Data wrangling, in simpler terms, it is the process of transforming raw data into another format to make it more suitable for analytics. It may involve structuring and cleaning the data to make it more usable. For eg: Filtering the data by a particular year, replacing null values with mean and merging two or more columns. These were just a few examples of data wrangling. As a data scientist, you would have to probably spend most of the time in data wrangling.
Source: forbes
Importance of Data Wrangling
1. Improve the Quality – Many a time; the data is untidy and incomplete such as missing values, noisy values. So by cleaning the data, we improve its quality to improve accuracy.
2. Makes Data Presentable – Sometimes, the data is in a different format than needed for which we may want to change its format and schemas.
3. Scaling Down the Data – The data available might be too huge in size for which we would have to reduce its size. Also, we may want to analyze specific things about specific variables for which we need to use data wrangling.
4. Finding Outliers – Sometimes, the data may contain outliers or errors that may need to be removed or replaced. Also, in some cases the data might be biased which can lead to sampling error, for example, interpreting the global opinion about the most unsafe countries; the participants might be from a particular country, or the questions might be too value or biased.
Data Wrangling with R
In this article, I have demonstrated some examples in R to make the data clean and tidy using the packages tidyr, dplyr and stringr.
This is the tourist data file which shows the number of tourists that visited India in particular years from various countries-
Notice the variable Country is in rows and the variable year is in column. This means the dataset is untidy. So, we need to bring the years in rows and countries in columns.
For this purpose, we will use the package tidyr, install and the load the package with these commands-
install.packages(“tidyr”)
library(tidyr)
Now let’s understand what Gather function is. Gather takes multiple columns and collapses into key—value pairs, duplicating all other columns as needed. We use gather function when the columns are not variables. Here the year are mentioned in the column and we want to bring it I rows. So, first we will use gather function to bring all columns in rows-
Here, we have specified the dataset and the columns (that is from X2001 To X2015). Notice in the dataset tourist_datafile, there are 19 rows and in new dataset tourist1, there are 285 rows. Basically, in old data, those 19 rows represent 19 countries, and now we have gathered the years (15 years from 2001 to 2015) mentioned in columns into rows, so all those years and the value corresponding to year and country have collapsed in the form of key value pairs. So we have 15 multiplied by 19 rows that makes it 285 rows.
So now we want to pull the countries into the columns. For that we would use Spread function which spread a key value pair into multiple columns.
tourist3 <- spread(tourist2, key = "Country", value = "number_tourists")
Notice, here we have mentioned key as ‘Country’ as we want to spread Country.
view(tourist3)
The countries that represent the variable are now in columns and the years in rows.
Modify Patterns of a String
Notice in the year column, there is X before every year such as X2001.
So we will be cleaning the year column by removing the X from it using str_replace which is used to replace patterns in a string because the class of year column is string. It is in ‘stringr’ package, so first we will install and load this package.
date <- read.csv("C:\\Users\\hp\\Desktop\\Dimensionless\\date.csv")
view(date)
Suppose we want to separate the date column into day, month and year; we could do use separate function for that-
separate(date, col = V1, into = c("Day","Month","Year"), sep = "/")
Here, the first argument is the dataset, and then in ‘col’, we specify the column that we want to separate. In ‘into’ we specify the names of the columns that we want, here since we want 3 columns, I have passed a vector of 3 values in it. ‘sep’ is used to specify the separator in the column.
date_seperate <- separate(date, col = V1, into =
c("Day","Month","Year"), sep = "/")
Let’s view the data-
view(date_seperate)
So the column V1 has been separated into 3 columns.
Uniting the Columns
Similarly, we can unite multiple columns into one-
Here, the first argument is the dataset; in ‘col’ , we specify the name of the new column, then, we specify the columns that we want to unite. If we don’t specify the columns, it would unite all columns. And then we specified the separator using ‘sep’. Rather than specifying the columns as a vector, we can also pass it as variables.
unite(date_seperate, col = "Date", Day, Month, Year, sep = "-")
So, now let’s view the dataset-
view(data_unite)
Convert to Date Type
If we check the class of the date column, it is character.
So, we’ll convert the column to Date type and set the format accordingly-
date_unite$Date <- as.Date(date_unite$Date, format = "%d-%m-%Y")
class(date_unite$Date)
Notice the last 6 rows and 4 columns in the data, they all are null.
The dimensions of the data are 18*16
dim(household_data)
So we can remove them by sub-setting the data.
household_data <- household_data[1:15,1:10]
Notice after removal of the last few rows and columns, there are null values still remaining in the data in the columns pernum and sex; and in 8th row in column sex, there is a value called NULL which depicts that it is a null value but R would treat it as any other value.
household_data[8,6]
It is treating NULL as a level along with female and male.
So, we need to change this value such that R depicts is as a null value.
household_data[household_data == "NULL"] <- NA
It will change all the values that are written as NULL to NA
view(household_data)
Notice that the 8th row and the 6th column has been changed to NA
Replace NA with a Value
We can replace the missing value to make better analyses of the data.
Let’s replace the NAs in pernum column to the mean of the data, since NA are present, so we have to specify na.rm as TRUE,
mean(household_data[,4], na.rm = TRUE)
Since in this data, all columns are not numeric, so we cannot change all values that are NULL to their mean as it will throw error. So, here I have specifically changed the column 4’s NA values to its mean.
Visualizing the data is important as it makes it easier to understand large amount of complex data using charts and graphs than studying documents and reports. It helps the decision makers to grasp difficult concepts, identify new patterns and get a daily or intra-daily view of their performance. Due to the benefits it possess, and the rapid growth in analytics industry, businesses are increasingly using data visualizations; which can be assessed from the prediction that the data visualization market is expected to grow annually by 9.47% to $7.76 billion by 2023 from $4.51 billion in 2017.
R is a programming language and a software environment for statistical computing and graphics. It offers inbuilt functions and libraries to present data in the form of visualizations. It excels in both basic and advanced visualizations using minimum coding and produces high quality graphs on large datasets.
This article will demonstrate the use of its packages ggplot2 and plotly to create visualizations such as scatter plot, boxplot, histogram, line graphs, 3D plots and Maps.
1. ggplot2
#install package ggplot2
install.packages("ggplot2")
#load the package
library(ggplot2)
There are a lot of datasets available in R in package ‘datasets’, you can run the command data() to list those datasets and use any dataset to work upon. Here I have used the dataset named ‘economics’ which gives the monthly U.S. data of various economic variables like unemployment for the time period 1967-2015.
