The advancement in the analytical eco-space has reached new heights in the recent past. The emergence of new tools and techniques has certainly made life easier for an analytics professional to play around with the data. Moreover, the massive amounts of data that’s getting generated from diverse sources need huge computational power and storage system for analysis.
Three of the most commonly used terms in analytics are Data mining, Machine Learning, and Data Science which is a combination of both. In this blog post, we would look into each of these three buzzwords along with examples.
Data Mining:
By term ‘mining’ we refer to extracting some object by digging. Similarly, that analogy could be applied to data where information could be extracted by digging into it. Data mining is one of the most used terms these days. Unlike previously, our life is circulated entirely by big data and we have the tools and techniques to handle such voluminous diverse meaningful data.
In the data, there are a lot of patterns which people could discover once the data has been gathered from relevant sources. The hidden patterns could be extracted to provide valuable insights by combining multiple sources of data even if it is junk. This entire process is known as Data mining.
Now the data used for mining could be enterprise data which are restricted and secured and has privacy issues. It could also be an integration of multiple sources which includes financial data, third-party data, etc. The more the data available to us, the better it is as we need to find patterns and insights in sequential and non-sequential data.
The steps involved in data mining are –
Data Collection – This is one of the most important steps in Data mining as getting the correct data is always a challenge in any organization. To find patterns in the data, we need to ensure that the source of the data is accurate and as much as possible data is gathered.
Data Cleaning – A lot of the times the data we get is not clean enough to draw insights from it. There could be missing values, outliers, NULL in the data which needs to be handled either by deletion or by imputation based on its significance to the business.
Data Analysis – Once the data is gathered, and cleaned the next step is to analyze the data which in short known as Exploratory Data Analysis. Several techniques and methodologies are applied in this step to derive relevant insights from the data.
Data Interpretation – Only analyzing the data is worthless unless it is interpreted through the form of graphs or charts to the stakeholders or the business who would make conclusions based on the analysis.
Data mining has several usages in the real world. For example, if we take the logs data for login in a web application, we would see that the data is messy containing information like timestamp, activities of the user, time spent on the website, etc. However, if we clean the data, and then analyze it, we would find some relevant information from it such as the user’s regular habit, the peak time for most of the activities, and so on. All this information could help to increase the efficiency of the system.
Another example of data mining is in crime prevention. Though data mining has most usage in education and healthcare, it is also used by agencies in the crime department to spot patterns in the data. This data would consist of information about some of the criminal activities that have taken place. Hence, mining, and gathering information from the data would help the agencies to predict future crime events and prevent it from occurring. The agencies could mine the data and find out the place where the next crime could take place. They could also prevent cross-border calamity by understanding which vehicle to check, the age of the occupants, etc.
However, a few of the important points one should remember about Data Mining –
Data mining should not be considered as the first solution to any analysis task if other accurate solutions are applicable. It should be used when such solutions fail to provide value.
Sufficient amount of data should be present to draw insights from it.
The problem should be understood to be a Regression or a Classification one.
Machine Learning:
Previously, we learned about Data mining which is about gathering, cleaning, analyzing, and interpreting relevant insights from the data for the business to draw conclusions from it.
If Data mining is about describing a set of events, Machine Learning is about predicting the future events. It is the term coined to define a system which learns from past data to generalize and predict the future events from the unknown set of data.
Machine Learning could be divided into three categories –
Supervised Learning – In supervised learning, the target is labeled i.e., for every corresponding row there is an output value.
Unsupervised Learning – The data set is unlabelled in unsupervised learning i.e., one has to cluster the data into various groups based on the similarities in the pattern of the data points.
Reinforcement Learning – It is a special category of Machine Learning which is mostly used in self-driving cars. In reinforcement learning, the learner is rewarded for every correct move, and penalized for any incorrect move.
The field of Machine Learning is vast, and it requires a blend of statistics, programming, and most importantly data intuition to master it. Supervised and unsupervised learning are used to solve regression, classification, and clustering problems.
In regression problems, the target is numeric i.e., continuous or discrete in nature. A continuous value could be an integer, float, or a decimal, whereas a discrete value is a number or an integer.
In classification problems, the target is categorical i.e., binary, multinomial, or ordinal in nature.
In clustering problems, the dataset is grouped into different clusters based on the similar properties among the data in a particular group.
