Principal Component Analysis or PCA is one of the simplest and fundamental techniques used in machine learning. It is perhaps one of the oldest techniques available for dimensionality reduction, and thus, its understanding is of paramount importance for any aspiring Data Scientist/Analyst. An in-depth understanding of PCA in R will not only help in the implementation of effective dimensionality reduction but also help to build the foundation for development and understanding of other advanced and modern techniques.
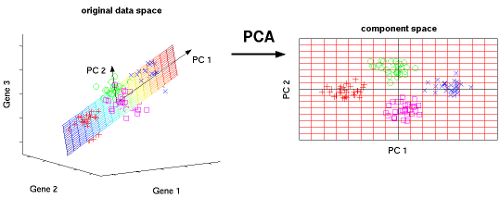
Examples of Dimension Reduction from 2-D space to 1-D space Courtesy: Bits of DNA
PCA aims to achieve two
primary goals:
1. Dimensionality
Reduction
Real-life data has several features generated from numerous resources. However, our machine learning algorithms are not adept enough to handle high dimensions efficiently. Feeding several features, all at once, almost always leads to poor results since the models cannot grasp and learn from such volume altogether. This is called the “Curse of Dimensionality” which leads to unsatisfactory results from the models implemented. Principal Component Analysis in R helps resolve this problem by projecting n dimensions to n-x dimensions (where x is a positive number), preserving as much variance as possible. In other words, PCA in R reduces the number of features by transforming the features into a lesser number of projections of themselves.
2. Visualization
Our visualization systems are limited to 2-dimensional space which prevents us from forming a visual idea of the high dimensional features in the dataset. PCA in R resolves this problem by projecting n dimensions to a 2-D environment, enabling sound visualization. These visualizations sometimes reveal a great deal about the data. For instance, the new feature projections may form clusters in the 2-D space which was previously not perceivable in higher dimensions.
Visualization with PCA (n-D to 2-D) Courtesy: nlpca.org
Intuition
Principal Component Analysis in R works with the simple idea of projection of a higher space to a lower space or dimension
The two alternate objectives of Principal Component Analysis are:
1. Variance Maximization
Formulation
2. Distance Minimization
Formulation
Let us demonstrate the above with the help of simple examples. If you have 2 features, and you wish to reduce the features to a 1-D feature set using PCA in R, you must lookout for the direction with maximal spread/variance. This becomes the new direction on which every data point is projected. The direction perpendicular to this direction has the least variance, and is thus, discarded.
Alternately, if one focuses on the perpendicular distance between a data point and the direction of maximum variance, our objective shifts to the minimization of that distance. This is because, lesser the distance, higher is the authenticity of the projection.
On completion of these projections, you would have successfully transformed your 2-D data to a 1-D dataset.
Mathematical Intuition
Principal Component Analysis in R locates the distance of maximal spread (or direction of minimal distance from data points) with the use of Eigen Vectors and Eigen Values. Every Eigen Vector (Vi) corresponds to an Eigen Value (Ei).
If X is a feature matrix (matrix with the feature values),
covariance matrix S = XT. X
If EiVi = SVi ,
Then Ei is an Eigen Value, and Vi becomes the corresponding Vector.
If there are d dimensions, there will be d Eigenvalues with d corresponding Eigen Vectors, such that:
E1>=E2>=E3>=E4>=…>=Ed
Each corresponding to V1, V2, V3, …., Vd
Here the vector corresponding to the largest Eigenvalue is the direction of Maximal spread since rotation occurs such that V1 is aligned with maximal variance in the feature space. Vd here has the least variance in its direction.
A very interesting property of Eigenvectors is the fact that if any two vectors are picked randomly from the set of d vectors, they will turn out to be perpendicular to each other. This happens because they align themselves such that they catch the most opposing directions in terms of variance.
When deciding between two Eigen Vector directions, Eigenvalues come into play. If V1 and V2 are two Eigen Vectors (perpendicular to each other), the values associated with these vectors, E1 and E2, help us identify the “percentage of variance explained” in either direction.
Percentage of variance explained Ei/(Sum(d Eigen Values)) where i is the direction we wish to calculate the percentage of variance explained for.
Implementation
Principal Component Analysis in R can either be applied with manual code using the above mathematical intuition, or it can be done using R’s inbuilt functions.
Even if the mathematical concept failed to leave a lasting impression on your mind, be assured that it is not of great consequence. On the other hand, understanding the basic high-level intuition counts. Without using the mathematical formulas, PCA in R can be easily applied using R’s prcomp() and princomp() functions which can be found here.
In order to demonstrate Principal Component Analysis, we will be using R, one of the most widely used languages in Data Science and Machine Learning. R was initially developed as a tool to aid researchers and scientists dealing with statistical problems in the academic field. With time, as more individuals from the academic spheres started seeping into the corporate and industrial sectors, they brought along R and its phenomenal uses along with them. As R got integrated into the IT sector, its popularity increased manifold and several revisions were made with the release of every new version. Today R has several packages and integrated libraries which enables developers and data scientists to instantly access statistical solutions without having to go into the complicated details of the operations. Principal Component Analysis is one such statistical approach which has been taken care of very well by R and its libraries.
