Taking into consideration the positive trends of Data Science from previous years, there lies an immense well of possibilities that awaits us in the future, that is, the upcoming year 2020. Some of these Data Science Trend Forecast for 2020 can be foreseen as follows:
Augmented Analysis
Complicated code and extensions will no longer be required to get deep insights from data. The augmented analysis helps layman users/analysts (in machine learning/data science) to make use of AI to analyze data. This will change the way data is consumed, created and shared across all data-intensive fields. Already several BI and analytics tools are trying to implement AI assistance full force in their platforms.
Continuous/ Real-time Intelligence
There is intensive activity ongoing every second in real-time platforms. If through some method, one can plug into this data, real-time user experience can be enhanced manifold. Continuous or real-time intelligence aims to do just that by analyzing data in real-time so that instant results can be provided to the user while he is still surfing the platform. It can also help increase profit margins by re-aligning the platform as per the observed interaction of the user.
NLP
Natural Language Processing is a very important segment of Artificial Intelligence since most real-world data are in text or voice format. To process such data, advanced NLP techniques are required which are being innovated with each passing data. Today, we can read, understand, classify and even create unique text documents with the help of machines. Further developments like intelligent summarization, entity recognition and task management using text input and much more are expected to happen, owing to the intense research and increasing data-science experts choosing NLP specialisation.
Conversational technology
There has already been a visible surge in the performance of voice assistants in 2019. In 2020, it is expected to further improve such that the conversational systems become more sensitive to the human language and also more humane in their response. By more humane, it will mean that the systems can keep track of previous responses and questions (which is not a very developed feature in any voice assistant in the market to this day). Also, most client interactions are expected to be taken over by conversational technology, thus, increasing response rate and efficiency.
Explainable AI
The last decade has seen massive growth in AI aided decisions for sure, but it has been a persistent problem to be able to explain these decisions or why the AI wants to go a certain way instead of another. Recently, however, a lot of research has increased the scope of explainable AI. 2020 can further be invested in understanding problems like say, how and why a certain neural network arrived at a certain decision. This will indefinitely increase the faith of clients on adolescent technology.
Persistent memory/ In-memory computation
In-memory computing or IMC can deliver extremely high-performance tasks due to optimized memory architecture. It also has become more feasible due to the decreasing expense of memory which owes credit to constantly emerging innovations.
Data Fabric
Data Fabric helps in the smooth access and sharing of data in distributed environments. It is usually custom made and helps in the transfer and store of data, data pipelines, APIs and previously used data services that have a chance of being re-invoked. Trusted and efficient data fabric can help to catalyze data science pipelines and reduce delays in customer-client interaction/iterations.
Advances in Quantum Computing
The research in Quantum Computing has a very high momentum at the moment. Even though the whole architecture of Quantum computing is at a very basic stage, increased investments and research are helping the field to grow by inches every passing day. A quantum computer is said to perform calculations which will take general computers a few years, in just a few seconds! As remarkable as it sounds, it can bestow superpowers to mankind! Imagine munching on years and years of historical data to arrive at conclusions about the future in just a few seconds. A whole lot of astonishing things await us, and we must be blessed to be a part of this century.
It is expected that India’s job openings in the analytics sector will double to about 200000 or two lakh jobs in 2020. Here is what 2020 for job seekers in data science will look like:
Fields like finance, IT, professional services and insurance will see a boom in demand for data science and analytics.
Having analytics skills like MapReduce, Apache Pig, Machine learning and Hadoop can provide an edge over other competitors in the field. The most fundamental in-demand skills will be Python and Machine Learning. Statistics is an added advantage.
Vacancies for roles like data developers, data engineers and data scientists will go over 700,000 by 2020.
The most promising sectors that will tend to create increasing opportunities include Aviation, Agriculture, Security, Healthcare and Automation.
The average salaries in India in development roles like Data Scientist or Data Engineer will range from 5 to 8 Lakh per annum.
The average salaries in India in management/strategizing roles like data architect or business intelligence manager will range from 10 to 20 Lakh per annum.
