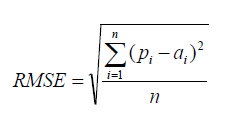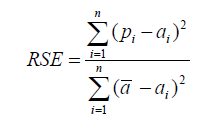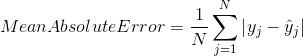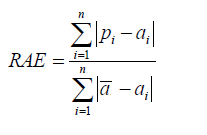Computing infrastructure is an ever-changing landscape of technology advancements. Current changes affect the way companies deploy smart manufacturing systems to make the most of advancements.
The rise of edge computing capabilities coupled with traditional industrial control system (ICS) architectures provides increasing levels of flexibility. In addition, time-synchronized applications and analytics augment, or in some cases minimize, the need for larger Big Data operations in the cloud, regardless of cloud premise.
In this blog, we will start with the definition of edge computing. After that, we will discuss the need of edge computing and it’s applications. Also, we will try to understand the scope of edge computing in the future.
What is Edge computing
Consolidation and the centralized nature of cloud computing have proven cost-effective and flexible, but the rise of the IIoT and mobile computing has put a strain on networking bandwidth. Ultimately, not all smart devices need to use cloud computing to operate. In some cases, architects can — and should — avoid the back and forth. Edge computing could prove more efficient in some areas where cloud computing operates.
Furthermore, edge computing permits data processing closer to it’s origin (i.e., motors, pumps, generators or other sensors), reducing the need to transfer that data back and forth between the cloud.
Additionally, think of edge computing in manufacturing as a network of micro data centers capable of hosting, storage, computing and analysis on a localized basis while pushing aggregate data to a centralized plant or enterprise data center, or even the cloud (private or public, on-premise or off) for further analysis, deeper learning, or to feed an artificial intelligence (AI) engine hosted elsewhere.
According to Microsoft, in edge computing, compute resources are “placed closer to information-generation sources to reduce network latency and bandwidth usage generally associated with cloud computing.” This helps to ensure continuity of services and operations even if cloud connections aren’t steady.
Also, this moving of compute and storage to the “edge” of the network, away from the data centre and closer to the user, cuts down the amount of time it takes to exchange messages compared with traditional centralized cloud computing. Moreover, according to research by IEEE, it can help to balance network traffic, extend the life of IoT devices and, ultimately, reduce “response times for real-time IoT applications.”
Terms in Edge Computing
Like most technology areas, edge computing has its own lexicon. Here are brief definitions of some of the more commonly used terms
Edge devices: These can be any device that produces data. These could be sensors, industrial machines or other devices that produce or collect data.
Edge: What the edge depends on the use case. In a telecommunications field, perhaps the edge is a cell phone or maybe it’s a cell tower. Furthermore, in an automotive scenario, the edge of the network could be a car. Also, in manufacturing, it could be a machine on a shop floor. Additionally, in enterprise IT, the edge could be a laptop.
Edge gateway: A gateway is a buffer between where edge computing processing is done and the broader fog network. The gateway is the window into the larger environment beyond the edge of the network.
Fat client: Software that can do some data processing in edge devices. This is opposite to a thin client, which would merely transfer data.
Edge computing equipment: Edge computing uses a range of existing and new equipment. We can outfit many devices, sensors and machines to work in an edge computing environment by simply making them Internet-accessible. Cisco and other hardware vendors have a line of rugged network equipment that has hardened exteriors meant to be used in field environments. A range of compute servers and even storage-based hardware systems like Amazon Web Service’s Snowball have usage in edge computing deployments.
Mobile edge computing: This refers to the buildout of edge computing systems in telecommunications systems, particularly 5G scenarios
Why Rise in Edge Computing
1. Latency in decision making
Businesses are getting a huge boost from computerised systems, especially as they evolve into the cloud era. But bringing that same level of technology across different sites has proven to be not so straightforward for many companies, particularly as the sites started generating more data. The main concern is latency, that being the time it takes for data to move between points. As with the NYSE, a little distance goes a long way in the computer world, so it stands to reason that delays in sending data needed to reach decisions will translate into delays for the business.
2. Decentralisation and scaling
To some, it may seem counterintuitive to move away from the centre. Wasn’t centralisation the whole point of cloud systems? But the cloud isn’t about pooling everything in the middle. It’s about scale and making it easier to access the services that the business uses every day. Also, the transfer gap problem between sites and data centres predates the cloud era. Yet cloud can exacerbate it. The only way to overcome this transfer gap is to move some of the data centres to where the data is.
3. Process Optimisation
With edge computing, data centres can execute rules that are time sensitive (like “stop the car” in case of driverless vehicles), and then stream data to the cloud in batches when bandwidth needs aren’t as high. Furthermore,the cloud can then take the time to analyze data from the edge, and send back recommended rule changes — like “decelerate slowly when the car senses human activity within 50 feet.”
4. Cost
Cost is also a driving factor for edge computing. The bulk of telemetry data that is from the sensors and actuators is likely not relevant for the IoT application. The fact a temperature sensor reports a 20ºC reading every second might not be interesting until the sensor reports a 40ºC reading. Edge computing allows for the filtering and processing of data before sending it to the cloud. This reduces the network cost of data transmission. It also reduces the cloud storage and processing cost of data that is not relevant to the application.
5. Resourcefulness
Storing and processing data on the edge and only sending out to the cloud what will be used and useful saves bandwidth and server space.
Where all we are using it
1. Grid Edge Control and Analytics
Grid Edge computing solutions are helping the utility monitor and analyse these additional renewable power generating resources integrated into their grid, in real time. This is something legacy SCADA systems are unable to offer.
