A decade ago, machine learning was simply a concept but today it has changed the way we interact with technology. Devices are becoming smarter, faster and better, with Machine Learning at the helm.
Thus, we have designed a comprehensive list of projects in Machine Learning course that offers a hands-on experience with ML and how to build actual projects using the Machine Learning algorithms. Furthermore, this course is a follow up to our Introduction to Machine Learning course and delves further deeper into the practical applications of Machine Learning.
Progressing step by step
In this blog, we will have a look at projects divided mostly into two different levels i.e. Beginners and Advanced. First, projects mentioned under the beginner heading cover important concepts of a particular technique/algorithm. Similarly, projects under advanced category involve the application of multiple algorithms along with key concepts to reach the solution of the problem at hand.
Projects offered by Dimensionless Technologies
We have tried to take a more exciting approach to Machine Learning, by not working on simply the theory of it, but instead by using the technology to actually build real-world projects that you can use. Furthermore, you will learn how to write the codes and then see them in action and actually learn how to think like a machine learning expert.
Following are some of the projects among many others that they cover in their courses:
Disease Detection — In this project, you will use the K-nearest neighbor algorithm to help detect breast cancer malignancies by using a support vector machine.
Credit Card Fraud Detection — In this project, you are going to do a credit card fraud detection and going to focus on anomaly detection by using probability densities.
Stock Market Clustering Project — In this project, you will use a K-means clustering algorithm to identify related companies by finding correlations among stock market movements over a given time span.
Beginners
1) Iris Flowers Classification ML Project– Learn about Supervised Machine Learning Algorithms
Iris flowers dataset is one of the best data sets in classification literature. The classification of the iris flowers machine learning project is often referred to as the “Hello World” of machine learning. Furthermore, this dataset has numeric attributes and beginners need to figure out how to load and handle data. Also, the iris dataset is small which easily fits into the memory and does not require any special transformations or scaling, to begin with.
The goal of this machine learning project is to classify the flowers into among the three species — virginica, setosa, or versicolor based on length and width of petals and sepals.
2) Social Media Sentiment Analysis using Twitter Dataset
Platforms like Twitter, Facebook, YouTube, Reddit generate huge amounts of big data that can be mined in various ways to understand trends, public sentiments, and opinions. A sentiment analyzer learns about various sentiments behind a “content piece” through machine learning and predicts the same using AI. Also, Twitter data is considered a definitive entry point for beginners to practice sentiment analysis. Hence, using Twitter dataset, one can get a captivating blend of tweet contents and other related metadata such as hashtags, retweets, location and more which pave way for insightful analysis. Using Twitter data you can find out what the world is saying about a topic whether it is movies, sentiments about any trending topic. Probably, working with the Twitter dataset will help you understand the challenges associated with social media data mining and also learn about classifiers in depth.
3) Sales Forecasting using Walmart Dataset
Walmart dataset has sales data for 98 products across 45 outlets. Also, the dataset contains sales per store, per department on weekly basis. The goal of this machine learning project is to forecast sales for each department in each outlet consequently which will help them make better data-driven decisions for channel optimization and inventory planning. Certainly, the challenging aspect of working with Walmart dataset is that it contains selected markdown events which affect sales and should be taken into consideration.
In the book Moneyball, the Oakland A’s revolutionized baseball through analytical player scouting. Furthermore, they built a competitive squad while spending only 1/3 of what large market teams like the Yankees were paying for salaries.
First, if you haven’t read the book yet, you should check it out. Ceratinly, It’s one of our favorites!
Fortunately, the sports world has a ton of data to play with. Data for teams, games, scores, and players are all tracked and freely available online.
There are plenty of fun machine learning projects for beginners. For example, you could try…
Sports Betting… Predict box scores given the data available at the time right before each new game.
Talent scouting… Use college statistics to predict which players would have the best professional careers.
General managing… Create clusters of players based on their strengths in order to build a well-rounded team.
Sports is also an excellent domain for practicing data visualization and exploratory analysis. You can use these skills to help you decide which types of data to include in your analyses.
Data Sources
Sports Statistics Database — Sports statistics and historical data covering many professional sports and several college ones. The clean interface makes it easier for web scraping.
Sports Reference — Another database of sports statistics. More cluttered interface, but individual tables can be exported as CSV files.
cricsheet.org — Ball-by-ball data for international and IPL cricket matches. CSV files for IPL and T20 internationals matches are available.
As the name suggests (no points for guessing), this dataset provides the data on all the passengers who were aboard the RMS Titanic when it sank on 15 April 1912 after colliding with an iceberg in the North Atlantic ocean. Also, it is the most commonly used and referred to data set for beginners in data science. With 891 rows and 12 columns, this data set provides a combination of variables based on personal characteristics such as age, class of ticket and sex, and tests one’s classification skills.
Objective: Predict the survival of the passengers aboard RMS Titanic.
Advance level projects
This is where an aspiring data scientist makes the final push into the big leagues. After acquiring the necessary basics and honing them in the first two levels, it is time to confidently play the big game. Certainly, these datasets provide a platform for putting to use all the learnings and take on new, and more complex challenges.
This data set is a part of the Yelp Dataset Challenge conducted by crowd-sourced review platform, Yelp. It is a subset of the data of Yelp’s businesses, reviews, and users, provided by the platform for educational and academic purposes.
In 2017, the tenth round of the Yelp Dataset Challenge was held and the data set contained information about local businesses in 12 metropolitan areas across 4 countries.
Rich data comprising 4,700,000 reviews, 156,000 businesses, and 200,000 pictures provides an ideal source of data for multi-faceted data projects. Projects such as natural language processing and sentiment analysis, photo classification, and graph mining among others, are some of the projects that can be carried out using this dataset containing diverse data. The data set is available in JSON and SQL formats.
Objective: Provide insights for operational improvements using the data available.
With the increasing demand to analyze large amounts of data within small time frames, organizations prefer working with the data directly over samples. Consequently, this presents a herculean task for a data scientist with a limitation of time.
This dataset contains information on reported incidents of crime in the city of Chicago from 2001 to the present. It does not contain data from the most recent seven days. Not included in the data set, is data on murder, where data is recorded for each victim.
It contains 6.51 million rows and 22 columns and is a multi-classification problem. In order to achieve mastery over working with abundant data, this dataset can serve as the ideal stepping stone.
Objective: Explore the data, and provide insights and forecasts about crimes in Chicago.
KKD cup is a popular data mining and knowledge discovery competition held annually. It is one of the first-ever data science competition which dates back to 1997.
Every year, the KDD cup provides data scientists with an opportunity to work with data sets across different disciplines. Some of the problems tackled in the past include
Identifying which authors correspond to the same person
Predicting the click-through rate of ads using the given query and user information
Development of algorithms for Computer Aided Detection (CAD) of early-stage breast cancer among others.
The latest edition of the challenge was held in 2017 and required participants to predict the traffic flow through highway tollgates.
Objective: Solve or make predictions for the problem presented every year.
Conclusion
Undertaking different kinds of projects is one of the good ways through which one can progress in any field. Certainly, this allows an individual to have hands on at the problems faced during the implementation phase. Also, it is easier to learn concepts by applying them. Finally, you will have a feeling of doing actual work rather than just being all lost in the theoretical part.
There are wonderful competitions available on kaggle and other similar data science competition platforms. Hence, make sure you take some time out and jump into these competitions. Whether you are a beginner or a pro, certainly, there is a lot of learning available while attempting these projects.