You can view the data using view function-
view(economics)
Scatter Plot
We’ll make a simple scatter plot to view how unemployment has fluctuated over the years by using plot function-
plot(x = economics$date, y = economics$unemploy)
ggplot() is used to initialize the ggplot object which can be used to declare the input dataframe and set of plot aesthetics. We can add geom components to it that acts as its layer and are used to specify the plot’s features.
We would use its feature geom point which is used to create scatter plots.
ggplot(data = economics, aes(x = date , y = unemploy)) + geom_point()
Modifying Plots
We can modify the plot like its color, shape, size etc. using geom_point aesthetics.
ggplot(data = economics, aes(x = date , y = unemploy)) + geom_point(size = 3)
Lets view the graph by modifying its color-
ggplot(data = economics, aes(x = date , y = unemploy)) + geom_point(size = 3, color = "blue")
Boxplot
Boxplot is a method of graphically depicting groups of numerical data through their quartiles. a geom boxplot layer of ggplot is used to create boxplot of the data.
ggplot(data = economics, aes(x = date , y = unemploy)) + geom_boxplot()
When there is overplotting, one or more points are in the same place and we can’t tell by looking at the plot that how many points are there. In that case, we can use the jitter geom which adds a small amount of variation to the location of each point that is it slightly moves the point, which is used to spread out the points that would otherwise be overplotted.
ggplot(data = economics, aes(x = date , y = unemploy)) +
geom_jitter(alpha = 0.5, color = "red") + geom_boxplot(alpha = 0)
Line Graph
We can view the data in the form of a line graph as well using geom_line.
To change the names of the axis and to give a title to the graph, use labs feature-
ggplot(data = economics, aes(x = date, y = unemploy)) + geom_line()
+ labs(title = "Number of unemployed people in U.S.A. from 1967 to 2015",
x = "Year", y = "Number of unemployed people")
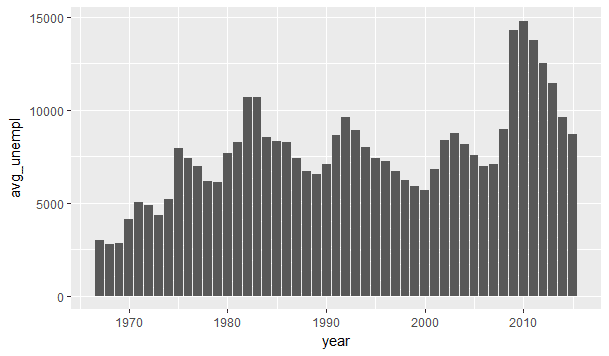
Let’s group the data according to year and view how average unemployment fluctuated through these years.
We will load dplyr package to manipulate our data and lubridate package to work with date column.
library(dplyr)
library(lubridate)
Now we will use mutate function to create a column year from the date column given in economics dataset by using the year function of lubridate package. And then we will group the data according to year and summarise it according to average unemployment-
Now, lets view the data as a line plot using line geom of ggplot2
ggplot(data = economics_update, aes(x = year , y = avg_unempl)) + geom_bar(stat = “identity”)
(Since here we want the height of the bar be equal to avg_unempl, so we need to specify stat equal to identity)
This graph shows the average unemployment in each year
Plotting Time Series Data
In this section, I’ll be using a dataset that records the number of tourists who visited India from 2001 to 2015 which I have rearranged such that it has 3 columns, country, year and number of tourists arrived.
To visualize the plot of the number of tourists that visited the countries over the years in the form of line graph, we use geom_line-
Unfortunately, we get this graph which looks weird because we have plotted all the countries data together.
So, we group the graph by country by specifying it in aesthetics-
ggplot(data = tourist1, aes(x = year, y = number_tourist, group = Country)) + geom_line()
This graph is showing the country wise line graph which shows the trend of a number of tourists arrived from these countries over the years.
To better view the graph that distinguishes countries and is bigger in size, we can specify color and size-
ggplot(data = tourist1, aes(x = year, y = number_tourist, group = Country,
color = Country)) + geom_line(size = 1)
Faceting
Faceting is a feature in ggplot which enables us to split one plot into multiple plots based on some factor. We can use it to visualize one-time series for each factor separately-
ggplot(data = tourist1, aes(x = year, y = number_tourist, group =
Country, color = Country)) + geom_line(size = 1) + facet_wrap(~Country)
For convenience purpose, you can change the theme of the background as well, here I am keeping the theme as white-
ggplot(data = tourist1, aes(x = year, y = number_tourist,
group = Country, color = Country)) + geom_line(size = 1) +
facet_wrap(~Country) + theme_bw()
These were some basic functions of ggplot2, for more functions, check out the official guide.
2. Plotly
Plotly is deemed to be one of the best data visualization tools in the industry.
Line graph
Lets construct a simple line graph of two vectors by using plot_ly function that initiates a visualization in plotly. Since we are creating a line graph, we have to specify type as ‘scatter’ and mode as ‘lines’.
plot_ly(x = c(1,2,3), y = c(10,20,30), type = "scatter", mode = "lines")
Now let’s create a line graph using the economics dataset that we used earlier-
plot_ly(x = economics$date, y = economics$unemploy, type = "scatter", mode = "lines")
Now, we’ll use the dataset ‘women’ that is available in R which records the average height and weight of American women.
Scatter Plot
Now lets create a scatter plot for which we need to specify mode as ‘markers’ –
plot_ly(x = women$height, y = women$weight, type = "scatter", mode = "markers")
Bar Chart
Now, to create a bar chart, we need to specify the type as ‘bar’.
plot_ly(x = women$height, y = women$weight, type = "bar")
Histogram
To create a histogram in plotly, we need to specify the type as ‘histogram’ in plot_ly.
1. Normal distribution
Let x follow a normal distribution with n=200
X < -rnorm(200)
We then plot this normal distribution in histogram,
plot_ly(x = x, type = "histogram")
Since its a normally distributed data, so the shape of this histogram is bell-shaped.
2. Chi-Square Distribution
Let y follow a chi square distribution with n = 200 and df = 4,
y = rchisq(200, 4)
Then, we construct a histogram of y-
plot_ly(x = y, type = "histogram")
This histogram represents a chi square distribution, so it is positively skewed
Boxplot
We will build a boxplot of a normally distributed data, fr that we need to specify the type as ‘box’.
plot_ly(x = rnorm(200, 0, 1), type = "box")
here x follows a normal distribution with mean 0 and sd 1,
So in this box plot, the median is at 0 as in normal distribution, median is equal to mean.
