Python and R have been around for well over 20 years. Python was developed in 1991 by Guido van Rossum, and R in 1995 by Ross Ihaka and Robert Gentleman. Both Python and R have seen steady growth year after year in the last two decades. Will that trend continue, or are we coming to an end of an era of the Python-R dominance in the data science segment? Let’s find out!
Python
Python in the last decade has grown from strength to strength. In 2013, Python overtook R as the most popular language used fordata science, according to the Stack Overflow developer survey (Link).
In the last three years, Python was the most wanted language according to this survey (25% in 2018, JavaScript was second with 19%). It is by far the easiest programming language to learn, the Julia and the Go programming languages being honorable mentions in this regard.
Python shines in its versatility, being easy to use for data science, web development, utility programming, and as a general-purpose programming language. Even full-stack development can be done in Python, the only area where it is not used being mobile (although that may change if the Kivy mobile programming framework comes of age and stops stalling all the time). It was also ranked higher than JavaScript in the most loved programming languages for the last three years (Node.js and React.js have ranked below it consistently).
Will Python’s Dominance Continue?
We believe, yes, definitely. Two words – data science.
From https://www.digitaldesignjournal.com
Data science is such a hot and happening field right now, and the data scientist job is hyped as the ‘sexiest job of the 21st century‘, according to Forbes. Python is by far the most popular language for data science. The only close competitor is R, which Python overtook in the KDNuggets data science survey of 2016 . As shown in the link, in 2018, Python held 65.6% of the data science market, and R was actually below RapidMiner, at 48.5%. From the graphs, it is easy to see that Python is eating away at R’s share in the market. But why?
Deep Learning
In 2018, we say a huge push towards advancement across all verticals in the industry due to deep learning. And what is the most famous tool for deep learning? TensorFlow and Keras – both Python-based frameworks! While we have Keras and TensorFlow interfaces in R and RStudio now, Python was the initial choice and is still the native library – kerasR and tensorflow in RStudio being interfaces to the Python packages. Also, a real-life implementation of a deep learning project contains more than the deep learning model preparation and data analysis.
There is the data preprocessing, data cleaning, data wrangling, data preparation, outlier detection and missing data values management section which is infamous for taking up 99% of the time of a data scientist, with actual deep learning model work taking just 1% or less of their on-duty time! And what language is used for this commonly? For general purpose programming, Python is the goto language in most cases. I’m not saying that R doesn’t have data preprocessing packages. I’m saying that standard data science operations like web scraping are easier in Python than in R.And hence Python will be the language used in most cases, except in the statistics and the university or academic fields.
Our prediction for Python – growth – even to 70% of the data science market as more and more research-level projects like AutoML keep using Python as a first language of choice.
What About R?
In 2016, the use of R for data science in the industry was 55%, and Python stood at 51%. Python increased by 33% and R decreased by 25% in 2 years. Will that trend continue and will R continue on its downward spiral? I believe perhaps in figures, but not in practice. Here’s why.
Data science is at its heart, the field of the statistician. Unless you have a strong background in statistics, you will be unable to process the results of your experiments, especially in concepts like p-values, tests of significance, confidence intervals, and analysis of experiments. And R is the statistician’s language.Statistics and mathematics students will always find working in R remarkably easy and simple, which explains its popularity in academia. R programming lends itself to statistics. Python lends itself to model building and decent execution performance (R can be 4x slower). R, however, excels in statistical analysis. So what is the point that I am trying to express?
Simple – Python and R are complementary. They are best used together. You will find that knowledge of both Python and R will suit you best for most projects. You need to learn both. You can find this trend expressed in every article that speaks about becoming a data science unicorn – knowledge of both Python and R is required as a norm.
Yes, R is having a downturn in popularity. However, due to the complementary nature of the tools, I believe that R will have a part to play in the data scientist’s toolbox, even if it does dip a bit in growth in the years to come. Very simply, R is too convenient for a statistician to be neglected by the industry completely. It will continue to have its place in the toolbox. And yes; deep learning is now practical in R with support for Keras and AutoML as well as of right now.
Dimensionless Technologies
Dimensionless Technologies
Dimensionless Technologies is the market leader as far as training in AI, cloud, deep learning and data science in Python and R is concerned. Of course, you don’t have to spend 40k for a data science certification, you could always go for its industry equivalent – 100-120 lakhs for a US university’s Ph.D. research doctorate! What Dimensionless Technologies has as an advantage over its closest rival – (Coursera’s John Hopkins University’s Data Science Specialization) – is:
Live Video Training
The videos that you get on Coursera, edX, Dataquest, MIT OCW (MIT OpenCourseWare), Udacity, Udemy, and many other MOOCs have a fundamental flaw – they are NOT live! If you have a doubt in a video lecture, you only have the comments as a communication tool to the lectures. And when over 1,000 students are taking your class, it is next to impossible to respond to every comment. You will not and cannot get personalized attention for your doubts and clarifications. This makes it difficult for many, especially Indian students who may not be used to foreign accents to have a smooth learning curve in the popular MOOCs available today.
Try Before You Buy Fully
Dimensionless Technologies offers 20 hours of the course for Rs 5000, with the remaining 35k (10k of 45k waived if you qualify for the scholarship) payable after 2 weeks / 20 hours of taking the course on a trial basis. You get to evaluate the course for 20 hours before deciding whether you want to go through the entire syllabus with the highly experienced instructors who are strictly IIT alumni.
Instructors with 10 years Plus Industry Experience
In Coursera or edX, it is more common for Ph.D. professors than industry experienced professionals to teach the course. If you are good with American accents and next to zero instructor support, you will be able to learn a little bit about the scholastic side of your field. However, if you want to prepare for a 100K USD per year US data scientist job, you would be better off learning from professionals with industry experience. I am Not criticizing the Coursera instructors here, most have industry experience as well in the USA. However, if you want connections and contacts in the data science industry in India and the US, you might be a bit lost in the vast numbers of student who take those courses. Industry experience in instructors is rare in a MOOC and critically important to your landing a job.