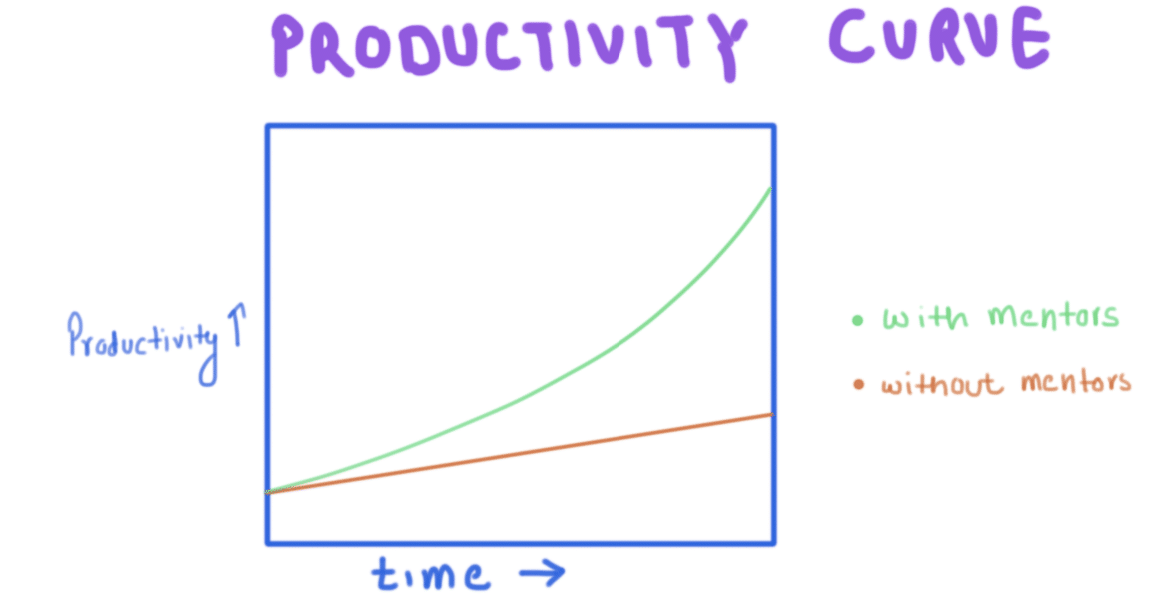
Although Data Science has been around us ever since the 1960s, it has only gained traction in the last few decades. This is one of the main reasons why budding data scientists find it quite challenging to find the right mentors. However, this scenario is drastically changing now. With the right approach and by looking at the right corners, you can find data scientist mentors who can help you bridge the gap between theoretical and practical applications of data science.
In this article, we will be looking at why there is even a need for individuals to have mentors in data science and how can we find them.
Why does one need a mentor in Data Science?
Earlier for data science jobs if you had a technical grad degree, you could brush up on your Python skills, fill a small portfolio with scikit-learn projects, and more or less watch the offers roll in. But this is not the case anymore. Data science industry has made a lot of advancements in a small span of time. These advancements have basically done two things here. First, they have resulted in organizations looking for more than basic skills from the data scientists. Secondly, it has created a huge demand for data scientists which have resulted in a lot of competition between different job seekers
Take you under their wing and help you to stay motivated and discover the path that you may need to take.
Understand what it takes to get to the top and be a valuable resource by answering your career or work related questions and providing good advice.
Help you to be passionate about your success and brand.
Provide you with a wealth of knowledge and resources and help you to connect with various Subject Matter Experts (SMEs).
Be your own personal cheerleader and help you discover new opportunities.
Where to find mentors?
Available Online Courses
Dimensionless Technologies provides best online data science training that provides in-depth course coverage, case study based learning, entirely Hands-on driven sessions with personalized attention to every participant. We provide only instructor-led LIVE online training sessions and not classroom training.
These programs are led by Kushagra (IIT, Delhi – 10+ years experience in Data Science) who is a machine-learning practitioner, fascinated by the numerous application of Artificial Intelligence in the day to day life. He enjoys applying my quantitative skills to new large-scale, data-intensive problems. Also, he is an avid learner, keen to be the frontrunner in the field of AI.
LinkedIn
Learning data science will never be easy without any help from the community or from someone who is willing to help beginners. These someones are the ones that are making up our amazing LinkedIn Data Science Community.
Kate Strachnyi ♕ – If you’re in pursuit of having a data science career and learning data visualization. You must follow her in a heartbeat. Her hashtag#makerovermonday posts are amazing and she shares a lot of information that can help you in your journey.
Randy Lao ☁️ – He has been serving the community from as long as I know there was one for data science in LinkedIn. He shares the best resources for everything in data science. Starting from libraries in Python to courses on machine learning. You will find a lot of useful resources in his posts. Also, check out his collaboration with Kyle.
Kyle McKiou – Top-notch data science influencer. Can’t afford to not follow him if you want to learn from books to pick for data science to interview tips and tricks. Constantly helping beginners with his experience and content.
Mentors at work/college
Experienced working with professional developers can make or break your ability to land a data science position.
The best strategy we’ve found is called income share: basically, aspiring data scientists work with an expert mentor on an industry-level project, and they pay their mentor a small share of their future income in exchange (but only if they actually get hired as a result).
Income share has two benefits: first, it means that you can get expert instruction at no upfront cost. You only pay when you can afford to, and if you don’t get a data science job within a certain time limit (usually 24 months) you don’t pay anything at all.
Second, income share aligns the incentives of the mentors and mentees. Even after the formal mentorship period ends, mentors still have a stake in your future success, which means they’ll look out for opportunities for you by default.
Income share mentorships make new opportunities accessible to people who can’t afford the expert time or find professional data scientists to learn from.
Paid mentorship available at different websites
If you have a disposable income to spend then I’d highly recommend hiring a mentor who can walk you through your problems. When I was just starting to learn data science, I found having a paid mentor (via Thinkful) was incredibly helpful as it allowed me to ask all the dumb questions that I otherwise would’ve been too embarrassed to ask on a community forum.
Learn code & data science 1-on-1 with a mentor
Instant hands-on programming help available 24/7
Clarity – On Demand Business Advice
What if you are not able to find one?
Take ownership of your career
People who think a mentor is a key to success may lack confidence in their own ability to take initiative. Carreau advises taking control of your own growth. “Create your own plan to take control of your career and your life, and rise above the average,” she recommends.”Howard Schultz is a great example of someone from humble beginnings who took control of his destiny early. He has famously said, ‘I had no mentor, no role model, no special teacher to help me sort out my options.
Get value from peers
Even though a mentor is not necessary to success does not mean that you should ignore the opportunity of turning to your peers for guidance. In fact, Carreau advises joining a peer-mentoring group. “The combination of great networking and feedback makes participation in these kinds of circles invaluable, rather than the standard networking coffee meetings between two people,” she stated. “Getting feedback from not just one, but many people is much more valuable, and leads to better solutions and ideas. The dialogue in these groups consistently impresses me. And the business outcomes I see from promotions to career changes to overcoming major career challenges are substantial.
Learn from the youth
As technology continues to accelerate the rate of change, many would-be mentors are finding their approach outdated and obsolete. They find they actually have a lot to learn from younger generations. Instead of using experienced senior leaders as mentors to younger colleagues, some companies are reversing roles. “The younger person becomes the mentor, and the senior professional becomes the mentee,” explains Carreau. “In India, they have found that this concept has re-energized senior professionals and showed them a lot about technology and the social media world we live in today.
Combine activities to maximize time
For real value to take place, mentorship requires focused time, which is a valuable commodity. Carreau recommends looking for ways to combine learning activities to save time and be productive all at once. “Instead of going for a jog and then meeting a friend for coffee, why not go for a jog with your friend?” notes Carreau. “Instead of letting your commute be wasted time, listen to a podcast, relevant news or language tapes. Leveraging the power of multipliers lets you accomplish more by overlaying tasks that make sense together.”
