Modern technologies such as artificial intelligence, machine learning, data science, and Big Data have become the phrases everyone talks about, but no one fully understands them. To a layman, they seem very complex. All these words resemble a business executive or a student from a non-technical background. People are often confused by words such as AI, ML, and data science.
People are often confused about using technology for growing their business. With a plethora of technologies available and rise and shine of data science in recent times, the decision makes individuals & companies face the consent dilemma of whether to choose big data or ML or data science which can boost their businesses. In this blog, we will understand different concepts and have a look at this problem.
Let us understand key terms first i.e data science, machine learning, and big data
What is Data Science
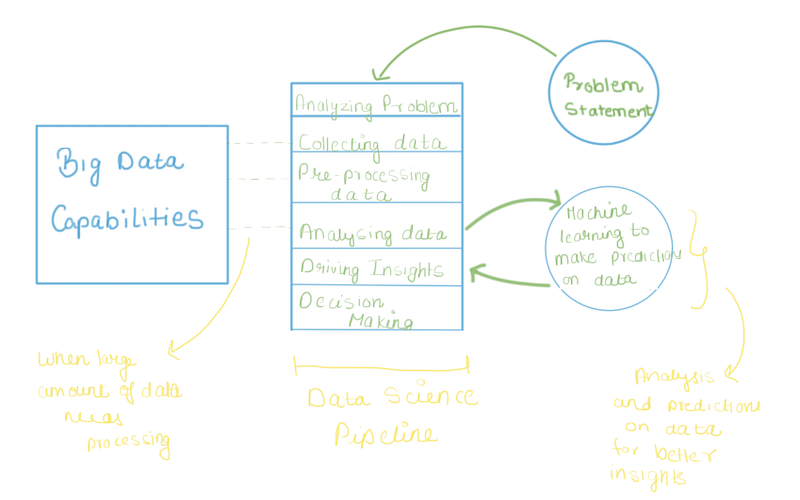
Data science is the umbrella under which all these terminologies take the shelter. Data science is a like a complete subject which has different stages within itself. Suppose a retailer wants to forecast the sales of an X item present in its inventory in the coming month. This is a business problem and data science aims to provide optimal solutions for the same.
Data science enables us to solve this business problem with a series of well-defined steps.
Collecting data
Pre-processing data
Analyzing data
Driving insights and generating BI report
Taking insight-bases decisions
Generally, these are the steps we mostly follow to solve a business problem. All the terminologies related to data science falls under different steps which we are going to understand just in a while. Different terminologies fall under different steps listed above.
You can learn more about the different component in data science from here
If you want to learn data science online then follow the link here
What is Big Data
Big data is high-volume, high-velocity and/or high-variety information assets that demand cost-effective, innovative forms of information processing that enable enhanced insight, decision making, and process automation.
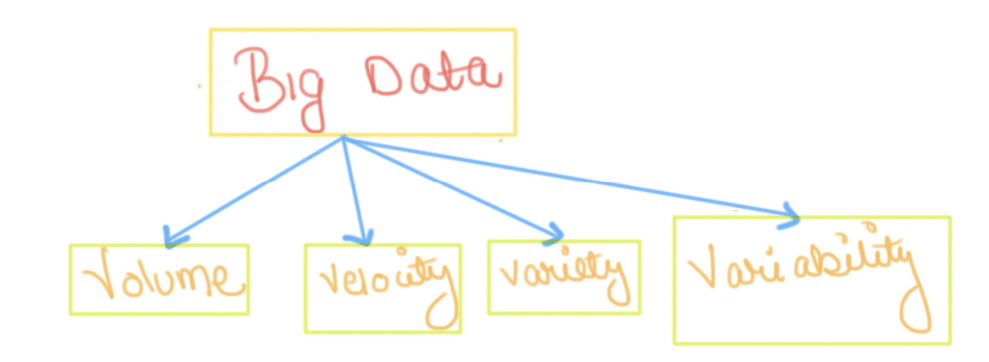
Characteristics Of ‘Big Data’
Volume — The name ‘Big Data’ itself is related to a size which is enormous. Size of data plays a very crucial role in determining value out of data. Also, whether a particular data can actually be considered as a Big Data or not, is dependent upon the volume of data. Hence, ‘Volume’ is one characteristic which needs to be considered while dealing with ‘Big Data’.
Variety — The next aspect of ‘Big Data’ is its variety. Variety refers to heterogeneous sources and the nature of data, both structured and unstructured. During earlier days, spreadsheets and databases were the only sources of data. Nowadays, analysis applications use data in the form of emails, photos, videos, monitoring devices, PDFs, audio, etc. This variety of unstructured-data poses certain issues for storage, mining and analyzing data.
Velocity — The term ‘velocity’ refers to the speed of generation of data. How fast the data is generated and processed to meet the demands, determines real potential in the data. Big Data Velocity deals with the speed at which data flows in from sources like business processes, application logs, networks, and social media sites, sensors, Mobile devices, etc. The flow of data is massive and continuous.
Variability — This refers to the inconsistency which can be shown by the data at times, thus hampering the process of being able to handle and manage the data effectively.
