
source: PPM Express
As we move towards a data-driven world, we tend to realize how the power of analytics could unearth the most minute details of our lives. From drawing insights from data to making predictions of some unknown scenarios, both small and large industries are thriving under the power of big data analytics.
A-Z Glossary
There are various terms, keywords, concepts that are associated with Analytics. This field of study is broad, and hence, it could be overwhelming to know each one of it. This blog covers some of the critical concepts in analytics from A-Z, and explain the intuition behind that.
A: Artificial Intelligence – AI is the field of study which deals with the creation of intelligent machines that could behave like humans. Some of the widespread use cases where Artificial Intelligence has found its way are ChatBots, Speech Recognition, and so on.
There are two main types of Artificial Intelligence –Narrow AI, and Strong AI. A poker game is an example for the weak or the narrow AI where you feed all the instructions into the machines. It is trained to understand every scenario and incapable of performing something on their own.
On the other hand, a Strong AI thinks and acts like a human being. It is still far-fetched, and a lot of work is being done to achieve ground-breaking results.
B: Big Data – The term Big Data is quite popular and is being used frequently in the analytical ecosystem. The concept of big data came into being with the advent of the enormous amount of unstructured data. The data is getting generated from a multitude of sources which bears the properties of volume, veracity, value, and velocity.
Traditional file storage systems are incapable of handling such volumes of data, and hence companies are looking into distributed computing to mine such data. Industries which makes full use of the big data are way ahead off their peers in the market.
C: Customer Analytics – Based on the customer’s behavior, relevant offers delivered to them. This process is known as Customer Analytics. Understanding the customer’s lifestyle and buying habits would ensure better prediction of their purchase behaviors, which would eventually lead to more sales for the company.
The accurate analysis of customer behavior would increase customer loyalty. It could reduce campaign costs as well. The ROI would increase when the right message delivered to each segmented group.
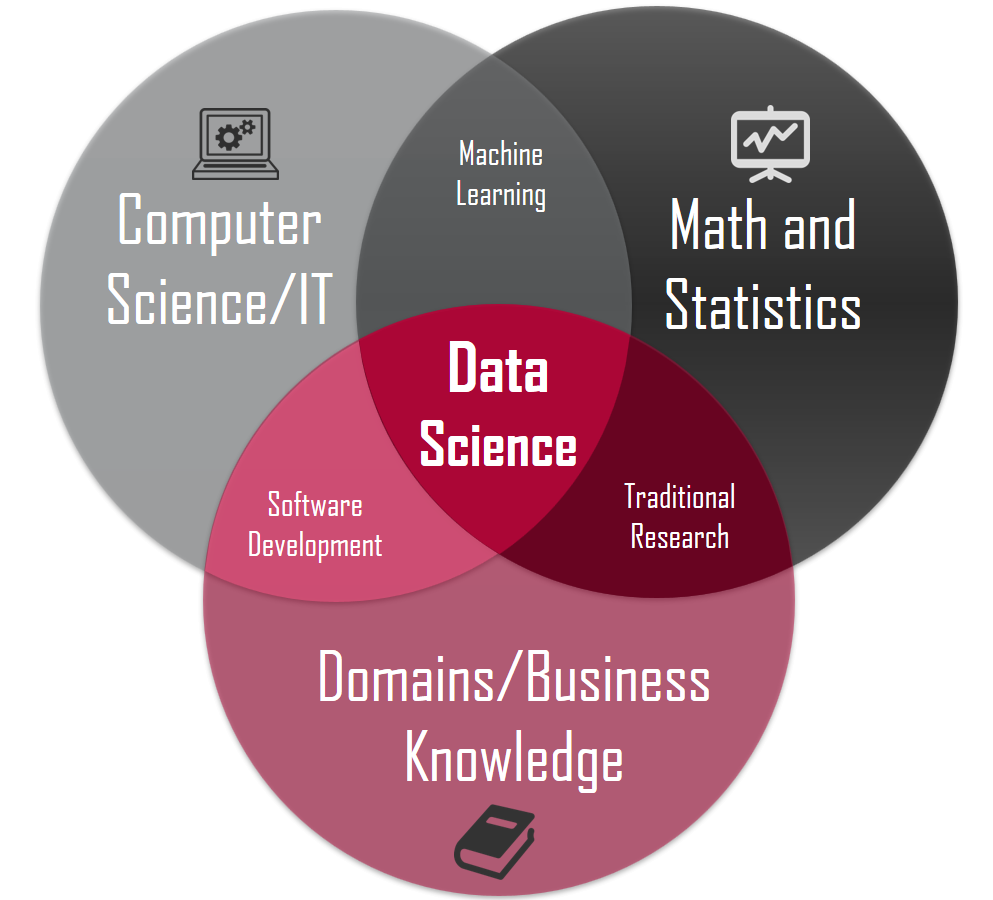
D: Data Science – Data Science is a holistic term which involves a lot of processes which includes data extraction, data pre-processing, building predictive models, data visualization, and so on. Generally, in big companies, the role of a Data Scientist is well defined unlike in startups where you would need to look after all the aspects of an end-to-end project.