Become a better networker
Building a network is not an intuitive skill for most people. It is also an iterative process; you are never finished, and the way you develop your network will change as your career progresses. When you begin networking, you are still figuring out your interests and career goals,” elaborates Carreau. Because of this, you must cast as large a net as possible among the people you can. Hence you should contact-family friends, school alumni and more. As you understand your ambitions better, you will become a better networker as well. Thus you are able to quickly spot the diamond in the rough among your contacts. You should not focus on networking and wasting your time on superficial contacts. Rather, make ensure you are engaging in an authentic and helpful way with them both online and in person.
Conclusion
Data science is one of the areas where this idea is starting to take off. Data scientists remain rare, and students may find it hard to get access to information. Mentoring bridges that gap and enables students to improve their skills and understanding of using data science in business.
Recommender systems use algorithms to provide users with product or service recommendations. Recently, these systems have been using machine learning algorithms from the field of artificial intelligence. An increasing number of online companies are utilizing recommendation systems to increase user interaction and enrich shopping potential. Use cases of recommendation systems have been expanding rapidly. They across many aspects of eCommerce and online media, and we expect this trend to continue.
Recommendation systems (often called “recommendation engines”) have the potential to change the way websites communicate with users. They allow companies to maximize their ROI based on the information they have on each customer’s preferences and purchases.
In this article, we will be looking upon machine learning methods which provide the personalized experiences. This matters most to the customers on different websites and end-consumers of the different business lines
What is Machine Learning?
Before we begin our journey of understanding how machine learning enhances personalization across various businesses, let us try to get a little idea about machine learning first. Machine learning mainly focuses on the development of computer programs which can teach themselves to grow and change when exposed to new data. Machine learning studies algorithms for self-learning to do stuff. It can process massive data faster with the learning algorithm.
Data is growing day by day, and it is impossible to understand all of the data with higher speed and higher accuracy. More than 80% of the data is unstructured that is audios, videos, photos, documents, graphs, etc. Finding patterns in data on planet earth is impossible for human brains. The data has been very massive and the time taken to compute would increase only. This is where Machine Learning comes into action, to help people with significant data in minimum time.
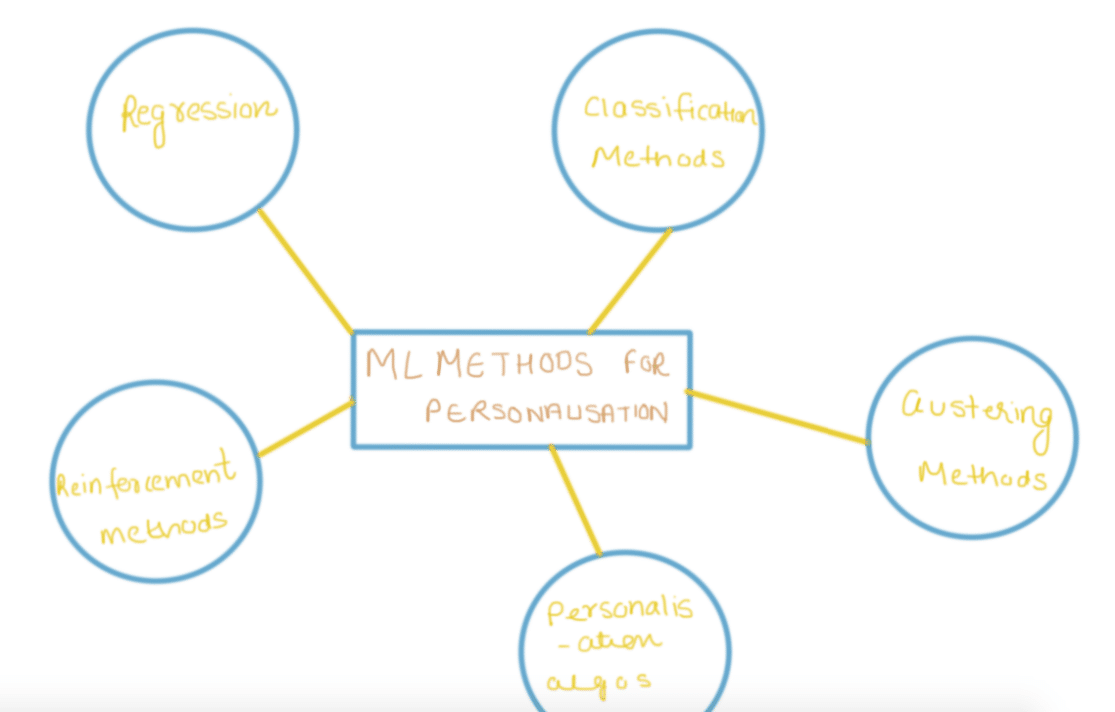
ML methods for personalization
In this section, we will introduce you to different techniques in machine learning that can help in the personalization of your business services for your end user. User experience and conversion(eventually) are the prime goals of a business. The following algorithms are the means which will help you in achieving personalization
Regression
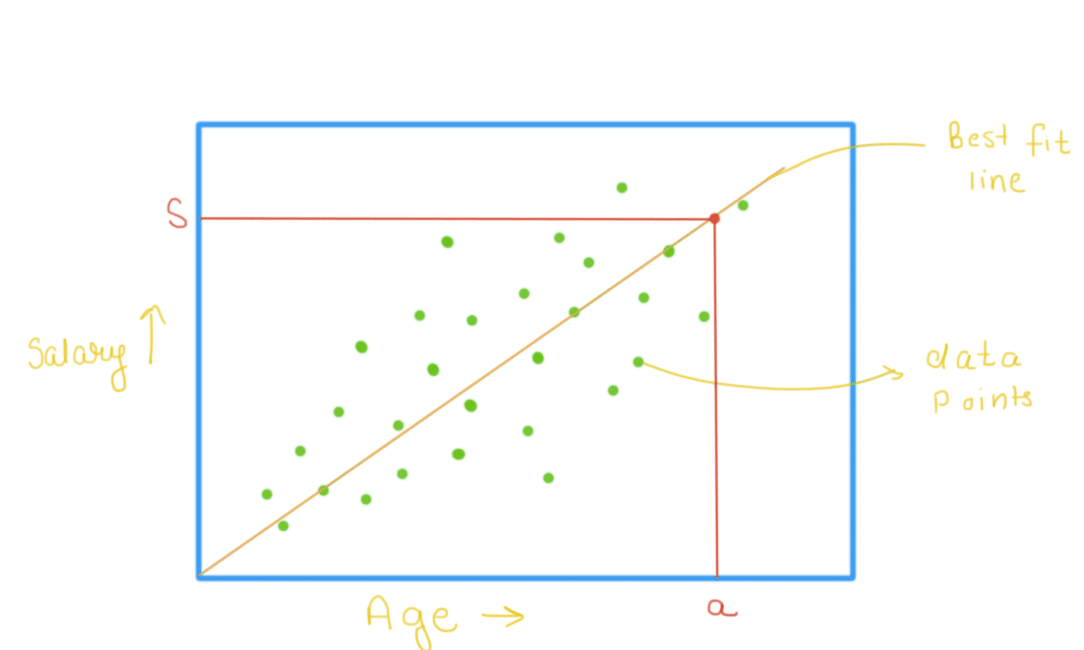
Regression analysis is a form of predictive modeling technique which investigates the relationship between a dependent and independent variable. Regression(linear) aims at finding a straight line which can accurately depict the actual relationship between the two variables.
