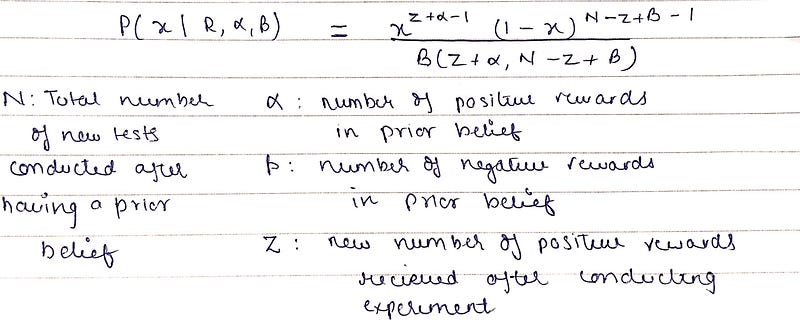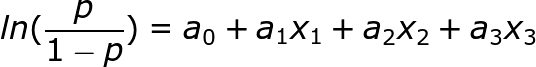In this blog we will try to get the basic idea behind reinforcement learning and understand what is a multi arm bandit problem. We will also be trying to maximise CTR(click through rate) for advertisements for a advertising agency.
Article includes:
1. Basics of reinforcement learning
2. Types of problems in reinforcement learning
3. Understamding multi-arm bandit problem
4. Basics of conditional probability and Thompson sampling
5. Optimizing ads CTR using Thompson sampling in R
Reinforcement Learning Basics
Reinforcement learning refers to goal-oriented algorithms, which learn how to attain a complex objective (goal) or maximise along a particular dimension over many steps; for example, maximise the points won in a game over many moves. They can start from a blank slate, and under the right conditions, they achieve superhuman performance. Like a child incentivized by spankings and candy, these algorithms are penalized when they make the wrong decisions and rewarded when they make the right ones — this is reinforcement.
Reinforcement Learning is the science of making optimal decisions.
Let us understand this by an example. Suppose there is a robot which is learning to walk. If it takes a big step, it will fall down. Next time if it takes a smaller step then it is able to hold the balance. The robot tries variations like this many times and learns to walk steadily. The robot has succeeded.
What we see here is called reinforcement learning. It directly connects a robot’s action with an outcome, without the robot having to learn a complex relationship between its activities and results. The robot learns how to walk based on reward (staying on balance) and punishment (falling). This feedback is considered “reinforcement” for doing or not doing an action.
How is reinforcement learning different from machine learning?
Machine learning is often split between three main types of learning: supervised learning, unsupervised learning, and reinforcement learning.
The Big Picture
The type of learning is defined by the problem you want to solve and is intrinsic to the goal of your analysis:
You have a target, a value or a class to predict. For instance, let’s say you want to predict the revenue of a store from different inputs (day of the week, advertising, promotion). Then your model will be trained on historical data and use them to forecast future revenues. Hence the model is supervised, it knows what to learn.
You have unlabelled data and looks for patterns, groups in these data. For example, you want to cluster to clients according to the type of products they order, how often they purchase your product, their last visit, … Instead of doing it manually, unsupervised machine learning will automatically discriminate between different clients.
You want to attain an objective. For example, you want to find the best strategy to win a game with specified rules. Once these rules are specified, reinforcement learning techniques will play this game many times to find the best strategy.
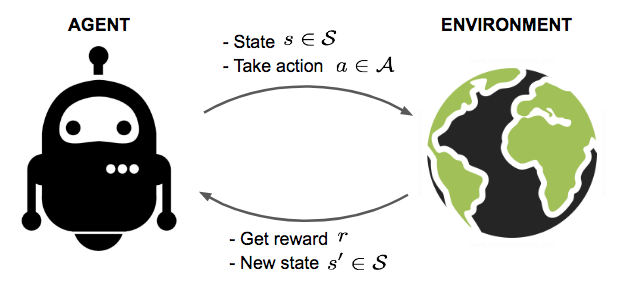
Reinforcement learning algorithms try to find the best ways to earn the greatest reward. Rewards can be winning a game, earning more money or beating other opponents. They present state-of-art results on very human task, for instance. There are three basic concepts in reinforcement learning: state, action, and reward.
Agent
It is an actor which interacts with the environment and accomplishes the task. In the previous example, the robot which is learning to walk is the agent
State
The state describes the current situation. For a robot that is learning to walk, the state is the position of its two legs.
Action
The action is what an agent can do in each state. Given the state, or positions of its two legs, a robot can take steps within a certain distance. There are typically finite (or a fixed range of) actions an agent can take. For example, a robot stride can only be, say, 0.01 meter to 1 meter.
Reward
When a robot takes an action in a state, it receives a reward. Here the term “reward” is an abstract concept that describes feedback from the environment. A reward can be positive or negative. When the reward is positive, it is corresponding to our normal meaning of reward. When the reward is negative, it is corresponding to what we usually call “punishment.”
There are generally 3 fundamental problems we deal with in the reinforcement learning.
The problem of exploration versus exploitation
The exploration-exploitation trade-off is a fundamental dilemma whenever you learn about the world by trying things out. The dilemma is between choosing what you know and getting something close to what you expect (‘exploitation’) and choosing something you aren’t sure about and possibly learning more (‘exploration’).
Exploration is related to global search as well as exploitation is related to local search. In the first one, we are interested in exploring the search space looking for good solutions, whereas in the second one we want to refine the solution and try to avoid big jumps on the search space.
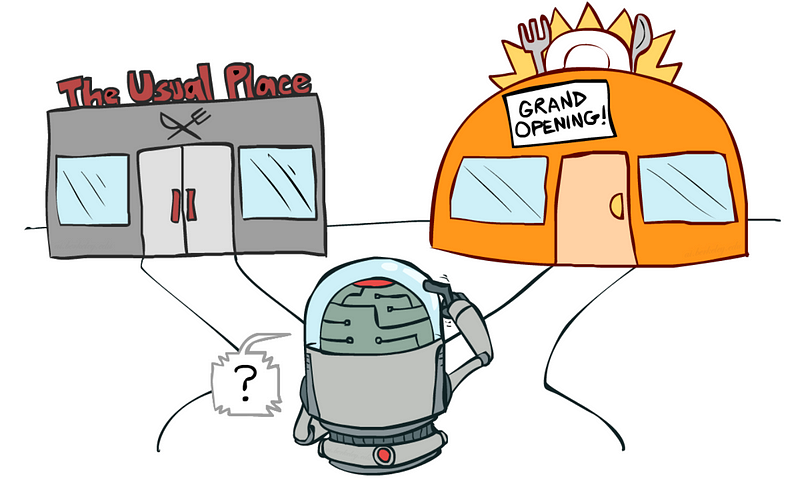
Example: Suppose you are at your favourite food joint which serves you your favourite chicken burger whose taste you are quite familiar with. One day, you find some other restaurants nearby who also serve your favourite chicken burger. What will you do here? Will you stay with the previous restaurant and have your burger whose taste you are quite sure of (exploitation) or you try out a different restaurant (exploration) only to realise that they server much better burgers as compared to previous one.
2. The problem of delayed reward
“Real” reinforcement learning, or the version used as a machine learning method today, concerns itself with the long-term reward, not just the immediate reward.
The long-term reward is learned when an agent interacts with an environment through many trials and errors. The robot that is running through the maze remembers every wall it hits. In the end, it remembers the previous actions that lead to dead ends. It also remembers the path (that is, a sequence of actions) that leads it successfully through the maze. The essential goal of reinforcement learning is learning a sequence of actions that lead to a long-term reward. An agent learns that sequence by interacting with the environment and observing the rewards in every state.
3. Generalisation problems
There will be many learning problems in the world in which going through every possible state is not possible. Suppose in the previous example if instead of 3 or 4, you have an option of exploring 2,000,000 other restaurants, will you be able to visit every possible restaurant? Maybe not. Maybe you will try to generalize them using different criteria, for example, saying restaurants in region A serves better burgers than restaurants in region B. Here we are generalizing some of the states (visiting a restaurant) which we may not actually visit ever or are even hidden.
