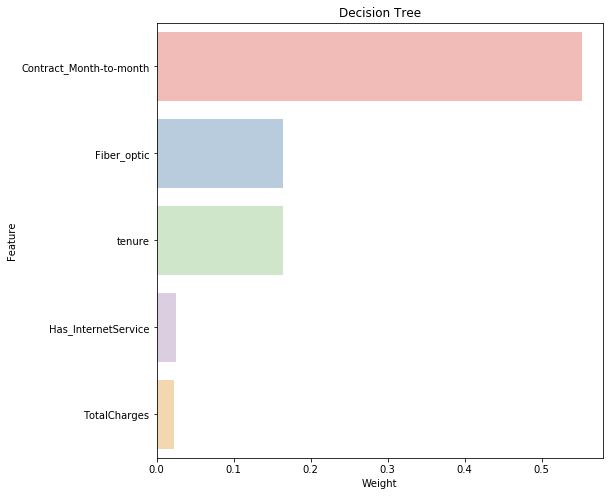In computer science, Decision tree learning uses a decision tree (as a predictive model) to go from observations about an item to conclusions about the item’s target value. It is one of the predictive modelling approaches used in statistics, data mining and machine learning. Tree models where the target variable can take a discrete set of values are called classification trees and where the target variable can take continuous values (typically real numbers) are called regression trees.
In this blog, we will use decision trees to solve the churn problem for a telephonic service provider, Telco! The goal of this blog is about building a decision tree classifier. Furthermore, we will look at some metrics in the end in order to evaluate the performance of our decision tree model.
What is Customer Churn?
Churn is defined slightly differently by each organization or product. Generally, the customers who stop using a product or service for a given period of time are referred to as churners. As a result, churn is one of the most important elements in the Key Performance Indicator (KPI) of a product or service. A full customer lifecycle analysis requires taking a look at retention rates in order to better understand the health of the business or product.
From a machine learning perspective, churn can be formulated as a binary classification problem. Although there are other approaches to churn prediction (for example, survival analysis), the most common solution is to label “churners” over a specific period of time as one class and users who stay engaged with the product as the complementary class.
What is a Decision Tree?
Decision trees, one of the simplest and yet most useful Machine Learning structures. Decision trees, as the name implies, are trees of decisions.
You have a question, usually a yes or no (binary; 2 options) question with two branches (yes and no) leading out of the tree. You can get more options than 2, but for this article, we’re only using 2 options.
Trees are weird in computer science. Instead of growing from a root upwards, they grow downwards. Think of it as an upside down tree.
The top-most item, in this example, “Am I hungry?” is called the root. It’s where everything starts. Branches are what we call each line. A leaf is everything that isn’t the root or a branch.
Trees are important in machine learning as not only do they let us visualise an algorithm, but they are a type of machine learning.
Telco Customer Churn Problem Statement
Teleco is looking to predict behaviour to retain customers for their product. You can analyze all relevant customer data and develop focused customer retention programs.
Each row in the data represents a customer, each column contains customer’s attributes described in the column Metadata.
The data set includes information about:
Customers who left within the last month — the column is called Churn
Services that each customer has signed up for — phone, multiple lines, internet, online security, online backup, device protection, tech support, and streaming TV and movies
Customer account information — how long they’ve been a customer, contract, payment method, paperless billing, monthly charges, and total charges
Demographic info about customers — gender, age range, and if they have partners and dependents
1. Data Exploration
In this step, we will focus more on understanding data at hand. Before directly jumping to any modelling approach, one must understand the data at hand. We will look at different features/columns present in the data. We will also try to understand what every column relates too in the context of the Telco churn problem.
2. Data Preprocessing There are very rare chances that data available at hand is directly applicable for building ML models. There can be multiple issues with data before you can even start implementing any fancy algorithm. Some of the issues can be missing values, improper format, the presence of categorical variables etc. We need to handle such issues then only we can train machine learning models. In our case of churn prediction, you can actually see our approach of handling missing data and categorical variables.
3. Training a decision tree classifier In this section, we will fit a decision tree classifier on the available data. The classifier learns the underlying pattern present in the data and builds a rule-based decision tree for making predictions. In this section, we are focussing more on the implementation of the decision tree algorithm rather than the underlying math. But, we will cover some basic math behind it for your better understanding while implementing the decision tree algorithm. Also, you can read about the decision trees in detail here!
4. Model Evaluation In this section, we will use our classifier to predict whether a customer will stop using the services of Telco or not. We will be looking at some of the methods like confusion matrix, AUC value and ROC-curve etc to evaluate the performance of our decision tree classifier.
Implementation in Python
We start by importing all the basic libraries and the data for training the decision tree algorithm. We are using numpy and pandas for performing mathematical operations and managing data in form of tables respectively.
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt # this is used for the plot the graph
import seaborn as sns # used for plot interactive graph.
import warnings
warnings.filterwarnings("ignore")
from pylab import rcParams
%matplotlib inline
data = pd.read_csv('./telco-churn.csv')
You can see the columns in the data below
######################### RESULT ###################################
Customer ID contains no specific information about any customer hence we need to drop this column from our dataset
data=data.drop(['customerID'], axis=1)
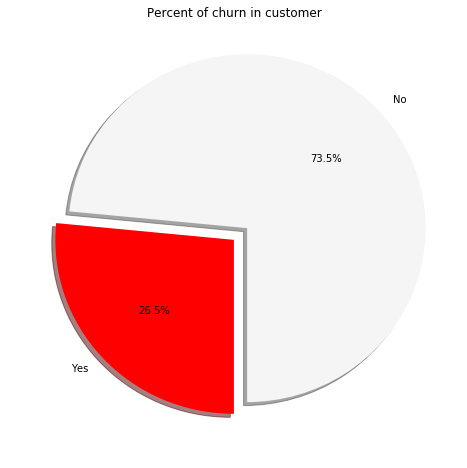
Now, let us have a look at our target variable. Here the target variable is “Churn” i.e. if a customer is going to stop using the services of Telco or not. We can see the proportion of the people opting out of the Telco services (churners) through the following code. It builds a simple pie chart to show the distribution of two classes in the dataset.
# Data to plot for the % of target variable
labels =data['Churn'].value_counts(sort = True).index
sizes = data['Churn'].value_counts(sort = True)
colors = ["whitesmoke","red"]
explode = (0.1,0) # explode 1st slice
rcParams['figure.figsize'] = 8,8
# Plot
plt.pie(sizes, explode=explode, labels=labels, colors=colors,
autopct='%1.1f%%', shadow=True, startangle=270,)
plt.title('Percent of churn in customer')
plt.show()
W can see through the pie chart, that 26.5% of customers present in the dataset are actually the churners i.e the people who opt out of the Telco services. The two target variables have a class imbalance in this case. No is present 73.5% of the times whereas yes is present only 26.5% of the times. In order to have a good machine learning model, we need to have a balance of the classes say 50% of both the class or in general, equal representation of the classes in the target variable.
There are techniques to manage the imbalanced classes like SMOTE but this is beyond the scope of this article for now. Decision trees can handle some imbalance present in the data better than other algorithms hence, we will not be using any technique to obtain balanced classes.
Finally, we need to convert yes/no of the target variable to 0 or 1. Machine learning models do not understand categorical variables. They need numbers to implement the underlying algorithms. Hence, our task in the data processing stage is to convert all the categorical variables to numbers.
# Converting the target class to 1’s and 0's
data['Churn'] = data['Churn'].map(lambda s :1 if s =='Yes' else 0)
Preprocessing Gender
In this section, we are processing the gender column to convert the categorical values into values. Pandas provide a get_dummies() function which can help you to convert your categorical column to a numeric one. It does one hot encoding of the values present in the column.
data['gender'].unique()
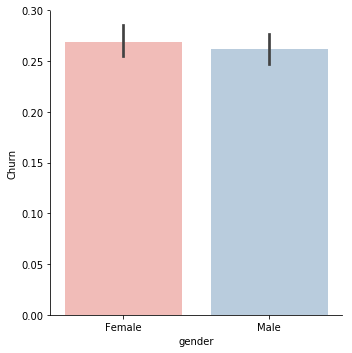
g = sns.factorplot(y="Churn",x="gender",data=data,kind="bar" ,palette = "Pastel1")
data = pd.get_dummies(data=data, columns=['gender'])
In this case, males and females have the same proportion of churning hence this variable is not informative enough to tell if a customer is going to stop using the services of Telco or not
Preprocessing Partner column
Partner columns contain a single yes/no. When there are only two categorical values present, we can directly replace the categories with 1 and 0. In case of more than two categorical variables, it is better to switch to one hot encoding of the values.
data['Partner'] = data['Partner'].map(lambda s :1 if s =='Yes' else 0)
Processing dependents, phone service and paperless billing variables
Above columns also contain only two categorical values. The following code assigns these categories a numeric 1/0 based on the respective category
data['Dependents'] = data['Dependents'].map(lambda s :1 if s =='Yes' else 0)
data['PhoneService'] = data['PhoneService'].map(lambda s :1 if s =='Yes' else 0)
data['PaperlessBilling'] = data['PaperlessBilling'].map(lambda s :1 if s =='Yes' else 0)
Analysing the number of months a person has stayed in the company
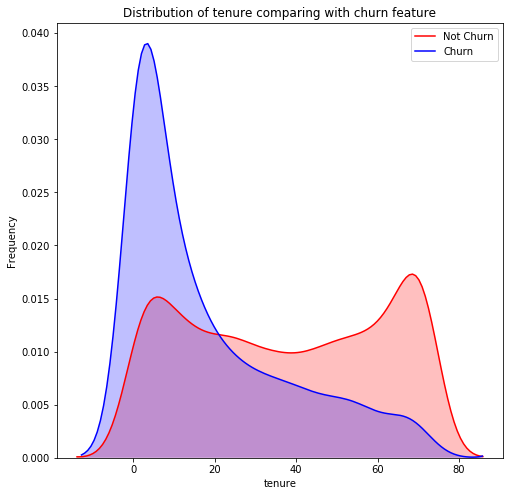
Let us analyse the number of months variable in order to understand the churn of the customers. We are plotting a distribution chart using the seaborn library in python through the following code!
# tenure distibution
g = sns.kdeplot(data.tenure[(data["Churn"] == 0) ], color="Red", shade = True)
g = sns.kdeplot(data.tenure[(data["Churn"] == 1) ], ax =g, color="Blue", shade= True)
g.set_xlabel("tenure")
g.set_ylabel("Frequency")
plt.title('Distribution of tenure comparing with churn feature')
g = g.legend(["Not Churn","Churn"])
We can clearly observe that most numbers of customers leave before 20 months. Once a customer has stayed with Telco for more than 20 months, it is highly unlikely that he is going to stop using the services provided by the Telco
Handling the telephone lines variable
Converting telephone line variable into dummy values
data['MultipleLines'].replace('No phone service','No', inplace=True)
data['MultipleLines'] = data['MultipleLines'].map(lambda s :1 if s =='Yes' else 0)
Preprocessing Customer Service variable
Converting customer service variable into dummy values
data['Has_InternetService'] = data['InternetService'].map(lambda s :0 if s =='No' else 1)
data['Fiber_optic'] = data['InternetService'].map(lambda s :1 if s =='Fiber optic' else 0)
data['DSL'] = data['InternetService'].map(lambda s :1 if s =='DSL' else 0)
data['OnlineSecurity'] = data['OnlineSecurity'].map(lambda s :1 if s =='Yes' else 0)
data['OnlineBackup'] = data['OnlineBackup'].map(lambda s :1 if s =='Yes' else 0)
data['DeviceProtection'] = data['DeviceProtection'].map(lambda s :1 if s =='Yes' else 0)
data['TechSupport'] = data['TechSupport'].map(lambda s :1 if s =='Yes' else 0)
data['StreamingTV'] = data['StreamingTV'].map(lambda s :1 if s =='Yes' else 0)
data['StreamingMovies'] = data['StreamingMovies'].map(lambda s :1 if s =='Yes' else 0)
Preprocessing payment and contract variables
data = pd.get_dummies(data=data, columns=['PaymentMethod'])
data = pd.get_dummies(data=data, columns=['Contract'])
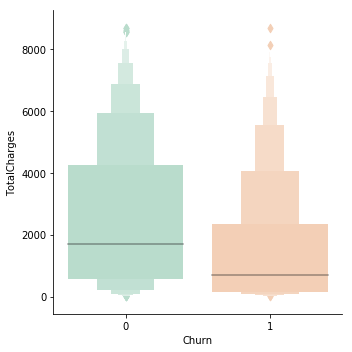
Analysing monthly and total charges
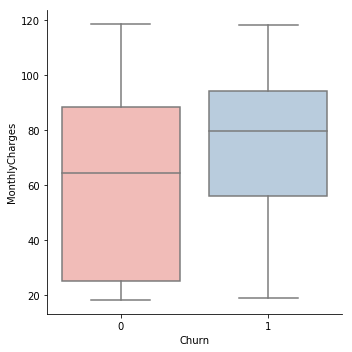
In this section, we will analyse the total and monthly charges column to understand their effect on the churning of the customers. Below code outputs a box plot based on the monthly charges between the customers who have left using the services and those who have not.
g = sns.factorplot(x="Churn", y = "MonthlyCharges",data = data, kind="box", palette = "Pastel1")
The high monthly charge is one cause for customers opting out of the services. The box plot also suggests that that loyal customers are those who have a low monthly charge.
data['TotalCharges'] = pd.to_numeric(data['TotalCharges'])
g = sns.factorplot(y="TotalCharges",x="Churn",data=data,kind="boxen", palette = "Pastel2")
Modeling
In this section, we are building our decision tree classifier. Decision tree algorithm has been implemented in the sklearn package and it provides an interface to invoke that algorithm.
We first separate out the target variables from the rest of our features present in the data. Following code performs this task
After that, we import the decision tree algorithm from the sklearn package. We pass the training data and the target data separately so that the algorithm can understand the input and create a rule-based mapping to the output in the form of a decision tree.
from sklearn import tree
# Initialize our decision tree object
classification_tree = tree.DecisionTreeClassifier(max_depth=4)
# Train our decision tree (tree induction + pruning)
classification_tree = classification_tree.fit(X_train, Y_train)
We can also visualise the trained decision tree in the previous step using the below code. Branches represent the actions while the internal nodes represent a decision. Leaf nodes represent the final target variables i.e whether a customer is churning or not (1/0)
Before we move on to the evaluation of our algorithm, let us quickly test the accuracy of our model by making some predictions. Below code makes some predictions on the test data. We are using cross-validation here in order to avoid bias while testing the model for accuracy.
One great aspect of rule-based learning is that we can actually visualise how important a given feature is towards predicting our target variable. Below code forms a chart showing the relative importance of the features present in the data towards the prediction of our target churn class.
In order to evaluate our classification model, we are using the confusion matrix. A confusion matrix is a table that is often used to describe the performance of a classification model (or “classifier”) on a set of test data for which the true values are known.
You can read more about the confusion matrix here.
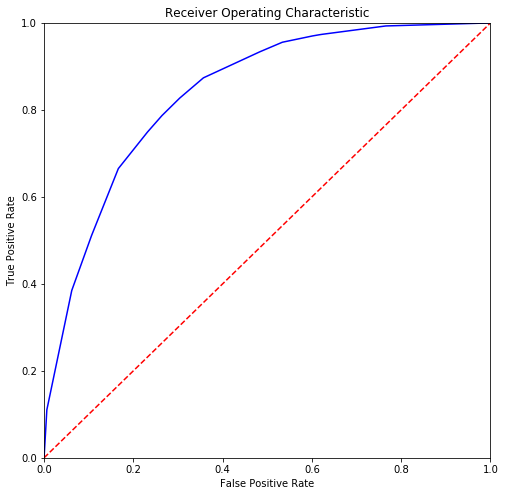
Following code generates the ROC curve for the predictions performed by our decision tree classifier. More the area under the ROC curve, better the prediction capability of the decision tree classifier.
from sklearn.metrics import roc_curve
# Calculate the fpr and tpr for all thresholds of the classification
fpr, tpr, threshold = roc_curve(Y_train, probs[:,1])
plt.title('Receiver Operating Characteristic')
plt.plot(fpr, tpr, 'b')
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
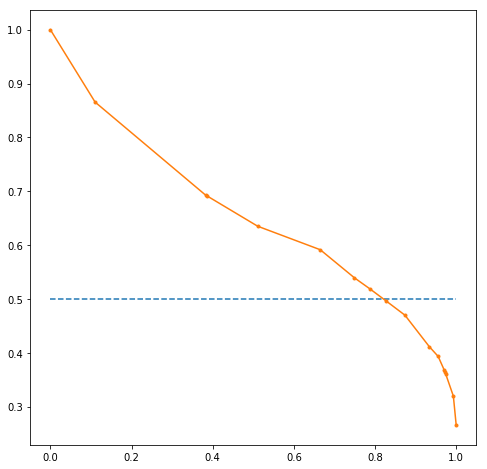
Below code makes a precision vs recall curve on the basis of the predictions. A precision-recall curve is a better indicator of the model performance than the ROC curve in case of imbalance in the target variable.
from matplotlib import pyplot
from sklearn.metrics import precision_recall_curve
precision, recall, thresholds = precision_recall_curve(Y_train, probs[:,1])
# plot no skill
pyplot.plot([0, 1], [0.5, 0.5], linestyle='--')
# plot the roc curve for the model
pyplot.plot(recall, precision, marker='.')
Summary
In this blog, we covered building a decision tree classifier for a sample use case. Decision trees can be a great platform to plant your footsteps in the world of machine learning as they are easier to implement and interpret. Also, we made some predictions using our decision tree classifier and evaluated its performance. The scope of this article was to familiarise the readers with decision trees and it’s an implementation for a use case!
For the next steps, you can also look at the Random Forest algorithm, which is nothing but a collection of different decision trees together making predictions. You can read more about the random forest here.
Follow this link, if you are looking to learn more about data science online!
As organizations turn to digital transformation strategies, they are also increasingly forming teams around the practice of Data Science. Currently, the main challenge for many CIOs, CDOs, and other Chief Data Scientists consist of positioning the Data Science function precisely where an organization needs it to improve its present and future activities. This implies embedding Data Science teams to fully engage with the business and adapting the operational backbone of the company
Furthermore, with all the requirements and expectations businesses are having from data science, innovation and experimentation will be key factors moving data science forward. Moreover, let us have a look at the growth of data science in recent years. After that, we will understand how creativity and innovation have accelerated this growth till now and the future prospects.
The Growth of Data Science
LinkedIn recently published a report naming the fastest growing jobs in the US based on the site’s data. The social networking site compared data from 2012 and from 2017 to complete the report. Eventually, the top two spots were machine learning jobs, which grew by 9.8X in the past five years, and data scientist, which grew 6.5X since 2012. So why are data science positions, and specifically machine learning positions, growing so fast?
1. The amount of data has skyrocketed
Not only has roughly 90 per cent of the data created in the last two years, but the current data output is 2.5 quintillion bytes of data daily
2. Data-driven decisions are more profitable
In the end, for many companies, data is not useful unless it is beneficial, which it certainly is. Data not only helps companies make better decisions but those decisions also usually come with a financial gain. Furthermore, a study by Harvard Business Review found that “companies in the top third of their industry in the use of data-driven decision making were more productive and profitable than their competitors.
3. Machine learning is changing how you do business
Machine learning is a type of artificial intelligence (AI) where the systems can actually learn and evolve. Also, it has infiltrated many industries, from marketing to finance to health care. The advanced algorithms save time and resources, making quick, correct decisions based on past learnings
4. Machine learning provides better forecasting
Machine learning algorithms often find hidden insights that went unseen by the human eye. With the vast amount of data in the processing stage, even an entire team of data scientists might miss a particular trend or pattern. The ability to predict what will happen in the market is what keeps businesses competitive.
Why Creativity and Curiosity are Needed for Growth of Data Science?
Data Science is More About Asking Why?
Data science is focussed on querying every result and having an inquisitive mindset. You can not be a good data scientist if you lack the inquisitive skills. Furthermore, an Inquisitive nature in a data scientist plays a major role in bringing out hidden patterns and insights present in the data. Data can be complex and answer to your hypothesis may lie somewhere hidden in the data. But, It is the inquisitive skills of a data scientist which leverages the hidden potential of data in achieving business goals.
Varied Implementations in Different Domains
Industry influencers, academicians, and other prominent stakeholders certainly agree that data science has become a big game changer in most, if not all, types of modern industries over the last few years. As big data continues to permeate our day-to-day lives, there has been a significant shift of focus from the hype surrounding it to finding real value in its use. Also, data science finds it’s usage in the most unlikely places one can ever think of now. Such varied implementations and decision making require creativity and curiosity in the minds of data scientists.
Different Problems — One Solution
This talks about the idea of dealing with multiple problems at hand with one solution. There can be solutions to different problems, but re-using an old solution from different problem space and applying it in the unlikely domains(extreme experimentation) sure has resulted in some great ideas recently. For example, CNN in deep learning is a classic implementation for image processing. But who could have thought that an image processing algorithm can also give strikingly good results in processing natural language? But, today CNN is also widely used for doing natural language processing. Creativity and curiosity take time to innovate things but when it does, it all worth the time invested!
One Problem — Multiple Solutions
We emphasise more on having multiple solutions for a single problem here. Having multiple ways of solving a given problem requires creativeness in mind. One should be ready to experiment and challenge the existing methods of solving a given problem. Furthermore, innovation can only occur when existing methods are challenged rather than just plainly accepting them. If everyone was to accept earlier beliefs, then maybe we could have been stuck with linear regression forever and will not have algorithms like SVM and Random Forest. Hence, It is this inquisitive nature which actaully gave birth to these classic ML algorithms today we have with us.
Examples of Innovations in Data Science in Recent Years
1. Coca-Cola managed to strengthen its data strategy by building a digital-led loyalty program. Coca-Cola director of data strategy was interviewed by ADMA managing editor. The interview made it clear that big data analytics is strongly behind customer retention at Coca-Cola.
2. Netflix is a good example of a big brand that uses big data analytics for targeted advertising. With over 100 million subscribers, the company collects huge data, which is the key to achieving the industry status Netflix boosts. If you are a subscriber, you are familiar with how they send you suggestions for the next movie you should watch. Basically, this is done using your past search and watch data. This data is used to give them insights on what interests the subscriber most.
3. Amazon leverages big data analytics to move into a large market. The data-driven logistics gives Amazon the required expertise to enable creation and achievement of greater value. Focusing on big data analytics, Amazon whole foods are able to understand how customers buy groceries and how suppliers interact with the grocer. This data gives insights whenever there is a need to implement further changes.
Creative Solutions for Innovation using Data Science
1. Profit model
Crunching numbers can identify untapped potential hidden in the profit margins or pin-point insufficiently used revenue streams. Simulations can also show if specific markets are ready. Data can help you apply the 80/20 principle and focus on your top clients.
2. Network
Data recorded and analyzed by one company can benefit others in numerous ways, especially if the two entities are in complementary businesses. Just imagine how a hotel could boost their bookings by using the weather and delayed flights information collected by a nearby airport during their regular operations.
3. Structure
Algorithms to ingest organizational charts with augmented information from thousands of companies and produce models of the best performing. It could offer recipes for the gender and educational composition of a Board to maximize talent. This could end artificial efforts of having more women on the board and produce even recommendations of possible candidates by scanning professional profiles.
4. Process
Data science consulting company InData Labs states that using analytics in the company’s operations is the best way to handle uncertainty by teaching staff to guide their decisions on results and numbers instead of gut feeling and customs.
5. Product performance
One company which already does this through their newsfeed automation is Facebook. They have innovated the way it looks for each individual user to boost their revenue from PPC ads. By employing data science in every aspect of user experience,
you can create better products and cut development costs by abandoning bad ideas early on.
How to Encourage Curiosity and Creativity among Data Scientists
1. Give importance to data science in growth planning
Don’t bury it under another department like marketing, product, finance, etc. Set up an innovation and development wing for research and experimentation purposes which is separate from business deadlines. The data science team will need to collaborate with other departments to provide solutions. But it will do so as for equal partners, not as a support staff that merely executes on the requirements from other teams. Instead of positioning data science as a supportive team in service to other departments, make it responsible for business goals
2. Provide the required infrastructure
Give full access to data as well as the compute resources to process their explorations. Requiring them to ask permission or request resources will impose a cost and less exploration will occur.
3. Focus on learning over knowing
Entire company must have common values for things like learning by doing, being comfortable with ambiguity, balancing long-and short-term returns. These values should spread across the entire organisation as they cannot survive in isolation.
4. Laying importance of extreme experimentation More emphasis should be put on experimentation tasks and mindset. Having an experimentation mindset gives the ability to data scientists to take steps into something innovative. Experimentation brings you a step closer to innovation and data science is all about it!
Summary
Creativity in data science can be anything from innovative features for modelling, development of new tools, cool new ways to visualise data, or even the types of data that we use for analysis. What’s interesting in data is that everyone will do things differently, depending on how they think about the problem. When put that way, almost everything we do in data science can be creative if we think outside the box a little bit.
The best way I can think to describe creativity in a candidate or in an approach is when they give you this moment of “wow!.” Ideally, as a company or team, you want to have a maximum number of moments like this — keep good ideas flowing, prioritize, and execute.
Follow this link, if you are looking to learn more about data science online!
With the growth of Data science in recent years, we have seen a growth in the development of the tools for it. R and Python have been steady languages used by people worldwide. But before R and Python, there was only one key player and it was MATLAB. MATLAB is still in usage in most of the academics areas and mostly all the researchers throughout the world use MATLAB.
In this blog, we will look at the reasons why MATLAB is a good contender to R and Python for Data science. Furthermore, we will discuss different courses which offer data science with MATLAB.
What is MATLAB?
MATLAB is a high-performance language for technical computing. It integrates computation, visualization, and programming in an easy-to-use environment where problems and solutions are expressed in familiar mathematical notation.
It is a programming platform, specifically for engineers and scientists. The heart of MATLAB is the MATLAB language, a matrix-based language allowing the most natural expression of computational mathematics.
Typical uses include:
Math and computation
Algorithm development
Modelling, simulation, and prototyping
Data analysis, exploration, and visualization
Scientific and engineering graphics
Application development, including Graphical User Interface building
The language, apps, and built-in math functions enable you to quickly explore multiple approaches to arrive at a solution. MATLAB lets you take your ideas from research to production by deploying to enterprise applications and embedded devices, as well as integrating with Simulink® and Model-Based Design.
Features of MATLAB
Following are the basic features of MATLAB −
It is a high-level language for numerical computation, visualization and application development
Provides an interactive environment for iterative exploration, design and problem-solving.
Holds a vast library of mathematical functions for linear algebra, statistics, Fourier analysis, filtering, optimization, numerical integration and solving ordinary differential equations.
It provides built-in graphics for visualizing data and tools for creating custom plots.
MATLAB’s programming interface gives development tools for improving code quality maintainability and maximizing performance.
It provides tools for building applications with custom graphical interfaces.
It provides functions for integrating MATLAB based algorithms with external applications and languages such as C, Java, .NET and Microsoft Excel.
Why Use MATLAB in Data Science?
Physical-world data: MATLAB has native support for the sensor, image, video, telemetry, binary, and other real-time formats. Explore this data using MATLAB MapReduce functionality for Hadoop, and by connecting interfaces to ODBC/JDBC databases.
Machine learning, neural networks, statistics, and beyond: MATLAB offers a full set of statistics and machine learning functionality, plus advanced methods such as nonlinear optimization, system identification, and thousands of prebuilt algorithms for image and video processing, financial modelling, control system design.
High-speed processing of large data sets. MATLAB’s numeric routines scale directly to parallel processing on clusters and cloud.
Online and real-time deployment: MATLAB integrates into enterprise systems, clusters, and clouds, and can be targeted to real-time embedded hardware.
Also, MATLAB finds its features available for the entire data science problem-solving journey. Let us have a look at how MATLAB fits in every stage of a data science problem pipeline
1. Accessing and Exploring Data
The first step in performing data analytics is to access the wealth of available data to explore patterns and develop deeper insights. From a single integrated environment, MATLAB helps you access data from a wide variety of sources and formats like different databases, CSV, audio, video etc
2. Preprocessing and Data Munging
When working with data from numerous sources and repositories, engineers and scientists need to preprocess and prepare data before developing predictive models. For example, data might have missing values or erroneous values, or it might use different timestamp formats. MATLAB helps you simplify what might otherwise be time-consuming tasks such as cleaning data, handling missing data, removing noise from the data, dimensionality reduction, feature extraction and domain analysis such as videos/audios.
3. Developing Predictive Models
Prototype and build predictive models directly from data to forecast and predict the probabilities of future outcomes. You can compare machine learning approaches such as logistic regression, classification trees, support vector machines, and ensemble methods, and use model refinement and reduction tools to create an accurate model that best captures the predictive power of your data. Use flexible tools for processing financial, signal, image, video, and mapping data to create analytics for a variety of fields within the same development environment.
4. Integrating Analytics with Systems
Integrate analytics developed in MATLAB into production IT environments without having to recode or create custom infrastructure. MATLAB analytics can be packaged as deployable components compatible with a wide range of development environments such as Java, Microsoft .NET, Excel, Python, and C/C++. You can share standalone MATLAB applications or run MATLAB analytics as a part of the web, database, desktop, and enterprise applications. For low latency and scalable production applications, you can manage MATLAB analytics running as a centralized service that is callable from many diverse applications.
People these days use MATLAB only when they need to create a quick prototype and then for doing trial and error for validating a fresh concept. The real implementation will never be made with MATLAB but with python, c++ or a similar language. In my opinion MATLAB and python (or python libs) serve for different purposes. Scripting is just one feature out of thousands of features in MATLAB but it is the only feature in python. People use both python and MATLAB scripts where in some other faculties people rely on only MATLAB toolboxes with zero scripting. Hence both python and MATLAB will exist in future but most probably the usage of MATLAB “outside” may be reduced. MATLAB will exist until we have a better alternative of it.
Summary
MATLAB provides a lot of inbuilt utilities which one can directly apply in data science. Furthermore, MATLAB today finds it’s heavy usage in the field of academics and research. Although languages like R and Python are dominating data science worldwide, they are no way near to the simplicity level which MATLAB has to offer. Also, MATLAB will go a long way in the field of data science in the years to come. Additionally, learning MATLAB will be a great bonus for those who are willing to pursue a career in research!
Also, follow this link, if you are looking to learn more about data science online!
Time series analysis is the use of statistical methods to analyze time series data and extract meaningful statistics and characteristics of the data. In this blog, we will begin our journey of learning time series forecasting using python. We will be taking a small forecasting problem and try to solve it till the end learning time series forecasting alongside.
What is Time Series analysis
Time series analysis is the collection of data at specific intervals over a period of time, with the purpose of identifying trends, cycles, and seasonal variances to aid in the forecasting of a future event. Data is any observed outcome that’s measurable. Unlike in statistical sampling, in time series analysis, data must be measured over time at consistent intervals to identify patterns that form trends, cycles, and seasonal variances. Measurements at random intervals lose the ability to predict future events.
There are two main goals of time series analysis: (a) identifying the nature of the phenomenon represented by the sequence of observations, and (b) forecasting (predicting future values of the time series variable). Both of these goals require that the pattern of observed time series data is identified and more or less formally described. Once the pattern is established, we can interpret and integrate it with other data (i.e., use it in our theory of the investigated phenomenon, e.g., seasonal commodity prices). Regardless of the depth of our understanding and the validity of our interpretation (theory) of the phenomenon, we can extrapolate the identified pattern to predict future events.
Problem Statement
There is a company X which has been keeping a record of monthly sales of shampoo for the past 3 years. Company X wants to forecast the sale of the shampoo for the next 4 months so that the demand and supply gap can be managed by the organisation. Our main job here is to simply predict the sales of the shampoo for the next 4 months.
Dataset comprises of only two columns. One is the Date of the month and other is the sale of the shampoo in that month.
Stages in Time Series Forecasting
Solving a time series problem is a little different as compared to a regular modelling task. A simple/basic journey of solving a time series problem can be demonstrated through the following processes. We will understand about tasks which one needs to perform in every stage. We will also look at the python implementation of each stage of our problem-solving journey.
Steps are –
Visualising time series
In this step, we try to visualise the series. We try to identify all the underlying patterns related to the series like trend and seasonality. Do not worry about these terms right now, as we will discuss them during implementation. You can say that this is more a type of an exploratory analysis of time series data.
Stationarising time series
A stationary time series is one whose statistical properties such as mean, variance, autocorrelation, etc. are all constant over time. Most statistical forecasting methods are based on the assumption that the time series can be rendered approximately stationary (i.e., “stationarised”) through the use of mathematical transformations. A stationarised series is relatively easy to predict: you simply predict that its statistical properties will be the same in the future as they have been in the past! Another reason for trying to stationarise a time series is to be able to obtain meaningful sample statistics such as means, variances, and correlations with other variables. Such statistics are useful as descriptors of future behaviour only if the series is stationary. For example, if the series is consistently increasing over time, the sample mean and variance will grow with the size of the sample, and they will always underestimate the mean and variance in future periods. And if the mean and variance of a series are not well-defined, then neither are its correlations with other variables
Finding the best parameters for our model
We need to find optimal parameters for forecasting models one’s we have a stationary series. These parameters come from the ACF and PACF plots. Hence, this stage is more about plotting above two graphs and extracting optimal model parameters based on them. Do not worry, we will cover on how to determine these parameters during the implementation part below!
Fitting model
Once we have our optimal model parameters, we can fit an ARIMA model to learn the pattern of the series. Always remember that time series algorithms work on stationary data only hence making a series stationary is an important aspect
Predictions
After fitting our model, we will be predicting the future in this stage. We will find out the sales of the shampoo for the next 4 months.
Since we are now familiar with a basic flow of solving a time series problem, let us get to the implementation. The language used is python in this case. A tutorial based on R will also be available in coming weeks!
Implementation in Python
Visualising a time series
Visualization plays an important role in time series analysis and forecasting. Plots of the raw sample data can provide valuable diagnostics to identify temporal structures like trends, cycles, and seasonality that can influence the choice of model.
We start by importing the dataset and required libraries for data processing and the libraries for plotting the graphs
import numpy as np # linear algebra
import pandas as pd # data processing
import matplotlib.pyplot as plt
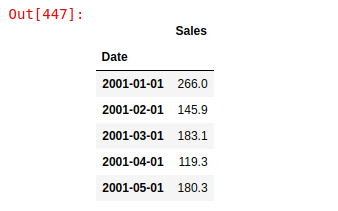
Following is a snapshot of the data used for this tutorial
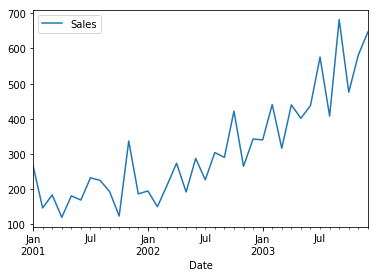
To visualise a time series, we can call the plot function directly
df.plot()
The output will be like this below
Remember that for time series forecasting, a series needs to be stationary. The series should have a constant mean, variance and covariance.
There are three basic criteria for a series to be classified as a stationary series :
1. The mean of the series should not be a function of time rather should be a constant.
2. The variance of the series should not be a function of time. This property is known as homoscedasticity.
3. The covariance of the ith term and the (i + m) term should not be a function of time.
Look closely here. There are a few inferences which we can draw out here. Mean is not constant in this case as we can clearly see an upward trend. Hence, we have identified that our series is not stationary. We need to have a stationary series to do time series forecasting. In the next stage, we will try to convert this into a stationary series.
Before we begin to make our stationary series, let us explore a bit more about our series
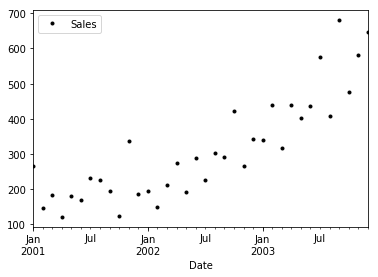
Following function can help you visualise your series in form of scatter plots
df.plot(style='k.')
plt.show()
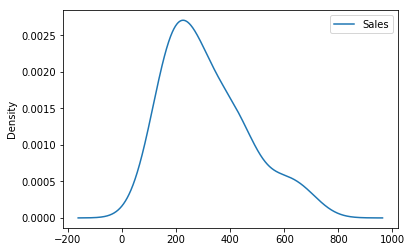
We can also visualise the data in our series through a distribution too. We can observe a near-normal distribution(bell-curve) over sales values.
df.plot(kind='kde')
Also, a given time series is thought to consist of three systematic components including level, trend, seasonality, and one non-systematic component called noise.
These components are defined as follows:
Level: The average value in the series.
Trend: The increasing or decreasing value in the series.
Seasonality: The repeating short-term cycle in the series.
Noise: The random variation in the series.
In order to perform a time series analysis, we may need to separate seasonality and trend from our series. The resultant series will become stationary through this process.
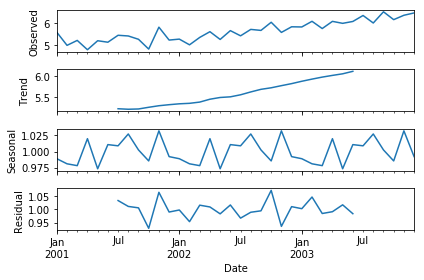
To separate the trend and the seasonality from a time series, we can decompose the series using the following code.
from statsmodels.tsa.seasonal import seasonal_decompose
result = seasonal_decompose(df, model='multiplicative')
result.plot()
plt.show()
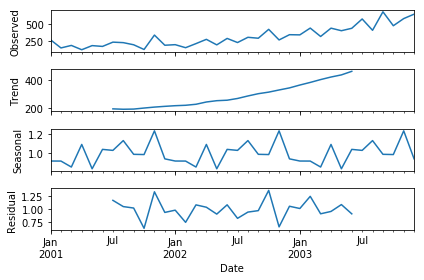
The above code has a separated trend and seasonality for us. This gives us more insight into our data and real-world actions. Clearly, there is an upward trend and a recurring event where shampoo sales shoot maximum every year!
Stationarising the time series
As we all know that we need to have a stationary series for time series forecasting. Before we can convert a series to stationary one, we need to check if a series is stationary or not.
Following function is a one which can plot a series with it’s rolling mean and standard deviation. If both mean and standard deviation are flat lines(constant mean and constant variance), the series become stationary!
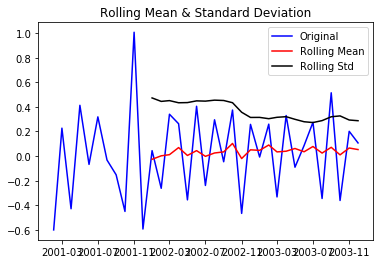
Let us test the stationarity of our original series
from statsmodels.tsa.stattools import adfuller
def test_stationarity(timeseries):
#Determing rolling statistics
rolmean = pd.rolling_mean(timeseries, window=12)
rolstd = pd.rolling_std(timeseries, window=12)
#Plot rolling statistics:
orig = plt.plot(timeseries, color='blue',label='Original')
mean = plt.plot(rolmean, color='red', label='Rolling Mean')
std = plt.plot(rolstd, color='black', label = 'Rolling Std')
plt.legend(loc='best')
plt.title('Rolling Mean & Standard Deviation')
plt.show(block=False)
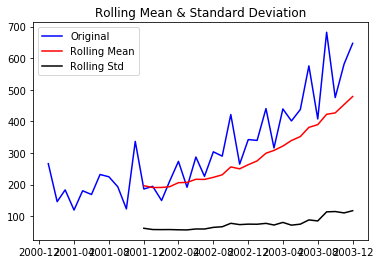
test_stationarity(df)
Through the above graph, we can see the increasing mean and standard deviation and hence our series is not stationary.
To get a stationary series, we need to eliminate the trend and seasonality from the series. The following section talks about removing the trend from the time series. Let us start stationarising our series!
Eliminating trend
To eliminate a trend from series, we start by taking a log of the series to reduce the magnitude of the values and reduce the rising trend in the series. Then after getting the log of the series, we find the rolling average of the series. A rolling average is calculated by taking input for the past 6 months and giving a mean sales value at every point further ahead in series.
After finding the mean, we take the difference of the series and the mean at every point in the series. This way, we eliminate trend out of a series and obtain a more stationary series.
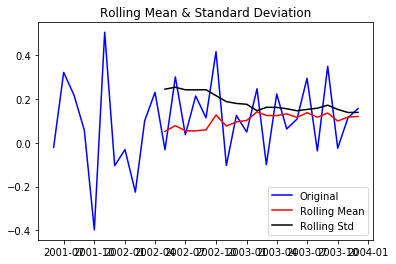
Above plot also suggests a less fluctuating mean and standard deviation. Our series looks more stationary now!
There can be cases when there is a high seasonality in the data. In those cases, just removing the trend will not help much. We need to also take care of the seasonality in the series. One such method for this task is differencing!
Differencing
Differencing is a method of transforming a time series dataset. It can be used to remove the series dependence on time, so-called temporal dependence. This includes structures like trends and seasonality. Differencing can help stabilize the mean of the time series by removing changes in the level of a time series, and so eliminating (or reducing) trend and seasonality.