Personalized Attention and Job Placement Guarantee
Dimensionless has a batch size of strictly not more than 25 per batch. This means that unlike other MOOCs with hundreds or thousands of students, every student in a class will get individual attention and training. This is the essence of what makes this company the market leader in this space. No other course provider has this restriction, which makes it certain that when you pay the money, you are 100% certain of completing your course, unlike all the other MOOCs out there. You are also given training for creating a data science portfolio, and how to prepare for data science interviews when you start applying to companies. The best part of this entire process is the 100% job placement guarantee.
If this has got your attention, and you are highly interested in data science, I encourage you to go to the following link to see more about the Data Science Using Python and R course, a strong foundation for a data science career:
The amount of data that is generated every day is mind-boggling. There was an article on Forbes by Bernard Marr that blew my mind. Here are some excerpts. For the full article, go to Link
There are 2.5 quintillion bytes of data created each day. Over the last two years alone 90 percent of the data in the world was generated.
Europe has more than 307 million people on Facebook
There are five new Facebook profiles created every second!
More than 300 million photos get uploaded per day
Every minute there are 510,000 comments posted and 293,000 statuses updated (on Facebook)
And all this data was gathered 21st May, last year!
Photo by rawpixel on Unsplash
So I decided to do a more up to date survey. The data below was from an article written on 25th Jan 2019, given at the following link:
By 2020, the accumulated volume of big data will increase from 4.4 zettabytes to roughly 44 zettabytes or 44 trillion GB.
Originally, data scientists maintained that the volume of data would double every two years thus reaching the 40 ZB point by 2020. That number was later bumped to 44ZB when the impact of IoT was brought into consideration.
The rate at which data is created is increased exponentially. For instance, 40,000 search queries are performed per second (on Google alone), which makes it 3.46 million searches per day and 1.2 trillion every year.
The data gathered is no more text-only. An exponential growth in videos and photos is equally prominent. On YouTube alone, 300 hours of video are uploaded every minute.
IDC estimates that by 2020, business transactions (including both B2B and B2C) via the internet will reach up to 450 billion per day.
Globally, the number of smartphone users will grow to 6.1 billion by 2020 (this will overtake the number of basic fixed phone subscriptions).
In just 5 years the number of smart connected devices in the world will be more than 50 billion – all of which will create data that can be shared, collected and analyzed.
Photo by Fancycrave on UnsplashSo what does that mean for us, as data scientists?
Data = raw information. Information = processed data.
Theoretically, inside every 100 MB of the 44,000,000,000,000,000 GB available in the world, today produced as data there lies a possible business-sector disrupting insight!
But who has the skills to look through 44 trillion GB of data?
The answer: Data Scientists! WithCreativity and Originality in their Out-of-the-Box Thinking, as well as DisciplinedFocus.
Here is a description estimating the salaries for data scientists followed by a graphic which shows you why data science is so hyped right now:
Freshers in Analytics get paid more than then any other field, they can be paid up-to 6-7 Lakhs per annum (LPA) minus any experience, 3-7 years experienced professional can expect around 10-11 LPA and anyone with more than 7-10 years can expect, 20-30 LPA.
Opportunities in tier 2 cities can be higher, but the pay-scale of Tier 1 cities is much higher.
E-commerce is the most rewarding career with great pay-scale especially for Fresher’s, offering close to 7-8 LPA, while Analytics service provider offers the lowest packages, 6 LPA.
It is advised to combine your skills to attract better packages, skills such as SAS, R Python, or any open source tools, offers around 13 LPA.
Machine Learning is the new entrant in analytics field, attracting better packages when compared to the skills of big data, however for a significant leverage, acquiring the skill sets of both Big Data and Machine Learning will fetch you a starting salary of around 13 LPA.
Combination of knowledge and skills makes you unique in the job market and hence attracts high pay packages.
Picking up the top five tools of big data analytics, like R, Python, SAS, Tableau, Spark along with popular Machine Learning Algorithms, NoSQL Databases, Data Visualization, will make you irresistible for any talent hunter, where you can demand a high pay package.
As a professional, you can upscale your salary by upskilling in the analytics field.
So there is no doubt about the demand or the need for data scientists in the 21st century.
Now we have done a survey for India. but what about the USA?
The following data is an excerpt from an article by IBM< which tells the story much better than I ever could:
Jobs requiring machine learning skills are paying an average of $114,000.
Advertised data scientist jobs pay an average of $105,000 and advertised data engineering jobs pay an average of $117,000.59% of all Data Science and Analytics (DSA) job demand is in Finance and Insurance, Professional Services, and IT.
Annual demand for the fast-growing new roles of data scientist, data developers, and data engineers will reach nearly 700,000 openings by 2020.
By 2020, the number of jobs for all US data professionals will increase by 364,000 openings to 2,720,000 according to IBM.
Data Science and Analytics (DSA) jobs remain open an average of 45 days, five days longer than the market average.
And yet still more! Look below:
By 2020 the number of Data Science and Analytics job listings is projected to grow by nearly 364,000 listings to approximately 2,720,000 The following is the summary of the study that highlights how in-demand data science and analytics skill sets are today and are projected to be through 2020.
There were 2,350,000 DSA job listings in 2015
By 2020, DSA jobs are projected to grow by 15%
Demand for Data scientists and data engineers is projectedto grow byneary40%
DSA jobs advertise average salaries of 80,265 USD$
81% of DSA jobs require workers with 3-5 years of experience or more.
Machine learning, big data, and data science skills are the most challenging to recruit for and potentially can create the greatest disruption to ongoing product development and go-to-market strategies if not filled.
So where does Dimensionless Technologies, with courses in Python, R, Deep Learning, NLP, Big Data, Analytics, and AWS coming soon, stand in the middle of all the demand?
The answer: right in the epicentre of the data science earthquake that is no hitting our IT sector harder than ever.The main reason I say this is because of the salaries increasing like your tummy after you finish your fifth Domino’s Dominator Cheese and Pepperoni Pizza in a row everyday for seven days! Have a look at the salaries for data science:
Do you know which city in India pays highest salaries to data scientist?