If you are looking to learn Big Data online then follow the link here
What is Machine Learning
At a very high level, machine learning is the process of teaching a computer system how to make accurate predictions when fed data.
Those predictions could be answering whether a piece of fruit in a photo is a banana or an apple, spotting people crossing the road in front of a self-driving car, whether the use of the word book in a sentence relates to a paperback or a hotel reservation, whether an email is a spam, or recognizing speech accurately enough to generate captions for a YouTube video.
The key difference from traditional computer software is that a human developer hasn’t written code that instructs the system how to tell the difference between the banana and the apple.
Instead, a machine-learning model has been taught how to reliably discriminate between the fruits by being trained on a large amount of data, in this instance likely a huge number of images labelled as containing a banana or an apple.
You can read more on how to be an expert in AI from here
The relationship between Data Science, Machine learning and Big Data
Data science is a complete journey of solving a problem using data at hand wheres Big data and machine learning are tools for the data scientists. It helps them to perform some specific tasks. While, Machine learning is more around making predictions using data present at hand whereas Big data emphasis on all the techniques that can be used to analyze a large set of data(thousands of petabytes may be, to begin with)
Let us understand in detail the difference between machine learning and Big Data
Big Data Analytics vs Machine Learning
You will find both similarities and differences when you compare between big data analytics and machine learning. However, the major differences lie in their application.
Big data analytics as the name suggest is the analysis of patterns or extraction of information from big data. So, in big data analytics, the analysis is done on big data. Machine learning, in simple terms, is teaching a machine how to respond to unknown inputs but still produce desirable outputs.
Most data analysis activities which do not involve expert task can be done through big data analytics without the involvement of machine learning. However, if the computational power required is beyond human expertise, then machine learning will be required.
Normal big data analytics is all about cleaning and transforming data to extract information, which then can be fed to a machine learning system in order to enable further analysis or predict outcomes without the requirement of human involvement.
Big data analytics and machine learning can go hand-in-hand and it would benefit a lot to learn both. Both fields offer good job opportunities as the demand is high for professionals across industries. When it comes to salary, both profiles enjoy similar packages. If you have skills in both of them, you are a hot property in the field of analytics.
However, if you do not have the time to learn both, you can go for whichever you are interested in.
So what to choose?
After understanding the 3 key phrases i.e Data science, Big data and machine learning, we are now in a better position to understand their selection and usage in business. We now know that data science is a complete process of using the power of data to boost business growth. So any decision-making process involving data has to involve data science.
There are few factors which may determine whether you should go for machine learning or Big data way for your organisation. Let us have a look at these factors and understand them in more detail
Factors affecting the selection
1. Goal
Selection of Big Data or Machine learning depends upon the end-goal of the business. If you are looking forward to generating predictions say based on customer behaviour or you want to build recommender systems then machine learning is the way to go. On the other hand, if you are looking for data handling and manipulation support where you can extract, load and transform data then Big Data will be the right choice for you.
2. Scale of operations
The scale of operation is one deciding factor between Big data and machine learning. If you have lots and lots of data like thousands of TB’s etc then employing Big data capabilities is the only choice. Traditional systems are not built to handle this much amount of data. Various businesses these days are sitting over huge chunks of data collected but lack the ability to meaningfully process them. Big Data systems allow handling of such amounts of data. Big data employs the concept of parallel computing which eases enables the systems to process and manipulate data in bulk quantities
3. Available resources
Employing Big data or machine learning capabilities requires a lot of investment both in terms of human resource and capital. If an organisation has resources trained for big data capabilities, then only they can manage such big infrastructure and leverage its benefits
Applications of Machine Learning
1. Image Recognition
It is one of the most common machine learning applications. There are many situations where you can classify the object as a digital image. For digital images, the measurements describe the outputs of each pixel in the image.
2. Speech Recognition
Speech recognition (SR) is the translation of spoken words into text. It is also known as “automatic speech recognition” (ASR), “computer speech recognition”, or “speech to text” (STT).
3. Learning Associations
Learning association is the process of developing insights into various associations between products. A good example is how seemingly unrelated products may reveal an association with one another. When analyzed in relation to buying behaviours of customers.
4. Recommendation systems
These applications have been the bread and butter for many companies. When we talk about recommendation systems, we are referring to the targeted advertising on your Facebook page, the recommended products to buy on Amazon, and even the recommended movies or shows to watch on Netflix.
Applications of Big Data
1. Government
Big data analytics has proven to be very useful in the government sector. Big data analysis played a large role in Barack Obama’s successful 2012 re-election campaign. The Indian Government utilizes numerous techniques to ascertain how the Indian electorate is responding to government action, as well as ideas for policy augmentation.
2. Social Media Analytics
The advent of social media has led to an outburst of big data. Various solutions have been built in order to analyze social media activity like IBM’s Cognos Consumer Insights, a point solution running on IBM’s BigInsights Big Data platform, can make sense of the chatter. Social media can provide valuable real-time insights into how the market is responding to products and campaigns. With the help of these insights, the companies can adjust their pricing, promotion, and campaign placements accordingly.
