Predictive analysis is heavily used today to gain insights on a level that are not possible to detect with human eyes. And R is an extremely powerful and easy tool to implement the same. In this piece, we will explore how we can predict the status of breast cancer using predictive modeling in less than 30 lines of code.
Who should read this blog?
Someone who wants to get started with R programming.
You are gonna write your program in the top left box.
What are We About to Do?
Place the downloaded file in a folder. You can name it anything. If you open the CSV file downloaded from Kaggle, it looks something like this –
A lot of numbers, right? Those numbers are the features. Features are the attributes of a data point. For example, if a house is a data point, its features could be the carpet is, number of rooms, number of floors, etc. Basically, features describe the data. In our case, the features are a description of the affected breast area. The highlighted column, labeled ‘diagnosis’ is the status of the disease – M for Malignant (dangerous) and B for Benign (not dangerous). This is the variable we wish to predict. It is also called the predicted variable. So we have the features and the predicted variable in our excel sheet. Our task is to train a model that can learn from these labeled (whose diagnosis status is given) points and then can predict for a new data point for which we know the features but not the predicted variable (in this case the ‘diagnosis status’) value.
What Exactly is the Model We Use?
To start with, we use the simplest of all
KNN: K-Nearest Neighbours
“You are the average of 5 people you surround yourself with”-John Rim
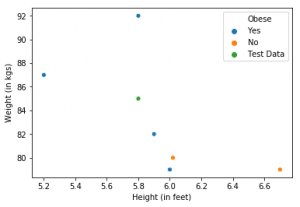
Consider a prediction problem. Let’s set K, which is the number of closest neighbours to be considered equal to 3. We have 6 seen data points whose features are height and weight of individuals and predicted variable is whether or not they are obese.
Consider a point from the unseen data (in green). Our algorithm has to predict whether the person represented by the green data point is obese or not. If we consider it’s K(=3) nearest neighbours, we have 2 obese (blue) and one not obese (orange) data points. We take the majority vote of these 3 neighbours which is ‘Yes’. Hence, we predict this individual to be obese.
Easy, right?
The Code
In the console (bottom left box on the RStudio, we first set our working directory. Type in setwd(“//path”) … where the path is the route to your folder. Something like “C:\Users\DHRUVIL\Desktop\R”. Change the \ to / and press enter.
Since KNN is a distance-based algorithm, it is a good idea to scale all our numeric features. That way a few features won’t dominate in the distance calculations. We first create a function and then apply that function to all our features (column 2 to 31).
To implement KNN, we need to install a package called class. In your console, type the following:
install.packages(“class”)
library(“class”)
To check the performance of the model, our data is divided into training and test set. We train the model on the training set and validate the test set.
wbcd_train<-wbcd_n[1:469,]
dim(wbcd_train)
wbcd_test<-wbcd_n[470:569, ]
im(wbcd_test)
wbcd_train_label <- wbcd[1:469,1]
wbcd_test_label <- wbcd[470:569,1]
As you can see, 469 points are used in the training set and the rest in the test set.
Here, the model is trained on the wbcd_train and wbcd_train_label and predictions are generated on wbcd_test. The number of neighbors or K is set to 21. The performance of the model is evaluated then.
The results are tabulated above. As we can see, out of 77 actual Benign, 0 were misclassified as Malignant. For the 23 actual Malignant, 2 were misclassified as Benign. You can tweak the value of K and check if the results are getting better.
Congratulations on building your first model!
Summary
R is a programming language originally written for statisticians to do statistical analysis, including predictive analytics. It’s open-source software, used extensively in academia to teach such disciplines as statistics, bio-informatics, and economics.
Follow this link, if you are looking to learn more about data science online!
Almost every sector today is embracing technology. One of the ways in which technology is enabling a better quality of services by automating time-consuming yet straightforward tasks, thereby allowing humans to focus on more important and complex matters. In the following article, we look at how this philosophy applies to the real estate sector. In particular, how real estate is benefitting from the massive advances in AI.