Adding Traces
We can add multiple traces to the plot using pipelines and add_trace feature-
plot_ly(x = iris$Sepal.Length, y = iris$Sepal.Width,
type = "scatter", mode = "markers")%>%
add_trace(x = iris$Petal.Length, y = iris$Petal.Width)
Now let’s construct two boxplots from two normally distributed datasets, one with mean 0 and other with mean 1-
Now, let’s modify the size and color of the plot, since the mode is a marker, so we would specify the marker as a list with the modifications that we require.
plot_ly(x = women$height, y = women$weight, type = "scatter",
mode = "markers", marker = list(size = 10, color = "red"))
We can modify points individually as well if we know the number of points in the graph-
We can modify the plot using the layout function as well which allows us to customize the x-axis and y-axis. We can specify the modifications in the form of a list-
plot_ly(x = women$height, y = women$weight, type = "scatter", mode = "markers",
marker = list(size = 10, color = "red"))%>%
layout(title = "scatter plot", xaxis = list(showline = T, title = "Height"),
yaxis = list(showline = T, title = "Weight"))
Here, we have given a title to the graph and the x-axis and y-axis as well. Also, we have the X-axis line and Y-axis line
Let’s say we want to distinguish the points in the plot according to a factor-
plot_ly(x = iris$Sepal.Length, y = iris$Sepal.Width, type = "scatter",
color = ~iris$Species, colors = "Set1")
here, if we don’t specify the mode, it will set the mode to ‘markers’ by default
Mapping Data to Symbols
We can map the data into differentiated symbols so that we can view the graph better for different factors-
plot_ly(x = iris$Sepal.Length, y = iris$Sepal.Width, type = "scatter",
mode = “markers”, symbol = ~iris$Species)
here, the points pertaining to 3 factors are distinguished by symbols that R assigned to it.
We can customize the symbols as well-
plot_ly(x = iris$Sepal.Length, y = iris$Sepal.Width, type = "scatter",
mode = “makers”, symbol = ~iris$Species, symbols = c("circle", "x", "o"))
3D Line Plot
We can construct a 3D plot as well by specifying it in type. Here we are constructing a 3D line plot-
plot_ly(x = c(1,2,3), y = c(2,4,6), z = c(3,6,9), type = "scatter3d",
mode = "lines")
Map Visualization
We can visualize map as well by specifying in type as ‘scattergeo’. Since its a map, so we need to specify lattitude and longitude.
plot_ly(lon = c(40, 50), lat = c(10, 20), type = "scattergeo", mode = "markers")
We can modify the map as well. Here we have increased the size of the points and changed its color. We have also added text that is the location of the point which would show the location name when the cursor is placed on it.
plot_ly(lon = c(-95, 80), lat = c(30, 20), type = "scattergeo",
mode = "markers", size = 10, color = "Set2", text = c("U.S.A.", "India"))
These were some of the visualizations from package ggplot2 and plotly. R has various other packages for visualizations like graphics and lattice. Refer to the official documentation of R to know more about these packages.
To know more about our Data Science course, click below
Hadoop is a software framework from Apache Software Foundation that is used to store and process Big Data. It has two main components; Hadoop Distributed File System (HDFS), its storage system and MapReduce, is its data processing framework. Hadoop has the capability to manage large datasets by distributing the dataset into smaller chunks across multiple machines and performing parallel computation on it .
Overview of HDFS
Hadoop is an essential component of the Big Data industry as it provides the most reliable storage layer, HDFS, which can scale massively. Companies like Yahoo and Facebook use HDFS to store their data.
HDFS has a master-slave architecture where the master node is called NameNode and slave node is called DataNode. The NameNode and its DataNodes form a cluster. NameNode acts like an instructor to DataNode while the DataNodes store the actual data.
source: Hasura
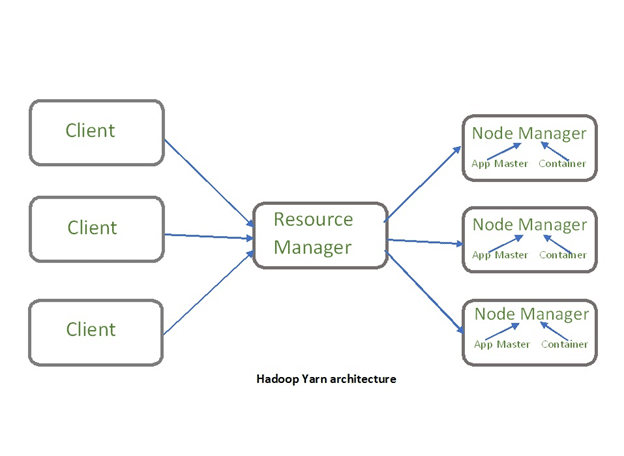
There is another component of Hadoop known as YARN. The idea of Yarn is to manage the resources and schedule/monitor jobs in Hadoop. Yarn has two main components, Resource Manager and Node Manager. The resource manager has the authority to allocate resources to various applications running in a cluster. The node manager is responsible for monitoring their resource usage (CPU, memory, disk) and reporting the same to the resource manager.
source: GeeksforGeeks
To understand the Hadoop architecture in detail, refer this blog
Advantages of Hadoop
1. Economical – Hadoop is an open source Apache product, so it is free software. It has hardware cost associated with it. It is cost effective as it uses commodity hardware that are cheap machines to store its datasets and not any specialized machine.
2. Scalable – Hadoop distributes large data sets across multiple machines of a cluster. New machines can be easily added to the nodes of a cluster and can scale to thousands of nodes storing thousands of terabytes of data.
3. Fault Tolerance – Hadoop, by default, stores 3 replicas of data across the nodes of a cluster. So if any node goes down, data can be retrieved from other nodes.
4. Fast – Since Hadoop processes distributed data parallelly, it can process large data sets much faster than the traditional systems. It is highly suitable for batch processing of data.
5. Flexibility – Hadoop can store structured, semi-structured as well as unstructured data. It can accept data in the form of textfile, images, CSV files, XML files, emails, etc
6. Data Locality – Traditionally, to process the data, the data was fetched from the location it is stored, to the location where the application is submitted; however, in Hadoop, the processing application goes to the location of data to perform computation. This reduces the delay in processing of data.
7. Compatibility – Most of the emerging big data tools can be easily integrated with Hadoop like Spark. They use Hadoop as a storage platform and work as its processing system.