3. Technology
The technological applications of big data comprise of the following companies which deal with huge amounts of data every day and put them to use for business decisions as well. For example, eBay.com uses two data warehouses at 7.5 petabytes and 40PB as well as a 40PB Hadoop cluster for search, consumer recommendations, and merchandising. Inside eBay‟s 90PB data warehouse. Amazon.com handles millions of back-end operations every day, as well as queries from more than half a million third-party sellers.
4. Fraud detection
For businesses whose operations involve any type of claims or transaction processing, fraud detection is one of the most compelling Big Data application examples. Big Data platforms that can analyze claims and transactions in real time, identifying large-scale patterns across many transactions or detecting anomalous behaviour from an individual user, can change the fraud detection game.
Examples
1. Amazon
Amazon employs both machine learning and big data capabilities to serve its customers. It uses ML in form of recommender systems to suggest new products to its customers. They use big data to maintain and serve all the products data they have. Right from processing all the images and the content, to displaying them over the website, it is handled by the employed big data systems.
2. Facebook
Facebook similarly like Amazon has loads and loads of user data available with it. It uses machine learning to segment all the users based on their activity. Then, Facebook finds the best advertisements for its users in order to increase the clicks on the ads. All this is done through machine learning. With large user data at disposal, traditional systems can not process this data and make it ready for machine learning purposes. Facebook has employed big data systems so that they can process and transform this huge data and actually can derive insights out of it. Big data is required to make all this huge data processable.
Conclusion
In this blog, we learned how data science, machine learning and Big data link with each other. Whenever you want to solve any problem by using data at hand, data science is the process to solve it. If the data is too large and traditional systems or small-scale machines cannot handle it then BIG data techniques are the option to analyze such large chunks of data set. Machine learning covers the part when you want to make predictions of some kind, based on data you have at your end. These predictions will help you in validating your hypothesis around data and will enable smarter decision making.
Follow this link, if you are looking to learn more about data science online!
In very simple words, Amazon Web Services is a subsidiary of Amazon that provides on-demand cloud computing platforms to individuals, companies and governments, on a paid subscription basis. The technology allows subscribers to have at their disposal a virtual cluster of computers, available all the time, through the Internet.
Let us give a shot at a very technical description of AWS. Amazon Web Services (AWS) is a secure cloud services platform, offering computing power, database storage, content delivery and other functionality to help businesses scale and grow. Explore how millions of customers are currently leveraging AWS cloud products and solutions to build sophisticated applications with increased flexibility, scalability and reliability.
Capabilities?
Websites & Website Hosting: Amazon Web Services offers cloud web hosting solutions that provide businesses, non-profits, and governmental organizations with low-cost ways to deliver their websites and web applications. Whether you’re looking for marketing, rich media, or e-commerce website, AWS offers a wide range of website hosting options, and we’ll help you select the one that is right for you.
Backup & Recovery: AWS offers the most storage services, data-transfer methods, and networking options to build solutions that protect your data with unmatched durability and security
Data Archive: Amazon Web Services offers a complete set of cloud storage services for archiving. You can choose Amazon Glacier for affordable, non-time sensitive cloud storage, or Amazon Simple Storage Service (S3) for faster storage, depending on your needs. With AWS Storage Gateway and our solution provider ecosystem, you can build a comprehensive, storage solution.
DevOps: AWS provides a set of flexible services designed to enable companies to more rapidly and reliably build and deliver products using AWS and DevOps practices. These services simplify provisioning and managing infrastructure, deploying application code, automating software release processes, and monitoring your application and infrastructure performance.
Big Data: AWS delivers an integrated suite of services that provide everything needed to quickly and easily build and manage a data lake for analytics. AWS-powered data lakes can handle the scale, agility, and flexibility required to combine different types of data and analytics approaches to gain deeper insights, in ways that traditional data silos and data warehouses cannot. AWS gives customers the widest array of analytics and machine learning services, for easy access to all relevant data, without compromising on security or governance.
Why learn AWS?
DevOps Automation
You don’t want your data scientists spending time on DevOps tasks like creating AMIs, defining Security Groups, and creating EC2 instances. Data science workloads benefit from large machines for exploratory analysis in tools like Jupyter or RStudio, as well as elastic scalability to support bursty demand from teams, or parallel execution of data science experiments, which are often computationally intensive.
Cost controls, resource monitoring, and reporting
Data science workloads often benefit from high-end hardware, which can be expensive. When data scientists have more access to scalable compute, how do you mitigate the risk of runaway costs, enforce limits, and attribute across multiple groups or teams?
Environment management
Data scientists need agility to experiment with new open source tools and packages, which are evolving faster than ever before. System administrators must ensure stability and safety of environments. How can you balance these two points in tension?
GPUs
Neural networks and other effective data science techniques benefit from GPU acceleration, but configuring and utilizing GPUs remains easier said than done. How can you provide efficient access to GPUs for your data scientists without miring them in DevOps configuration tasks?