From residential rooftop solar to solar farms, commercial solar, electric vehicles and wind farms, smart meters are generating a ton of data that helps utilities to view the amount of energy available and required, allowing their demand response to become more efficient, avoid peaks and reduce costs. This data is first processed in the Grid Edge Controllers that perform local computation and analysis of the data only send necessary actionable information over a wireless network to the Utility.
2. Oil and Gas Remote Monitoring
Safety monitoring within critical infrastructures such as oil and gas utilities is of utmost importance. For this reason, many cutting edge IoT monitoring devices are being deployed in order to safeguard against disaster. Edge computing allows data to be analysed, processed, and then delivered to end-users in real-time, allowing for control centres to access data as it occurs in order to foresee and prevent malfunctions or incidents before they occur. This is really important. As, when dealing with critical infrastructures such as oil and gas or other energy services, any failures within a particular system have the potential to be catastrophic and should always warrant the highest levels of precaution.
3. Internet of Things
A smart window firm monitors windows for errors, weather information, maintenance needs and performance. This generates a massive stream of data as each device is regularly reporting information. Edge services filter this information and report a summary back to a centralized service that is running from the firm’s primary data centres. By summarizing information before reporting it, global bandwidth consumption is reduced by 99%.
4. E-Commerce
An e-commerce company delivers images and static web content from a content delivery network. They also perform processing at edge data centres to quickly calculate product recommendations for customers.
5. Markets
A hedge fund pays an expensive premium for servers that are in close proximity to various stock exchanges to achieve extremely low latency trading. Trading algorithms are deployed on these machines. These servers are expensive and resource constrained. As such, they connect back to a cloud service for processing support.
6. Games
A game platform executes certain real-time elements of the game experience on edge servers near the user. The edges connect to a cloud backend for support processing. The backend is run from three regions that need not be close to the end-user.
Predictions for Edge Computing in Future
According to IDC by 2020, the IT spend on edge infrastructure will reach up to 18% of the total spend on IoT infrastructure. That spend is driven by the deployment of converged IT and OT systems which reduces the time to value of data collected from their connected devices IDC adds. It’s what we explained and illustrated in a nutshell.
According to a November 1, 2017, announcement regarding research of the edge computing market across hardware, platforms, solutions and applications (smart city, augmented reality, analytics etc.) the global edge computing market is expected to reach USD 6.72 billion by 2022 at a compound annual growth rate of a whopping 35.4 per cent.
The major trends responsible for the growth of the market in North America are all too familiar. Also, there is a growing number of devices and dependency on IoT devices. Hence, the need for faster processing, the increase in cloud adoption, and the increase in pressure on networks.
In an October 2018 blog post, Gartner’s Rob van der Meulen said that currently, around 10% of enterprise-generated data is created and processed outside a traditional centralized data centre or cloud. By 2022, Gartner predicts this figure will reach 50 per cent.
Summary
Edge is still in early stage adoption, but one thing is clear: Edge devices are subject to large-scale investments from cloud suppliers to offload bandwidth. Also, there are latency issues due to an explosion of the Internet of Things (IoT) data in both industrial and commercial applications.
Edge soon will likely increase in adoption where users have questions about how or if the cloud applies for the specific use case. Cloud-level interfaces and apps will migrate to the edge. Industrial application hosting and analytics will become common at the edge, using virtual servers and simplified operational technology-friendly hardware and software.
Benefits in network simplification, security and bandwidth accompany the IT simplification.
Follow this link, if you are looking to learn more about data science online!
Data Industry is on boom today and it seems no shortage of intelligent opinions about the job responsibilities and roles accelerating the data industry. Most of the people are usually confused between the role of a Data Scientist and the Data Analyst. Even if both of them deal with Data only still there are plenty of significant differences that make them suitable for different job positions.
Here, we will discuss how to differentiate Data Scientist from Data Analyst, and their job roles too. Before we switch on the actual topic, let us have a quick look at the differences. Later on, we will try to find out the reasons for the diminishing gap between data scientists and business analysts today. We will try to analyse if there is actually any gap between the two roles and look further into it.
Difference Between a Data Scientist and Business Analyst
A company relies on its business analysts to gain business insights by interpreting and analyzing data and predicting trends-related aspects which help in making critical business decisions. Business analysts also focus on end-to-end automation to eliminate manual intervention and optimizing business process flows which can increase the productivity and turnaround time for an efficient and successful end result. They also recommend systems changes needed to optimize an organization’s overall execution.
Data scientists, on the other hand, specialize and purely rely on data which is further broken down to simpler facts and figures by using tools such as statistical calculations, big data technology, and subject matter expertise. They use data comparison algorithms and methodologies to identify and determine potential competitors or resolve day-to-day business issues.
Business analysts often work on preconceived notions or judgments related to the factors that help drive the businesses. Data scientists, whereas; have had an edge over business analysts, as they leverage data related algorithms which provide accuracy and also use mathematical, statistical, and fact-based predictions.
As organizations are proactively defining new initiatives and campaigns to evaluate the existing strategy on how big data can help to transform their businesses, the role of business analyst is slowly but certainly widening into a major role.
Upgradation in Duties of Business Analysts and Data Scientists
In recent times, there have been a lot of advancements in the data science industry. With these advancements, different businesses are in better shape to extract much more value out of their data. With increased expectation, there is a shift in the roles of both data scientists and business analysts now. The data scientists have moved from statistical focus phase to more of a research phase. But the business analysts are now filling in the gap left by data scientists and are taking their roles up.
We can see it as an upgrade in both the job roles. Business analysts now hold the business angle firm but are also handling the statistical and technical part of the things too. Business analysts are now more into predictive analytics. They have reached a stage now where they can use off-the-shelf algorithms for predictions in their business domains. BA’s are not limited to just reporting and business but now are more into the prescriptive analytics too. They are handling the role of model building, data warehousing and statistical analysing.
