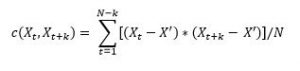Around the world, India is well known for ‘IT’. 1.3 million students graduate in Engineering of which a large percentage have a degree in computer science. Now marry this fact with the large scale research and democratization of AI. What you have is a nation with immense youth equipped with the skills to tackle the problems of tomorrow. In this article, we talk about AI in India from three different corners
Academia
Government
Startups
Academia
According to various sources, India ranks third in the number of papers published in the field of AI. But when the number of citations, meaning the number of times a research paper is being referred, India ranks fifth. Meaning the quality of research in AI in India has to be improved. NITI Aayog, a government think tank estimates that AI, if integrated successfully into operations can add benefits worth $1 trillion to the economy.
In addition, Prime Minister Narendra Modi also opened India’s first AI research institute in Mumbai – Wadhwani AI. The institute will focus on researching ways to harness the power of AI to solve deep-rooted problems in healthcare, education, agriculture, and infrastructure to accelerate social development. Founded by Indian-American tech entrepreneurs Dr Romesh Wadhwani and Mr Sunil Wadhwani, the institute will be led by AI pioneer and founding MD of Microsoft Research India, Dr P. Anandan.
Apart from research, in terms of education, there have been a number of programs launched by private and government institutes. Recently, IIT Hyderabad launched its first bachelor’s program in AI. It will commence from the year 2019 and has 20 seats for its first batch. The B.Tech. in Artificial Intelligence course will include the study of algorithms, signal processing, robotics and mathematical foundations. It will also focus on application verticals such as healthcare, agriculture, smart mobility, and more. IIT Hyderabad notes that the ethical impact of AI and related technologies on areas such as privacy, bias, and related issues will also be taught to the students.
IIT Kharagpur, IIM Calcutta and ISI Kolkata have collaboratively launched Post Graduate Diploma in Business Analytics (PGDBA). It is a full time 2-year residential program aimed at imparting advanced analytics training. IIM Bangalore has its own Business Analytics and Intelligence program which spans over 9 months. IISc Bangalore offers a Masters degree in Computational and Data Science
Startups
Indian AI startups raised about $87 million in 2017. In 2018, Indian startups with operations in India and worldwide raised USD$ 529.52 million. All the high-growth companies that attracted big ticket funding had AI as a core product or are applying AI, ML technologies to verticals like healthcare, finance, supply chain and energy.
There is no well defined AI market in India yet. AI finds its niche in almost every market. For example, a startup niki.ai provides chatbot service to automate tasks like handling orders and payments. Niki.ai has raised funding from eminent investors such as Ratan Tata and Unilazer Ventures and reports 35% month to month growth in revenues.Rivigo, a Gurgaon based AI enabled logistic services offers pan-India delivery services to e-commerce, pharma, automobiles, cold-chain and FMCG players.
Sigtuple, a Bangalore based Healthcare startups founded by former American Express executives, Raised over $6.5 million dollars from IDG, Pi ventures, Accel partners etc. They are helping hospitals and healthcare centres improve the speed and accuracy of blood reports. In finance space, Active.ai, a Bangalore based firm founded by former bankers, has raised over $3.5 million from Kalaari and IDG Ventures. It is an intelligent interface that allows banks and consumers to connect over chat. Artivatic Data Labs empowers an enterprise through its AI Enterprise Tech Platform to take efficient human-like decisions on behalf of the businesses. It helps to integrate intelligent solutions and products without any external effort or human intervention. Built on neuroscience capabilities, genomic science, and psychology.
Government
NITI Aayog released a discussion paper on AI strategy in India. According to its discussion, the government of India will focus on implementing AI solutions in 5 key areas.
Healthcare – to increase affordability and quality of healthcare services provided to the citizens.
Agriculture – Increase farmers productivity and reduce wastage.
Education – Improved access to quality education
Smart Cities and Infrastructure: efficient and connectivity for the burgeoning urban population
Smart Mobility and Transportation: smarter and safer modes of transportation and better traffic and congestion problems
NITI Aayog chief Amitabh Kant says,”The paper gives many disruptive suggestion including one to utilize market place models for data, annotation, and deployable solutions in AI. We need to democratise access to and development of this technology”
The paper also proposed a two-tiered structure to address India’s AI research aspirations:
Centre of Research Excellence (CORE) focused on developing a better understanding of existing core research and pushing technology frontiers through creation of new knowledge
International Centers of Transformational AI (ICTAI) with a mandate of developing and deploying application-based research. Private sector collaboration is envisioned to be a key aspect of ICTAIs.
