Top 10 Machine Learning Algorithms
Introduction
Machine learning paradigm is ruled by a simple theorem known as “No Free Lunch” theorem. According to this, there is no algorithm in ML which will work best for all the problems. To state, one can not conclude that SVM is a better algorithm than decision trees or linear regression. Selection of an algorithm is dependent on the problem at hand and other factors like the size and structure of the dataset. Hence, one should try different algorithms to find a better fit for their use case
In this blog, we are going to look into the top machine learning algorithms. You should know and implement the following algorithms to find out the best one for your use case
Top 10 Best Machine Learning Algorithms
1. Linear Regression
Regression is a method used to predict numerical numbers. Regression is a statistical measure which tries to determine the power of the relation between the label-related characteristics of a single variable and other factors called autonomous (periodic attributes) variable. Regression is a statistical measure. Just as the classification is used for categorical label prediction, regression is used for ongoing value prediction. For example, we might like to anticipate the salary or potential sales of a new product based on the prices of graduates with 5-year work experience. Regression is often used to determine how the cost of an item is affected by specific variables such as product cost, interest rates, specific industries or sectors.
The linear regression tries by a linear equation to model the connection between a scalar variable and one or more explaining factors. For instance, using a linear regression model, one might want to connect the weights of people to their heights
The driver calculates a linear pattern of regression. It utilizes the model selection criterion Akaike. A test of the comparative value of fitness to statistics is the Akaike information criterion. It is based on the notion of entropy, which actually provides a comparative metric of data wasted when a specified template is used to portray the truth. The compromise between bias and variance in model building or between the precision and complexity of the model can be described.
2. Logistic Regression
Logistic regression is a classification system that predicts the categorical results variable that may take one of the restricted sets of category scores using entry factors. A binomial logistical regression is restricted to 2 binary outputs and more than 2 classes can be achieved through a multinomial logistic regression. For example, classifying binary conditions as’ safe’/’don’t-healthy’ or’ bike’ /’ vehicle’ /’ truck’ is logistic regression. Logistic regression is used to create an information category forecast for weighted entry scores by the logistic sigmoid function.
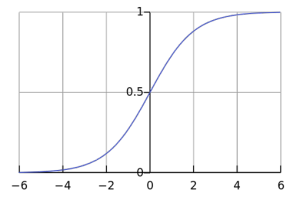
The probability of a dependent variable based on separate factors is estimated by a logistic regression model. The variable depends on the yield that we want to forecast, whereas the indigenous variables or explaining variables may affect the performance. Multiple regression means an assessment of regression with two or more independent variables. On the other side, multivariable regression relates to an assessment of regression with two or more dependent factors.
3. Linear Discriminant Analysis
Logistic regression is traditionally a two-class classification problem algorithm. If you have more than two classes, the Linear Discriminant Analysis algorithm is the favorite technique of linear classification. It contains statistical information characteristics, which are calculated for each category.
For a single input variable this includes:
- The mean value for each class.
- The variance calculated across all classes.
The predictions are calculated by determining a discriminating value for each class and by predicting the highest value for each class. The method implies that the information is distributed Gaussian (bell curve) so that outliers are removed from your information in advance. It is an easy and strong way to classify predictive problem modeling.
4. Classification and Regression Trees
Prediction Trees are used to forecast answer or YY class of X1, X2,…, XnX1,X2,… ,Xn entry. If the constant reaction is called a regression tree, it is called a ranking tree, if it is categorical. We inspect the significance of one entry XiXi at any point of the tree and proceed to the left or to the correct subbranch, based on the (binary) response. If we hit a tree, we will discover the forecast (generally the leaves as the most popular value of the accessible courses is a straightforward statistical figure of the dataset).
In contrast to global model linear or polynomial regression (a predictive formula should be contained in the whole data space), trees attempt to split the data space in a sufficiently small part, where a simply different model can be applied on each side. For each xx information, the non-leaf portion of the tree is simply the process to determine what model we use for the classification of each information (i.e. which leaf).
