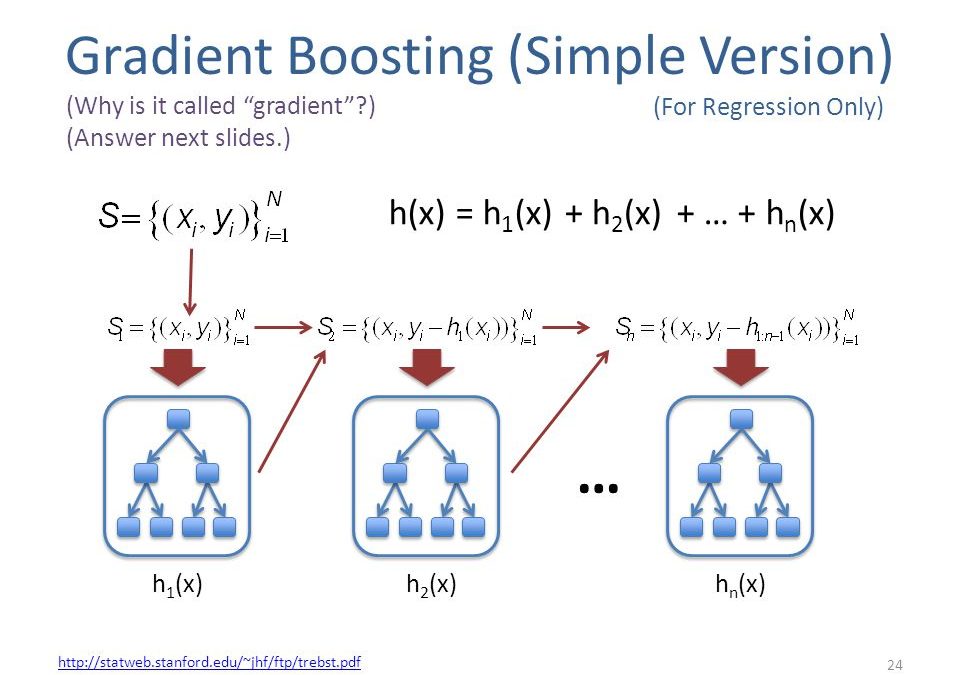
Gradient Boosting Model is a machine learning technique, in league of models like Random forest, Neural Networks etc.It can be used over regression when there is non-linearity in data, data is sparsely populated, has low fil rate or simply when regression is just unable to give expected results.Must Read: First step to exploring data: Univariate AnalysisThough GBM is a black box modeling technique with relatively complicated mathematics behind it, this blog aims to present it in a way which helps easy visualization while staying true to the basic nature of the model.Let us assume a simple classification problem where one has to classify positives and negatives.A simple classification model (with errors associated with it) eg.Regression trees, can be run to acheive it.The Box 1 in the diagram below represents such a model.

Understanding GBM
- The decision boundary predicts 2 +ve and 5 -ve points correctly.
lijek za potenciju u ljekarnamaBox 2: Output of Second Weak Learner
- The points classified correctly in box 1 are given a lower weight and vice versa.
- The model focuses on high weight points now and classifies them correctly. But, others are misclassified now.
Similar trend can be seen in box 3 as well.This continues for many iterations.In the end, all models (e.g.regression trees) are given a weight depending on their accuracy and a consolidated result is generated.In a simple notational form if M(x) is our first model say with an 80% accuracy.Instead of building new models altogether, a simpler way would be followingY= M(x) + errorIf the error is white noise i.e it has correlation with the target variable, a model can be built on iterror = G(x) + error2error2 = H(x) + error3combining these three:Y = M(x) + G(x) + H(x) + error3 This probably will have a accuracy of even more than 84%.Now , optimal weights are given to each of the three learners, Y = alpha * M(x) + beta * G(x) + gamma * H(x) + error4This was a broad overview just touching the tip of a more complex iceberg behind Gradient Boosting technique.Keep watching the space as we dig some deeper into it.
Trackbacks/Pingbacks