In addition to being the sexiest job of the twenty-first century, Data Science is new electricity as quoted by Andrew Ng. A lot of professionals from various disciplines and domain are looking to make a transition into the field of analytics and use Data Science to solve various problems across multiple channels. Being an inter-disciplinary study, one could easily mine data for various operations and help decision-makers make relevant conclusions to achieve sustainable growth.
The field of Data Science comprises of various components such as Data Analysis, Machine Learning, Deep Learning, and Business Intelligence and so on. The implication differs according to the business needs and its workflow. In a corporate firm, a Data Science project is always comprised of people with diverse skillsets as various nitty-gritty need to be taken care of by different people.
Now the question may arise – What is Data Science? Data Science is nothing but a way to use several tools and techniques to mine relevant data for a business to derive insights and take appropriate decisions. Analytics could be divided into Descriptive and Predictive Analytics. While descriptive analytics deals with cleaning, munging, wrangling and presenting the data in the form of charts and graphs to the stakeholders, on the other hand, predictive analytics is about building robust models which would predict future scenarios.
In this blog, we would talk about exploratory data analysis which in one sense is a descriptive analysis process and is one of the most important parts in a Data Science project. Before you start building models, your data should be accurate with no anomalies, duplicates, missing values and so on. It should also be properly analysed to find relevant features which would make the best prediction.
Exploratory Data Analysis in Python
Python is one of the most flexible programming languages which has a plethora of uses. There is a debate between Python and R as to which one is best for Data Science. However, in my opinion, there is no fixed language and it completely depends on the individual. I personally prefer Python because of its ease of use and its broad range of features. Certainly, in exploring the data, Python provides a lot of intuitive libraries to work with and analyse the data from all directions.
To perform exploratory Data Analysis, we would use a house pricing dataset which is a regression problem. The dataset could be downloaded from here.
Below is the description of the columns in the data.
SalePrice – This is our target variable which we need to predict based on the rest of the features. In dollars, the price of each property is defined.
MSSubClass – It is the class of the building.
MSZoning – The zones are classified in this column.
LotFrontage – With respect to the property, the values of the linear feet of the street connected to it is provided here.
LotArea – The size of the lot in square feet.
Street – The road access type.
Alley – The alley access type.
LotShape – The property shape in general.
LandContour – The property flatness is defined by this column.
Utilities – The utilities type that are available.
LotConfig – The configuration lot.
LandSlope – The property slope.
Neighborhood – Within the Amies city limits, the physical locations.
Condition1 – Main road or the railroad proximity.
Condition2 – If a second is present, then the main road or the railroad proximity.
BldgType – The dwelling type.
HouseStyle – The dwelling style.
OverallQual – The finish and the overall material quality.
OverallCond – The rating of the overall condition.
YearBuilt – The date of the original construction.
YearRemodAdd – The date of the remodel.
RoofStyle – The roof type.
RoofMatl – The material of the roof.
Exterior1st – The exterior which covers the house.
Exterior2nd – If more than one material is present, then the exterior which covers the house.
MasVnrType – The type of the Masonry veneer.
MasVnrArea – The area of the Masonry veneer.
ExterQual – The quality of the exterior material.
ExterCond – On the exterior, the material’s present condition.
Foundation – The foundation type.
BsmtQual – The basement height.
BsmtCond – The basement condition in general.
BsmtExposure – The basement walls in the garden or the walkout.
BsmtFinType1 – The finished area quality of the basement.
BsmtFinSF1 – The square feet area of the Type 1 finished.
BsmtFinType2 – If present, then the second finished product area quality.
BsmtFinSF2 – The square feet area of the Type 2 finished.
BsmtUnfSF – The square feet of the unfinished area of the basement.
TotalBsmtSF – The area of the basement.
Heating – The heating type.
HeatingQC – The condition and the quality of heating.
CentralAir – The central air conditioning.
Electrical – The electrical system.
1stFlrSF – The area of the first floor.
2ndFlrSF – The area of the second floor.
LowQualFinSF – The area of all low quality finished floors.
GrLivArea – The ground living area.
BsmtFullBath – The full bathrooms of the basement.
BsmtHalfBath – The half bathrooms of the basement.
FullBath – The above grade full bathrooms.
HalfBath – The above grade half bathrooms.
Bedroom – The above basement level bathroom numbers.
Kitchen – The kitchen numbers.
KitchenQual – The quality of the kitchen.
TotRmsAbvGrd – Without the bathrooms, the number of rooms above the ground.
Functional – The rating of home functionality.
Fireplaces – The fireplace numbers.
FireplaceQu – The quality of the fireplace.
GarageType – The location of the Garage.
GarageYrBlt – The garage built year.
GarageFinish – The garage’s interior finish.
GarageCars – In car capacity, the size of the garage.
GarageArea – The area of the garage.
GarageQual – The quality of the garage.
GarageCond – The condition of the garage.
WoodDeckSF – The area of the wood deck.
OpenPorchSF – The area of the open porch.
EnclosedPorch – The area of the enclosed porch area.
3SsnPorch – The area of the three season porch.
ScreenPorch – The area of the screen porch area.
PoolArea – The area of the pool.
PoolQC – The quality of the pool.
Fence – The quality of the fence.
MiscFeature – Miscellaneous features.
MiscVal – The miscellaneous feature value in dollars.
MoSold – The selling month.
YrSold – The selling year.
SaleType – The type of the sale.
SaleCondition – The sale condition.