Keep a note here that Business analysts are in no way replacing Data scientists. Data scientists are now researching new methods and algorithms which can be used by Business analysts combined with their business acumen in specific business domains.
Recent Advancements in Data Analytics
Data analytics is a field which witnesses a continuous revolution. Since data is becoming increasingly valuable with each passing time, it has been now treated with great care and concern. To cope up with the constant changes in the industries and societies as a whole, new tools, techniques, theories and trends and always introduced in the data analytics sector. In this article, we will go through some of the latest data analytics opportunities which have come up in the industry.
1. Self-service BI
With self-service BI tools, such as Tableau, Qlik Sense, Power BI, and Domo, managers can obtain current business information in graphical form on demand. While a certain amount of setup by IT may be needed at the outset and when adding a data source, most of the work in cleaning data and creating analyses can be done by business analysts, and the analyses can update automatically from the latest data any time they are opened.
Managers can then interact with the analyses graphically to identify issues that need to be addressed. In a BI-generated dashboard or “story” about sales numbers, that might mean drilling down to find underperforming stores, salespeople, and products, or discovering trends in year-over-year same-store comparisons. These discoveries might in turn guide decisions about future stocking levels, product sales and promotions, and even the building of additional stores in under-served areas.
2. Artificial Intelligence and Machine Learning
Artificial intelligence is one such data analytics opportunity which is finding widespread adoption in all businesses and decision-making applications. As per Gartner 2018, as much as 41 per cent of organizations have already adopted AI into some aspect of their functioning already while the rest 59 per cent are striving hard to do the same. There is considerable research going on at present to incorporate artificial intelligence into the field of data science too. With data becoming larger and more complex with each passing minute, management of such data is getting out of manual capacities very soon. Scholars have therefore now turned to the use of AI for storing, handling, manipulating and managing larger chunks of data in a safe environment.
3. R language
Data scientists have a number of option to analyze data using statistical methods. One of the most convenient and powerful methods is to use the free R programming language. R is one of the best ways to create reproducible, high-quality analysis since unlike a spreadsheet, R scripts can be audited and re-run easily. The R language and its package repositories provide a wide range of statistical techniques, data manipulation and plotting, to the point that if a technique exists, it is probably implemented in an R package. R is almost as strong in its support for machine learning, although it may not be the first choice for deep neural networks, which require higher-performance computing than R currently delivers.
R is available as free open source and is embedded into dozens of commercial products, including Microsoft Azure Machine Learning Studio and SQL Server 2016.
4. Big Data
the applications of the Big Data world. Well, most of us are now more than familiar with terms like Hadoop, Spark, NO-SQL, Hive, Cloud etc. We know there are at least 20 NO-SQL databases and a number of other Big Data solutions emerging every month. But which of these technologies see prospects going forward? Which technologies are going to fetch you big benefits?
Why the Role Update?
1. Advancement in technology
There have been a lot of technological advancements in data science. Machine learning, deep learning, automatic data processing are just to name few. With all these new technologies, organisations are expecting more out of their business analysts. Organisations are looking to leverage all these technologies into their decision-making process. To fulfil this, business analysts need to upgrade their role and take the role of data scientists too. Also, data scientists are more towards researching new methods and algorithms. They are the ones now bringing innovation in data science one after another.
2. Identification of more areas of application
Organisations are now able to explore more areas where they can leverage the power of data science. With more applications, organisations are aiming to automate their decision-making process. Business analysts need to step up for more diversified applications. Hence, they have to expand their skillset and takes upgraded roles. Decision scientists are more towards finding newer methods which can help the BA’s in solving complex business problems.
3. Increase in complexity of the business problem
Applications of data science in business are getting both complicated and complex day by day. With an increase in complexity. business analysts have now more prominent and complex roles. This can be one reason where the new BA’s may need to expand their skillset. This is due to the fact that organisations are expecting more out.
4. Growth of data
There has been a tremendous increase in data generation, practices like BIG data are coming as a prominent player in the picture. Business analysts today may need to be handy with Big data technologies rather than just having a business mindset towards the problem.
5. Lack of qualified talent
Today, there is also lack of qualified professionals in data science. This results in one individual taking multiple roles like BA, data engineer, data scientist etc. There are no clear boundaries between these roles in most of the organisations today. So a business analyst today, should also have knowledge of maths and technology. This is one reason too about business analysts acting as data scientists in many organisations.
The Tools of the Trade
The world of a business analyst is business-model centric. Either they are reporting, discussing, or modifying the business model. Not only must they be proficient with Microsoft Office, but they also must be excellent researchers and problem-solvers. Elite communication skills are also a must, as business analysts interact with every facet of the business. They must also be “team players” and able to interact and work with all departments within a company.
Data scientist’s job descriptions are much different than business analysts. They are mathematicians and understand the programming language, as opposed to reporting writers and company communicators. They, therefore, have a different set of tools they use. Utilizing programming languages, understanding the principles of machine learning, and being able to generate and apply mathematical models are critical skills for a data scientist.
The commonality between business analysts and data scientists is that both of them require generating and communicating figure-rich reports. The software used to generate such reports may be the same between the two different positions, but the content of the reports will be substantially different.
Which is Right for You?
If deciding between a future career between a business analyst and a data scientist, envisioning the type of position you want should steer you in the right direction. Do you like interacting with people? Do you like summarizing information to make reports? If so, you are more likely to be happy with a business analyst position than a data scientist. This is because data scientists work more independently. Data scientists are also more technical in nature. So if you have a more technical background, a career as a data scientist might before you.
Summary
In any case, organisations are now on the lookout for new age business analysts. They need to be a combo of the intelligence of knowing the right analytic tools, big data technology, and machine learning. Companies should rather not simply rely on business analysts to predict the future of a business. So if you are a business analyst then you have a lot to learn to stay relevant. But the good news is, there are various data science programs which can help you retool to stay competitive.
