In a world where we generate data at an extremely fast rate, the correct analysis of the data and providing useful and meaningful results at the right time can provide helpful solutions for many domains dealing with data products. We can apply this in Health Care and Finance to Media, Retail, Travel Services and etc. some solid examples include Netflix providing personalized recommendations at real-time, Amazon tracking your interaction with different products on its platform and providing related products immediately, or any business that needs to stream a large amount of data at real-time and implement different analysis on it.
One of the amazing frameworks that can handle big data in real-time and perform different analysis, is Apache Spark. In this blog, we are going to use spark streaming to process high-velocity data at scale. We will be using Kafka to ingest data into our Spark code
What is Spark?
Apache Spark is a lightning-fast cluster computing technology, designed for fast computation. It is based on Hadoop MapReduce and it extends the MapReduce model to efficiently use it for more types of computations, which includes interactive queries and stream processing. The main feature of Spark is its in-memory cluster computing that increases the processing speed of an application.
Spark is designed to cover a wide range of workloads such as batch applications, iterative algorithms, interactive queries and streaming. Apart from supporting all these workloads in a respective system, it reduces the management burden of maintaining separate tools.
What is Spark Streaming?
Spark Streaming is an extension of the core Spark API that enables high-throughput, fault-tolerant stream processing of live data streams. Data can be ingested from many sources like Kafka, Flume, Twitter, ZeroMQ or TCP sockets and processed using complex algorithms expressed with high-level functions like map, reduce, join and window. Finally, processed data can be pushed out to file systems, databases, and live dashboards. Since Spark Streaming is built on top of Spark, users can apply Spark’s in-built machine learning algorithms (MLlib), and graph processing algorithms (GraphX) on data streams. Compared to other streaming projects, Spark Streaming has the following features and benefits:
Ease of Use: Spark Streaming brings Spark’s language-integrated API to stream processing, letting users write streaming applications the same way as batch jobs, in Java, Python and Scala.
Fault Tolerance: Spark Streaming is able to detect and recover from data loss mid-stream due to node or process failure.
How Does Spark Streaming Work?
Spark Streaming processes a continuous stream of data by dividing the stream into micro-batches called a Discretized Stream or DStream. DStream is an API provided by Spark Streaming that creates and processes micro-batches. DStream is nothing but a sequence of RDDs processed on Spark’s core execution engine like any other RDD. It can be created from any streaming source such as Flume or Kafka.
Difference Between Spark Streaming and Spark Structured Streaming
Spark Streaming is based on DStream. A DStream is represented by a continuous series of RDDs, which is Spark’s abstraction of an immutable, distributed dataset. Spark Streaming has the following problems.
Difficult — it was not simple to built streaming pipelines supporting delivery policies: exactly once guarantee, handling data arrival in late or fault tolerance. Sure, all of them were implementable but they needed some extra work from the part of programmers.
Inconsistent — API used to generate batch processing (RDD, Dataset) was different than the API of streaming processing (DStream). Sure, nothing blocker to code but it’s always simpler (maintenance cost especially) to deal with at least abstractions as possible.
Spark Structured Streaming be understood as an unbounded table, growing with new incoming data, i.e. can be thought as stream processing built on Spark SQL.
More concretely, structured streaming brought some new concepts to Spark.
Exactly-once guarantee — structured streaming focuses on that concept. It means that data is processed only once and output doesn’t contain duplicates.
Event time — one of the observed problems with DStream streaming was processing order, i.e the case when data generated earlier was processed after later generated data. Structured streaming handles this problem with a concept called event time that, under some conditions, allows to correctly aggregate late data in processing pipelines.
sink, Result Table, output mode and watermark are other features of spark structured-streaming.
Implementation Goal
In this blog, we will try to find the word count present in the sentences. The major point here will be that this time sentences will not be present in a text file. Sentences will come through a live stream as flowing data points. We will be counting the words present in the flowing data. Data, in this case, is not stationary but constantly moving. It is also known as high-velocity data. We will be calculating word count on the fly in this case! We will be using Kafka to move data as a live stream. Spark has different connectors available to connect with data streams like Kafka
Word Count Example Using Kafka
There are few steps which we need to perform in order to find word count from data flowing in through Kafka.
The initialization of Spark and Kafka Connector
Our main task is to create an entry point for our application. We also need to set up and initialise Spark Streaming in the environment. This is done through the following code
val sparkConf = new SparkConf().setAppName("DirectKafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
Since we have Spark Streaming initialised, we need to connect our application with Kafka to receive the flowing data. Spark has inbuilt connectors available to connect your application with different messaging queues. We need to put information here like a topic name from where we want to consume data. We need to define bootstrap servers where our Kafka topic resides. Once we provide all the required information, we will establish a connection to Kafka using the createDirectStream function. You can find the implementation below
Now, we need to process the sentences. We need to map through all the sentences as and when we receive them through Kafka. Upon receiving them, we will split the sentences into the words by using the split function. Now we need to calculate the word count. We can do this by using the map and reduce function available with Spark. For every word, we will create a key containing index as word and it’s value as 1. The key will look something like this <’word’, 1>. After that, we will group all the tuples using the common key and sum up all the values present for the given key. This will, in turn, return us the word count for a given specific word. You can have a look at the implementation for the same below
val lines = messages.map(_.value)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
wordCounts.print()
Finally, the processing will not start unless you invoke the start function with the spark streaming instance. Also, remember that you need to wait for the shutdown command and keep your code running to receive data through live stream. For this, we use the awaitTermination method. You can implement the above logic through the following two lines
ssc.start()
ssc.awaitTermination()
Full Code
package org.apache.spark.examples.streaming
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka010._
object DirectKafkaWordCount {
def main(args: Array[String]) {
if (args.length < 3) {
System.err.println(s"""
|Usage: DirectKafkaWordCount <brokers> <topics>
| <brokers> is a list of one or more Kafka brokers
| <groupId> is a consumer group name to consume from topics
| <topics> is a list of one or more kafka topics to consume from
|
""".stripMargin)
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
val Array(brokers, groupId, topics) = args
// Create context with 2 second batch interval
val sparkConf = new SparkConf().setAppName("DirectKafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
// Create direct kafka stream with brokers and topics
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,
ConsumerConfig.GROUP_ID_CONFIG -> groupId,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer])
val messages = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams))
// Get the lines, split them into words, count the words and print
val lines = messages.map(_.value)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
wordCounts.print()
// Start the computation
ssc.start()
ssc.awaitTermination()
}
}
// scalastyle:on println
Summary
Earlier, as Hadoop have high latency that is not right for near real-time processing needs. In most cases, we use Hadoop for batch processing while used Storm for stream processing. It leads to an increase in code size, a number of bugs to fix, development effort, and causes other issues, which makes the difference between Big data Hadoop and Apache Spark.
Ultimately, Spark Streaming fixed all those issues. It provides the scalable, efficient, resilient, and integrated system. This model offers both execution and unified programming for batch and streaming. Although there is a major reason for its rapid adoption, is the unification of distinct data processing capabilities. It becomes a hot cake for developers to use a single framework to attain all the processing needs. In addition, through Spark SQL streaming data can combine with static data sources.
Follow this link, if you are looking to learn more about data science online!
One of the major reasons organizations migrate to the AWS cloud is to gain the elasticity that can grow and shrink on demand, allowing them to pay only for resources they use. But the freedom to provide on-demand resources can sometimes lead to very high costs if they aren’t carefully monitored. Cost Optimization is one of the five pillars of the AWS Well-Architected Framework, and with good reason. When you optimize your costs, you build a more efficient cloud that helps focus your cloud spend where it’s needed most while freeing up resources to invest in things like more headcount, innovative projects or developing competitive differentiators.
Additionally, considering the cost implementation in mind, we will try to optimise our own cost of AWS usage by visualising it with AWS Quicksight. We will look into the complete setup of viewing the AWS cost and usage reports. Furthermore, we will look to implement our goal using S3 and Athena.
What is AWS Cost and Usage Service?
The AWS Cost and Usage report tracks your AWS usage and provides estimated charges associated with your AWS account. The report contains line items for each unique combination of AWS product, usage type, and operation that your AWS account uses. You can customize the AWS Cost and Usage report to aggregate the information either by the hour or by the day. AWS delivers the report files to an Amazon S3 bucket that you specify in your account and updates the report up to three times a day. You can also call the AWS Billing and Cost Management API Reference to create, retrieve, or delete your reports. You can download the report from the Amazon S3 console, upload the report into Amazon Redshift or Amazon QuickSight, or query the report in Amazon S3 using Amazon Athena.
What is AWS QuickSight?
Amazon QuickSight is an Amazon Web Services utility that allows a company to create and analyze visualizations of its customers’ data. The business intelligence service uses AWS’ Super-fast, Parallel, In-memory Calculation Engine (SPICE) to quickly perform data calculations and create graphs. Amazon QuickSight reads data from AWS storage services to provide ad-hoc exploration and analysis in minutes. Amazon QuickSight collects and formats data, moves it to SPICE and visualizes it. By quickly visualizing data, QuickSight removes the need for AWS customers to perform manual Extract, Transform, and Load operations.
Amazon QuickSight pulls and reads data from Amazon Aurora, Amazon Redshift, Amazon Relational Database Service, Amazon Simple Storage Service (S3), Amazon DynamoDB, Amazon Elastic MapReduce and Amazon Kinesis. The service also integrates with on-premises databases, file uploads and API-based data sources, such as Salesforce. QuickSight allows an end user to upload incremental data in a file or an S3 bucket. The service can also transform unstructured data using a Prepare Data option
What is AWS Athena?
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. Athena is easy to use. Simply point to your data in Amazon S3, define the schema, and start querying using standard SQL. Most results are delivered within seconds. With Athena, there’s no need for complex ETL jobs to prepare your data for analysis. This makes it easy for anyone with SQL skills to quickly analyze large-scale datasets.
Athena is out-of-the-box integrated with AWS Glue Data Catalog, allowing you to create a unified metadata repository across various services, crawl data sources to discover schemas and populate your Catalog with new and modified table and partition definitions, and maintain schema versioning. You can also use Glue’s fully-managed ETL capabilities to transform data or convert it into columnar formats to optimize cost and improve performance.