As you can see, it is a high dimensional dataset with a lot of variables but all these columns would not be used in our prediction because then the model could suffer from multicollinearity problem. Below are some of the basic exploratory Data Analysis steps we could perform on this dataset.
source: Cambridge Spark
The libraries would be imported using the following commands –
Import pandas as pd
Import seaborn as sns
Import matplotlib.pyplot as plt
To read the dataset which is a CSV(Comma separated value format) we would use the read csv function of pandas and load it into a data frame.
df = pd.read_csv(‘…/input/train.csv’)
The head() command would display the first five rows of the dataset.
The info() command would give an idea about the number of values each column along with their datatypes.
To drop irrelevant features and columns with more than 30 percent missing values, the below code is used.
df2 = df[[column for column in df if df[column].count() / len(df) >= 0.3]]
del df2[‘Id’]
print(“List of dropped columns:”, end=” “)
for c in df.columns:
if c not in df2.columns:
print(c, end=”, “)
print(‘\n’)
df = df2
The describe() command would give a statistical description of all the numeric features. The statistical value includes count, mean, standard deviation, minimum, the first quartile, the mean, the third quartile, and the maximum.
dtypes gives the datatypes of all the columns.
To find the correlation between each feature, the corr() command is used. It not only helps in identifying which feature column has more variance with the target but also helps to observe multicollinearity and avoid it.
There are other operations such as df.value_counts() which gives the count of every unique value in each feature. Moreover, to fill the missing values, we could use the fillna command.
For efficient analysis of data, other than having the skills to use tools and techniques, what matters the most is your intuition about the data. Understanding the problem statement is the first step of any Data Science project followed by the necessary questions that could be formulated from it. Exploratory Data Analysis could be performed well only when you know what the questions that need to be answered are and hence the relevancy of the data is validated.
I have seen professionals jumping into Machine Learning, Deep Learning and the focusing more on the state of the art models, however, they forget or skip the most rigorous and time-consuming part which is exploratory data analysis. Without proper EDA, it is difficult to get good prediction and your model could suffer from underfitting or overfitting. A model under fits when it is too simple and has high bias resulting in both high training and test set errors. While an overfit model has high variance and fails to generalize well to an unknown set.
Conclusion
I hope this article has created an understanding of why exploratory data analysis is required and how it could go a long way in developing a better model.
Dimensionless has several blogs and training to get started with Python, and Data Science in general.
Follow this link, if you are looking to learn more about data science online!
Additionally, if you are having an interest in learning Data Science, Learnonline Data Science Course to boost your career in Data Science.
Furthermore, if you want to read more about data science, you can read our blogs here
Cloud Computing is the way to store and access data over the internet. Using cloud computing, higher level services could be obtained with minimal effort. Extreme scalability is offered by cloud computing in comparison to the traditional hardware systems. Launched in the year 2006, Amazon Web Services or AWS uses Cloud Infrastructure-as-a-Service. Amazon Web Services provides computing power, data storage and other solutions to the organizations according to their needs.
It is not only difficult but time-consuming as well to build scalable infrastructure. In the modern generation, large applications deem robust infrastructure which is even more challenging. Cloud Computing resolves such scenarios by providing services over the internet. Amazon Web Services has eliminated the need to maintain on-premise private infrastructure. At AWS, you would only pay for what you use. Security is another area where AWS has made significant strides. There is no permanent data loss as Amazon Web Services has data centers all over the world.
What is Big Data?
Technology has advanced a lot in the past decade and so is the amount of data that it generates. The internet is the source of such volumes of data from a plethora of channels. Data got generated previously as well but it didn’t have the system to mine such voluminous data. However, the recent advancement in technology and the arrival of cloud computing such as Amazon Web Services has certainly changed the way we look at such huge volumes of data now.
Big Data stands for 4 V’s – Volume, Velocity, Variety, and Veracity. Volume refers to the large chunks of terabytes of data that’s getting generated while velocity measures how rapidly we are getting such data. Variety is the different channels which generate such data while veracity is the relevant meaning that it carries.
Now, to handle and analyze such data, it requires huge computational power or strong infrastructure to build applications which would cost a lot to set up such a system. Cloud Infrastructure such as AWS thus gives us a chance to utilize big data with the help of their services and work seamlessly without worrying about scalability or security.
Why AWS Big Data is the Best Career Move?
source: rhipe
You learned about Big Data and saw how AWS provides a platform to utilize such data. Amazon Web Services is one of the go-to skills in the current market. Companies are gradually moving more traditional infrastructure set up to cloud to speed fast their process and increase the scalability.
Below are the ten reasons why AWS Big data is the best career move right now.
1. There is a saying that it is useless if you don’t have the skills to analyze it. Job opportunities in analytics and big data management have risen and so is the need to invest money and time to get trained in skills such as Amazon Web Services or AWS.
Moreover, with the analytics market set to conquer almost one-third of the current IT market, it is necessary that you train yourself with the relevant skills. The demand for professionals trained in AWS Big Data is high as organizations are looking out for various ways to exploit big data. Among US business, AWS big data is considered to be of utmost priority. As more companies are now moving towards cloud solutions such as AWS, Azure, it would enable them to get the best insights from such voluminous data.
2. To be a proven expert in AWS, you need to showcase your worth and get yourself certified. The AWS Certified solutions architect is one of the top level certifications’ at the associate level. On the Amazon Web Services platform, you would gain the experience of designing distributed applications and systems.
Additionally, it would teach you how to deploy big data applications and scale it up on the Amazon Web Services. Based on the customer requirements, what services you should use for your application. You would learn how to deploy a big data app in AWS. The other certification which you could acquire and would certainly help in taking your AWS Big Data career to the next level is the AWS Certified Solutions Architect-Professional course.