As exciting as all of it sounds, there is always a bag of unforeseen advancements that are bound to take us all by surprise, as has always happened with Data Science and AI in the past. So, hold tight for yet another mind-boggling ride through the lanes of technology this 2020!
Data Science has seen a massive boom in the past few years. It has also been claimed that it is indefinitely one of the fastest-growing fields in the IT/academic sector. One of the most hyped Trends in Data Science this year was that the sector saw a major hike in jobs as compared to the past years!
Such an unprecedented growth owes all its dues to the unimaginable benefits that artificial intelligence has brought to the plate of mankind for the very first time. It was never before imagined that external machines could aid us with such sophistication as is present today. Owing to this, it is imperative that an individual, irrespective of his/her calling, must have at least a superficial knowledge about the past advances and future possibilities of this field of study. Even if it is the job of scientists and engineers to figure out solutions using machine learning and data science, the solutions, undoubtedly is bound to affect all our lives in the upcoming years. Moreover, if you are planning to plug into the huge well of job openings in data science, exploring the past and upcoming trends in this field will surely take you a step ahead.
Looking back on the achievements of the year 2019, there is much which has happened. Here is a brief glimpse of what Trends in Data Science of 2019 looked like:
Accessible AI
The once-popular belief that AI technology was only meant for high-scale and high-tech industries, is now an old wives’ tale. AI has spread so rapidly across every phase of our lives, that sometimes we do not even realize that we are being aided by AI. For instance, recommendations that we get on online forums are something we have become very used to in recent times. However, very few have the conscious knowledge that the recommendations are regulated by AI technology. There are also several instances where a layman can use AI to get optimized outputs, like in automated machine learning pipelines. We even have improvised AI-aided security systems, music systems and voice assistants in our very homes! Overall, the impact of AI in everyday lives saw a massive boost in 2019, and it is only bound to increase.
The rapid growth of IoT products
As was already forecasted, the number of machines/devices which came online in 2019 was immense. Billions were invested in research to back the uprising IoT industry. Today it is nothing out of the ordinary to control home appliances like television and air conditioners with our smartphones or lock our and unlock our cars from even the opposite end of the globe. Bringing devices online not only makes the user experience far smoother but also generates crucial data for analysis. With such data, several unopened gates can be explored across several domains. The investments and count of IoT devices are expected to go up at an increasing rate in the upcoming years.
Evolution of Predictive Analysis
The concept of predictive analysis is to use past data to learn recurring patterns, such that it can predict outcomes of future events based on the patterns learnt. Today, with increasing data it becomes extensively important to make use of optimized predictive solutions. Big data comes into picture here and significant advancements have been made in 2019 about it. Tools like PySpark and MLLib have helped scale simple predictive solutions to extensive data.
Migration of Dark Data
Dark data is very old data which has probably been sitting in obsolete archives like old systems or even files in storage rooms! There is a general understanding that such unexplored data can show us the way to crucial insights about past trends which can help grab useful opportunities and even avoid unwanted loopholes. Therefore, there has been visible initiatives to make dark data more available to present-day systems with the help of efficient storage and migration tools.
Implementation of Regulations
In 2018, General Data Protection Regulation (GDPR) brought in a few data governance rules to emphasize the importance of data governance. The rules were laid down so fast that even at the year-end, several companies dealing with data are still trying to comply wholly with all the principles laid down. These principles have not only created a standard for data consumption and data handling domains but are also bound to shape the future of data handling with great impact.
DataOps
DataOps is an initiative to bring in some order in the way the data science pipeline functions. It is essentially a reflection of agile and DevOps methods in the field of data science. In 2019, it has been one of the major concerns of management in data science to integrate DataOps into their respective teams. Previously, such integration was not possible since the generic pipeline was still in making or under research. However, now, with a more robust structure, integrating DataOps can mean wonders for data science teams.