For demonstrating PCA in R, we will be using the Breast Cancer Wisconsin Dataset which can be downloaded from here: Data Link
These code statements help to read data into the variables wdbc.
wdbc.pr <- prcomp(wdbc[c(3:32)], center = TRUE, scale = TRUE) summary(wdbc.pr)
The prcomp() function helps to apply PCA in R on the data variable wdbc. This function of R makes the entire process of implementing PCA as simple as writing just one line of code. The internal operations and functions are taken care of and are even optimized in terms of memory and performance to carry out the operations optimally. The range 3:32 is used to tell the function to apply PCA only on the features or columns which lie in the range of 3 to 32. This excludes the sample ID and diagnosis variables since they are identification columns and are invalid as features with no direct significance with regard to the target variable.
wdbc.pr
now stores the values of the principal components.
Let us now
visualize the different attributes of the resulting Principal Components for
the 30 features:
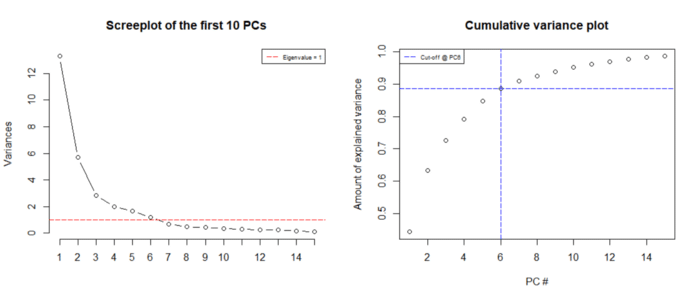
screeplot(wdbc.pr, type = "l", npcs = 15, main = "Screeplot of the first 10 PCs")
This plot
clearly demonstrates that the first 6 components account for 90% of the variance
in the dataset (with Eigen Value > 1). This means that one can easily
exclude 24 features out of 30 features in order to preserve 90% of the data.
Limitations of PCA
Even though Principal Component Analysis in R displays a highly intuitive technique, it hosts certain shocking limitations.
1. Loss of Variance: If the percentage of variance against the chosen axis is around 50-60%, it is evident that 40-50% of the information which contributes to the variance of the dataset is lost during dimensionality reduction. This happens often when the data is spherical or bulging in nature.
2. Loss of Clusters: If there are several clusters present in the original dataset, but most of them lie in the direction perpendicular to the chosen direction. Thus, all the points from different clusters will be projected to the same region on the line of chosen direction, leading to one cluster of data points which are in fact quite different in nature.
3. Loss of Data Patterns: If the dataset forms a nice wavy pattern in direction of maximal spread, PCA takes to project all the points on the line aligned against the direction. Thus, data points which formed a wave function are concentrated on one-dimensional space.
These demonstrate how PCA in R, even though very effective for certain datasets, is a weak instrument for dimensionality reduction or visualization. To resolve these limitations to a certain extent, t-SNE, which is another dimensionality reduction algorithm, is used. Stay tuned to our blogs for a similar and well-guided walkthrough in t-SNE.
Data visualization is an important component of many company approaches due to the growing information quantity and its significance to the company. In this blog, we will be understanding in detail about visualisation in Big Data. Furthermore, we will be looking into the areas like why visualisation in big data is a tedious task or are there any tools available for visualising Big Data
What is Data Visualisation?
Data display represents data in a systematic manner, including information unit characteristics and variables. Data discovery techniques based on visualization enable company consumers to generate customized analytical opinions using disparate information sources. Advanced analytics can be incorporated into techniques for the development on desktop and laptop or mobile devices like tablets and smartphones of interactive and animated Graphics.
What is Big Data Visualisation?
Big data are large volumes, elevated speed and/or high-speed information sets that involve fresh types of handling to optimize processes, discover understanding and make choices. Data capture, storage, evaluation, sharing, searches and visualization face great challenges for big data. Visualization could be considered as “large information front end. There’s no data visualization myth.
It is important to visualize only excellent information: an easy and fast view can show something incorrect with information just like it helps to detect exciting patterns.
Visualization always manifests the correct choice or intervention: visualization is not a substitute for critical thinking.
Visualization brings assurance: data are displayed, not showing an exact image of what is essential. Visualization with various impacts can be manipulated.
Tables, diagrams, pictures and other intuitive display methods to represent the information are created using visualization methods. Visualizing large information is not as simple as conventional tiny information sets. The expansion of traditional methods to visualization was already evolved but far enough. Many scientists use feature extraction and geometrical modeling in large-scale data visualization to significantly decrease the volume of information before real information processing. When viewing big data, it is also very essential to select the correct representation of information.