This certification proves your worth in AWS and could put you in a more advanced role in your organization. You would not only learn how dynamically scalable and reliable apps are designed or deployed.
3. The shortage of professionals who are expertized in working with Big Data in AWS is huge. On the supply side, there is a significant skill deficit. In terms of the global percentage, India has the number of analytics professionals. The talent demand in the field of Big Data Analytics and AWS is expected to grow in the future.
4. In addition, to maintain the infrastructure and build a seamless data pipelines, it is pertinent for Big Data developers to learn to code in order to build flexible systems. Thus to work with big data in AWS, it is necessary to get yourself certified with the AWS Certified Developer Associate certification.
It would provide you with the relevant knowledge to choose the Amazon Web Services package based on your application. From the application, the servers which interact with the software development kits could be made the most out of. You would also master the skills to optimize the big data system performances with the code. Moreover, security is one of the primary concerns when you are dealing with applications that are built on such volumes of data. Thus with AWS, you could add security to your big data application while still coding.
5. Amazon Web Services gives you full flexibility in controlling the flow of big data in and out of your AWS platform. In fact, on AWS, if you want to migrate on-premises big data application you could also do that. The operational cost control mechanism could be identified as well with the help of AWS.
Real-time feature is one of the primary needs while building a big data application. AWS provided the platform to do just that by managing and implementing continuous delivery systems and methods. The automation of the operational process of your application is another major advantage that Amazon Web Services provides. You would work and handle such tools which would automate those process. The governance procedures and the security control could be set as well.
6. Big Data Analytics helps in decision making and building a scalable application with Amazon Web Services would certainly help in making such decisions. At this point in time, there is still a huge amount of data that is not being used. Those unused data carries enormous information and with years to come, organizations would leave no stones unturned and would even make cloud infrastructure like AWS as the primary tool to mine those data.
For decision making, analytics is the key factor. Additionally, for strategic initiatives, big data is one of the major ingredients. In a survey conducted by the Peer-Research Big Data Analytics, it was agreed by majority that for effective business decisions, adding value to the organization, making timely analysis, big data analytics is the major factor.
7. The capability to handle various forms of data is another important feature of Amazon Web Services. Gone are those days when companies stored structured data in the form of tables in the Relational Database Management System and use SQL to perform descriptive analysis on the tabular data. These days, the maximum information is carried by data which are unstructured and generated from numerous sources across the internet.
To handle such variety of voluminous data, building scalable and robust infrastructure is a challenge and hence Amazon Web Services provides the perfect solution to that. You could easily build big data applications using both structured and unstructured data and scale those applications as well.
8. The diversity of fields or domain where big data is used is another reason why it is the best career move for you. You could apply the skills in Healthcare, Finance, Banking, Insurance, Marketing, E-Commerce and many other platforms. As most of the companies in these sectors use AWS in the backend, it would certainly improve your value if you could add big data and AWS to your skills.
9. The flexibility of the Amazon Web Services plays a major role in choosing it as one leading cloud solutions for your applications. You don’t need to pay for each and every facility but you only pay for the services you need. This makes AWS a cost-effective, robust and scalable platform for your big data problem.
10. Last but not the least and certainly one the major factors in choosing big data with AWS as the career is because of the salary that it pays and the roles that you would be working on. In India, the average package would be around 15 lakhs per annum while it is even higher outside the country such as in the UK, USA, etc.
Moreover, you would be working in roles such as Big Data Analyst, Big Data Engineer, Big Data Architect, and so on.
Conclusion
Going by the market trend, Big Data with AWS certainly gives you an edge over others and puts you in a better position in the market. To know more about it, you could look into Dimensionless.
Dimensionless has several blogs and training to get started with Python, and Data Science in general.
Follow this link, if you are looking to learn more about data science online!
Additionally, if you are having an interest in Learning AWS Big Data, LearnAWS Course Onlineto boost your career
Furthermore, if you want to read more about data science and big data, you can read our blogs here
Amazon Web Services or AWS is a cloud infrastructure-as-a-Service platform which has enabled helped organization from the burden of setting up infrastructure for any application as it provides services for various applications whose price is minimal and could be paid only for the specific services delivered. Moreover, robust, scalable and secure services are provided by the AWS which are much better than any website which a company hosts. Its data centers all over the world ensure no data is lost.
There are various instances of AWS which contributes to its workflow such as the EC2 instance, the Elastic Compute Cloud, Elastic Load Balancer, Amazon Cloud Front and so on. The description of all these components is beyond the scope of this blog. Amazon Web Services has reduced the management, maintenance overhead. The resources of AWS are reliable and available all over. The right tools could improve productivity and scalability as well.
One of the key areas where Amazon Web Services has impacted is healthcare. In this article, we would learn AWS has helped to improve clinical trials and the process that’s being followed under the hood.
Improving the Clinical Trials
In the present world, incurable diseases are being cured by personalized medicines while those are made healthier using digital medicines. There is a constant study about the eradication of the cancer cells and the functioning of our immune system. The reported study has declined since the last few years and projected to go down even further.
Thus it is necessary to work securely with the clinical trial data and maintain the compliance. AI and Machine Learning are also playing their part in this regard. To modernize the clinical trials, the AWS customers could use some common architectural patterns which would ensure cost reduction, better generation of evidence, more personalized medicines and so on.