In this article, we will be focusing on the problem based on exploration vs exploitation. One such problem is Multi-arm bandit problem.
What is a multi-arm bandit problem?
The multi-armed bandit problem is a classic problem that well demonstrates the exploration vs exploitation dilemma. Imagine you are in a casino facing multiple slot machines and each is configured with an unknown probability of how likely you can get a reward for one play. The question is: What is the best strategy to achieve the highest long-term rewards?
They are called “bandits” as these machines at casino loot away money from the people in most of the cases.
A naive approach can be that you continue playing with one machine for many many rounds so as to eventually estimate the “true” reward probability according to the law of large numbers. However, this is quite wasteful and surely does not guarantee the best long-term reward.
Multi-Armed Bandit Example
A news website has to make a decision about which articles to display to a visitor. With no information about the visitor, all click outcomes are unknown. The first question is, which articles will get the most clicks? And in which order should they appear? The website’s goal is to maximise engagement, but they have many pieces of content from which to choose, and they lack data that would help them to pursue a specific strategy\
A drug company needs to provide the best medicine to set of patients. The company needs to find the best set of patients for the particular drug and at the same time making sure of the case that it is wrongly administered to as a small set of people as possible
Defining a multi-arm bandit problem
A Bernoulli multi-armed bandit can be described as a tuple of ⟨A, R⟩, where:
We have K machines with reward probabilities, {θ1,…,θK}.
At each time step t, we take an action an on one slot machine and receive a reward r.
A is a set of actions, each referring to the interaction with one slot machine. The value of action a is the expected reward, Q(a)=E[r|a]=θ. If action a at the time step t is on the sixth machine, then Q(at)=θi.
R is a reward function. In the case of Bernoulli bandit, we observe a reward r in a stochastic fashion. At the time step t, rt=(at)rt=R(at) may return reward 1 with a probability Q(at)Q(at) or 0 otherwise.
3 Strategies to solve multi-arm bandit problem
No exploration/Random Selection
Here we may select any slot machine at random and obtain a reward from it. This is the most naive and bad approach
Exploration at random
In this case, we try to explore first by trying out different slot machines and then shift to an exploitation mode based upon rewards received from our exploration. While doing constant exploitation, we keep a small probability aside for selecting some other slot machine rather than current winner to look for better rewards
Exploration smartly with preference to uncertainty
Rather than leaving the exploration mode completely in hands of a fixed probability value, we calculate smartly the probability of exploring the options rather than exploiting them
Thompson Sampling as a solution to multi-arm bandit problem
In artificial intelligence, Thompson sampling named is a heuristic for choosing actions that addresses the exploration-exploitation dilemma in the multi-armed bandit problem. It consists in choosing the action that maximises the expected reward with respect to a randomly drawn belief.
Before understanding the core concepts of Thompson sampling, it will be really helpful to revise some basic concepts of conditional probability.
Conditional probability is the probability of one event occurring with some relationship to one or more other events.
Conditional probability formula
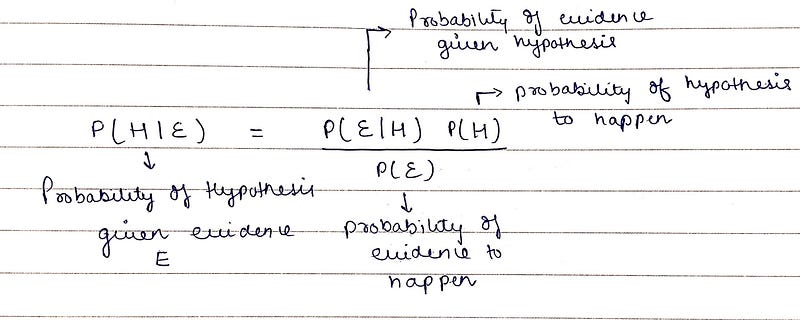
Bayes theorem is a formula that describes how to update the probabilities of hypotheses when given evidence. It follows simply from the axioms of conditional probability but can be used to powerfully reason about a wide range of problems involving belief updates.
Given a hypothesis H and evidence E, Bayes theorem states that the relationship between the probability of the hypothesis before getting the evidence and the probability of the hypothesis after getting the evidence.
Bayes theorem
Thompson sampling follows bayesian statistics very closely. Let us directly dive into components of Thompson sampling.
Consider a set of contexts X, a set of Actions A (pulling the arm of a slot machine) and rewards received as R(0 for losing money/1 for winning the lottery). In each round, an agent/player chooses from a set of actions(which slot machine`s arm it should pull) and receives a corresponding reward R(1: Agent wins the lottery by performing the action an on the specific slot machine,0: Agent loses money in that action performed). The aim of the agent is to play such actions so that it maximizes the cumulative rewards.
Basic components in Thompson sampling are
Likelihood function
Likelihood function determines what is the most suitable distribution of rewards for a given slot machine.
Prior Belief Distribution
Prior belief can be stated as the belief we have on a given slot machine that it will produce a winning reward. Rewards observed over different probability values of prior belief of a given slot machine is known as prior belief distribution.
Prior belief distribution
Posterior Belief Distribution
It is also a beta distribution which is relieved after multiplying the likelihood function with prior belief distribution. Posterior belief refers to updated prior belief (after conducting more actions of pulling arms of slot machines) that a given slot machine will produce a winning reward.
Posterior belief distribution formula
Thompson sampling is generally of the form of
Example
Suppose we as a team belong to an archaeological department wherein we dig up ancient artefacts and try to determine their age. Our job is to try and pinpoint what year(s) the place was likely inhabited. In probability terms, we want to work out forp(inhabited) a range of years. As we uncover relics like pottery and coins, we use that evidence to refine our beliefs about when the village was inhabited.
Our prior belief, in this case, can be the inhabitance period of the people who used this pottery.
Likelihood function can be taken as the existence of pottery(manufacturing) during the inhabitance period.
Our posterior belief of inhabitance of village given we have found a pottery from there.
Posterior belief is calculated by multiplying prior belief distribution with likelihood distribution given the evidence.
Thompson Sampling Algorithm to solve MAB
Implementation in R to solve MAB problem
Problem Statement
An advertising agency has 10 different ads which they want to show to their users. Agency wants to find the add which will get the clients of the agency highest conversion. We need to help the agency in finding the most suited add to maximize the conversions through them.