Problems in Visualising Big Data
In the visual analysis, scalability and dynamics are two main difficulties. The visualization of big data (structured or unstructured) with diversity and heterogeneity is a big difficulty. For big data analysis, speed is the required variable. Big information does not make it simple to design a fresh visualization tool with effective indexing. In order to improve the handling of Big Data scalability factors that influence information viewing decisions, cloud computing, and the sophisticated graphical user interface can be combined with Big Data.
Unstructured information formats such as charts, lists, text, trees, and other information must be used by visualization schemes. Often large information has unstructured formats. Due to the constraints on bandwidth and power consumption, visualization should step nearer to the data to effectively obtain significant information. The software for visualization should be executed on location. Due to the large volume of the information, visualization requires huge parallelisation. The difficulty in simultaneous viewing algorithms is to break down an issue into autonomous functions that can be carried out at the same time.
There are also the following problems for big data visualization:
Visual noise: Most items on the dataset are too related to each other. There are also the following issues when viewing large-scale information. Users can not split them on the display as distinct items.
Info loss: Visible data sets may be reduced, but information loss may occur.
Broad perception of images: data display techniques are restricted not only by aspect ratio and device resolution but also by physical perception limitations.
The elevated pace of changes in the picture: users view information and are unable to respond to the amount of changes in information or its intensity.
High-performance requirements: In static visualization it is hard to notice because of reduced demands for display velocity— high performance demands.
Choice of visualization factors
Audience: The information depiction should be adjusted to the target audience. If clients are ending up in a fitness application and are looking at advancement, then simplicity is essential. On the other side, when information ideas are for scientists or seasoned decision-makers, you can and should often go beyond easy diagrams.
Satisfaction: The data type determines the strategies. For instance, when there are metrics that change over the moment, the dynamics will most likely be shown with line graphs. You will use a dispersion plot to demonstrate the connection between two components. Bar diagrams are ideal for comparison assessment, in turn.
Context: The way your graphs appear can be taken with distinct methods and therefore read according to the framework. For instance, you may want to use colors of one color to highlight a certain figure, which is a major profit increase relative to other years, and choose a shiny one as the most important component on the graph. Instead, contrast colors are used to distinguish components.
Dynamics: Dynamics. Data are distinct and each means a distinct pace of shift. For example, each month or year the financial results can be measured while time series and data tracking change continuously. Dynamic representation (steaming) or a static visualization can be considered, depending on the type of change.
Objective: The objective of viewing the information also has a major effect on the manner in which it is carried out. Visualizations are built into dashboards with checks and filters to carry out a complicated study of a scheme or merge distinct kinds of information for a deeper perspective. Dashboards are, however, not required to display one or more occasional information.
Visualization Techniques for Big Data
1. Word Clouds
Word clouds work easy: the larger and bolder the word is in the term cloud the more a particular word is displayed in a source of text information (such as a lecture, newspaper post or database).
Here is an instance of USA Today using the United States. State of Union Speech 2012 by President Barack Obama:
As you can see, words like “American,” “jobs,” “energy” and “every” stand out since they were used more frequently in the original text.
Now, compare that to the 2014 State of the Union address:
You can easily see the similarities and differences between the two speeches at a glance. “America” and “Americans” are still major words, but “help,” “work,” and “new” are more prominent than in 2012.
2. Symbol Maps
Symbol maps are merely maps shown over a certain length and latitude. You can rapidly create a strong visual with the “Marks” card at Tableau, which tells customers of their place information. You can also use the information to manage the form of the label on the map using the illustration in the Pie chart or forms for a different degree of detail.
These maps can be as simple or as complex as you need them to be
3. Line charts
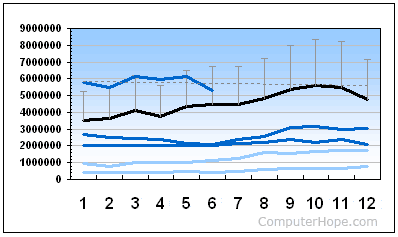
Alternatively known as a row graph, a row graph is a graph of the information shown using a number of rows. Line diagrams show rows horizontally through the diagram, with the scores axis on the left hand of the diagram. An instance of a line chart displaying distinctive Computer Hope travelers can be seen in the image below.
As can be seen in this example, you can easily see the increases and decreases each year over different years.
4. Pie charts
A diagram is a circular diagram, split into sections like wedges, which shows the amount. The complete valuation of each coin is 100% and is a proportional portion of the whole.
The portion size can easily be understood on a look at pie charts. They are commonly used to demonstrate the proportion of expenditure, population sections or study responses across a big number of classifications.
5. Bar Charts
A bar graph is a visual instrument which utilizes bars to match information between cities. bars are also called a bar chart or bar diagram. A bar chart can be executed horizontally or vertically. What we need to understand is that the longer the bar is, the more valuable it is. Two axes are the bar graphs. The horizontal axis (or x-axis) is shown on a graph of the vertical bar, as shown above. They are years in this instance. The vertical axis is the magnitude. The information sequence is the colored rows.
Bar charts have three main attributes:
A bar character allows for a simple comparison of information sets among distinct organizations.
The graph shows classes on one axis and on the other a separate value. The objective is to demonstrate the connection between the two axes.
Bar diagrams can also display over moment large information modifications.
6. Heat Maps
A heat map represents information that are displayed two-dimensionally by color values. An instant visual overview of the data is provided by a straightforward heat chart.
There can be numerous methods to show thermal maps, but they all share one thing in common: to transmit interactions between information values in a tablet, they use a color that would be much difficult to comprehend.
Visualisation Tools for Big Data
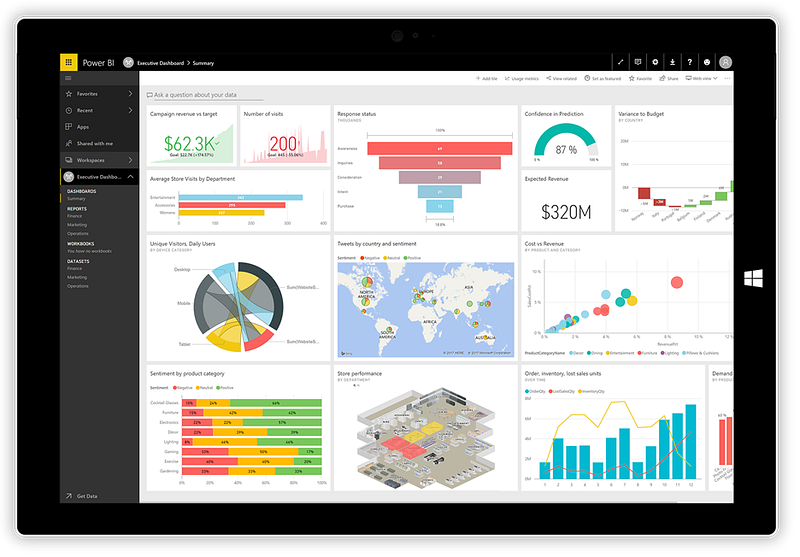
1. Power BI
Power BI is a company analysis option that enables you to view and share your information or integrate them into your app or blog. Connect to hundreds of information sources and live dashboards and accounts to take your information to life.
Microsoft Power BI is used to discover perspectives into the information of an organization. Power BI can communicate, convert and wash information into the data model and generate chart or diagram to display information graphics. All this can be communicated within the organisation with other consumers of Power BI.
Data models generated by Power BI can be used by organizations in many ways, including story telling through charts and views of data and “what if” scenarios inside the data. Power BI accounts can also respond to issues in real time and assist predict how departments will fulfill company criteria.
The Power BI can also provide executives or executives with corporate dashboards to provide them with an understanding of the agencies.
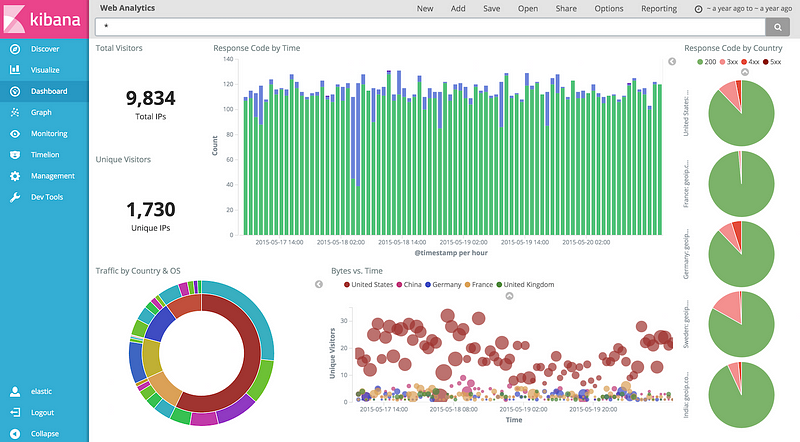
2. Kibana
Kibana is an open-source log analysis and time series analysis information visualization and exploring device for the surveillance of applications and operational intelligence instances. It provides strong and easy-to-use characteristics like histograms, diagrams, pie charts, thermal maps and integrated geospatial assistance. In addition, it ensures close inclusion with the famous analytics and search engine Elasticsearch, which makes Kibana the main option for viewing the information saved in Elasticsearch.
Kibana has been intended with Elasticsearch to render large and complicated information flows understandable by visual depiction more rapidly and smoothly. Elasticsearch analytics provide both information and improved aggregation mathematical transformations. The application produces a versatile, vibrant dashboard with PDF records on request or on timetable. The generated documents can depict information with customisable colors and highlighted search outcomes in the form of bar, row, scatter plot and paste graph sizes. Kibana also involves visualized data sharing instruments.
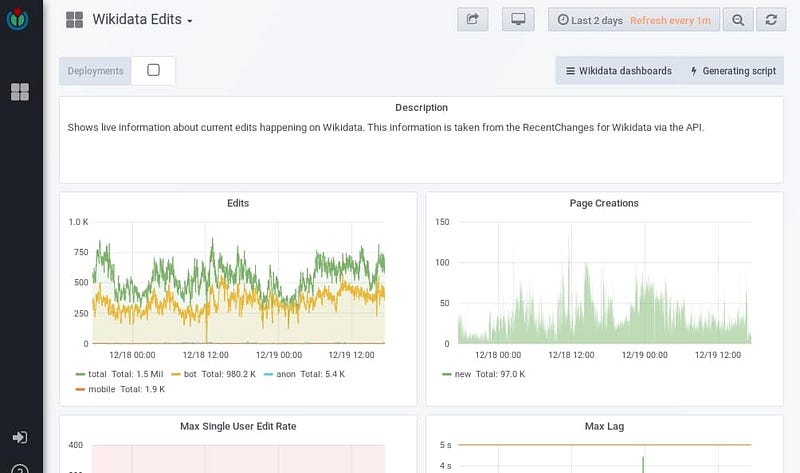
3. Grafana
Grafana is a metrics & visualizing package of open source analysis. It is used most frequently for moment serial data visualization for infrastructure and implementation analysis, but many use it in other areas including agricultural equipment, domestic automation, climate, and process control.
Grafana is a temporary information sequence display instrument. A graphical description can be obtained from a lot of gathered information of the position of a business or organisation. How are they doing it? The collaborative editing of Wikidata, an extensive database of information, that increasingly builds papers in Wikipedia, utilizes the grafana.wikimedia.org to demonstrate openly (in our situation we do so on a regular basis) the publishings conducted out by associates and computers, in a certain span of moment produced and edited’ websites,’ or information sheets:
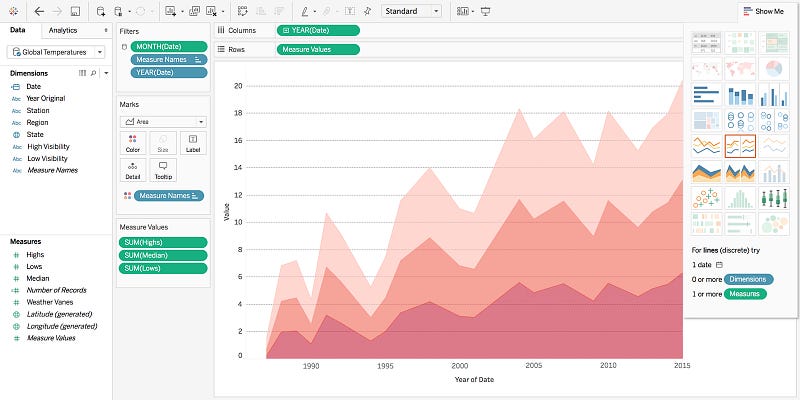
4. Tableau
Tableau has been utilized in the business intelligence industry as a strong and rapidly increasing information vision instrument. It makes it readily understandable to simplify raw information.
Data analysis with Tableau is very quick and the visualizations are in the shape of dashboards and tablets. The information produced using Tableau can be comprehended at every stage in an organisation by the specialist. It even enables a non-technical user a personalized dashboard to be created.
The best feature Tableau are
Data Blending
Real-time analysis
Collaboration of data
Tableau software is fantastic because it does not require any technical or programming abilities to function. The instrument has attracted individuals from all sectors, such as company, scientists, various industries, etc.
Summary
Static or vibrant visualizations can be interactive viewing often results in discovery and works better than static information instruments. Interactive views can assist you to get an overview of big data. The scientific method can be facilitated by interactive brushing and connecting visualisation methods to networks or web-based instruments. The web-based display enables to ensure dynamic data is kept up to date and updated.
There is not sufficient room for extending some standard visualization methods to manage big data. More fresh Big Data viewing techniques and instruments for various Big Data apps should be created
Visualizing the data is important as it makes it easier to understand large amount of complex data using charts and graphs than studying documents and reports. It helps the decision makers to grasp difficult concepts, identify new patterns and get a daily or intra-daily view of their performance. Due to the benefits it possess, and the rapid growth in analytics industry, businesses are increasingly using data visualizations; which can be assessed from the prediction that the data visualization market is expected to grow annually by 9.47% to $7.76 billion by 2023 from $4.51 billion in 2017.
R is a programming language and a software environment for statistical computing and graphics. It offers inbuilt functions and libraries to present data in the form of visualizations. It excels in both basic and advanced visualizations using minimum coding and produces high quality graphs on large datasets.
This article will demonstrate the use of its packages ggplot2 and plotly to create visualizations such as scatter plot, boxplot, histogram, line graphs, 3D plots and Maps.
1. ggplot2
#install package ggplot2
install.packages("ggplot2")
#load the package
library(ggplot2)
There are a lot of datasets available in R in package ‘datasets’, you can run the command data() to list those datasets and use any dataset to work upon. Here I have used the dataset named ‘economics’ which gives the monthly U.S. data of various economic variables like unemployment for the time period 1967-2015.
You can view the data using view function-
view(economics)
Scatter Plot
We’ll make a simple scatter plot to view how unemployment has fluctuated over the years by using plot function-
plot(x = economics$date, y = economics$unemploy)
ggplot() is used to initialize the ggplot object which can be used to declare the input dataframe and set of plot aesthetics. We can add geom components to it that acts as its layer and are used to specify the plot’s features.
We would use its feature geom point which is used to create scatter plots.
ggplot(data = economics, aes(x = date , y = unemploy)) + geom_point()
Modifying Plots
We can modify the plot like its color, shape, size etc. using geom_point aesthetics.
ggplot(data = economics, aes(x = date , y = unemploy)) + geom_point(size = 3)
Lets view the graph by modifying its color-
ggplot(data = economics, aes(x = date , y = unemploy)) + geom_point(size = 3, color = "blue")
Boxplot
Boxplot is a method of graphically depicting groups of numerical data through their quartiles. a geom boxplot layer of ggplot is used to create boxplot of the data.
ggplot(data = economics, aes(x = date , y = unemploy)) + geom_boxplot()
When there is overplotting, one or more points are in the same place and we can’t tell by looking at the plot that how many points are there. In that case, we can use the jitter geom which adds a small amount of variation to the location of each point that is it slightly moves the point, which is used to spread out the points that would otherwise be overplotted.
ggplot(data = economics, aes(x = date , y = unemploy)) +
geom_jitter(alpha = 0.5, color = "red") + geom_boxplot(alpha = 0)
Line Graph
We can view the data in the form of a line graph as well using geom_line.
To change the names of the axis and to give a title to the graph, use labs feature-
ggplot(data = economics, aes(x = date, y = unemploy)) + geom_line()
+ labs(title = "Number of unemployed people in U.S.A. from 1967 to 2015",
x = "Year", y = "Number of unemployed people")
Let’s group the data according to year and view how average unemployment fluctuated through these years.
We will load dplyr package to manipulate our data and lubridate package to work with date column.
library(dplyr)
library(lubridate)
Now we will use mutate function to create a column year from the date column given in economics dataset by using the year function of lubridate package. And then we will group the data according to year and summarise it according to average unemployment-
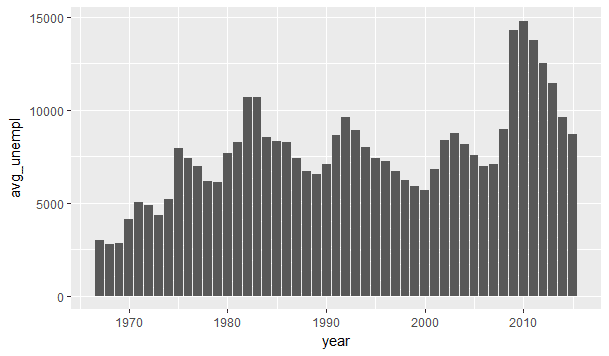
Now, lets view the data as a line plot using line geom of ggplot2
ggplot(data = economics_update, aes(x = year , y = avg_unempl)) + geom_bar(stat = “identity”)
(Since here we want the height of the bar be equal to avg_unempl, so we need to specify stat equal to identity)
This graph shows the average unemployment in each year
Plotting Time Series Data
In this section, I’ll be using a dataset that records the number of tourists who visited India from 2001 to 2015 which I have rearranged such that it has 3 columns, country, year and number of tourists arrived.
To visualize the plot of the number of tourists that visited the countries over the years in the form of line graph, we use geom_line-
Unfortunately, we get this graph which looks weird because we have plotted all the countries data together.
So, we group the graph by country by specifying it in aesthetics-
ggplot(data = tourist1, aes(x = year, y = number_tourist, group = Country)) + geom_line()
This graph is showing the country wise line graph which shows the trend of a number of tourists arrived from these countries over the years.
To better view the graph that distinguishes countries and is bigger in size, we can specify color and size-
ggplot(data = tourist1, aes(x = year, y = number_tourist, group = Country,
color = Country)) + geom_line(size = 1)
Faceting
Faceting is a feature in ggplot which enables us to split one plot into multiple plots based on some factor. We can use it to visualize one-time series for each factor separately-
ggplot(data = tourist1, aes(x = year, y = number_tourist, group =
Country, color = Country)) + geom_line(size = 1) + facet_wrap(~Country)
For convenience purpose, you can change the theme of the background as well, here I am keeping the theme as white-
ggplot(data = tourist1, aes(x = year, y = number_tourist,
group = Country, color = Country)) + geom_line(size = 1) +
facet_wrap(~Country) + theme_bw()
These were some basic functions of ggplot2, for more functions, check out the official guide.
2. Plotly
Plotly is deemed to be one of the best data visualization tools in the industry.
Line graph
Lets construct a simple line graph of two vectors by using plot_ly function that initiates a visualization in plotly. Since we are creating a line graph, we have to specify type as ‘scatter’ and mode as ‘lines’.
plot_ly(x = c(1,2,3), y = c(10,20,30), type = "scatter", mode = "lines")
Now let’s create a line graph using the economics dataset that we used earlier-
plot_ly(x = economics$date, y = economics$unemploy, type = "scatter", mode = "lines")
Now, we’ll use the dataset ‘women’ that is available in R which records the average height and weight of American women.
Scatter Plot
Now lets create a scatter plot for which we need to specify mode as ‘markers’ –
plot_ly(x = women$height, y = women$weight, type = "scatter", mode = "markers")
Bar Chart
Now, to create a bar chart, we need to specify the type as ‘bar’.
plot_ly(x = women$height, y = women$weight, type = "bar")
Histogram
To create a histogram in plotly, we need to specify the type as ‘histogram’ in plot_ly.
1. Normal distribution
Let x follow a normal distribution with n=200
X < -rnorm(200)
We then plot this normal distribution in histogram,
plot_ly(x = x, type = "histogram")
Since its a normally distributed data, so the shape of this histogram is bell-shaped.
2. Chi-Square Distribution
Let y follow a chi square distribution with n = 200 and df = 4,
y = rchisq(200, 4)
Then, we construct a histogram of y-
plot_ly(x = y, type = "histogram")
This histogram represents a chi square distribution, so it is positively skewed
Boxplot
We will build a boxplot of a normally distributed data, fr that we need to specify the type as ‘box’.
plot_ly(x = rnorm(200, 0, 1), type = "box")
here x follows a normal distribution with mean 0 and sd 1,
So in this box plot, the median is at 0 as in normal distribution, median is equal to mean.
Adding Traces
We can add multiple traces to the plot using pipelines and add_trace feature-
plot_ly(x = iris$Sepal.Length, y = iris$Sepal.Width,
type = "scatter", mode = "markers")%>%
add_trace(x = iris$Petal.Length, y = iris$Petal.Width)
Now let’s construct two boxplots from two normally distributed datasets, one with mean 0 and other with mean 1-
Now, let’s modify the size and color of the plot, since the mode is a marker, so we would specify the marker as a list with the modifications that we require.
plot_ly(x = women$height, y = women$weight, type = "scatter",
mode = "markers", marker = list(size = 10, color = "red"))
We can modify points individually as well if we know the number of points in the graph-
We can modify the plot using the layout function as well which allows us to customize the x-axis and y-axis. We can specify the modifications in the form of a list-
plot_ly(x = women$height, y = women$weight, type = "scatter", mode = "markers",
marker = list(size = 10, color = "red"))%>%
layout(title = "scatter plot", xaxis = list(showline = T, title = "Height"),
yaxis = list(showline = T, title = "Weight"))
Here, we have given a title to the graph and the x-axis and y-axis as well. Also, we have the X-axis line and Y-axis line
Let’s say we want to distinguish the points in the plot according to a factor-
plot_ly(x = iris$Sepal.Length, y = iris$Sepal.Width, type = "scatter",
color = ~iris$Species, colors = "Set1")
here, if we don’t specify the mode, it will set the mode to ‘markers’ by default
Mapping Data to Symbols
We can map the data into differentiated symbols so that we can view the graph better for different factors-
plot_ly(x = iris$Sepal.Length, y = iris$Sepal.Width, type = "scatter",
mode = “markers”, symbol = ~iris$Species)
here, the points pertaining to 3 factors are distinguished by symbols that R assigned to it.
We can customize the symbols as well-
plot_ly(x = iris$Sepal.Length, y = iris$Sepal.Width, type = "scatter",
mode = “makers”, symbol = ~iris$Species, symbols = c("circle", "x", "o"))
3D Line Plot
We can construct a 3D plot as well by specifying it in type. Here we are constructing a 3D line plot-
plot_ly(x = c(1,2,3), y = c(2,4,6), z = c(3,6,9), type = "scatter3d",
mode = "lines")
Map Visualization
We can visualize map as well by specifying in type as ‘scattergeo’. Since its a map, so we need to specify lattitude and longitude.
plot_ly(lon = c(40, 50), lat = c(10, 20), type = "scattergeo", mode = "markers")
We can modify the map as well. Here we have increased the size of the points and changed its color. We have also added text that is the location of the point which would show the location name when the cursor is placed on it.
plot_ly(lon = c(-95, 80), lat = c(30, 20), type = "scattergeo",
mode = "markers", size = 10, color = "Set2", text = c("U.S.A.", "India"))
These were some of the visualizations from package ggplot2 and plotly. R has various other packages for visualizations like graphics and lattice. Refer to the official documentation of R to know more about these packages.
To know more about our Data Science course, click below
All the best dataset, Artificial Intelligence, Machine Learning, and Business Intelligence tools are useless without effective visualization capabilities. In the end, data science is all about presentation, Whether you are a chief data scientist at Google or an all-in-one ‘many-hats’ data scientist at a start-up, you still have to show the results of your algorithm to a management executive for approval. We have all heard the adage, “a picture is worth a thousand words”. I would rephrase that for data science as “An effective infographic is worth an infinite amount of data”. Because even if you present the most amazing algorithms and statistics in the universe to your management, they will be unable to comprehend it. But present even a simple infographic – and everyone in the boardroom, from the CEO to your personnel manager, will be able to understand what your findings mean for your business enterprise.
Tools for Visualization
Because of the fundamental truth stated above, there are a ton of data visualization tools out there for the needs of every data scientist on the planet. There is a wide variety available. From premium and power-user based, to products from giants like Microsoft and Google, to free offerings for developers like Plot.ly across multiple languages and bokeh for Python developers, to DataWrapper for non-technical users. So I have picked five tools that vary widely but are all very effective and worth learning in depth. So let’s get started!
Tableau Sample Email Marketing ReportTableau is the market leader for visualization as far as data science is concerned. The statistics speak for themselves. Over 32,000 companies use Tableau around the world and this tool is by far the most popular choice among top companies like Facebook and Amazon. What is more, once you learn Tableau, you will know visualization well enough to handle every other tool in the market. This tool is the most popular, the most powerful, and yet surprisingly intuitive to use. If you wanted to learn one single tool for data science, this is It.
Qlikview is another solution like Tableau that requires payment for a commercial user, yet it is so powerful that I couldn’t help but include it in my article. This tool is situated more for the power-user and the well-experienced data scientists. While not as intuitive as Tableau, this tool boasts of powerful features that can be used by large-scale users. This is a very powerful choice for many companies all over the world.
Unlike the first two tools, Microsoft Power BI (Business Intelligence) is completely free to use and download. It integrates beautifully with Microsoft tools. If you’re on Microsoft Azure as a cloud computing solution, you will enjoy this tool’s seamless integration with Microsoft products. Contrary to popular business ethos at Microsoft, this tool is both free to download (full-featured) and free to use, even the Desktop version. If you use Microsoft tools, then this could be a solution that fits you well. (Although Tableau is the tool used the most by software companies).
This tool is strictly cloud-based and its highest USP is that it tightly integrates with the Google Internet Website Ecosystem. In fact, it is better that the solution be cloud-based and not on your desktop since a copy on your desktop would have to be continually resynchronized, whereas a cloud solution manages all requirements as required with the latest Internet datasets, refreshed every time you load the page. Nearly every single tool you need is at your fingertips, and this is one way to learn the Google-based way to manage your website or company. And did I mention – like Microsoft Power BI, it is completely free of cost! But again, Tableau is still the preferred solution for mainstream software companies.
This is by far the most user-friendly visualization tool for data science available on the Internet today. And while I was skeptical, this tool can be used by completely non-technical users. And the version I used was free up to to a massive 10,000 chart views. So if you want to create a visualization and don’t have technical skills in coding or Python, this may be your best way to get started. In case you’re feeling skeptical (as I was), visit the website above and view the instructions video (100 seconds – less than 2 minutes). If you are a beginner to data visualization, this is where to go first.
This is an article on visualization and communicating concepts and analysis through graphics, so it would not be complete without this free gallery of samples at www.informationisbeautiful.net. What do we plan to communicate but information? Information is processed data. Data scientists deal with data but produce as output information. This website has opened my eyes as to how data can be presented effectively. While this is not something you would use for an industrial report, do visit the site for inspiration for ways to make your data visualization more good-looking. If you have business transformational data, it requires the best presentation available. This is a post for five data visualization tools, but consider this sixth one as a bonus for inspiration and all the times you wished your dashboard or charts could be more effective graphically.
Conclusion
While there is a ton of information out there, choose tools that cater to your domain. If you are a large scale enterprise, Tableau could be your best option. If you are a student or want a high-quality free solution, go for DataWrapper. QlikView can be used by companies who want to save on their budget and have plenty of experienced professionals (although this is also a use-case for Tableau). For convenient tools, you can’t go wrong with Microsoft Power BI if your company uses Microsoft ecosystem and Google Data Studio is you are integrated into the Google ecosystem instead. Finally, if you are a student of data visualization or just want to improve your data presentation, please visit informationisbeautiful.net. Trust me, it will be an eye-opener.
Finally, Tableau is what you need to learn to be a true data science professional, especially in FAMGA (Facebook, Apple, Microsoft, Google, and Amazon).
Also, remember to enjoy your work. This adds a fun element to your current job and ensures against burnout and other such problems. This is, in the end, artistry. Even if you are into coding. All the best!
For more on Data Visualization, I strongly recommend the articles below:


























 This histogram represents a chi square distribution, so it is positively skewed
This histogram represents a chi square distribution, so it is positively skewed So in this box plot, the median is at 0 as in normal distribution, median is equal to mean.
So in this box plot, the median is at 0 as in normal distribution, median is equal to mean.
