Regression can help finance and investment professionals as well as professionals in other businesses. Regression can help predict sales for a company based on weather, previous sales, GDP growth or other conditions. The capital asset pricing model (CAPM) is an often-used regression model in finance for pricing assets and discovering costs of capital. The general form of each type of regression is:
Linear Regression: Y = a + bX + u
Where:
Y = the variable that you are trying to predict (dependent variable)
X = the variable that you are using to predict Y (independent variable)
a = the intercept
b = the slope
u = the regression residual
Let us take one example here. A firm X is trying to predict the salary of individuals using their age as the deciding parameter. One can plot all the available data points and find out a “best-fit line” which will describe the relationship between your age and salary parameter. In the following picture, green dots are all the available data points and the straight line passing through these points is the best fit line. Using this line, we can make predictions of salary for the other customers. Say we want to predict the salary of a person with age a. Using the best fit line, we will look at the corresponding value of salary when age is a(given parameter). Using such predictions, businesses like retail can offer different products(based on pricing) to different customers in personalizing their experience on the platform
Classifiers
In machine learning and statistics, classification is an important supervised learning approach in which the computer program learns from the data input given to it and then uses this learning to classify new observation. This data set may simply be bi-class (like identifying whether the person is male or female or that the mail is spam or non-spam) or it may be multi-class too. Some examples of classification problems are speech recognition, handwriting recognition, biometric identification, document classification etc.
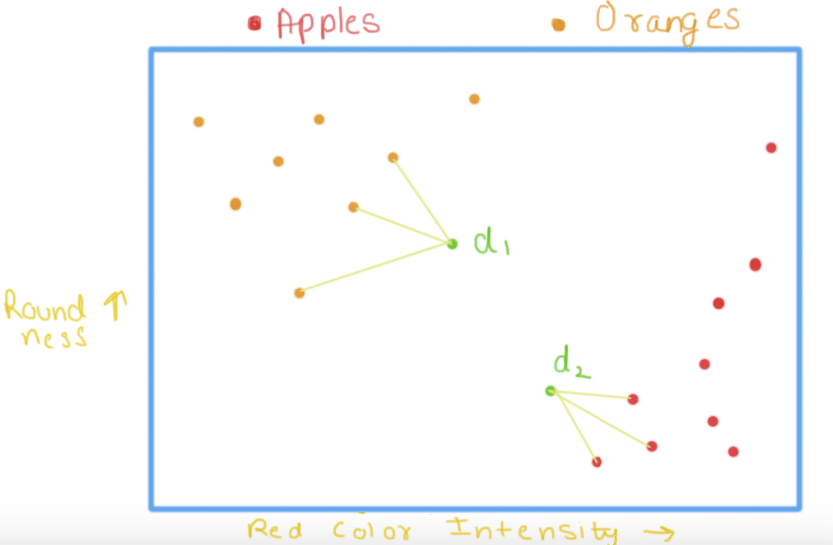
K-Nearest Neighbors is one of the most basic yet essential classification algorithms in Machine Learning. It belongs to the supervised learning domain and finds intense application in pattern recognition, data mining and intrusion detection.
Let us take an illustration here. Suppose you want to classify apples from oranges. Our data contains 2 parameters i.e. roundness of fruit and intensity of the red color of the fruit. We then proceed to plot them. As we can see, the upper left corner contains the oranges(one with less red color intensity and more roundness) and lower right contain all the data points that represent an apple. Suppose we have a fruit whose roundness and red color intensity we know, say d1 and d2. We check the nearest neighbors of d1 and d2 and assign the class accordingly to the new data points. Nearest points to d1 are all oranges hence d1 is classified as an orange and closest points to d2 are all apples hence d2 is classified as apple.
Classification techniques are used when we have a set of predefined classes for personalization scheme. Suppose we want to classify customers on the basis of movie categories they watch on Netflix to provide movie recommendations from that particular genre, then classification techniques come really handy!
Clustering Methods
Clustering is one of the most important unsupervised learning problems; so, like every other problem of this kind, it deals with finding a structure in a collection of unlabeled data.
A loose definition of clustering could be “the process of organizing objects into groups whose members are similar in some way”.
A cluster is, therefore, a collection of objects which are “similar” between them and are “dissimilar” to the objects belonging to other clusters.
The goal of clustering is to determine the intrinsic grouping in a set of unlabeled data. But how to decide what constitutes a good clustering? It can be shown that there is no absolute “best” criterion which would be independent of the final aim of the clustering. Consequently, it is the user which must supply this criterion, in such a way that the result of the clustering will suit their needs.
For instance, we might need to find representatives for homogeneous groups (data reduction), in finding “natural clusters” and describe their unknown properties (“natural” data types), in finding useful and suitable groupings (“useful” data classes) or in finding unusual data objects (outlier detection).
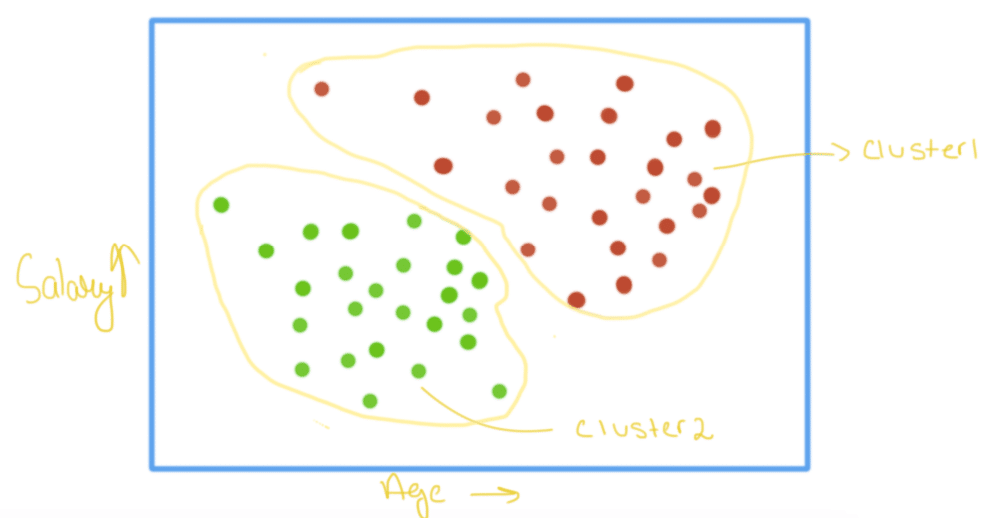
Given below is an age vs salary plot, where we can identify two sets of individuals in the data. One set is those who are younger in age and purchased the new budget smartphone whereas another cluster represents the people who are much more mature and earning high salaries but didn’t buy the product. It was easily inferred that the product was hit among the younger generation with income falling in the middle-class level
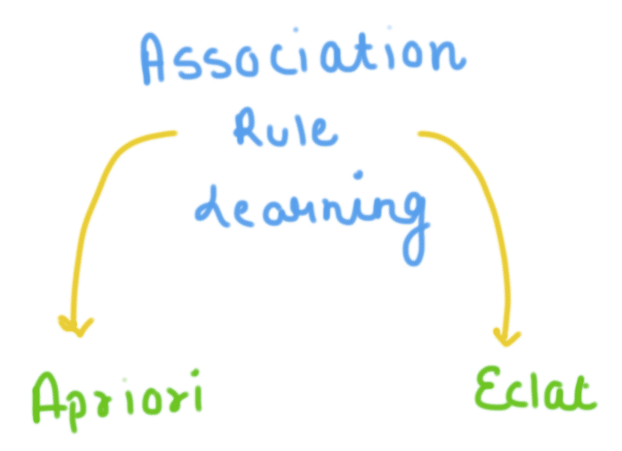
Association Rule Learning Methods
In basic terms, association rules present relations between items. They are statements that help to discover relationships between data in a database. An association rule is an implication of the form A → B. Here ‘A’ is a premise, which represents a condition that must be true for ‘B’ to hold. ‘B’ is a conclusion that happens when ‘A’ is true. An antecedent is an element found in data whereas a consequent is found in combination with the antecedent.