Hadoop Deployment Methods
1. Standalone Mode – It is the default mode of configuration of Hadoop. It doesn’t use hdfs instead, it uses a local file system for both input and output. It is useful for debugging and testing.
2. Pseudo-Distributed Mode – It is also called a single node cluster where both NameNode and DataNode resides in the same machine. All the daemons run on the same machine in this mode. It produces a fully functioning cluster on a single machine.
3. Fully Distributed Mode – Hadoop runs on multiple nodes wherein there are separate nodes for master and slave daemons. The data is distributed among a cluster of machines providing a production environment.
Hadoop Installation on Windows 10
As a beginner, you might feel reluctant in performing cloud computing which requires subscriptions. While you can install a virtual machine as well in your system, it requires allocation of a large amount of RAM for it to function smoothly else it would hang constantly.
You can install Hadoop in your system as well which would be a feasible way to learn Hadoop.
We will be installing single node pseudo-distributed hadoop cluster on windows 10.
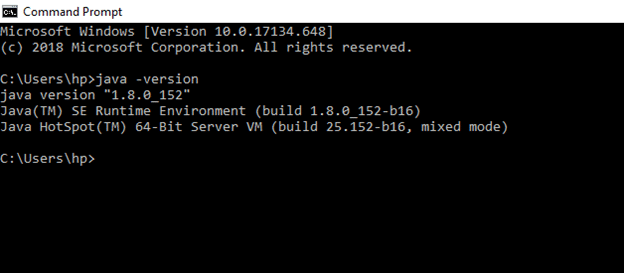
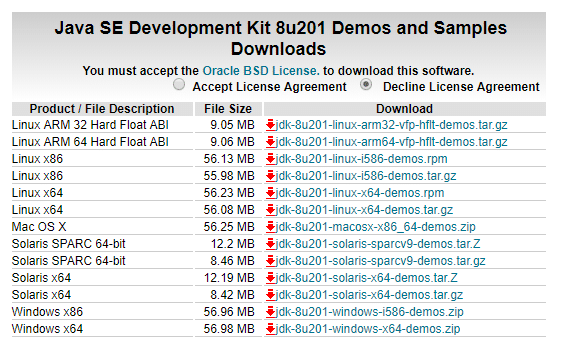
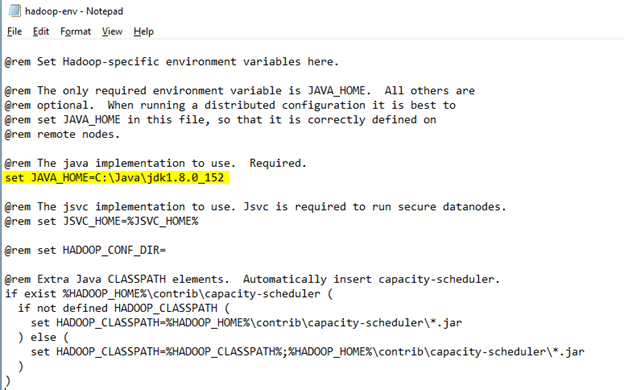
Prerequisite: To install Hadoop, you should have Java version 1.8 in your system.
Check your java version through this command on command prompt
Download the file according to your operating system. Keep the java folder directly under the local disk directory (C:\Java\jdk1.8.0_152) rather than in Program Files (C:\Program Files\Java\jdk1.8.0_152) as it can create errors afterwards.
After downloading java version 1.8, download hadoop version 3.1 from this link –
Extract it to a folder.
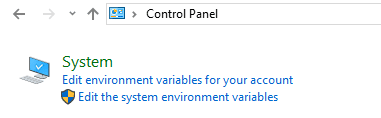
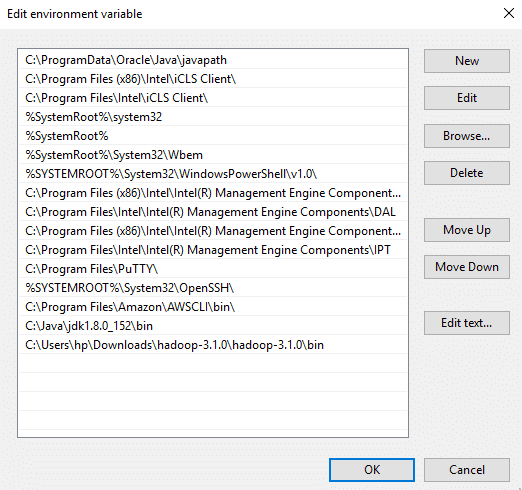
Setup System Environment Variables
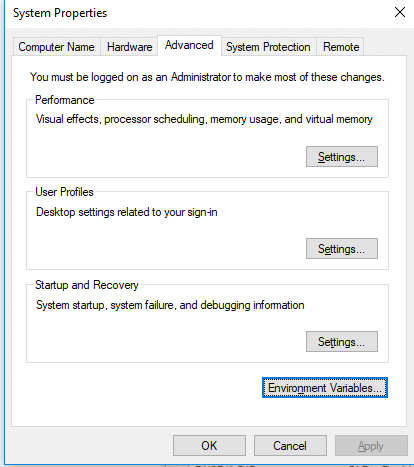
Open control panel to edit the system environment variable
Go to environment variable in system properties
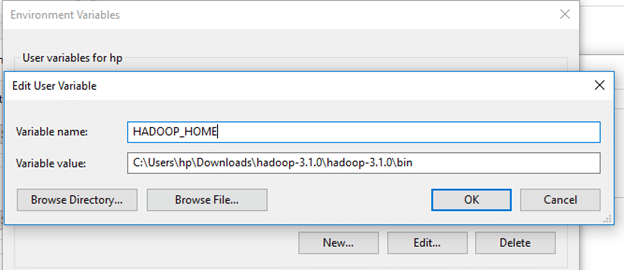
Create a new user variable. Put the Variable_name as HADOOP_HOME and Variable_value as the path of the bin folder where you extracted hadoop.
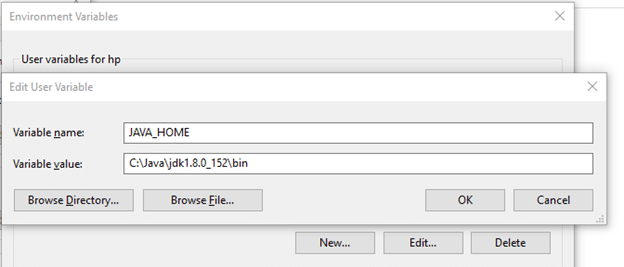
Likewise, create a new user variable with variable name as JAVA_HOME and variable value as the path of the bin folder in the Java directory.