Setting up AWS S3 and Cost Service
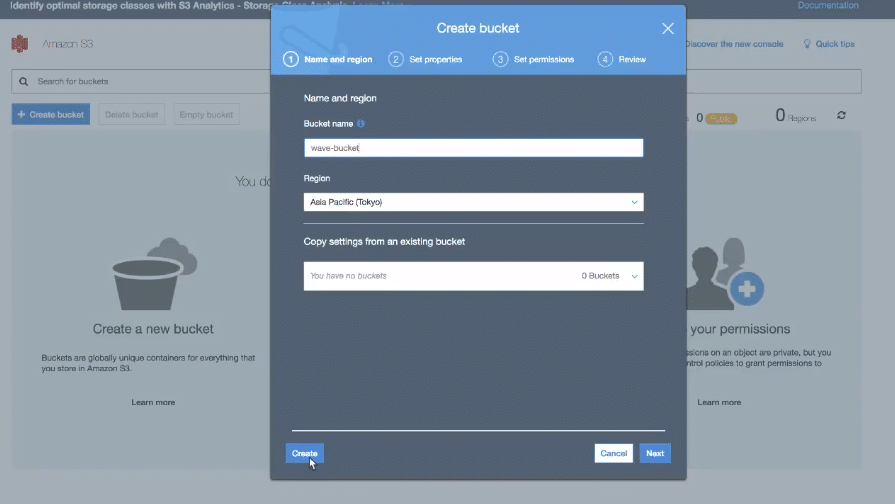
The very first task requires you to set up an S3 bucket. S3 bucket is the location where we will be putting our amazon cost and usage data. Go to your Amazon console and select S3. Click on create bucket button to initialise the setup
Once the create bucket menu pops up, you will see the different options to fill. You need to write the bucket name, mention region and select access settings for the bucket in this step.
Click on create after filling all the fields. Open S3 and navigate to the Permissions tab in the console. We need to copy the access policy from here to access this bucket from quicksight. Furthermore, this policy will help in connecting the bucket with AWS cost and usage service.
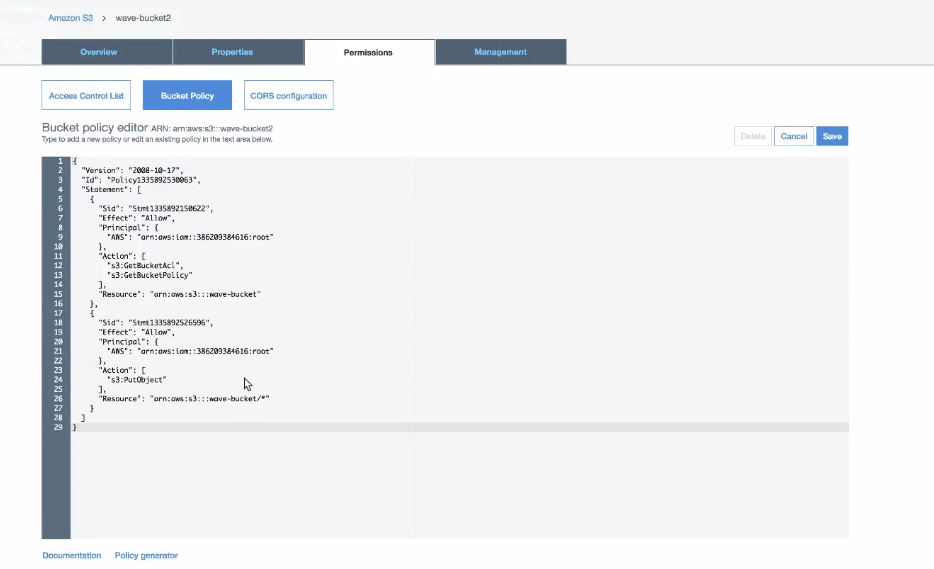
Click on bucket policy. A JSON file will come up with some default settings. We do not need to change much of the things in this file. You can directly copy the code their
We are able to set up our S3 bucket till now. Additionally, we need to create our cost and usage report now. Go to AWS Cost and usage reports tab from the console. Click on create the report to create a new report on cost and usage.
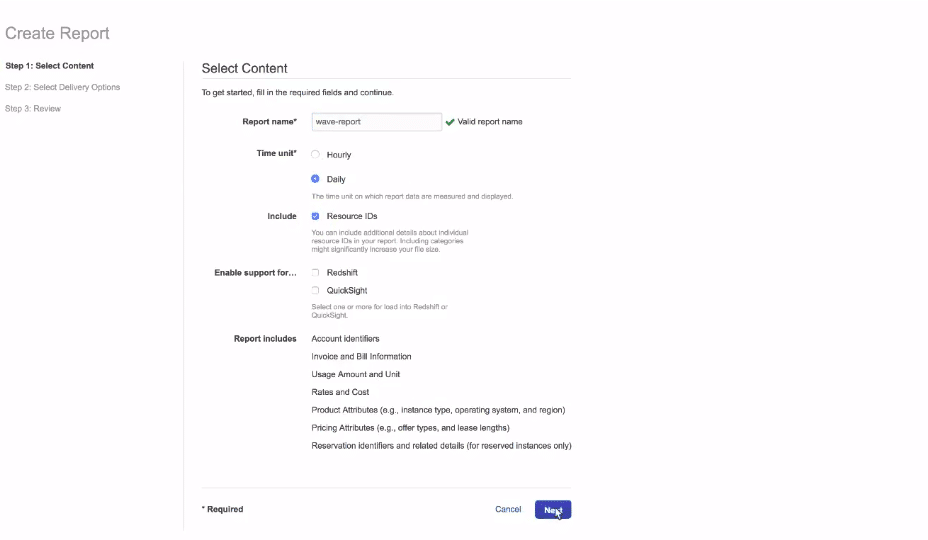
After clicking on create report, a form will pop up. Mention all the necessary details here. The form includes the report name, cost and usage time level. You can directly access these reports for Redshift and Quicksight. In this tutorial, we are storing the data in the S3 bucket first. After storing it in S3 bucker, we will connect it with AWS Quicksight.
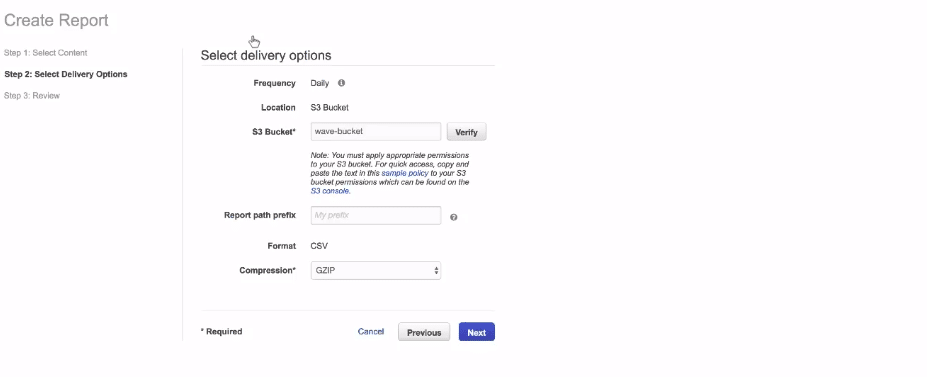
In the second part, we need to select a delivery option. I will mention the name of the final delivery S3 bucket which we created in the previous step.
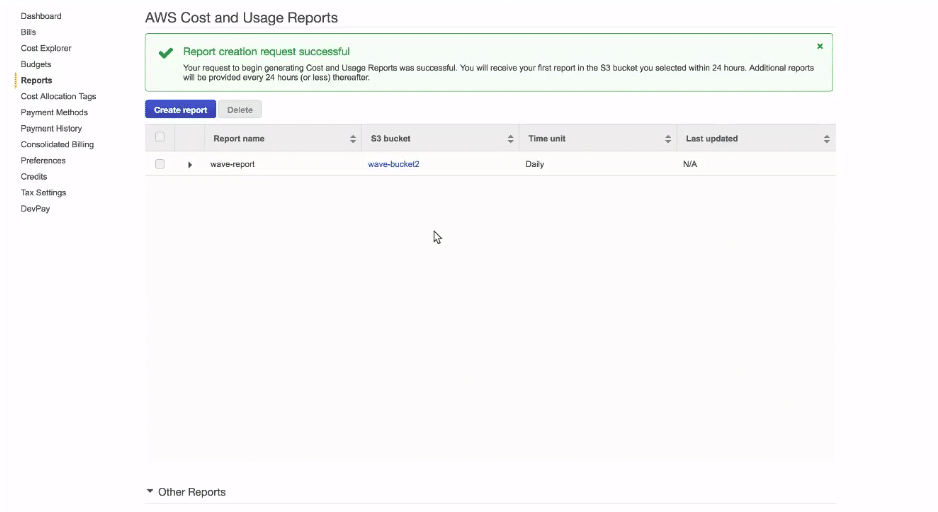
Fill the form and click next. After clicking the next, we have created a report on AWS cost and billing. Click on the newly generated report now.
We need to set up access policies for the report. Click on create a new policy and sample editor will pop up
You can choose to edit the policy depending upon your requirement. Edit the resource section here and mention the correct name of your S3 bucket here. Click on done to complete the policy initialisation
Congratulations! Till this part, we have done most of our work. We have an S3 bucket to store cost and usage data. Also, we have set up cost and usage reports to access our S3 bucket and store the results there.