Machine Learning has a vast usage in various fields such as Banking, Insurance, Healthcare, Manufacturing, Oil and Gas, and so on. Professionals from various disciplines feel the need to predict future outcomes in order to work efficiently and prepare for the best by taking appropriate actions. Some of the real-life examples where Machine Learning has found its usage is –
Email Spam filtering – This is the first application of Machine Learning where an email is classified as ‘Spam’ or ‘Not Spam’ based on certain keywords in the mail. It is a binary classification supervised learning problem where the system is initially trained with a set of sample emails to learn the patterns which would help in filtering out irrelevant emails. Once the system has generalized well, it is passed through a validation set to check for its efficiency, and then through a test set to find its accuracy.
Credit Risk Analytics – Machine Learning has vast influence in the Banking, and Insurance domain with one of its usage being in predicting the delinquency of a loan by a borrower. Defaulting a credit loan is a prevalent issue in which the lender or the bank has lost millions by failing to identify the possibility of a borrower not repaying back the loans or meeting the contractual agreements. However, Machine Learning has been introduced by various banks which takes into several features of a borrower and builds a predictive model which helps in mitigating the risk involved in giving credit card loans to them.
Product Recommendations – Flipkart, and Amazon are of the two biggest e-commerce industry in the world where millions of users shop every day the products of their choice. However, there is a recommendation algorithm that works behind the scenes which simplify the life of the customer by displaying them the products they make like based on their previous shopping or search patterns. This is an example of unsupervised learning where a customer is grouped based on their shopping patterns.
Data Science:
So far, we have learned about the two most common and important terms in Analytics i.e., Data mining and Machine Learning.
If Data mining deals with understanding and finding hidden insights in the data, then Machine Learning is about taking the cleaned data and predicting future outcomes. All of these together form the core of Data Science.
Data Science is a holistic study which involves both Descriptive and Predictive Analytics. A Data Scientist needs to understand and perform exploratory analysis as well as employ tools, and techniques to make predictions from the data.
A Data Scientist role is a mixture of the work done by a Data Analyst, a Machine Learning Engineer, a Deep Learning Engineer, or an AI researcher. Apart from that, a Data Scientist might also be required to build data pipelines which is the work of a Data Engineer. The skill set of a Data Scientist consists of Mathematics, Statistics, Programming, Machine Learning, Big Data, and communication.
Some of the applications of Data Science in the modern world are –
Virtual assistant – Amazon’s Alexa, and Apple’s Siri are two of the biggest achievements in the recent past where AI has been used to build human-like intelligent systems. A virtual assistant could perform most of the tasks that a human being could with proper instructions.
ChatBot – Another common usage of Data Science is the ChatBot development which is now being integrated into almost every corporation. A technique called Natural Language Processing is in the core of ChatBot development.
Identifying cancer cells – Deep Learning has made tremendous progress in the healthcare sector where it is used to identify the pattern in the cells to predict whether it is cancerous or not. Deep Learning uses neural networks which functions like the human brain.
Conclusion
Data mining, Machine Learning, and Data Science is a broad field and it would require quite a few things to learn to master all these skills.
Dimensionless has several resources to get started with.
Machine Learning is the latest buzzword in the analytical eco-space. The idea was there before as well but its usage has largely increased in recent times due to the enormous amounts of data that is available and the huge computational capacity of the modern systems.
Machine Learnings is the study of identifying patterns in the data by the system to make predictions on the new set of data. Several algorithms are programmed for this purpose and only the correct usage of such methods based on the problem statement in hand would lead to an accurate prediction.
The study of Machine Learning is divided into Supervised, Unsupervised, and Reinforcement learning. In Supervised learning, the output is labeled whereas unsupervised learning deals with an unlabeled dataset. In the case of Reinforcement learning, the learner is rewarded with prizes when made a correct decision and penalized for any incorrect move.
There are several algorithms used to make predictions. Some of them Linear, and Logistic Regression, Tree-Based algorithms like Decision Tree, Random Forest, Ensemble methods like Gradient Boost, XGBoost, and so on. Apart from these basic algorithms, there is a branch of Machine Learning which works on the concept of neural networks called Deep Learning.
Deep Learning is the advanced form of Machine Learning which requires more data and higher computational capacity. Some of the frameworks of Deep Learning are TensorFlow, Keras, Theano, PyTorch, etc.
Machine Learning is used by professionals of several fields like Banking, Insurance, Healthcare, and Manufacturing, to make predictions pertaining to several use cases in their respective fields. In this blog post, we would delve one of the use cases in the Transactional analytics field where Machine Learning has made several ground-breaking achievements.
What is Meant by Transactional Analytics?