source: Towards Data Science
E: Excel –An old, and yet the most used after visualization tool in the market is Microsoft Excel. Excel is used in a variety of ways while presenting the data to the stakeholders. The graphs and charts lay down the proper demonstration of the work done, which makes it easier for the business to take relevant decisions.
Moreover, Excel has a rich set of utilities which could useful in analyzing structured data. Most companies still need personnel with the knowledge of MS Excel, and hence, you must master it.
F: Financial Analytics – Financial Data such as accounts, transactions, etc., are private and confidential to an individual. Banks refrain from sharing such sensitive data as it could breach privacy and lead to financial damage of a customer.
However, such data if used ethically could save losses for a bank by identifying potential fraudulent behaviors. It would also be used to predict the loan defaulting probability. Credit scoring is another such use case of financial analytics.
G: Google Analytics – For analyzing website traffic, Google provides a free tool known as Google Analytics. It is useful to track any marketing campaign which would give an idea about the behavior of customers.
There are four levels via which the Google Analytics collects the data – User level which understands each user’s actions, Session level which monitors the individual visit, Page view level which gives information about each page views, and Event level which is about the number of button clicks, views of videos, and so on.
H: Hadoop –The framework most commonly used to store, and manipulate big data is known as Hadoop. As a result of high computing power, the data is processed fast in Hadoop.
Moreover, parallel computing in multiple clusters protects the loss of data and provides more flexibility. It is also cheaper, and could easily be scaled to handle more data.
I: Impala – Impala is a component of Hadoop which provides a SQL query engine for data processing. Written in Java, and C++, Impala is better than other SQL engines. Use SQL; the communication enabled between users and the HDFS, which is faster than Hive. Additionally, different formats of a file could also be read using Impala.
J: Journey Analytics – A sequential journey related to customer experience, which meets a specific business referred to as Journey Analytics. Over time, a customer’s interaction with the company compiled from its journey analytics.
K: K-means clustering – Clustering is a technique where you group a dataset into some small groups based on the similar properties shared among the members of the same group.
K-Means clustering is one such clustering algorithm where an unsupervised dataset split into k number of groups or clusters. K-Means clustering could be used to group a set of customers or products resembling similar properties.
L: Latent Dirichlet Allocation – LDA or Latent Dirichlet Allocation is a technique used over textual data in use cases such as topic modeling. Here, a set of topics imagined by the LDA representing a set of words. Then, it maps all the documents to the topics ensuring that those imaginary topics capture words in each text.
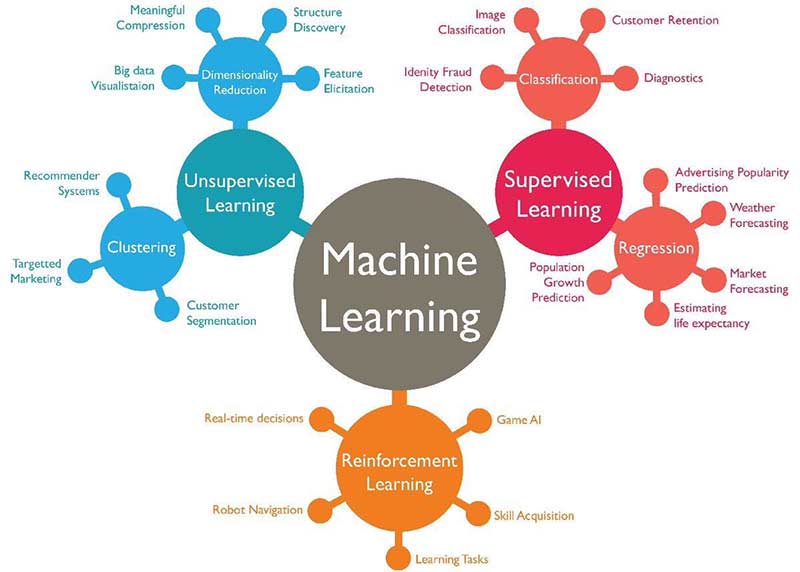
M: Machine Learning – Machine Learning is a field of Data Science which deals with building predictive models to make better business decisions.
A machine or a computer is first trained with some set of historical data so that it finds patterns in it, and then predict the outcome on an unknown test set. There are several algorithms used in Machine Learning, one such being K-means clustering.
source: TechLeer
N: Neural Networks – Deep Learning is the branch of Machine Learning, which thrives on large complex volumes of data and is used to cases where traditional algorithms are incapable of producing excellent results
Under the hood, the architecture behind Deep Learning is Neural Networks, which is quite similar to the neurons in the human brain.
O: Operational Analytics –The analytics behind the business, which focuses on improving the present state of operations, referred to as Operational Analytics.
Various data aggregation and data mining tools used which provides a piece of transparent information about the business. People who are expert in this field would use operational software provided knowledge to perform targeted analysis.
P: Pig –Apache Pig is a component of Hadoop which is used to analyze large datasets by parallelized computation. The language used is called Pig Latin.
Several tasks, such as Data Management could be served using Pig Latin. Data checking and filtering could be done efficiently and quickly with Pig.
Q: Q-Learning –It is a model-free reinforcement learning algorithm which learns a policy by informing an agent the actions to be taken under specific certain circumstances. The problems handled with stochastic transitions and rewards, and it doesn’t require adaptations.
R: Recurrent Neural Networks –RNN is a neural network where the input to the current step is the output from the previous step.
It used in cases such as text summarization was to predict the next word, the last words are needed to remember. The issue of the hidden layer was solved with the advent of RNN as it recalls sequence information.
S: SQL –One of the essential skill in analytics is Structured Query Language or SQL. It is used in RDBMS to fetch data from tables using queries.
Most companies use SQL for their initial data validation and analysis. Some of the standard SQL operations used are joins, sub-queries, window functions, etc.
T: Traffic Analytics –The study of analyzing a website’s source of traffic by looking into its clickstream data is known as traffic analytics. It could help in understanding whether direct, social, paid traffic, etc., are bringing in more users.
U: Unsupervised Machine Learning –The type of machine learning which deals with unlabeled data is known as unsupervised machine learning.
Here, no labels provided for a corresponding set of features, and information is grouped based on the similarity in the properties shared by the members of each group. Some of the unsupervised algorithms are PCA, K-Means, and so on.
V: Visualization –The analysis of data is useless if not presented in the forms of graphs and charts to the business. Hence, Data visualization is an integral part of any analytics project and also one of the key steps in data pre-processing and feature engineering.
W: Word2vec –It is a neural network used for text processing which takes in a text as input and output are a set of feature vectors of the words.
Some of the applications of word2vec are in genes, social media graphs, likes, etc. In a vector space, similar words are grouped using word2vec without the need for human intervention.
X: XGBoost –Boosting is a technique in machine learning by which a strong learner strengthens a weak learner in subsequent steps.
XGBoost is one such boosting algorithm which is robust to outliers, or NULL values. It is the go-to algorithm in Machine Learning competitions for its speed and accuracy.
Y: Yarn –YARN is a component of Hadoop which lies between HDFS, and the processing engines. In individual cluster nodes, the processing operations monitored by YARN.
The dynamic allocation of resources is also handled by it, which improves application performance and resource utilization.
Z: Z-test –A type of hypothesis testing used to determine whether to reject or accept the NULL hypothesis. By how many standard deviations, a data point is further away from the mean could be calculated using Z-test.
Conclusion
In this blog post, we covered some of the terms related to the analytics starting with each letter in the English.
If you are willing to learn more about Analytics, follow the blogs and courses of Dimensionless.
Follow this link, if you are looking to learn more about data science online!
Additionally, if you are having an interest in learning Data Science, Learn online Data Science Course to boost your career in Data Science.
Furthermore, if you want to read more about data science, you can read our blogs here