# Importing the dataset
dataset = read.csv('Ads_CTR_Optimisation.csv')
# Implementing Thompson Sampling
N = 10000 ## Number of total trials
d = 10 ## Number of processes
ads_selected = integer(0)
numbers_of_rewards_1 = integer(d) ### Number of 1 rewards received from dataset
numbers_of_rewards_0 = integer(d) ### Number of 0 rewards received from dataset
total_reward = 0
for (n in 1:N) {
ad = 0
max_random = 0
for (i in 1:d) {
### We create a beta distribution for every ad here and take any 1 random point from it
random_beta = rbeta(n = 1,
shape1 = numbers_of_rewards_1[i] + 1,
shape2 = numbers_of_rewards_0[i] + 1)
### Selecting the add which is further away from 0 since we are placing one with better distribution to
### at extreme end
if (random_beta > max_random) {
max_random = random_beta
ad = i
}
}
ads_selected = append(ads_selected, ad) ## Storing which add was selected
reward = dataset[n, ad] ## Storing reward for the add we selected
#### Dividing rewards into 1s and 0s to to plot the beta distribution
if (reward == 1) {
numbers_of_rewards_1[ad] = numbers_of_rewards_1[ad] + 1
} else {
numbers_of_rewards_0[ad] = numbers_of_rewards_0[ad] + 1
}
total_reward = total_reward + reward ## Calculating total rewards
}
# Visualising the results
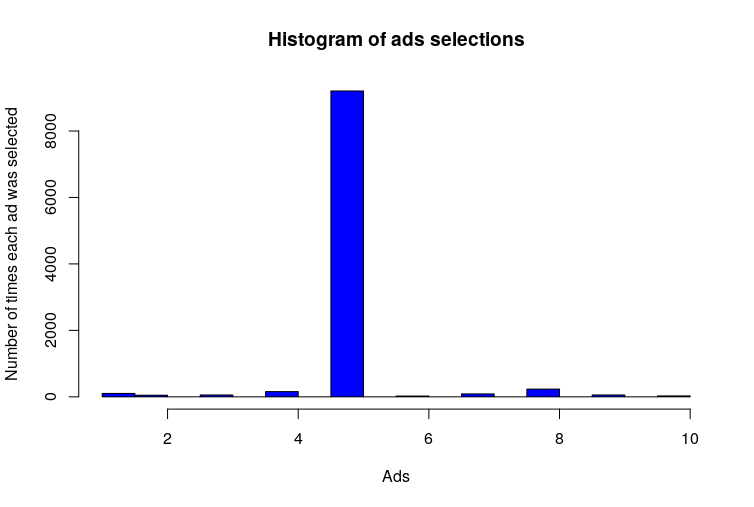
hist(ads_selected,
col = 'blue',
main = 'Histogram of ads selections',
xlab = 'Ads',
ylab = 'Number of times each ad was selected')
Output
Using Thompson sampling it was observed that selected ad 5 is capable of maximising conversions for the client of the ad agency. The cumulative reward for the ad 5 is much more than any other reward. Congratulations, we were able to finally help news agency in selecting the best ad to display to users in an optimised manner.
Big data is high-volume, high-velocity and/or high-variety information assets that demand cost-effective, innovative forms of information processing that enable enhanced insight, decision making, and process automation.
There are numerous components in Big Data and sometimes it can become tricky to understand it quickly. Through this article, we will try to understand different components of Big Data and present these components in the order which will ease the understanding.
Understanding what actually big data is
Big Data is nothing but any data which is very big to process and produce insights from it. Data being too large does not necessarily mean in terms of size only. There are 3 V’s (Volume, Velocity and Veracity) which mostly qualifies any data as Big Data. The volume deals with those terabytes and petabytes of data which is too large to be quickly processed. Velocity deals with data moving with high velocity. Continuous streaming data is an example of data with velocity and when data is streaming at a very fast rate may be like 10000 of messages in 1 microsecond. Veracity deals with both structured and unstructured data. Data that is unstructured or time-sensitive or simply very large cannot be processed by relational database engines. This type of data requires a different processing approach called big data, which uses massive parallelism on readily-available hardware.
Familiarise yourself with Hadoop
Hadoop is an open source distributed processing framework that manages data processing and storage for big data applications running in clustered systems. Let’s understand this piece by piece.
It is an open source framework which refers to any program whose source code is made available for use or modification as users see fit.
It is a distributed processing framework. In Hadoop, we rather than computing everything on a very computationally powerful machine, we divide work across a set of machines which collectively process the data and produce results. This is also known as horizontal scaling.
It has distributed storage feature. Here we do not store all the data on a big volume rather than we store data across different machines, Retrieving large chunks of data from one single volume involves a lot of latency. In case of storage across multiple systems, reading latency is reduced as data is parallelly read from different machines.
Understanding HDFS and Map-Reduce
HDFS is part of Hadoop which deals with distributed storage. It enables to store and read large volumes of data over distributed systems. Map-Reduce deals with distributed processing part of Hadoop. Map-Reduce breaks the larger chunk of data into smaller entities(mapping) and after processing the data, it collects back the results and collates it(reducing). Mapping involves processing data on the distributed machines and reducing involves getting back the data from the distributed nodes to collate it together.
Bringing Hive and Pig in the picture
Hive and ping are more like data extraction mechanism for Hadoop. They offer SQL like capabilities to extract data from non-relational/relational databases on Hadoop or from HDFS. Users can query the selective data they require and can perform ETL operations and gain insights out of their data.
No-SQL databases
NoSQL (commonly referred to as “Not Only SQL”) represents a completely different framework of databases that allows for high-performance, agile processing of information at a massive scale. In other words, it is a database infrastructure that has been very well-adapted to the heavy demands of big data.
The efficiency of NoSQL can be achieved because unlike relational databases that are highly structured, NoSQL databases are unstructured in nature, trading off stringent consistency requirements for speed and agility. NoSQL centres around the concept of distributed databases, where unstructured data may be stored across multiple processing nodes, and often across multiple servers. This distributed architecture allows NoSQL databases to be horizontally scalable; as data continues to explode, just add more hardware to keep up, with no slowdown in performance.
Data collection using Sqoop and Flume
Analytical processing using Hadoop requires loading of huge amounts of data from diverse sources into Hadoop clusters. This process of bulk data load into Hadoop, from heterogeneous sources and then processing it, comes with a certain set of challenges.
Apache Sqoop (SQL-to-Hadoop) is designed to support bulk import of data into HDFS from structured data stores such as relational databases, enterprise data warehouses, and NoSQL systems. Sqoop is based upon a connector architecture which supports plugins to provide connectivity to new external systems.
Apache Flume is a system used for moving massive quantities of streaming data into HDFS. Collecting log data present in log files from web servers and aggregating it in HDFS for analysis, is one common example use case of Flume.
Yarn
Yarn stands for “Yet another resource manager”. Role of the YARN is to divide the task into multiple sub-tasks and assign them to distributed systems so that they can perform the assigned computation. It keeps a track of resources i.e. which all nodes are free etc. Apart from being a resource manager, it is also a job manager. It also keeps a check on the progress of tasks assigned to different compute nodes
Spark
Spark is a general-purpose data processing engine that is suitable for use in a wide range of circumstances. It is more like an open-source cluster computing framework. It is more or less like Hadoop but the difference is that it performs all the operations in the memory. Spark can be seen as either a replacement for Hadoop or as a powerful complement to it. Spark is capable of handling several petabytes of data at a time, distributed across a cluster of thousands of cooperating physical or virtual servers. It has an extensive set of developer libraries and APIs and supports languages such as Java, Python, R, and Scala. It’s use cases include
1. Handling streaming data and processing it
2. Machine learning over Big Data
3. ETL operations over Big Data
Messaging Queues- Kafka
Apache Kafka is a fast, scalable, fault-tolerant publish-subscribe messaging system which enables communication between producers and consumers using message-based topics. It designs a platform for high-end new generation distributed applications. Kafka permits a large number of permanent or ad-hoc consumers. Kafka is highly available and resilient to node failures and supports automatic recovery. These characteristics make Kafka ideal for communication and integration between components of large-scale data systems in real-world data systems. Did you know that AWS is providing Kafka as a service
The ability to give higher throughput, reliability, and replication has made this technology replace the conventional message brokers such as JMS, AMQP, etc.
A Kafka broker is a node on the Kafka cluster that is used to persist and replicate the data. A Kafka Producer pushes the message into the message container called the Kafka Topic and a Kafka Consumer pulls the message from the Kafka Topic.
Through this article, we try to understand the concept of the logistic regression and its application. We will, as usual, deep dive into the model building in R and look at ways of validating our logistic regression model and more importantly understand it rather than just predicting some values.
We will be covering
1. Categorical and numerical variables
2. Why linear regression is not fit for classification
3. Understanding how logistic regression works
4. Assumptions of logistic regression
5. Building logistic regression model in R
6. Measuring performance of model using confusion matrix and ROC curve
7. Improving performance of the logistic model
In my previous article on multiple linear regression, we predicted the cab price I will be paying in the next month. Here the final cab price, which we were predicting, is a numerical variable. In very simple terms, it was a number which varied over a range of values. But now there is one more data type which we should first understand before diving into logistic regression.