Edge Computing
As stated by Gartner, Inc. cloud computing and edge computing has evolved to become a complementary model in 2019. Edge computing goes by the concept of “more the proximity (or closeness to the source of computation), better is the efficiency”. Edge computing allows workloads to be located closer to the consumers and thus, reduces latency several-fold.
There is, however, a huge recurring gap when it comes to the need and availability of skilled people who can launch and contribute to these developments significantly. India contributed to 6% of job openings worldwide in 2019, which scales to around 97000 jobs!
The job trends of 2019 looked as follows:
BFSI sector had a massive demand for analytics professionals, followed by the e-commerce and telecom sectors. The banking and financial sectors continued to have high demand throughout.
Python served as a great skill to attract employers to skilled job seekers
A 2% increase in jobs offering over 15 Lakh per annum was observed
Also, 21% of jobs demanded young talent in data science, a great contrast to all previous years. 70% of job openings were for professionals with less than 5 years of experience.
The top in-demand designations were Analytics Manager, Business Analyst, Research Analyst, Data Analyst, SAS Analyst, Analytics Consultants, Statistical Analyst and Hadoop Developer
Big data skills like Hadoop and Spark were extremely in demand due to the growing rate of data.
Telecom industry saw a fall in demand for data science professionals.
The median salary of analytics jobs was just over 11 Lakh per annum.
AI, Data Science and Analytics have gained a burst of hype over the last decade and for good reasons. However, compared to other IT and academic fields/courses, Data Science is not as concrete and clear-cut. But what was the reason for this sudden outburst of demand for a vague and emerging field?
There are a few highly contributing factors which are
involved in making Data Science an extremely enticing and desirable field of
action. The upsurge in the demand for data science jobs can be credited to the
following factors:
Increasing Data: As is known, almost every digital action we take generates bits of information which gets recorded as potentially useful data. Every action leaves behind a trail of data which is also sometimes referred to as digital footprints. A larger volume of data helps to track down trends and patterns over a wide range so that smart analysis can be undertaken and informed decisions can be formulated based on best performance trends observed from past data.
Better Computation: Just a few decades ago, in spite of having a sufficient volume of data, it was almost impossible to implement sophisticated operations on them. This was largely due to primitive computation and technology which could only handle a few units of data at any given time. However, advanced statistical theories were already in place and just lacked the right tools for application. This time period is referred to as the AI winter when in spite of extremely advanced algorithm formulation, implementation was next to impossible. In the last decade or so, once this problem was solved and processors and storage capacities evolved to be in their present state, the theoretical concepts could be applied across several recurring problems. This was when the demand for data specialists like statisticians, data engineers, data scientists and machine learning engineers outgrew the average count.
Who should consider signing up for Data Science / AI / Machine Learning courses?
As was seen above, the demand for data science jobs is in fact, quite overwhelming. The question, however, arises that in spite of an increasing number of data science enthusiasts, why still, is there a largely visible vacancy in this field? The answer is extremely simple, yet harsh.
The available supply of people in this field is extremely under-skilled.
Learning open-source library syntax codes and having an overview of modelling algorithms is simply not enough. Sadly, however, most of the aspiring data scientists of this generation, barely have enough knowledge beyond these basic skills.
It is imperative to understand that Data Science is not simple, contrary to the general belief that media has propagated over the years. Indeed, most people from an engineering or mathematical background can learn and understand coding syntax, modelling concepts and visualization basics with ease, but how many of them can actually modify the already existing foundations to build something better?
Data Science is the science of patterns in data. Therefore, as data patterns and data type changes, which happens very frequently in real-world scenarios, the need arises for new solutions which suites the new input. Good companies and research organizations ask for highly experienced candidates so that they can smartly handle any new challenge, and with data, it is almost always a new challenge. Even the same problems end up getting solved with different techniques when the input data changes.
Therefore, if an individual is looking to opt for data science because of its simplicity or hype, they definitely need to look elsewhere because this field will test his/her extreme limits over time. On the other hand, an individual who is truly interested in the mechanisms of Data Science and really wishes to be invested in the learning and development of improved skills every day must delve into the field right away and gather as much knowledge as possible when the time is good with the help of AI courses, Data Science Courses or Machine Learning Courses.