Traditionally, when you want to buy a new property, say a house, you contact a real estate agent so that they can show you the best available houses according to your requirements and budget constraints.
In the pre-internet era, there used to be an information asymmetry. Meaning, most of the knowledge about a transaction resided with the middleman, in our case the agent. With the advent of the internet, this asymmetry started breaking. Anyone, in any part of the world, was able to access the details about the prices of real estate in a particular location. However, this wasn’t enough. There was a ton of information available, which in turn led to users browsing through websites, but unable to decide on an option. This is where AI takes this process a step ahead. One of the key advantages of using AI is getting personalized recommendations. Recommender systems, a popular AI application is used to filter out a few of the thousands of possible options.
As a result, you save time, energy as well as get an idea of how would your dream property look like and what price would you pay for it.
Skyline, An Israeli company, founded just last year, but with offices in one of the world’s most expensive real estate markets, New York, Skyline AI just raised a $3 million Seed round in March from top VC firm Sequoia Capital. The startup claims its platform can tell real estate investors what properties offer the best return by ingesting tons of data from more than 130 sources, taking into account over 10,000 different attributes on every property, going back as much as 50 years on every multi-family property in the United States.
If you are into Machine Learning competitions, you must have heard or even participated in the House Price Prediction Challenge. A popular competition, here the participants have to train a model that can predict the prices of the house based on many parameters relating to the locality, house size, house age and many more. Famous as a competition, this idea has a lot of business value in it. Pricing is perhaps the most critical deal breaker/maker in the real estate business. Methods like Machine Learning, Time-Series forecasting, can be used to evaluate the price of property not only today but also in the future.
London-based Proportunity, which raised $1.7 million last year, might be an even more attractive acquisition for a company like Zillow in the future. Founded in 2016 by a pair of Romanian entrepreneurs, Proportunity claims its machine learning algorithms can accurately forecast which homes, and even neighborhoods will experience the most significant bump in value over a specified period.
Computer Vision, a broad field in AI that deals with extracting information from images has one promising application in the real estate sector. The structural properties, which include any damages can be monitored using Machine Learning techniques. Just a few images of the structure can give you quick results as to how healthy your future house is.
In India, startups like Housing.com have reinvented the way people in India hunt for rentals and buys or sells properties. The startup used infused technology and innovation into the business with its verified listings, availability of maps and location descriptions, search widgets, high-quality pictures, refined search through filters and much more. More startups like 99 acres and commonfloor are on a similar mission to simplify real estate.
If you wish to learn about more AI trends, do give the below article a read-
You have finally trained your first Machine Learning model. Congratulations! What’s next though? How would you unleash the power of your model outside of your laptop? In this tutorial, we help you take the first step towards deploying models. We will use flask to create apps and flasgger to create a beautiful UI.
Github repository for this tutorial – https://github.com/DhruvilKarani/MLapp_using_flask_and_flasgger
You can install libraries using Anaconda Prompt (use the search option on windows) by typing –pip install <name of the library>. For flasgger, use pip install flasgger==0.8.1
Of course, don’t include the <>
Building an ML model
Before we deploy any model, let’s first build one. For now, let’s build a simple model on a simple dataset so that we can spend more time on the deployment part. We use the Iris dataset from sklearn’s datasets. The required imports are given below.
The Iris dataset looks something like this –
Image Credits: Analyticskhoj
The variable to be predicted, i.e., Species, has three categories – Sentosa, Virginica, Versicolour. Now, we build our model in just 6 lines of code
The model we build is saved as a pickle file. A pickle file saves any file into its binary form. Next time we want to use this model, we don’t have to train it again. We can merely load this pickle file.
The above command saves the model as a pickle file under the name model_pkl in the path specified (in this case – C:/Users….model.pkl). Also, make sure you have / and not \. You might also want to check once if the file is present in the folder. Once you have made sure the file exists, the next step is to use flask and flasgger to make a fantastic UI. Make a new Python script and import the following modules and read the pickle file.
