
The flux of data is increasing exponentially in this age of Digital awakening. Data has become so important to major industries and sectors around the globe that it can literally be referred to as digital gold! From simple company centric applications to major platforms interweaving people from all around the world, data has started to shape major decisions for not only autonomous machines, but also for the human race as a whole. This imagery is as intriguing as it is terrifying, but only if we make it so.
In order to handle this rapidly incoming data with relative ease, a competent system is required to act instantly and deliver results on the fly. Otherwise, such large-scale investments on data gathering and data generation will go to waste since the data will be left in its dormant state without any active or competent agent acting on it. This is where the concept of real time data streaming and processing comes up. So, what is real time data streaming?
As is already known, data is being generated from various sources at a lightening pace. If we stop to ingest enough data, process it in batches and then provide the results after enough time has passed, the results will tend to lose its relevance and will reflect outdated patterns and trends. This happens majorly because of the high rate of variance in incoming data and also because of time constraints.
For instance, suppose that you have a machine which tells you which horse to bet upon in a horse race. You have the option of changing your choice during the race until the last lap commences. In such a case, if your machine gives you predictions based on the first lap where horse A was showing promise, and predicts that horse A will win, where in fact, during the third lap, horse B shows further promise, you will lose your bet just because of a machine which lags behind by two laps. This problem can be avoided by processing incoming data instantly, or in other words, real time data streaming. A stack of old data or historical data is studied and incoming records are processed based on the studied patterns such that the results are delivered within milliseconds. For our example, the horse race prediction machine would have already studied data about the different horses in the race previously and then based on the incoming data (the horse number, position of the horse, time since beginning of race, number of contestants, etc.), will be able to instantly allocate a rank for the different participants with the help of real time data streaming.
How to Go About Real-Time Data Streaming?
In real time mission-critical applications, Apache Kafka has turned out to be one of the most widely used frameworks for implementation. Apache Kafka is integrated with efficient machine learning frameworks in order to enable model training and speedy deliverance by supporting real time data streaming.
What is Apache Kafka?
As per Kafka’s website, it defines itself and its tasks as follows:
“Kafka® is used for building real-time data pipelines and streaming apps. It is horizontally scalable, fault-tolerant, wicked fast, and runs in production in thousands of companies.”
“The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds. Its storage layer is essentially a “massively scalable pub/sub message queue designed as a distributed transaction log”, making it highly valuable for enterprise infrastructures to process streaming data.” – Wikipedia
These definitions might seem like a mouthful at first, but as we go through with this subject step by step in this discussion, one will easily get the hang of it in no time!
Why use Tensorflow as the machine learning platform which is to be integrated with Apache Kafka?
Tensorflow is one of the most popular and efficient open source machine learning platforms available. It has a beautiful and well-suited architecture which enables data flow with extreme grace and optimization. It enables users and developers to establish large-scale projects with minimal hassles and maximal resource optimization. It is thus, a very competent platform to integrate with Apache Kafka for the purpose of serving real-time data streaming.
Tensorflow’s tf.keras and tf.data are responsible for streaming data in and out. Previously however, these modules were limited in their usage and could only support a few data formats. Support for Kafka streaming was not included during the earlier versions of Tensorflow. It was also difficult to use Tensorflow supported modules like tf. Examples and TFRecord in Big data and the general community of Data Science as a whole and were, therefore, rarely spotted.
It was thus, a difficult task to integrate the Apache Kafka and Tensorflow frameworks. A lot of intermediary bridges had to be constructed in order to establish reliable handshakes between these two frameworks and ensure smooth integration. This was a burdensome process since it included designing of an entire infrastructure which turned out to be a fault prone mechanism most of the time. These were the steps which were required to be followed in order to establish a working data streaming flow:
Read data from the Kafka stream -> Convert to TFRecord format -> call Tensorflow’s function to read the TFRecord object from file system -> execute model and deliver result -> save the result in the file system again -> write results/ inference back to Kafka
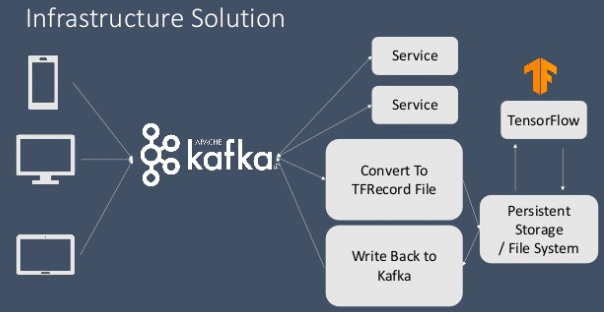
Source: Kafka Summit NYC 2019, Yong Tang
However, with the release of Tensorflow 2.0, the tables turned and the support for Apache Kafka data streaming module was issued along with support for a varied set of other data formats in the interest of the data science and statistics community (released in the IO package from Tensorflow: here).

Source: Kafka Summit NYC 2019, Yong Tang
With this development, it is now possible to enable real time streaming with Kafka and Tensorflow with relative ease and minimized error. This process is implemented with the use of KafkaDataset module (written in C++) which is a part of the new release of the Tensorflow IO package. KafkaDataset module has been integrated as a subclass of tf.data.Dataset module. This module works just like any other data streaming module where users can simply read data from a kafka stream and use it in a Tensorflow graph or feed it to tf.keras and other Tensorflow specific modules for model training and evaluation purpose. The option of writing back through output stream is also possible of course.
Here is how to implement data streaming, processing, model training and inference gathering in just a few lines of code with Kafka support on Tensorflow:
1. import tensorflow_io.kafka as kafka_io
2.dataset = kafka_io.KafkaDataset(‘topic’, server=’localhost’,group=’’)
#Preprocessing, if required
3.dataset=dataset.map(lambda x: ….)
#Model building
4.model = tf.keras.models….
5.model.compile(…)
6.model.fit(dataset, epochs=5)
#keras callback
7.class OutputCallback(tf.keras.callbacks.Callback):
8. def.__init__(self, batch_size, topic, servers):
9. self.sequence = kafka_io.KafkaOutputSequence(topic=topic, servers=servers)
10. self._batch_size = batch_size
11. def on_predict_batch_end(self, batch, logs=None):
12. self._sequence.setitem(index, class_names[np.argmax(output)])
#results with callback for streaming input and output
13.model.predict(test_dataset, callbacks=[OutputCallback(32,’topic’,’localhost’)])
Source: Kafka Summit NYC 2019, Yong Tang
Code Overview/ Explanation:
Line 2 simply streams in data with the help of the KafkaDataset module and data processing and modeling are immediately commenced as can be seen in lines 3 and 4. Thereafter, we move on to the keras callback stage. Keras callbacks are very informative since they provide an overview of the internal stages and statistical details of the model during the training or prediction process. The callback function is written in the 7th line. The KafkaOutputSequence is responsible for writing the results to the output stream (with so much relative ease!). In line 13 the predict function is called to get the model details and inference on the test dataset.
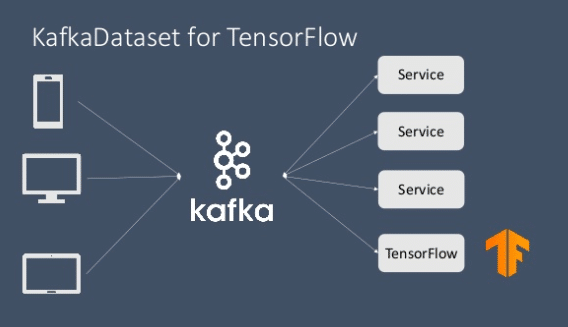
Source: Kafka Summit NYC 2019, Yong Tang
Real time data streaming with Kafka and Tensorflow has not only helped in the elimination of the complicated infrastructure which previously bridged the wide gap between the two popular platforms, but has also made the process less error prone and more approachable for real time mission critical systems with respect to machine learning and data science. The above picture shows how easy it is now to implement Kafka along with Tensorflow with just one call for data streaming. Further development in this area looks highly promising and is sure to contribute manifold in the ease of scalability and smooth integration when it comes to Big Data, live or real time data streaming, machine learning and deep learning techniques to develop smart and autonomous systems across the globe!
Get a grip on the machine learning, data science, big data and several other intriguing topics by following our blogs or even our detailed courses provided in the links below:
Follow this link, if you are looking to learn data science online!
You can follow this link for our Big Data course, which is a step further into advanced data analysis and processing!
Additionally, if you are having an interest in learning Data Science, click here to start the Online Data Science Course
Furthermore, if you want to read more about data science, read our Data Science Blogs