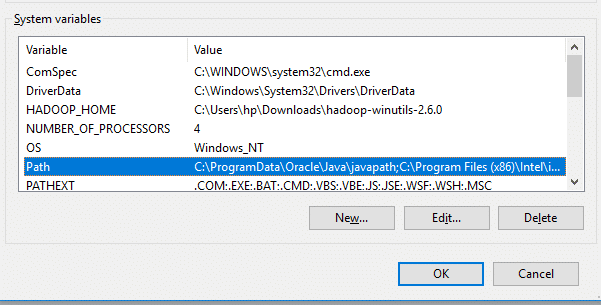
Now we need to set Hadoop bin directory and Java bin directory path in system variable path.
Edit Path in system variable
Click on New and add the bin directory path of Hadoop and Java in it.
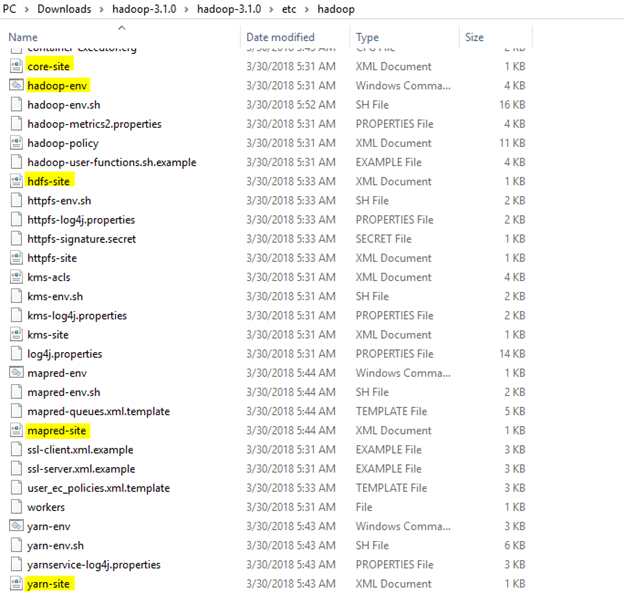
Configurations
Now we need to edit some files located in the hadoop directory of the etc folder where we installed hadoop. The files that need to be edited have been highlighted.
1. Edit the file core-site.xml in the hadoop directory. Copy this xml property in the configuration in the file
Download it as zip file. Extract it and copy the bin folder in it. If you want to save the old bin folder, rename it like bin_old and paste the copied bin folder in that directory.
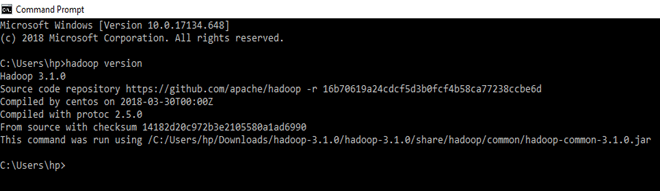
Check whether hadoop is successfully installed by running this command on cmd-
hadoop version
Since it doesn’t throw error and successfully shows the hadoop version, that means hadoop is successfully installed in the system.
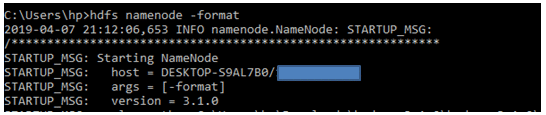
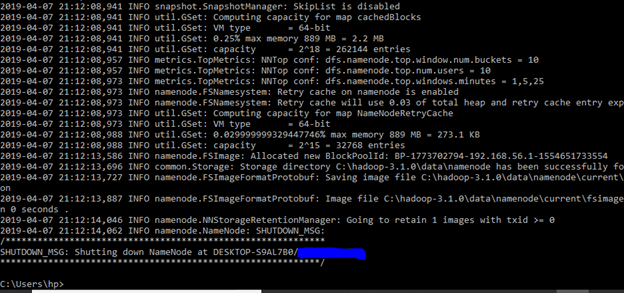
Format the NameNode
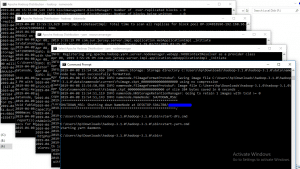
Formatting the NameNode is done once when hadoop is installed and not for running hadoop filesystem, else it will delete all the data inside HDFS. Run this command-
hdfs namenode –format
It would appear something like this –
Now change the directory in cmd to sbin folder of hadoop directory with this command,
(Note: Make sure you are writing the path as per your system)
cd C:\Users\hp\Downloads\hadoop-3.1.0\hadoop-3.1.0\sbin
Start namenode and datanode with this command –
start-dfs.cmd
Two more cmd windows will open for NameNode and DataNode
Now start yarn through this command-
start-yarn.cmd
Two more windows will open, one for yarn resource manager and one for yarn node manager.
Note: Make sure all the 4 Apache Hadoop Distribution windows are up n running. If they are not running, you will see an error or a shutdown message. In that case, you need to debug the error.
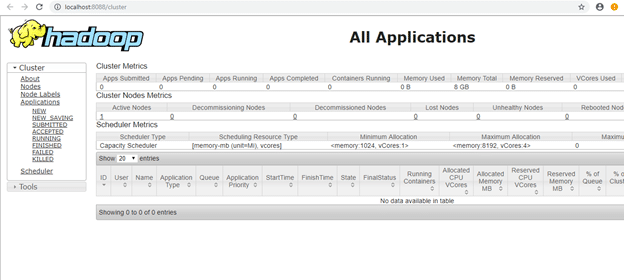
To access information about resource manager current jobs, successful and failed jobs, go to this link in browser-
To verify if the file is copied to the folder, I will use ‘ls’ command by specifying the folder name which will read the list of files in that folder –
hdfs dfs –ls /sample
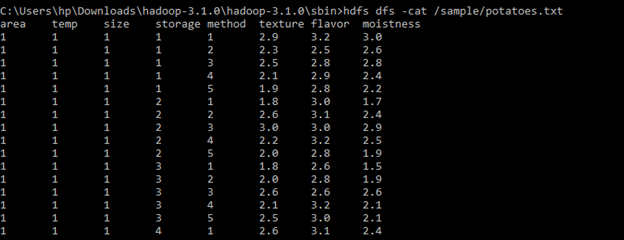
To view the contents of the file we copied, I will use cat command-
hdfs dfs –cat /sample/potatoes.txt
To Copy file from hdfs to local directory, I will use get command –
These were some basic hadoop commands. You can refer to this HDFS commands guide to learn more here
Conclusion
Hadoop MapReduce can be used to perform data processing activity. However, it possessed limitations due to which frameworks like Spark and Pig emerged and have gained popularity. A 200 lines of MapReduce code can be written with less than 10 lines of Pig code. Hadoop has various other components in its ecosystem like Hive, Sqoop, Oozie, and HBase. You can download this software as well in your windows system to perform data processing operations using cmd.