Security
AWS offers world-class security in their environment — but you must still make choices about how you configure security for your applications running on AWS. These choices can make a significant difference in mitigating risk as your data scientists transfer logic (source code) and data sets that may represent your most valuable intellectual property.
Our AWS Course
1. AWS Introduction
This section covers the basic and different concepts and terms which are AWS specific. This lays out the basic setting where learners are fed with all the AWS specific terms and are prepared for the deep dive.
2. VPC Subnet
A virtual private cloud (VPC) is a virtual network dedicated to your AWS account. It is logically isolated from other virtual networks in the AWS Cloud. You can launch your AWS resources, such as Amazon EC2 instances, into your VPC.
3. Route
A route table contains a set of rules, called routes, that are used to determine where network traffic is directed. Each subnet in your VPC must be associated with a route table; the table controls the routing for the subnet. A subnet can only be associated with one route table at a time, but you can associate multiple subnets with the same route table.
4. EC2
Amazon Elastic Compute Cloud (Amazon EC2) is a web service that provides secure, resizable compute capacity in the cloud. It is designed to make web-scale cloud computing easier for developers.
5. IAM
AWS Identity and Access Management (IAM) is a web service that helps you securely control access to AWS resources. You use IAM to control who is authenticated (signed in) and authorized (has permissions) to use resources.
6. S3
Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance. This means customers of all sizes and industries can use it to store and protect any amount of data for a range of use cases, such as websites, mobile applications, backup and restore, archive, enterprise applications, IoT devices, and big data analytics.
7. Lambda
AWS Lambda is a ‘compute’ service that lets you run code without provisioning or managing servers. AWS Lambda executes your code only when needed and scales automatically, from a few requests per day to thousands per second
8. SNS
Amazon Simple Notification Service (SNS) is a highly available, durable, secure, fully managed pub/sub messaging service that enables you to decouple microservices, distributed systems, and serverless applications. Amazon SNS provides topics for high-throughput, push-based, many-to-many messaging.
9. SQS
Amazon Simple Queue Service (SQS) is a fully managed message queuing service that enables you to decouple and scale microservices, distributed systems, and serverless applications. SQS eliminates the complexity and overhead associated with managing and operating message-oriented middleware and empowers developers to focus on differentiating work.
10. RDS
Amazon Relational Database Service (Amazon RDS) makes it easy to set up, operate, and scale a relational database in the cloud. It provides cost-efficient and resizable capacity while automating time-consuming administration tasks such as hardware provisioning, database setup, patching and backups.
11. Dynamo DB
Amazon DynamoDB is a key-value and document database that delivers single-digit millisecond performance at any scale. It’s a fully managed, multi-region, multi-master database with built-in security, backup and restores, and in-memory caching for internet-scale applications. DynamoDB can handle more than 10 trillion requests per day and support peaks of more than 20 million requests per second.
13. Cloud Formation
AWS CloudFormation provides a common language for you to describe and provision all the infrastructure resources in your cloud environment. CloudFormation allows you to use a simple text file to model and provision, in an automated and secure manner, all the resources needed for your applications across all regions and accounts. This file serves as the single source of truth for your cloud environment.
14. Projects
No learning can happen without doing any project. This is our mantra at Dimensionless Technologies. We have different projects planned for our learners which will help in implementing all the learners during the course.
Why Dimensionless as your learning partner?
Dimensionless Technologies provide instructor-led LIVE online training with hands-on different problems. We do not provide classroom training but we deliver more as compared to what a classroom training could provide you with
Are you sceptical of online training or you feel that online mode is not the best platform to learn? Let us clear your insecurities about online training!
Live and Interactive sessions
We conduct classes through live sessions and not pre-recorded videos. The interactivity level is similar to classroom training and you get it in the comfort of your home.
Highly Experienced Faculty
We have very highly experienced faculty with us (IIT`ians) to help you grasp complex concepts and kick-start your career success journey
Up to Data Course content
Our course content is up to date which involves all the latest technologies and tools. Our course is well equipped for learners to grasp the knowledge required to solve real-world problems through their data analytical skills
Availability of software and computing resource
Any laptop with 2GB RAM and Windows 7 and above is perfectly fine for this course. All the software used in this course are Freely downloadable from the Internet. The trainers help you set it up in your systems. We also provide access to our Cloud-based online lab where these are already installed.
Industry-Based Projects
During the training, you will be solving multiple case studies from different domains. Once the LIVE training is done, you will start implementing your learnings on Real Time Datasets. You can work on data from various domains like Retail, Manufacturing, Supply Chain, Operations, Telecom, Oil and Gas and many more.
Course Completion Certificate
Yes, we will be issuing a course completion certificate to all individuals who successfully complete the training.
Placement Assistance
We provide you with real-time industry requirements on a daily basis through our connection in the industry. These requirements generally come through referral channels, hence the probability to get through increases manifold
Conclusion
Dimensionless technologies have the right courses for you if you are aiming to kick-start your career in the field of data science. Not only we cover all the important concepts and technologies but also focus on their implementation and usage in real-world business problems. Follow the link to register yourself for the free demo of the courses!