Recently, a startup named One Fourth Labs, started by two IIT Madras professors Mitesh Khapra and Pratyush Kumar have started a four month course on deep learning that focuses on solving India specific problems. Their course can be taken by students as well as professionals. Students have to pay 1180 INR and professionals, 5900 INR. The course commences from 1st Feb.
Conclusion
From multiple perspectives, AI in India is being promoted. But what’s concerning is how well we do in comparison to other nations in this so-called fourth Industrial Revolution. There are hundreds of issues lying around in our countries for years. Can technology be answers to these questions?
More than 90 per cent of total data was generated in the last two years. Of this, text data has a large chunk. Just think about how much you type each day. Ironically, I was thinking about it while writing this blog. And more than chunks of characters, there is information hidden in the text which can be extremely insightful if harnessed well. Consequently, data scientists started using this data for countless applications. Thus was born the field of text mining or text analytics. In this blog, we discuss 5 applications of text analytics.
Document retrieval
Suppose you have a cluster of documents (news articles for example). A single document can have information about many topics. For example, an article talking about a legal investigation of a pharmaceutical company will have contents related to topics like Government, Politics, Medicine, etc. What if we want to retrieve articles from this cluster of documents that talk about particular topics. Imagine a customer service centre where you have a team of individuals emailing to customer queries with relevant articles. If the queries by the customers can be clustered according to the type of problem, every query in a single clustered can be answered by sending them a single article. The entire process can largely be automated.
Methods like topic modelling help you do this. The number of topics or ‘the clusters’ is decided by us. The model works by associating words and documents with these topics. Basically, they calculate the probability of the words and documents belonging to a particular topic. For a detailed explanation, you can view the following blog that explains topic modelling using an algorithm named PLSA (Probabilistic Latent Semantic Analysis) along with implementation-
No one has ever enjoyed reading advertisements. And what could be worse than having them beep in your email inboxes? This is where spam filtering saves you. It helps keep the prince of Nigeria asking for money at bay. So how do we do it in reality? Consider you have large amounts of data labelled spam or not spam. And you have the text content in those emails. What follows is looking at words that are frequent in a spam email. The probability that the email is spam given those words in the email text is very high. These probabilities are calculated using an algorithm known as Naive Bayes.
The metric here is optimizing false positives (spams) without sacrificing important non-spam emails. This algorithm is very simple in its implementation yet extremely effective and has been in use since 1990s.
Sentiment Analysis
Everyone has heard of the recent scandal by a company named Cambridge Analytica. Allegedly, it illegally used Facebook data of millions of American users to hamper the content they consumed in order to change their political opinion. Christopher Wylie, the whistleblower has explained how the firm used the Facebook data to understand the opinions or, the sentiment of the masses and then created microtargeted content to psychologically change the perception of people. Although this is completely unethical, we can see how powerful analytics can be.
Sentiment analysis is basically understanding the emotional component behind peoples opinion. People express their opinion in many ways, one of them being in the form of posts, comments. Essentially, in the form of text. Consider a product on Amazon with 1000s of reviews. Reading each one of these reviews is manually impossible. We want an algorithm to help us understand the sentiment of these reviews as to know if the product is doing well or not. This is where sentiment analysis comes into picture.
Although this is an amazing method, it has some limitations. Human language is complex. Consider the following sentences –
I want that burger so bad
I ate the burger. It was bad
It is highly likely that an algorithm would label both of them as negative sentiment because of the word bad. But we know that the first one is, in fact, an extremely positive review.
Human Resources
With hundreds of job portals, a job gets numerous applications. It becomes difficult for recruiters and human resource professionals to manually screen each resume and select a few. There are startups that provide software as services to make recruiters life easier. These softwares can scan the resume, look out for desired skills in the form of keywords and shortlist relevant and good candidates from the pile.
Chatbots
This is a no brainer, isn’t it? Chatbots are revolutionizing the way information is consumed. Almost every website has started deploying its own chatbot. And why not! It saves you a ton of time. Websites can have a lot of information. Sometimes, it can be hard to find the particular piece you are looking for. A well-trained chatbot can answer your questions in a jiffy. This can not only save the visitor time but also company lot of money it would have spent otherwise on installing customer call services.