Mumbai pays the highest salary in India around 12.19L p.a.
Report of Data Analytics Salary of the Top Companies in India
Accenture’s Data Analytics Salary in India: 90% gets a salary of about Rs 980,000 per year
Tata Consultancy Services Limited Data Analytics Salary in India: 90% of the employees get a salary of about Rs 550,000 per year. A bonus of Rs 20,000 is paid to the employees.
EY (Ernst & Young) Data Analytics Salary in India: 75% of the employees get a salary of Rs 620,000 and 90% of the employees get a salary of Rs 770,000.
HCL Technologies Ltd. Data Analytics Salary in India: 90% of the people are paid Rs 940,000 per year approximately.
In the USA
From glassdoor.com
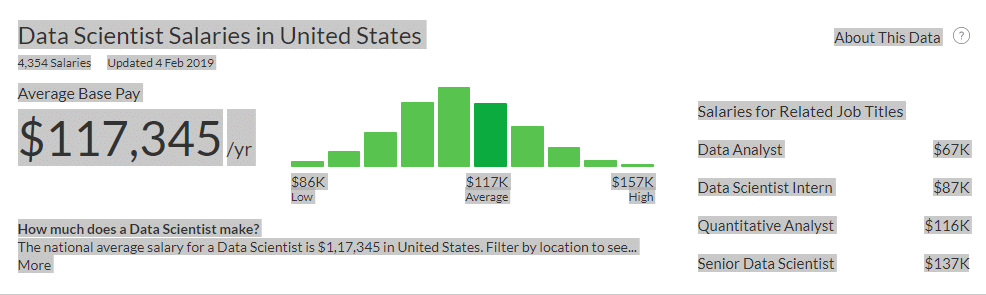
To convert into INR, in the US, the salaries of a data scientist stack up as follows:
Lowest: 86,000 USD = 6,020,000 INR per year (60 lakh per year)
Average: 117,00 USD = 8,190,000 INR per year (81 lakh per year)
Highest: 157,000 USD = 10,990,000 INR per year(109 lakh per year or approximately one crore)
at the exchange rate of 70 INR = 1 USD.
By now you should be able to understand why everyone is running after data science degrees and data science certifications everywhere.
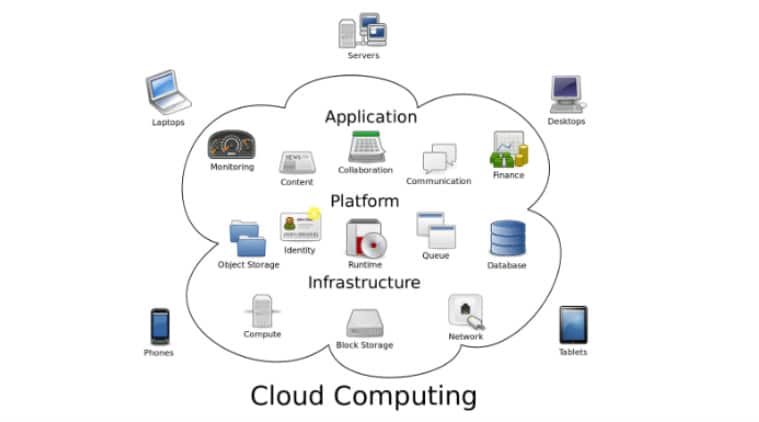
The only other industry that offers similar salaries is cloud computing.
A Personal View
On my own personal behalf, I often wondered – why does everyone talk about following your passion and not just about the money. The literature everywhere advertises“Follow your heart and it will lead you to the land of your dreams”. But then I realized – passion is more than your dreams. A dream, if it does not serve others in some way, is of no inspirational value. That is when I found the fundamental role – focus on others achieving their hearts desires, and you will automatically discover your passion. I have many interests, and I found my happiness doing research in advanced data science and quantum computing and dynamical systems, focusing on experiments that combine all three of them together as a single unified theory. I found that that was my dream. But, however, I have a family and I need to serve them. I need to earn.
Thus I relegated my dreams of research to a part-time level and focused fully on earning for my extended family, and serving them as best as I can. Maybe you will come to your own epiphany moment yourself reading this article. What do you want to do with your life? Personally, I wish to improve the lives of those around me, especially the poor and the malnourished. That feeds my heart. Hence my career decision – invest wisely in the choices that I make to garner maximum benefit for those around me. And work on my research papers in the free time that I get.
So my hope for you today is: having read this article, understand the rich potential that lies before you if you can complete your journey as a data scientist. The only reason that I am not going into data science myself is that I am 34 years old and no longer in the prime of my life to follow this American dream. Hence I found my niche in my interest in research. And further, I realized that a fundamental ‘quantum leap’ would be made if my efforts were to succeed. But as for you, the reader of this article, you may be inspired or your world-view expanded by reading this article and the data contained within. My advice to you is: follow your heart. It knows you best and will not betray you into any false location. Data science is the future for the world. make no mistake about that. And – from whatever inspiration you have received go forward boldly and take action. Take one day at a time. Don’t look at the final goal. Take one day at a time. If you can do that, you will definitely achieve your goals.
The salary at the top, per year. From glassdoor.com. Try not to drool. 🙂
Finding Your Passion
Many times when you’re sure you’ve discovered your passion and you run into a difficult topic, that leaves you stuck, you are prone to the famous impostor syndrome. “Maybe this is too much for me. Maybe this is too difficult for me. Maybe this is not my passion. Otherwise, it wouldn’t be this hard for me.” My dear friend, this will hit you. At one point or the other. At such moments, what I do, based upon lessons from the following course, which I highly recommend to every human being on the planet, is: Take a break. Do something different that completely removes the mind from your current work. Be completely immersed in something else. Or take a nap. Or – best of all – go for a run or a cycle. Exercise. Workout. This gives your brain cells rest and allows them to process the data in the background. When you come back to your topic, fresh, completely free of worry and tension, completely recharged, you will have an insight into the problem for you that completely solves it. Guaranteed. For more information, I highly suggest the following two resources:
or the most popular MOOC of all time, based on the same topic: Coursera
Learning How to Learn – Coursera and IEEE
This should be your action every time you feel stuck. I have completely finished this MOOC and the book and it has given me the confidence to tackle any subject in the world, including quantum mechanics, topology, string theory, and supersymmetry theory. I strongly recommend this resource (from experience).