It is a popular technique for uncovering interesting relationships between different variables in huge databases. The association rules are suitable to build recommendation engines, like those of Amazon or Netflix. Simply put, this method allows one to thoroughly analyze the items bought by different users. With this analysis, one can easily find relations between them
To understand the strength of associations among these transactions, the algorithm uses various metrics:
Support helps to choose from billions of records only the most important and interesting itemsets for further analysis. You can set a specific condition here, for example, analyze itemsets that occur 40 times out of 12,000 transactions.
Confidence tells us how likely a consequent is when the antecedent has occurred. Example — how likely it is for a user to buy a biography book of Agassi when they’ve already bought that of Sampras.
Lift controls the consequent frequency to avoid a negative dependence or a substitution effect. The rule may show a high confidence value for products that have a weak association. The lift considerst the support of both antecedent and consequent to calculate the conditional probability and avoid fluke.
Reinforcement Methods
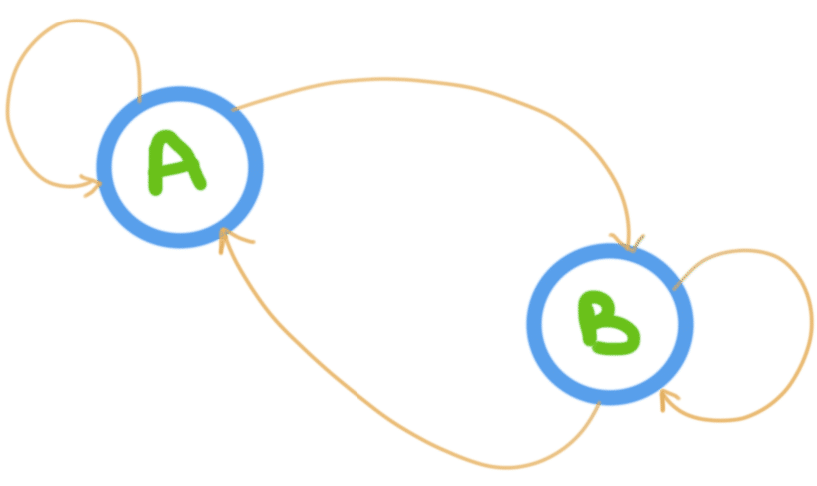
A Markov chain is a mathematical system that experiences transitions from one state to another according to certain probabilistic rules. The defining characteristic of a Markov chain is that no matter how the process arrived at its present state, the possible future states are fixed. In other words, the probability of transitioning to any particular state is dependent solely on the current state and time elapsed. The state space, or set of all possible states, can be anything: letters, numbers, weather conditions, baseball scores, or stock performances.
Markov chains are similar as finite state machines, and random walks provide a prolific example of their usefulness in mathematics. They arise broadly in statistical and information-theoretical contexts. Their application lies in economics, game theory, queueing (communication) theory, genetics, and finance. While it is possible to discuss Markov chains with any size of state space, the initial theory and most applications should focus on cases with a finite (or countably infinite) number of states.
Considering the fact that Markov chains make use of just real-time data without taking into account historical information, this method is not one-size-fits-all. An example of a good use case is PageRank, Google’s algorithm that determines the order of search results.
However, when building, for instance, an AI-driven recommendation engine, you’ll have to combine Markov chains with other ML methods, including the above-mentioned ones. To wit, Netflix uses a slew of ML approaches to providing users with hyper-personalized offerings.
Conclusion
In this blog, we looked at different techniques in ML through which one can provide personalization to end users of their respective businesses. Consumers are connecting with brands via multiple channels, which means retailers must do more to drive customer loyalty. Marketing teams need to harness actionable insights from the multiple data channels available to them to create engaging and relevant conversations with the customers. The more personalized the experience, the happier the customer.
The advent of Cloud computing has made it possible for many organizations to rapidly scale their current analytics operations. It involves very little maintenance overhead. This has, in turn, created a need to build strategies for migration to the Cloud. In this blog, we will discuss the various factors to consider while evaluating different Cloud technologies.
What is cloud computing?
Cloud Computing is an Information Technology (IT) paradigm that enables ubiquitous access to shared pools of configurable system resources. It also provides higher-level services that can be rapidly provisioned with minimal management effort, often over the Internet. Cloud Computing relies on the sharing of resources to achieve coherence and economy of scale, similar to a utility. By using a Cloud-based solution for computing, organizations can significantly reduce their IT infrastructure. It costs while focusing on their core business.
Advantages of cloud computing
Scalability
With the advent of Cloud infrastructure, it has become virtually effortless to scale an organization’s infrastructure up or down. This is due to the infrastructure essentially being the responsibility of the Cloud service provider. The customer only needs to specify the required configuration of the application or service without worrying about procuring the necessary infrastructure.
Reliability
Since cloud providers handle the infrastructure and its maintenance, any periodic or immediate maintenance activities adhere to the predefined SLA, essentially creating a highly reliable system.
High availability
Providers generally have servers located in physical locations across the world and ensure highly available data and services through multiple replication strategies.
Reduced operational costs
When opting for a Cloud vendor, the infrastructure becomes their responsibility hence eliminating the most cost associated with operations/maintenance for the customer. This pulls the cost down to virtually zero.
Increased IT effectiveness
The IT team is now able to focus solely on software development without worrying about hardware limitations or maintenance. The utopia of building a platform with almost no hardware constraints allows for more robust platform development. It also increases overall effectiveness
Cloud services providers
Amazon Web Services Amazon Web Services, commonly referred to as AWS, was the starting point for the Cloud Computing paradigm with its launch of EC2 compute instances in 2006. AWS has documented all the services very well and seamlessly integrate with other provided services at almost zero cost for transfer of data between services. AWS is cost-effective, highly scalable with high availability. It provides spawning and allows for usage of services both programmatically and through the UI console. AWS comprises of more than 90 different services, spanning a wide range of use cases including computing, storage, networking, database, analytics, application services, deployment, management, mobile, developer tools, and tools for machine learning and the Internet of Things.
Google Cloud Platform
Google Cloud Platform, also known as GCP, is built with power and simplicity in mind. GCP offers services which can seamlessly integrate with other Google products, providing access to a wide range of services in the domain of computing, data storage, data analytics, and machine learning. It also has a wide set of management tools which work on top of these services.
Where is the difference?
As cloud computing continues to find its way into MNC big and small, the choice of the right cloud computing solution has become a talking point for specialists and business owners alike. Among public cloud providers, Amazon Web Services (AWS) seems to have the lead in the competition, with Google Cloud and Microsoft Azure close behind.