What are the prerequisites for taking Data Science/ AI/ Analytics/ Machine Learning courses?
If you have persevered and passed the last question graciously, there is also some good news. Data Science has minimum and very simple requirements. It is mostly desired that people who opt for Data Science are from Engineering or Mathematical backgrounds, but it can suit anybody else just fine if there is a willingness to learn and the ability to grasp a wide range of concepts. Here are a few basic prerequisites:
Basic Coding skills: Even ground-level coding knowledge works in order to implement Data Science/Machine Learning techniques. The two most popular languages in Data Science, Python and R, are extremely simple languages which are easy to learn, implement and work with in general. Both these languages have built-in libraries which have optimized code and can be implemented in just a few lines, speeding things up many-fold.
Statistical Understanding: Statistical concepts are paramount in data science. They form the foundation of every concept and every algorithm. So, even though an individual never had any relevant education in statistical subjects, it must be noted that she/he must be able to grasp these concepts with ease. Going through a few good courses in statistics can help individuals progress really well in this front. Anything can be explained with simplicity, and if it cannot be, more work has to be done in order to make it simple! Good Analytics and Data Science courses provide you just that, simplicity. You can go through the skills and concepts required to be fluent with statistics here.
Can a person shift career paths to data science?
For those looking to shift career paths, online data science courses, Machine Learning courses and AI courses are a really effective way to do it in case one does not want to invest in a large scale or lose out on years of experience. Good data science courses provide well-guided instructions and simplified concepts so that real-life projects can be solved. If an individual follows the instructions well and implements them in real-life projects in order to achieve satisfying results, he/she can showcase these in their resume during the application of jobs. You can read about the top 5 careers in Data Science in order to be more informed about your next steps during career shiting.
Tip: Use the tips and tricks from the Data Science and Machine Learning courses to solve problems in online hackathons and competitions. Compete for top ranks so that it can be displayed on your CV with a digital proof. Machine Hack (Relatively Easy), Hacker Earth (Medium Level), Kaggle (Advanced) and Analytics Vidya (Relatively Easy).
What is the scope for freshers in Data Science?
If you are a fresher in Data Science, your scope of advancement and learning is immense. Concentrate on learning with the depth-first approach. In other words, take one concept and dive to extreme depths with it so that you can decipher the nuts and bolts of the technique if asked to. This helps to increase one’s ability to tune and tweak the algorithms to the best possible optimizations as per the problem at hand.
As a fresher, staying motivated and discovering your true calling is the key to gaining from these young years. Therefore, experiment with as many problems and techniques as possible in order to understand what really aligns with you and your interests. In case Data Science turns out to be your best possible alignment, in few years’ time, with enough variance and experience by your side, you will be able to work with extremely good projects with large scale firms and research institutes as per your preference. All come with patience, knowledge and hard work.
What is the road map which one needs to follow to leverage
any data science course?
Just studying AI, Machine Learning or Data Science courses and memorizing the approaches theoretically will not give good returns. Only take a course you are willing to implement the learnings on a practical front. With every concept you learn, see how and where you can apply it, and then go ahead and do it. This way, whatever was learned, will last much longer in the mind and will also be more effective since you will know the applications and shortcomings at one go. Therefore, follow this approach to make maximum use of any data science/ AI/ ML course:
If you are unable to do so, there is hardly any benefit of going through an entire course as you will forget it soon by this method.
What are the courses that one can go through to improvise
and learn Data Science skills?
Few of the good Data Science / AI / Machine Learning courses which one can follow to learn about data science, machine learning, or Artificial Intelligence are as follows:
Data
Science Course: All about data science, analytics and machine learning.
Big Data course: A step further into advanced data analysis
and processing. This course deals with Big Data and its operations on Cloud (Amazon
Web Services)
Artificial Intelligence course: This is a level higher than
the ordinary machine learning. This course delves into deep learning
techniques, a branch of AI which deals with biologically similar mechanisms which
try to mimic human intelligence. Deep learning is extremely efficient when it
comes to data interpretation.