5. Naive Bayes
A Naive Bayes classification is a supervised algorithm for machinery-learning which utilizes the theorem of Bayes, which implies statistical independence of its characteristics. The theorem depends on the naive premise that input factors are autonomous from each other, that is, that when an extra variable is provided there is no way to understand anything about other factors. It has demonstrated to be a classifier with excellent outcomes regardless of this hypothesis.
The Bavarian Theorem, relying on a conditional probability, or in easy words, is used for the Naive Bayes classifications as a probability of a case (A) occurring considering that another incident (B) has already occurred. In essence, the theorem enables an update of the hypothesis every moment fresh proof is presented.
The equation below expresses Bayes’ Theorem in the language of probability:

Let’s explain what each of these terms means.
- “P” is the symbol to denote probability.
- P(A | B) = The probability of event A (hypothesis) occurring given that B (evidence) has occurred.
- P(B | A) = The probability of the event B (evidence) occurring given that A (hypothesis) has occurred.
- P(A) = The probability of event B (hypothesis) occurring.
- P(B) = The probability of event A (evidence) occurring.
6. K-Nearest Neighbors
The KNN is a simple machine study algorithm which classifies an entry using its closest neighbours.
The input of information points of particular males and women’s height and weight as shown below should be provided, for instance, by a k-NN algorithm. K-NN can peer into the closest k neighbour (personal) and determine if the entry gender is masculine in order to determine the gender of an unidentified object (green point). This technique is extremely easy and logical, with a strong achievement level for labelling unidentified input.
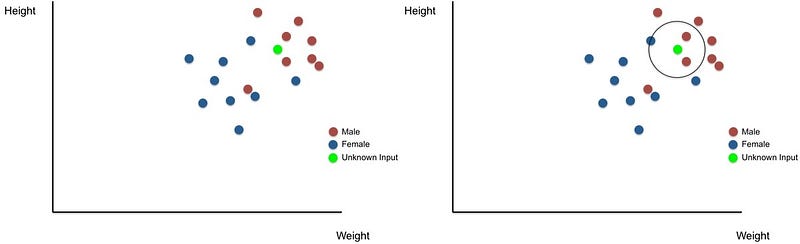
k-NN is used in a range of machine learning tasks; k-NN, for example, can help in computer vision in hand-written letters and the algorithm is used to identify genes that are contributing to a specific characteristic of the gene expression analysis. Overall, neighbours close to each other offer a mixture of ease and efficiency that makes it an appealing algorithm for many teaching machines.7. Learning Vector Quantization
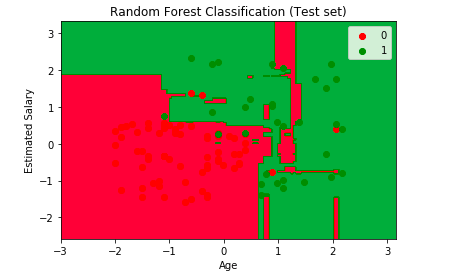
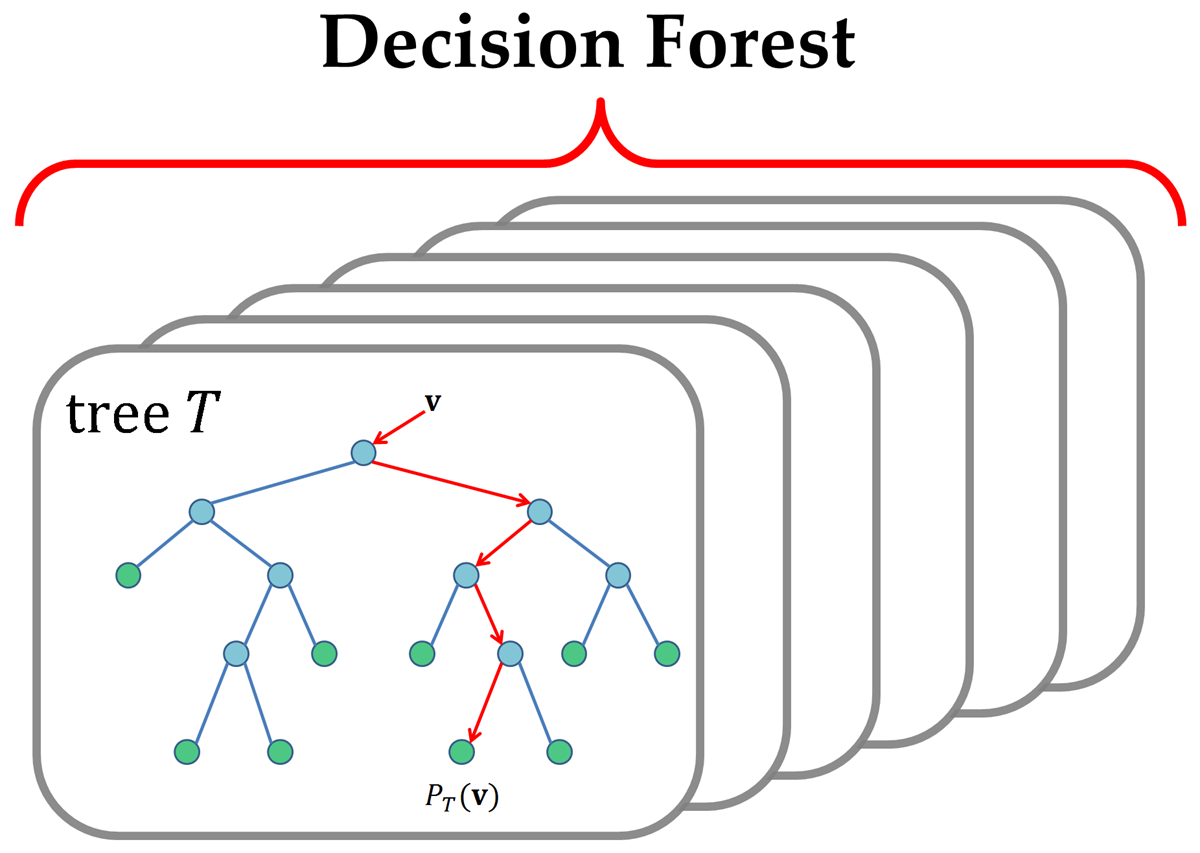
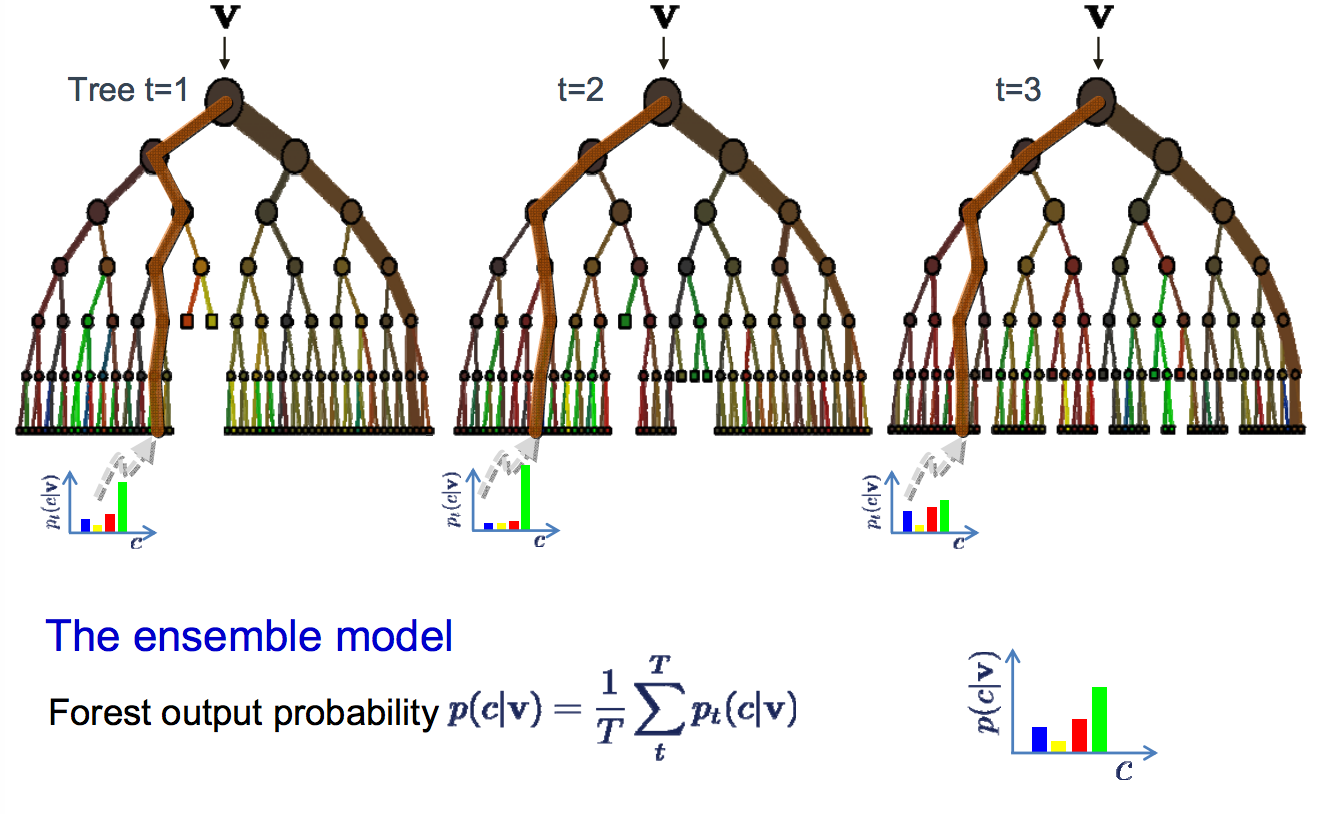
8. Bagging and Random Forest
A Random Forest is a group of easy tree predictors, each of which is capable of generating an answer when it has a number of predictor values. This reaction requires the form of a class affiliation for classification issues, which combines or classifies a number of indigenous predictor scores with one of the classifications in the dependent variable. Otherwise, the tree reaction is an assessment of the dependent variable considering the predictors for regression difficulties. Breiman has created the Random Forest algorithm.