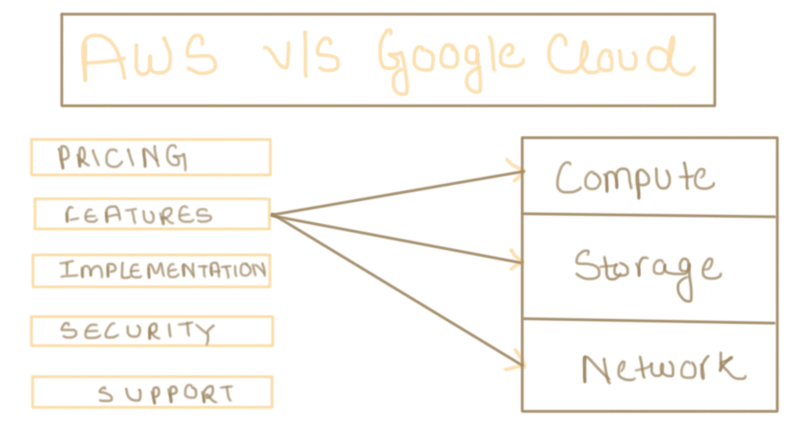
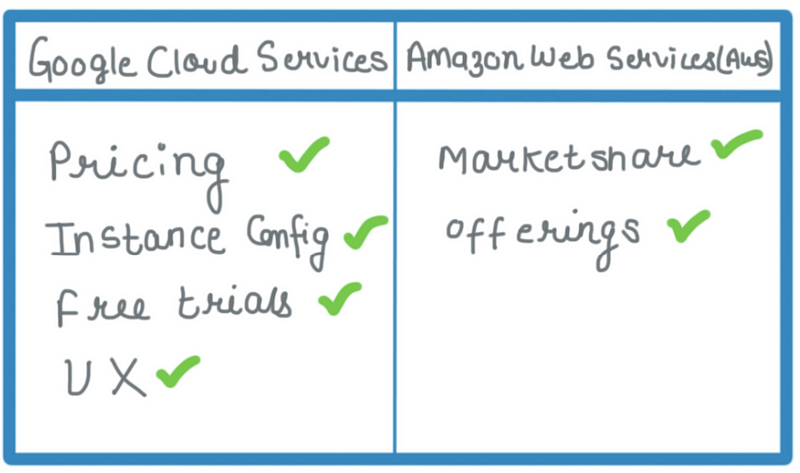
Let us focus on some key differences between Google cloud services and AWS. We can differentiate between both of them based upon
Pricing
Features
Implementation
Security
Support
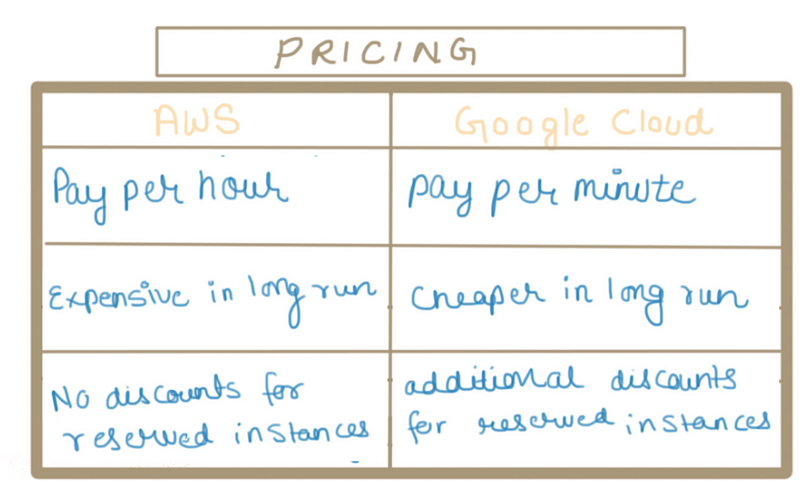
Pricing
When comparing Google Cloud vs AWS, both handle billing differently. And to be honest, neither of them provide a very straightforward way of easily calculating this unless you are very familiar with the platforms. More generally a difference in pricing is not much but google cloud services can turn out to be a tad cheaper in long run!
Google’s Cloud is a winner when it comes to computing and storage costs. For example, a 2 CPUs/8GB RAM instance will cost $69/month with AWS, compared to only $52/month with GCP (25% cheaper). As for cloud storage costs, GCP’s regional storage costs are only 2 cents/GB/month vs 2.3 cents/GB/month for AWS. Additionally, GCP offers a “multi-regional” cloud storage option, where the data is automatically replicated across several regions for the very little added cost (total of 2.6 cents/GB/month).
Here are their monthly calculators if you’re just starting:
Estimating monthly spend with both of these cloud providers can be a challenge. There are even entire tools out there such as reOptimize or Cloudability which were built to help you understand your bills better. Essentially AWS offers you a dashboard which provides insights into your bill. Google Cloud Platform provides estimated exports via their BigQuery tool. However, both providers are doing things to decrease costs and make billing easier.
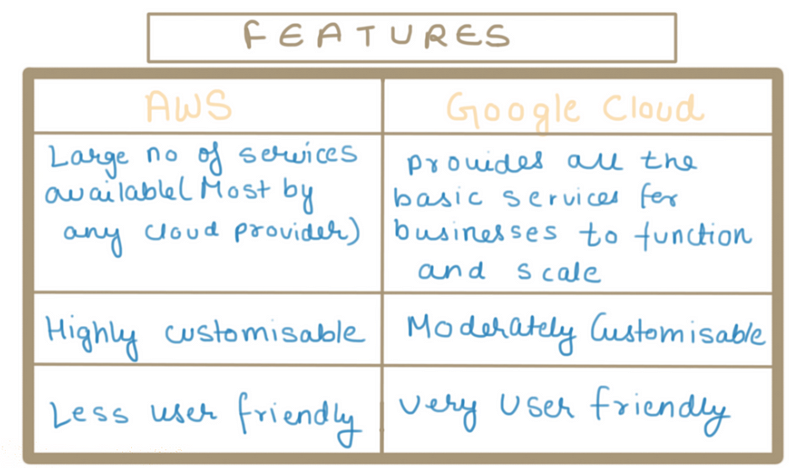
Features
In this parameter, we will divide features into 3 major parts which are most essentially used. On those features, we will try to list out differences between Google cloud and AWS.
Let us also have a look at the 3 most common services provided by both of them
Compute: The first category is how Google Compute Engine and AWS EC2 handle their virtual machines (instances). The technology behind Google Cloud’s VMs is KVM, whereas the technology behind AWS EC2 VMs is Xen. Both offer a variety of predefined instance configurations with specific amounts of virtual CPU, RAM, and network. However, they have a different naming convention, which can at first be confusing. Google Compute Engine refers to them as machine types, whereas Amazon EC2 refers to them as instance types.
Storage: One of the most common use cases for public IaaS cloud computing is storage and that’s for good reason: Instead of buying hardware and managing it, users simply upload data to the cloud and pay for how much they put there.
Networking: Google Cloud and AWS both utilize different networks and partners to interconnect their data centres across the globe and deliver content via ISPs to end users. They offer a variety of different products to accomplish this.
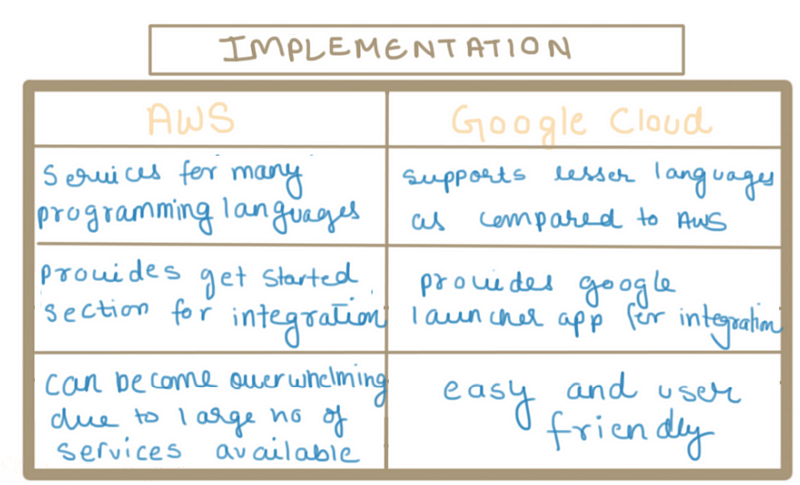
Implementation
AWS provides a nice and easy page to start using their services.