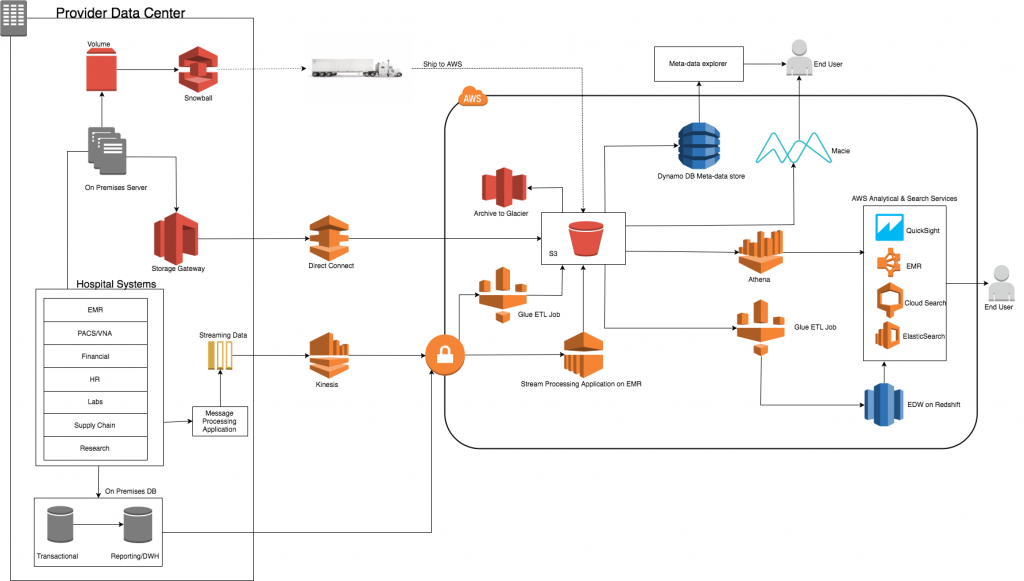
source: amazon web services
There is pressure within the pharma organizations for efficient use of the resources and streamline the process while reducing the costs. Thus gathering data from non-traditional sources such as mobile, IoT, clinical devices, and so on has become a necessity now. To improve accuracy, reduce costs, and speed up outcomes, mobile technologies could be used as it provides data ingestion supplemented with Machine Learning and Artificial Intelligence Technologies.
The traditional clinical trial process could not meet the need of emerging industries. Because of this, in case of evolving the clinical trial operations, pharmaceutical companies need assistance. To improve outcome as well as reduce the costs, clinical trials could deploy traditional technologies as well the mobile technologies. The various technologies could be integrated for some of the below use cases –
In clinical trials, the participants could be identified and tracked and recruit them. Also, patients could be educated. The trial participants could receive the associated information with the help of the standardized protocols. The adverse events could be tracked as well.
To identify novel biomarkers, the genomic and phenotypic data could be integrated.
To manage the clinical trial better, mobile data could be integrated into clinical trials.
Based on the historical data, a patient-control arm could be created.
Based on the registry, claims data sets, the cohorts are stratified.
To share data and create knowledge, an interoperable and collaborative network is built.
To manage the clinical trial, compliance-ready infrastructure could be built.
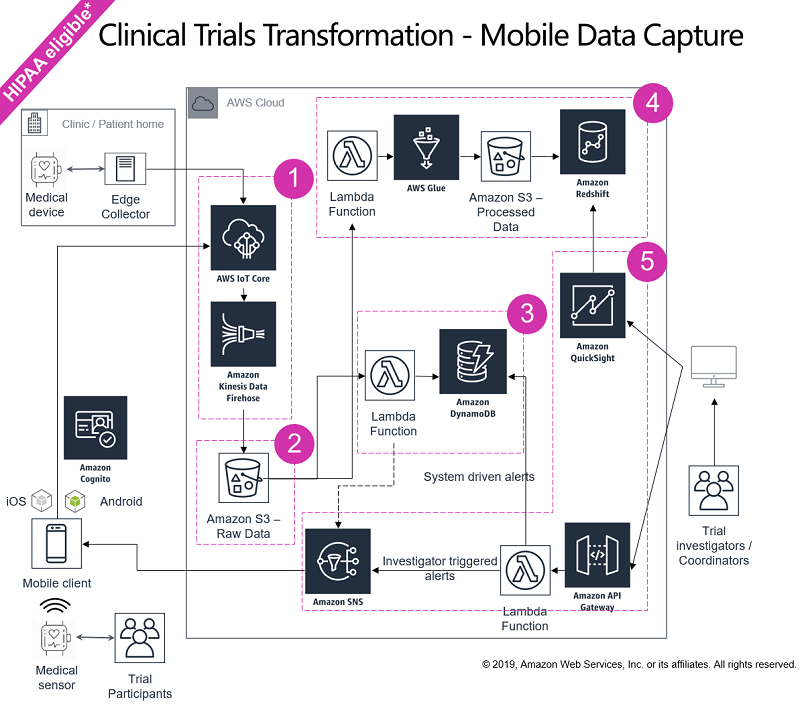
Using site monitoring, smart analytics, the patients are found and recruited. Along with it, the trial outcomes are accelerated and adverse events are detected. To manage clinical trial using mobile technologies, the below architecture is used. It ensures processing the real-time data captured through mobile devices.
source: Amazon Web Services
Steps Which the Architecture Follows –
1. Data Collection –
To generate real-time data for activity tracking, monitoring, and so on, the clinical trials and various pharmaceutical companies use personal wearables, mobile devices extensively. Devices like a dialysis machine, infusion pumps have remote setting management which is a major use case. A lot of telemetry data which are emitted by mobile devices requires data cleansing, transformation.
A sufficient computing resource is provided by the connection of these devices to the edge node which allows to stream data to the AWS IoT Core that in real time would write data to the Amazon Kinesis Data Firehouse. Cost-Efficient, flexible storage is provided by the Amazon S3 which allows replicating data on the three availability zones. Electronic medical records, case report forms, and other kinds of data could also be captured. A voluminous data could be ingested with velocity as AWS securely connects to these data sources with the help of multiple tools and services.