Follow Data Science Blogs in order to get more information on how to go about Data Science with a series of tricks, hacks and beautifully simplified concepts.
Principal Component Analysis or PCA is one of the simplest and fundamental techniques used in machine learning. It is perhaps one of the oldest techniques available for dimensionality reduction, and thus, its understanding is of paramount importance for any aspiring Data Scientist/Analyst. An in-depth understanding of PCA in R will not only help in the implementation of effective dimensionality reduction but also help to build the foundation for development and understanding of other advanced and modern techniques.
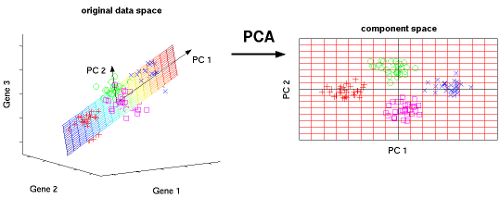
Examples of Dimension Reduction from 2-D space to 1-D space Courtesy: Bits of DNA
PCA aims to achieve two
primary goals:
1. Dimensionality
Reduction
Real-life data has several features generated from numerous resources. However, our machine learning algorithms are not adept enough to handle high dimensions efficiently. Feeding several features, all at once, almost always leads to poor results since the models cannot grasp and learn from such volume altogether. This is called the “Curse of Dimensionality” which leads to unsatisfactory results from the models implemented. Principal Component Analysis in R helps resolve this problem by projecting n dimensions to n-x dimensions (where x is a positive number), preserving as much variance as possible. In other words, PCA in R reduces the number of features by transforming the features into a lesser number of projections of themselves.
2. Visualization
Our visualization systems are limited to 2-dimensional space which prevents us from forming a visual idea of the high dimensional features in the dataset. PCA in R resolves this problem by projecting n dimensions to a 2-D environment, enabling sound visualization. These visualizations sometimes reveal a great deal about the data. For instance, the new feature projections may form clusters in the 2-D space which was previously not perceivable in higher dimensions.
Visualization with PCA (n-D to 2-D) Courtesy: nlpca.org
Intuition
Principal Component Analysis in R works with the simple idea of projection of a higher space to a lower space or dimension
The two alternate objectives of Principal Component Analysis are:
1. Variance Maximization
Formulation
2. Distance Minimization
Formulation
Let us demonstrate the above with the help of simple examples. If you have 2 features, and you wish to reduce the features to a 1-D feature set using PCA in R, you must lookout for the direction with maximal spread/variance. This becomes the new direction on which every data point is projected. The direction perpendicular to this direction has the least variance, and is thus, discarded.
Alternately, if one focuses on the perpendicular distance between a data point and the direction of maximum variance, our objective shifts to the minimization of that distance. This is because, lesser the distance, higher is the authenticity of the projection.
On completion of these projections, you would have successfully transformed your 2-D data to a 1-D dataset.
Mathematical Intuition
Principal Component Analysis in R locates the distance of maximal spread (or direction of minimal distance from data points) with the use of Eigen Vectors and Eigen Values. Every Eigen Vector (Vi) corresponds to an Eigen Value (Ei).
If X is a feature matrix (matrix with the feature values),
covariance matrix S = XT. X
If EiVi = SVi ,
Then Ei is an Eigen Value, and Vi becomes the corresponding Vector.
If there are d dimensions, there will be d Eigenvalues with d corresponding Eigen Vectors, such that:
E1>=E2>=E3>=E4>=…>=Ed
Each corresponding to V1, V2, V3, …., Vd
Here the vector corresponding to the largest Eigenvalue is the direction of Maximal spread since rotation occurs such that V1 is aligned with maximal variance in the feature space. Vd here has the least variance in its direction.
A very interesting property of Eigenvectors is the fact that if any two vectors are picked randomly from the set of d vectors, they will turn out to be perpendicular to each other. This happens because they align themselves such that they catch the most opposing directions in terms of variance.
