of multi-collinearity improves the interpretation of the parameters of the machine learning model.
It becomes easier to visualize the data when reduced to very low dimensions such as 2D or 3D.
It avoids the curse of dimensionality.
The most commonly used algorithm for dimensionality reduction is Principal Components Analysis or PCA. While this is a linear model, it can be converted to a non-linear model through a kernel trick similar to that used in a Support Vector Machine, in which case the technique is known as Kernel PCA. Thus, the algorithms commonly used are:
Ensembling means combining multiple ML learners together into one pipeline so that the combination of all the weak learners makes an ML application with higher accuracy than each learner taken separately. Intuitively, this makes sense, since the disadvantages of using one model would be offset by combining it with another model that does not suffer from this disadvantage. There are various algorithms used in ensembling machine learning models. The three common techniques usually employed in practice are:
Simple/Weighted Average/Voting: Simplest one, just takes the vote of models in Classification and average in Regression.
Bagging: We train models (same algorithm) in parallel for random sub-samples of data-set with replacement. Eventually, take an average/vote of obtained results.
Boosting: In this models are trained sequentially, where (n)th model uses the output of (n-1)th model and works on the limitation of the previous model, the process stops when result stops improving.
Stacking: We combine two or more than two models using another machine learning algorithm.
(from Amardeep Chauhan on Medium.com)
In all four cases, the combination of the different models ends up having the better performance that one single learner. One particular ensembling technique that has done extremely well on data science competitions on Kaggle is the GBRT model or the Gradient Boosted Regression Tree model.
We include the source code from the scikit-learn module for Gradient Boosted Regression Trees since this is one of the most popular ML models which can be used in competitions like Kaggle, HackerRank, and TopCoder.
GradientBoostingClassifier supports both binary and multi-class classification. The following example shows how to fit a gradient boosting classifier with 100 decision stumps as weak learners:
GradientBoostingRegressor supports a number of different loss functions for regression which can be specified via the argument loss; the default loss function for regression is least squares ('ls').
import numpy as np
from sklearn.metrics import mean_squared_error
from sklearn.datasets import make_friedman1
from sklearn.ensemble import GradientBoostingRegressor
X, y = make_friedman1(n_samples=1200, random_state=0, noise=1.0)
X_train, X_test = X[:200], X[200:]
y_train, y_test = y[:200], y[200:]
est = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1,
max_depth=1, random_state=0, loss='ls').fit(X_train, y_train)
mean_squared_error(y_test, est.predict(X_test))
You can also refer to the following article which discusses Random Forests, which is a (rather basic) ensembling method.
In the last decade, there has been a renaissance of sorts within the Machine Learning community worldwide. Since 2002, neural networks research had struck a dead end as the networks of layers would get stuck in local minima in the non-linear hyperspace of the energy landscape of a three layer network. Many thought that neural networks had outlived their usefulness. However, starting with Geoffrey Hinton in 2006, researchers found that adding multiple layers of neurons to a neural network created an energy landscape of such high dimensionality that local minima were statistically shown to be extremely unlikely to occur in practice. Today, in 2019, more than a decade of innovation later, this method of adding addition hidden layers of neurons to a neural network is the classical practice of the field known as deep learning.
Deep Learning has truly taken the computing world by storm and has been applied to nearly every field of computation, with great success. Now with advances in Computer Vision, Image Processing, Reinforcement Learning, and Evolutionary Computation, we have marvellous feats of technology like self-driving cars and self-learning expert systems that perform enormously complex tasks like playing the game of Go (not to be confused with the Go programming language). The main reason these feats are possible is the success of deep learning and reinforcement learning (more on the latter given in the next section below). Some of the important algorithms and applications that data scientists have to be aware of in deep learning are:
Long Short term Memories (LSTMs) for Natural Language Processing
Recurrent Neural Networks (RNNs) for Speech Recognition
Convolutional Neural Networks (CNNs) for Image Processing
Deep Neural Networks (DNNs) for Image Recognition and Classification
Hybrid Architectures for Recommender Systems
Autoencoders (ANNs) for Bioinformatics, Wearables, and Healthcare
Deep Learning Networks typically have millions of neurons and hundreds of millions of connections between neurons. Training such networks is such a computationally intensive task that now companies are turning to the 1) Cloud Computing Systems and 2) Graphical Processing Unit (GPU) Parallel High-Performance Processing Systems for their computational needs. It is now common to find hundreds of GPUs operating in parallel to train ridiculously high dimensional neural networks for amazing applications like dreaming during sleep and computer artistry and artistic creativity pleasing to our aesthetic senses.
Artistic Image Created By A Deep Learning Network. From blog.kadenze.com.
For more on Deep Learning, please visit the following links:
In the recent past and the last three years in particular, reinforcement learning has become remarkably famous for a number of achievements in cognition that were earlier thought to be limited to humans. Basically put, reinforcement learning deals with the ability of a computer to teach itself. We have the idea of a reward vs. penalty approach. The computer is given a scenario and ‘rewarded’ with points for correct behaviour and ‘penalties’ are imposed for wrong behaviour. The computer is provided with a problem formulated as a Markov Decision Process, or MDP. Some basic types of Reinforcement Learning algorithms to be aware of are (some extracts from Wikipedia):
1.Q-Learning
Q-Learning is a model-free reinforcement learning algorithm. The goal of Q-learning is to learn a policy, which tells an agent what action to take under what circumstances. It does not require a model (hence the connotation “model-free”) of the environment, and it can handle problems with stochastic transitions and rewards, without requiring adaptations. For any finite Markov decision process (FMDP), Q-learning finds a policy that is optimal in the sense that it maximizes the expected value of the total reward over any and all successive steps, starting from the current state. Q-learning can identify an optimal action-selection policy for any given FMDP, given infinite exploration time and a partly-random policy. “Q” names the function that returns the reward used to provide the reinforcement and can be said to stand for the “quality” of an action taken in a given state.
2.SARSA
State–action–reward–state–action (SARSA) is an algorithm for learning a Markov decision process policy. This name simply reflects the fact that the main function for updating the Q-value depends on the current state of the agent “S1“, the action the agent chooses “A1“, the reward “R” the agent gets for choosing this action, the state “S2” that the agent enters after taking that action, and finally the next action “A2” the agent choose in its new state. The acronym for the quintuple (st, at, rt, st+1, at+1) is SARSA.
3.Deep Reinforcement Learning
This approach extends reinforcement learning by using a deep neural network and without explicitly designing the state space. The work on learning ATARI games by Google DeepMind increased attention to deep reinforcement learning or end-to-end reinforcement learning. Remarkably, the computer agent DeepMind has achieved levels of skill higher than humans at playing computer games. Even a complex game like DOTA 2 was won by a deep reinforcement learning network based upon DeepMind and OpenAI Gym environments that beat human players 3-2 in a tournament of best of five matches.
For more information, go through the following links:
If reinforcement learning was cutting edge data science, AutoML is bleeding edge data science. AutoML (Automated Machine Learning) is a remarkable project that is open source and available on GitHub at the following link that, remarkably, uses an algorithm and a data analysis approach to construct an end-to-end data science project that does data-preprocessing, algorithm selection,hyperparameter tuning, cross-validation and algorithm optimization to completely automate the ML process into the hands of a computer. Amazingly, what this means is that now computers can handle the ML expertise that was earlier in the hands of a few limited ML practitioners and AI experts.
AutoML has found its way into Google TensorFlow through AutoKeras, Microsoft CNTK, and Google Cloud Platform, Microsoft Azure, and Amazon Web Services (AWS). Currently it is a premiere paid model for even a moderately sized dataset and is free only for tiny datasets. However, one entire process might take one to two or more days to execute completely. But at least, now the computer AI industry has come full circle. We now have computers so complex that they are taking the machine learning process out of the hands of the humans and creating models that are significantly more accurate and faster than the ones created by human beings!
The basic algorithm used by AutoML is Network Architecture Search and its variants, given below:
Network Architecture Search (NAS)
PNAS (Progressive NAS)
ENAS (Efficient NAS)
The functioning of AutoML is given by the following diagram:
If you’ve stayed with me till now, congratulations; you have learnt a lot of information and cutting edge technology that you must read up on, much, much more. You could start with the links in this article, and of course, Google is your best friend as a Machine Learning Practitioner. Enjoy machine learning!