2. Data Storing –
On the Amazon S3, the Kinesis Data Firehouse stores the data after it’s ingested in the clinical trial from various devices and wearables. To predict pattern, and historical analysis, a raw copy of the stored data is used. To optimize the costs, the data could be periodically moved to Amazon S3 Glacier which is reduced cost storage.
When the pattern of the data access changes, the costs could be automatically optimized using the Amazon S3 Intelligent Tiering. Various encryption options are also available to encrypt the data. The data processing, backup, and other tasks have been simplified by the Amazon S3 data storage infrastructure which is durable and high availability.
3. Data Processing –
The events are published to the AWS Lambda and a lambda function is invoked which extracts the key performance indicators such as treatment schedule, medication adherence, etc., from the data. The KPI’s could be processed and stored in the Amazon DynamoDB with encryption. In real-time, the clinical trial coordinators are alerted to ensure appropriate measures are taken.
A machine learning model could be trained and implemented using a full of a medical records data warehouse which would give an idea about the patients with the chances of switching medications. These findings would ensure coordinators of the clinical trials to take those patients matter into serious consideration.
The data could be processed in batches as well. An ETL process is triggered using the AWS Glue which helps in loading the data to perform analytics. The historical data could be mined and actionable insights could be derived. The data is loaded on to the Amazon Redshift after it is stored on Amazon S3. The machine learning models are trained to identify patterns of the adherence challenges risk. The co-ordinators of the clinical trials could reinforce support and patient education henceforth.
4. Data Visualization –
The Amazon QuickSight service which is serverless is used after the data is processed. Other third-party reporting tools like PostgreSQL could also be used. The costs could be optimized using the Pay-per session pricing model of the Amazon QuickSight.
Real-Time feedback is sent to the patients using the Amazon Simple Notification Service. A fully managed pub/sub messaging is provided by the Amazon SNS which ensures many-to-many messaging and high throughput.
Amazon Web Services ensures the trust of the customer as their topmost priority. Over 190 countries, millions of customers, organizations, and so on are provided with active services and helps to protect sensitive information. The Amazon Web Services Identity and Access Management service could also be used which maintains access control and secures end user’s mobile applications.
A layer of security is also provided by the Amazon Web Services on the data. Encryption is provided for several services by the AWS. The ownership of the data could be maintained by the customer and for processing and hosting of the content, the AWS services could be selected. For marketing or any other purpose, the customer’s data is not used by AWS.
Numerous aspects of the clinical trials could be improved by the mobile devices and sensors in this ever growing technological advances in the medical devices. Activities such as patient counseling, recruitment, and so on could be helped by it. Alerting the patients, medication adherence, etc., could also be improved. In conducting clinical trials, the smart devices and robust interconnecting systems are in the heart of it.
To achieve trail performance and maintain the consistency of the data, a conundrum is faced even by the biopharma organizations. The collection, storage and the usage of data for clinical trials have been given a new dimension by the Amazon Web Services. All the conundrums are addressed and a new reality has been put into place. The technical challenges of establishing IT infrastructure, scaling, and so on has been abstracted away by the Amazon Web Services cloud. The ultimate mission is to improve the patient lives and the bio-pharma organizations have achieved just that with the development of ground-breaking and effective treatments.
Conclusion –
It is necessary to work securely with clinical trial data and maintain compliance. AI and Machine Learning are also playing their part in this regard. To modernize the clinical trials, the AWS customers could use some common architectural patterns which would ensure cost reduction, better generation of evidence, more personalized medicines and so on.
Dimensionless has several blogs and training to get started with Python, and Data Science in general.
Follow this link, if you are looking to learn more about data science online!
Additionally, if you are having an interest in learning AWS BIG DATA COURSE, Learn AWS Course Online
Furthermore, if you want to read more about data science, you can read our blogs here
Technology has seen advancing rapidly in the last few years and so is the amount the data that is getting generated. There are a plethora of sources which generates unstructured data that carries a huge amount of information if mined correctly. These varieties of voluminous data are known as the Big Data which traditional computers or storage systems are incapable to handle.
To mine big data, the concept of parallel computing or clusters came into place popularly known as the Hadoop. Hadoop has several components which not only stores the data in the form of clusters but processes them in parallel as well. The HDFS or the Hadoop storage file system stores the big data while using the Map Reduce technique the data is processed.
However, most applications nowadays generate data in real-time which requires real-time analysis. Hadoop doesn’t allow real-time data storage or analysis as the data is processed in batches in Hadoop. To resolve such instances, Apache introduced Spark which is faster than Hadoop and allows data to be processed in real time. More and more companies have since transitioned from Hadoop to Spark as their application depends on real-time data analytics. You could also perform Machine Learning operations on Spark using the MLlib library.
The computation in spark is done in memory, unlike Hadoop which relies on disk for computation. It is an elegant and expressive development application programming interface which allows fast and efficient SQL and ML operations on iterative datasets. Applications could be created everywhere and the power of Spark could be exploited as Spark runs on Apache Hadoop YARN. Within a single dataset in Hadoop, insights could be derived and the data science workloads could be enriched.
A common cluster could be shared by Spark and other applications by maintaining service and response consistency which is a foundation provided by the Hadoop YARN-based architecture. Working with YARN in HDP, one of the many data access engines now is Spark. A Spark Core and other libraries are present in the Apache Spark.
The abstraction in Spark makes data science easier. Machine Learning is a technique where algorithms learn from data. The data processing speeds up by caching the dataset by Spark which is ideal for implementing such algorithms. To model an entire Data Science workflow, a high-level abstraction is provided by Spark’s Machine Learning Pipeline API. Abstractions like Transformer, Estimator, and so on are provided by the Spark’s Machine Learning pipeline package which increases the productivity of a Data Scientist.
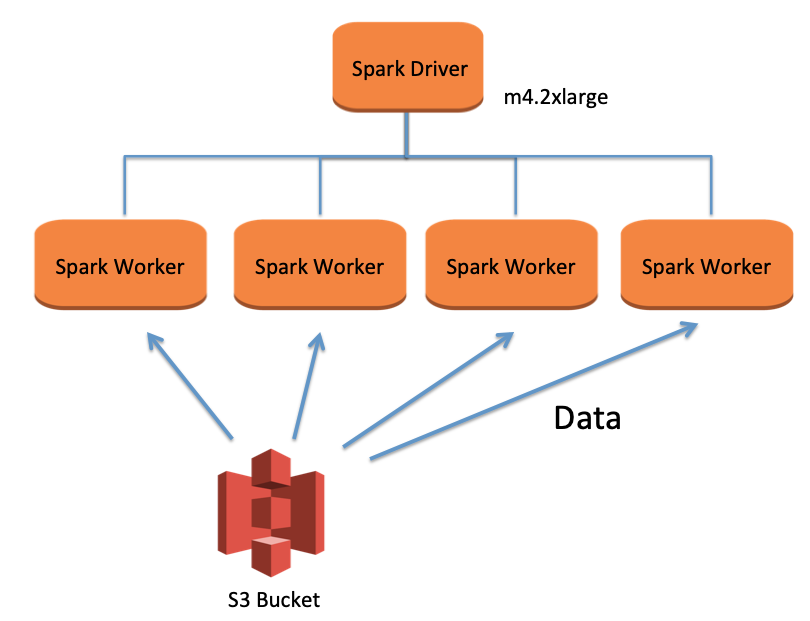
So far we have discussed Big Data and how it could be processed using Apache Spark. However, to run Apache Spark applications, proper infrastructure needs to be in place and thus Amazon EMR provides a platform to manage applications built on Apache Spark.
Managing Spark Applications on Amazon EMR
source: medium
Amazon EMR is one of the most popular cloud-based solutions to extract and analyze huge volumes of data from a variety of sources. On AWS, frameworks such as Apache Hadoop and Apache Spark could be run with the help of the Amazon EMR. In the matter of a few minutes, with the help of multiple instances, organizations could spin up a cluster which is enabled by the Amazon EMR. Through parallel processing, various data engineering and business intelligence workloads to be processed which reduces effort, cost, and time of the data processing involved in setting up the cluster.
As Apache Spark is a fast, an open-source framework, it is used in the processing of the big data. To reduce I/O, in memory across nodes, Apache Spark performs parallel computing in memory and thus the reliability of cluster memory (RAM) is heavy. On Amazon EMR, to run a Spark application, the following steps need to be performed –
To the Amazon S3, the Spark application package is uploaded.
With the configured Apache Spark, the Amazon EMR cluster is configured and launched.
Onto the cluster, from the Amazon S3, the application package is installed and then the application is run.
After the application is completed, the cluster is terminated.
For a successful operation, based on the data and processing requirements, the Spark application needs to be configured. There could be memory issues if Spark is configured with the default settings. Below are some of the memory errors occurs while maintaining Apache Spark on Amazon EMR in a default setting.
The loss of memory error when the Java Heap space is not empty – lang.OutOfMemoryError: Java heap space
When the physical memory exceeds, you get the out of memory error – Error: ExecutorLostFailure Reason: Container killed by YARN for exceeding limits
If the Virtual memory is exceeded, you would also get the out of memory error.
The Executor memory also gives the out of memory error if it’s exceeded.
Some of the reasons why these issues occur are –
While handling large volumes of data, due to the inappropriate settings of the number of cores, executor memory, or the number of Spark executor instances.
The memory allocated by YARN is exceeded by the Spark executor’s physical memory. In such cases, to handle memory intensive operations, the memory of the Spark executor and the overhead together is not enough.
In the Spark executor instance, to handle operations like garbage collection, enough memory is not present.
Below are the ways in which Amazon Spark could be successfully configured and maintained on Amazon EMR.
Based on the needs of the application, the number of instances and type should be determined. There are three types of nodes in the Amazon EMR –
The master acts as the resource manager.
The Core nodes which are managed by the master that executes tasks and manages storage.
The Task which performs only tasks but no storage.
The right instance type should be chosen based on the application whether it is memory intensive or compute intensive. The R-type instances are preferred for the memory intensive applications while the C-Type instances are preferred for the compute-intensive applications. For each node types, the number of instances are decided after the type of the instance is decided. The number is dependent on the frequency requirements, the execution time of the application, and the input dataset size.
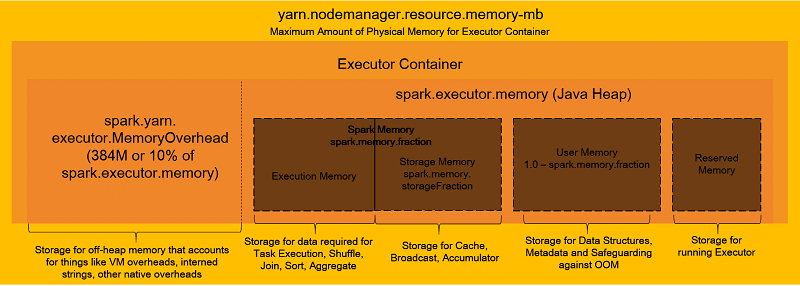
The Spark Configuration parameters need to be determined. Below is the diagram representing the executor container memory.
source: Amazon Web Services
There are multiple memory compartments in the executor container. However, for task execution, only one is used and for seamlessly running of the task, these need to be configured properly.