Setting up Athena (Cloud formation template) and Running Queries
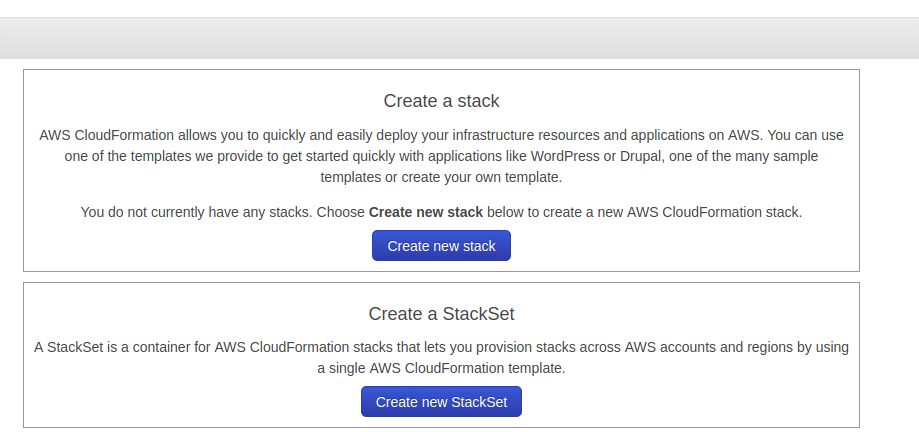
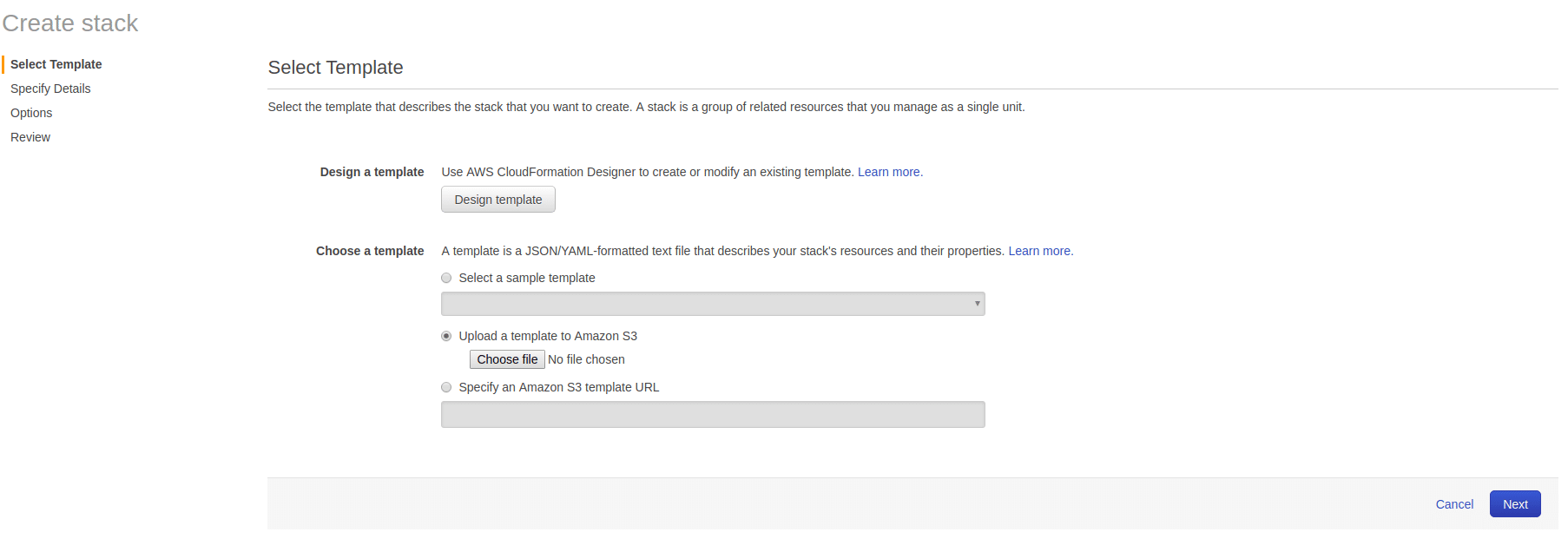
Now we need to setup Athena using a cloud formation template. Go to cloud formation console and click on select “Create New Stack”. Once you click on create a new stack, a sample popup will come.
Here you need to fill the form for creating the template. You can choose to select an existing Amazon S3 or can mention a template URL. Once you fill all the fields, click on next. This will create the Athena stack for you using cloud formation template.
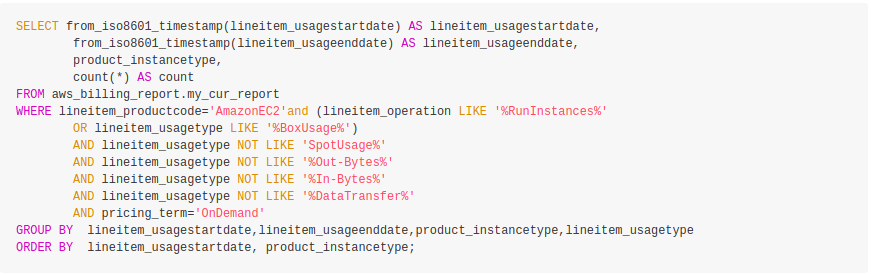
Following is the query command, to access the cost and usage statistics. Also, you can try running the following code on the Athena editor to view the results.
Setting up Quicksight
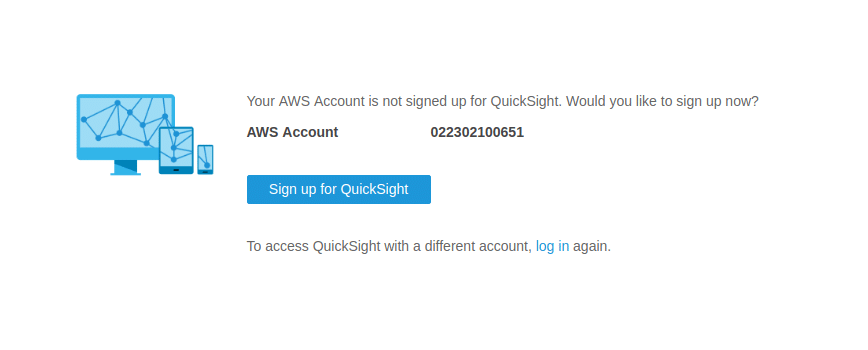
Now we have our Athena and S3 setup completely. We need to setup Quicksight now. Go to Quicksight section, and click on setup. There can be the case when you need to enable or signup for the Quicksight again. In case the below pop up appears, click on signup to create the QuickSight account
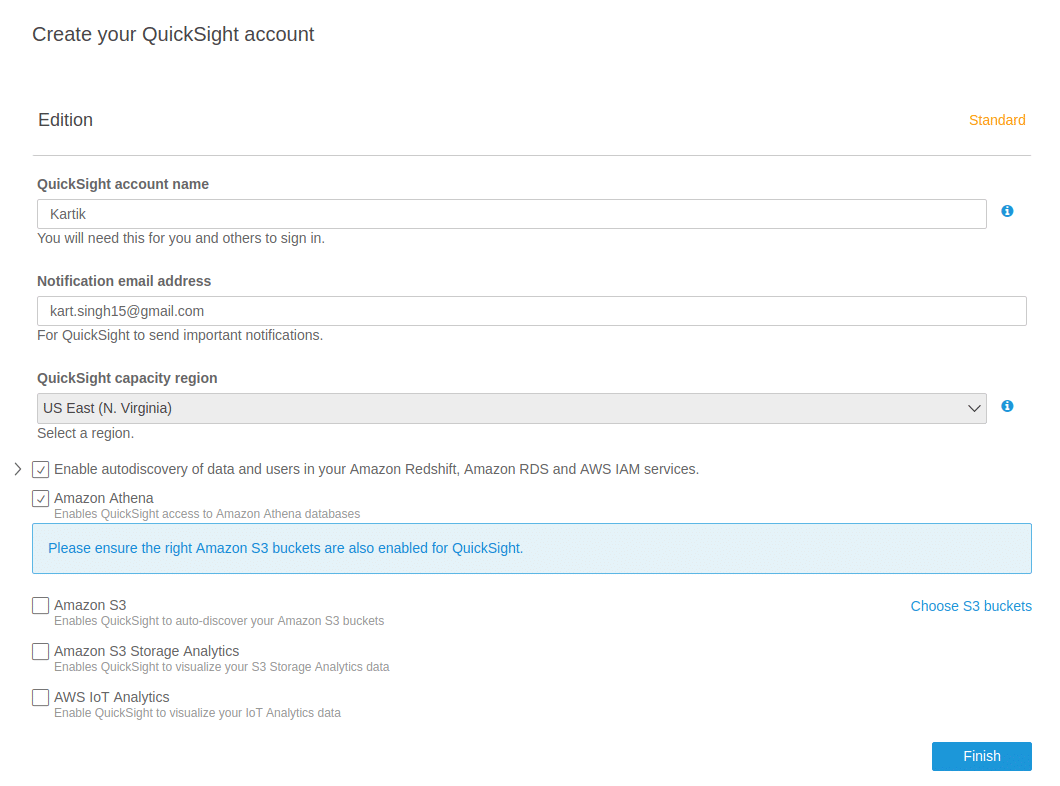
A sample form like below will pop up for you. Mention the account name, email address and the services you want to enable for Quicksight. Once you have filled all the entries, click on Finish to complete the setup
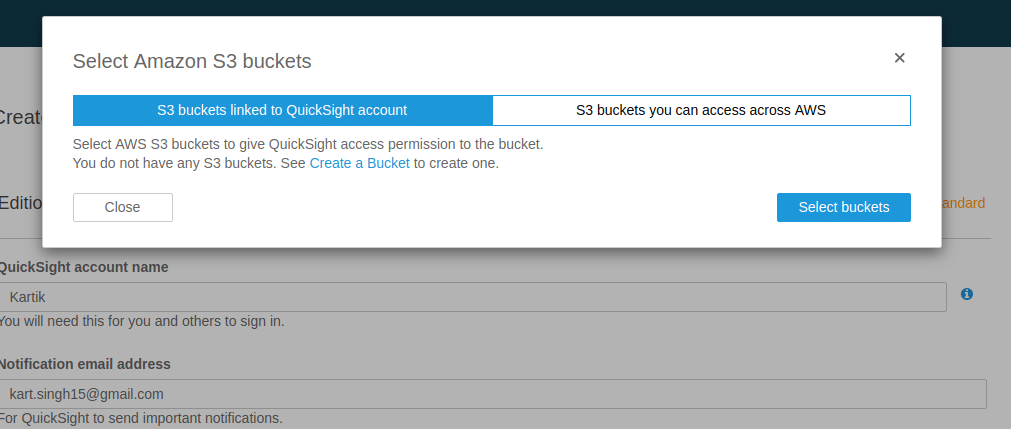
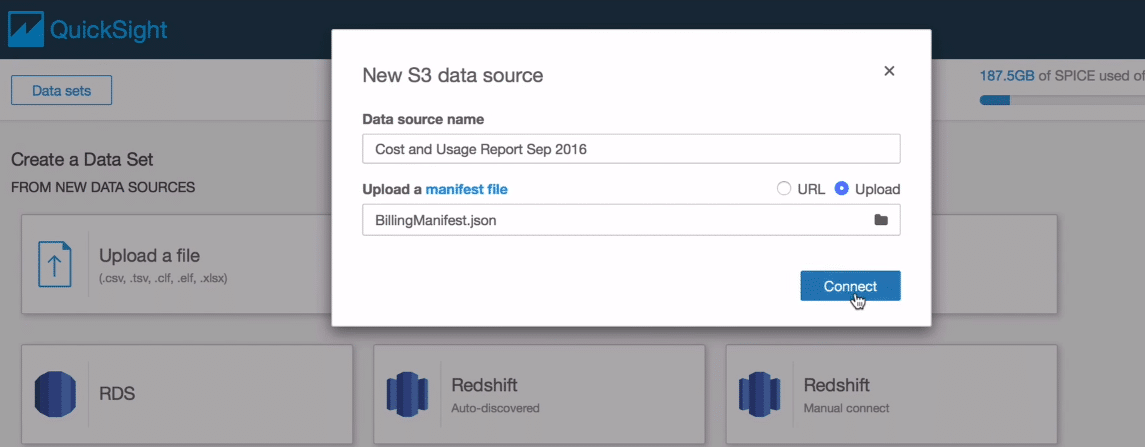
You can choose to connect your s3 account with Quicksight. In the following popup, a sample of already existing buckets will pop for you. You can select the pre-existing buckets and it will automatically get connected with your Quicksight. Here you can easily connect the bucket which holds your AWS cost and usage report. With bucket already connected, you can easily pull the cost and usage report into Quicksight and analyse it.