You can see that they break it down by the platform you wish to work on, so whether you are making an iOS app, or writing in PHP, they provide some sample code to begin the integration.
Lastly, we have the process of starting with Google — named ‘Cloud Launcher’.
They equally provide some starting documentation and list some useful benefits
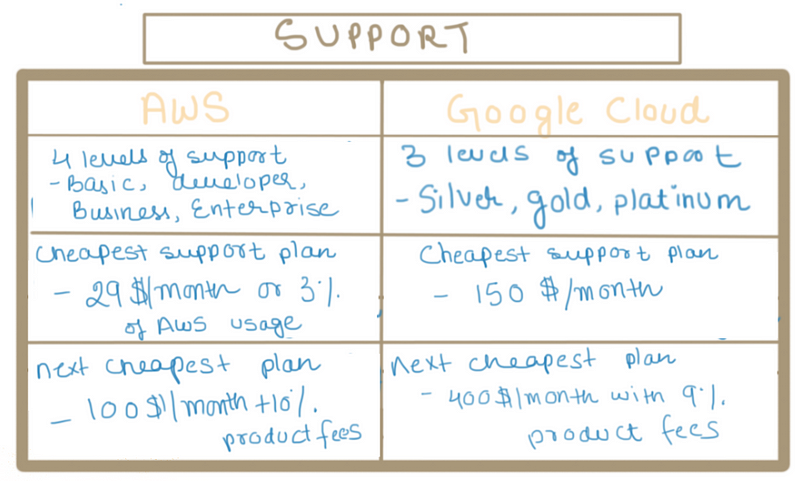
Support
Both Google Cloud and AWS have extensive documentation and community forums which you can take advantage of for free.
However, if you need assistance or support right away, you’ll have to pay. Both Google Cloud and AWS have support plans, but you’ll definitely want to read the fees involved as they can add up quite fast. Both providers include an unlimited number of account and billing support cases, with no long-term contracts.
Cheapest support plan, Silver, starts at $150/month minimum
The next level support plan, Gold, starts at a $400/month minimum, but at this level, GCP will bill you a minimum of 9% of product usage fees (decreases as spend increases)
Cheapest paid support plan, Developer, starts at $29/month or 3% of monthly AWS usage
The next level support plan, Business, starts at a $100/month minimum, but at this level, AWS will bill you a minimum of 10% of product usage fees (decreases as spend increases)
Security
In their Second Annual Cloud Computing Survey (2017), Clutch surveyed 283 IT professionals at businesses across the United States that currently use a cloud computing service. In regards to security, they found that almost 70% of professionals were more comfortable storing data in the cloud than their previous legacy systems.
All the data stored on EC2 instances is encrypted under 256-bit AES. Each encryption key is also encrypted with a set of regularly changed master keys.
Network firewalls built into Amazon VPC, and web application firewall capabilities in AWS WAF let you create private networks. They control access to your instances and applications.
AWS Identity and Access Management (IAM), AWS Multi-Factor Authentication, and AWS Directory Services allow for defining, enforcing, and managing user access policies.
AWS has audit-friendly service features for PCI, ISO, HIPAA, SOC and other compliance standards.
All the data stored on persistent disks and is encrypted under 256-bit AES and each encryption key is also encrypted with a set of regularly changed master keys. By default.
Commitment to enterprise security certifications (SSAE16, ISO 27017, ISO 27018, PCI, and HIPAA compliance).
Only authenticated and authorized requests from other components that coming to Google storage stack are required.
Google Cloud Identity and Access Management (Cloud IAM) was launched in September 2017 to provide predefined roles that give granular access to specific Google Cloud Platform resources and prevent unwanted access to other resources.
Conclusion
After going through different aspects and components of cloud services, we can form a conclusion that
Electronic video gaming has extended from being a hobby into a serious sport and business. Earlier this year, eSports officially became a medal event in the 2022 Asian Games. According to data analytics expert Andrew Pearson, the rise of eSports presents exciting opportunities in data analytics and marketing.
There’s been an explosive growth in esports popularity over recent years, fuelled by games specifically designed with online competition in mind. Blizzard’s Overwatch is a case in point. When the Overwatch League debuted in January 2018, 415,000 viewers tuned in to watch.
The stakes are high. Each team in the Overwatch League stumped up $20 million (£14.4 million) for a city franchise. Participating gamers enjoy $50,000 (£36,000) salaries while competing for a prize pool totaling a cool $3.5 million (£2.5 million).
AI and ESPORTS
Just as data analytics is helping golfers, athletes, F1 teams, football clubs and cricketers improve their performance, esports is well-placed to follow suit. As with any sport, winning doesn’t just hinge on skill, dedication and luck. It’s often determined by strategy and the analysis of past performance. The secrets to success lie in data and esports is overflowing with it.
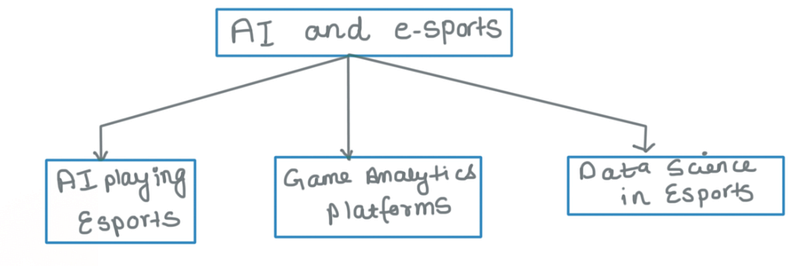
We can divide the idea of AI and Esports into 3 different aspects or perspectives. It can be as AI playing gaming sports themselves, game analytics platforms to provide the insights and details about the players and their gaming behavior and tactics and lastly, data science in the gaming industry to manage the business side of the games as products
Let us have a look at each of the aspects and discuss them in detail one by one!
ESPORTS by AI
Gamers have been pitting their wits and skill against computers since the earliest days of video games. The levels of difficulty were pre-programmed, and at a certain point in the game, the computer was simply unbeatable by all but the most gifted gamers.
Over time, the concept of difficulty levels evolved. For example, “Madden” NFL Football games have four different levels (ranging from Rookie to All-Madden) that make running plays more difficult, while first-person shooter (FPS) games like “Duke Nukem 3D” follow the same type of tiered difficulty (ranging from Piece of Cake to Damn, I’m Good) that makes it tougher to stay alive and kill enemies.
The rise of machine learning combined with the increasing popularity of esports (organized, multiplayer video game competitions that feature professional video gamers gaming against each other with millions of dollars of prize money on the line), may inextricably link AI to gaming and esports.
That said, the most common implementation of AI in esports is in the games themselves. Companies like AI Gaming want to develop smarter AI bots that would compete against each other in an effort to grow smarter and more competitive, while OpenAI, a research lab co-founded by Elon Musk, developed AI that can beat the top 1% of Dota 2 amateurs (though the AI lost a best-of-three match to some of the game’s best players in August 2018).
DeepMind’s AlphaGo used some surprising tactics while playing against Lee Sedol. People thought these wouldn’t actually work, but they did. A similar discovery of new tactics and strategies can happen in eSports. Players will have to re-think their every move while playing. Situations like these will give them insight that might not have been possible.
CSGO has a ‘6th man’ setup where an observer advises the players on their strategies. A bot can instead replace the ‘6th man’, a form of ‘Augmented advising’. Teams will have to augment the bot’s recommendations into their gameplay. Teams who do this well will be the winners. Since a lot of machine learning algorithms are democratized there won’t be a situation where teams are unfairly matched.