Among researchers, there is a growing interest in conceptualizing complex problems. It requires using a system framework and using systems modelling tools to explore how components of a complex problem interact. In particular, system simulation approaches are useful tools for understanding the processes and structures involved in complex problems. Alo, identifying high-leverage points in the system and evaluating hypothetical interventions becomes easier.
One tool that has extensive usage in among researchers is agent-based modelling (ABM). We define traits and initial behaviour rules of an agent that organize their actions and interactions. Stochasticity plays an important part in determining which agents interact and how agents make decisions.
Before going into too much depth, let us first have a look at two basic modelling approaches. After that, we can further delve into the world of agent-based modelling.
Types of modelling approaches
Equation-based modelling
It builds on the interrelation of a set of equations that captures the variability of a system over time (ordinary differential equations — ODEs) or over time and space (partial differential equations — PDEs) An example would provide the development of pressure in a box. EBM does not aim at representing the micro-level behaviour of individual agents in the first place (e.g. the velocity of individual gas particles in the box). Therefore, EBM tends to focus the modeller’s attention on the overall behaviour of the system. Its basic constituencies are levels and flow rates, and not so many individual components.
Usually, we validate EBM on the systems level by comparing model output with real system behaviour. Since the behaviour of individual components is not explicitly in its focus, we do not validate it on this level.
Furthermore, EBM (when restricted to ODE-methods like System Dynamics) has no intrinsic option for representing space (PDEs provide parsimonious options for modelling physical space, but not the interaction space of individual agents).
Several intuitive drag-and-drop tools for constructing and analyzing system dynamics models exist (Stella, Powersim, Simulink (of Matlab) or VENSIM) which makes EBM relatively easy to use and therefore extensive usage and deployment.
In sum, EBM seems well-suited to represent physical processes (or processes that can be seen as such without loss). It suggests regarding a system as a whole in the first place and does not support an explicit representation of components (agents). To some extent hence, EBM is a type of top-down technology. It is most naturally applicable to systems which we can model centrally, and in which physical laws govern dynamics rather than by information processing.
Agent-based modelling
It usually starts out with modelling properties and behaviour of individual agents and only thereafter considers macro-level effects to emerge from the aggregation of agents’ behaviour. In ABM, the individual agent is the explicit subject to the modelling effort.
With this, ABM offers an additional level of validation. Like EBM it allows comparing model output with observed system behaviour. Additionally, however, it can be validated at the individual level by comparing the encoded behaviour of each agent with the actual behaviour of real agents. This, however, usually requires additional data and hence more efforts in empirical research.
Basically, ABM might seem intuitively more appropriate for modelling social systems, since it allows, and even necessitates, considering individual decisions, dispositions and inclinations. Its natural modularization follows boundaries among individuals, whereas in EBM modularization often crosses these boundaries.
What is more, ABM allows representing space, thereby offering possibilities to consider topological particularities of interaction and information transfer. In combination with graph theory and network analysis, it enables precise conceptualizations of differences in frequency, strength, existence etc. of interactions between agents.
What is Agent-Based Modelling
Agent-based modelling (ABM) is a style of modelling in which we represent the interaction between individuals and with each other environment in a program. Agents can be, for example, people, animals, groups, or cells. They can model entities that do not have a physical basis but are entities can perform some tasks such as gathering information or modelling the evolution.
It is a method of modelling complex systems by defining rules and behaviours for individual components (agents) as well as the environment they are present in. Further, we aggregate these rules to see the general behaviour of the system. It helps in understanding how simple micro-rules of individual behaviour emerge into macro-level behaviour of a system. Being able to model these complex systems can lead to a better understanding of them, thereby being able to control the course of events, just by tweaking simple rules at the individual level.
Entities in Agent-Based Modelling
ABM contains autonomous models called agents. These agents can be an individual, a group of individuals or even an organisation. Each agent is defined with properties of its own along with relationships with other agents. Apart from agents, ABMs also have environments, which is a set of conditions the agent is exposed to. Once these entities are defined in an ABM, individual behavioural rules of how an agent would behave in a given environment is defined. An aggregate of these simple individual-level behaviours that lead to a complex macro level pattern. A feedback-based learning-model is often used in ABMs to update agent actions based on their changing relationships with other agents and their environment.
Why Agent-Based modelling
Conventional models take into consideration only factors externals to their components to decide their actions. This has the drawback of not modelling the “big picture” entirely. An ABM, not only considers the external factors, but also one component’s interaction with other components, to decide their actions. Thus, it includes the possibilities of these interactions impacting the actions as well. Also, as stated by William Rand, Consumers modelled with ABM can be boundedly rational, heterogeneous in their properties and actions, adaptive and sensitive to history in their decisions, and located within social networks or geographical locations. This makes simulations of situations using ABMs more representative of the real world.
An Example of Agent-Based Models
This example simulates the spread of a fire through a forest. It shows that the fire’s chance of reaching the right edge of the forest depends critically on the density of trees. This is an example of a common feature of complex systems, the presence of a non-linear threshold or critical parameter.
Fire Model
The fire starts on the left edge of the forest and spreads to neighbouring trees. The fire spreads in four directions: north, east, south, and west.