After setting up the Quicksight, a sample popup will come. You can click on Next to finish the setup.
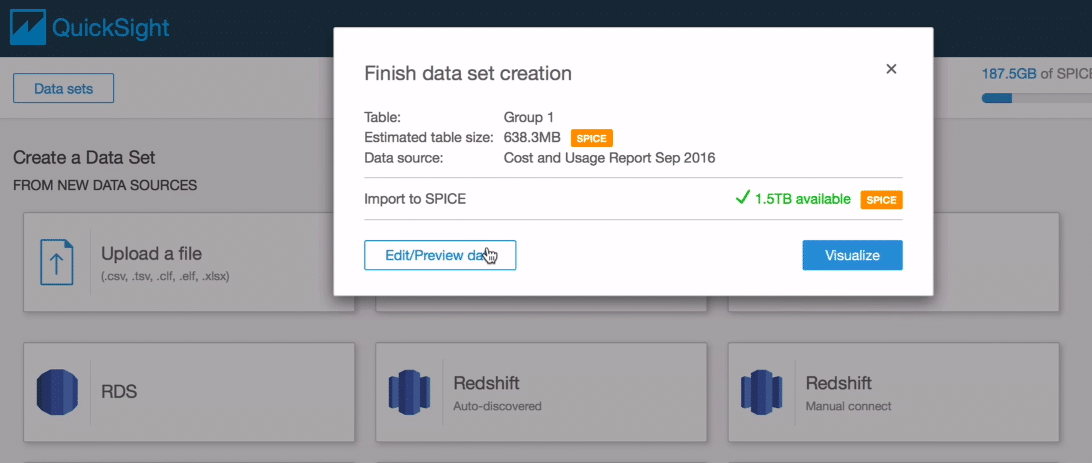
Now the basic setup of Quicksight is complete. All you want to do now is connect your S3 bucket with Quicksight using Athena. Click the Athena option and run the code to extract the usage report into the AWS S3 storage.
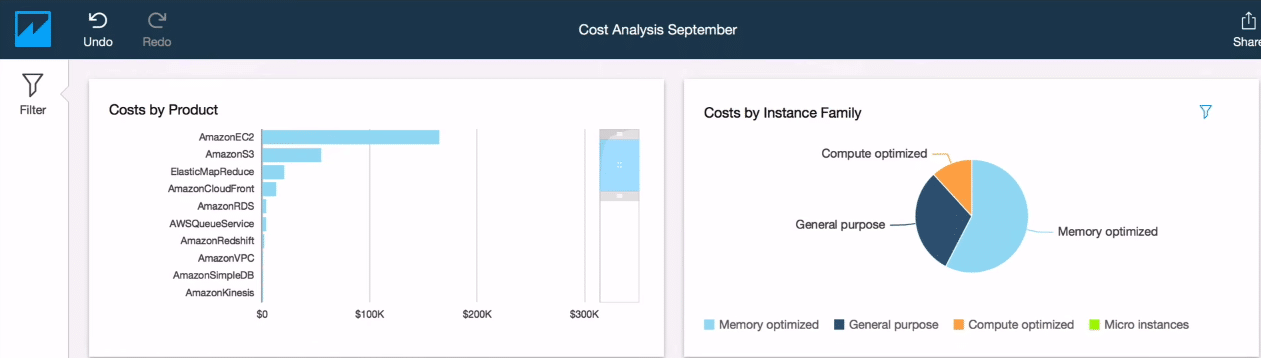
You can then select the column names present in the left sidebar panel to plot the charts in the right panel. Quick sight is a drag-and-drop visualisation tool. You can search for the columns and quick sight will show you the suggested visualisations. You can choose the visualisation and drop it onto the right canvas.
It will automatically plot the charts for you. As you can see, below image contains cost by product visualisation of the AWS services. It also depicts the costs distribution of different instances running on AWS.
Summary
Data-driven decision making is essential throughout an organization. It is no longer prohibitively expensive to ensure access to BI to employees at all levels. Amazon’s QuickSight lets you create and publish interactive dashboards that can be accessed from browsers or mobile devices. You can embed dashboards into your applications, providing your customers with powerful self-service analytics. It easily scales to tens of thousands of users without any software to install, servers to deploy, or infrastructure to manage.
QuickSight is an innovative and cloud-hosted BI platform that addresses the shortfalls of traditional BI systems. Furthermore, its low pay-per-session pricing is a great alternative to the competition. QuickSight can get data from various sources including relational databases, files, streaming, and NoSQL databases. QuickSight also comes with an in-memory caching layer that can cache and calculate aggregates on the fly. With QuickSight, data analysts are truly empowered and can build intuitive reports in minutes without any significant set up by IT.
Enterprises have long relied on BI to help them move their businesses forward. Years ago, translating BI into actionable information required the help of data experts. Today, technology supports BI which is accessible to people at all levels of an enterprise.
All that BI data needs to live somewhere. The data storage solution you choose for enterprise app development positions your business to access, secure, and use data in different ways. That’s why it’s helpful to understand the basic options, how they’re different, and which use cases are suitable for each.
In this blog, we will be looking at the key differences between Data lakes and Data warehouses. We will understand their basics and will try to see their implementation in different fields with different tools.
What is Data Lake?
A data lake is a central location in which you can store all your data, regardless of its source or format. It is typically, although not always, built using Hadoop. The data can be structured or unstructured. You can then use a variety of storage and processing tools — typical tools in the extended Hadoop ecosystem — to extract value quickly and inform key organizational decisions. Because of the growing variety and volume of data, data lakes are an emerging and powerful architectural approach, especially as enterprises turn to mobile, cloud-based applications, and the Internet of Things (IoT) as right-time delivery mediums for big data.
What is a Data Warehouse?
A data warehouse is a large collection of business data used to help an organization make decisions. The concept of the data warehouse has existed since the 1980s when it was developed to help transition data from merely powering operations to fueling decision support systems that reveal business intelligence.
A large amount of data in data warehouses comes from different places such as internal applications such as marketing, sales, and finance; customer-facing apps; and external partner systems, among others. On a technical level, a data warehouse periodically pulls data from those apps and systems; then, the data goes through formatting and import processes to match the data already in the warehouse. The data warehouse stores this processed data so itʼs ready for decision-makers to access. How frequently data pulls occur, or how data is formatted, etc., will vary depending on the needs of the organization.
Differences
1. Data Types
Data warehouses store structured organizational data such as financial transactions, CRM and ERP data. Other data sources such as social media, web server logs, and sensor data, not to mention documents and rich media, are not storable because they are more difficult to model, and their sheer volume makes them expensive and difficult to manage. These types of data are more appropriate for a data lake.
2. Processing
In a data warehouse, data is organized, defined, and metadata is applied before the data is written and stored. We call this process as ‘schema on writeʼ. A data lake consumes everything, including data types considered inappropriate for a data warehouse. Data is present in raw form; information is present to the schema as we extract data from the data source, not when we write it to storage. We call this as a ‘schema on readʼ.
3. Storage and Data Retention
Before we can load data to a data warehouse, data engineers work hard to analyze the data and how to use it for business analysis. They design transformations to summarize and transform the data to enable the extraction of relevant insights. They do not consider the data which doesnʼt answer concrete business questions in the data warehouse. In order to reduce storage space and improve performance — a traditional data warehouse is an expensive and scarce enterprise resource. In a data lake, data retention is less complex, because it retains all data — raw, structured, and unstructured. Data is never going in the deletion phase, permitting analysis of past, current and future information. Data lakes run on commodity servers using inexpensive storage devices, removing storage limitations.
4. Agility
Data warehouses store historical data. Incoming data conforms to a predefined structure. This is useful for answering specific business questions, such as “what is our revenue and profitability across all 124 stores over the past week”. However, if business questions are evolving, or the business wants to retain all data to enable in-depth analysis, data warehouses are insufficient. The development effort to adapt the data warehouse and ETL process to new business questions is a huge burden. A data lake stores data in its original format, so it is immediately accessible for any type of analysis. Information can be retrieved and reused — a user can apply a formalized schema to the data, store it, and share it with others. If the information is not useful, the copy can be discarded without affecting the data stored in the data lake. All this is done with no development effort.
5. Security, Maturity, and Usage
Data warehouses have been around for two decades and are a secure, enterprise-ready technology. Data lakes are getting there, but are newer and have a shorter enterprise track record. A large enterprise cannot buy and implement a data lake like it would a data warehouse — it must consider which tools to use, open source or commercial, and how to piece them together to meet requirements. The end users of each technology are different: a data warehouse is used by business analysts, who query the data via pre-integrated reporting and BI. Business users cannot use a data lake as easily, because data requires processing and analysis to be useful. Data scientists, data engineers, or sophisticated business users, can extract insights from massive volumes of data in the data lake.
Benefits of Data lakes
1. The Historical Legacy Data Architecture Challenge
Some reasons why data lakes are more popular are historical. Traditional legacy data systems are not that open, to say the least, if you want to start integrating, adding and blending data together to analyze and act. Analytics with traditional data architectures weren’t that obvious nor cheap either (with the need for additional tools, depending on the software). Moreover, they weren’t built with all the new and emerging (external) data sources which we typically see in big data in mind.
2. Faster Big Data Analytics as a Driver of Data Lake Adoption
Another important reason to use data lakes is the fact that big data analytics can be done faster. In fact, data lakes are designed for big data analytics if you want and, more important than ever, for real-time actions based on real-time analytics. Data lakes are fit to leverage big quantities of data in a consistent way with algorithms to drive (real-time) analytics with fast data.
3. Mixing and Converging Data: Structured and Unstructured in One Data Lake
A benefit we more or less already mentioned is the possibility to acquire, blend, integrate and converge all types of data, regardless of sources and format. Hadoop, one of the data lake architectures, can also deal with structured data on top of the main chunk of data: the previously mentioned unstructured data coming from social data, logs and so forth. On a side note: unstructured data is the fastest growing form of all data (even if structured data keeps growing too) and is predicted to reach about 90 percent of all data.
Benefits of Data Warehousing
Organizations that use a data warehouse to assist their analytics and business intelligence to see a number of:
Substantial Benefits
Better data, hence adding data sources to a data warehouse enables organizations to ensure that they are collecting consistent and relevant data from that source. They donʼt need to wonder whether the data will be accessible or inconsistent as it comes into the system. This ensures higher data quality and data integrity for sound decision making.