Follow this link, if you are looking to learn more about data science online!
Data scientists are the no. 1 most promising job in America for 2019, according to a Thursday report from LinkedIn. Hence, this comes as no surprise: Data scientist topped Glassdoor’s list of Best Jobs in America for the past three years, with professionals in the field reporting high demand, high salaries, and high job satisfaction.
Also, with the increase in demand, employers are looking for more skills in modern day data scientists. Furthermore, a modern-day data scientist needs to be a good player in aspects like maths, programming, communication and problem-solving.
In this blog, we are going to explore if knowledge of mathematics is really necessary to become good data scientists. Also, we will try to explore ways, if any, through which one can become a good data scientist without learning maths.
What all it takes for a modern day Data Scientist
Data scientists continue to be in high demand, with companies in virtually every industry looking to get the most value from their burgeoning information resources. Additionally, this role is important, but the rising stars of the business are those savvy data scientists that have the ability to not only manipulate vast amounts of data with sophisticated statistical and visualization techniques but have a solid acumen from which they can derive forward-looking insights, Boyd says. Also, these insights help predict potential outcomes and mitigate potential threats to the business. Additionally, key skills of modern-day data scientists are as follows
Data scientists need to be critical thinkers, to be able to apply the objective analysis of facts on a given topic or problem before formulating opinions or rendering judgments. Also, they need to understand the business problem or decision being made and be able to ‘model’ or ‘abstract’ what is critical to solving the problem, versus what is extraneous and can be ignored.
2. Coding
Top-notch data scientists know how to write code and are comfortable handling a variety of programming tasks. Furthermore, to be really successful as a data scientist, the programming skills need to comprise both computational aspects — dealing with large volumes of data, working with real-time data, cloud computing, unstructured data, as well as statistical aspects — [and] working with statistical models like regression, optimization, clustering, decision trees, random forests, etc.
3. Math
Data science is probably not a good career choice for people who don’t like or are not proficient at mathematics. Moreover, the data scientist whiz is one who excels at mathematics and statistics while having an ability to collaborate closely with line-of-business executives to communicate what is actually happening in the “black box” of complex equations in a manner that provides reassurance that the business can trust the outcomes and recommendations
4. Machine learning, deep learning, AI
Industries are moving extremely fast in these areas because of increased computing power, connectivity, and huge volumes of data being collected. A data scientist needs to stay in front of the curve in research, as well as understand what technology to apply when. Also, too many times a data scientist will apply something ‘sexy’ and new when the actual problem they are solving is much less complex.
Data scientists need to have a deep understanding of the problem to be solved, and the data itself will speak to what’s needed. Furthermore, being aware of the computational cost to the ecosystem, interpretability, latency, bandwidth, and other system boundary conditions — as well as the maturity of the customer — itself, helps the data scientist understand what technology to apply. That’s true as long as they understand the technology.
5. Communication
The importance of communication skills bears repeating. Virtually nothing in technology today is performed in a vacuum; there’s always some integration between systems, applications, data and people. Data science is no different, and being able to communicate with multiple stakeholders using data is a key attribute.
6. Data architecture
It is imperative that the data scientist understands what is happening to the data from inception to model to a business decision. Additionally, to not understand the architecture can have a serious impact on sample size inferences and assumptions, often leading to incorrect results and decisions.
As we have seen, mathematics is a crucial skill of a data scientist among many others. Agreed it is not everything that a data scientist may require. Hence, we will explore more on the usage of mathematics in data science. Also, this will help us to answer our question better!
Application of maths in data science and AI
Modelling a process (physical or informational) by probing the underlying dynamics
Constructing hypotheses
Rigorously estimating the quality of the data source
Quantifying the uncertainty around the data and predictions
Identifying the hidden pattern from the stream of information
Understanding the limitation of a model
Understanding mathematical proof and the abstract logic behind it
What all Maths You Must Know?
1. Linear algebra
You need to be familiar with linear algebra if you want to work in data science and machine learning because it helps deal with matrices — mathematical objects consisting of multiple numbers organised in a grid. Also, the data collected by a data scientist naturally comes in the form of a matrix — the data matrix — of n observations by p features, thus an n-by-p grid.
2. Probability theory
Probability theory — even the basic, not yet measure-theoretic probability theory — helps the data scientist deal with uncertainty and express it in models. Frequentists, Bayesian, and indeed quantum physicists argue to this day what probability really is (in many languages, such as Russian and Ukrainian, the word for probability comes from “having faith”), whereas pragmatists, such as Andrey Kolmogorov, shirk the question, postulate some axioms that describe how probability behaves (rather than what it is) and say: stop asking questions, just use the axioms.
3. Statistics
After probability theory, there comes statistics. As Ian Hacking remarked, “The quiet statisticians have changed our world — not by discovering new facts or technical developments, but by changing the ways that we reason, experiment, and form opinions”. Read Darrell Huff’s How to Lie with Statistics — if only to learn how to be truthful and how to recognise the truth — just as Moses learned “all the wisdom of the Egyptians” — in order to reject it.
4. Estimation theory
A particular branch of statistics — estimation theory — had been largely neglected in mathematical finance, at a high cost. It tells us how well we know a particular number: what is the error present in our estimates? How much of it is due to bias and how much due to variance?
Also, going beyond classical statistics, in machine learning, we want to minimise the error on new data — out-of-sample — rather than on the data that we have already seen — in-sample. As someone remarked, probably Niels Bohr or Piet Hein, “prediction is very difficult, especially about the future.”