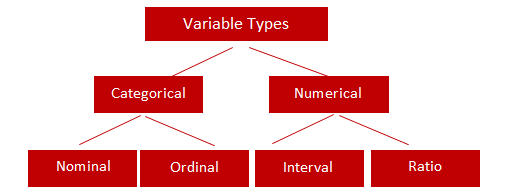
Types of data
Categorical: Categorical variables take on values that are names or labels. The color of a ball (e.g., red, green, blue) or the breed of a dog (e.g., collie, shepherd, terrier) would be examples of categorical variables.
Quantitative: Quantitative variables are numerical. They represent a measurable quantity. For example, when we speak of the population of a city, we are talking about the number of people in the city — a measurable attribute of the city. Therefore the population would be a quantitative variable.
Categorical
Nominal: Nominal values are the type of categorical variables that represent a discrete category which does not contain any kind of order within them. For example, say male and female are nominal categorical values because they are discrete and they do not have any implied order. Suppose we represent all males by 1 and all females by 0, then we can not imply that 1 is greater than 0 or vice-versa
Ordinal: Ordinal values are the type of categorical variables that represent again a discrete category but they do have an implied order within them. For instance, let us take the speed of a fan which can be stated say low, medium and high. If we denote low by 0, medium by 1 and high by 2 then we can still imply that 1>0 since the medium speed of the fan is greater than the low speed of the fan. Here there is an implicit order in discrete values.
There is another class of machine learning problems which involve predicting a categorical variable rather than predicting a variable which is continuous in nature. These type of machine learning problems where our aim is to predict a categorical variable are known as classification problems.
So in very simple terms, classification is about predicting a label and regression is about predicting a quantity.
Logistic regression is a method for fitting a regression curve, y = f(x) when y is a categorical variable. It is a classification algorithm used to predict a binary outcome (1 / 0, Yes / No, True / False) given a set of independent variables.
A logistic regression model can be represented by the equation
p is the probability of an event to happen which you are trying to predict
x1, x2 and x3 are the independent variables which determine the occurrence of an event i.e. p
a0 is the constant term which will be the probability of the event happening when no other factors are considered
R.H.S represent the link function which will help us to determine a non-linear relation in a linear way wherein (p/1-p) is the odd ratio. Whenever the log of the odds ratio is found to be positive, the probability of success is always more than 50%.
Before going any further let us quickly see why we can not use linear regression for a classification problem and how logistic regression comes to our rescue there
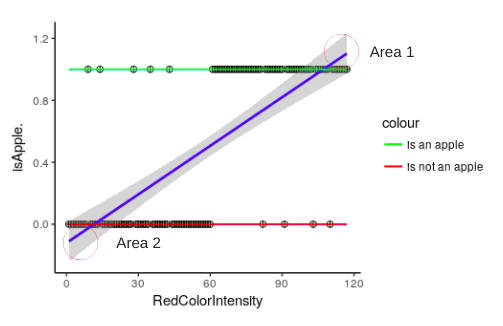
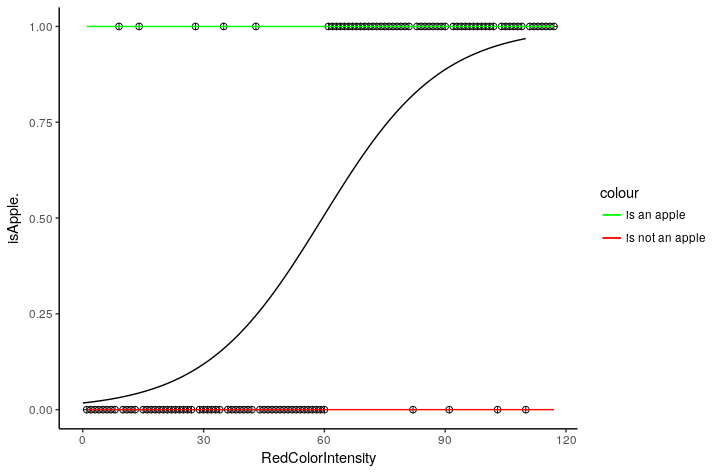
Let us take a small case here, suppose we have a model whose only job is to look at the fruit in front of the camera and state whether it is an apple or not. This is a simple binary classification problem where our output variable can take only 2 states(yes/no or 0/1). Our model gives an output 1 if it recognises it as an apple and output 0 if it is not an apple.
Let us build a simple linear regression model for this classification case and see why it is not a good idea to solve a classification problem using linear regression.
#Training simple linear regression model
model = lm(isApple ~ RedColorIntensity, data=dataset)
Now it is time to visualize our linear regression model here ….
1 represents all the points which are classified as an apple
0 represents all the points which are not apple
The line in blue is a “best fit” line plotted by our linear regression model
Issue 1: Area 1 and Area 2 represent a portion of the line where the probability of any fruit seen by our model being an apple is >1(area1) and <0(area2). Since probabilities can never be greater than 1 or less than 0, part of the regression line in area 1 and area 2 does not make any sense.
Solution 1: Since both, the areas are not required, we cut them and keep the remaining with us. This line has a finite limit. Whenever your x tends to infinity, y will tend to 1 and whenever your x will tend to -infinity, y will tend to 0.
Issue 2: Since binary classification problems can only have one of two possible values(0 or 1), the residuals(Actual value -predicted value) will not be normally distributed about the regression line.
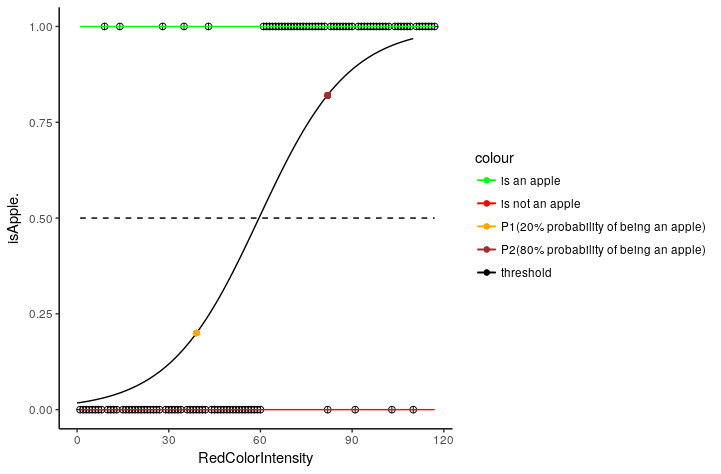
Solution 2: To overcome the residual issue, we identify a threshold probability value. Our final variable in logistic regression is the probability of the target event. So if my apple identifier logistic model outputs a value like 0.45 then this means that there is a 45% probability that new fruit seen by our model is an apple. Here we set a threshold value 0.5 which means that if the probability of fruit seen by the model is an apple is greater than 50% then our model will predict it to be an apple and if it is less than 50% then our model will say that it is not an apple.
So every value predicted by the model below 0.5, the model will classify it as not an apple in this case and for every other value greater than threshold 0.5, the model will classify it as an apple.
Assumptions in logistic regression
There are some assumptions which need to be satisfied for having a logistic regression model which we can interpret meaningfully.
But let us look at some things which we no longer have to take care of in the case of logistic regression if we compare it with logistic regression.
Logistic regression does NOT require a linear relationship between the dependent and independent variables
The error terms (residuals) do NOT need to be normally distributed
Homoscedasticity is NOT required
The dependent variable in logistic regression is NOT measured on an interval or ratio scale
But then there are some assumptions which should hold
Logistic regression requires the dependent variable to be categorical
Logistic regression requires there to be little or no multicollinearity among the independent variables. This means that the independent variables should not be too highly correlated with each other.
There should be a linear relationship between the link function (log(p/(1-p))and independent variables in the logit model.
Problem Statement: The diabetes dataset consists of several medical predictor variables and one target variable, Outcome. Predictor variables include the number of pregnancies the patient has had, their BMI, insulin level, age, and so on. The objective is to diagnostically predict whether or not a patient has diabetes, based on certain diagnostic measurements included in the dataset.