The model assumes there is no wind. So, the fire must have trees along its path in order to advance. That is, the fire cannot skip over an unwooded area (patch), so such a patch blocks the fire’s motion in that direction.
When you run the model, how much of the forest burns. If you run it again with the same settings, do the same trees burn? How similar is the burn from run to run?
Each turtle that represents a piece of the fire is born and then dies without ever moving. If the fire comprises of turtles but no turtles are moving, what does it mean to say that the fire moves? This is an example of different levels in a system: at the level of the individual turtles, there is no motion, but at the level of the turtles collectively over time, the fire moves.
Tools for Agent-Based Modelling
Amp. The AMP project provides extensible frameworks and exemplary tools for representing, editing, generating, executing and visualizing agent-based models (ABMs) and any other domain requiring spatial, behavioural and functional features.
Ascape. An innovative tool for developing and exploring general-purpose agent-based models.
Breve. A free, open-source software package which makes it easy to build 3D simulations of multi-agent systems and artificial life.
GAMA is a simulation platform, which aims at providing field experts, modellers, and computer scientists with a complete modelling and simulation development environment for building spatially explicit multi-agent simulations.
MASON is a fast discrete-event multiagent simulation library core in Java, designed to be the foundation for large custom-purpose Java simulations.
MASS is a Multi-Agent Simulation Suite consists of four major components built around a simulation core.
MetaABM. Supports a high-level architecture for designing, executing and systematically studying ABM models.
NetLogo. A cross-platform multi-agent programmable modeling environment.
Player/Stage. Free Software tools for robot and sensor applications.
PS-I is an environment for running agent-based simulations. It is cross-platform, with binaries available for Win32.
Repast. A free and open source agent-based modelling toolkit that simplifies model creation and use.
Problem Description
The “Heroes and Cowards” game, also called the “Friends and Enemies” game or the “Aggressors and Defenders” game dates back to the Fratelli Theater Group at the 1999 Embracing Complexity conference, or perhaps earlier.
In the human version of this game, each person arbitrarily chooses someone else in the room to be their perceived friend, and someone to be their perceived enemy. They don’t tell anyone who they have chosen, but they all move to position themselves either such that a) they are between their friend and their enemy (BRAVE/DEFENDING), or b) such that they are behind their friend relative to their enemy (COWARDLY/FLEEING).
This simple model demonstrates an idealized form of this game played out by computational agents. Mostly it demonstrates how rich, complex, and surprising behaviour can emerge from simple rules and interactions.
Next Steps
In the next blog of this series, we will be implementing the above-mentioned problem. We will use NetLogo for modelling the above problem. Keep watching this space for the next part!
Conclusion
ABM offers the behavioural sciences a computational toolkit for developing precise and specific models. It focuses on how individuals interact and discover patterns of behaviour and organization that emerge from these interactions. Instead of relying on verbal theories, we can now build ABMs of the phenomena which we want to understand. We can test these models against data. Depending upon the degree they successfully agree with the data, we can achieve a deeper understanding of any phenomena.
Additionally, if you are interested in learning Data Science, click here to get started
Furthermore, if you want to read more about data science, you can read our blogs here
Also, the following are some suggested blogs you may like to read
Data science is an interdisciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from data in various forms, both structured and unstructured, similar to data mining.
Data science is a “concept to unify statistics, data analysis, machine learning and their related methods” in order to “understand and analyze actual phenomena” with data. It employs techniques and theories drawn from many fields within the context of mathematics, statistics, information science, and computer science.
In this blog, we will look at why grasping theoretical knowledge is something which should never be missed while learning data science!!
The two aspects of Data Science
When it comes to knowledge there are different kinds of knowledge and different ways of acquiring each kind. On one side is theory and on the other side is the practical application of theory. Both types of knowledge are important and both make you better at whatever you do.
I think those who advance the furthest in life tend to be those who acquire knowledge at both ends of the spectrum and acquire it in a variety of ways.
Theoretical knowledge
It teaches the why and helps you understand why one technique works where another fails. Also, it shows you the whole forest, buildsthe context, and helps you set strategy. Where self-education is concerned theory prepares you to set a direction for your future education. Theory teaches you through the experience of others.
Theoretical knowledge can often lead to a deeper understanding of a concept through seeing it in context of a greater whole and understanding the why behind it.
Practical knowledge
It helps you acquire the specific techniques that become the tools of your trade. It sits much closer to your actual day-to-day work. There are some things you can only learn through doing and experiencing. Where theory is often taught in the idea of a vacuum, the practical is learned through the reality of life.
Practical knowledge can often lead to a deeper understanding of a concept through the act of doing and personal experience.
Both of the above are important. You won’t survive in any career unless you can bring results and to do that you need practical knowledge. There’s no avoiding it.
At the same time learning how to solve a specific problem only teaches you how to solve that same problem again. Practice can only take you so far. Theory helps you apply what you learned solving one problem to different problems.
How is theoretical knowledge important?