Follow this link, if you are looking to learn more about data science online!
Technological progress and the development of infrastructure has increased the popularity of Big Data immensely. Businesses have started to realize that data can be used to accurately predict the needs of customers which can increase profits significantly. The growing use of Big Data can be assessed from Forrester’s prediction of the global Big Data market to grow 14% this year.
Even though more n more individuals are entering this field, yet 41% of organisations face challenges due to lack of talent to implement Big Data as surveyed by Accenture. Users begin Big Data projects thinking it will be easy but discover that there is a lot to learn about data. It shows the need for good talent in the Big Data market.
According to a Qubole report of 2018, 83% of data professionals said that it’s very difficult to find big data professionals with necessary skills and experience and 75% said that they face headcount shortfall of professionals who can deliver big data value.
Qubole report found Spark is the most popular big data framework used in the enterprises. So if you want to enter Big Data market, learning Spark has become more like a necessity. If Big Data is a movie, Spark is its protagonist.
source: Edureka
Why Spark?
Spark is a leading platform for large scale SQL, batch processing, stream processing and machine learning.
An O’Reilly survey suggests that learning Spark could have more impact on salary than getting a PhD. It found strong correlations between those who used Apache Spark and those who were paid more.
Spark is being used for financial services by banks to recommend new financial products. It helps banks to analyse social media profiles, emails, call recordings for target advertising and customer segmentation. It is used in investment banking to analyse stock prices to predict future trends. It is being used in the healthcare industry to analyse patient records along with their past clinical data to assess their health risks. It is also used in manufacturing for large dataset analysis and retail industry to attract customers through personalized services. Many other industries like travel, e-commerce, media and entertainment are also using Spark to analyse large scale data to make better business decisions.
A major advantage of using Spark is it’s easy to use API for large scale data processing.
Spark’s API supports programming languages like Java, Python, R, and Scala. Many individuals are not from a coding background, in such a case, a simple programming language like python makes Spark user-friendly.
Spark in the Job Market
Linkedin’s top emerging jobs in India, according to its 2018 report, is topped by Machine Learning which mentions Big Data as its key skill. Big Data and Data Science jobs are one of the top 10 growing jobs in India.
Top 10 growing jobs in India
Source: LinkedIn
At least 3 out of these 10 fastest growing jobs require Big Data as a key skill. Spark is one of the most well-known and implemented Big Data processing frameworks makes it crucial in the job market.
In US, Machine Learning is the second most growing job and requires Apache Spark as a key skill.
Source: linkedIn
When you search for Big Data jobs in India on LinkedIn, you will find almost all companies have mentioned Spark as a requirement. There are close to 6500 jobs for Big Data on LinkedIn.
Source: LinkedIn
In fact, more than 2700 jobs on LinkedIn have exclusively mentioned Spark in the job profiles.
Source: LinkedIn
Demand for Apache Spark professionals is even higher in US, with more than 42k job listings, exclusively for Spark, on LinkedIn.
Source: LinkedIn
Talking about salary, on average, Big Data professionals in non-managerial role make Rs. 8.5 lacs per annum. People with specialized skill sets in Big Data earn even further and can go from 12 to 14 lacs. Freshers with a master’s degree in Big Data and analytics ranges between 4 to 10 lacs per annum, while for experienced professionals, it can go between 10 to 30 lacs per annum. IT professionals with over 10 years of experience get Big Data analytics salary of up to 1 crore.
If along with Big Data, an individual possesses Machine Learning skills, the annual salary could go up by 4 lac. Imagine if you are proficient in Spark’s other components as well, then you have much more to offer to an organization.
source: Dataflair
In United States, the average salary for Big Data ranges from approximately $68,242 per year for Data Analyst to $141,819 per year for a software architect.
Whereas, the average salary for Spark related jobs in U.S., as per Indeed, ranges from approximately $97,915 for the developer to $143,786 per year for Machine Learning Engineer.
Why Spark is in Demand?
Unified Analytics Engine: The growing demand for Spark professionals lies in the fact that it comes with high-level libraries which enable teams to run multiple workloads with a single engine. The tasks that had to be performed in a series of separate frameworks can be performed by Spark alone. It supports the following functionalities –
Source: Amazon AWS
Spark Core: It is the fundamental unit of Spark containing the basic functionalities like in-memory computation, fault tolerance and task scheduling. It can deal with unstructured data like streams of text.
Spark Streaming: It enables the processing of live data streams. This data may come from multiple sources and has to be processed as n when it arrives. It supports data from Twitter, Kafka, Flume, HDFS, and many other systems.
Spark streaming has the capability to handle streaming and analyzing enormous amounts of data in real time on a daily basis.
Companies like Uber use Spark Streaming for carrying complex analytics in real time.
Spark SQL: It is a distributed query engine that queries the data up to 100x faster than MapReduce. It is used to execute SQL queries. Data is represented as Dataframe/Dataset in Spark SQL.
Spark MLlib: It is Spark’s machine learning library. It provides tools such as ML Algorithms, Featurization, Pipelines, Persistence and Utilities like linear algebra and statistics. It supports both RDD based API and Dataframe/Dataset based API.
It enables Spark to be used for common big data functions like predictive intelligence, customer segmentation for marketing purposes and sentiment analysis. Given the growing demand for Machine learning profiles in both U.S. and India, and Spark MLlib being one of the leading platforms for machine learning, it becomes a key component in the job market.
Spark GraphX: it is used for graphs and graph parallel computations. It includes a collection of graph algorithms and builders to simplify graph analytics.
Lightning Fast Speed: Spark can be 100 times faster than Hadoop MapReduce for large scale data processing as it is an in-memory processing framework. Spark performs faster than MapReduce even when it uses disk-based processing.
Interactive Analysis: Interactive analysis allows you to quickly explore data using visualizations. Spark has the capability to explore complex datasets fastly with interactive visualization. You can use Spark’s libraries to visualize streaming machine learning algorithms.