Loading dataset
### Reading data ###
dataset = read.csv("data.csv")
### Exploring columns in our data ###
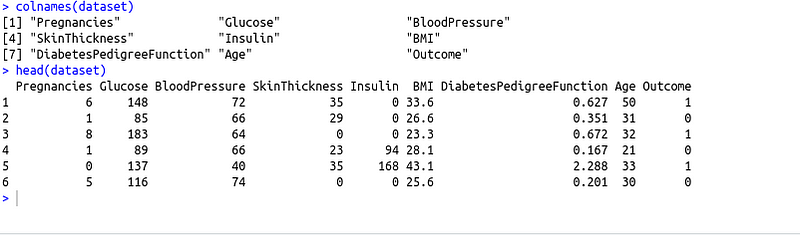
colnames(dataset)
head(dataset)
There are 9 columns in our dataset which includes 8 predictor variables (Pregnancies, Glucose, Blood Pressure .. etc) and 1 target variable (Outcome). The patients diagnosed with diabetes are represented 1 and patients which were not diagnosed with diabetes are represented with 0.
Building a logistic regression model
Let us straight away build a simplest logistic regression model using the glm function in R. The glm function expects the first parameter as the target variable (Outcome) and then predictor variables after “~” sign.
A “dot” in the place of predictor variables signify that all the columns in the dataset (obviously apart from target variable) are taken into the consideration to predict the target variable (Outcome). data parameter takes the training data as input and family in glm should be set to binomial in this case.
Why family = binomial?
We set the family parameter to binomial because the variable to predict (Outcome) is binary(0/1), however, logistic regression can also be used to predict a dependent variable which can assume more than 2 values. In this second case, we call the model “multinomial logistic regression”. A typical example, for instance, would be classifying films between “Entertaining”, “borderline” or “boring”.
### Training logistic regression model
model <- glm(Outcome ~ ., data = training_set, family = binomial)
summary(model)
Let us have a closer look at what all the above terms are in the summary of our logistic model which will help us to gain a better understanding of the model we have built.
Null Deviance: When the model includes only an intercept term (no predictor variables are taken into account), then the performance of the model is governed by null deviance.
Residual Deviance: When the model has included 6 predictor variables, then the deviance is residual deviance which is lower(506.94) than null deviance(695.42). The lower value of residual deviance points out that the model has become better when it has included predictor variables
AIC value: Its full form is Akaike Information Criterion (AIC). This is useful when we have more than one model to compare the goodness of fit of the models. It is a maximum likelihood estimate which penalizes to prevent overfitting. It measures the flexibility of the models. It is analogous to adjusted R squared in multiple linear regression where it tries to prevent you from including irrelevant predictor variables. Lower AIC of a model is better than the model having higher AIC.
Fisher score: It tells how the model was estimated. The algorithm looks around to see if the fit would be improved by using different estimates. If it improves then it moves in that direction and then fits the model again. The algorithm stops when no significant additional improvement can be done. “Number of Fisher Scoring iterations,” tells “how many iterations this algorithm run before it stopped”.Here it is 5.
Predicting whether the new person coming for diagnosis will be diabetic or not
### Predicting target variable for new patients###
prob_pred = predict(model, type = 'response', newdata = test_set[,-8]
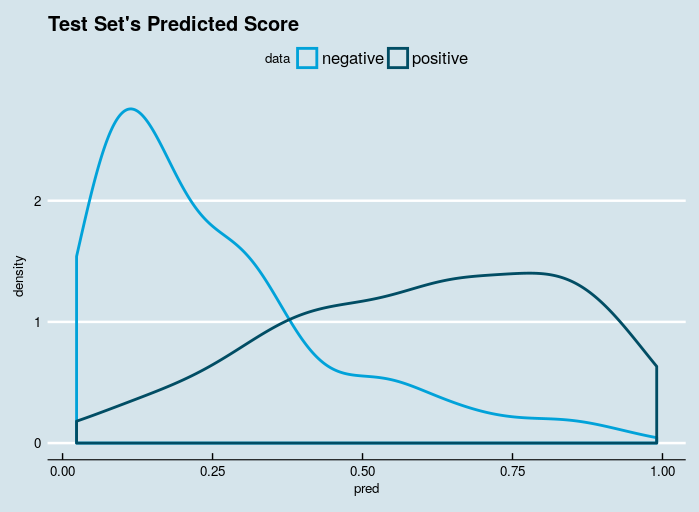
Now we’ll perform a quick evaluation on the test set by plotting the probability (score) estimated by our model with a double density plot.
Given that our model’s final objective is to classify new instances into one of two categories, whether the patient is having diabetes or not we will want the model to give high scores to positive instances ( 1: patients with diabetes) and low scores (0: patients without diabetes ) otherwise. Thus for an ideal double density plot, you want the distribution of scores to be separated, with the score of the negative instances to be on the left and the score of the positive instance to be on the right.
Since the separation between negative points and positive data points is well enough, hence we can proceed forward with this model.
Setting threshold and classifying the predicted probabilities to 0 or 1
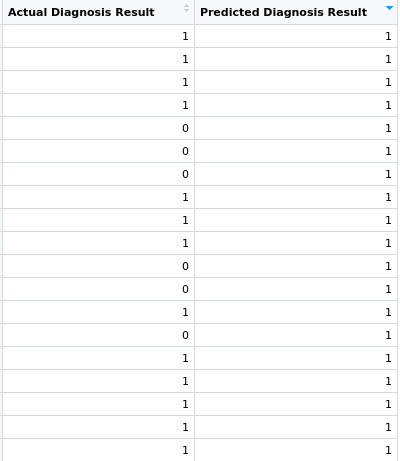
### Combining actual result with predicted result ###
y_act = test_set[,7]
results <- data.frame("Actual Diagnosis Result" = y_act,
"Predicted Diagnosis Result" = y_pred)
In the predict function, we passed our logistic regression model as an input to the first parameter and setting type as “response”. In new data parameter, we passed our test set without the target (Outcome) column.
Then in the second line, we set the threshold value to 0.5. As we already discussed,
Any probability value predicted by our logistic regression model which will be less than the threshold will be converted to 0
Any probability value predicted by our logistic regression model which will be greater than the threshold will be converted to 1
Then we make a data frame to view original outcome and the outcome predicted by our model.
Our model was able to predict correctly for many patients coming in that which ones will have diabetes but there were some patients for which our model predicted that they have diabetes although they were not actually diabetic.
Measuring the performance of our logistic regression model
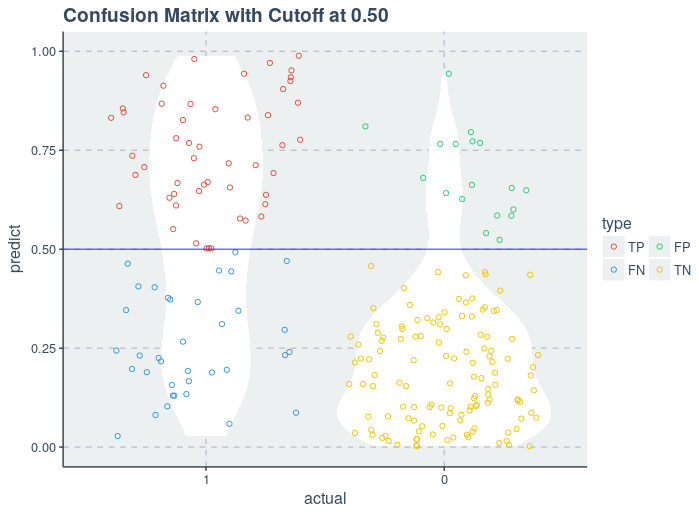
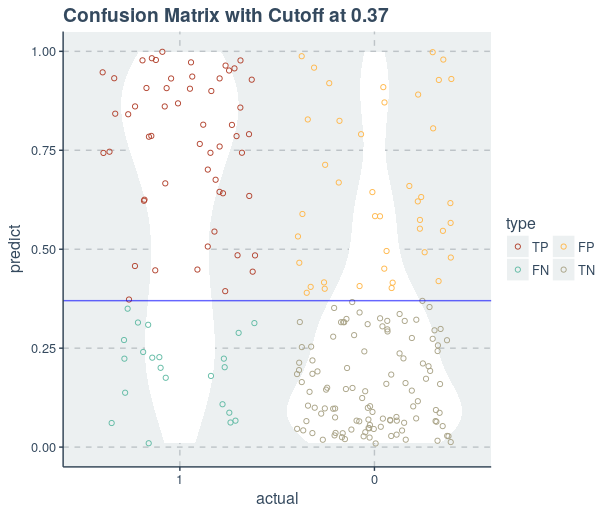
Confusion Matrix
A confusion matrix is a table that is often used to describe the performance of a classification model (or “classifier”) on a set of test data for which the true values are known.
Let us directly create a confusion matrix for our logistic regression model and understand it in the process
There are two possible outcomes for prediction i.e. either a yes or a no. Yes means that the given patient will be diagnosed with diabetes and no means the patient will not be diagnosed with diabetes.
Classifier made a total of 231 (121+13+43+54) predictions for the diagnosed patients
Out of cases, our model predicted YES 67 (13+54) times and “NO” only 164 (121+43) times
In reality, 134 (121+13) patients were not diagnosed with diabetes and 97 (43+54) patients were diagnosed with diabetes.
Key terms in confusion matrix
True Positive (TP): This refers to the cases in which we predicted “YES” and our prediction was actually TRUE (Patient is actually having diabetes)
True Negative (TN): This refers to the cases in which we predicted “NO” and our prediction was actually TRUE (Patient was not having diabetes)
False Positive (FP): This refers to the cases in which we predicted “YES”, but our prediction turned out FALSE
(Patient was not having diabetes but our model predicted that he is diabetic)
False Negative (FN): This refers to the cases in which we predicted “NO” but our prediction turned out FALSE
(Patient was diabetic but our model predicted that he is not having diabetes)
Understanding model performance metrics in classification problems
The accuracy of the model is not the only criteria to measure the performance of a classification model
Accuracy: Overall, how often is the classifier correct?
( TP + TN )/TOTAL = ( 121+54 )/231 = 0.757
Misclassification Rate: Overall, how often is it wrong?
1-Accuracy = 0.243
True Positive Rate: When it’s actually yes, how often does it predict yes?
TP/Actual Yes = 54/(43+54) = 0.5596
False Positive Rate: When it’s actually no, how often does it predict yes?
FP/Actual No = 13/(121+13) = 0.08441
Specificity: When it’s actually no, how often does it predict no?
TN/Actual No = 121/(121+13)= 0.9156
Precision: When it predicts yes, how often is it correct?
TP/Predicted Yes = 54/(54+13) = 0.8059
Prevalence: How often does the yes condition actually occur in our sample?
Actual Yes/Total = (43+54)/231 = 0.4199
## Training logistic regression model ##
model <- glm(Outcome ~ ., family = "binomial" , data = train)
## Predicting probabilities ##
pred <- predict(model, newdata = test, type = "response")
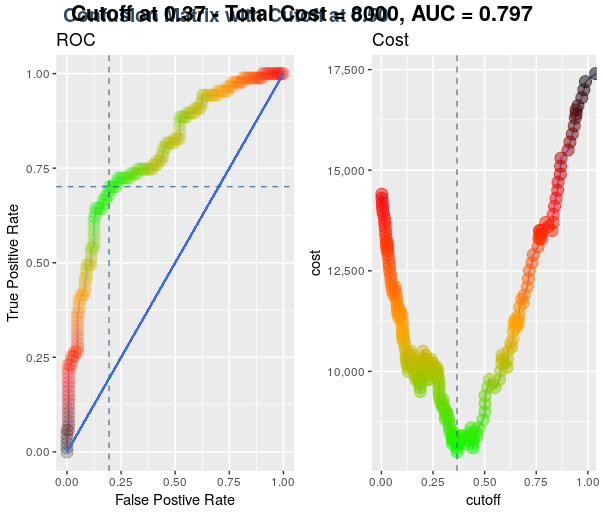
## Setting threshold value to 0.37 ##
y_pred_num <- ifelse(pred > 0.37, 1, 0)
## Making confusion matrix ###
y_act <- test$Outcome
results <- as.data.frame(cbind(y_act,y_pred))
cm <- table(test$Outcome, y_pred)
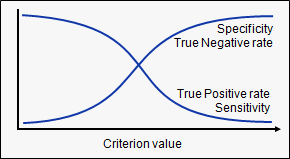
Most machine learning classifiers produce real-valued scores that correspond with the strength of the prediction that a given case is positive. Turning these real-valued scores into yes or no predictions require setting a threshold; cases with scores above the threshold are classified as positive, and cases with scores below the threshold are predicted to be negative.
Different threshold values give different levels of sensitivity and specificity.
A high threshold is more conservative about labeling a case as positive; this makes it less likely to produce false positive results but more likely to miss cases that are in fact positive (lower rate of true positives).
A low threshold produces positive labels more liberally, so it is less specific (more false positives) but also more sensitive (more true positives).
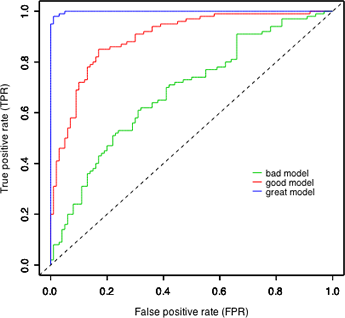
2. What are ROC curves
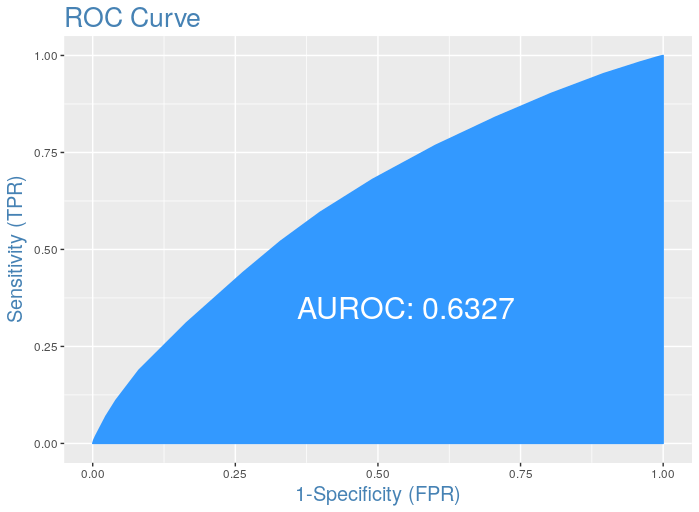
ROC curves are commonly used to characterize the sensitivity/specificity tradeoffs for a binary classifier. The ROC curve plots true positive rate against false positive rate, giving a picture of the whole spectrum of such trade-offs.
The accuracy of the test depends on how well the model separates the group into two classes(in the case of binary classification). Accuracy is measured by the area under the ROC curve. An area of 1 represents a perfect test; an area of .5 represents a worthless test. A rough guide for classifying the accuracy of a test is the traditional academic point system:
The ROC is invariant against class skew of the applied data set — that means a data set featuring 60% positive labels will yield the same (statistically expected) ROC as a data set featuring 45% positive labels (though this will affect the cost associated with a given point of the ROC). Hence it is capable of handling imbalance in the data set as it not dependent on it in any way
The ROC is invariant against the evaluated score — which means that we could compare a model giving non-calibrated scores like a regular linear regression with a logistic regression or a random forest model whose scores can be considered as class probabilities.
Getting optimal threshold value
Since the prediction of a logistic regression model is a probability, in order to use it as a classifier, we’ll have to choose a cutoff value, or you can say it a threshold value. Where scores above this value will be classified as positive, those below as negative. By default, we take threshold at 0.5.