When deciding between two Eigen Vector directions, Eigenvalues come into play. If V1 and V2 are two Eigen Vectors (perpendicular to each other), the values associated with these vectors, E1 and E2, help us identify the “percentage of variance explained” in either direction.
Percentage of variance explained Ei/(Sum(d Eigen Values)) where i is the direction we wish to calculate the percentage of variance explained for.
Implementation
Principal Component Analysis in R can either be applied with manual code using the above mathematical intuition, or it can be done using R’s inbuilt functions.
Even if the mathematical concept failed to leave a lasting impression on your mind, be assured that it is not of great consequence. On the other hand, understanding the basic high-level intuition counts. Without using the mathematical formulas, PCA in R can be easily applied using R’s prcomp() and princomp() functions which can be found here.
In order to demonstrate Principal Component Analysis, we will be using R, one of the most widely used languages in Data Science and Machine Learning. R was initially developed as a tool to aid researchers and scientists dealing with statistical problems in the academic field. With time, as more individuals from the academic spheres started seeping into the corporate and industrial sectors, they brought along R and its phenomenal uses along with them. As R got integrated into the IT sector, its popularity increased manifold and several revisions were made with the release of every new version. Today R has several packages and integrated libraries which enables developers and data scientists to instantly access statistical solutions without having to go into the complicated details of the operations. Principal Component Analysis is one such statistical approach which has been taken care of very well by R and its libraries.
For demonstrating PCA in R, we will be using the Breast Cancer Wisconsin Dataset which can be downloaded from here: Data Link
These code statements help to read data into the variables wdbc.
wdbc.pr <- prcomp(wdbc[c(3:32)], center = TRUE, scale = TRUE) summary(wdbc.pr)
The prcomp() function helps to apply PCA in R on the data variable wdbc. This function of R makes the entire process of implementing PCA as simple as writing just one line of code. The internal operations and functions are taken care of and are even optimized in terms of memory and performance to carry out the operations optimally. The range 3:32 is used to tell the function to apply PCA only on the features or columns which lie in the range of 3 to 32. This excludes the sample ID and diagnosis variables since they are identification columns and are invalid as features with no direct significance with regard to the target variable.
wdbc.pr
now stores the values of the principal components.
Let us now
visualize the different attributes of the resulting Principal Components for
the 30 features:
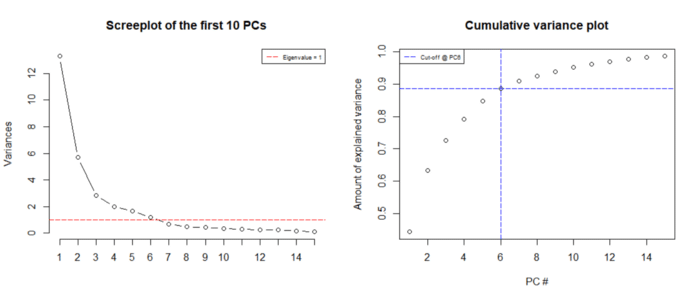
screeplot(wdbc.pr, type = "l", npcs = 15, main = "Screeplot of the first 10 PCs")
This plot
clearly demonstrates that the first 6 components account for 90% of the variance
in the dataset (with Eigen Value > 1). This means that one can easily
exclude 24 features out of 30 features in order to preserve 90% of the data.
Limitations of PCA
Even though Principal Component Analysis in R displays a highly intuitive technique, it hosts certain shocking limitations.
1. Loss of Variance: If the percentage of variance against the chosen axis is around 50-60%, it is evident that 40-50% of the information which contributes to the variance of the dataset is lost during dimensionality reduction. This happens often when the data is spherical or bulging in nature.
2. Loss of Clusters: If there are several clusters present in the original dataset, but most of them lie in the direction perpendicular to the chosen direction. Thus, all the points from different clusters will be projected to the same region on the line of chosen direction, leading to one cluster of data points which are in fact quite different in nature.