Hybrid Framework: It supports both batch processing and stream processing which gives organizations an advantage to handle both kinds of data processing simultaneously with less space and computational time.
Deployment: It can be run both by itself on standalone mode and over several other existing cluster managers like Hadoop YARN, making it suitable for just about any business. It can also be run locally on Windows or UNIX machine that can be used for development or testing.
Conclusion
Apache Spark alone is a very powerful tool. It is in high demand in the job market. If integrated with other tools of Big Data, it makes a strong portfolio.
Today, Big Data market is booming and many individuals are making use of it. It is wiser to pull your socks up and make use of the opportunity.
There is no particular threshold size which classifies data as “big data”, but in simple terms, it is a data set that is too high in volume, velocity or variety such that it cannot be stored and processed by a single computing system.
Big Data market is predicted to rise from $27 billion (in 2014) to $60 billion in 2020 which will give you an idea of why there is a growing demand for big data professionals.
The increasing need for big data processing lies in the fact that 90% of the data was generated in the past 2 years and is expected to increase from 4.4 zb (in 2018) to 44 zb in 2020.
Let’s see what Hadoop is and how it manages such astronomical volumes of data.
What is Hadoop?
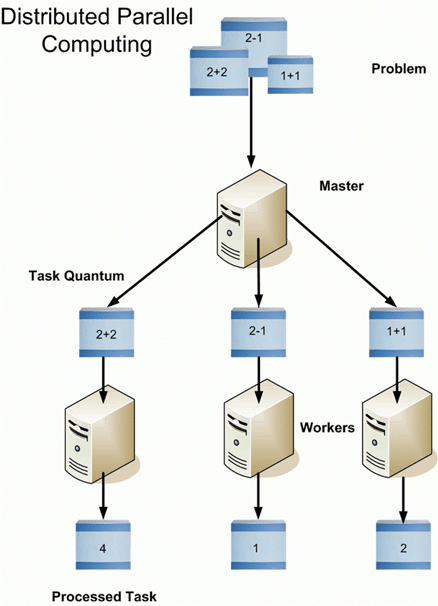
Hadoop is a software framework which is used to store and processBig Data. It breaks down large datasets into smaller pieces and processes them parallelly which saves time. It is a disk-based storage and processing system.
Distributed storage processing
It can scale from a single server to thousands of machines which increase its storage capacity and makes computation of data faster.
For eg: A single machine might not be able to handle 100 gb of data. But if we split this data into 10 gb partitions, then 10 machines can parallelly process them.
In Hadoop, multiple machines connected to each other work collectively as a single system.
There are two core components of Hadoop: HDFS and MapReduce
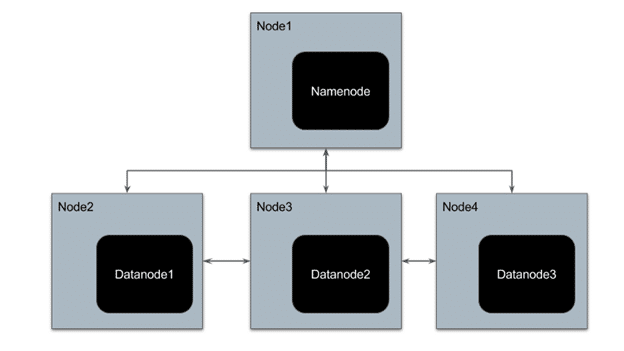
1.Hadoop Distributed File System (HDFS) –
It is the storage system of Hadoop.
It has a master-slave architecture, which consists of a single master server called ‘NameNode’ and multiple slaves called ‘DataNodes’. A NameNode and its DataNodes form a cluster. There can be multiple clusters in HDFS.
A file is split into one or more blocks and these blocks are stored in a set of DataNodes.
NameNode maintains the data that provides information about DataNodes like which block is mapped to which DataNode (this information is called metadata) and also executes operations like the renaming of files.
DataNodes store the actual data and also perform tasks like replication and deletion of data as instructed by NameNode. DataNodes also communicate with each other.
Client is an interface that communicates with NameNode for metadata and DataNodes for read and writes operations.
There is a Secondary NameNode as well which manages the metadata for NameNode.
2. MapReduce
It is a programming framework that is used to process Big Data.
It splits the large data set into smaller chunks which the ‘map’ task processes parallelly and produces key-value pairs as output. The output of Mapper is input for ‘reduce’ task in such a way that all key-value pairs with the same key goes to same Reducer. The Reducer then aggregates the set of key-value pairs into a smaller set of key-value pairs which is the final output.
An example of how MapReduce works
MapReduce Architecture
It has a master-slave architecture which consists of a single master server called ‘Job Tracker’ and a ‘Task Tracker’ per slave node that runs along DataNode.
Job Tracker is responsible for scheduling the tasks on slaves, monitoring them and re-executing the failed tasks.
Task Tracker executes the tasks as directed by master.
Task Tracker returns the status of the tasks to job tracker.
The DataNodes in HDFS and Task Tracker in MapReduce periodically send heartbeat messages to their masters indicating that it is alive.
Hadoop Architecture
What is Spark?
Spark is a software framework for processing Big Data. It uses in-memory processing for processing Big Data which makes it highly faster. It is also a distributed data processing engine. It does not have its own storage system like Hadoop has, so it requires a storage platform like HDFS. It can be run on local mode (Windows or UNIX based system) or cluster mode. It supports programming languages like Java, Scala, Python, and R.
Spark Architecture
Spark also follows master-slave architecture. Apart from the master node and slave node, it has a cluster manager that acquires and allocates resources required to run a task.
In master node, there is a ‘driver program’ which is responsible for creating ‘Spark Context’.
Spark Context acts as a gateway for the execution of Spark application.
The Spark Context breaks a job into multiple tasks and distributes them to slave nodes called ‘Worker Nodes’.
Inside the worker nodes, there are executors who execute the tasks.
The driver program and cluster manager communicate with each other for the allocation of resources. The cluster manager launches the executors. Then the driver sends the tasks to executors and monitors their end to end execution.
If we increase the number of worker nodes, the job will be divided into more partitions and hence execution will be faster.
Data Representations in Spark : RDD / Dataframe / Dataset
Data can be represented in three ways in Spark which are RDD, Dataframe, and Dataset. For each of them, there is a different API.
1. Resilient Distributed Dataset (RDD)
RDD is a collection of partitioned data.
The data in an RDD is split into chunks that may be computed among multiple nodes in a cluster.