Differencing is performed by subtracting the previous observation from the current observation.
Following code performs differencing for us. We shift the time series and subtract two series. The resultant series is a differenced one!
Following is the output of the differenced series. It certainly looks more stationary now.
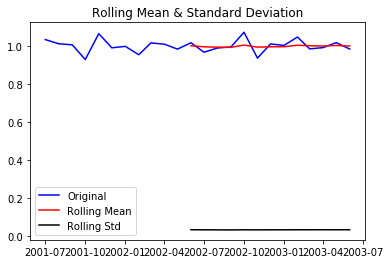
Let us test the stationarity of our resultant series
test_stationarity(df_log_diff)
Above plot also confirms that our series has become stationary!
Decomposing
Decomposition is primarily used for time series analysis, and as an analysis tool, it can be used to inform forecasting models on your problem. It provides a structured way of thinking about a time series forecasting problem, both generally in terms of modelling complexity and specifically in terms of how to best capture each of these components in a given model.
Each of these components is something you may need to think about and address during data preparation, model selection, and model tuning. You may address it explicitly in terms of modelling the trend and subtracting it from your data, or implicitly by providing enough history for an algorithm to model a trend if it may exist.
The statsmodels library provides an implementation of the naive, or classical, decomposition method in a function called seasonal_decompose(). It requires that you specify whether the model is additive or multiplicative.
Both will produce a result and you must be careful to be critical when interpreting the result. A review of a plot of the time series and some summary statistics can often be a good start to get an idea of whether your time series problem looks additive or multiplicative.
The seasonal_decompose() function returns a result object. The result object contains arrays to access four pieces of data from the decomposition.
from plotly.plotly import plot_mpl
from statsmodels.tsa.seasonal import seasonal_decompose
result = seasonal_decompose(df_log, model='multiplicative')
result.plot()
plt.show()
After the decomposition, if we look at the residual then we have clearly a flat line for both mean and standard deviation. We have got our stationary series and now we can move to model building!!!
Forecasting
In this section, we will start modelling our forecasting model. Before we go on to build our forecasting model, we need to determine optimal parameters for our model. For those optimal parameters, we need ACF and PACF plots.
ARIMA(p,d,q) forecasting equation: ARIMA models are, in theory, the most general class of models for forecasting a time series which can be made to be “stationary” by differencing (if necessary), perhaps in conjunction with nonlinear transformations such as logging or deflating (if necessary). A random variable that is a time series is stationary if its statistical properties are all constant over time. A stationary series has no trend, its variations around its mean have a constant amplitude, and it wiggles in a consistent fashion, i.e., its short-term random time patterns always look the same in a statistical sense. The latter condition means that its autocorrelations (correlations with its own prior deviations from the mean) remain constant over time, or equivalently, that its power spectrum remains constant over time. A random variable of this form can be viewed (as usual) as a combination of signal and noise, and the signal (if one is apparent) could be a pattern of fast or slow mean reversion, or sinusoidal oscillation, or rapid alternation in sign, and it could also have a seasonal component. An ARIMA model can be viewed as a “filter” that tries to separate the signal from the noise, and the signal is then extrapolated into the future to obtain forecasts.
A nonseasonal ARIMA model is classified as an “ARIMA(p,d,q)” model, where:
p is the number of autoregressive terms,
d is the number of nonseasonal differences needed for stationarity, and
q is the number of lagged forecast errors in the prediction equation.
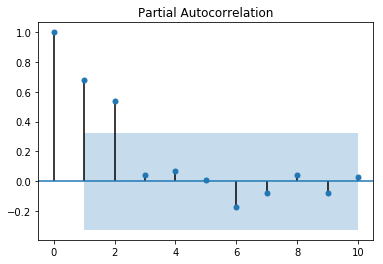
Values of p and q come through ACF and PACF plots. So let us understand both ACF and PACF!
Autocorrelation Function(ACF)
Statistical correlation summarizes the strength of the relationship between two variables. The Pearson’s correlation coefficient is a number between -1 and 1 that describes a negative or positive correlation respectively. A value of zero indicates no correlation.
We can calculate the correlation for time series observations with observations with previous time steps, called lags. Because the correlation of the time series observations is calculated with values of the same series at previous times, this is called a serial correlation, or an autocorrelation.
A plot of the autocorrelation of a time series by lag is called the AutoCorrelation Function, or the acronym ACF. This plot is sometimes called a correlogram or an autocorrelation plot.
Partial Autocorrelation Function(PACF)
A partial autocorrelation is a summary of the relationship between an observation in a time series with observations at prior time steps with the relationships of intervening observations removed.
The partial autocorrelation at lag k is the correlation that results after removing the effect of any correlations due to the terms at shorter lags.
The autocorrelation for observation and observation at a prior time step is comprised of both the direct correlation and indirect correlations. It is these indirect correlations that the partial autocorrelation function seeks to remove.
Below code plots, both ACF and PACF plots for us
from pandas.tools.plotting import autocorrelation_plot
from statsmodels.graphics.tsaplots import plot_pacf, plot_acf
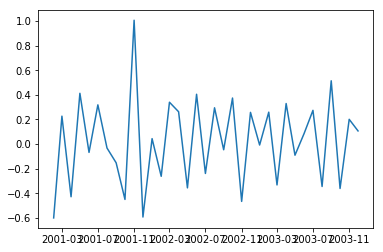
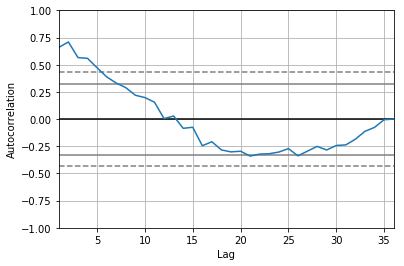
autocorrelation_plot(df_log)
plot_pacf(df_log, lags=10)
plt.show()
What suggests AR(q) terms in a model?
ACF shows a decay
PACF cuts off quickly
What suggests MA(p) terms in a model?
ACF cuts off sharply
PACF decays gradually
In PACF, the plot crosses the first dashed line(95% confidence interval line) around lag 4 hence p=4
Below code fits an ARIMA model for us
from statsmodels.tsa.arima_model import ARIMA
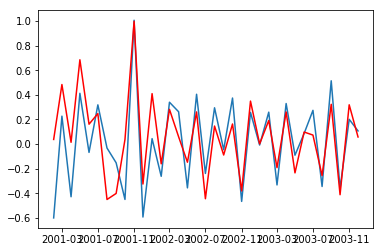
model = ARIMA(df_log, order=(4,1,2))
result_AR = model.fit(disp=-1)
plt.plot(df_log_diff)
plt.plot(result_AR.fittedvalues, color='red')
plt.show()
Let us visualise the ARIMA model on shampoo prices.
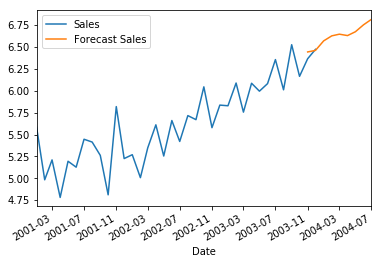
Following code helps us to forecast shampoo sales for the next 4 months
You can clearly see the predictions being made for the next 4 months!! Kudos to everyone for following till here.