Solid Foundation
Giving attention to theoretical knowledge, in the beginning, helps an individual to develop a strong foundation and understanding of the subject. Practical application focus on the implementation of theoretical concepts and is important too, but directly jumping to implementation without much knowledge is one big mistake which individuals commit while learning data science.
Ability to reason and interpret the practical application
Deep understanding of the subject allows an individual to interpret results of any practical implementation. With a strong hold on theoretical concepts, you can always reason out scenarios like poor performance of your machine learning model or explaining selection of one technique over other. The practical application makes you learn how to do things but theoretical knowledge deals with “what” and “why” of the implementation
Dynamic application of rules to multiple problems
The practical implementation makes an individual learn about solving a specific kind of problem. While repeating the practical implementation, you may get skilled in solving that particular problem. But this will now allow you to solve some different problem with the same learnings. Theoretical knowledge enables an individual to understand the basic concepts of data science. With these basic concepts, the theory then can help in solving multiple other problems. You do not get confined to solve only one single kind of problem if you have strong theoretical knowledge.
No conceptual mistakes in application
If you directly jump to practical implementation, then there are high chances of committing basic conceptual mistakes. A practical implementation without proper knowledge is more like a shot in the dark. You may get it right but you are going to fail a lot more. No one will want to see all their hard work go waste because of some small gap in the concepts which you skipped or missed by not giving much attention to theoretical knowledge.
Validated application
Theoretical knowledge helps you validate your practical implementation. How do you know that the selection of an ML model for a given problem is correct? Are the results from your ML model holds any statistic significance or are just some random values? Validation can only come to you if you have a deep understanding of underlying concepts. Without these concepts, you can get skilled at doing a task but you can never validate if that was the optimised solution for the given problem or even that solution is right or wrong at first place!
Why theory in Data Science?
Vast knowledge base
Data science is a multi-disciplinary field. It involves the amalgamation of maths, business and technology. In order to be a good data scientist, you need to have a great skill at all of these. Since there is a plethora of knowledge in data science, you can not just learn by doing the practical implementation. You have to get your hands dirty with theoretical aspects of the data science and master them first. If you hurry to practical implementation, you are surely going to miss on a lot of edge cases and conceptual concepts which may lead you to make an error while doing the practical implementation.
Unexplored applications
Data sciences is a fairly new subject. There are no well-defined applications of data sciences in any domain. Every day we observe how beautifully a given problem was approached and solved using data science. Solving an unexplored problem requires a lot of theoretical knowledge which just cannot come by the practical implementation. As a data scientist, you should be able to solve any problem at hand with strong core knowledge rather than solving only a single kind of problem every time like a routine work
Constant evolution
Data science is constantly evolving and so are the concepts around it. There is a lot of research going around in data science. There are new use cases, algorithms and approach process every other day. At this phase, if you miss the theoretical aspect then you will never have updated knowledge. Regular brushup and learning of theoretical concepts is required in data science.
A lot of MATH
Data science has a lot of math aspect to it. The algorithms, the statistics, the numbers.. you can just not skip it in any form. Math is something which will come to you when you learn and implement it theoretically first. Any error in the mathematical knowledge and you will be seeing all your algorithm, analysis and insights fail right in front of you
No clearly defined roles
Currently, data science has no clearly defined roles. A data scientist is supposed to handle maths, technology and the business aspect together. But in jobs today, there is no clear balance between these 3 aspects of data science. At some firms, you need to be “math” heavy data scientist and maybe at some you need to be “tech” heavy data scientist. There are no clear demarcations currently in the industry. So if you need to find a job in data sciences, you should have a strong core knowledge. This will enable to scale up in any one aspect be it maths, business or technology quickly
When to switch modes
So you may ask me what is more important here? Theoretical knowledge or Practical application? I would say both are important and hold importance in different aspects. The key idea is to formulate your learning process in a such a way that you get enough theoretical knowledge along with proper time to implement and learn while doing the practical implementation. You can start by learning some theory then switching to the basic practical implementation of it. Once you are done with a basic implementation, come back to theory and question every step you performed during practical implementation. Analyse why those steps were required and are there other ways/means of performing a similar task and finding the most optimal method of all
Conclusion
Both are prominent at their own instances and neglecting one could lead to drastic failure in the other. Theory provides you the apt information about the experiences of others and practical knowledge helps you build your own experiences.
To simplify the topic, there is no theoretical knowledge or practical one, it’s all about formal education and self-learning. Hard knowledge and soft knowledge, both are like two distant beaches, it is you who has to find and build a strong bridge between the both.
As quoted by the great Yogi Berra, “In theory, there is no difference between theory and practice. In practice there is”. And also, “Knowledge is of no value unless you put it into practice and practice is never possible without a deep knowledge”, as said by Anton Chekhov. We all have to find a balance between the two else, the debate is of no use and has no end.
Additionally, if you are interested in learning Data Science, click here to get started
Furthermore, if you want to read more about data science, you can read our blogs here
Also, the following are some suggested blogs you may like to read
Data Science is a study which deals with the identification, representation, and extraction of meaningful information from data. Data analysts collect it from different sources to use for business purposes.