Chatbot can be built in many simple to complex ways. But an important part of it is information retrieval by scrapping the website and structuring an answer.
In addition, you might have observed the word prediction Google or any other keyboard does. Google learns the pattern of your typing, the common phrases you use and then predicts those the nest time it feels that you might need it. This is called language modelling.
I hope you get the idea of how text can be used in Data Science. Now that you have some high-level idea of it, you shouldn’t wait to get started and get your hands dirty.
To get started with text check out the following blogs –
After months of hard work and an infinite number of import pandas as pd, you finally have acquired the skills to get started in this field. But the next big question is – which company to apply to? The number of analytics and AI startups and companies have grown exponentially. In addition, there are so many things you can do in analytics and data science – Marketing analytics, Supply chain, Finance, so on and so forth.
We have prepared a concise summary of companies you can apply to for your first stint in Data Science. Hope you find it helpful!
Sigmoid is an analytics company providing services in Strategy development, Data Consulting and implementation, Predictive Analytics and Data Engineering. Founded in 2013 by IIT Kharagpur alumni Mayur Rustagi, Rahul Kumar Singh and Lokesh Anand, Sigmoid provides analytics solutions across multiple domains like Marketing, Retail, Advertising and Gaming. Essentially, they aspire to be the best Big Data company. They provide a platform for real-time data processing on top of Apache Spark. Company’s employee strength is estimated to be 80-100. Right from the beginning, Sigmoid has been a global company with offices in San Francisco and Bengaluru.
Fractal Analytics was founded in the year 2000 by Srikanth Velamakanni, Pranay Agrawal, Nirmal Palaparthi, Pradeep Suryanarayan and Ramakrishna Reddy in the US. In 2015 they opened an office in Bengaluru. They are now one of the largest analytics service provider in India. It mainly focuses on AI and Machine Learning based solutions. Cuddle.ai an AI-powered voice-enabled platform for business analysis that helps users analyze data seamlessly, is incubated by Fractal. Another startup funded by Fractal called qure.ai aims at making healthcare faster and more affordable. Using deep learning, it helps the doctor diagnose disease from radiology and pathology imaging.
LatentView is a global analytics firm founded in the year 2006. It provides solutions using Machine Learning across areas like Marketing Analytics, Business Analytics, Risk and Compliance analytics and Supply Chain Analytics. They work for many high profile clients like PayPal, Microsoft, Pepsico, Expedia and in total more than two dozens of Fortune 500 companies. They have been listed in Gartner’s market guide for advanced analytics and service provider for the year 2017 and have been recognized as the ‘Company of the year’ by Frost and Sullivan in the year 2015 and 2017.
ZS Associates is quite an old firm, founded in 1983, headquartered in the United States. It provides solutions to its clients in areas like business planning, marketing, strategy, transformation and many others across industries like Pharmaceuticals, Energy, Travel, Media, etc. Recently, ZS Associates opened its third India office and 23rd global office in Bangalore.
“Our plan to inaugurate a new office in Bangalore is about strengthening our capabilities in big data and artificial intelligence in India and beyond. This will continue to deepen our partnership with clients around the globe in helping them navigate their digital transformation journey.”, Sanjay Joshi, ZS’s managing principal for Asia region.
Founded in the year 2012 Lymbyc (previously known as Ma Foi Analytics) is a predictive analytics solutions provider, has developed a first of its kind virtual analyst platform which helps other companies with data analysis and assists with useful business insights. The virtual analyst product named ‘Lymbyc’ is driven by an adaptive machine learning engine which crunches data and processes insights quickly. It is currently headquartered in Bengaluru and has an employee strength of 51-200 employees.
CropIn technology, founded in the year 2010, aims at developing smart solutions for agribusinesses. Its vision is to maximize value per hectare and make every farm traceable. It uses IoT, remote sensing, AI and machine learning to enable its clients to analyze and interpret data to derive insights and plan their crop production. It has digitized over 3.1 million acres of farm till date.
Product portfolio –
CropIn’s product suite enables data-driven farming by connecting all the stakeholders in the Ag-ecosystem. The product portfolio includes 1. SmartRisk: A predictive and prescriptive business intelligence solution that leverages agri-alternate data for effective credit risk assessment and loan recovery assistance 2. SmartFarm: An award-winning, robust farm management solution that drives digital strategy and provides complete visibility of resources, processes and performance on the field 3. mWarehouse: A comprehensive pack house solution that enables farm-to-fork traceability, and compliance 4. SmartSales: A CRM and input channel management solution to forecast and improve sales 5. AcreSquare: A unique farmer application that helps companies interact directly with their farmers, share content, educate them and provide consultation
Currently, the company’s employee size is around 100-150 and is headquartered in Bengaluru.
Founded in 2013, Quantiphi is headquartered in the United States and has an office in Mumbai. Apart from delivering advanced analytics solutions in Healthcare, Insurance and CPG, Quantiphi also works extensively in Analytics for Media. This included viewership analytics, content feature analysis which revolves around decoding hidden features of video content like emotions, characters and location. AthenasOwl, Quantiphi’s media analytics solution that delivers high definition content meta tags, at scale. Current employee size is more than 500.
Founded in 2004, Mu Sigma claims to be world’s largest pure-play in Big Data Analytics with a unicorn status (meaning, a privately held company valued over $1 billion) in the US and the only profitable unicorn in India. They work with more than 140 Fortune 500 and have 3500+ decision scientist worldwide. It is headquartered in the United States and has an office at Bengaluru in India. It was ranked 907 on the 2012 Inc. 5000 list of America’s fastest growing companies.
Founded in 2009, Cartesian consulting is a global analytics firm that specializes in customer, marketing and business analytics. They work across multiple industries like Retail, Finance, eCommerce and many more. Their solutions include Solus, which is a hyper-personalized marketing intelligence system and Kyte, which helps boost the open rate of emails by using AI to craft better subject lines.
Cartesian’s employee size is around 200 and is headquartered in Mumbai.
Founded in 2012, they provide technology-enabled analytics solutions in marketing & sales effectiveness. We integrate technology, industry knowledge and cutting-edge statistical techniques to deliver “fast, cost-efficient and actionable business insights. Their team is filled with individuals having expertise in a plethora of industries like Automobile, Consumer Goods, Pharmaceuticals, Retail and many more. Their analytics solution suite includes Marketing Analytics, Customer Analytics, Sales Analytics, etc. They also provide analytics training to institutions.
Among multiple areas like customer analytics, finance, marketing, AI has shown a great promise in the healthcare domain. There has been increasing support towards using AI by both, the industry and the academia. In the following blog, we discuss 4 areas in which AI has helped the healthcare industry. As a bonus, for all the techies who like to get their hands dirty, we have included a practical tutorial for you to build your own malaria detection algorithm.
Virtual Assistants
Healthcare industry is massively investing in intelligent systems in order to make their services more efficient. One such way is by developing Medical Virtual Assistants. The assistants, supported by AI enable smooth and quick interaction not only with patients about frequently asked questions but also with doctors who might want to retrieve medical information or the history of a patient. According to a study, 49% of a physician’s time is spent doing administrative work. Something that can be largely automated using IT.
Using Machine Learning and Natural Language Processing techniques, it becomes extremely convenient to navigate through medical databases in order to get the desired information. In addition, these assistants are able to deliver personalized notes to a patient by analyzing their medical information and history. It is estimated that the virtual assistant market will reach $15.8 B in 2021 from $1.6B in 2015. Nuance, a company founded in 1992 claims that its virtual assistant is helping doctors serve patients better automating a doctor’s schedule for the day, patient’s problems, his/her summary and much more.
CT Scans
Repetitive tasks like analyzing X Rays and CT scans can and have been made easier and less time consuming by AI. A 2016 startup qure.ai claims to be making an interpretable deep learning algorithm to analyze X Rays. According to them, head CT scans are the first line diagnostic modality for patients with head injury or stroke. One of their products, qER is designed for triage or diagnostic assistance in this setting. The most critical scans are prioritized on the radiology worklist so that they can be reviewed first.
Radiology
Radiology, another field in healthcare has been shown to benifit immensly from AI. Doctors and AI engineers found that technologies like Deep Learning can help radiologists in multiple ways. Application of deep learning like autoencoders can help improve the image quality by ‘repairing’ the pixels. It can also help detect lesions (a region in an organ or tissue which has suffered damage through injury or disease, such as a wound, ulcer, abscess, or tumour) that may be subtle. This can be useful when the radiologist is tired or exhausted, which is very often the case. Although there have been arguments that AI algorithms will eventually surpass human accuracy, experts say that in fact the opposite would occur. These intelligent applications will help humans gain a deeper and better understanding of the process.
Drug Design
AI has shown immense potential to help pharmaceutical industries, especially in their Research and Development process, particularly in the areas like predicting treatment results, drug design and data preprocessing. On the research side, algorithms like Convolutional Neural Networks have levelled up the process of drug design. A company named Atomwise developed a technology named AtomNet technology that enables researchers to combine atoms virtually to come up with possible molecules. The company claims that their algorithm is trained to process and analyze billions of atoms to find which ones will bond, and will then simulate their testing on the computers.
GANs or Generative Adversarial Networks are a class of networks that generate images that are real looking. pharm.ai , a project by Insilico medicine uses these GANs and reinforcement learning to generate new molecular structures and to find the biological origin of a disease. lnsilico uses AI to help pharmaceutical companies improve the R&D processes, develop companion diagnostics and improve clinical trials enrollment practices. The company claims to collect the human tissue of young, middle-aged, old, and very old patients to build its own data, which can be used to train other datasets.
Case Study
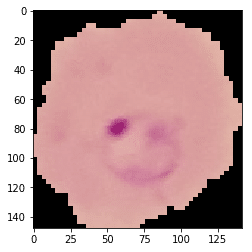
For those of you who would like to have a hands-on experience of how these technologies work, we have created a program to check if a microscopic image of a cell is infected by malaria or not using a simple Convolutional Neural Network or a CNN
Consider an image of an uninfected and parasitized cell –
An uninfected cell
A parasitized cell
As we can see, the parasitized cell varies from the uninfected cell by the presence of a purple substance. Our objective is to train a classifier to distinguish infected and uninfected cells.
In our dataset, we have in total 27,558 images. The infected and uninfected images are distributed equally.
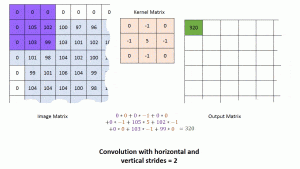
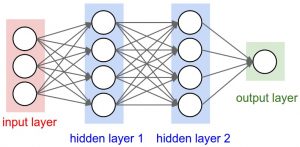
For those of you not familiar with CNNs, we’ll understand it very intuitively. Essentially, there are two main parts in a CNN
Convolutional filters
Fully connected layers
Convolution filters are like eyes. They capture details or features in an image. For example, in the case of a flower, they capture complex features about the shape, colour, etc. These features are captured by sliding a window called a convolution filter over an image.
Then these features are passed on to the fully connected layers. Fully connected layers process these features. This network comprises many connections among unit cells or neurons. The final output is used to predict the class.
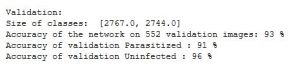
Using the pytorch framework available in python, we train a model and then test it on a validation set. Here are our results:
Our accuracy on this set is 93% on an average which is great for a simple network.
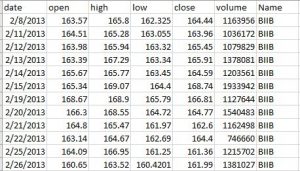
Loosely speaking, a time series describes the behavior of a variable with time. For example a company’s daily closing stock prices. Our major interest lies in forecasting this variable or the stock price in our case in the future. We try to develop various statistical and machine learning models to fit the data, capture the patterns and forecast the variable well in the future.
In this article, we will try traditional models like ARIMA, popular machine learning algorithms like Random Forest and deep learning algorithms like LSTM.
Tutorial link (you can download the data from this repository)
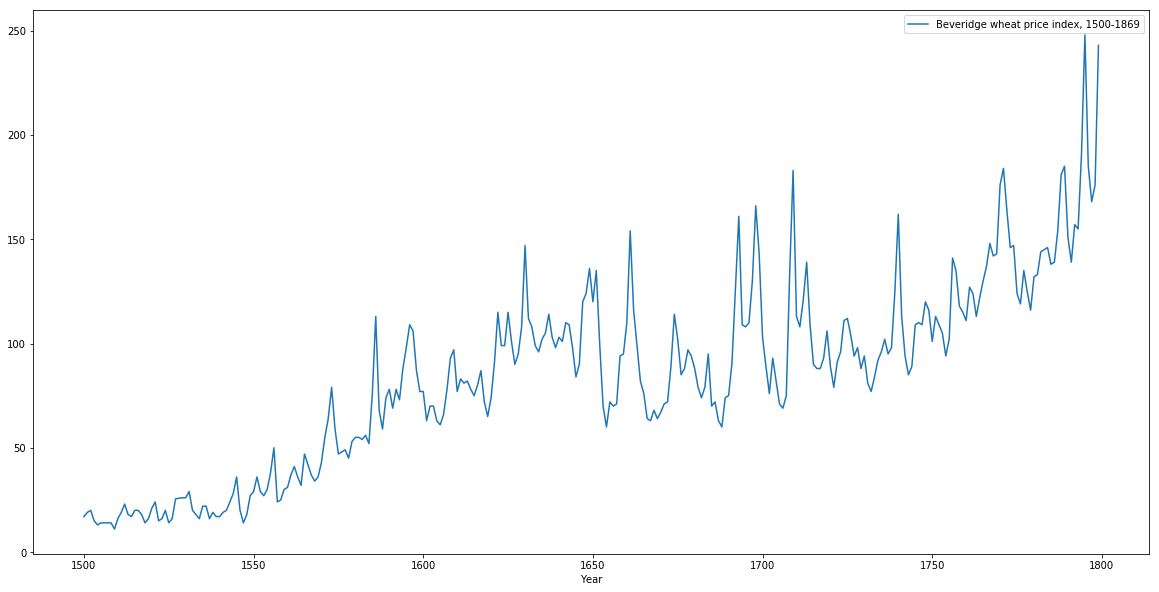
Before we actually dive into the model, let’s see if the data is in it’s the best form for our model.
Clearly, we see there is an upwards trend. When we analyze a time series, we want it to be stationary, meaning the mean and variance should be constant along the time series. Why? This is because it is useful to analyze such a series from a statistical point of view. Like in our case, usually there exists a trend. To make a time series stationary, a common way is to difference it
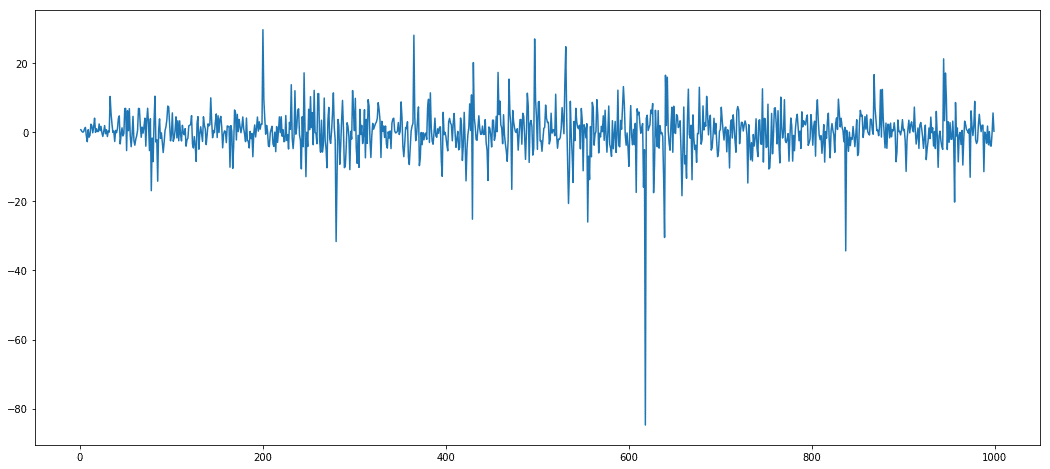
I.e. a series having [a,b,c,d] is transformed to [b-a,c-b,d-c].
A differenced time series looks something like this –
The mean and variance looks almost constant, except for a few outliers. Such a differenced time series is suitable for modelling.
OK! We know something about how our data should look like. But what exactly is ARIMA?
Let’s break it down into 3 terms
AR – This term indicates the number of auto-regressive terms (p) in the model. Intuitively, it denotes the number of previous time steps the current value of our variable depends on. For example, at time T, our variable Xt depends on Xt-1 and Xt-2, linearly. In this case, we have 2 AR terms and hence our p parameter=2
I – As stated earlier, to make our time series stationary, we have to difference it. Depending on the data, we difference it once or multiple times (usually once or twice). The number of times we do it is denoted by d.
MA – This term is a measure of the average over multiple time periods we take into account. For example, to calculate the value of our variable at the current time step, if we take an average over previous 2 timesteps, the number of MA terms, denoted by q=2
Specifying the parameters (p,d,q) will specify our model completely. But how do we select these parameters?
We use something called ACF (Autocorrelation plot) and PACF(Partial autocorrelation plot) for this purpose. Let’s get an intuition of what autocorrelation and partial autocorrelation mean.
We know that for 2 variables X and Y, correlation denotes how the two variables behave with each other. Highly positive correlation denotes that X increases with Y. Highly negative correlation denotes that X decreases with Y. So what is autocorrelation?
In a time series, it denotes the variance of the predicted variable at a particular time step with its previous time steps. Mathematically,
Where X’ is the mean, k is the lag (number of time steps we look back. k=1 means t-1), N is the total number of points. C is the autocovariance. For a stationary time series, c does not depend on t. It only depends on k or the lag.
Partial autocorrelation is a bit tricky concept. Just get an intuition for now. Consider an example – We have the following data – body fat level (F), triceps measurement (Tr) and thigh circumference (Th). We want to measure the correlation between F and Tr but we also don’t want thigh circumference or Th to play any role. So what do we do? We try to remove linearity from F and Tr introduced by Th. Let F’ be the fat levels predicted by Th, linearly. Similarly, let Tr’ be triceps measurement as predicted by Th, linearly.
The residuals for fat levels is given by F-F’ and for tricep measurement is given by Tr-Tr’. Partial correlation is the correlation measured between these residuals.
In our case the
Next, we answer two important questions
What suggests AR terms in a model?
ACF shows a decay
PACF cuts off quickly
What suggests MA terms in a model?
ACF cuts off sharply
PACF decays gradually
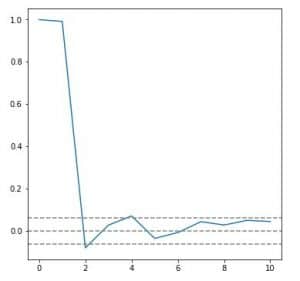
In our case, the ACF looks something like
From lag 0 it decays gradually. The top and bottom grey dashed lines show the significance level. Between these levels, the autocorrelation is attributed to noise and not some actual relation. Therefore q=0
PACF looks like
It cuts off quickly, unlike the gradual decay in ACF. Lag 1 is significantly high, indicating the presence of 1 AR term. Therefore p=1.
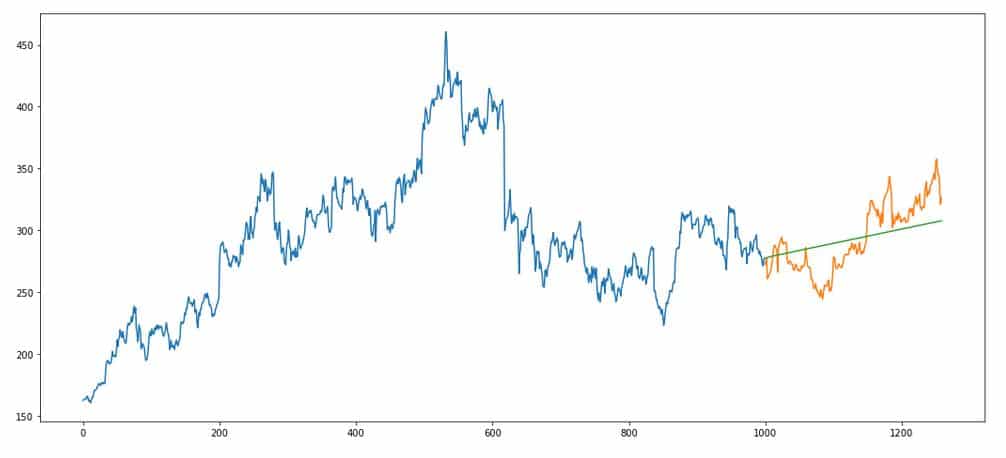
So now we have specified our model. Let’s fir our ARIMA(p=1,d=1,q=0) model. Follow the tutorial to implement the model. Results look something like –
Blue portion is the data on which the model is fitted. Orange is the holdout/validation set. Green is our model’s performance. Note that we only need the predicted variable for ARIMA. Nothing else.
The mean squared error for our model turns out to be 439.38.
Machine and Deep learning algorithms
To see if machine learning and deep learning algorithms work well on our data, we test two algorithms – Random Forest and LSTM. The data is the same except for that we use all the features and not just the predicted variable. We do some basic feature engineering like extracting the month, day and year.
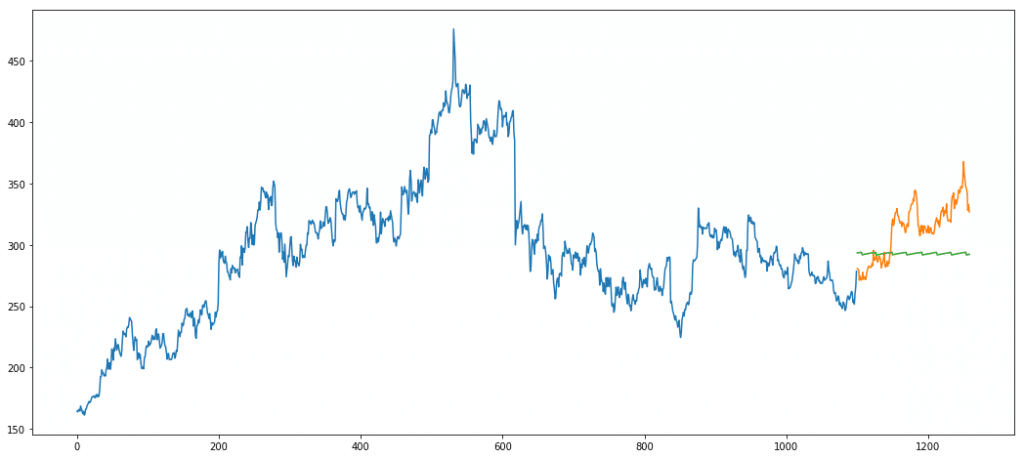
Deep Learning Model – LSTM
LSTM or long short-term memory network is a variation of the standard vanilla RNN (Recurrerent Neural Networks). RNNs, many times tend to suffer through a problem of vanishing/exploding gradients. This means that the gradient values become too large or too small, causing problems in updating the weights of RNN. LSTMs are improvised versions of RNN that solve this problem through the use of gates. For a detailed explanation, I highly recommend this video – https://youtu.be/8HyCNIVRbSU
In our case, we use Keras framework to train an LSTM.
Error = 895.06
As we can see, LSTM performs really poorly on our data. Main reason is the lack of data. We train only on 1000 data points. This is really less for a deep neural network. This is a classic example where neural nets don’t always outperform traditional algorithms.
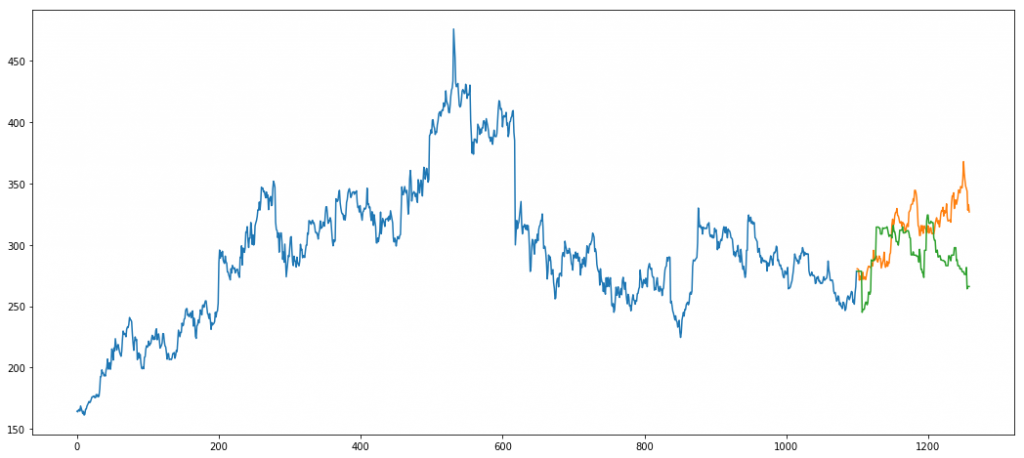
Random Forest
Random forest is a tree bases supervised machine learning algorithm. It builds short weak tree learners by randomly sampling features to split the data on. This ensures features getting adequate representation in the model unlike the greedy approach classical decision trees take.
Suppose we train 10 trees. For a data point, each tree outputs its own y value. In a regression problem the average of these 10 trees is taken as the final value for the data point. In classification, majority vote is the final call.
Using grid search we set the appropriate parameters. Our final predictions look something like
Error = 1157.91
If you notice carefully, our holdout set does not follow the peaks that our train set follows. The model fails to predict the same as it has learned to predict peaks like the ones in blue. Such an unexpected shift in trend is not captured by models.