
Introduction
Data science is one of the hottest topics in the 21st century because we are generating data at a rate which is much higher than what we can actually process. A lot of business and tech firms are now leveraging key benefits by harnessing the benefits of data science. Due to this, data science right now is really booming.
In this blog, we will deep dive into the world of machine learning. We will walk you through machine learning basics and have a look at the process of building an ML model. We will also build a random forest model in python to ease out the understanding process.
What is Machine Learning?
Machine Learning is the science of getting computers to learn and act like humans do, and improve their learning over time in an autonomous fashion, by feeding them data and information in the form of observations and real-world interactions.
There are many different types of machine learning algorithms, with hundreds published each day, and they’re typically grouped by either learning style (i.e. supervised learning, unsupervised learning, semi-supervised learning) or by similarity in form or function (i.e. classification, regression, decision tree, clustering, deep learning, etc.). Regardless of learning style or function, all combinations of machine learning algorithms consist of the following:
- Representation (a set of classifiers or the language that a computer understands)
- Evaluation (aka objective/scoring function)
- Optimization (search method; often the highest-scoring classifier, for example; there are both off-the-shelf and custom optimization methods used)
Steps for Building ML Model
Here is a step-by-step example of how a hospital might use machine learning to improve both patient outcomes and ROI:
1. Define Project Objectives
The first step of the life cycle is to identify an opportunity to tangibly improve operations, increase customer satisfaction, or otherwise create value. In the medical industry, discharged patients sometimes develop conditions that necessitate their return to the hospital. In addition to being dangerous and troublesome for the patient, these readmissions mean the hospital will spend additional time and resources on treating patients for the second time.
2. Acquire and Explore Data
The next step is to collect and prepare all of the relevant data for use in machine learning. This means consulting medical domain experts to determine what data might be relevant in predicting readmission rates, gathering that data from historical patient records, and getting it into a format suitable for analysis, most likely into a flat file format such as a .csv.
3. Model Data
In order to gain insights from your data with machine learning, you have to determine your target variable, the factor of which you are trying to gain a deeper understanding. In this case, the hospital will choose “readmitted,” which is included as a feature in its historical dataset during data collection. Then, they will run machine learning algorithms on the dataset that build models that learn by example from the historical data. Finally, the hospital runs the trained models on data the model hasn’t been trained on to forecast whether new patients are likely to be readmitted, allowing it to make better patient care decisions.
4. Interpret and Communicate
One of the most difficult tasks of machine learning projects is explaining a model’s outcomes to those without any data science background, particularly in highly regulated industries such as healthcare. Traditionally, machine learning has been thought of as a “black box” because of how difficult it is to interpret insights and communicate their value to stakeholders and regulatory bodies alike. The more interpretable your model, the easier it will be to meet regulatory requirements and communicate its value to management and other key stakeholders.
5. Implement, Document, and Maintain
The final step is to implement, document, and maintain the data science project so the hospital can continue to leverage and improve upon its models. Model deployment often poses a problem because of the coding and data science experience it requires, and the time-to-implementation from the beginning of the cycle using traditional data science methods is prohibitively long.
Problem Statement
A certain car manufacturing company X is looking to target its customers for their particular car model. Customers are identified by their age, salary, and Gender. The organisation wants to identify or predict which customers will affect the sales of their new car and actually purchase it.
We have a purchased column here which holds two values i.e 0 and 1. 0 indicates that the car has not been purchased by a certain individual. 1 indicates the sale of the car.
Code Implementation
Importing the Required Libraries
You need to import all the required libraries first which will ease the model building parts for us. We are using keras to build our random forest model. We are using the matplotlib library to plot the charts and graphs and visualise results. In the end, we are also importing functions from the sklearn module which can help us in splitting our data into training and testing parts
# Importing the libraries import numpy as np import matplotlib.pyplot as plt import pandas as pd from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier
Loading the Dataset
In this step, you need to load your dataset in the memory. After that, we separate out the dependent and the independent variables for the training of our classifier. In most of the cases, you need to separate the dependent and he the independent variables
# Importing the dataset
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, [2, 3]].values
y = dataset.iloc[:, 4].values
Splitting the Dataset to Form Training and Test Data
In all the cases, you need to make some partitions in your data. A major chunk of your data acts as a training set and a smaller chunk acts as a test set. There are no clearly defined criteria on the proportion of the training and the test set. But most people follow 70–30 or 75–25 rule where a larger chunk is your training set. We train the data on the training set and test it on the test set. This process is known as validation. The prime idea behind this purpose is that one needs to gauge the performance of the model on the data which model has never seen before. In the real-world scenarios, the model will be predicting values on the unseen data. Furthermore, techniques like validation help us in avoiding overfitting or underfitting the model.
Overfitting refers to the case when our model has learnt all about the specific data on which it trained. It will work well on the training data but will have poor accuracy for any unseen data point. Overfitting is like your model is very specific to the data it has and has no generality. Similarly, underfitting is the case where your model is very general and is not able to predict well for your specific use-case. To achieve the best model accuracy, you need to strike a perfect balance between overfitting and under-fitting.
# Splitting the dataset into the Training set and Test set from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
Standardising the Dataset Values
from sklearn.preprocessing import StandardScaler sc = StandardScaler() X_train = sc.fit_transform(X_train) X_test = sc.transform(X_test)
Fitting a Random Forest Classifier
In this case, we are fitting our model with the training data. We are using the random forest model exposed by the sklearn package in python. Ultimately, we pass the dependent and independent features separately through which our model makes an internal mapping between them using mathematical coefficients.
# Fitting Random Forest Classification to the Training set from sklearn.ensemble import RandomForestClassifier classifier = RandomForestClassifier(n_estimators = 10, criterion = 'entropy', random_state = 0) classifier.fit(X_train, y_train)
Predicting Results from the Classifier
In this part, we are passing unseen values to our model on which it is making predictions. We use a confusion matrix to derive metrics like accuracy, precision, and recall for our model. These metrics help us to understand the performance of the model.
# Predicting the Test set results y_pred = classifier.predict(X_test) # Making the Confusion Matrix from sklearn.metrics import confusion_matrix cm = confusion_matrix(y_test, y_pred)
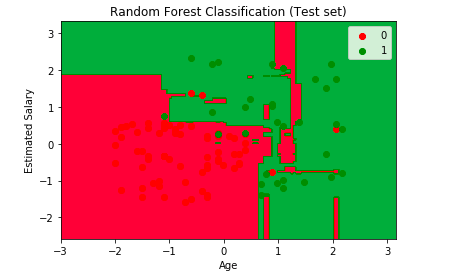
Visualising the Predictions
Additionally, we have made an attempt to visualise the predictions of our model using the below code.
# Visualising the Test set results
# Visualising the Test set results
from matplotlib.colors import ListedColormap
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('Random Forest Classification (Test set)')
plt.xlabel('Age')
plt.ylabel('Estimated Salary')
plt.legend()
plt.show()
Summary
Hence, in this Machine Learning Tutorial, we studied the basics of ML. Earlier machine learning was the theory that computers can learn without being programmed to perform specific tasks. But now, the researchers interested in artificial intelligence wanted to see if computers could learn from data. They learn from previous computations to produce reliable decisions and results. It’s a science that’s not new — but one that’s gaining fresh momentum.
Follow this link, if you are looking to learn more about data science online!
You can follow this link for our Big Data course!
Additionally, if you are having an interest in learning Data Science, click here to start Best Online Data Science Courses
Furthermore, if you want to read more about data science, you can read our blogs here