5. Optimization theory
You can spend a lifetime studying this. Much of machine learning is about optimization — we want to find the weights that give the best (in optimisation speak, optimal) performance of a neural network on new data, so naturally, we have to optimise — perhaps with some form of regularisation. (And before you have calibrated that long short-term memory (LSTM) network — have you tried the basic linear regression on your data?)
What you miss on skipping Maths?
No in-depth knowledge of working of ML models
Inability to prove the correctness of your hypothesis
Prone to introducing bias and errors in your analysis
Inefficiency in math-heavy business problems
Some resources to learn maths online
We will divide the resources to 3 sections (Linear Algebra, Calculus, Statistics and probability), the list of resources will be in no particular order, resources are diversified between video tutorials, books, blogs, and online courses.
Linear Algebra
Used in machine learning (& deep learning) to understand how algorithms work under the hood. Basically, it’s all about vector/matrix/tensor operations, no black magic is involved!
Used in machine learning (&deep learning) to formulate the functions used to train algorithms to reach their objective, known by loss/cost/objective functions.
Linear algebra, calculus II, stats and probability are sufficient for understanding and handle 90% of machine learning models. Also, some areas and methods require special insights, for example, Bayesian and variational method require a calculus of variation, MCMC and Gibbs sample require advanced concepts of probability theory, information geometry and submanifolds learning to require differential geometry, kernel theory requires calculus III. Lately, it seems that even abstract algebra is playing a role.
Aditionally, not knowing maths may help you in reaching low-level positions in data science or solving some dummy projects. But in the long run, it will be maths only which will help you in scaling your career up!
Follow this link, if you are looking to learn more about data science online!
Evaluation metrics have a correlation with machine learning tasks. The tasks of classification, regression, ranking, clustering, topic modelling, etc, all have different metrics. Some metrics, such as precision, recall, are of use for multiple tasks. Classification, regression, and ranking are examples of supervised learning, which comprises a majority of machine learning applications. In this blog, we’ll be focusing on the metrics for supervised learning modules.
What is the Model Evaluation?
Evaluating a model is a very important step throughout the development of the model. Some methods such as the ANN model do the evaluation when it performs backpropagation. However, we still perform the evaluation of a model manually through various methods. It is important to note that we can evaluate models successfully. Especially, when working in a supervised learning environment as the actual values are available. These values help in order for the evaluation methods to function.
The models under supervised learning fall broadly under two categories- Regression problems and Classification problems. Also, the methods of evaluating these models also fall under such two categories only. Additionally, they are the evaluation of regression Models and evaluation of classification problems.
There is a fundamental difference between the methods for evaluating a regression and classification model.
With regression, we deal with continuous values where one can identify the error between the actual and prediction output.
However, when evaluating a classification model, the focus is on the number of predictions that we can classify correctly. Also to evaluate a classification model correctly, we also have to consider the data points that we classify incorrectly. Also, we deal with two types of classification models. There are some of which produce class output such as KNN and SVM. Furthermore, these are ones whose output is simply the class label. Others are probability producing models such as Logistic Regression, Random Forest etc. Also, their output is the probability of a data point belonging to a particular class. Also, through the use of a cut off value, we are able to convert these probabilities into class labels. Then we can end up classifying the data points.
Model Evaluation Techniques
Model Evaluation is an integral part of the model development process. It helps to find the best model that represents our data. It also focusses on how well the chosen model will work in the future. Evaluating model performance with the training data is not acceptable in data science. It can easily generate overoptimistically and overfit models. There are two methods of evaluating models in data science, Hold-Out and Cross-Validation. To avoid overfitting, both methods use a test set (not seen by the model) to evaluate model performance.
Hold-Out
In this method, the mostly large dataset is randomly divided into three subsets:
The training set is a subset of the dataset to build predictive models.
The validation set is a subset of the dataset to assess the performance of the model built in the training phase. It provides a test platform for fine-tuning model’s parameters and selecting the best-performing model. Not all modelling algorithms need a validation set.
Test set or unseen examples is a subset of the dataset to assess the likely future performance of a model. If a model fit to the training set much better than it fits the test set, overfitting is probably the cause.
Cross-Validation
When only a limited amount of data is available, to achieve an unbias estimate of the model performance we use k-fold cross-validation. In the k-fold cross-validation, we divide the data into k subsets of equal size. We build models times, each time leaving out one of the subsets from training and use it as the test set. If k equals the sample size, this is a “leave-one-out” method.
Regression Model Evaluation Methods
After building a number of different regression models, there is a wealth of criteria by which we can evaluate and compare them
Root Mean Square Error
RMSE is a popular formula to measure the error rate of a regression model. However, we can only compare between models whose errors we can measure in the same units
Relative Square Error Unlike RMSE, the relative squared error (RSE) can be compared between models whose errors we can measure in different units
Mean Absolute Error
Mean Absolute Error is the average of the difference between the Original Values and the Predicted Values. It gives us the measure of how far the predictions were from the actual output. However, they don’t give us any idea of the direction of the error i.e. whether we are under predicting the data or over predicting the data. Mathematically, it is represented as :
Relative Absolute Error Like RSE, the relative absolute error (RAE) can be compared between models whose errors are measured in the different units.
Coefficient of Determination
The coefficient of determin
ation (R2) summarizes the explanatory power of the regression model and is computed from the sums-of-squares terms.
R2 describes the proportion of variance of the dependent variable explained by the regression model. If the regression model is “perfect”, SSE is zero, and R2 is 1. If the regression model is a total failure, SSE is equal to SST, no variance is explained by regression, and R2 is zero.
Standardized Residuals (Errors) Plot
The standardized residual plot is a useful visualization tool in order to show the residual dispersion patterns on a standardized scale. There are no substantial differences between the pattern for a standardized residual plot and the pattern in the regular residual plot. The only difference is the standardized scale on the y-axis which allows us to easily detect potential outliers.
Classification Model Evaluation Methods
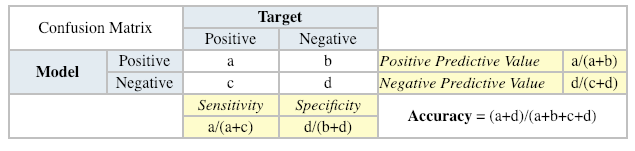
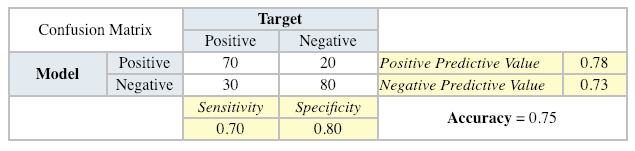
Confusion Matrix
A confusion matrix shows the number of correct and incorrect predictions made by the classification model compared to the actual outcomes (target value) in the data. The matrix is NxN, where N is the number of target values (classes). Performance of such models is commonly evaluated using the data in the matrix. The following table displays a 2×2 confusion matrix for two classes (Positive and Negative).
Accuracy: the proportion of the total number of predictions that were correct.
Positive Predictive Value or Precision: the proportion of positive cases that were correctly identified.
Negative Predictive Value: the proportion of negative cases that were correctly identified.
Sensitivity or Recall: the proportion of actual positive cases which are correctly identified.
Specificity: the proportion of actual negative cases which are correctly identified.
Gain and Lift Charts
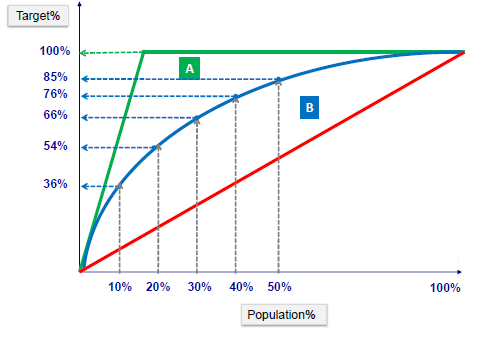
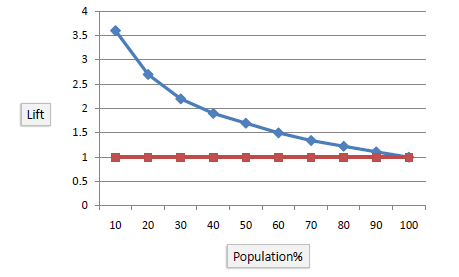
Gain or lift is a measure of the effectiveness of a classification model calculated as the ratio between the results obtained with and without the model. These charts are visual aids for evaluating the performance of classification models. However, in contrast to the confusion matrix that evaluates models on the whole population gain or lifts chart evaluates model performance in a portion of the population.
Example:
Gain Chart
Lift Chart
The lift chart shows how much more likely we are to receive positive responses than if we contact a random sample of customers. For example, by contacting only 10% of customers by our predictive model we will reach 3 times as many respondents as if we use no model.
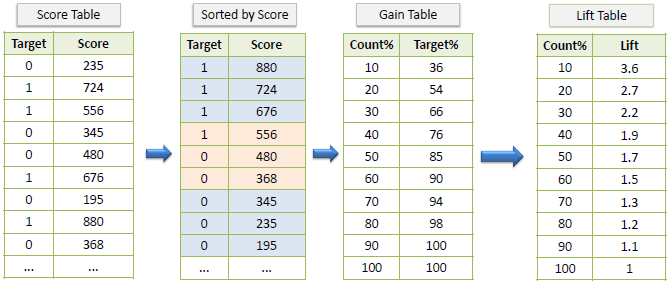
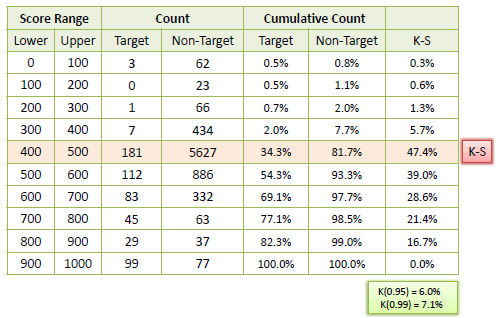
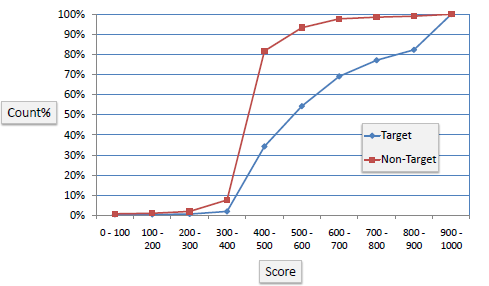
K-S Chart
K-S or Kolmogorov-Smirnov chart measures the performance of classification models. More accurately, K-S is a measure of the degree of separation between positive and negative distributions. The K-S is 100 if the scores partition the population into two separate groups in which one group contains all the positives and the other all the negatives. On the other hand, If the model cannot differentiate between positives and negatives, then it is as if the model selects cases randomly from the population. The K-S would be 0. In most classification models the K-S will fall between 0 and 100, and that the higher the value the better the model is at separating the positive from negative cases.
Example: The following example shows the results from a classification model. The model assigns a score between 0–1000 to each positive (Target) and negative (Non-Target) outcome.