Conclusion
Finally, we were able to build an ARIMA model and actually forecast for a future time period. Keep note that this is a basic implementation to get one started with time series forecasting. There are a lot of concepts like smoothening etc and models like ARIMAX, prophet etc to build your time series models. We will be covering more about time series in further blogs. Stay tuned!!
Follow this link, if you are looking to learn more about data science online!
During the most recent decade, the force originating from both the scholarly community and industry has lifted the R programming language. Also, they have worked hard to end up the absolute most significant tool for computational statistics, perception, and data science.
Due to the growth of R in the data science community, there is a constant need to upgrade and develop both R and RStudio. R studio conference is a platform where scholars around the globe come and share their knowledge and developments.
What is the R studio Conference?
Rstudio conference 2019 is all about R and RStudio. Hundreds of advanced and new R users in Austin, Texas from Tuesday, January 15 thru Friday, January 18 came together to become better at data science with R through this conference.
This conference happens every year where the latest trends, developments and goals for next year take place.
Agendas
This year conference happens in two parts i.e workshops and conferences. Conferences emphasise on different speakers sharing their experiences and advancements they have done in the previous year in R. Though, in workshops, hands-on experience happens over various topics like Big data in R, getting hands-on R-shiny on the production level.
The main theme of this session was R in production. Most of the conferences and workshops focus on the production aspect of the application in R whether be it Rshiny, sparkR or even different packages that rolled out in the conference
Conferences
1. Shiny in production: Principles, practices, and tools
Shiny is a web framework for R, a language not traditionally known for web frameworks, to say the least. As such, Shiny has always faced questions about whether it can or should be used “in production”. In this talk, they explored what “production” even means, reviewed some of the historical obstacles and objections to using Shiny for production purposes, and discussed practices and tools that can help your Shiny apps flourish.
2. A guide to modern reproducible data science with R
The session focussed on creating custom computing environments that can be shared and instantly with remote users, packaging small to medium data inside and outside packages, and creating simple to complex workflows to track the provenance of your results. Additionally, this solves the problem developers used to face in while reproducing their work in R in terms of package dependencies, mismatched versions etc
3. R in Production
With the increase in people using R for data science comes an associated increase in the number of people and organisations wanting to put models or other analytic code into “production”. We often hear it said that R isn’t suitable for production workloads, but is that true? Also, in this talk, Mark looked at some of the misinformation around the idea of what “putting something into production” actually means, as well as provided tips on overcoming the obstacles put in your path.
4. Databases using R: The latest
Many of the techniques covered are based on our personal and the community’s experiences of implementing concepts introduced last year, such as offloading most of the data wrangling to the database using dplyr, and using the RStudio IDE to preview the database’s layout and data.
5. Scaling R with Spark
This talk introduced new features in sparklyr that enable real-time data processing, brand new modelling extensions and significant performance improvements. The sparklyr package provides an interface to Apache Spark to enable data analysis and modelling in large datasets through familiar packages like dplyr and broom.
6. Democratizing R with Plumber APIs
The Plumber package provides an approachable framework for exposing R functions as HTTP API endpoints. This allows R developers to create code that can be consumed by downstream frameworks, which may be R agnostic. In this talk, an existing Shiny application that uses an R model was taken and turned that model into an API endpoint so it can be used in applications that don’t speak R.
7. tidy time series analysis
Time series can be frustrating to work with, particularly when processing raw data into model-ready data. But, this work presented two new packages that address a gap in existing methodology for time series analysis (raised in rstudio:: conf 2018). Furthermore, the tsibble package supports organizing and manipulating modern time series, leveraging tidy data principles along with contextual semantics: index and key. The tsibble data structure seamlessly flows into forecasting routines. Also, the fable package is a tidy renovation of the forecast package. It promotes transparent forecasting practices and concise model representations, to empower analysts tackling a broad domain of forecasting problems. This collection of packages form the tidyverts, which facilitates a fluent and fluid workflow for analyzing time series.
8. 3D mapping, plotting, and printing with rayshade
In this talk, speakers emphasised on the creation of beautiful 3D maps and visualizations with the rayshader package. In addition, talk about the value of 3D plotting, how interactions with the R community helped drive the development of rayshader, and how writing/blogging about your projects can vastly improve your code was taken.
9. Spatial Data Science in the Tidyverse
Package sf (simple feature) and ggplot2::geom_sf have caused a fast uptake of tidy spatial data analysis by data scientists. But, they do not handle important spatial data science challenges, including raster and vector data cubes and out-of-memory datasets. Powerful methods to analyse such datasets are now put in packages stars and tidync. This talk discussed how the simple feature and tidy data frameworks can handle these challenging data types. Also, it shows how R can be used for out-of-memory spatial and spatiotemporal datasets using tidy concepts.
Workshops
1. Applied Machine Learning Workshop
This two-day workshop provided an overview of using R for supervised learning. The session stepped through the process of building, visualizing, testing and comparing models that are focused on prediction. The goal of the course was to provide a thorough workflow in R to use with different ML techniques.
2. Advanced R Markdown Workshop
This workshop was for those who want to take their R Markdown skills to the next level. They talked about many low-level details in the rmarkdown package and the whole R Markdown ecosystem. The two goals of this workshop were: 1) learn how to fully customize R Markdown output (HTML, LaTeX/PDF, Word, and PowerPoint); and 2) learn more about existing R Markdown extensions in the ecosystem, such as flexdashboard, bookdown, blogdown, pkgdown, xaringan, rticles, and learnr.
3. Big Data with R Workshop
A two-day workshop. We will cover how to connect to and analyze data that exists outside of R. For databases, we will focus on the dplyr, DBI and odbc packages. For Big Data clusters, we will also learn how to use the sparklyr package to run models inside Spark and return the results to R. These packages enable us to use the same dplyr verbs inside R. We also will review recommendations for connection settings, security best practices and deployment options. Throughout the workshop, we will take advantage of RStudio’s professional tools such as RStudio Server Pro, the new professional data connectors, and RStudio Connect.
4. Shiny in Production | Data Products at Scale Workshop
This two-day workshop taught the best practices that make production-quality Shiny application performance possible. Does 30,000 simultaneous users for a Shiny application sound challenging? People use Shiny all over the world to deliver interactive, visual data products from data science teams to internal and external audiences at scale. The course focused on the open source and professional ecosystem around shiny that includes performance optimization, testing, and production deployment.
5. Introduction to Deep Learning Workshop
This one-day workshop introduces the essential concepts of building deep learning models with TensorFlow and Keras. During this course, you will build and train neural networks using the Keras package.
Summary
With a lot of development and growth in usage of R, advancements are necessary. It was really great to see the community moving towards the idea of production level quality in R focusing on both execution speed and efficiency. R conference 2020 holds more promise based upon the great development in the conference this year. R is sure to go beyond places!