So Dimensionless Technologies (link given above) is your entry point to all things data science. Before you go to TensorFlow, Hadoop, Keras, Hive, Pig, MapReduce, BigQuery, BigTable, you need to know the following topics first:
All the best. Your passion is not just a feeling. It is a choice you make the day in and a day out whether you like it or not. That is the definition of character – to do what must be done even if you don’t feel like it. Internalize this advice, and there will be no limits to how high you can go.All the best!
TensorFlow 2.0 is coming soon. And boy, are we super-excited! TensorFlow first began the trend of open-sourcing AI and DL frameworks for use by the community. And what has been the result? TensorFlow has become an entire ML ecosystem for all kinds of AI technology. Just to give you an idea, here are the features that an absolutely incredible community has added to the original TensorFlow package:
From Medium.com
Features of TensorFlow contributed from the Open Source Community
TensorFlow started out as a difficult-to-learn framework for deep learning from Google. With one difference – it was open-sourced. That may appear as stupidity for a commercial company that focuses on profits, but it was the right thing to do. Because the open source community took it up as their own property and ported it to nearly every platform available today including mobile, web, IoT, embedded, Edge Computing and so much more. And even more: from Python and C, it was ported to JavaScript, C++, C#, Node.js, F#, React.js, Go, Julia, R, Rust, Android, Swift, Kotlin, and even a port to Scala, Haskell, and numerous other coding languages. Then, after that complete conquest, Google went into the next level for optimization – hardware.
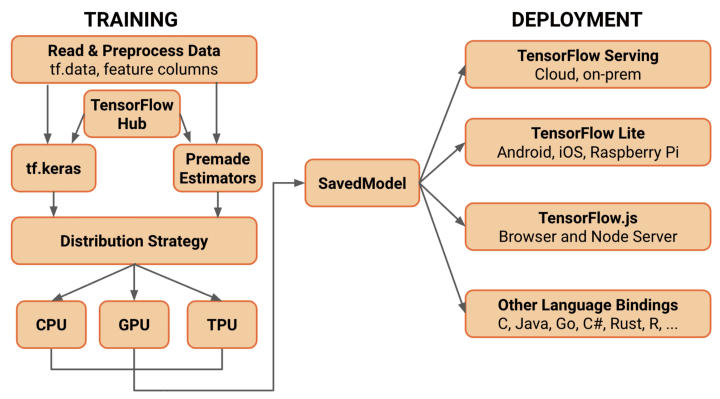
Which means – now we have CUDA (library for executing ML code on GPUs) v8-v9-v10 (9.2 left out), GPGPU, GPU-Native Code, TPU (Tensor Processing Unit – custom hardware provided by Google specially designed for TensorFlow), Cloud TPUs, FPGAs (Field-Programmable Gate Arrays – Custom Programmable Hardware), ASIC (Application Specific Integrated Circuits) chip hardware specially designed for TensorFlow, and now MKL for Intel, BLAS optimization, LINPACK optimization (the last three all low-level software optimization for matrix algebra, vector algebra, and linear algebra packages), and so much more that I can’t fit it into the space I have to write this article. To give you a rough idea of what the TensorFlow architecture looks like now, have a look at this highly limited graphic:
Source: planspaces.org
Note: XLA stands for A(X)ccelerated Linear Algebra compiler still in development that provides highly optimized computational performance gains.
And Now TensorFlow 2.0
This release is expected shortly in the next six months from Google. Some of its most exciting features are:
Keras Integration as the Main API instead of raw TensorFlow code
Simplified and Integrated Workflow
Eager Execution
More Support for TensorFlow Lite and TensorFlow Edge Computing
Extensions to TensorFlow.js for Web Applications and Node.js
TensorFlow Integration for Swift and iOS
TensorFlow Optimization for Android
Unified Programming Paradigms (Directed Acyclic Graph/Functional and Stack/Sequential)
Support for the new upcoming WebGPU Chrome RFC proposal
Integration of tf.contrib best Package implementations into the core package
Expansion of tf.contrib into Separate Repos
TensorFlow AIY (Artificial Intelligence for Yourself) support
Improved TPU & TPU Pod support, Distributed Computation Support
Improved HPC integration for Parallel Computing
Support for TPU Pods up to v3
Community Integration for Development, Support and Research
Domain-Specific Community Support
Extra Support for Model Validation and Reuse
End-to-End ML Pipelines and Products available at TensorFlow Hub
And yes – there is still much more that I can’t cover in this blog.
Wow – that’s an Ocean! What can you Expand Upon?
Yes – that is an ocean. But to keep things as simple as possible (and yes – stick to the word limit – cause I could write a thousand words on every one of these topics and end up with a book instead of a blog post!) we’ll focus on the most exciting and striking topics (ALLare exciting – we’ll cover the ones with the most scope for our audience).
1. Keras as the Main API to TensorFlow
From www.keras.io
Earlier, comments like these below were common on the Internet:
“TensorFlow is broken” – Reddit user
“Implementation so tightly coupled to specification that there is no scope for extension and modification easily in TensorFlow” – from a post on Blogger.com
“We need a better way to design deep learning systems than TensorFlow” – Google Plus user
Understanding the feedback from the community, Keras was created as an open source project designed to be an easier interface to TensorFlow. Its popularity grew very rapidly, and now nearly 95% of ML tasks happening in the real world can be written just using Keras. Packaged as ‘Deep Learning for Humans’, Keras is simpler to use. Though, of course, PyTorch gives it a real run for the money as far as simplicity is concerned!
In TensorFlow 2.0, Keras has been adopted as the main API to interact with TensorFlow. Support for pure TensorFlow has not been removed, and thus TensorFlow 2.0 will be completely backwards-compatible, including a conversion tool that can be used to convert TensorFlow 1.x to TensorFlow 2.0 where implementation details differ. Kind of like the Python tool 2to3.py! So now, Keras is the main API for TensorFlow deep learning applications – which takes out a huge amount of unnecessary complexity burdens from the ML engineer.
Use tf.data for data loading and preprocessing or use NumPy.
Use Keras or Premade Estimators to do your model construction and validation work.
Use tf.function for DAG graph-based execution or use eager execution ( a technique to smoothly debug and run your deep learning model, on by default in TF 2.0).
For TPUs, GPUs, distributed computing, or TPU Pods, utilize Distribution Strategy for high-performance-computing distributed deep learning applications.
TF 2.0 standardizes SavedModel as a serialized version of a TensorFlow graph for a variety of different platforms like Mobile, JavaScript, Edge, Lite, TensorBoard, TensorHub, and TensorServing. This makes it easier to move models around different architectures. This was one feature that was highly necessary compared to the older scenario.
This means that now even novices at machine learning can perform deep learning tasks with relative ease. And of course, did we mention the wide variety of end-to-end pluggable deep learning solutions available at TensorHub and on the Tutorials section? And guess what – they’re all free to download and use for commercial purposes. Google, you are truly the best friend of the open source community!
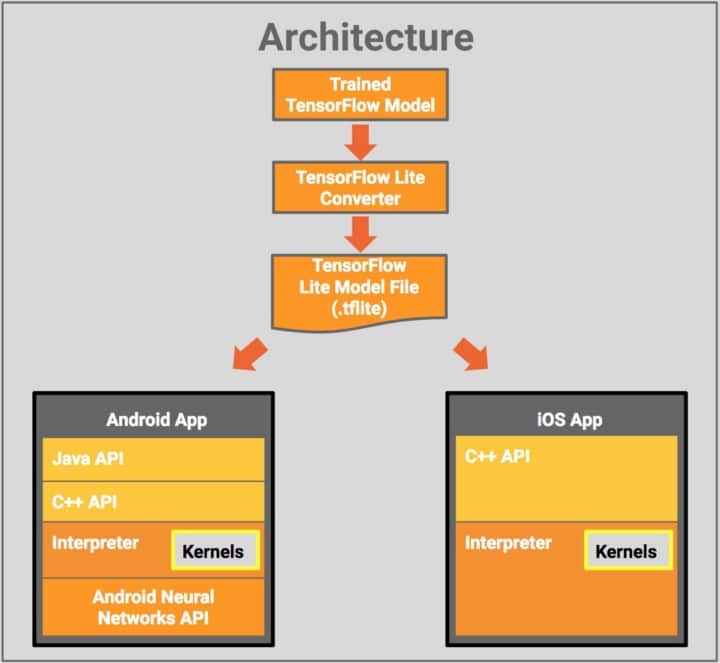
3. Expanded Support for Mobile (Android and iOS), Web (JavaScript), TF Lite, TF Edge and IoT
From Medium.com
In all the above platforms, where computational and memory resources are scarce, there is a common trend in TF 2.0 that extends over most of these platforms.
Greater support for various ops in TF 2.0 and several deployment techniques
SIMD+ support for WebAssembly
Support for Swift (iOS) in Colab.
Increased support for data input pipelines, and data visualization libraries in JavaScript.
A smaller and lighter footprint for Edge Computing, Mobile Computing and IoT
Better support for audio and text-based models
Easier conversion of trained TF 2.0 graphs
Increased and improved mobile model optimization techniques
As you can see, Google knows that Edge and Mobile is the future as far as computing is concerned, and has designed its products accordingly. TF Mobile should be replaced by TF Lite soon.
4. Unified Programming Models and Methodologies
There are two/three major ways to code deep learning networks in Keras. They are:
We build models symbolically by describing the structure of its DAG (Directed Acyclic Graph) or a sequential stack. This following image is an example of Keras code written symbolically.
From Medium.com TensorFlow publication
This looks familiar to most of us since this is how we use Keras usually. The advantages of this process are that it’s easy to visualize, has debugging errors usually only at compile time, and corresponds to our mental model of the deep learning network and is thus easy to work with.
Stack-Based/Subclassing/Imperative API
The following code is an example of the Sequential paradigm or subclassing paradigm to building a deep learning network:
From Medium.com TensorFlow publication (code still in development)
Rather similar to Object Oriented Python, this style was first introduced into the deep learning community in 2015 and has since been used by a variety of deep learning libraries. TF 2.0 has complete support for it. Although it appears simpler, it has some serious disadvantages.
Imperative models are not a data structure that is transparent but an opaque class instead. You are prone to many errors at runtime following this approach. As a deep learning practitioner, you are obliged to know both symbolic as well as imperative and subclassing methodologies of coding your deep neural network. For example, recursive or recurrent neural networks cannot be defined by the symbolic programming model. So it is good to know both. But be aware of the disparate advantages and disadvantages of them!
5. TensorFlow AIY
From slideshare.com
This is a brand new offering from Google and other AI companies such as Intel. AIY stands for Artificial Intelligence for Yourself (a play on DIY – Do It Yourself) and is a new marketing scheme from Google to show consumers how easy it is to use TensorFlow in your own DIY devices to create your own AI-enabled projects and gadgets. This is a very welcome trend, since it literally brings the power of AI to the masses, at a very low price. I honestly feel that now the day is nearing when schoolchildren will bring their AIY projects for school exhibitions and that the next generation of whiz kids will be chock full of AI expertise and development of new and highly creative and innovative AI products. This is a fantastic trend and now I have my own to-buy-and-play-with list if I can order these products on Google at a minimal shipping charge. So cool!
6. Guidelines and New Incentives for Community Participation and Research Papers
We are running out of the word limit very fast! I hoped to cover TPUs and TPU Pods and Distributed Computation, but for right now, this is my final point. Realizing and recognizing the massive role the open source community has played in the development of TensorFlow as a worldwide brand for deep learning neural nets, the company has set up various guidelines to introduce domain-specific innovation and the authoring of research papers and white papers from the TensorFlow community, in collaboration with each other. To quote:
Grow global TensorFlow communities and user groups.
Collaborate with partners to co-develop and publish research papers.
Continue to publish blog posts and YouTube videos showcasing applications of TensorFlow and build user case studies for high impact application
In fact, when I read more of the benefits of participating in the TensorFlow community open source development process, I could not help it, I joined the TensorFlow development community, myself as well!
A Dimensionless Technologies employee contributing to TensorFlow!
Who knows – maybe, God-willing, one day my code will be a part of TensorFlow 2.0/2.x! Or – even better – there could be a research paper published under my name with collaborators, perhaps. The world is now built around open source technologies, and as a developer, there has never been a better time to be alive!
In Conclusion
So don’t forget, on the day of writing this blog article, 31th January 2019, TensorFlow 2.0 is yet to be released, but since its an open source project, there are no secrets and Google is (literally) being completely ‘open’ about the steps it will take to take TF further as the world market leader in deep learning. I hope this article has increased your interest in AI, open source development, Google, TensorFlow, deep learning, and artificial neural nets. Finally, I would like to point you to some other articles on this blog that focus on Google TensorFlow. Visit any of the following blog posts for more details on TensorFlow, Artificial intelligence Trends and Deep Learning:
Now unless you’ve been a hermit or a monk living in total isolation, you will have heard of Amazon Web Services and AWS Big Data. It’s a sign of an emerging global market and the entire world becoming smaller and smaller every day. Why? The current estimate for the cloud computing market in 2020, according to Forbes (a new prediction, highly reliable), is a staggering 411 Billion USD$! Visit the following link to read more and see the statistics for yourself:
To know more, refer to Wikipedia for the following terms by clicking on them, which mark, in order the evolution of cloud computing (I will also provide the basic information to keep this article as self-contained as possible):
This was the beginning of the revolution called cloud computing. Companies and industries across verticals understood that they could let experts manage their software development, deployment, and management for them, leaving them free to focus on their key principle – adding value to their business sector. This was mostly confined to the application level. Follow the heading link for more information, if required.
PaaS began when companies started to understand that they could outsource both software management and operating systems and maintenance of these platforms to other companies that specialized in taking care of them. Basically, this was SaaS taken to the next level of virtualization, on the Internet. Amazon was the pioneer, offering SaaS and PaaS services worldwide from the year 2006. Again the heading link gives information in depth.
After a few years in 2011, the big giants like Microsoft, Google, and a variety of other big names began to realize that this was an industry starting to boom beyond all expectations, as more and more industries spread to the Internet for worldwide visibility. However, Amazon was the market leader by a big margin, since it had a five-year head start on the other tech giants. This led to unprecedented disruption across verticals, as more and more companies transferred their IT requirements to IaaS providers like Amazon, leading to (in some cases) savings of well over 25% and per-employee cost coming down by 30%.
After all, why should companies set up their own servers, data warehouse centres, development centres, maintenance divisions, security divisions, and software and hardware monitoring systems if there are companies that have the world’s best experts in every one of these sectors and fields that will do the job for you at less than 1% of the cost the company would incur if they had to hire staff, train them, monitor them, buy their own hardware, hire staff for that as well – the list goes on-and-on. If you are already a tech giant like, say Oracle, you have everything set up for you already. But suppose you are a startup trying to save every penny – and there and tens of thousands of such startups right now – why do that when you have professionals to do it for you?
There is a story behind how AWS got started in 2006 – I’m giving you a link, so as to not make this article too long:
OK. So now you may be thinking, so this is cloud computing and AWS – but what does it have to do with Big Data Speciality, especially for startups? Let’s answer that question right now.
A startup today has a herculean task ahead of them.
Not only do they have to get noticed in the big booming startup industry, they also have to scale well if their product goes viral and receives a million hits in a day and provide security for their data in case a competitor hires hackers from the Dark Web to take down their site, and also follow up everything they do on social media with a division in their company managing only social media, and maintain all their hardware and software in case of outages. If you are a startup counting every penny you make, how much easier is it for you to outsource all your computing needs (except social media) to an IaaS firm like AWS.
You will be ready for anything that can happen, and nothing will take down your website or service other than your own self. Oh, not to mention saving around 1 million USD$ in cost over the year!If you count nothing but your own social media statistics, every company that goes viral has to manage Big Data! And if your startup disrupts an industry, again, you will be flooded with GET requests, site accesses, purchases, CRM, scaling problems, avoiding downtime, and practically everything a major tech company has to deal with!
Bro, save your grey hairs, and outsource all your IT needs (except social media – that you personally need to do) to Amazon with AWS!
And the Big Data Speciality?
Having laid the groundwork, let’s get to the meat of our article. The AWS certified Big Data Speciality website mentions the following details:
The AWS Certified Big Data – Specialty exam validates technical skills and experience in designing and implementing AWS services to derive value from data. The examination is for individuals who perform complex Big Data analyses and validates an individual’s ability to:
Implement core AWS Big Data services according to basic architecture best practices
Design and maintain Big Data
Leverage tools to automate data analysis
So, what is an AWS Big Data Speciality certified expert? Nothing more than an internationally recognized certification that says that you, as a data scientist can work professionally in AWS and Big Data’s requirements in Data Science.
Please note: the eligibility criteria for an AWS Big Data Speciality Certification is:
Minimum five years hands-on experience in a data analytics field
Background in defining and architecting AWS Big Data services with the ability to explain how they fit in the data life cycle of collection, ingestion, storage, processing, and visualization
Experience in designing a scalable and cost-effective architecture to process data
To put it in layman’s terms, if you, the data scientist, were Priyanka Chopra, getting the AWS Big Data Speciality certification passed successfully is the equivalent of going to Hollywood and working in the USA starring in Quantico!
Suddenly, a whole new world is open at your feet!
But don’t get too excited: unless you already have five years experience with Big Data, there’s a long way to go. But work hard, take one step at a time, don’t look at the goal far ahead but focus on every single day, one day, one task at a time, and in the end you will reach your destination. Persistence, discipline and determination matters. As simple as that.
From whizlabs.org
Five Advantages of an AWS Big Data Speciality
1. Massive Increase in Income as a Certified AWS Big Data Speciality Professional (a long term 5 years plus goal)
Everyone who’s anyone in data science knows that a data scientist in the US earns an average of 100,000 USD$ every year. But what is the average salary of an AWS Big Data Speciality Certified professional? Hold on to your hat’s folks; it’s 160,000 $USD starting salary. And with just two years of additional experience, that salary can cross 250,000 USD$ every year if you are a superstar at your work. Depending upon your performance on the job! Do you still need a push to get into AWS? The following table shows the average starting salaries for specialists in the following Amazon products: (from www.dezyre.com)
Top Paying AWS Skills According to Indeed.com
AWS Skill
Salary
DynamoDB
$141,813
Elastic MapReduce (EMR)
$136,250
CloudFormation
$132,308
Elastic Cache
$125,625
CloudWatch
$121,980
Lambda
$121,481
Kinesis
$121,429
Key Management Service
$117,297
Elastic Beanstalk
$114,219
Redshift
$113,950
2. Wide Ecosystem of Tools, Libraries, and Amazon Products
From slideshare.net
Amazon Web Services, compared to other Cloud IaaS services, has by far the widest ecosystem of products and tools. As a Big Data specialist, you are free to choose your career path. Do you want to get into AI? Do you have an interest in ES3 (storage system) or HIgh-Performance Serverless computing (AWS Lambda). You get to choose, along with the company you work for. I don’t know about you, but I’m just writing this article and I’mseriouslyexcited!
3. Maximum Demand Among All Cloud Computing jobs
If you manage to clear the certification in AWS, then guess what – AWS certified professionals have by far the maximum market demand! Simply because more than half of all Cloud Computing IaaS companies use AWS. The demand for AWS certifications is the maximum right now. To mention some figures: in 2019, 350,000 professionals will be required for AWS jobs. 60% of cloud computing jobs ask for AWS skills (naturally, considering that it has half the market share).
4. Worldwide Demand In Every Country that Has IT
It’s not just in the US that demand is peaking. There are jobs available in England, France, Australia, Canada, India, China, EU – practically every nation that wants to get into IT will welcome you with open arms if you are an AWS certified professional. And look no further than this site. AWS training will be offered soon, here: on Dimensionless.in. Within the next six months at the latest!
5. Affordable Pricing and Free One Year Tier to Learn AWS
Amazon has always been able to command the lowest prices because of its dominance in the market share. AWS offers you a free 1 year of paid services on its cloud IaaS platform. Completely free for one year. AWS training materials are also less expensive compared to other offerings. The following features are offered free for one single year under Amazon’s AWS free tier system:
The following is a web-scrape of their free-tier offering:
AWS Free Tier One Year Resources Available
There were initially seven pages in the Word document that I scraped from www.aws.com/free. To really have a look, go to the website on the previous link and see for yourself on the following link (much more details in much higher resolution). Please visit this last mentioned link. That alone will show you why AWS is sitting pretty on top of the cloud – literally.
Final Words
Right now, AWS rules the roost in cloud computing. But there is competition from Microsoft, Google, and IBM. Microsoft Azure has a lot of glitches which costs a lot to fix. Google Cloud Platform is cheaper but has very high technical support charges. A dark horse here: IBM Cloud. Their product has a lot of offerings and a lot of potential. Third only to Google and AWS. If you are working and want to go abroad or have a thirst for achievement, go for AWS. Totally. Finally, good news, all Dimensionless current students and alumni, the languages that AWS is built on has 100% support for Python! (It also supports, Go, Ruby, Java, Node.js, and many more – but Python has 100% support).
Keep coming to this website – expect to see AWS courses here in the near future!
Ok. So there’s been a lot of coverage by various websites, data science gurus, and AI experts about what 2019 holds in store for us. Everywhere you look, we have new fads and concepts for the new year. This article is going to be rather different. We are going to highlight the dark horses – the trends that no one has thought about but will completely disrupt the working IT environment (for both good and bad – depends upon which side of the disruption you are on), in a significant manner. So, in order to give you a taste of what’s coming up, let’s go through the top four (plus 1 (bonus) = five) top trends of 2019 for data science:
AutoML
Interoperability (ONNX)
Cyber Data Science Crime
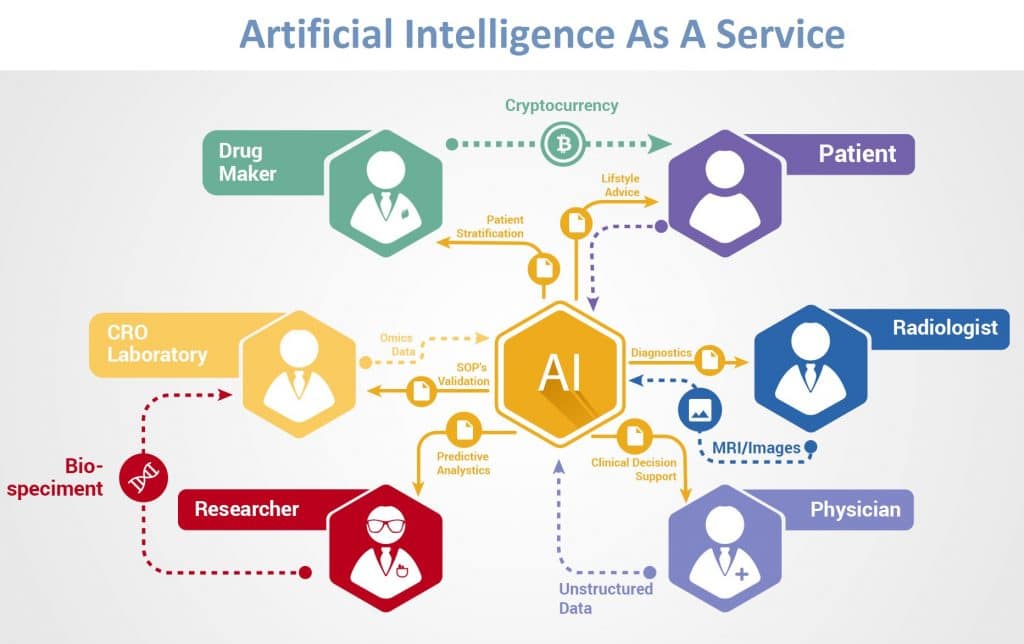
Cloud AI-as-a-Service
(Bonus) Quantum Computation & Data Science
1. AutoML (& AutoKeras)
Google AutoML Architecture From https://cloud.google.com/automl/
This single innovation is going to change the way machine learning works in the real world. Earlier, deep learning and even advanced machine learning was an aristocratic property of PhD holders and other research scientists. AutoML has changed that entire domain – especially now that AutoKeras is out.
AutoML automates machine learning. It chooses the best architecture by analyzing the data – through a technology called Neural Architecture Search (NAS), tries out various models and gives you the best possible hyperparameters for your scenario automatically! Now, this was priced at the ridiculous price of 76$ USD per hour, but we now have a free open source competitor, AutoKeras.
The open source killer of AutoML From https://www.pyimagesearch.com
AutoKeras is an open source free alternative to AutoML developed at University of Texas A & M DATA lab and the open source community. This project should make a lot of deep learning accessible to everyone on the planet who can code even a little. To give you an example, this is the code used to train an arbitrary image classifier with deep learning:
import autokeras as ak clf = ak.ImageClassifier() clf.fit(x_train, y_train) results = clf.predict(x_test )
Note:Of course, the entire training and testing process will take more than a day to complete at the very least, but less if you have some high-throughput GPUs or Google’s TPUs (Tensor Processing Units – custom hardware for data science computation) or plenty of money to spend on the cloud infrastructure computation resources of AutoML.
2. Interoperability (ONNX)
For those of you are new as to what interoperability means to neural networks – we now have several Deep Learning Neural Network Software Libraries competing with each other for market dominance. The most highly rated ones are:
TensorFlow
Caffe
Theano
Torch & PyTorch
Keras
MXNet
Chainer
CNTK
However, converting an artificial neural network written in CNTK (Microsoft Cognitive Tool Kit) to Caffe is a laborious task. Why can’t we simply have one single standard so that discoveries in AI can be shared with the public and with the open source community?
To solve this problem, the following standard has been proposed:
Open Neural Network Exchange Format
One Neural Network Standard over them all. From https://www.softwarelab.it
ONNX is a standard in which deep learning networks can be represented as a directed acyclic computation graph which is compatible with every deep learning framework available today (almost). Watch out for this release since if proper transparency is enforced, we could see decades worth of research happen in this single year!
3. Cyber Data Science Crime
There are allegations that the entire US elections conducted last year was a socially engineered manipulation of the US democratic process using data science and data mining techniques. The most incriminated product was Facebook, on which fake news were spread by Russian agents and the Russian intelligence forces, leading to an external agency deciding who the US president would be instead of the US people themselves. And yes, one of the major tools used was data science! So, this is not so much a new trend as an already existing phenomenon, one that needs to be recognized and dealt with effectively.
While this is a controversial trend or topic, it needs to be addressed. If the world’s most technologically advanced nation can be manipulated by its sworn enemies to elect a leader (Trump) that no one really wanted, then how much more easily can nations like India or the UK be manipulated as well?
This has already begun in a small way in India with BJP social media departments putting up pictures of clearly identifiable cities (there was one of Dubai) as cities in Gujarat on WhatsApp. This trend will not change any time soon. There needs to be a way to filter the truth from the lies. The threat comes not from information but from misinformation.
Are you interested in the elections? Then get involved in Facebook. What happened in the USA in 2018 could easily happen in India in 2019. The very fabric of democracy could break apart. As data scientists, we need to be aware of every issue in our field. And we owe it to the public – and to ourselves – to be honest and hold ourselves to the highest levels of integrity.
We could do more than thirty blog posts on this topic alone – but we digress.
To understand Cloud AI-as-a-Service, we need to know that maintaining an AI in-house analytics solution is overkill as far as most companies are concerned. It is so much easier to outsource the construction, deployment and maintenance costs of an AI system to a company that provides it online at a far lesser cost than what the effort and difficulty would be otherwise in maintaining and updating an in-built version that has to be managed by a separate department with some very hard-to-find and esoteric skills. There are so many start-ups in this area alone over the last year (over 100) that to list all of them would be a difficult task. Of course, as usual, all the big names are extremely involved.
This is a trend that has already manifested, and will only continue to grow in popularity. There are already a number of major players in this AI as a Service offering including but not limited to Google, IBM, Amazon, Nvidia, Oracle, and many, many more. In this upcoming year, companies without AI will fall and fail spectacularly. Hence the importance of keeping AI open to the public for all as cheaply as possible. What will be the end result? Only time will tell.
5. Quantum Computing and AI (Bonus topic)
Quantum Computing is very much an active research topic as of now. And the country with the greatest advances is not the US, but China. Even the EU has invested over 1 Billion Euros in its quest to build a feasible quantum computer. A little bit of info about quantum computing, in 5 crisp points:
It has the potential to become the greatest quantum leap since the invention of the computer itself. (pun intended)
However, practical hardware difficulties have kept quantum computers constructed so far as laboratory experiments alone.
If a quantum computer that can manipulate 100-200 qubits (quantum bits) is built, every single encryption algorithm used today will be broken quite easily.
The difficulty in keeping single atoms in isolated states consistently (decoherence) makes current research more of an academic choice.
Experts say a fully functional quantum computer could be 5-15 years away. But, also, it would herald a new era in the history of mankind.
In fact, the greatest example of a quantum computer today is the human brain itself. If we develop quantum computing to practical levels, we could also gain the information to create a truly intelligent computer.
Cognition in real world AI that is self-aware. How awesome is that?
So there you have it. The five most interesting and important trends that could become common in the year 2019 (although the jury will differ on the topic of the quantum computer – it could work this year or ten years from now – but it’s immensely exciting).
What are your thoughts? Do you find any of these topics worth further investigation? Feel free to comment and share!
For additional information, I strongly recommend the articles given below: