Are you from a computer science background and moving into data science? Are you planning to learn coding being from a non-programming background in data science? Then you need not worry because in this blog we will be talking about the importance of computer science in the data science world. Furthermore, we will also be looking at why is it necessary to be fluent with coding(basic at least) in the data science world.
Before enumerating the role of computer science in the data science world, let us clear our understanding of the above two terms. This will allow us to be on the same page before we reason out the importance of coding in data science.
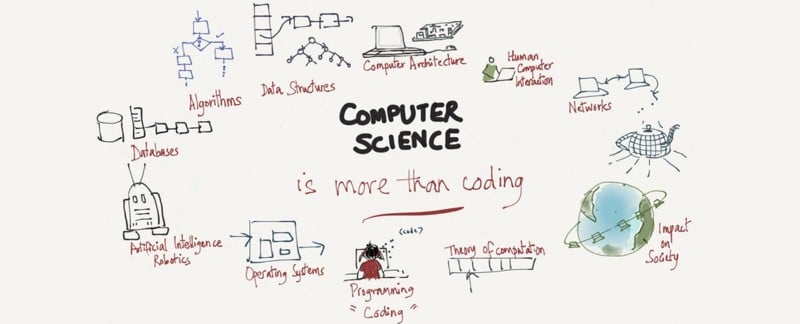
What is Computer Science
Computer Science is the study of computers and computational systems. Unlike electrical and computer engineers, computer scientists deal mostly with software and software systems; this includes their theory, design, development, and application.
Principal areas of study within Computer Science include artificial intelligence, computer systems, and networks, security, database systems, human-computer interaction, vision and graphics, numerical analysis, programming languages, software engineering, bioinformatics and theory of computing.
What is Data Science
Data science is the umbrella under which all these terminologies take the shelter. Data science is a like a complete subject which has different stages within itself. Suppose a retailer wants to forecast the sales of an X item present in its inventory in the coming month. This is known as a business problem and data science aims to provide optimized solutions for the same.
Data science enables us to solve this business problem with a series of well-defined steps.
1: Collecting data 2: Pre-processing data 3: Analysing data 4: Driving insights and generating BI reports 5: Taking decision based on insights
Generally, these are the steps we mostly follow to solve a business problem. All the terminologies related to data science falls under different steps which we are going to understand just in a while. Different terminologies fall under different steps listed above.
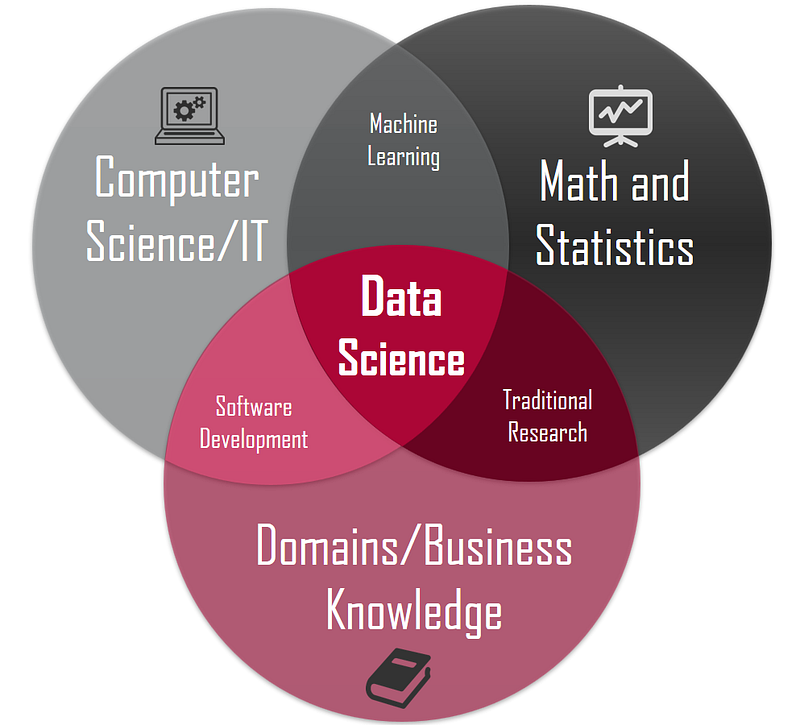
Data science as you can see is an amalgamation of Business, maths and computer science. A computer engineer is familiar with the entire CS aspect of it and much of maths sections is also covered. Hence, there is no denying fact that Computer science engineers will have a little advantage while beginning their career as data scientists.
Application of computer science in data science
After understanding the difference between Computer Science and Data Science, we will look at the areas in data science where computer science is employed
Data Collection (Big data and data engineering)
Computer science gives you an edge in understanding and working hands-on with aspects of BIG Data. Big data works mainly on important concepts like map-reduce, master-slave concepts etc. These concepts are something by which most of the computer engineers are aware of. Hence, familiarity with these concepts enables a head start in learning these technologies and using them effectively for the complex cases.
Data Pre-Processing (Cleaning, SQL)
Data extraction involves heavy usage of SQL in data sciences. SQL is one of a primary skill in data sciences. SQL is something which is never an alien term to Computer Engineers as most of them are/should be adept in it. Computer science engineers are taught the databases and their management in and out and hence knowledge of SQL is elementary to them.
Analysis(EDA etc)
For data analysis, knowledge of one of the programming language (R or Python mostly)is elementary. Being proficient in one of these languages grants the learner an ability to quickly get started with complex ETL operations. Additionally, the ability to understand and implement code quickly can enable you to go one extra mile while doing your analysis. Also, it reduces your time spent on such tasks as one is already through all the basic concepts.
Insights( Machine Learning/Deep Learning)
Computer scientists invented the name machine learning, and it’s part of computer science, so in that sense, it’s 100% computer science. Furthermore, computer scientists view machine learning as “algorithms for making good predictions.” Unlike statisticians, computer scientists are interested in the efficiency of the algorithms and often blur the distinction between the model and how the model is fit. Additionally, they are not too interested in how we got the data or in models as representations of some underlying truth. For them, machine learning is black boxes making predictions. And computer science has, for the most part, dominated statistics when it comes to making good predictions.
Visual Reports(Visualisations)
Visualizations are an important aspect of data science. Although Data science has multiple tools available for visualization, complex representation requires that extra coding effort. Complex enhancements in visualizations may require some technical aspect of changing few extra parameters of the base library or even the framework you are working with.
Pros of Computer Science knowledge in Data Science
Headstart with all technical aspect of data science
Ability to design, scale and optimise technical solutions
Interpreting algorithm/tool behaviour for different business use cases
Bringing a fresh perspective of looking at a business problem
Proficiency with most of the hands-on coding work
Cons of Computer Science knowledge in Data Science
May end up with a fixed mindset of doing things the “Computer Science” way.
You have to catch up with a lot of business knowledge and applications
Need to pay greater attention to maths and statistics as they are vital aspects of data science
Conclusion
In this blog, we had a look at the various application of computer science in the data science industry. No wonder that because of multiple applications of computer science in the data science industry, computer engineers find it easy, to begin with. Also, at no point in time, we imply that only computer science graduates can excel in the data science domain. Although, being a bachelor in computer science has its own perils in the science field. But, it also comes with its own set of disadvantages like lack of business knowledge and statistics. Anyone can excel in data science who can master all three aspects of it regardless of their bachelor degrees. All you need is right guidance outside and motivation within. Additionally, we at Dimensionless Technologies, provide hands-on training on Data Science, Big Data and NLP. You can check our courses here.
Furthermore, for more blogs on data science, visit our blog section here.
Also, you may also want to have a look at some of our previous blogs below.
The constant evolution of technology has meant data and information is being generated at a rate unlike ever before, and it’s only on the rise. Furthermore, the demand for people skilled in analyzing, interpreting and using this data is already high and is set to grow exponentially over the coming years. These new roles cover all aspect from strategy, operations to governance. Hence, the current and future demand will require more data scientists, data engineers, data strategists, and Chief Data Officers.
In this blog, we will be looking at different set of interview questions that can certainly help if you are planning to give a shift to your career towards data science.
Category of Interview Questions
Statistics
1. Name and explain few methods/techniques used in Statistics for analyzing the data?
Answer:
Arithmetic Mean: It is an important technique in statistics Arithmetic Mean can also be called an average. It is the number or the quantity obtained by summing two or more numbers/variables and then dividing the sum by the number of numbers/variables.
Median:
Median is also a way of finding the average of a group of data points. It’s the middle number of a set of numbers. There are two possibilities, the data points can be an odd number group or it can be en even number group.
If the group is odd, arrange the numbers in the group from smallest to largest. The median will be the one which is exactly sitting in the middle, with an equal number on either side of it. If the group is even, arrange the numbers in order and pick the two middle numbers and add them then divide by 2. It will be the median number of that set.
Mode: The mode is also one of the types for finding the average. A mode is a number, which occurs most frequently in a group of numbers. Some series might not have any mode; some might have two modes which is called bimodal series.
In the study of statistics, the three most common ‘averages’ in statistics are Mean, Median and Mode.
Standard Deviation (Sigma): Standard Deviation is a measure of how much your data is spread out in statistics.
Regression: Regression is an analysis in statistical modelling. It’s a statistical process for measuring the relationships among the variables; it determines the strength of the relationship between one variable and a series of other changing independent variables.
2. Explain about statistics branches?
Answer:
The two main branches of statistics are descriptive statistics and inferential statistics.
Descriptive statistics: Descriptive statistics summarizes the data from a sample using indexes such as mean or standard deviation.
Descriptive Statistics, methods include displaying, organizing and describing the data.
Inferential Statistics: Inferential Statistics draws the conclusions from data that are subject to random variation such as observation errors and sample variation.
3. List all the other models work with statistics to analyze the data?
Answer:
Statistics along with Data Analytics analyzes the data and help business to make good decisions. Predictive ‘Analytics’ and ‘Statistics’ are useful to analyze current data and historical data to make predictions about future events.
4. List the fields, where statistic can be used?
Answer:
Statistics can be used in many research fields. Below are the lists of files in which statistics can be used
Science
Technology
Business
Biology
Computer Science
Chemistry
It aids in decision making
Provides comparison
Explains action that has taken place
Predict the future outcome
Estimate of unknown quantities.
5. What is a linear regression in statistics?
Answer: Linear regression is one of the statistical techniques used in a predictive analysis, in this technique will identify the strength of the impact that the independent variables show on deepened variables.
6. What is a Sample in Statistics and list the sampling methods?
Answer:
In a Statistical study, a Sample is nothing but a set of or a portion of collected or processed data from a statistical population by a structured and defined procedure and the elements within the sample are known as a sample point.
Below are the 4 sampling methods:
Cluster Sampling: IN cluster sampling method the population will be divided into groups or clusters.
Simple Random: This sampling method simply follows the pure random division.
Stratified: In stratified sampling, the data will be divided into groups or strata.
Systematical: Systematical sampling method picks every kth member of the population.
7. What is P- value and explain it?
Answer:
When we execute a hypothesis test in statistics, a p-value helps us in determine the significance of our results. These Hypothesis tests are nothing but to test the validity of a claim that is made about a population. A null hypothesis is a situation when the hypothesis and the specified population is with no significant difference due to sampling or experimental error.
8. What is Data Science and what is the relationship between Data science and Statistics?
Answer: Data Science is simply data-driven science, also, it involves the interdisciplinary field of automated scientific methods, algorithms, systems, and process to extracts the insights and knowledge from data in any form, either structured or unstructured. Furthermore, It has similarities with data mining, both abstracts the useful information from data.
Data Sciences include Mathematical Statistics along with Computer science and Applications. Also by combing aspects of statistics, visualization, applied mathematics, computer science Data Science is turning the vast amount of data into insights and knowledge.
Similarly, Statistics is one of the main components of Data Science. Statistics is a branch of mathematics commerce with the collection, analysis, interpretation, organization, and presentation of data.
9. What is correlation and covariance in statistics?
Answer:
Covariance and Correlation are two mathematical concepts; these two approaches are widely used in statistics. Both Correlation and Covariance establish the relationship and also measure the dependency between two random variables. Though the work is similar between these two in mathematical terms, they are different from each other.
Correlation: Correlation is considered or described as the best technique for measuring and also for estimating the quantitative relationship between two variables. Correlation measures how strongly two variables are related.
Covariance: In covariance two items vary together and it’s a measure that indicates the extent to which two random variables change in cycle. It is a statistical term; it explains the systematic relation between a pair of random variables, wherein changes in one variable reciprocal by a corresponding change in another variable.
R is data analysis software which is used by analysts, quants, statisticians, data scientists, and others.
2. List out some of the function that R provides?
The function that R provides are
Mean
Median
Distribution
Covariance
Regression
Non-linear
Mixed Effects
GLM
GAM. etc.
3. Explain how you can start the R commander GUI?
Typing the command, (“Rcmdr”) into the R console starts the R Commander GUI.
4. In R how you can import Data?
You use R commander to import Data in R, and there are three ways through which you can enter data into it
You can enter data directly via Data New Data Set
Import data from a plain text (ASCII) or other files (SPSS, Minitab, etc.)
Read a dataset either by typing the name of the data set or selecting the data set in the dialogue box
5. Mention what does not ‘R’ language do?
Though R programming can easily connect to DBMS is not a database
R does not consist of any graphical user interface
Though it connects to Excel/Microsoft Office easily, R language does not provide any spreadsheet view of data
6. Explain how R commands are written?
In R, anywhere in the program, you have to preface the line of code with a #sign, for example
# subtraction
# division
# note order of operations exists
7. How can you save your data in R?
To save data in R, there are many ways, but the easiest way of doing this is
Go to Data > Active Data Set > Export Active dataset and a dialogue box will appear, when you click ok the dialogue box lets you save your data in the usual way.
8. Mention how you can produce co-relations and covariances?
You can produce co-relations by the cor () function to produce co-relations and cov() function to produce covariances.
9. Explain what is t-tests in R?
In R, the t.test () function produces a variety of t-tests. The t-test is the most common test in statistics and used to determine whether the means of two groups are equal to each other.
10. Explain what is With () and By () function in R is used for?
With() function is similar to DATA in SAS, it applies an expression to a dataset.
BY() function applies a function to each level of factors. It is similar to BY processing in SAS.
11. What are the data structures in R that are used to perform statistical analyses and create graphs?
In R missing values are represented by NA (Not Available), why impossible values are represented by the symbol NaN (not a number).
14. Explain what is transpose?
For re-shaping data before, analysis R provides a various method and transpose are the simplest methods of reshaping a dataset. To transpose a matrix or a data frame t () function is used.
15. Explain how data is aggregated in R?
By collapsing data in R by using one or more BY variables, it becomes easy. When using the aggregate() function the BY variable should be in the list.
Machine Learning
1. What do you understand by Machine Learning?
Answer:
Machine learning is an application of artificial intelligence that provides systems with the ability to automatically learn and improve from experience without being explicitly programmed. Also, machine learning focuses on the development of computer programs that can access data and use it learn for themselves.
2. Give an example that explains Machine Leaning in industry.
Answer:
Robots are replacing humans in many areas. It is because robots are programmed such that they can perform the task based on data they gather from sensors. They learn from the data and behaves intelligently.
3. What are the different Algorithm techniques in Machine Learning?
Answer:
The different types of Algorithm techniques in Machine Learning are as follows:
• Reinforcement Learning
• Supervised Learning
• Unsupervised Learning
• Semi-supervised Learning
• Transduction
• Learning to Learn
4. What is the difference between supervised and unsupervised machine learning?
Answer:
This is the basic Machine Learning Interview Questions asked in an interview. A Supervised learning is a process where it requires training labelled data While Unsupervised learning it doesn’t require data labelling.
5. What is the function of Unsupervised Learning?
Answer:
The function of Unsupervised Learning are as below:
• Find clusters of the data of the data
• Low-dimensional representations of the data
• Gaining interesting directions in data
• Interesting coordinates and correlations
• Figuring novel observations
6. What is the function of Supervised Learning?
Answer:
The function of Supervised Learning are as below:
• Classifications
• Speech recognition
• Regression
• Predict time series
• Annotate strings
7. What are the advantages of Naive Bayes?
Answer:
The advantages of Naive Bayes are:
• The classifier will converge quicker than discriminative models
• It cannot learn the interactions between features
8. What are the disadvantages of Naive Bayes?
Answer:
The disadvantages of Naive Bayes are:
• The problem arises for continuous features
• It makes a very strong assumption on the shape of your data distribution
• Does not work well in case of data scarcity
9. Why is naive Bayes so naive?
Answer:
Naive Bayes is so naive because it assumes that all of the features in a dataset are equally important and independent.
10. What is Overfitting in Machine Learning?
Answer:
This is the popular Machine Learning Interview Questions asked in an interview. Overfitting in Machine Learning is defined as when a statistical model describes random error or noise instead of underlying relationship or when a model is excessively complex.
11. What are the conditions when Overfitting happens?
Answer:
One of the important reason and possibility of overfitting is because the criteria used for training the model is not the same as the criteria used to judge the efficacy of a model.
12. How can you avoid overfitting?
Answer:
We can avoid overfitting by using:
• Lots of data
• Cross-validation
13. What are the five popular algorithms for Machine Learning?
Answer:
Below is the list of five popular algorithms of Machine Learning:
• Decision Trees
• Probabilistic networks
• Nearest Neighbor
• Support vector machines
• Neural Networks
14. What are the different use cases where machine learning algorithms can be used?
Answer:
The different use cases where machine learning algorithms can be used are as follows:
• Fraud Detection
• Face detection
• Natural language processing
• Market Segmentation
• Text Categorization
• Bioinformatics
15. What are parametric models and Non-Parametric models?
Answer:
Parametric models are those with a finite number of parameters and to predict new data, you only need to know the parameters of the model.
Non Parametric models are those with an unbounded number of parameters, allowing for more flexibility and to predict new data, you need to know the parameters of the model and the state of the data that has been observed.
16. What are the three stages to build the hypotheses or model in machine learning?
Answer:
This is the frequently asked Machine Learning Interview Questions in an interview. The three stages to build the hypotheses or model in machine learning are:
1. Model building
2. Model testing
3. Applying the model
17. What is Inductive Logic Programming in Machine Learning (ILP)?
Answer:
Inductive Logic Programming (ILP) is a subfield of machine learning which uses logical programming representing background knowledge and examples.
18. What is the difference between classification and regression?
Answer:
The difference between classification and regression are as follows:
• Classification is about identifying group membership while regression technique involves predicting a response.
• Both the techniques are related to prediction
• Classification predicts the belonging to a class whereas regression predicts the value from a continuous set
• Regression is not preferred when the results of the model need to return the belongingness of data points in a dataset with specific explicit categories
19. What is the difference between inductive machine learning and deductive machine learning?
Answer:
The difference between inductive machine learning and deductive machine learning are as follows:
machine learning where the model learns by examples from a set of observed instances to draw a generalized conclusion whereas in deductive learning the model first draws the conclusion and then the conclusion is drawn.
20. What are the advantages decision trees?
Answer:
The advantages decision trees are:
• Decision trees are easy to interpret
• Nonparametric
• There are relatively few parameters to tune
Answer:
The area of machine learning which focuses on deep artificial neural networks which are loosely inspired by brains. Alexey Grigorevich Ivakhnenko published the first general on working Deep Learning network. Today it has its application in various fields such as computer vision, speech recognition, natural language processing.
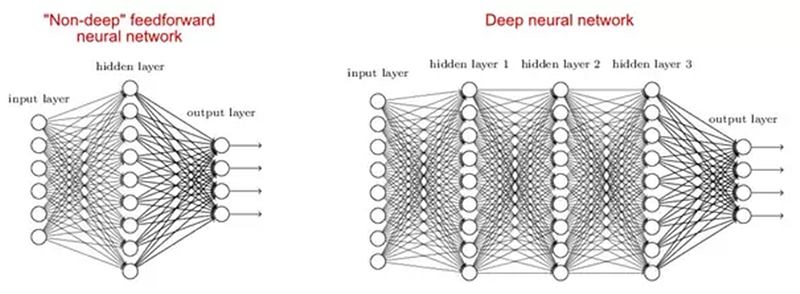
2. Why are deep networks better than shallow ones?
Answer:
There are studies which say that both shallow and deep networks can fit at any function, but as deep networks have several hidden layers often of different types so they are able to build or extract better features than shallow models with fewer parameters.
3. What is a cost function?
Answer:
A cost function is a measure of the accuracy of the neural network with respect to given training sample and expected output. It is a single value, nonvector as it gives the performance of the neural network as a whole. It can be calculated as below Mean Squared Error function:-
MSE=1n∑i=0n(Y^i–Yi)²
Where Y^ and desired value Y is what we want to minimize.
4. What is a gradient descent?
Answer:
Gradient descent is basically an optimization algorithm, which is used to learn the value of parameters that minimizes the cost function. Furthermore, It is an iterative algorithm which moves in the direction of steepest descent as defined by the negative of the gradient. We compute the gradient descent of the cost function for a given parameter and update the parameter by the below formula:-
Θ:=Θ–αd∂ΘJ(Θ)
Where Θ — is the parameter vector, α — learning rate, J(Θ) — is a cost function.
5. What is a backpropagation?
Answer:
Backpropagation is a training algorithm used for multilayer neural network. In this method, we move the error from an end of the network to all weights inside the network and thus allowing efficient computation of the gradient. It consists of several steps as follows:-
Forward propagation of training data in order to generate output.
Then using the target value and output value error derivative can be computed with respect to output activation.
Then we back propagate for computing derivative of error with respect to output activation on previous and continue this for all the hidden layers.
Using previously calculated derivatives for output and all hidden layers we calculate error derivatives with respect to weights.
And then we update the weights.
6. Explain the following three variants of gradient descent: batch, stochastic and mini-batch?
Answer:
Stochastic Gradient Descent: Here we use only single training example for calculation of gradient and update parameters.
Batch Gradient Descent: Here we calculate the gradient for the whole dataset and perform the update at each iteration.
Mini-batch Gradient Descent: It’s one of the most popular optimization algorithms. It’s a variant of Stochastic Gradient Descent and here instead of single training example, mini-batch of samples is used.
7. What are the benefits of mini-batch gradient descent?
Answer:
Below are the benefits of mini-batch gradient descent
•This is more efficient compared to stochastic gradient descent.
•The generalization by finding the flat minima.
•Mini-batches allows help to approximate the gradient of the entire training set which helps us to avoid local minima.
8. What is data normalization and why do we need it?
Answer:
Data normalization is used during backpropagation. The main motive behind data normalization is to reduce or eliminate data redundancy. Here we rescale values to fit into a specific range to achieve better convergence.
9. What is weight initialization in neural networks?
Answer:
Weight initialization is one of the very important steps. A bad weight initialization can prevent a network from learning but good weight initialization helps in giving a quicker convergence and a better overall error. Biases can be generally initialized to zero. The rule for setting the weights is to be close to zero without being too small.
10. What is an auto-encoder?
Answer:
An autoencoder is an autonomous Machine learning algorithm that uses backpropagation principle, where the target values are set to be equal to the inputs provided. Internally, it has a hidden layer that describes a code used to represent the input.
Some Key Facts about the autoencoder are as follows:-
•It is an unsupervised ML algorithm similar to Principal Component Analysis
•Minimizes the same objective function as Principal Component Analysis
•It is a neural network
•The neural network’s target output is its input
11. Is it OK to connect from a Layer 4 output back to a Layer 2 input?
Answer:
Yes, this can be done considering that layer 4 output is from previous time step like in RNN. Also, we need to assume that previous input batch is sometimes- correlated with the current batch.
12. What is a Boltzmann Machine?
Answer:
Boltzmann Machine is a method to optimize the solution of a problem. The work of the Boltzmann machine is basically to optimize the weights and the quantity for the given problem.
Some important points about Boltzmann Machine −
•It uses recurrent structure.
•Consists of stochastic neurons, which consist one of the two possible states, either 1 or 0.
•The neurons in this are either in adaptive (free state) or clamped (frozen state).
•If we apply simulated annealing on discrete Hopfield network, then it would become Boltzmann Machine.
13. What is the role of the activation function?
Answer:
The activation function is a method to introduce non-linearity into the neural network helping it to learn more complex function. Furthermore, without which the neural network would be only able to learn linear function which is a linear combination of its input data.
Follow this link if you are looking forward to becoming an AI expert
It is the perfect time to move ahead of the curve and position yourself with the skills needed to fill these emerging gaps in data science and analysis. Most importantly, this is not only for people who are at the very beginning of their careers and who decide on the path to study. Hence, professionals already in the workforce can benefit from this data science trend, perhaps even more than their fresh counterparts.
In a 2017 business research article IBM predicted that the need for Data Scientists will increase by 28% by 2020, with nearly 3 million job openings for Data Science professionals. According to a Forbes report, Data Science is the best job in America for three consecutive years, with a median base salary of $110,000 and over 4,524 job openings.
According to Glassdoor’s 50 Best Jobs In America For 2018 research, Data Scientist jobs are among the 50 best jobs based on each job’s overall Glassdoor Job Score. We calculate the Glassdoor Job Score by weighing three key factors equally: earning potential based on the median annual base salary, job satisfaction rating, and the number of job openings. Hence, the need for sharpening Data Scientist skills are at an all-time high.
In this blog, we will be looking at all the technical and non-technical skills that are absolute in mastering the domain of data science.
Technical Skills
R & Python
R is a language for statistical computations, data analysis and graphical representation of data. It is a very popular language in academia. Many researchers and scholars use it for experimenting with data science. Many popular books and learning resources on data science use R for statistical analysis as well. Also, it has an extensive library of tools for database manipulation and wrangling. Data visualization is the visual representation of data in graphical form. This allows analyzing data from angles which are not clear in unorganized or tabulated data. R has many tools that can help in data visualization, analysis, and representation. The packages ggplot2 and ggedit for have become the standard plotting packages. Also, It allows practising a wide variety of statistical and graphical techniques like time-series analysis, classification, classical statistical tests, clustering, etc.
When it comes to data science, Python is a very powerful tool, which is also open sourced and flexible, adding more to its popularity. It has massive libraries for manipulation of data and is extremely easy to learn and use for all data analysts. Anyone who is familiar with programming languages such as, Java, Visual Basic, C++ or C, will find this tool to be very accessible and easy to work with. Apart from being an independent platform, this tool has the ability to easily integrate with the existing Infrastructure and can also solve the most difficult of problems. This tool is powerful, friendly, easy and plays well with others, apart from running everywhere. A lot of banks use this tool for the purpose of crunching data, some institutions use it for analyzing and visualization. This tool offers the great benefit of using one programming language, across multiple application platforms.
Python has already been proven to be as good as R Programming is, in terms of all the process under data analytics. Any novice, entering the field of data analytics can use this programming language to start in the data science industry. As a result of its multipurpose uses, there are a lot of institutes, which offer courses in Python.
Hadoop
Hadoop is an open-source software framework that provides for processing of large data sets across clusters of computers using simple programming models. It can scale up from single servers to thousands of machines.
Hadoop grew out of an open-source search engine called Nutch, developed by Doug Cutting and Mike Cafarella. Back in the early days of the Internet, the pair were looking forward to inventing a way to return web search results faster by distributing data and calculations across different computers so multiple tasks could execute at the same time.
It has a lot to offer. Benefits are :
Computing power: Hadoop’s distributed computing model allows it to process huge amounts of data. The more nodes you use, the more processing power you have.
Flexibility: Hadoop stores data without requiring any preprocessing. Store data — even unstructured data such as text, images, and video — now; decide what to do with it later.
Fault tolerance: Hadoop automatically stores multiple copies of all data, and if one node fails during data processing, jobs are redirected to other nodes and distributed computing continues.
Low cost: The open-source framework is free, and data is stored on commodity hardware.
Scalability: You can easily grow your Hadoop system, simply by adding more nodes.
Although the development of Hadoop came from the need to search millions of web pages and return relevant results, it today serves a variety of purposes. Hadoop’s low-cost storage makes it an appealing option for storing information that is not currently critical but that might be analyzed later.
Spark
Hadoop continues to garner the most name-recognition in big data processing, but Spark is, appropriately, beginning to ignite it’s utility as a vehicle for data analysis and processing, versus simply data storage.
It consists of four core components:
Hadoop Common — Essential utilities and tools referenced by the other modules
Distributed File System — The high-throughput file storage system (HDFS)
Hadoop YARN — The job-scheduling framework for distributed process allocation
MapReduce — The parallel processing module based on YARN
Spark replaces only two of those, YARN and MapReduce. According to a February 2016 article in Information Week, many Spark implementations chug happily away on top of Hadoop Common code and the HDFS. Thanks to the integration, many major companies that have implemented Hadoop clusters to deal with insane amounts of data — the likes of Amazon and Facebook — have kept the data storage elements and simply swapped in Spark as a high-performance alternative to MapReduce.
SQL
SQL, or Structured Query Language, is a special-purpose programming language for managing data held in relational database management systems. Almost all structured data resides in such databases, so, if you want to play with data, chances are you’ll want to know some SQL.
Here are some awesome things you can do with SQL
Generate queries from a query: Basic string concatenation makes it easy to generate en masse queries that use data in a database to fetch data found in another system.
Handle dates: “Fantastic date functions” exist to meet all your formatting and type conversion needs.
Text mining: Yhat recommends going as far as you can with SQL’s built-in string functions before turning to a scripting language.
Find the median: Since there’s no built-in aggregate function for median, Yhat provides the code.
Load data into your database with the \COPY command.
Generate sequences: Use the generate_series function to create ranges of dates and times and to handle time series and funnels.
Machine Learning
Simply put, Machine Learning is the core subarea of artificial intelligence. It makes computers get into a self-learning mode without explicit programming. When fed new data, these computers learn, grow, change, and develop by themselves.
The machine learning field is constantly evolving. And along with evolution comes a rise in the demand and importance. There is one crucial reason why data scientists need machine learning, and that is: ‘High-value predictions that can guide better decisions and smart actions in real time without human intervention’.
Machine learning as a technology helps analyze large chunks of data, easing the tasks of data scientists in an automated process and is gaining a lot of prominence and recognition. Machine learning has changed the way data extraction and interpretation works by involving automatic sets of generic methods that have replaced the traditional statistical techniques.
Non-Technical Skills
Now, the skill set of a successful data scientist will comprise both technical and non-technical skills. While technical skills like programming and quantitative analysis are important, it is easy to undervalue the impact of non-technical skills. So, before we go on to the technical stuff, here is a list of 5 non-technical skills that you must possess:
Communication
Effective business communication is one of the most important abilities. Whether it’s understanding the business requirements or the problem at hand, seeking more data from stakeholders or communicating insights, a data scientist needs to be convincing. ” Storytelling, ” as data scientists call it, means that analytical solutions are communicated in a clear, concise and timely manner in order to benefit both technical and non-technical people. Data visualization and presentation tools are widely employed by data scientists for their graphic appeal and easy absorption by all teams in the organization. Often underestimated, this is one of the most important skills for the simple reason that all statistical computation is useless if the teams can’t act upon it.
Data-Driven Decision Making
A data scientist will not conclude, judge, or decide without adequate data. Scientists need to decide their approach to a business problem in addition to deciding several other things like where to look, what tools and techniques to use, and how to visualize and communicate it in the most effective possible way. The most important thing for them is to ask relevant questions, even if they seem far-fetched. Think of it as a child exploring all his surroundings to draw conclusions. A data scientist is pretty much the same.
Mathematical and Statistical Acumen
A data scientist will never thrive if he/she doesn’t understand what test to run when and how to interpret their findings. They need a solid understanding of algebra and calculus. In good old days, Math was a subject based on common sense and the need to resolve basic problems based on logic. This hasn’t changed much, though the scale has blown up exponentially. A statistical sensibility provides a solid foundation for several analysis tools and techniques, which are used by a data scientist to build their models and analytic routines.
Teamwork
Teamwork is another feather in the cap that data scientists can not do without. Although they may appear to be able to work in isolation, they are closely involved in the organization at various levels. On the one hand, they will have to work with the teams to understand their requirements, collect feedback to achieve beneficial solutions, and on the other hand work with data scientists, data architects and data engineers to perform their tasks well. The culture in a data-driven organization will never be that of the data science team working in isolation; instead, the team will have to use the same characteristics across the organization to make the best use of the insights they draw from various departments.
Intellectual Curiosity and Passion
This is a tad-bit cliched but true. Data scientists are passionate about their work and have an inconsolable itch to use data to find patterns and provide solutions to business problems. They often have to work with unstructured data and rarely know the exact steps they need to take to find valuable insights that lead to business growth. Sometimes, they don’t even have a clear problem to work with, just signs that there is something wrong. That’s where their intellectual curiosity guides them to look in areas no one else has looked in. You don’t need to read “How to think like Sherlock,” just ask a data scientist!
Conclusion
The next question I always get is, “What can I do to develop these skills?” There are many resources around the web, but I don’t want to give anyone the mistaken impression that the path to data science is as simple as taking a few MOOCs. Unless you already have a strong quantitative background, the road to becoming a data scientist will be challenging but not impossible.
However, if it’s something you sincerely want to pursue and have a passion for data and lifelong learning, don’t let your background discourage you from pursuing data science as a career.
A decade ago, machine learning was simply a concept but today it has changed the way we interact with technology. Devices are becoming smarter, faster and better, with Machine Learning at the helm.
Thus, we have designed a comprehensive list of projects in Machine Learning course that offers a hands-on experience with ML and how to build actual projects using the Machine Learning algorithms. Furthermore, this course is a follow up to our Introduction to Machine Learning course and delves further deeper into the practical applications of Machine Learning.
Progressing step by step
In this blog, we will have a look at projects divided mostly into two different levels i.e. Beginners and Advanced. First, projects mentioned under the beginner heading cover important concepts of a particular technique/algorithm. Similarly, projects under advanced category involve the application of multiple algorithms along with key concepts to reach the solution of the problem at hand.
Projects offered by Dimensionless Technologies
We have tried to take a more exciting approach to Machine Learning, by not working on simply the theory of it, but instead by using the technology to actually build real-world projects that you can use. Furthermore, you will learn how to write the codes and then see them in action and actually learn how to think like a machine learning expert.
Following are some of the projects among many others that they cover in their courses:
Disease Detection — In this project, you will use the K-nearest neighbor algorithm to help detect breast cancer malignancies by using a support vector machine.
Credit Card Fraud Detection — In this project, you are going to do a credit card fraud detection and going to focus on anomaly detection by using probability densities.
Stock Market Clustering Project — In this project, you will use a K-means clustering algorithm to identify related companies by finding correlations among stock market movements over a given time span.
Beginners
1) Iris Flowers Classification ML Project– Learn about Supervised Machine Learning Algorithms
Iris flowers dataset is one of the best data sets in classification literature. The classification of the iris flowers machine learning project is often referred to as the “Hello World” of machine learning. Furthermore, this dataset has numeric attributes and beginners need to figure out how to load and handle data. Also, the iris dataset is small which easily fits into the memory and does not require any special transformations or scaling, to begin with.
The goal of this machine learning project is to classify the flowers into among the three species — virginica, setosa, or versicolor based on length and width of petals and sepals.
2) Social Media Sentiment Analysis using Twitter Dataset
Platforms like Twitter, Facebook, YouTube, Reddit generate huge amounts of big data that can be mined in various ways to understand trends, public sentiments, and opinions. A sentiment analyzer learns about various sentiments behind a “content piece” through machine learning and predicts the same using AI. Also, Twitter data is considered a definitive entry point for beginners to practice sentiment analysis. Hence, using Twitter dataset, one can get a captivating blend of tweet contents and other related metadata such as hashtags, retweets, location and more which pave way for insightful analysis. Using Twitter data you can find out what the world is saying about a topic whether it is movies, sentiments about any trending topic. Probably, working with the Twitter dataset will help you understand the challenges associated with social media data mining and also learn about classifiers in depth.
3) Sales Forecasting using Walmart Dataset
Walmart dataset has sales data for 98 products across 45 outlets. Also, the dataset contains sales per store, per department on weekly basis. The goal of this machine learning project is to forecast sales for each department in each outlet consequently which will help them make better data-driven decisions for channel optimization and inventory planning. Certainly, the challenging aspect of working with Walmart dataset is that it contains selected markdown events which affect sales and should be taken into consideration.
In the book Moneyball, the Oakland A’s revolutionized baseball through analytical player scouting. Furthermore, they built a competitive squad while spending only 1/3 of what large market teams like the Yankees were paying for salaries.
First, if you haven’t read the book yet, you should check it out. Ceratinly, It’s one of our favorites!
Fortunately, the sports world has a ton of data to play with. Data for teams, games, scores, and players are all tracked and freely available online.
There are plenty of fun machine learning projects for beginners. For example, you could try…
Sports Betting… Predict box scores given the data available at the time right before each new game.
Talent scouting… Use college statistics to predict which players would have the best professional careers.
General managing… Create clusters of players based on their strengths in order to build a well-rounded team.
Sports is also an excellent domain for practicing data visualization and exploratory analysis. You can use these skills to help you decide which types of data to include in your analyses.
Data Sources
Sports Statistics Database — Sports statistics and historical data covering many professional sports and several college ones. The clean interface makes it easier for web scraping.
Sports Reference — Another database of sports statistics. More cluttered interface, but individual tables can be exported as CSV files.
cricsheet.org — Ball-by-ball data for international and IPL cricket matches. CSV files for IPL and T20 internationals matches are available.
As the name suggests (no points for guessing), this dataset provides the data on all the passengers who were aboard the RMS Titanic when it sank on 15 April 1912 after colliding with an iceberg in the North Atlantic ocean. Also, it is the most commonly used and referred to data set for beginners in data science. With 891 rows and 12 columns, this data set provides a combination of variables based on personal characteristics such as age, class of ticket and sex, and tests one’s classification skills.
Objective: Predict the survival of the passengers aboard RMS Titanic.
Advance level projects
This is where an aspiring data scientist makes the final push into the big leagues. After acquiring the necessary basics and honing them in the first two levels, it is time to confidently play the big game. Certainly, these datasets provide a platform for putting to use all the learnings and take on new, and more complex challenges.
This data set is a part of the Yelp Dataset Challenge conducted by crowd-sourced review platform, Yelp. It is a subset of the data of Yelp’s businesses, reviews, and users, provided by the platform for educational and academic purposes.
In 2017, the tenth round of the Yelp Dataset Challenge was held and the data set contained information about local businesses in 12 metropolitan areas across 4 countries.
Rich data comprising 4,700,000 reviews, 156,000 businesses, and 200,000 pictures provides an ideal source of data for multi-faceted data projects. Projects such as natural language processing and sentiment analysis, photo classification, and graph mining among others, are some of the projects that can be carried out using this dataset containing diverse data. The data set is available in JSON and SQL formats.
Objective: Provide insights for operational improvements using the data available.
With the increasing demand to analyze large amounts of data within small time frames, organizations prefer working with the data directly over samples. Consequently, this presents a herculean task for a data scientist with a limitation of time.
This dataset contains information on reported incidents of crime in the city of Chicago from 2001 to the present. It does not contain data from the most recent seven days. Not included in the data set, is data on murder, where data is recorded for each victim.
It contains 6.51 million rows and 22 columns and is a multi-classification problem. In order to achieve mastery over working with abundant data, this dataset can serve as the ideal stepping stone.
Objective: Explore the data, and provide insights and forecasts about crimes in Chicago.
KKD cup is a popular data mining and knowledge discovery competition held annually. It is one of the first-ever data science competition which dates back to 1997.
Every year, the KDD cup provides data scientists with an opportunity to work with data sets across different disciplines. Some of the problems tackled in the past include
Identifying which authors correspond to the same person
Predicting the click-through rate of ads using the given query and user information
Development of algorithms for Computer Aided Detection (CAD) of early-stage breast cancer among others.
The latest edition of the challenge was held in 2017 and required participants to predict the traffic flow through highway tollgates.
Objective: Solve or make predictions for the problem presented every year.
Conclusion
Undertaking different kinds of projects is one of the good ways through which one can progress in any field. Certainly, this allows an individual to have hands on at the problems faced during the implementation phase. Also, it is easier to learn concepts by applying them. Finally, you will have a feeling of doing actual work rather than just being all lost in the theoretical part.
There are wonderful competitions available on kaggle and other similar data science competition platforms. Hence, make sure you take some time out and jump into these competitions. Whether you are a beginner or a pro, certainly, there is a lot of learning available while attempting these projects.