### Performance metrics with 0.5 threshold value ###
With this process, we were able to improve the performance of our logistic model. We can further improve the performance of the model by selecting only the important variables and then building the model as I did in my previous article on multiple regression.
this article, I tried to cover the basic idea of a classification problem by trying to solve one using logistic regression. We also understood how to evaluate a model based on classification problem using confusion matrix and ROC curve and tried to improve our logistic model by selecting an optimal threshold value.
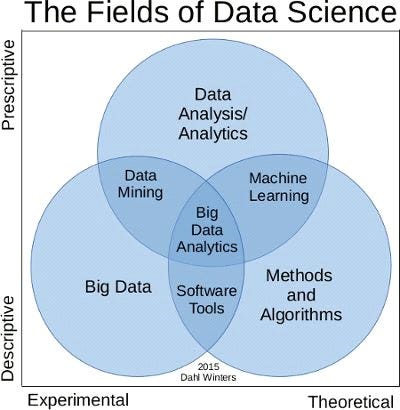
There are many fields under the umbrella of the data science and sometimes these roles look similar to each other or are used interchangeably. Let us list these terms first and try to understand them
Different parts within data science can be as following
Big Data
Data Mining
Data Analytics
Data Analysis
Data Science
Machine Learning
Data science is the umbrella under which all these terminologies take the shelter. Data science is a like a complete subject which has different stages within itself. Suppose a retailer wants to forecast the sales of an X item present in its inventory in the coming month. This is known as a business problem and data science aims to provide optimised solutions for the same.
Data science enables us to solve this business problem with a series of well-defined steps.
Step 1: Collecting data Step 2: Pre-processing data Step 3: Analysing data Step 4: Driving insights and generating BI reports Step 5: Taking decision based on insights
Generally, these are the steps we mostly follow to solve a business problem. All the terminologies related to data science falls under different steps which we are going to understand just in a while. Different terminologies fall under different steps listed above.
Collecting data: To solve any problem using a data-driven approach, the very first thing required at hand is data. In order to analyse anything, we need to have data first. Sometimes data will be given to you in a ready to consume format(which is rare) else you have to gather data from the client database and other sources. Our first terminology, BIG DATA, fits here. Big data is nothing but any data which is too big/complex to handle. Big data does not necessarily mean data which is large in science. Big data is characterised by 3 different properties and if your data exhibits this property then it is qualified to be called Big data. These properties are defined by 3 V’s.
– Volume: Data in terabytes
– Velocity: Streaming data with high throughput
– Veracity: Data with varying structure
In a retail business, a lot of transactions happen every second by a large number of customers, a lot of data is maintained in a structured or unstructured format about customers, employees, stores, sales etc. All this data put together is very complex to process or even comprehend. Big data technologies like Hadoop, Spark, Kafka simplifies our work here.
Cleaning data: This is one task which you will always end up doing. Cleaning data essentially means removing discrepancies from your data such as missing fields, improper values, setting the right format of the data, structuring data from raw files etc. Any process from this point until generating insights falls under the data analysis. It involves extracting, cleaning, transforming, modelling and visualisation of data with an intention to uncover meaningful and useful information that can help in deriving the conclusion and take decisions. Data on which it is applied can be structured or unstructured. We may get data about some retail store which has missing info about an employee’s second name or phone numbers. Knowing how to handle these situations is a part of the data cleaning process
Analysing data: Now we create a plan to do analytics on the data. There can be different types of data analytics which can be performed on the data depending upon the problem at hand. Different types of analytics may include descriptive analytics, predictive analytics, and prescriptive analytics. So we first determine which type of analytics we intend to perform. This is part of data analytics. After getting a structured data from the cleaning operations (which is generally the case), we perform the data mining operation in order to identify and discovering hidden patterns and information in a large dataset. This is known as data mining. For example, identifying seasonality in sales. Data analysis is the more of a holistic approach but data mining tends to find the hidden patterns in data only. These discovered patterns are fed to data analysis approach taken to generate hypothesis and find insights.
Driving insights and BI reports: Once we have analysed data, we gather insight from data which will enable us to take actions. These insights can be based on insights we have gathered through data mining processes or through some predictions. These predictions can come from a mathematical model which will just take into the input parameters and predict some final values. Machine learning is mostly applied at this stage, where we make future predictions and validate our previously defined hypothesis. Machine learning is a technique where we obtain a mathematical model by learning from the patterns present in the data.
Taking actions: Based upon all the insights we have gathered through observation of data or through machine learning model’s result, we get into a state where we can take some decisions regarding any business problem at hand. For example how much stock of item X we need to have in inventory. How much discount should be given to an item X to boost its sales and maintain the trade-off between discount and profit
Different roles in the data science industry
There are multiple roles a professional can take in the data science industry which are in a lot of demand too. These roles all deal with data in some way or the other but are different from each other depending on what you do with data.
The Data Scientist He/she masters a whole range of skills and talents going from being able to handle the raw data, analysing that data with the help of statistical techniques, to share his/her insights with his peers in a compelling way. No wonder these profiles are highly wanted by companies like Google and Microsoft.
The Data Analyst He/She is a master of languages like R, Python, SQL and C. Main responsibility is collecting, processing and performing statistical data analysis.
The Data Engineer
The data engineer often has a background in software engineering and loves to play around with databases and large-scale processing systems.
The Data Architect With the rise of big data, the importance of the data architect’s job is rapidly increasing. The person in this role creates the blueprints for data management systems to integrate, centralise, protect and maintain the data sources. The data architect masters technologies like Hive, Pig and Spark, and needs to be on top of every new innovation in the industry.
The Data Statistician The historical leader of data and its insights. Although often forgotten or replaced by fancier sounding job titles, the statistician represents what the data science field stands for: getting useful insights from data
The Machine Learning Engineer Artificial intelligence is the goal of a machine learning engineer. They are computer programmers, but their focus goes beyond specifically programming machines to perform specific tasks. They create programs that will enable machines to take actions without being specifically directed to perform those tasks. An example of a system a machine learning engineer would work on is a self-driving car. They take the key role of providing the intelligence to the work done by analysts, for example, forecasting sales of products, segmenting different types of customers based on their habits and traits etc
The Business Analyst Less technically oriented, the business analyst makes up for it with his/her deep knowledge of the different business processes. (S)he masters the skill of linking data insights to actionable business insights and is able to use storytelling techniques to spread the message across the entire organization.
Conclusion
Big Data: Collecting and processing any data which is huge in volume, arrival/processing rate or invariant in structure. Data Mining: Process of finding out hidden patterns in the structured data and find hidden information in the data Data Analytics: It is a process which is one step above data mining. Data analytics identifies the type of the analysis to be performed within which data mining techniques will be performed. Data Analysis: It is a more general approach of finding insights out of the raw data by forming a hypothesis and proving them using statistical tests. Data Science: It defines the process of understanding the business problem to deliver the solution Machine Learning: It is a tool used in data analytics to predict/find out a hidden layer of information in data. An example can be predicting the attrition rate of an organisation/whether an employee will stay in the organisation or leave it.
In this article, we will try to understand the concept behind box plots. When i first saw a box plot, I was utterly confused and could not extract much information out of it on the first go. This article will help you to avoid the situation I faced in understanding a box plot.
Introduction to box plots
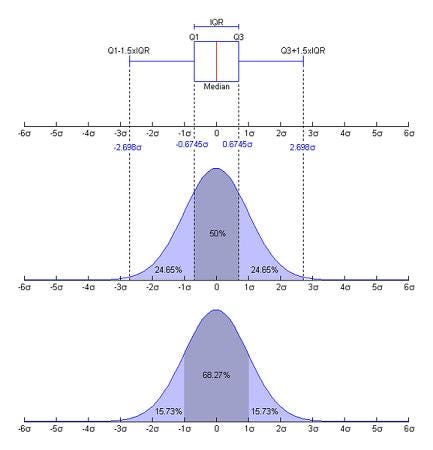
A Box and Whisker Plot (or Box Plot) is a convenient way of visually displaying the data distribution through their quartiles. It is a graphical rendition of statistical data based on the minimum, first quartile, median, third quartile, and maximum. The term “box plot” comes from the fact that the graph looks like a rectangle with lines extending from the top and bottom. Because of the extending lines, this type of graph is sometimes called a box-and-whisker plot.