The application performance, the outcome of the business, and the users are connected real-time through a mechanism known as Transactional Analytics. The real-time data gives insights on the customer experience, business outcomes after it is collected and correlated.
Transactional Analytics could be used to answer several questions about the performance of the business, and the KPI’s in real time. A correlation between the business and the performance data would ensure business growth, and the automated data gathering would provide time to value.
Moreover, the application performance could be optimized if the hundred percent of the business transaction is automatically collected, and correlated. Details of every business transactions of the application need to be captured, and its performance needs to be analyzed. The relationship between the data about a particular application should be auto-correlated to optimize the performance of that application.
How Transactional Analytics has helped in the growth of the business?
The rapid rise in the usage of the internet has resulted in the generation of unprecedented amounts of data. The sources of the data are endless and modern tools and technologies are equipped to handle large volumes of unstructured data as well which often carries more insights than structured data. Any organization could leverage the massive potential of big data to achieve real-time insights which would lead to the growth of the business.
Usage of Machine Learning for Transactional Analytics
Machine Learning has been implemented in several transactional systems to ease the process of the operation. Starting from Fraud detection systems to analyzing real-time high volume user information to drive riveting customer experiences, Machine learning has helped businesses to flourish. Here, we would look into one such use case where Machine Learning is implemented in Transactional Analytics.
The life Value of Customer Against its Acquisition Cost
The understanding of the transactional behavior of a customer is one of the key criteria for the growth of any business. In today’s world, there is no shortage of offers for customers for acquisition, and retention due to the large of small-scale companies that are emerging gradually. The behavioral analysis of a customer had become complex in recent times due to the enormous amounts of data and the arrival of several new business houses. However, modern technologies and tools do possess the power to leverage such terabytes of data to ensure customer satisfaction.
Collecting different sorts of data like operation cost, revenue growth, etc. could the profit trends of the customer, but it would not answer questions like the amount of money a business needs to spend to acquire a new customer or the true present value of a new customer.
To simplify the understanding, to understand new customer value, his cash flow patterns, and the customer’s longevity with the business need to be known. Suppose, a customer generates twenty-six dollars in two years, and two hundred sixty-four dollars in five years, then in ten years, his net worth would be seven hundred and sixty dollars.
Thus spending such huge amount of money at the start for a customer who would stay for ten years is not wise as the profit might vary in the future. On such scenarios, discount computing could be used which would cut the value from seven hundred and sixty dollars to three hundred and four dollars at fifteen percent discount rate. This amount is viable as the company could pay three hundred and four dollars for a customer who would stay for ten years on acquisition costs.
Once the amount is calculated, the next hurdle is to find the longevity of the customer in the company. The answer to these questions lies within the retention rates which is dependent upon age, gender, and so on. The best way to calculate the average stay of a customer is to get the count of the number of customers who would defect to find the defection rate and then invert the fraction.
The customer lifetime calculation leads to the question of customer cash flow. Assuming that the defection rate is constant which never happens in real life as the rate is generally much higher in the initial years and decreases gradually. On top of this assumption, we need to calculate the classes of the customer at different cycles instead of individual customer value one by one as companies invest in a set of customers during acquisition.
Imagine a scenario where one lakh new customers enter at a particular time, and the company invests eighty dollars at that particular time which would take the amount to eight million dollars for the entirely new group of customers. Now, after a year, say twenty-two percent of the customer’s defects and leaves behind the remaining seventy-eight percent to pay back the eight million dollars invested initially. After five years, if more than half of the customers joined defects, then the cash flow till of the time of defect is estimated.
Previously, we set three hundred and four dollars as customer value. Now, if the defection rate continues to be at ten percent, then it would be dangerous to decide the money invested as at this rate the number would reduce to hundred and seventy-two dollars from three hundred and four dollars.
The scope of Machine learning is quite feasible in this regard. So far, we tried to find the longevity of the customer and its lifetime value which got decreased from $ 760 to $172. Still, it contains some distinct human behaviors which need to be taken into the account. The marketing campaign based on machine learning to target a customer could also allow calculating every unique customer’s lifetime value.
It could also be added that various dependent variables make it difficult to get the correct accounting number as more and more transactional data is generated. There are various factors which influence the transactional behavior of customers, and using machine learning model would create a probabilistic metric which could help the business to make economic predictions going forward.