Next, we create a Flask object and name it app. The argument to this Flask object is the special keyword __name__. To create an easy UI for this app, we use the Swagger module in the Flasgger library.
Now, we create two apps – One which accepts individual values for all 4 input values and the other which accepts a CSV file as inputs. Let’s create the first app
The first line @app.route(‘/predict’) specifies the part of the URL which runs this particular app. If you do not understand this as of now, don’t worry. Things get more evident as we use the app. The next thing we do is create a function, named predict_iris. Under this function, we have a long docstring. Swagger uses this string for creating a UI. It says that the app requires 4 parameters namely S_length, S_width, P_length, P_width. All of these input values are of the query type. Next, the app uses the GET method to accept these values which means that we need to enter the numbers by ourselves. Then we pass these values to our model in a 2 D numpy array and return the predictions. Two things here –
Predictions[0] returns the element in the prediction numpy array
We always output a string, never a numeric value to avoid errors.
Now we build the second app, the one that accepts a file. However, before the app, we create a file that has all four variable values for which we predict the output. In the Python console, type the following
Select any 2-4 rows at random, copy them and save them in a CSV file. We use this file to test our second app. The file would look something like this
Notice the changes here. The @app.route decorator has ‘/predict_file’ as one of its argument. The docstring under our new function predict_iris_file tells Swagger to set the file as an input file. Next, we read the CSV using read_csv and make sure the header is set to None if you haven’t set the column names while making the CSV. Next, we use the model to make the predictions and return them as a string.
Finally, we run the app using
In the console, the output generates a local URL, something like this –
Copy the URL (the one highlighted) and paste it in your browser. Add /apidocs to it and hit Enter. For example http://127.0.0.1:5000/apidocs. Something like this opens up –
Click on default and then on /predict. You’ll find something like this –
Above is a UI for your first app. Go ahead, insert the four values and click on ‘Try it out!’. Under the response body, you find the predicted class. For our second app, upload the file by clicking on choose file.
When you try it out, you get a string of predicted classes.
Congratulations! You have just created a nice UI for your ML model. Feel free to play around and try out new things.
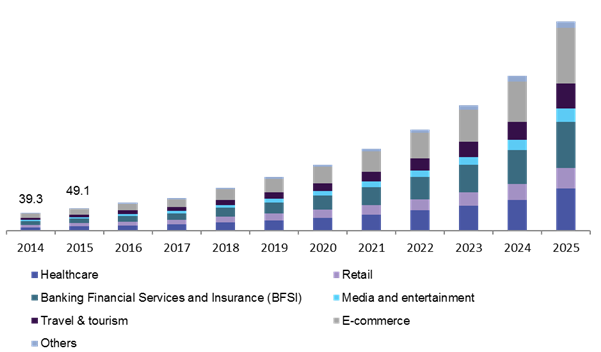
Chatbots are the hot thing right now. Many surveys claim that XX% of companies plan to deploy a chatbot in Y years. Consider the infographic below that describes the chatbot market value in the US in a million dollars
Image Credits: Grandview Research
However, where did it all start? Where are we now? In this article, we try to answer these questions.
ELIZA
Joseph Weizenbaum, a German professor of Computer Science at the Massachuset Institute of Technology, developed a program called ELIZA in 1966. It aimed at tricking users by making them believe that they were having a conversation with a human. ELIZA is considered to be the first chatbot in the field of Computer Science.
However, how does this work? The processing loop of ELIZA takes in the user input and breaks it into sentences and scans each sentence for the keyword or phrase. It then applies synonym list to match equivalent words. For each key, it looks for a pattern. In case the input does not match with any of its stored patterns, it returns some generic response like “Can you elaborate?”
Image Credit: Infermedica.com
As you can see, it does not understand your input for its next response. However, let’s not be too hard on 1966.
ALICE
ALICE (Artificial Linguistic Internet Computer Entity) developed by Wallace in 1995. A key thing about ALICE is that it relies on many simple categories and rule matching to process the input. ALICE goes for size over sophistication: it makes up for lack of morphological, syntactic, and semantic NLP modules by having a massive number of simple rules.