Based on the task and core instance types, the values for the Spark parameters are automatically set by the in spark-defaults. The maximize resource allocation is set to True to use all the resources in the cluster. Based on the workloads, the number of executors used could be dynamically scaled by Spark on YARN. In an application, to use the right number of executors, in most cases, the sub-properties are required which requires a lot of trial and error. These could often lead to the wastage of memory if the trial and error are not right.
Memory should be effectively cleared with the implementation of a proper garbage collector. In certain cases, out of memory error could occur due to the garbage collection especially when in the application, there are multiple RDDs. between the RDD cached memory and the task memory, when there is an interference, such instances might occur. Multiple garbage collectors could be used and in the memory, the new ones could be placed. However, the latency is overcome by the latest Garbage First Garbage Collector (G1GC).
The configuration parameters of YARN should be set. As the operating system bumps up the virtual memory aggressively, the virtual out of memory could still occur, even if all properties of Spark are configured correctly. The virtual memory and the physical memory check flag should be set to False to prevent such application failures.
Monitoring and Debugging should be performed. With the verbose option, the spark-submit should be run and the Spark configuration details could be known. To monitor Network I/O, the application progress, Spark UI and Ganglia could be used. A Spark application could process ten terabytes of data successfully if it is configured using 170 executor instances, 37GB memory, eight terabytes of RAM, five virtual CPUs, a twelve times large master and core nodes and 1700 equaled parallelism.
Conclusion
Apache Spark is being used by most industries these days and thus building a flawless application using Spark is a necessity which could help the business in their day to day activities.
Amazon EMR is one of the most popular cloud-based solutions to extract and analysis huge volumes of data from a variety of sources. On AWS, frameworks such as Apache Hadoop and Apache Spark could be run with the help of the Amazon EMR. This blog post covered various memory errors, the causes of the errors and how to prevent them when running Spark applications on Amazon EMR.
Dimensionless has several blogs and training to get started with Python, and Data Science in general.
Follow this link, if you are looking to learn more about data science online!
Additionally, if you are having an interest in learning AWS Big Data Course, LearnAWS Course Online
Furthermore, if you want to read more about data science, you can read our blogs here
Data has consumed our day to day lives. The amount of data that’s is available in the web or from other variety of sources is more than enough to get an idea about any entity. The past few years has seen exponential rise in the volume which has resulted into the adaptation of the term Big Data. Most of these generated data are unstructured and could up in any format. Previously computers were not equipped to understand such unstructured data but modern computers coupled with some programs are able to mind such data and extract relevant information from it which has certainly helped many business.
Machine Learning is the study of predictive analytics where the structured or unstructured data are analysed and new results are predicted after the model is trained to learn the patterns from historical data. There are several pre-programmed Machine Learning algorithms which helps in building the model and the choice of the algorithm to be used completely depends on the problem statement, the architecture and the relationship among the variables.
However, the traditional state-of-the-art Machine Learning algorithms like Support Vector Machines, Logistic Regression, Random Forest, etc., often lacks efficiency when the size of the data increases. This problem is resolved by the advent of Deep Learning which is a sub-field of Machine Learning. The idea behind Deep Learning is more or less akin to our brain. The neural networks in Deep Learning works almost similarly to the neurons in the human brain.
Deep Learning networks could be divided into Shallow Neural Networks and Deep L-Layered Neural Networks. In Shallow Neural Network, there is only one hidden layer along with the input and the output layers while in Deep L-Layered Neural Network there could be L number of small hidden layers along with the input and the output layers. On the contrary, computing some functions would require exponentially large shallow neural network and thus using a deep L-layered network is the best option in these scenarios. The choice of the activation function is Neural Network is an important step. In Binary classification problem, the sigmoid activation function is sufficient whereas in other problems, the Rectified Linear Unit activation function could be used. Some of the other important parameters in Deep Learning are Weights, Bias and hyper parameters such as the Learning rate, number of hidden layers, and so on.
To measure the performance of our Neural Network, one the best ways is to minimize the optimization function. For example – in Linear Regression, the optimization function is the Mean Squared Error and the lesser its value, the more accurate would be our model. In this blog post we would look into the optimization functions for Deep Learning.
Objective Functions in Deep Learning
To improve the performance of a Deep Learning model the goal is to the reduce the optimization function which could be divided based on the classification and the regression problems. Below are of some of objective functions used in Deep Learning.
1. Mean Absolute Error
In Regression problems, the intuition is to reduce the difference between the actual data points and the predicted regression line. Mean absolute error is one such function to do so which takes the mean of the absolute value of the difference between the actual and the predicted value for all the examples in the data set. The magnitude of errors are measured without the directions. Though it is a simple objective function but there is a lack of robustness and stability in this function. Also known as the L1 loss, its value ranges from 0 to infinity.
2. Mean Squared Error
Similar to the mean absolute error, instead of taking the absolute value, it squares the difference between the actual and the predicted data points. The squaring is done to highlight those points which are farther away from the regression line. Mean Squared Error is also known as the cost function in regression problems and the goal is to reduce the cost function to its global optimum in order to get the best fit line to the data.