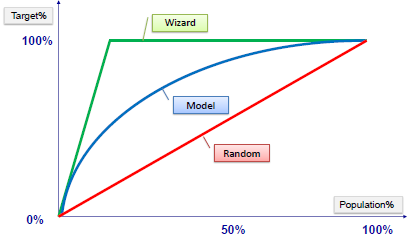
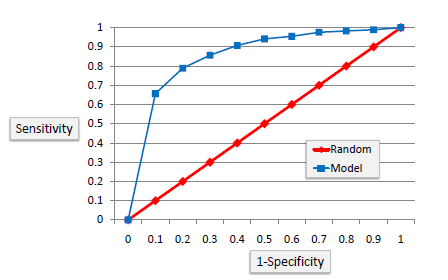
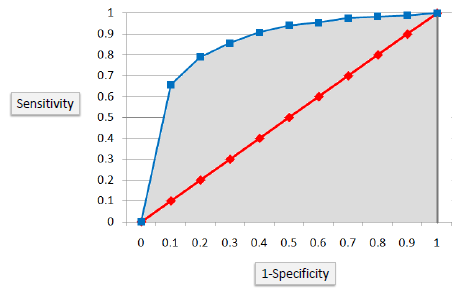
ROC Chart
The ROC chart is similar to the gain or lifts charts in that they provide a means of comparison between classification models. Also, the ROC chart shows false positive rate (1-specificity) on X-axis, the probability of target=1 when its true value is 0, against true positive rate (sensitivity) on Y-axis, the probability of target=1 when its true value is 1. Ideally, the curve will climb quickly toward the top-left meaning the model has correct predictions. Furthermore, the diagonal red line is for a random model.
Area Under the Curve (AUC)
The area under the ROC curve is often a measure of the quality of the classification models. A random classifier has an area under the curve of 0.5, while AUC for a perfect classifier is equal to 1. In practice, most of the classification models have an AUC between 0.5 and 1.
An area under the ROC curve of 0.8, for example, means that a randomly selected case from the group with the target equals 1 has a score larger than that for a randomly chosen case from the group with the target equals 0 in 80% of the time. Furthermore, when a classifier cannot distinguish between the two groups, the area will be equal to 0.5 ( will coincide with the diagonal). Also, when there is a perfect separation of the two groups, i.e., no overlapping of the distributions, the area under the ROC curve reaches to 1 (the ROC curve will reach the upper left corner of the plot).
Follow this link, if you are looking to learn more about data science online!
Technology has become the embedded component of applications and the defacto driver for growth in industries. With the advent of AI, new milestones are being achieved each day. We are moving towards an era of more and more integration, making it an indispensable mediator between systems and humans. The rapid strides taken by the mobile industry seems like an overwhelming convergence of multiple worlds. The innate ability of such systems to improve itself, strengthened by data analytics, IoT and AI have opened new frontiers. To reap the unbound merits of AI, software application vendors are integrating it into software applications.
In this blog, we will understand what exactly are these intelligent apps. What all does it require to make an intelligent app? Also, we will look into the real world applications of these intelligent apps.
What are Intelligent Applications?
So what exactly are intelligent apps? These are apps that not only know how to support key user decisions but also learn from user interactions. These apps aim to become even more relevant and valuable to these users.
In other words, intelligent apps are those that also learn and adapt and can even act on their own. Much like all of us, these apps learn and change behaviour. We are already seeing this at work. Have you noticed how e-commerce websites show you the right recommendations at the right time?
Intelligent apps are becoming a thing thanks to the strides being made in Artificial Intelligence (AI) and Machine Learning. Machine learning gives systems the ability to learn and improve from experience without being specifically programmed. There is an increase in the popularity of conversational systems and the growth of the Internet of Things. Therefore, we are seeing machine learning applied to more things in our everyday life.
Using AI algorithms, intelligent apps can study users’ behaviour and choices. Furthermore, it can sort through this data to use the relevant information to predict your needs and act on your behalf. For example, Smart Reply enables you to quickly respond to emails by giving you auto-generated replies. Productivity apps like Microsoft Office 365 and Google’s G Suite also use AI. Chatbots such as Meziuse machine learning to study user’s behaviour and provide them with choices they would like.
Features of Intelligent Applications
1. Data-driven
Intelligent apps combine and process multiple data sources — such as IoT sensors, beacons or user interactions — and turn an enormous quantity of numbers into valuable insights.
2. Contextual and relevant
Intelligent apps make much smarter use of a device’s features to proactively deliver highly relevant information and suggestions. Users will no longer have to go to their apps. Instead, the apps will come to them.
3. Continuously adapting
Through machine learning, intelligent apps continuously adapt and improve their output.
4. Action-oriented
By anticipating user behaviours with predictive analytics, smart applications deliver personalized and actionable suggestions.
5. Omnichannel
Progressive web applications are increasingly blurring the lines between native apps and mobile web applications.
Applications
1. Health Care Benefits
We are exploring AI/ML technology for health care. It can help doctors with diagnoses and tell when patients are deteriorating so medical intervention can occur sooner before the patient needs hospitalization. It’s a win-win for the healthcare industry, saving costs for both the hospitals and patients. The precision of machine learning can also detect diseases such as cancer sooner, thus saving lives.
2. Intelligent Conversational Interfaces
We are using machine learning and AI to build intelligent conversational chatbots and voice skills. These AI-driven conversational interfaces are answering questions from frequently asked questions and answers, helping users with concierge services in hotels, and to provide information about products for shopping. Advancements in the deep neural network or deep learning are making many of these AI and ML applications possible
3. Market Prediction
We are using AI in a number of traditional places like personalization, intuitive workflows, enhanced searching and product recommendations. More recently, we started baking AI into our go-to-market operations to be first to market by predicting the future. Or should I say, by “trying” to predict the future?