Image credits: Scielo.org
ALICE stores knowledge about English conversation patterns in AIML files. AIML, or Artificial Intelligence Mark-up Language, is a derivative of Extensible Mark-up Language (XML). It was developed by the Alicebot free software community during 1995-2000 to enable people to input dialogue pattern knowledge into chatbots based on the ALICE free software technology. AIML consists of data objects called AIML objects, which are made up of units called topics and categories. A topic is an optional top-level element; it has a name attribute and a set of categories related to that topic. Categories are the basic unit of knowledge in AIML. Each category is a rule for matching input and converting it to an output and consists of a pattern, which represents the user input, and a template, which implies the ALICE robot answer.
As you can see, it works pretty well. However, it’s not good enough. Natural Language is complex and evolving. Relying on a rule-based chatbot is not a long term way to go.
Neural Conversational Bots
Deep Learning is today’s buzz word. Moreover, it’s there for a reason. The level of complexity these algorithms can learn once fed with vast amounts of data and sufficient computational capacity is just astounding. Models like Convolutional Neural Nets have proven their ability in image processing. In Natural Language Processing, models like Recurrent Neural Networks (RNN) or their advanced variants like Long Short Term Memory (LSTM) or Gated Recurrent Units (GRU) have now enabled us to take a step further towards actual Natural Language Understanding. Since this is the state of the art model, let’s very intuitively understand what’s happening.
Like any Machine Learning algorithm, Neural Nets learn from examples. Meaning, to predict the outcome for an unknown instance (say the price of a house), you need to train the model. How do you do that? Feed it already existing instances ( say information about houses whose price is already known) whose predictions you already know. The model will learn from the fed data and will be able to predict for a new instance, who’s predicted value isn’t known. Now RNN, a modification of Neural Networks is specially built to process sequential data, i.e., where the order matters. Like sentences. Here the order of the words matter.
Image Credit: Wildml.com
Consider the example of language translation above. The RNN aims to translate German into English. On the left, we feed the German sentence, word by word. The RNN process a word (say Echt) and passes on some information about it to the next step where the next word (in this case dicke). Finally, all the information about the sentence is Encoded in a vector. This vector is then Decoded in a Decoder. Thus the decoder returns the translated sentence in English. What I have given is a very high-level idea of RNNs.
You might ask – Have we cracked the code to the perfect chatbot? No. However, researchers firmly believe that deep learning is the way to go unless something disruptive emerges in the future. One good thing about it is that it does an end to end task. Meaning, we don’t have to define rules. We need to feed it with high-quality data.
However, let’s not get misled by the hype. Even today, chatbots make many mistakes. Look at the example below.
Image Credit: business.com
Many times you might have noticed that even the most advanced bots like Alexa or Cortana fail to respond correctly. Quite often their best response to a question is a link which opens in a browser. The point being if a business needs a chatbot, they should clearly define the problem they wish to solve with it.
For example, a chatbot can save time and energy of customer helpline executives by automating simple queries and thus allowing them to focus on issues that require human assistance.
Another example could be how easily customers can look for a particular piece of information instead of navigating through nested web pages.
In conclusion, chatbots have been in the picture for quite long, and they are very promising. However, we are yet to reach a point where they converse like you and me.
2018 has been where AI and analytics surprised everyone. A large amount of time spent on research and experimentation has given us a clearer picture of what AI can do. But in 2019, organizations and professionals are going to invest in how these innovations can be used for real-life value-creating applications. In this article, we discuss AI and Analytics trends in three areas
Data Safety
Explanable AI
Industry applications
Data Safety
It is clear that companies are realizing how valuable data can be and how it can drastically change the decision-making process, for better. This led companies to collect more and more data about consumers. Fun fact – Facebook even keeps track of where your mouse pointer moves on the screen. Fine movements of ours are being recorded and processed to make our experience better. But it’s not so easy for these companies.