This reduction in loss or the Gradient Descent is an incremental process where a value is initialized first and then the parameters are updated at each descent towards the global optimum. The speed of descent depends on the learning rate which needs to be adjusted as a very small value would lead to a slow step gradient descent while a larger value could fail to converge at all. Mean Squared Errors, however are sensitive to outliers. The range of values is always between 0 and infinity.
3. Huber
The penalty incurred by an estimation procedure f is described by the loss function Huber. For large values, the Huber function is linear while for small values, it is quadratic in nature. To make it quadratic, the magnitude by which the value needs to be small completely depends on the hyperparameter delta. This hyperparameter could be tuned as well.
Also known as the Smooth Mean Absolute Error, the sensitivity of Huber loss to outliers is less compared to the other functions. At zero, the Huber loss is differentiable. The Huber loss approaches Mean Absolute Error when the hyperparameter delta approaches to 0 and it approaches to the Mean Squared Error when the delta approaches to infinity. The value of delta would determine how much outlier you are willing to consider. L1 minimizes the residuals larger than delta while L2 minimizes the residuals smaller than delta.
4. Log-Cosh loss
A regression optimization function which is smoother than L2. The prediction error’s hyperbolic cosine’s logarithm is known as the log-cash loss function. For small value, it is equal to the half of its square while for large value, it equal to the difference between its absolute value of the logarithm of 2.
Log-cosh is not effected that much by occasional incorrect predictions and almost works similar to the mean squared error. Unlike Huber, it is twice differentiable. However, log-cosh often suffers from the Gradient problem.
5. Cosine Proximity
Between the predicted and the actual value, the cosine proximity is measured by this loss function which minimizes the dot product between them. There is maximal similarity between the unit vectors in this case if they are parallel which is represented by 0. However, in case of orthogonality, it is dissimilar represented by +1.
6. Poisson
The diversion of the predicted distribution from the expected distribution is measured by the Poisson loss function which is a Poisson distribution’s variant. For a normal approximation, the distribution is limited to a binomial as the probability becomes zero and trials becomes infinity. In Deep Learning, the Exponential Log Likelihood is similar to the Poisson.
7. Hinge
For training classifiers, the loss function which is used is known as the Hinge loss which follows the maximum-margin objective. The output of the predicted function in this case should be raw. The sign of the actual output data point and the predicted output would be same. The loss would be equal to zero when the predicted output is greater than 1. The loss increases linearly with the actual output data is the sign is not equal. In Support Vector Machines it is used mostly.
8. Cross Entropy
In Binary classification problem where the labels are either 0 or 1, the Cross Entropy loss function is used. The multiclass cross entropy however is used in case of multi-classification problem. Between two probability functions, the divergence is measured by the cross entropy function. Between two distributions, the difference would be large if the cross entropy is large but they are same when the difference is small. Cross entropy doesn’t suffer from the problem of slow divergence as seen in the mean squared error function due to the Sigmoid activation function.
The learning speed is fast when the difference is large and slow when the difference is small. Chances of reaching the global optimum is more in case of the cross entropy loss function because of its fast convergence.
9. Kullback-Leibler
The diversion of one probability distribution from a second expected probability distribution is measured by the Kullback-Leibler divergence also known as entropy, information divergence. Not considered as statistical measure of spread as it is a distribution wise asymmetric measure. Similarity is assumed when the value of Kullback-Leibler loss function is 0 while 1 indicates distributions behaving in a different manner.
10. Negative Logarithm Likelihood
Used widely in neural networks, the accuracy of a classifier is measured by the negative logarithm likelihood function. The idea of probabilistic confidence is followed by this function which outputs each class’s probability.
Conclusion
Deep Learning is one the growing fields in Data Science which thrives on more data. The concept of objective functions is crucial in Deep Learning as it needs to be optimized in order to get better prediction or a more efficient model.
Dimensionless has several blogs and training to get started with Python, and Data Science in general.




;" src="https://dimensionless.in/different-ways-to-manage-apache-spark-applications-on-amazon-emr/embed/#?secret=2IWRGZA97p" data-secret="2IWRGZA97p" width="600" height="338" title="“Different Ways to Manage Apache Spark Applications on Amazon EMR” — DIMENSIONLESS TECHNOLOGIES PVT.LTD." frameborder="0" marginwidth="0" marginheight="0" scrolling="no"></iframe>)

;" src="https://dimensionless.in/how-to-visualize-aws-cost-and-usage-data-using-amazon-athena-and-quicksight/embed/#?secret=xzwvqsYOvq" data-secret="xzwvqsYOvq" width="600" height="338" title="“How to Visualize AWS Cost and Usage Data Using Amazon Athena and QuickSight” — DIMENSIONLESS TECHNOLOGIES PVT.LTD." frameborder="0" marginwidth="0" marginheight="0" scrolling="no"></iframe>)
;" src="https://dimensionless.in/different-ways-to-manage-apache-spark-applications-on-amazon-emr/embed/#?secret=eGO8teI5AO" data-secret="eGO8teI5AO" width="600" height="338" title="“Different Ways to Manage Apache Spark Applications on Amazon EMR” — DIMENSIONLESS TECHNOLOGIES PVT.LTD." frameborder="0" marginwidth="0" marginheight="0" scrolling="no"></iframe>)

;" src="https://dimensionless.in/how-to-visualize-aws-cost-and-usage-data-using-amazon-athena-and-quicksight/embed/#?secret=xiGKHEcFlj" data-secret="xiGKHEcFlj" width="600" height="338" title="“How to Visualize AWS Cost and Usage Data Using Amazon Athena and QuickSight” — DIMENSIONLESS TECHNOLOGIES PVT.LTD." frameborder="0" marginwidth="0" marginheight="0" scrolling="no"></iframe>)