3. Loss of Data Patterns: If the dataset forms a nice wavy pattern in direction of maximal spread, PCA takes to project all the points on the line aligned against the direction. Thus, data points which formed a wave function are concentrated on one-dimensional space.
These demonstrate how PCA in R, even though very effective for certain datasets, is a weak instrument for dimensionality reduction or visualization. To resolve these limitations to a certain extent, t-SNE, which is another dimensionality reduction algorithm, is used. Stay tuned to our blogs for a similar and well-guided walkthrough in t-SNE.
The flux of data is increasing exponentially in this age of Digital awakening. Data has become so important to major industries and sectors around the globe that it can literally be referred to as digital gold! From simple company centric applications to major platforms interweaving people from all around the world, data has started to shape major decisions for not only autonomous machines, but also for the human race as a whole. This imagery is as intriguing as it is terrifying, but only if we make it so.
In order to handle this rapidly incoming data with relative ease, a competent system is required to act instantly and deliver results on the fly. Otherwise, such large-scale investments on data gathering and data generation will go to waste since the data will be left in its dormant state without any active or competent agent acting on it. This is where the concept of real time data streaming and processing comes up. So, what is real time data streaming?
As is already known, data is being generated from various sources at a lightening pace. If we stop to ingest enough data, process it in batches and then provide the results after enough time has passed, the results will tend to lose its relevance and will reflect outdated patterns and trends. This happens majorly because of the high rate of variance in incoming data and also because of time constraints.
For instance, suppose that you have a machine which tells you which horse to bet upon in a horse race. You have the option of changing your choice during the race until the last lap commences. In such a case, if your machine gives you predictions based on the first lap where horse A was showing promise, and predicts that horse A will win, where in fact, during the third lap, horse B shows further promise, you will lose your bet just because of a machine which lags behind by two laps. This problem can be avoided by processing incoming data instantly, or in other words, real time data streaming. A stack of old data or historical data is studied and incoming records are processed based on the studied patterns such that the results are delivered within milliseconds. For our example, the horse race prediction machine would have already studied data about the different horses in the race previously and then based on the incoming data (the horse number, position of the horse, time since beginning of race, number of contestants, etc.), will be able to instantly allocate a rank for the different participants with the help of real time data streaming.
How to Go About Real-Time Data Streaming?
In real time mission-critical applications, Apache Kafka has turned out to be one of the most widely used frameworks for implementation. Apache Kafka is integrated with efficient machine learning frameworks in order to enable model training and speedy deliverance by supporting real time data streaming.
What is Apache Kafka?
As per Kafka’s website, it defines itself and its tasks as follows:
“Kafka® is used for building real-time data pipelines and streaming apps. It is horizontally scalable, fault-tolerant, wicked fast, and runs in production in thousands of companies.”
“The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds. Its storage layer is essentially a “massively scalable pub/sub message queue designed as a distributed transaction log”, making it highly valuable for enterprise infrastructures to process streaming data.” – Wikipedia
These definitions might seem like a mouthful at first, but as we go through with this subject step by step in this discussion, one will easily get the hang of it in no time!
Why use Tensorflow as the machine learning platform which is to be integrated with Apache Kafka?
Tensorflow is one of the most popular and efficient open source machine learning platforms available. It has a beautiful and well-suited architecture which enables data flow with extreme grace and optimization. It enables users and developers to establish large-scale projects with minimal hassles and maximal resource optimization. It is thus, a very competent platform to integrate with Apache Kafka for the purpose of serving real-time data streaming.
Tensorflow’s tf.keras and tf.data are responsible for streaming data in and out. Previously however, these modules were limited in their usage and could only support a few data formats. Support for Kafka streaming was not included during the earlier versions of Tensorflow. It was also difficult to use Tensorflow supported modules like tf. Examples and TFRecord in Big data and the general community of Data Science as a whole and were, therefore, rarely spotted.