If a node fails, the cluster manager will assign that task to another node, thus, making RDD’s fault tolerant. Once an RDD is created, its state cannot be modified, thus it is immutable. But we can apply various transformations on an RDD to create another RDD. Also, we can apply actions that perform computations and send the result back to the driver.
2. Dataframe
It can be termed as dataset organized in named columns. It is similar to a table in a relational database.
It is also immutable like RDD. Its rows have a particular schema. We can perform SQL like queries on a data frame. It can be used only for structured or semi-structured data.
3. Dataset
It is a combination of RDD and dataframe. It is an extension of data frame API, a major difference is that datasets are strongly typed. It can be created from JVM objects and can be manipulated using transformations. It can be used on both structured and unstructured data.
Spark Ecosystem
Apache Spark has some components which make it more powerful. They are explained further.
1. Spark Core
It contains the basic functionality of Spark. All other libraries in Spark are built on top of it. It supports RDD as its data representation. Its responsibilities include task scheduling, fault recovery, memory management, and distribution of jobs across worker nodes, etc.
2. Spark Streaming
It is used to process data which streams in real time. Eg: You search for a product and immediately start getting advertisements about it on social media platforms.
3. Spark SQL
It supports using SQL queries. It supports data to be represented in the form of data frames and dataset.
4. Spark MLlib
It is used to perform machine learning algorithms on the data.
5. Spark GraphX
It allows data visualization in the form of the graph. It also provides various operators for manipulating graphs, combine graphs with RDDs and a library for common graph algorithms.
Hadoop vs Spark: A Comparison
1. Speed
In Hadoop, all the data is stored in Hard disks of DataNodes. Whenever the data is required for processing, it is read from hard disk and saved into the hard disk. Moreover, the data is read sequentially from the beginning, so the entire dataset would be read from the disk, not just the portion that is required.
While in Spark, the data is stored in RAM which makes reading and writing data highly faster. Spark is 100 times faster than Hadoop.
Suppose there is a task that requires a chain of jobs, where the output of first is input for second and so on. In MapReduce, the data is fetched from disk and output is stored to disk. Then for the second job, the output of first is fetched from disk and then saved into the disk and so on. Reading and writing data from the disk repeatedly for a task will take a lot of time.
But in Spark, it will initially read from disk and save the output in RAM, so in the second job, the input is read from RAM and output stored in RAM and so on. This reduces the time taken by Spark as compared to MapReduce.
2. Data Processing
Hadoop cannot be used for providing immediate results but is highly suitable for data collected over a period of time. Since it is more suitable for batch processing, it can be used for output forecasting, supply planning, predicting the consumer tastes, research, identify patterns in data, calculating aggregates over a period of time etc.
Spark can be used both for both batch processing and real-time processing of data. Even if data is stored in a disk, Spark performs faster. It is suitable for real-time analysis like trending hashtags on Twitter, digital marketing, stock market analysis, fraud detection, etc.
3. Cost
Both Hadoop and Spark are open source Apache products, so they are free software. But they have hardware costs associated with them. They are designed to run on low cost, easy to use hardware. Since Hadoop is disk-based, it requires faster disks while Spark can work with standard disks but requires a large amount of RAM, thus it costs more.
4. Simplicity
Spark programming framework is much simpler than MapReduce. It’s APIs in Java, Python, Scala, and R are user-friendly. But Hadoop also has various components which don’t require complex MapReduce programming like Hive, Pig, Sqoop, HBase which are very easy to use.
5. Fault Tolerance
In Hadoop, the data is divided into blocks which are stored in DataNodes. Those blocks have duplicate copies stored in other nodes with the default replication factor as 3. So, if a node goes down, the data can be retrieved from other nodes. This way, Hadoop achieves fault tolerance.
Spark follows a Directed Acyclic Graph (DAG) which is a set of vertices and edges where vertices represent RDDs and edges represents the operations to be applied on RDDs. In this way, a graph of consecutive computation stages is formed.
Spark builds a lineage which remembers the RDDs involved in computation and its dependent RDDs.
So if a node fails, the task will be assigned to another node based on DAG. Since RDDs are immutable, so if any RDD partition is lost, it can be recomputed from the original dataset using lineage graph. This way Spark achieves fault tolerance.
But for processes that are streaming in real time, a more efficient way to achieve fault tolerance is by saving the state of spark application in reliable storage. This is called checkpointing. Spark can recover the data from the checkpoint directory when a node crashes and continue the process.
6. Scalability
Hadoop has its own storage system HDFS while Spark requires a storage system like HDFS which can be easily grown by adding more nodes. They both are highly scalable as HDFS storage can go more than hundreds of thousands of nodes. Spark can also integrate with other storage systems like S3 bucket.
It is predicted that 75% of Fortune 2000 companies will have a 1000 node Hadoop cluster.
Facebook has 2 major Hadoop clusters with one of them being an 1100 machine cluster with 8800 cores and 12 PB raw storage.
Yahoo has one of the biggest Hadoop clusters with 4500 nodes. It has more than 100,000 CPUs in greater than 40,000 computers running Hadoop.
Source: https://wiki.apache.org/hadoop/PoweredBy
7. Security
Spark only supports authentication via shared secret password authentication.
While Hadoop supports Kerberos network authentication protocol and HDFS also supports Access Control Lists (ACLs) permissions. It provides service level authorization which is the initial authorization mechanism to ensure the client has the right permissions before connecting to Hadoop service.
So Spark is little less secure than Hadoop. But if it is integrated with Hadoop, then it can use its security features.
8. Programming Languages
Hadoop MapReduce supports only Java while Spark programs can be written in Java, Scala, Python and R. With the increasing popularity of simple programming language like Python, Spark is more coder-friendly.
Conclusion
Hadoop and Spark make an umbrella of components which are complementary to each other. Spark brings speed and Hadoop brings one of the most scalable and cheap storage systems which makes them work together. They have a lot of components under their umbrella which has no well-known counterpart. Spark has a popular machine learning library while Hadoop has ETL oriented tools. However, Hadoop MapReduce can be replaced in the future by Spark but since it is less costly, it might not get obsolete.













































 This histogram represents a chi square distribution, so it is positively skewed
This histogram represents a chi square distribution, so it is positively skewed So in this box plot, the median is at 0 as in normal distribution, median is equal to mean.
So in this box plot, the median is at 0 as in normal distribution, median is equal to mean.