With an enormous amount of facts generating each minute, the requirement to extract the useful insights is a must for the businesses. It helps them stand out from the crowd. With the huge demands for data scientists, many professionals are taking their founding steps in data science. With a large number of people being inexperienced in data science, there are a lot of basic mistakes committed by young data analysts.
In this blog, we will look into some of the common mistakes by young professionals in data analysis so that you don’t end up with the same.
Additionally, if you are interested in learning data science, then you can get an amazing course from us here
Common Mistakes
1. Correlation vs. causation
The underlying principle in statistics and data science is the correlation is not causation, meaning that just because two things appear to be related to each other doesn’t mean that one causes the other. This is apparently the most common mistake in Time Series. Fawcett cites an example of a stock market index and the unrelated time series Number of times Jennifer Lawrence was mentioned in the media. The lines look amusingly similar. There is usually a statement like “Correlation = 0.86”. Recall that a correlation coefficient is between +1 (a perfect linear relationship) and -1 (perfectly inversely related), with zero meaning no linear relationship. 0.86 is a high value, demonstrating that the statistical relationship of the two-time series is strong.
2. Not Looking Beyond Numbers
Some data analysts and marketers are only assessing the numbers they get, without putting them in their contexts. Quantitative data is not powerful unless it’s understood. In those instances, whoever performs the data analysis should ask himself “why” instead of “what”. Falling under the spell of big numbers is a common mistake that so many analysts commit.
3. Not defining the problem well
This can be regarded as the tone of the most fundamental problem in data science. Most of the issues which arise in data science are due to fact that the problem for which solution needs to be found out is itself not correctly defined. If you can’t define the problem well enough then reaching its solution will be a mere dream. One should research the problem well enough and analyse all the components like stakeholders, action plans etc.
4. Focussing on the wrong metric
When you’re just getting started, it can be tempting to get focus on small wins. While it’s definitely important and a great morale booster, make sure it’s not distracting from other metrics you should be more focused on (like sales, customer satisfaction, etc.
5. Not cleaning and normalising data before analysis
Always assume the data you are working with is inaccurate at first. Once you get familiar with it, you will start to “feel” when something is not quite right. Take a first glance using pivot tables or quick analytical tools to look for duplicate records or inconsistent spelling to clean up your data first. Also, not normalising the data is one more concern which can hinder your analysis. In most cases, when you normalize data you eliminate the units of measurement for data, enabling you to more easily compare data from different places.
6. Improper outlier treatment
Outliers can affect any statistical analysis, thereby analysts should investigate, delete and correct outliers as appropriate. For auditable work, the decision on how to treat any outliers should be documented. Sometimes loss of information may be a valid tradeoff in return for enhanced comprehension. In some cases, many people forget to treat the outliers which greatly affects the analysis and skews the results. In some other cases, you may focus too much on the outliers. Due to this, you devote large time handling those events which may not hold much significance in your analysis
7. Wrong graphs selection for visualisations
Let us take the case of pie charts here. Pie charts are for conveying a story about the parts-to-whole aspect of a set of data. That is, how big part A is in relation to part B, C, and so on. The problem with pie charts is that they force us to compare areas (or angles), which is pretty hard. Selecting the right kind of graph for the right context comes with experience.
8. Focussing more on the accuracy of the model rather than context
One should not focus too much on the accuracy of their model to an extent that you start overfitting the model to a particular case. Analysts build machine learning models to apply them to the general scenarios. Overfitting a model will make it work only for the situation which is exactly identical to training situation. In this case, model will fail badly for any situation different from the training environment.
9. Ignoring seasonality in data
Holidays, summer months, and other times of the year can mess up your data. Even a 3-month trend is explainable because of the busy tax season or back-to-school time. Make sure you are considering any seasonality in your data…even days of the week or times of the day!
10. No focus on the statistical significance of results while making decisions
Information from statistical significance testing is necessary but is not always sufficient. Statistical significance does not provide information about the impact of the significant result on business. Effect index size can evaluate this better
Why these common mistakes
1. Inadequate domain and technical knowledge
Having insufficient knowledge about the business of the problem at hand or maybe less technical knowledge required to solve that problem is a cause for these common mistakes. Proper business viewpoints, goal and technical knowledge must be a pre-requisite to the professionals before they start hands-on.
2. Time crunch
Less time available for the end analysis may make the analysts hurry up. This results in analysts missing out on small details as they can never follow a proper checklist and hence these common mistakes.
3. Inexperience in data analysis
Data science is a very huge subject and it is very uphill task for any fresher to have entire knowledge about data science. Common mistakes happening in data science are the result of the fact that most of the professionals are not even aware of certain fine aspects of data science.
Conclusion
Data analysis is both a science and an art. You need to be both calculative and creative, and your hard efforts will truly pay off. There’s nothing more satisfying than dealing with a data analysis problem and fixing it after numerous attempts. When you actually get it right, the benefits for you and the company will make a big difference in terms of traffic, leads, sales, and costs saved.
Additionally, if you are interested in learning Data Science, click here to get started
Furthermore, if you want to read more about data science, you can read our blogs here
Also, the following are some suggested blogs you may like to read