Let us understand these 5 components of the box plot
Median Value Value or quantity that falls halfway between a set of values arranged in an ascending or descending order. When the set contains an odd number of values, the median value is exactly in middle. If the number of values is even, the median is computed by averaging the two numbers closest to the middle.
Lower Quartile(Q1) The lower quartile is also known as the first quartile, splits the lower 25% of the data. Quartiles are three points that divide the data set into four equal groups. Each group represents the one-fourth of the data set. The lower quartile is the middle value of the lower half.
Upper Quartile(Q3) Upper quartile is also known as the third quartile. It splits lowest 75% (or highest 25%) of data. It can be also seen as the middle value of the upper half.
Interquartile Range(Q3-Q1) The Interquartile range is from Q1 to Q3. It is the difference between the lower quartile and upper quartile. The IQR is often seen as a better measure of a spread than the range (highest value-lowest value) as it is not affected by outliers.
Highest Value This point in the box plot represents the highest value in the data distribution over which the box plot is built which is not an outlier. This point does not correspond to the highest value in your dataset. Suppose you have some data like 65,76,87,100,105,100000. Here the largest value is 100000 but it is most likely to be an outlier and hence the box plot will not mark this as the maximum value. The most feasible option will be 105 as the maximum value of the box plot.
Lowest Value This point in the box plot represents the lowest value in the data distribution over which the box plot is built and is not an outlier (smallest value in the Interquartile range of the distribution). This point does not correspond to the smallest value in your dataset. Suppose you have some data like 0.005,65,76,87,100,105. Here the smallest value is 0.005 but it is most likely to be an outlier and hence the box plot will not mark this as the minimum value. The most feasible option will be 65 as the minimum value of the box plot.
Why box plots?
Handles Large Data Easily Due to the five-number data summary, a box plot can handle and present a summary of a large amount of data. A box plot consists of the median, which is the midpoint of the range of data; the upper and lower quartiles, which represent the numbers above and below the highest and lower quarters of the data and the minimum and maximum data values. Organizing data in a box plot by using five key concepts is an efficient way of dealing with large data too unmanageable for other graphs, such as line plots or stem and leaf plots.
Exact Values Not Retained The box plot does not keep the exact values and details of the distribution results, which is an issue with handling such large amounts of data in this graph type. A box plot shows only a simple summary of the distribution of results so that you can quickly view it and compare it with other data. Use a box plot in combination with another statistical graph method, like a histogram, for a more thorough, more detailed analysis of the data.
A clear summary
A box plot is a highly visually effective way of viewing a clear summary of one or more sets of data. It is particularly useful for quickly summarizing and comparing different sets of results from different experiments. At a glance, a box plot allows a graphical display of the distribution of results and provides indications of symmetry within the data.
Displays outliers A box plot is one of very few statistical graph methods that show outliers. There might be one outlier or multiple outliers within a set of data, which occurs both below and above the minimum and maximum data values. By extending the lesser and greater data values to a max of 1.5 times the inter-quartile range, the box plot delivers outliers or obscure results. Any results of data that fall outside of the minimum and maximum values known as outliers are easy to determine on a box plot graph.
Understanding different box plots
We have data on different house prices in 5 different areas of Bangalore. We will try to understand the distribution of this data and try to find some insights out of it.
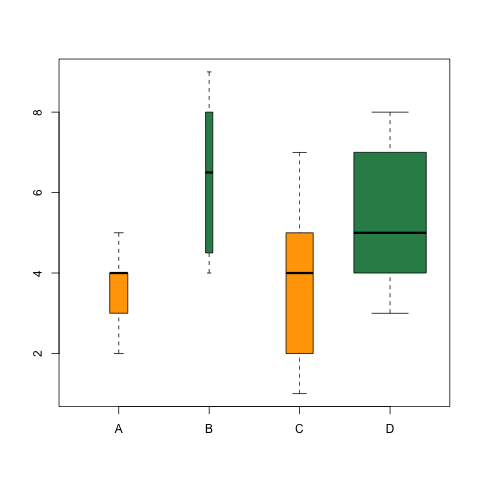
The Box plot as an Indicator of Centrality We will try to gather our first insight by observing the centrality of the box plots. Centerline represents the median value for the house price in different areas. Houses on airport road have the highest median value of the house which makes it a comparatively expensive place to live in whereas houses in Marathali have the least median value which allows us to conclude that houses here are relatively cheapest to live.
The Box plot as an indicator of the spread The spread of a box plot talks about the variance present in the data. More the spread, more the variance. If you look closely at the first two box plots, both Whitefield and Hoskote areas have the same median house price value so it seems like both places fall into the same budget category. But if we look more closely, we can observe that width of Hoskote box plot is more than Whitefield box plot. Hoskote area has more variance in house price as compared to Whitefield i.e. Hoskote offers more variety of budget in houses as compared to Whitefield. If we look at the overall graph, we find that Bellathur area has the most spread in its box plot. This clearly states that this area has the widest variety in the budget of the houses.
The Box plot as an indicator of symmetry Symmetry around the median talks about skewness present in the data. If the median line is towards the lower half of the box plot, then it is right skewed (positive skew) and if the median line is towards the upper portion of the box plot then it is left-skewed (negative skew). If we look at the box plot representing Marathalli, we can observe that median is towards the lower half of the box plot and hence it is right skewed (positive skew) which means that most of the houses are on the cheaper side in Marathalli and only a few are expensive.
The Box plot as an indicator of tail length Tail length talks about the kurtosis present in data. There are three cases here. Either your data will be normally distributed or it will have more data in its tail as compared to a normal distribution(platykurtic) or it will have fewer data in tails as compared to a normal distribution(leptokuritc). A long tail shows that the distribution is platykurtic and shorter tail gives the idea of distribution being leptokurtic. In above example, Marathalli has the shortest tail as compared to other box plots which may mean that in Marathalli most of the house prices lie in the interquartile range (q3-q1).
Types of box plots
Variable width box plots
Box plot represents a numeric vector of data that is split in several groups. When the number of points in each group is highly different, it can be great to represent it using the width of the box. The widths of the box plot indicate the size of the samples. The wider the box, the larger the sample. This is usually an option in statistical software programs, not all Box Plots have the widths proportional to the sample size. One common convention is to make the width of the boxes for a group of data proportional to the square roots of the number of observations in a given sample.
Notched box plots
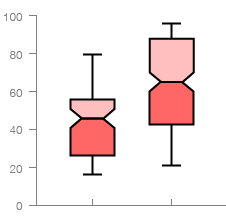
It works the same as a standard Box Plot, but has a narrowing of the box around the median value. This acts as a handy visual guide to help read and compare the differences between the median values across each data series. Notches visually illustrate an estimate on whether there is a significant difference of medians. The width of the notches is proportional to the inter quartile range of the sample.
Complications in box plots
Box plots generally do not go well when the sample size of distribution is small.
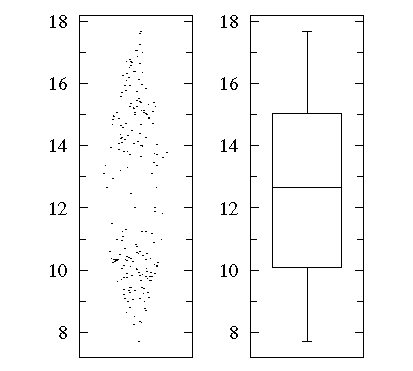
One case of particular concern — where a box plot can be deceptive — is when the data are distributed into “two lumps” rather than the “one lump” cases we’ve considered so far. A “bee swarm” plot shows that in this dataset there are lots of data near 10 and 15 but relatively few in between. See that a box plot would not give you any evidence of this.