Consider the Equifax data breach that happened not too long back. For those of you who do not know, Equifax is a credit reporting company. In our case, this means that it holds very sensitive information about citizens. More than 800 million of them. In the data breach, over personal data of 143 million Americans were compromised. Some of the information over which hackers were able to gain access to included name, address, and even social security number. The company’s security department said it “was aware of this vulnerability at that time, and took efforts to identify and to patch any vulnerable systems.” Equifax admitted it was aware of the security flaw a full two months before the company says hackers first gained access to its data.
There are many such examples of data breaches. Consequently, people are becoming more and more aware of their digital footprints. Government and lawmakers are realizing that data is no more just bunch of files on a computer. It has the potential to do good and to do the worst. This leads to the question – How safe are we digitally? What measures are being taken by the companies to safeguard our privacy?
Analytics is seen as a potential way to tackle this problem. Tools like user analytics try to understand steps a hacker takes when he crawls through the security walls of any company. It tries to understand if any user activity is different from the usual. For example a sudden spike in money withdrawal from a particular bank account. Deep Learning, arguably the most advanced form of analytics available to use is used on similar lines. Like user analytics, it focuses on anomalous behavior. The advantage is that it does it at a very micro level and is faster at detecting any such hazard, which is very important to take preventive measures.
Explanable AI
Today we hear about deep learning as if it is Harry Potter’s, Elder Wand. Deep Learning has given some surprising results. Consider the following painting created by AI, which got sold for $432k at an auction.
Image Source: Christie’s website
In case you are wondering what kind of signature is at the bottom right, it is the objective function of the GAN (Generative Adversarial Network) that produced this art. Now we know why Math is often called ‘Art’.
But as awesome it may seem, deep learning is still considered as a black box method. Meaning, we are not perfectly clear on what’s going under the hood. Consider the use of Deep Learning in Cancer Detection. The algorithm, out of 100 cancer positives, might detect 90 of them. But wrongly predicting even 10% is fatal. Moreover, we don’t know why did the algorithm make those 10 errors. This puts a limitation on deep learning. In addition, company executives cannot trust major decisions of a company with some algorithm that might be accurate, but can’t explain why. This is where explanable AI comes into the picture. So that we can go from ‘may be’, ‘should be’ and ‘can be’ to ‘is’ or ‘isn’t’. Explanable AI is an active research area.
Industry Trends
It’s a cliche to say AI will transform every possible industry on the earth. So let’s skip to the part where we specifically talk about a few selected industries and the ways.
Logistic Industry
In this nation of 1.25 B, where people are increasingly going online to shop, logistic is something every e-commerce focuses on the most. By forecasting demand and analyzing shopping patterns, companies can optimize their logistics. Thanks to real-time GPS data, weather data, road maintenance data and fleet and personnel schedules integrated into a system looking at historical trends, the most optimised routes and time are selected for delivery. Warehouse automation is something that has reduced the mundane repetitive work and has made processes faster and seamless.
Education
Personalization or the ability of the algorithms to go to the micro level details and offer the best recommendation could be very well used in education. When you and I studied, we probably sat in a classroom where we had 50 classmates who. Now some of us understood what was being taught and some of us didn’t. It was impossible to teach each one of us in a way we could understand. Because there wasn’t any unique way. AI can open doors to this kind of personalization and enhance our learning experience with multiple folds.
Disaster Management
We all know how dreadful disasters are. Life and property get destroyed in seconds when n earthquake or Tsunami strikes. In other cases like famine, a farmer’s livelihood gets disturbed. What if analytics can be used to predict the next earthquake or predict what crop would get the best yield? Startups like Cropin technologies provide smart solutions to farmers.
In 2015, researchers at the Vrije University Institute for Environmental Studies in Amsterdam published a research paper exploring how analyzing Twitter activity can help to detect flood events. The researchers found that by combining data from disaster response organizations, the Global Flood Detection System (GFDS) satellite flood signal, and flood-related Twitter activity, disaster relief organizations can “gain a quicker understanding of the location, the timing, as well as the causes and impacts of floods.”
If you liked this article and are trying to make your mark in this industry, do check out the following article –