4. Customer Lifetime Value Modeling
Customer lifetime value models are among the most important for eCommerce business to employ. That’s because they can be used to identify, understand, and retain your company’s most valuable customers, whether that means the biggest spenders, the most loyal advocates of your brand, or both. These models predict the future revenue that an individual customer will bring to your business in a given period. With this information, you can focus your marketing efforts to encourage these customers to interact with your brand more often and even target your acquisition spend to attract new customers that are similar to your existing MVPs.
5. Churn Modeling
Customer churn modelling can help you identify which of your customers are likely to stop engaging with your business and why. The results of a churn model can range from churn risk scores for individual customers to drivers of churn ranked by importance. These outputs are essential components of an algorithmic retention strategy because they help optimize discount offers, email campaigns, or other targeted marketing initiatives that keep your high-value customer’s buying.
6. Dynamic Pricing
Dynamic pricing, also known as demand pricing, is the practice of flexible pricing items based on factors like the level of interest of the target customer, demand at the time of purchase, or whether the customer has engaged with a marketing campaign. This requires a lot of data about how different customers’ willingness to pay for a good or service changes across a variety of situations, but companies like airlines and ride-share services have successfully implemented dynamic price optimization strategies to maximize revenue.
7. Customer Segmentation
Data scientists do not rely on intuition to separate customers into groups. They use clustering and classification algorithms to group customers into personas based on specific variations among them. These personas account for customer differences across multiple dimensions such as demographics, browsing behaviour, and affinity. Connecting these traits to patterns of purchasing behaviour allows data-savvy companies to roll out highly personalized marketing campaigns. Additionally, these campaigns are more effective at boosting sales than generalized campaigns.
8. Image Classification
Image classification uses machine learning algorithms to assign a label from a fixed set of categories to an image that’s inputted. It has a wide range of business applications including modelling 3D construction plans based on 2D designs, social media photo tagging, informing medical diagnoses, and more. Deep learning methods such as neural networks are often used for image classification because they can most effectively identify relevant features of an image in the presence of potential complications like the variation in the point of view, illumination, scale, or volume of clutter in the image.
9. Recommendation Engines
Recommendation engines are another major way machine learning proves its business value. In fact, Netflix values the recommendation engine powering its content suggestions at $1 billion per year and Amazon says its system drives a 20–35% lift in sales annually. That’s because recommendation engines sift through large quantities of data to predict how likely any given customer is to purchase an item or enjoy a piece of content and then suggest those things to the user. The result is a customer experience that encourages better engagement and reduces churn.
Examples
1. Email Filters in Gmail
Google uses AI to ensure that nearly all of the email landing in your inbox is authentic. Their filters attempt to sort emails into the following categories like primary, social, promotions, updates, forums and spam. The program helps your emails get organized so you can find your way to important communications quicker.
2. LinkedIn
AI is used to help match candidates to jobs with the hopes of creating better employee-employer matches.
On its talent blog, LinkedIn explains that they use “deeper insights into the behaviour of applicants on LinkedIn” in order to “predict not just who would apply to your job, but who would get hired…”
3. Google Predictive Searches
When you begin typing a search term and Google makes recommendations for you to choose from, that’s AI in action. Predictive searches are based on data that Google collects about you, such as your location, age, and other personal details. Using AI, the search engine attempts to guess what you might be trying to find.
4. Tesla Smart Cars
Talking about the AI, there is no better and more prominent display of this technology than what smart car and drone manufacturers are doing with it. Just a few years back, using a fully automatic car was a dream, however, now companies like Tesla have made so much progress that we already have a fleet of semi-automatic cars on the road.
5. Online Ads Network(Facebook/Microsoft/Google)
One of the biggest users of artificial intelligence is the online ad industry which uses AI to not only track user statistics but also serve us ads based on those statistics. Without AI, the online ad industry will just fail as it would show random ads to users with no connection to their preferences what so ever. AI has become so successful in determining our interests and serving us ads that the global digital ad industry has crossed 250 billion US dollars with the industry projected to cross the 300 billion mark in 2019. So next time when you are going online and seeing ads or product recommendation, know that AI is impacting your life.
6. Amazon Product Recommendations
Amazon and other online retailers use AI to gather information about your preferences and buying habits. Then, they personalize your shopping experience by suggesting new products tailored to your habits.
When you search for an item such as “Bose headsets,” the search engine also shows related items that other people have purchased when searching for the same product.
Current trends and explorations
Intelligent things are poised to be one of the important trends that have the potential for ‘disruption’ and large-scale impact across industries. According to Gartner, the future will see the utilization of AI by almost all apps and services, making these apps discreet yet useful and intelligent mediators between systems and humans. AI will be incorporated into various systems and apps in some way and is poised to become the key enabler across a variety of services and software systems. As mentioned at the Google conference, very fast, we are moving from mobile-first to AI-first world.
It won’t be an exaggeration to say that all the new applications built in the coming years will be intelligent apps. These apps use machine learning and historical as well as real-time data to make smart decisions and deliver a highly personalized experience to the users. These apps combine predictive and prescriptive analytics, customer data, product insights, and operational vision with contemporary user-focused design and application development tools to create a highly impactful experience for users.
The intelligent apps undoubtedly have the potential to change the face of work and structure at companies in the coming years. According to Gartner’s prediction, companies will increasingly use and develop intelligent apps and utilize analytics and big data to enhance their business processes and offer top class customer experiences.
Summary
As companies are charting their digital transformation initiatives, they need to add intelligent apps to their blueprint. The development of the right intelligent apps needs to consider the new growth areas, internal and external data sources, real-time data acquisition, processing, and analysis and putting the right technology to use.
Intelligent apps are undoubtedly paving the way for speedier business decisions, better business results, greater efficiency of the workforce, and long-term gains for all — they just need to be utilized right. Companies which are diving in intelligent apps now will have a considerable competitive advantage in the near future.
Follow this link, if you are looking to learn more about data science online!