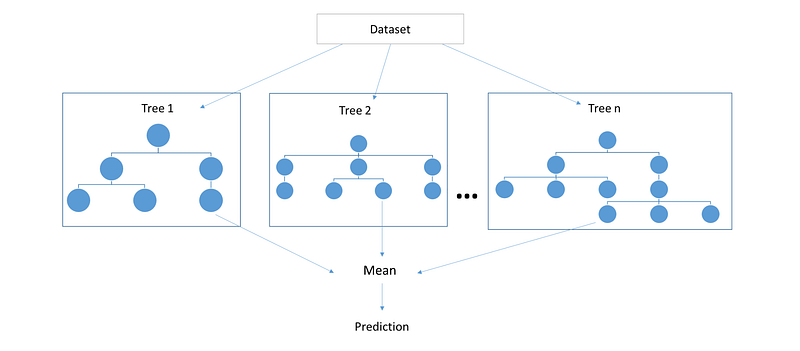
An arbitrary amount of plain trees are a random forest used to determine the ultimate result. The ensemble of easy trees votes for the most common category for classification issues. Their answers are averaged to get an assessment of the dependent variable for regression problems. With tree assemblies, the forecast precision (i.e. greater capacity to detect fresh information instances) can improve considerably.
9. SVM
The support vector machine(SVM) is a supervised, classifying, and regressing machine learning algorithm. In classification issues, SVMs are more common, and as such, we shall be focusing on that article.SVMs are based on the idea of finding a hyperplane that best divides a dataset into two classes, as shown in the image below.
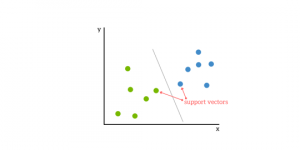
You can think of a hyperplane as a line that linearly separates and classifies a set of data.
The more our information points are intuitively located from the hyperplane, the more assured that they have been categorized properly. We would, therefore, like to see as far as feasible from our information spots on the right hand of the hyperplane.
So when new test data are added, the class we assign to it will be determined on any side of the hyperplane.
The distance from the hyperplane to the nearest point is called the margin. The aim is to select a hyperplane with as much margin as feasible between the hyperplane and any point in the practice set to give fresh information a higher opportunity to be properly categorized.
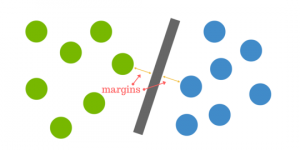
But the data is rarely ever as clean as our simple example above. A dataset will often look more like the jumbled balls below which represent a linearly non-separable dataset.

It is essential to switch from a 2D perspective to a 3D perspective to classify a dataset like the one above. Another streamlined instance makes it easier to explain this. Imagine our two balls stood on a board and this booklet is raised abruptly, throwing the balls into the air. You use the cover to distinguish them when the buttons are up in the air. This “raising” of the balls reflects a greater identification of the information. This is known as kernelling.
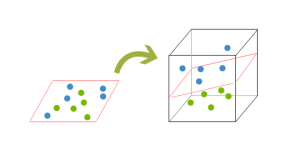
Our hyperplanes can be no longer a row because we are in three dimensions. It should be a flight now, as shown in the above instance. The concept is to map the information into greater and lower sizes until a hyperplane can be created to separate the information.
10. Boosting and AdaBoost
Boosting is an ensemble technology which tries to build a powerful classification of a set of weak classifiers. This is done using a training data model and then a second model has created that attempts the errors of the first model to be corrected. Until the training set is perfectly predicted or a maximum number of models are added, models are added.
AdaBoost was the first truly effective binary classification boosting algorithm. It is the best point of start for improvement. Most of them are stochastic gradient boosters, based on AdaBoost modern boosting techniques.
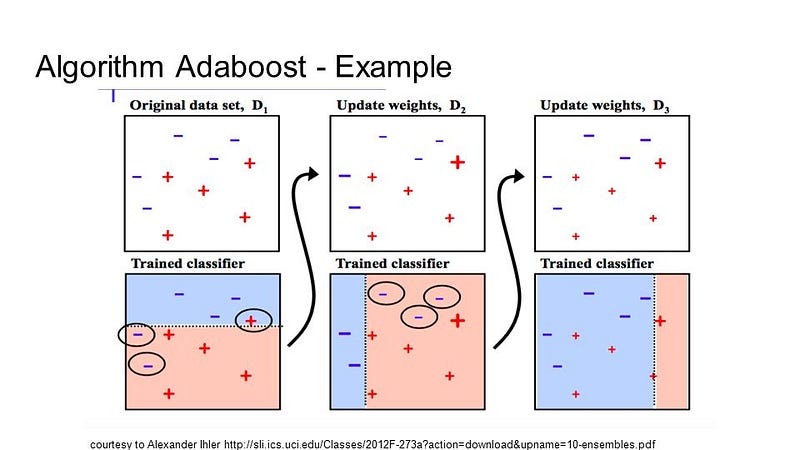
With brief choice trees, AdaBoost is used. After the creation of the first tree, each exercise instance uses the performance of the tree to weigh how much attention should be given to the next tree to be built. Data that are difficult to forecast will be provided more weight, while cases that are easily predictable will be less important. Sequentially, models are produced one by one to update each of the weights on the teaching sessions which impact on the study of the next tree. After all, trees have been produced, fresh information are predicted and how precise it was on the training data weighs the efficiency of each tree.
Since the algorithm is so careful about correcting errors, it is essential that smooth information is deleted with outliers.
Summary
In the end, every beginner in data science has one basic starting questions that which algorithm is best for all the cases. The response to the issue is not straightforward and depends on many factors like information magnitude, quality and type of information; time required for computation; the importance of the assignment; and purpose of information
Even an experienced data scientist cannot say which algorithm works best before distinct algorithms are tested. While many other machine learning algorithms exist, they are the most common. This is a nice starting point to understand if you are a beginner for machine learning.
Follow this link, if you are looking to learn data science online!
You can follow this link for our Big Data course!
Additionally, if you are having an interest in learning Data Science, click here to start the Online Data Science Course
Furthermore, if you want to read more about data science, read our Data Science Blogs