Like I mentioned earlier StarCraft II is a game with quite a bit of strategic depth. This also makes the game more difficult for new-comers. The presence of an in-game coach would be helpful. It would speed up the process of getting started on the game and decrease the learning time.
ESports at the end of the day is a form of sports. People tune in from all over the world to watch their favourite teams play and cheer for them. Only this time, they’ll be rooting for 5 players and a bot.
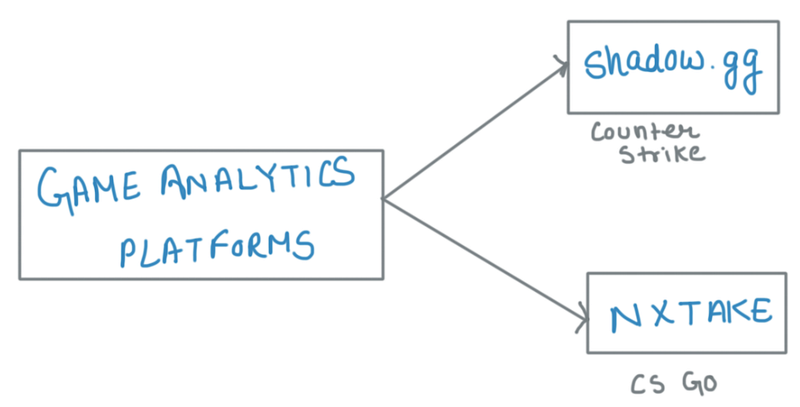
Game analytics platforms
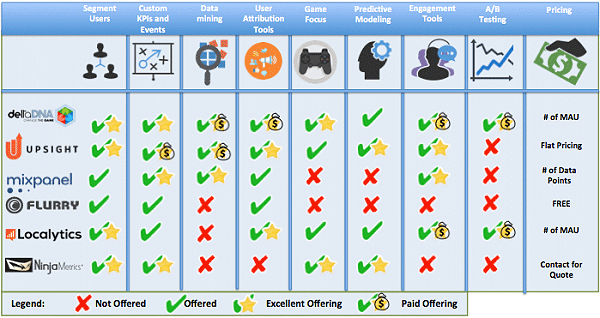
Shadow GG
Shadow.gg — a Counter-Strike analytics platform that its creators claim will cause a significant leap in how esports professionals currently approach preparing for a match by giving fast and easy access to a large number of in-game statistics for any match in the platform’s library. Built primarily for teams looking for a competitive edge, the tool aims to help scout opponents, quickly view data, and visualize that data in meaningful ways. It lessens the burden on coaches and analysts to scout demos and lets your coaches, analysts, and players focus on only important rounds.
The core value proposition here is that coaches and players that use this tool will be able to arrive at conclusions about their opponents’ play, and their own play, that is either too time intensive to arrive at through basic demo review, or simply can’t be reasoned about by trying to estimate data from observing matchplay. We can begin identifying trends for teams and players with regards to their tendencies in relation to the economic context, or how they utilize grenades, or how they prefer to retake a particular site, to name a few.
Obviously players still have to hit their shots in-game, and that’s on them; but going into a match armed with detailed information about which way your opponent leans in crucial situations could mean the difference between a comfortable win or a 16:14 loss; so we hope the value of the tool today and where we plan to take it over the next year will become rather self-evident.
NXTAKE — Advanced CSGO Analytics
Built by former daily fantasy sports professionals, NXTAKE is a leader in esports analytics and broadcast augmentation. Our company specializes in advanced analytics, data feeds, and esports prediction models. NXTAKE combines big data and simulation to bring next level analytics to the world of esports. Together, we have wagered enormous amounts of capital over the past few years and are sharing our expertise in a new and exciting industry. It can provide real-time analysis, coupled with live streams
Data science in esports
Targetting new gamers using data analytics
One of the best examples of data science in this area, customer “segmentation.”
This is a HIGHLY desired function within digital marketing because it’s the analysis of your existing and potential markets in an effort to better understand customers.
Doing this exercise, you can take in vast amounts of data from dozens of data sources (web, social, email, forums, media listening, etc) and feed it into statistical models to extract customer segments, like “your potential target market for your new game consists of those that classify themselves as hardcore gamers between the ages of 14 and 31 years old, that play RPGs like Skyrim, and that average a GTX 1070 GPU.”
What you can then do with this information, is to apply that segment to paid advertising strategies. So, when you start the pre-order push, you can make sure that your digital ads are targeted at the people that you were able to isolate to that segment, and not blasted to that CS: GO player that doesn’t like RPGs.
Competitive game pricing
The goal of an effective BI system in the gaming industry must be able gathering gamer data from several types of external sources, and comparing that data with data in internal systems to arrive at conclusive decisions about a customers spending pattern, tastes and levels of satisfaction. A large part of the data analyzed in this case may large volumes of unstructured, social-media data.
Improving gameplay experience
Insights from gaming analytics also enable companies to improve the gameplay itself. For example, millions of player records could be analyzed to pinpoint the most likely in-game moments when players quit the game entirely; perhaps a series of quests are too boring or the challenges are too hard/easy based on character level. Identifying these gaming “bottlenecks” is critical to understanding the reasoning & timing behind a game’s churn rate. Gaming Designers and Developers can then re-examine the game’s storylines, quests, and challenges in order to refine the gaming experience and, hopefully, reduce the number of lost subscribers.
Analyzing the devices used by players also helps developers to create gaming experiences that work effectively for their user base. Exploring a dungeon via an iPhone is quite different than doing it using a widescreen attached to a laptop, so developers need to address issues such as screen size, available functionality, navigation, and character interactions. Data analytics empowers companies to address this challenge by modeling and visualizing massive amounts of heterogeneous data.
Game analytics to improve gaming infrastructure
Today, games sometimes have global player bases… so the architecture supporting those users needs to be configured and implemented correctly. Online games are particularly prone to network-related metrics, such as ping and lag rates — these issues are exacerbated during peak gaming times. Again, Big Data analytics enables gaming companies to use server and network data to understand exactly when, and how, their infrastructure is being pushed to its limits. This knowledge enables companies to scale up or down according to player need; in today’s world of cloud-based PaaS/IaaS architectures (where cost is tied to usage), this information can have a dramatic impact on a company’s bottom line.
Analysing competitors
Make a list of games that are using the same theme and some (or all) of your core mechanics. Both released and upcoming. Especially upcoming, because chances are you’ll be judged against them.
Make a basic SWOT analysis for every one of them, but also add an additional field: “How is our game different?” The key word here is “different”, not “better”, so you won’t get caught in wishful thinking “we’ll have better graphics and better balance”. Why your target audience should consider your game instead of another one? People only have so much time to play.
You can also check geographical distribution and stats for released games on Steam Spy or AppAnnie, but, frankly, it’s not that useful at this stage. You’ll look into it later when deciding on focusing your marketing and localization efforts.
If you’ll decide to check geo distribution for similar games, don’t trust it too much — an audience research you did previously will be more helpful. Other games might’ve done something specific to become popular in some countries, like partnering with a local publisher or getting a good video from a local YouTube celebrity.
For example, there aren’t many owners of The Witcher 3 from Poland on Steam despite the game being immensely popular in that country. That’s because most Poles bought the game from CDP.pl or GOG.com instead of going for much more expensive Steam version.
Conclusion
The gaming industry has a long way to go when we talk about the application of full-fledged data science in its applications or AI bots beating world class players in the complex games like counter strike and DOTA. In this blog too, we looked at how different aspects of data sciences are applied in the gaming industry. But what is clear at this point is the power of AI and the myriad companies looking to harness the same. Gaming appears to be poised as a sector ripe for this type of disruption and companies are getting in early to explore the types of ways to profit off of connecting AI developments with esports.