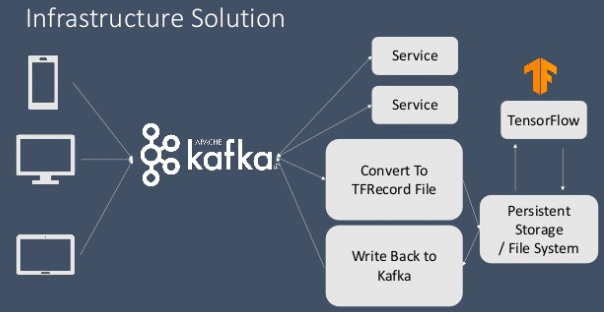
It was thus, a difficult task to integrate the Apache Kafka and Tensorflow frameworks. A lot of intermediary bridges had to be constructed in order to establish reliable handshakes between these two frameworks and ensure smooth integration. This was a burdensome process since it included designing of an entire infrastructure which turned out to be a fault prone mechanism most of the time. These were the steps which were required to be followed in order to establish a working data streaming flow:
Read data from the Kafka stream -> Convert to TFRecord format -> call Tensorflow’s function to read the TFRecord object from file system -> execute model and deliver result -> save the result in the file system again -> write results/ inference back to Kafka
Source: Kafka Summit NYC 2019, Yong Tang
However, with the release of Tensorflow 2.0, the tables turned and the support for Apache Kafka data streaming module was issued along with support for a varied set of other data formats in the interest of the data science and statistics community (released in the IO package from Tensorflow: here).
Source: Kafka Summit NYC 2019, Yong Tang
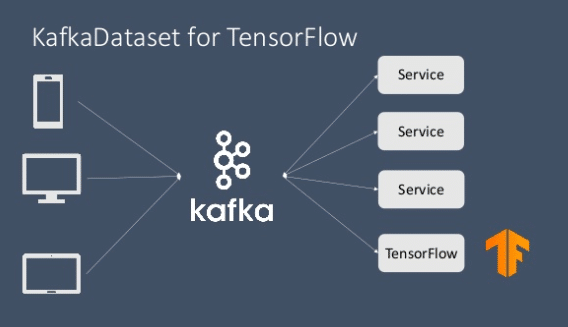
With this development, it is now possible to enable real time streaming with Kafka and Tensorflow with relative ease and minimized error. This process is implemented with the use of KafkaDataset module (written in C++) which is a part of the new release of the Tensorflow IO package. KafkaDataset module has been integrated as a subclass of tf.data.Dataset module. This module works just like any other data streaming module where users can simply read data from a kafka stream and use it in a Tensorflow graph or feed it to tf.keras and other Tensorflow specific modules for model training and evaluation purpose. The option of writing back through output stream is also possible of course.
Here is how to implement data streaming, processing, model training and inference gathering in just a few lines of code with Kafka support on Tensorflow:
Line 2 simply streams in data with the help of the KafkaDataset module and data processing and modeling are immediately commenced as can be seen in lines 3 and 4. Thereafter, we move on to the keras callback stage. Keras callbacks are very informative since they provide an overview of the internal stages and statistical details of the model during the training or prediction process. The callback function is written in the 7th line. The KafkaOutputSequence is responsible for writing the results to the output stream (with so much relative ease!). In line 13 the predict function is called to get the model details and inference on the test dataset.
Source: Kafka Summit NYC 2019, Yong Tang
Real time data streaming with Kafka and Tensorflow has not only helped in the elimination of the complicated infrastructure which previously bridged the wide gap between the two popular platforms, but has also made the process less error prone and more approachable for real time mission critical systems with respect to machine learning and data science. The above picture shows how easy it is now to implement Kafka along with Tensorflow with just one call for data streaming. Further development in this area looks highly promising and is sure to contribute manifold in the ease of scalability and smooth integration when it comes to Big Data, live or real time data streaming, machine learning and deep learning techniques to develop smart and autonomous systems across the globe!
Get a grip on the machine learning, data science, big data and several other intriguing topics by following our blogs or even our detailed courses provided in the links below: