
source: SlideShare
Technology has seen advancing rapidly in the last few years and so is the amount the data that is getting generated. There are a plethora of sources which generates unstructured data that carries a huge amount of information if mined correctly. These varieties of voluminous data are known as the Big Data which traditional computers or storage systems are incapable to handle.
To mine big data, the concept of parallel computing or clusters came into place popularly known as the Hadoop. Hadoop has several components which not only stores the data in the form of clusters but processes them in parallel as well. The HDFS or the Hadoop storage file system stores the big data while using the Map Reduce technique the data is processed.
However, most applications nowadays generate data in real-time which requires real-time analysis. Hadoop doesn’t allow real-time data storage or analysis as the data is processed in batches in Hadoop. To resolve such instances, Apache introduced Spark which is faster than Hadoop and allows data to be processed in real time. More and more companies have since transitioned from Hadoop to Spark as their application depends on real-time data analytics. You could also perform Machine Learning operations on Spark using the MLlib library.
The computation in spark is done in memory, unlike Hadoop which relies on disk for computation. It is an elegant and expressive development application programming interface which allows fast and efficient SQL and ML operations on iterative datasets. Applications could be created everywhere and the power of Spark could be exploited as Spark runs on Apache Hadoop YARN. Within a single dataset in Hadoop, insights could be derived and the data science workloads could be enriched.
A common cluster could be shared by Spark and other applications by maintaining service and response consistency which is a foundation provided by the Hadoop YARN-based architecture. Working with YARN in HDP, one of the many data access engines now is Spark. A Spark Core and other libraries are present in the Apache Spark.
The abstraction in Spark makes data science easier. Machine Learning is a technique where algorithms learn from data. The data processing speeds up by caching the dataset by Spark which is ideal for implementing such algorithms. To model an entire Data Science workflow, a high-level abstraction is provided by Spark’s Machine Learning Pipeline API. Abstractions like Transformer, Estimator, and so on are provided by the Spark’s Machine Learning pipeline package which increases the productivity of a Data Scientist.
So far we have discussed Big Data and how it could be processed using Apache Spark. However, to run Apache Spark applications, proper infrastructure needs to be in place and thus Amazon EMR provides a platform to manage applications built on Apache Spark.
Managing Spark Applications on Amazon EMR
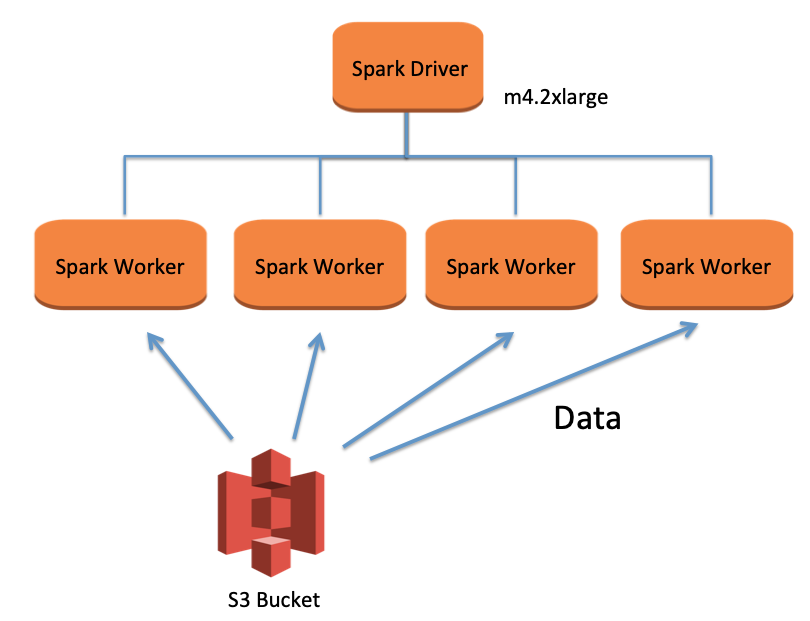
source: medium
Amazon EMR is one of the most popular cloud-based solutions to extract and analyze huge volumes of data from a variety of sources. On AWS, frameworks such as Apache Hadoop and Apache Spark could be run with the help of the Amazon EMR. In the matter of a few minutes, with the help of multiple instances, organizations could spin up a cluster which is enabled by the Amazon EMR. Through parallel processing, various data engineering and business intelligence workloads to be processed which reduces effort, cost, and time of the data processing involved in setting up the cluster.
As Apache Spark is a fast, an open-source framework, it is used in the processing of the big data. To reduce I/O, in memory across nodes, Apache Spark performs parallel computing in memory and thus the reliability of cluster memory (RAM) is heavy. On Amazon EMR, to run a Spark application, the following steps need to be performed –
- To the Amazon S3, the Spark application package is uploaded.
- With the configured Apache Spark, the Amazon EMR cluster is configured and launched.
- Onto the cluster, from the Amazon S3, the application package is installed and then the application is run.
- After the application is completed, the cluster is terminated.
For a successful operation, based on the data and processing requirements, the Spark application needs to be configured. There could be memory issues if Spark is configured with the default settings. Below are some of the memory errors occurs while maintaining Apache Spark on Amazon EMR in a default setting.
- The loss of memory error when the Java Heap space is not empty – lang.OutOfMemoryError: Java heap space
- When the physical memory exceeds, you get the out of memory error – Error: ExecutorLostFailure Reason: Container killed by YARN for exceeding limits
- If the Virtual memory is exceeded, you would also get the out of memory error.
- The Executor memory also gives the out of memory error if it’s exceeded.
Some of the reasons why these issues occur are –
- While handling large volumes of data, due to the inappropriate settings of the number of cores, executor memory, or the number of Spark executor instances.
- The memory allocated by YARN is exceeded by the Spark executor’s physical memory. In such cases, to handle memory intensive operations, the memory of the Spark executor and the overhead together is not enough.
- In the Spark executor instance, to handle operations like garbage collection, enough memory is not present.
Below are the ways in which Amazon Spark could be successfully configured and maintained on Amazon EMR.
Based on the needs of the application, the number of instances and type should be determined. There are three types of nodes in the Amazon EMR –
- The master acts as the resource manager.
- The Core nodes which are managed by the master that executes tasks and manages storage.
- The Task which performs only tasks but no storage.
The right instance type should be chosen based on the application whether it is memory intensive or compute intensive. The R-type instances are preferred for the memory intensive applications while the C-Type instances are preferred for the compute-intensive applications. For each node types, the number of instances are decided after the type of the instance is decided. The number is dependent on the frequency requirements, the execution time of the application, and the input dataset size.
The Spark Configuration parameters need to be determined. Below is the diagram representing the executor container memory.
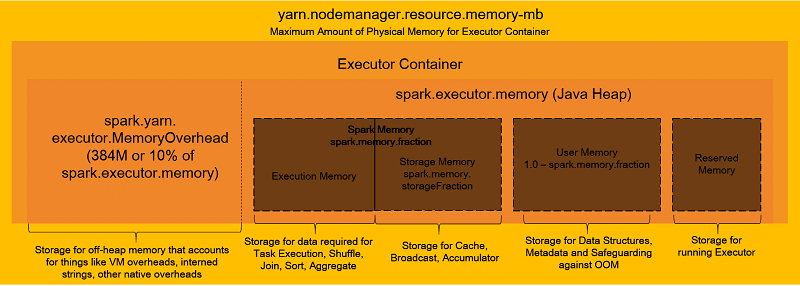
source: Amazon Web Services
There are multiple memory compartments in the executor container. However, for task execution, only one is used and for seamlessly running of the task, these need to be configured properly.
Based on the task and core instance types, the values for the Spark parameters are automatically set by the in spark-defaults. The maximize resource allocation is set to True to use all the resources in the cluster. Based on the workloads, the number of executors used could be dynamically scaled by Spark on YARN. In an application, to use the right number of executors, in most cases, the sub-properties are required which requires a lot of trial and error. These could often lead to the wastage of memory if the trial and error are not right.
- Memory should be effectively cleared with the implementation of a proper garbage collector. In certain cases, out of memory error could occur due to the garbage collection especially when in the application, there are multiple RDDs. between the RDD cached memory and the task memory, when there is an interference, such instances might occur. Multiple garbage collectors could be used and in the memory, the new ones could be placed. However, the latency is overcome by the latest Garbage First Garbage Collector (G1GC).
- The configuration parameters of YARN should be set. As the operating system bumps up the virtual memory aggressively, the virtual out of memory could still occur, even if all properties of Spark are configured correctly. The virtual memory and the physical memory check flag should be set to False to prevent such application failures.
- Monitoring and Debugging should be performed. With the verbose option, the spark-submit should be run and the Spark configuration details could be known. To monitor Network I/O, the application progress, Spark UI and Ganglia could be used. A Spark application could process ten terabytes of data successfully if it is configured using 170 executor instances, 37GB memory, eight terabytes of RAM, five virtual CPUs, a twelve times large master and core nodes and 1700 equaled parallelism.
Conclusion
Apache Spark is being used by most industries these days and thus building a flawless application using Spark is a necessity which could help the business in their day to day activities.
Amazon EMR is one of the most popular cloud-based solutions to extract and analysis huge volumes of data from a variety of sources. On AWS, frameworks such as Apache Hadoop and Apache Spark could be run with the help of the Amazon EMR. This blog post covered various memory errors, the causes of the errors and how to prevent them when running Spark applications on Amazon EMR.
Dimensionless has several blogs and training to get started with Python, and Data Science in general.
Follow this link, if you are looking to learn more about data science online!
Additionally, if you are having an interest in learning AWS Big Data Course, Learn AWS Course Online
Furthermore, if you want to read more about data science, you can read our blogs here
Also Read:

;" src="https://dimensionless.in/how-to-visualize-aws-cost-and-usage-data-using-amazon-athena-and-quicksight/embed/#?secret=xiGKHEcFlj" data-secret="xiGKHEcFlj" width="600" height="338" title="“How to Visualize AWS Cost and Usage Data Using Amazon Athena and QuickSight” — DIMENSIONLESS TECHNOLOGIES PVT.LTD." frameborder="0" marginwidth="0" marginheight="0" scrolling="no"></iframe>)