Faster Decisions
Data in a warehouse is in always consistent analyzable formats. It also provides analytical power and a more complete dataset to base decisions on hard facts. Therefore, decision-makers no longer need to rely on hunches, incomplete data, or poor quality data and risk delivering slow and inaccurate results.
Tools for Data Warehousing
1. Amazon Redshift
Amazon Redshift is an excellent data warehouse product which is a very critical part of Amazon Web Services — a very famous cloud computing platform. Redshift is a fast, well-managed data warehouse that analyses data using the existing standard SQL and BI tools. It is a simple and cost-effective tool that allows running complex analytical queries using smart features of query optimization. It handles analytics workload pertaining to big data sets by utilizing columnar storage on high-performance disks and massively parallel processing concepts. One of its very powerful features is Redshift spectrum, that allows the user to run queries against unstructured data directly in Amazon S3. It eliminates the need for loading and transformation. It automatically scales query computing capacity depending on data. Hence the queries run fast. Official URL: Amazon Redshift
2. Teradata
Teradata is another market leader when it comes to database services and products. Most of the competitive enterprise organizations use Teradata DWH for insights, analytics & decision making. Teradata DWH is a relational database management system by Teradata organization. It has two divisions i.e. data analytics & marketing applications. It works on the concept of parallel processing and allows users to analyze data in a simple yet efficient manner. An interesting feature of this data warehouse is its data segregation into hot & cold data. Here cold data refers to less frequently used data and this is the tool in the market these days. Official URL: Teradata
Tools for Data lakes
1. Amazon S3
The Amazon S3-based data lake solution uses Amazon S3 as its primary storage platform. Amazon S3 provides an optimal foundation for a data lake because of its virtually unlimited scalability. You can seamlessly and nondisruptively increase storage from gigabytes to petabytes of content, paying only for what you use. Amazon S3 has 99.999999999% durability. It has scalable performance, ease-of-use features, and native encryption and access control capabilities. Amazon S3 integrates with a broad portfolio of AWS and third-party ISV data processing tools.
2. Azure Data lake
Azure Data Lake Storage Gen2 is a highly scalable and cost-effective data lake solution for big data analytics. It combines the power of a high-performance file system with massive scale and economy to help you speed your time to insight. Data Lake Storage Gen2 extends Azure Blob Storage capabilities and can handle analytics workloads. Data Lake Storage Gen2 is the most comprehensive data lake available.
Summary
So Which is Better? Data Lake or the Data Warehouse? Both! Instead of a Data Lake vs Data Warehouse decision, it might be worthwhile to consider a target state for your enterprise that includes a Data Lake as well as a Data Warehouse. Just like the advanced analytic processes that apply statistical and machine learning techniques on vast amounts of historical data, the Data Warehouse can also take advantage of the Data Lake. Newly modeled facts and slowly changing dimensions can now be loaded with data from the time the Data Lake was built instead of capturing only new changes.
This also takes the pressure off the data architects to create each and every data entity that may or may not be used in the future. They can instead focus on building a Data Warehouse exclusively on current reporting and analytical needs, thereby allowing it to grow naturally.
Follow this link, if you are looking to learn more about data science online!
Building data pipelines is a core component of data science at a startup. In order to build data products, you need to be able to collect data points from millions of users and process the results in near real-time. Today, many organizations nowadays are struggling with the quality of their data. Data quality (DQ) problems can arise in various ways. Here are common causes of bad data quality:
Multiple data sources: Multiple sources with the same data may produce duplicates; a problem of consistency.
Limited computing resources: Lack of sufficient computing resources and/or digitalization may limit the accessibility of relevant data; a problem of accessibility.
Changing data needs: Data requirements change on an ongoing basis due to new company strategies or the introduction of new technologies; a problem of relevance.
Different processes using and updating the same data; a problem of consistency.
In this blog, we are going to look into the world of data lakes and their significance. Furthermore, we will peep into some of the inherent issues in data lakes like quality management. In the end, we will discuss some of the quality measures to control the quality of data in data lakes.
What is Data Lake?
A data lake is a centralized place, like a lake, that allows you to hold a lot of raw data in its native format, structured and unstructured, at any scale. Furthermore, you can store your data as- it is, without having to first structure the data or define it until its needed. Its purpose is for creating reporting dashboards and visualizations, real-time analytics, and machine learning. Also, this can guide better programmatic advertising decisions.
In its extreme form, a data lake ingests data in its raw, original state, straight from data sources. This happens without any cleansing, standardization, remodelling, or transformation. These and other sacrosanct data management disciplines are applicable on the fly. Moreover, it helps in enabling ad hoc queries, data exploration, and discovery-oriented analytics. The early ingestion of data means that operational data is present and made available to analytics as soon as possible. Additionally, the raw state of the data ensures that data analysts, data scientists, and similar users have ample raw material. They can repurpose into many diverse data sets, as needed by unanticipated analytics questions.
Components of Data Lake
A Data Lake is a platform combining a number of advanced, complex data storage and data analysis technologies.
To simplify, we might group the components of a Data Lake into four categories, representing the four stages of data management:
Data Ingestion and Storage, that is the capability of acquiring data in real time or in batch, and also the capacity to store data and make it accessible.
Data Processing, that is the ability to work with raw data so that they’re ready to be analysed through standard processes. It also includes the capability of engineering solutions that extract value from the data, leveraging automated, periodical processes resulting from the analysis operations.
Data Analysis, that is the creation of modules that extract insights from data in a systematic manner; this can happen in real time or by means of processes that are running periodically.
Data Integration, that is the ability to connect applications to the platform; in the first place, applications must allow querying the Data Lake to extract the data in the right format, based on the usage you want to make of it
Why use Data Lakes
1. Data Indexing
Data Lakes allow you to store relational data (a collection of data items organized as a set of formally-described tables from which data can be accessed or reassembled in many different ways without having to reorganize the database tables.) — operational databases (data collected in real-time), and data from line of business applications, and non-relational data like mobile apps, connected devices, and social media. They also give you the ability to understand what data is in the lake through crawling, cataloguing, and indexing of data.
2. Analytics
Data Lakes allow data scientists, data developers, and operations analysts to access data with their choice of analytic tools and frameworks. This also includes open source data frameworks such as Apache Hadoop, Presto, and Apache Spark, and commercial offerings from data warehouse and business intelligence vendors. Data Lakes allow you to run Analytics without the need to move your data from one system to another.
3. Machine Learning
Data Lakes will allow organizations to generate different types of marketing and operational insights. It includes reporting on historical data and doing machine learning where models produce forecasts and predictions.
4. Improved Customer Interaction
A Data Lake can combine customer data from a CRM platform with social media data analytics, as well as a marketing platform that includes buying history to empower the business to understand the most profitable audiences, the root of customer churn, and what promotions or rewards could increase loyalty.
The Challenge with Data Lakes
A challenge in data lakes is the inability for analysts to determine data quality because a thorough check-up has not taken place. Also, there is no way to use insights from others who have worked with the data, as there is no account of the lineage of findings by previous analysts. Finally, one of the biggest risks of data lakes is security and access control. Data can be placed into a lake without any oversight, and some of the data may contain privacy and regulatory requirements that other data doesn’t.
Ways to Improve Quality in Data Lakes
1. Use of Machine Learning and NLP
Machine learning can be a game changer because it can capture tacit knowledge from the people that know the data best, then turn this knowledge into algorithms, which can be used to automate data processing at scale. This is exactly how Talend is leveraging Spark machine learning to learn from data stewards during data matching and deduplication of data samples, and then apply it at big data scale for billions of records.
2. Setting the standards for agile data quality
for companies to get the most out of their digital transformation projects and build an agile data lake, they need to design data quality processes from the start. Organisations should focus on standardising the following for maintaining the quality of big data
Roles — Identify roles including data stewards and users of data
Discovery — Understand where data is coming from, where it is going and what shape it is in. Focus on cleaning your most valuable and most used data first
Standardization — Validate, cleanse, and transform data. Add metadata early so data can be found by humans and machines. Identify and protect personal and private organizational data with data masking.
Reconciliation — Verify that data was migrated correctly
Self-service — Make data quality agile, by letting people who know the data best, clean their data
Automate — Identify where machine learning in the data quality process can help, such as data deduplication
Monitor and Manage — Get continuous feedback from users, come up with data quality measurement metrics to improve
3. Employing data quality management frameworks
Another category of frameworks focuses on the maturity of data quality management processes. They aim at assessing the maturity level of DQ management to understand best practices in mature organizations and identify areas for improvement. Popular examples of such frameworks include Total Data Quality Management (TDQM), Capability Maturity Model Integration (CMMI), Control Objectives for Information and Related Technology (CobiT), Information Technology Infrastructure Library (ITIL), and Six Sigma.
As an example, we can take the TDQM framework. A TDQM cycle consists of four steps, Define, Measure, Analyze, and Improve. The define step identifies the pertinent data quality dimensions. One can quantify them using metrics in the Measure step. Some example metrics are the percentage of customer records with the incorrect address (accuracy), the percentage of customer records with missing birth date (completeness), or an indicator specifying the last update of the customer. The Analyze step tries to identify the root cause of data quality problems. We remedy the previous issues in the improve step. Example actions could be automatic and periodic verification of customer addresses, the addition of a constraint that makes the birth date a mandatory data field, and the generation of alerts when there is no update to customer data in 6 months.
Summary
More and more companies are experimenting with data lakes, hoping to capture inherent advantages in information streams that are readily accessible regardless of platform and business case and that cost less to store than do data in traditional warehouses. As with any deployment of new technology, however, companies will need to reimagine systems, processes, and governance models. Furthermore, if actual data quality improvement is not an option in the short term for reasons of technical constraints or strategic priorities, it is sometimes a partial solution to annotate the data with explicit information about its quality. Such data quality metadata can be stored in the catalogue, possibly with other metadata.
Follow this link, if you are looking to learn more about data science online!
Amazon Web Services (AWS) was the first significant player to offer reasonably priced cloud infrastructure and services, and it continues to be the single largest vendor in the cloud market. With AWS, businesses have access to extremely durable storage, cost-effective compute power, high-performing databases and more without the hassle of provisioning and managing infrastructure. AWS services are available without any up-front investments, and you pay for only what you use.
ETL is one of the primary tasks in the analytics industry. You can do ETL in AWS in a few different ways:
AWS Glue
Data pipeline
A custom solution, e.g. a Docker
In this blog, we are going to focus the ETL part through AWS Glue. We will also look at components of AWS Glue. Furthermore, we will try to play with AWS glue a bit in order to understand it in depth.
What is AWS Glue?
AWS Glue is a fully managed ETL (extract, transform, and load) service that makes it simple and cost-effective to categorize your data, clean it, enrich it, and move it reliably between various data stores. It consists of a central metadata repository known as the AWS Glue Data Catalog, an ETL engine that automatically generates Python or Scala code, and a flexible schedule that handles dependency resolution, job monitoring, and retries. Also, AWS Glue is serverless, so there’s no infrastructure to set up or manage.
Use the AWS Glue console to discover data, transform it, and make it available for search and querying. The console calls the underlying services to orchestrate the work required to transform your data. You can also use the AWS Glue API operations to interface with AWS Glue services. Edit, debug and test your Python or Scala Apache Spark ETL code using a familiar development environment.
AWS Glue Components
AWS Glue provides a console and API operations to set up and manage your extract, transform, and load (ETL) workload. You can use API operations through several language-specific SDKs and the AWS Command Line Interface (AWS CLI)
AWS Glue uses the AWS Glue Data Catalog to store metadata about data sources, transforms, and targets. The Data Catalog is a drop-in replacement for the Apache Hive Metastore. The AWS Glue Jobs system provides a managed infrastructure for defining, scheduling, and running ETL operations on your data.
AWS Glue Console
You use the AWS Glue console to define and orchestrate your ETL workflow. The console calls several API operations in the AWS Glue Data Catalog and AWS Glue Jobs system to perform the following tasks:
Define AWS Glue objects such as jobs, tables, crawlers, and connections.
Schedule when crawlers run.
Define events or schedules for job triggers.
Search and filter lists of AWS Glue objects.
Edit transformation scripts.
AWS Glue Data Catalog
The AWS Glue Data Catalog is your persistent metadata store. It is a managed service that lets you store, annotate, and share metadata in the AWS Cloud in the same way you would in an Apache Hive metastore.
Each AWS account has one AWS Glue Data Catalog. It provides a uniform repository where disparate systems can store and find metadata to keep track of data in data silos and use that metadata to query and transform the data.
You can use AWS Identity and Access Management (IAM) policies to control access to the data sources managed by the AWS Glue Data Catalog. These policies allow different groups in your enterprise to safely publish data to the wider organization while protecting sensitive information. IAM policies let you clearly and consistently define which users have access to which data, regardless of its location.
AWS Glue Crawlers and Classifiers
AWS Glue also lets you set up crawlers that can scan data in all kinds of repositories, classify it, extract schema information from it, and store the metadata automatically in the AWS Glue Data Catalog. From there it can be used to guide ETL operations.
AWS Glue ETL Operations
Using the metadata in the Data Catalog, AWS Glue can autogenerate Scala or PySpark (the Python API for Apache Spark) scripts with AWS Glue extensions that you can use and modify to perform various ETL operations. For example, you can extract, clean, and transform raw data, and then store the result in a different repository, where it can be queried and analyzed. Such a script might convert a CSV file into a relational form and save it in Amazon Redshift.
The AWS Glue Jobs System
The AWS Glue Jobs system provides managed infrastructure to orchestrate your ETL workflow. You can create jobs in AWS Glue that automate the scripts you use to extract, transform, and transfer data to different locations. Jobs can be scheduled and chained, or they can be triggered by events such as the arrival of new data.
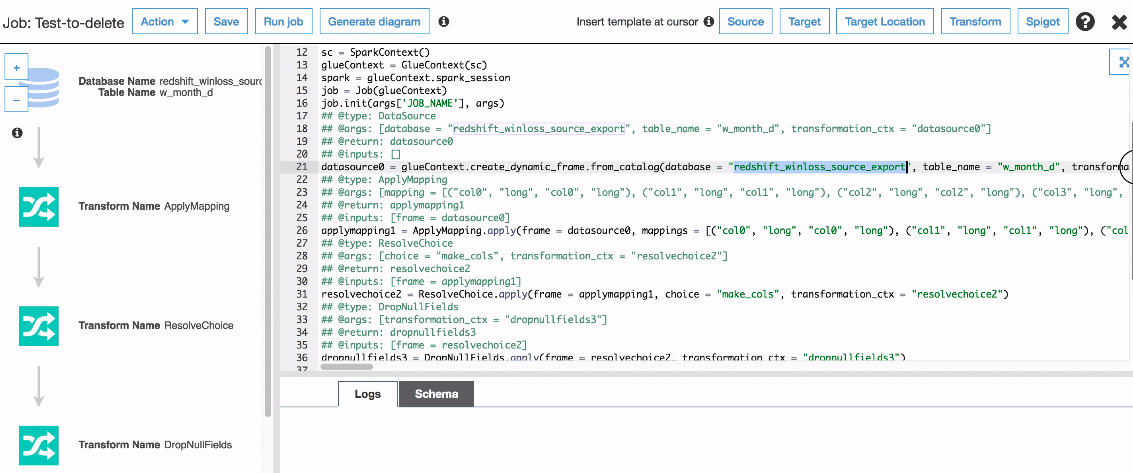
Importing Metadata and Running Crawlers
In this section, we will be importing data table and it’s metadata from Amazon redshift to Glue. We will be using the crawler features present in the Amazon Glue to import the data. So let us start importing!
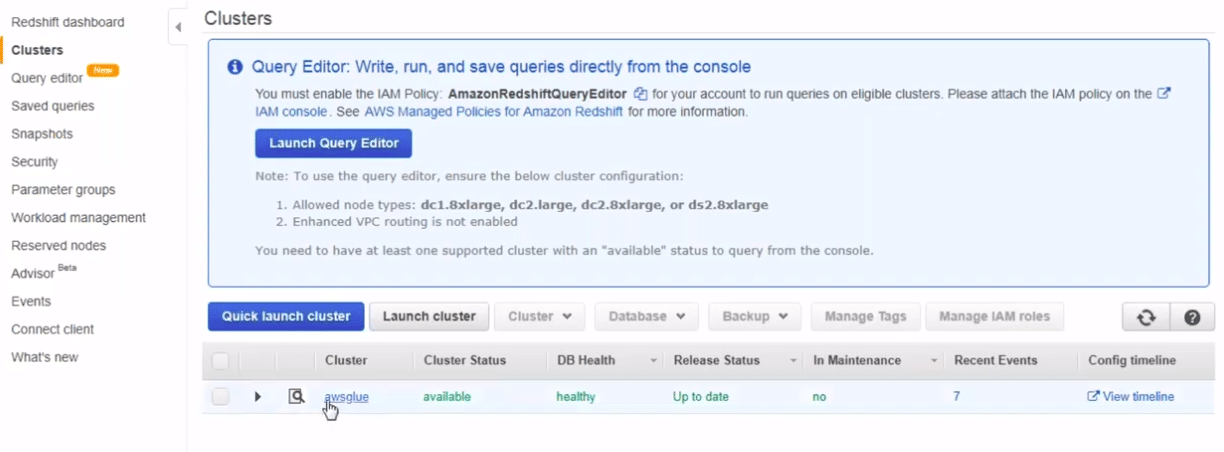
First, we will go to our redshift cluster and navigate to the database. From there, we will navigate to our final table.
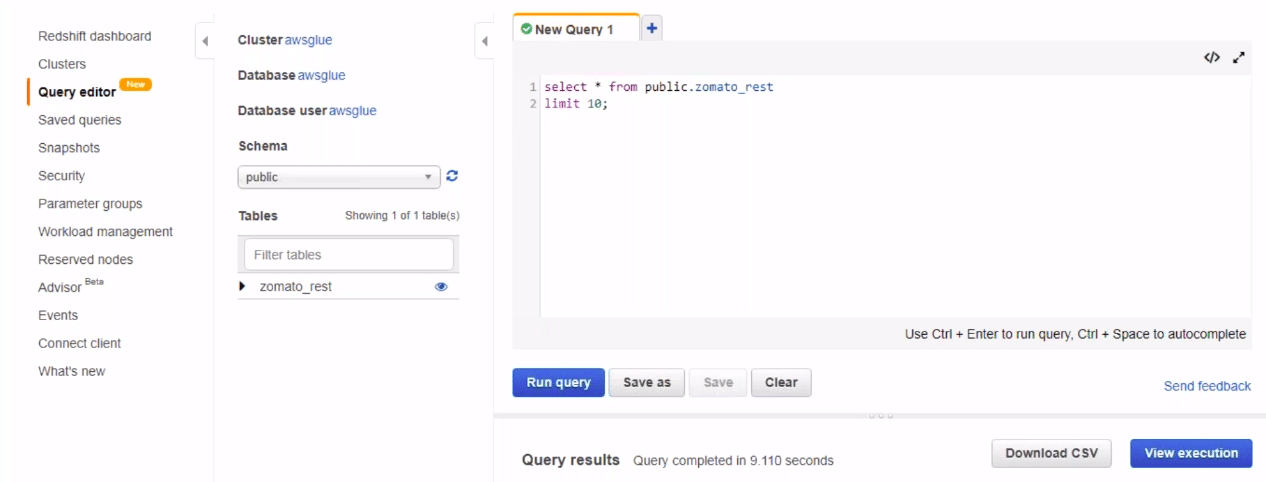
We can try running the query to view the data. We will view all the components of the data which we need to export to Glue.
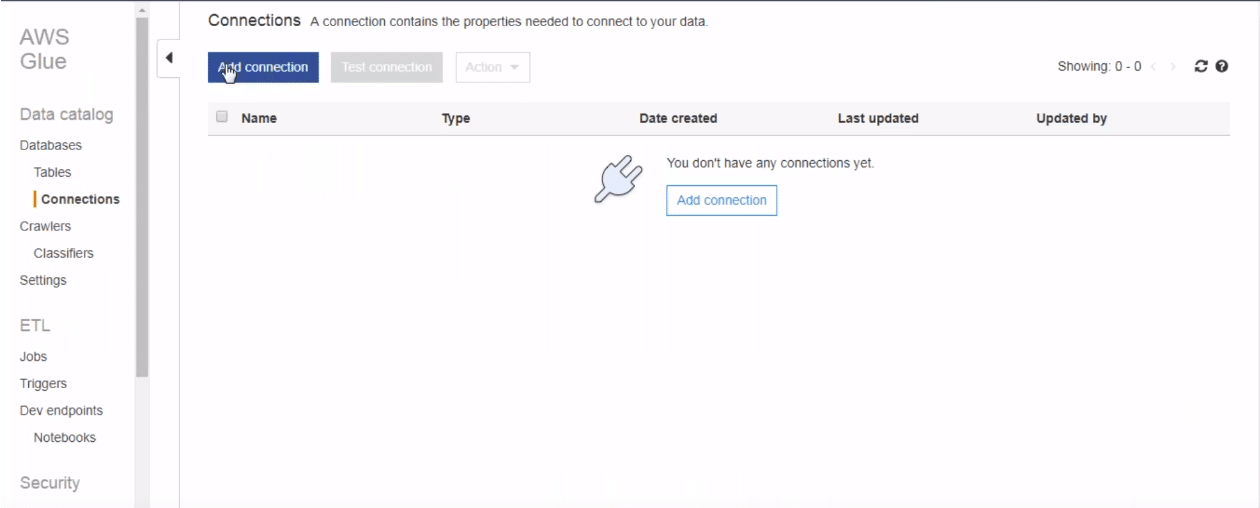
Once we have our data, we can go to AWS Glue and select add connection feature.
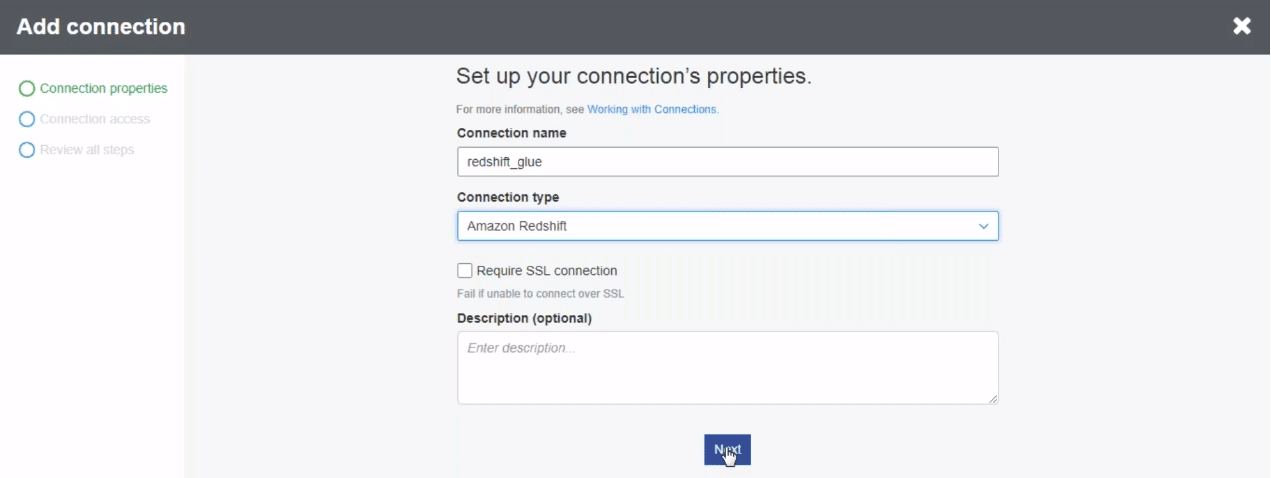
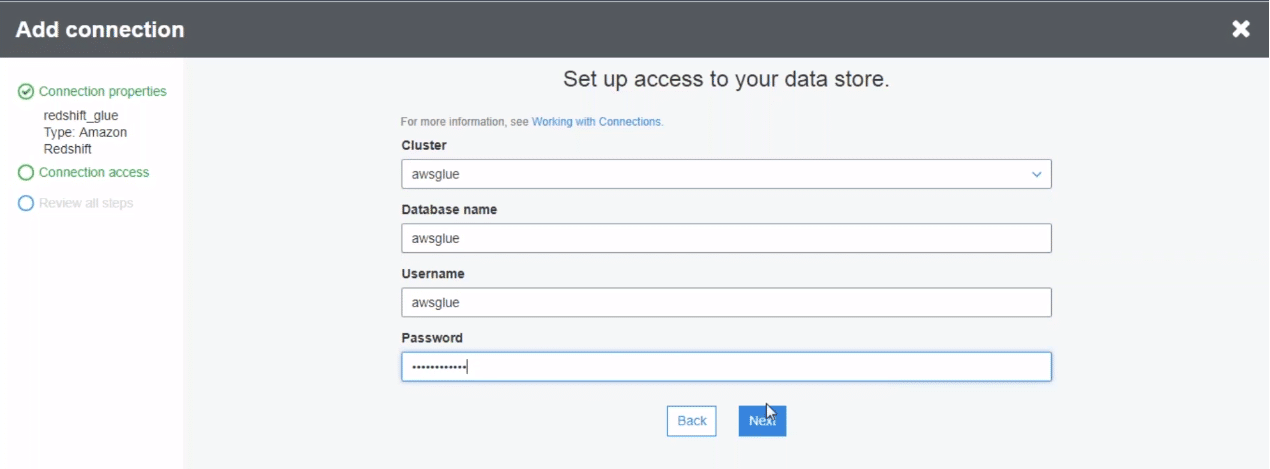
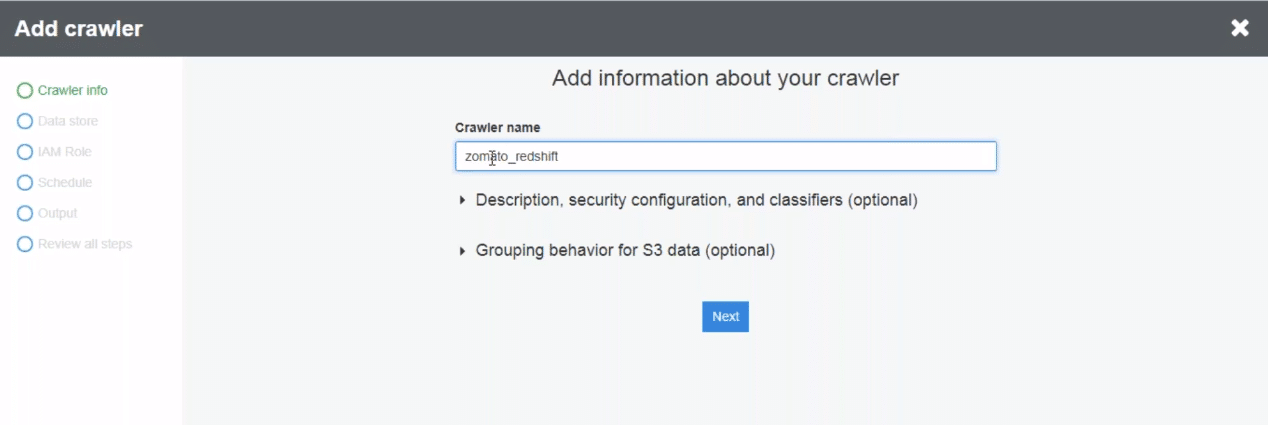
After clicking add the connection, we need to mention the various attributes to set up the connection. You need to mention the connection name and type. Since we are importing from redshift, we mention redshift here. We follow a similar process to fill the remaining setup.
Click next to set up the connection!
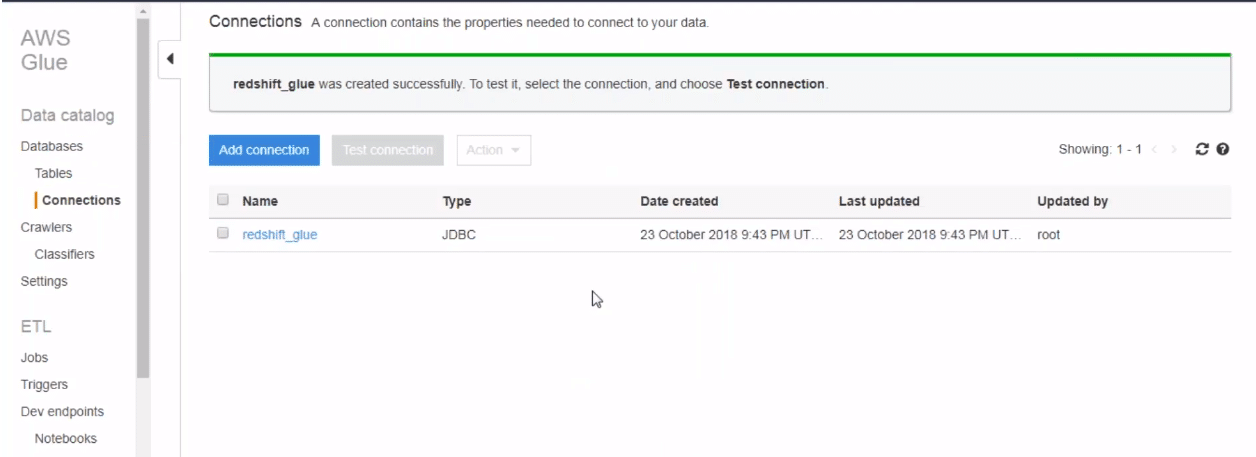
Once, you click next, AWS starts setting up the connection to the redshift. Once the connection is there, you can see it on your console.
Now we need to set up a crawler to get the data from redshift to the Glue. Similar to add a connection, we fill different attributes of the crawler here
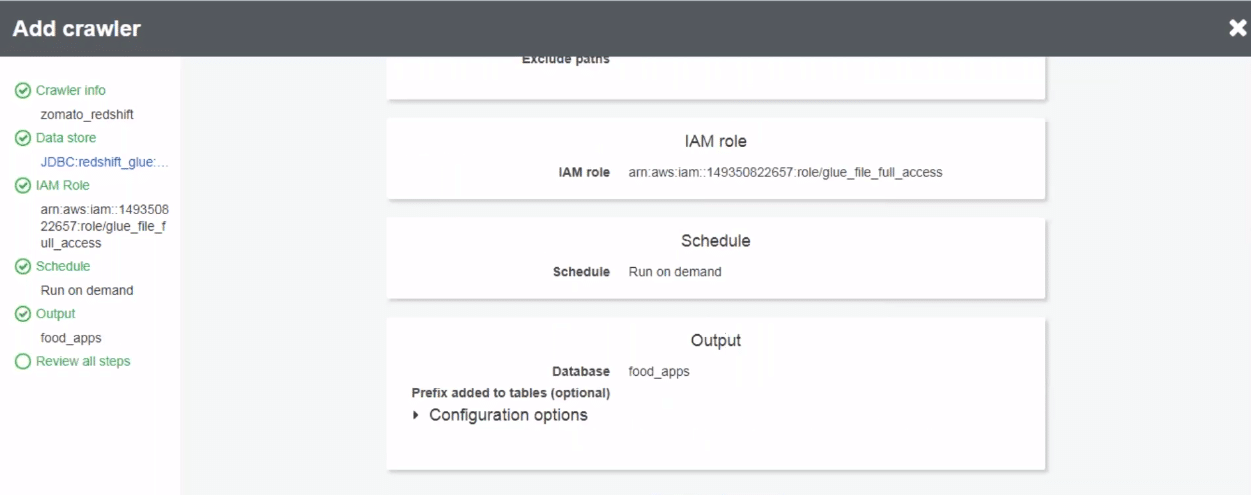
You need to mention parameters like the database to read, the table to read, connection type etc to set up the crawler. Once we have all the parameters filled, we can click next to set up the crawler.
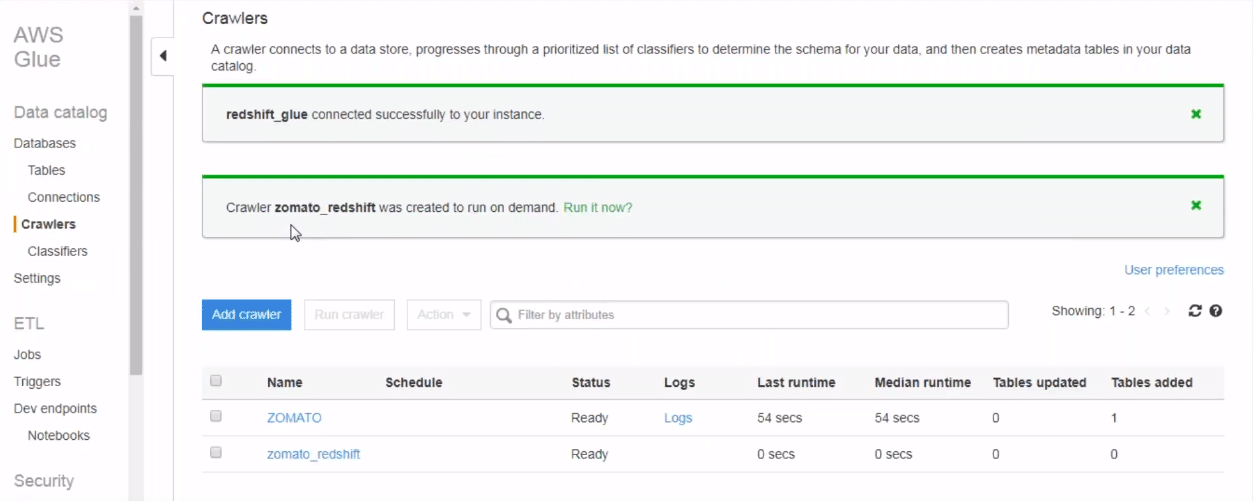
As you can see in the below screenshot, after clicking next, the crawler is setup. All we need to do now is run it. Click on “run it now” button. Upon clicking the button, AWS runs the crawler. Once the crawler task finishes, it stores all the data from redshift to Glue.
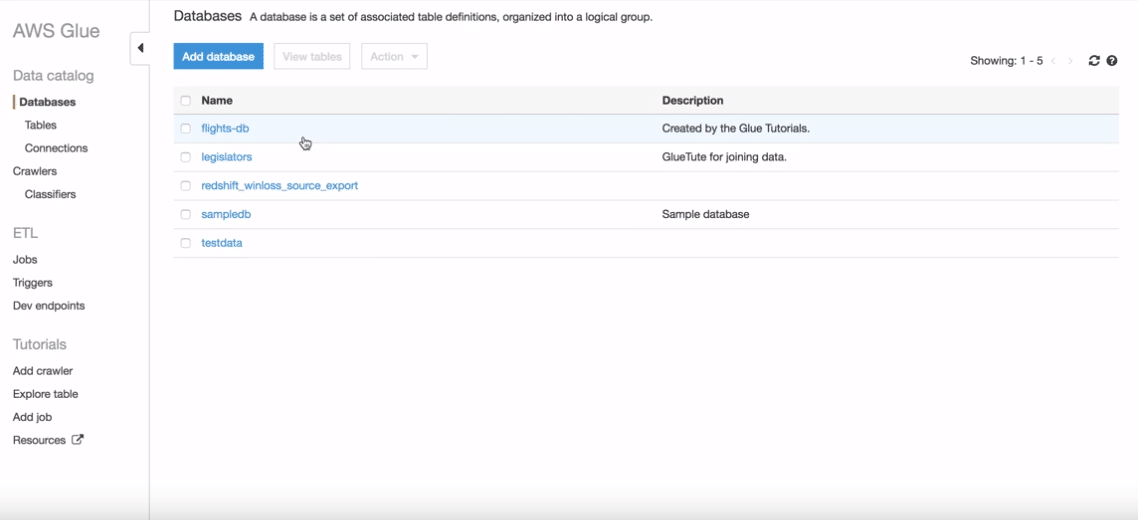
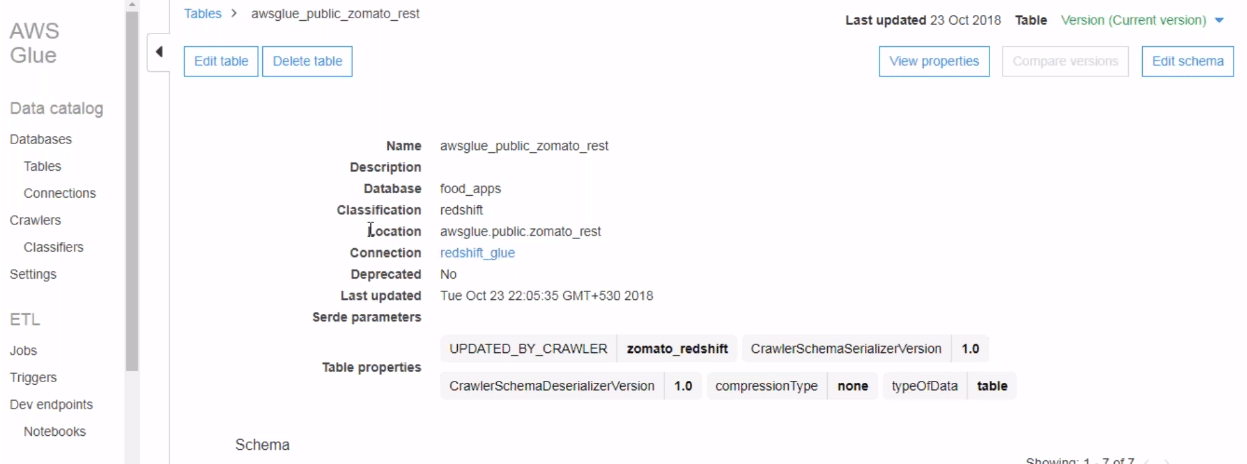
You can actually view the imported tables. Also, you can go to the tables and then you can see your specific table created there. Now click on the table to view the properties and the schema
Writing and Triggering Scripts in Glue
A script contains the code that extracts data from sources, transforms it, and loads it into targets. AWS Glue runs a script when it starts a job.
AWS Glue ETL scripts can be coded in Python or Scala. Python scripts use a language that is an extension of the PySpark Python dialect for extract, transform, and load (ETL) jobs. The script contains extended constructs to deal with ETL transformations. When you automatically generate the source code logic for your job, a script is created. You can edit this script, or you can provide your own script to process your ETL work.
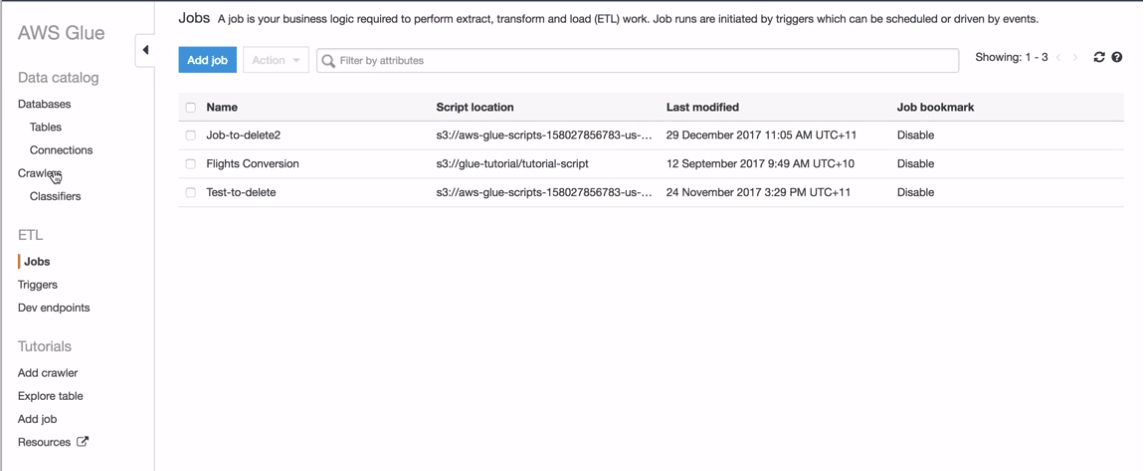
To make a script, click on jobs in AWS Glue. You can make a new script here. In this case, we are editing our old one. Click on the script/job and a sample pop up will come. To edit the script, you can click “edit script”.
Edit script option gives you a full editor view to manage the job. The job is more again like ETL operations which you want to perform on the moving data.
There can be cases when you want your jobs to happen in a sequence. you can use triggers. Triggers can run the code upon receiving some action. For example, you may want a script to run once a prev script has finished the execution. In the screenshot below too, you can see how delete job is mapped to completion trigger of some other job. Once that previous job finishes execution, only then delete job will start the execution
Summary
I’ve used a custom solution for a while but recently decided to move to Glue, gradually. Why? Because when it is set up, you have so much less to worry about. Glue is the preferred choice when you need to move data around. If you’re unsure what route to take, stick to Glue. If you find it doesn’t fit your needs well, only then look elsewhere.
Follow this link, if you are looking to learn more about data science online!





;" src="https://dimensionless.in/how-to-discover-and-classify-metadata-using-apache-atlas-on-amazon-emr/embed/#?secret=dsDpxQUGMT" data-secret="dsDpxQUGMT" width="600" height="338" title="“How to Discover and Classify Metadata using Apache Atlas on Amazon EMR” — DIMENSIONLESS TECHNOLOGIES PVT.LTD." frameborder="0" marginwidth="0" marginheight="0" scrolling="no"></iframe>)

;" src="https://dimensionless.in/how-to-discover-and-classify-metadata-using-apache-atlas-on-amazon-emr/embed/#?secret=joTh4EHf9v" data-secret="joTh4EHf9v" width="600" height="338" title="“How to Discover and Classify Metadata using Apache Atlas on Amazon EMR” — DIMENSIONLESS TECHNOLOGIES PVT.LTD." frameborder="0" marginwidth="0" marginheight="0" scrolling="no"></iframe>)


;" src="https://dimensionless.in/how-to-discover-and-classify-metadata-using-apache-atlas-on-amazon-emr/embed/#?secret=5ySnzA1FzV" data-secret="5ySnzA1FzV" width="600" height="338" title="“How to Discover and Classify Metadata using Apache Atlas on Amazon EMR” — DIMENSIONLESS TECHNOLOGIES PVT.LTD." frameborder="0" marginwidth="0" marginheight="0" scrolling="no"></iframe>)