Conclusion
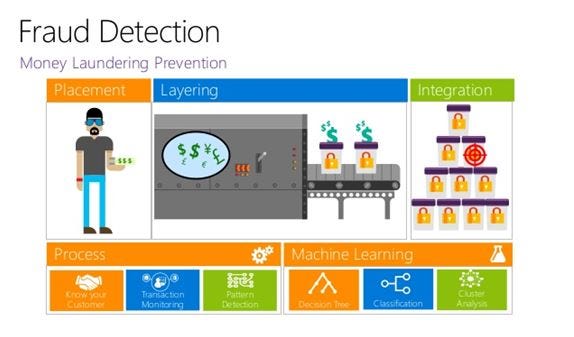
This was one of the use cases where Machine Learning plays a major role in improving the transactional business. One of the other usages of Machine Learning in Transactional Analytics is in Fraud Detection.
In this case, the system could understand patterns from the customer’s purchased data and predict the fraud in the new set of transactions based on the concept of cognitive computing. Machine Learning ensures the confidence level is high while deciding on a transaction. It also allows the evaluation of multiple transactions in real time.
With an increased number of transactions, the models tend to perform better. It maintains efficiency and often acts better than humans in dealing with fraudulent behaviors.
The fraud detection process starts with gathering the relevant data and perform exploratory data analysis on the data to get rid of noise from the data. It is then divided into training, testing, and validation data sets. Once the data set is ready, it is then fed to several classification algorithms like Logistic Regression, Decision Tree, Random Forest, and even neural networks which are fast and more efficient than conventional Machine Learning algorithms.
However, there are few drawbacks in Fraud Detection using Machine Learning such as Lack of inspectability, the possibility of overlooking some obvious activities like card sharing.
Machine Learning has a wide range of usage in the Transactional analytics and in this article we have seen a couple of such use cases. Dimensionless has several blogs and training to get started with Machine Learning and Data Science in general.
Follow this link, if you are looking to learn more about data science online!
Artificial Intelligence and Machine Learning have empowered our lives to a large extent. The number of advancements made in this space has revolutionized our society and continue making society a better place to live in.
In terms of perception, both Artificial Intelligence and Machine Learning are often used in the same context which leads to confusion. AI is the concept in which machine makes smart decisions whereas Machine Learning is a sub-field of AI which makes decisions while learning patterns from the input data.
In this blog, we would dissect each term and understand how Artificial Intelligence and Machine Learning are related to each other.
What is Artificial Intelligence?
The term Artificial Intelligence was recognized first in the year 1956 by John Mccarthy in an AI conference.
In layman terms, Artificial Intelligence is about creating intelligent machines which could perform human-like actions. AI is not a modern-day phenomenon. In fact, it has been around since the advent of computers. The only thing that has changed is how we perceive AI and define its applications in the present world.
The exponential growth of AI in the last decade or so has affected every sphere of our lives. Starting from a simple google search which gives the best results of a query to the creation of Siri or Alexa, one of the significant breakthroughs of the 21st century is Artificial Intelligence.
The Four types of Artificial Intelligence are:-
Reactive AI – This type of AI lacks historical data to perform actions, and completely reacts to a certain action taken at the moment. It works on the principle of Deep Reinforcement learning where a prize is awarded for any successful action and penalized vice versa. Google’s AlphaGo defeated experts in Go using this approach.
Limited Memory – In the case of the limited memory, the past data is kept on adding to the memory. For example, in the case of selecting the best restaurant, the past locations would be taken into account and would be suggested accordingly.
Theory of Mind – Such type of AI is yet to be built as it involves dealing with human emotions, and psychology. Face and gesture detection comes close but nothing advanced enough to understand human emotions.
Self-Aware – This is the future advancement of AI which could configure self-representations. The machines could be conscious, and super-intelligent.
Two of the most common usage of AI is in the field of Computer Vision, and Natural Language Processing.
Computer Vision is the study of identifying objects such as Face Recognition, Real-time object detection, and so on. Detection of such movements could go a long way in analyzing the sentiments conveyed by a human being.
Natural Language Processing, on the other hand, deals with textual data to extract insights or sentiments from it. From ChatBot Development to Speech Recognition like Amazon’s Alexa or Apple’s Siri all uses Natural Language to extract relevant meaning from the data. It is one of the widely popular fields of AI which has found its usefulness in every organization.
One other application of AI which has gained popularity in recent times is the self-driving cars. It uses reinforcement learning technique to learn its best moves and identify the restrictions or blockage in front of the road. Many automobile companies are gradually adopting the concept of self-driving cars.
What is Machine Learning?
Machine Learning is a state-of-the-art subset of Artificial Intelligence which let machines learn from past data, and make accurate predictions.
Machine Learning has been around for decades, and the first ML application that got popular was the Email Spam Filter Classification. The system is trained with a set of emails labeled as ‘spam’ and ‘not spam’ known as the training instance. Then a new set of unknown emails is fed to the trained system which then categorizes it as ‘spam’ or ‘not spam.’
All these predictions are made by a certain group of Regression, and Classification algorithms like – Linear Regression, Logistic Regression, Decision Tree, Random Forest, XGBoost, and so on. The usability of these algorithms varies based on the problem statement and the data set in operation.
Along with these basic algorithms, a sub-field of Machine Learning which has gained immense popularity in recent times is Deep Learning. However, Deep Learning requires enormous computational power and works best with a massive amount of data. It uses neural networks whose architecture is similar to the human brain.
Machine Learning could be subdivided into three categories –
Supervised Learning – In supervised learning problems, both the input feature and the corresponding target variable is present in the dataset.
Unsupervised Learning – The dataset is not labeled in an unsupervised learning problem i.e., only the input features are present, but not the target variable. The algorithms need to find out the separate clusters in the dataset based on certain patterns.
Reinforcement Learning – In this type of problems, the learner is rewarded with a prize for every correct move, and penalized for every incorrect move.
The application of Machine Learning is diversified in various domains like Banking, Healthcare, Retail, etc.
One of the use cases in the banking industry is predicting the probability of credit loan default by a borrower given its past transactions, credit history, debt ratio, annual income, and so on. In Healthcare, Machine Learning is often been used to predict patient’s stay in the hospital, the likelihood of occurrence of a disease, identifying abnormal patterns in the cell, etc.
Many software companies have incorporated Machine Learning in their workflow to steadfast the process of testing. Various manual, repetitive tasks are being replaced by machine learning models.
Comparison Between AI and Machine Learning
Machine Learning is the subset of Artificial Intelligence which has taken the advancement in AI to a whole new level. The thought behind letting the computer learn from themselves and voluminous data that are getting generated from various sources in the present world has led to the emergence of Machine Learning.
In Machine Learning, the concept of neural networks plays a significant role in allowing the system to learn from themselves as well as maintaining its speed, and accuracy. The group of neural nets lets a model rectifying its prior decision and make a more accurate prediction next time.
Artificial Intelligence is about acquiring knowledge and applying them to ensure success instead of accuracy. It makes the computer intelligent to make smart decisions on its own akin to the decisions made by a human being. The more complex the problem is, the better it is for AI to solve the complexity.
On the other hand, Machine Learning is mostly about acquiring knowledge and maintaining better accuracy instead of success. The primary aim is to learn from the data to automate specific tasks.
The possibilities around Machine Learning and Neural Networks are endless. A set of sentiments could be understood from raw text. A machine learning application could also listen to music, and even play a piece of appropriate music based on a person’s mood. NLP, a field of AI which has made some ground-breaking innovations in recent years uses Machine Learning to understand the nuances in natural language and learn to respond accordingly.
Different sectors like banking, healthcare, manufacturing, etc., are reaping the benefits of Artificial Intelligence, particularly Machine Learning. Several tedious tasks are getting automated through ML which saves both time and money.
Machine Learning has been sold these days consistently by marketers even before it has reached its full potential. AI could be seen as something of the old by the marketers who believe Machine Learning is the Holy Grail in the field of analytics.
The future is not far when we would see human-like AI. The rapid advancement in technology has taken us closer than ever before to inevitability. The recent progress in the working AI is much down to how Machine Learning operates.
Both Artificial Intelligence and Machine Learning has its own business applications and its usage is completely dependent on the requirements of an organization. AI is an age-old concept with Machine Learning picking up the pace in recent times. Companies like TCS, Infosys are yet to unleash the full potential of Machine Learning and trying to incorporate ML in their applications to keep pace with the rapidly growing Analytics space.
Conclusion
The hype around Artificial Intelligence and Machine Learning are such that various companies and even individuals want to master the skills without even knowing the difference between the two. Often both the terms are misused in the same context.
To master Machine Learning, one needs to have a natural intuition about the data, ask the right questions, and find out the correct algorithms to use to build a model. It often doesn’t requiem how computational capacity.
On the other hand, AI is about building intelligent systems which require advanced tools and techniques and often used in big companies like Google, Facebook, etc.
There is a whole host of resources to master Machine Learning and AI. The Data Science blogs of Dimensionless is a good place to start with.