
source: Amazon Web Services
It is said that most of the modern-day data have been generated in the past few years. The advancement in technology and the growth of the internet is the source of such voluminous unstructured data which is rapidly changing the dynamics of our daily lives. No wonder, Prof. Andrew NG said – ‘Data is the new electricity’.
Introduction
We refer to such data which exhibits the properties such as volume, variety, veracity, and value as Big Data. Big Data Developers has built several architectures to get the best out of this big data. Two such frameworks are Hadoop and Spark.
In this blog post, I would provide a brief about Apache Spark and Amazon EMR and then we would learn how memory of an Apache Spark application could be managed on Amazon EMR.
What is Apache Spark?
Though Hadoop was the most popular Big Data framework built, it lacked the real time data processing capabilities which Spark provides. Unlike in Hadoop, Spark uses both memory and disk for data processing.
The applications in Spark are written mainly in Scala, Java, Python. Other libraries like SQL, Machine Learning, Spark Streaming, and so on are also included. It makes Spark flexible for a variety of use cases.
Many big organizations have incorporated Spark in their application to speed up the data engineering process. It has a directly acyclic graph which boosts performance. A detailed description of the architecture of Spark is beyond the scope of this article.
What is Amazon EMR?
The processing and analysis of Big data in Amazon Web Services is done with the help of a tool known as the Amazon Elastic Map Reduce. As an alternative to in-house cluster computing, an expandable low configuration service is provided by Amazon EMR.
On Apache Hadoop, the Amazon EMR is based upon and across the Hadoop cluster on Amazon EC2 and Amazon S3, the big data is processed. The dynamic resizing ability is referred to by the elastic property which allows flexible usage of resources based on the needs.
In the scientific simulation, data warehousing, financial analysis, machine learning, and so on, the Amazon EMR is used for data analysis. The Apache Spark based workloads are also supported by it which we would see later in this blog.
Managing Apache Spark Application Memory on Amazon EMR
As mentioned earlier, the running of the big data frameworks like Hadoop, Spark, etc., are simplified by the Amazon EMR. ETL or Extract Transform Load is one of the common use cases in the modern world to generate insights from data and one of the best cloud solutions to analyse data is Amazon EMR.
Through parallel processing, various business intelligence and data engineering workloads managed using Amazon EMR. It reduces time, effort, and costs that is involved in scaling and establishing a cluster.
In the distributed processing of big data, a fast, open source framework known as Apache Spark is widely used which relies on RAM performing parallel computing and reducing the input output time. On Amazon EMR, to run a Spark application below steps are performed.
- To Amazon S3, the Spark application package is uploaded.
- The Amazon EMR cluster is configured and launched with Apache Spark.
- From Amazon S3, the application package is installed onto the cluster and the application is ran.
- The cluster is terminated post the completion of the application.
Based on the requirements, the Spark application needs to be configured appropriately. There could be virtual and physical issues if the default settings are kept. Below are of the memory related issues in Apache Spark.
- Exceeding physical memory – When limits are exceeded, YARN kills the container and throws an error message: Executor Lost Failure: 4.5GB of 3GB physical memory used limits. It would even ask you to boost spark.yarn.executor.memoryOverhead.
- Exceeding virtual memory – If the virtual memory exceeds, Yarn kills the container.
- Java Heap Space – This is a very common memory issue that we face when the Java Heap Space is out of memory. The error message thrown is java.lang.OutOfMemoryError.
- Exceeding Executor memory – When the executor memory required is above a threshold, we get an out of memory error.
Some of the reasons why the above reasons occur are –
- Due to the inappropriate setting of the executor memory, executor instances, the number of cores, and so on to handle large volumes of data.
- When the YARN allocated memory is exceeded by the Spark executor’s physical memory which creates issues while handling memory intensive operations.
- In the Spark executor instance, when memory is not available to perform operations like garbage collection and so on.
On Amazon EMR, to successfully configure a Spark application, the following steps should be performed.
Step 1: Based on the application needs, the number and the type of instances should be determined
There are three types of nodes in Amazon EMR.
- The one master node which manages the cluster and acts as a resource manager.
- The master node manages the core nodes. The Map-Reduce tasks, the Node Manager daemons are run by the core nodes which executes tasks, manages storage, and sends a report back to the master which gives information about its activeness.
- The task node which only performs but doesn’t save the data.
The R-type instances are preferred for memory-based applications while the C type of instances is preferable for compute-intensive applications. The M-type instances provides a balance between compute and memory applications. The number of instances following the selection of the instance type is done based on the execution time of the application, input data sets, and so on.
Step 2: Determining the configuration parameters of Spark
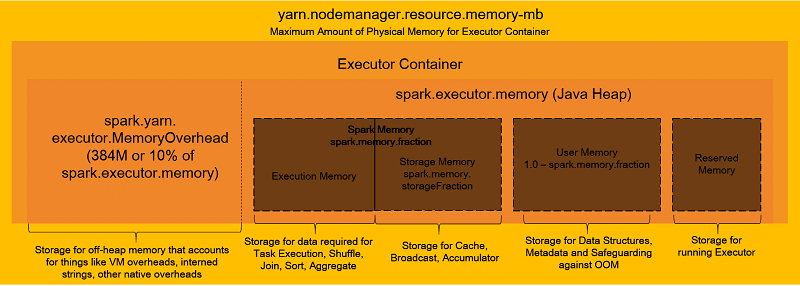
source: AWS
There are multiple memory compartments in the Spark executor container among which the only one executes the task. Some of the parameters which need to be configured efficiently are –
- For each executor, the size of memory that is required to run the task represented by spark.executor.memory. The formula for executor memory is given by the total per instance RAM divided by the per-instance executor’s number.
- The number of virtual cores given by spark.executor.cores. A large number of virtual cores leads to reduced parallelism while vice versa results in high I/O operations. Thus, five virtual cores are optimal.
- The driver memory size – spark.driver.memory. This should be equal to the spark.executor.memory.
- The driver’s virtual cores number – spark.driver.cores. Setting its value equal to the spark.executor.core is recommended.
- The executor’s number – spark.executor.instances. This is calculated by multiplying per instance number of executors with the core instances and subtracting one from the product.
- In RDD, the default number of partitions – spark.default.parallelism. To set its value, multiply spark.executor.instances with spark.executor.cores and two.
Some of the parameters which need to be set in the default configuration file to avoid memory and time-out related issues are.
- All network transactions timeout – spark.network.timeout.
- Each executor’s heartbeats interval – spark.executor.heartbeatInterval.
- To save space by compressing the RDDs, the spark.rdd.compress property is set to True.
- To compress the data during shuffles, spark.shuffle.compress is set to true.
- For joins and aggregations, the number of partitions is set by spark.sql.shuffle.partitions.
- The map output is compressed by setting spark.shuffle.compress to True.
Step 3: To clear memory, a garbage collector needs to be implemented
In certain scenarios, out-of-memory errors is led by the garbage collection. In the application, when there are multiple RDDs, such cases would occur. An interference between RDD cached memory and task execution memory would also lead to such cases.
To replace old objects with new in the memory, multiple garbage collectors could be used. The limitations with the old garbage collector could be overcome with the Garbage First Garbage Collector.
Step 4: The Configuration parameters of YARN
The YARN site setting should be set accordingly to prevent virtual-out-of-memory errors. The physical and virtual memory flag should be set to False.
Step 5: Monitoring and debugging should be performed
To monitor the progress of the Spark application Network I/O, etc., the Spark UI and Ganglia should be used. To manage 10 terabytes of data successfully in Spark, we need at least 8 terabytes of RAM, 170 instances of executor, 37 GB of executor per memory, the total virtual CPU’s of 960, 1700 parallelism, and so on.
The default configurations of Spark could lead to out of physical memory error as the configurations are incapable of processing 10 terabytes of data. Moreover, the memory is not cleared efficiently by the default garbage collectors leading to failures quite often.
The future of Cloud
Technology is gradually moving from traditional infrastructure set up to an all cloud-based environment. Amazon Web Services is certainly a frontrunner in cloud services which lets you build and deploy scalable applications at a reasonable cost. It also ensures payment for only those services which are required.
As the size of the data would increase exponentially in the future, it is pertinent that companies and employees master learn the art of using cloud platforms like AWS to build robust applications.
Conclusion
Apache Spark is one of the most sought-after big frameworks in the modern world and Amazon EMR undoubtedly provides an efficient means to manage applications built on Spark.In this blog post, we learned about the memory issues in an Apache Spark application and the measures taken to prevent it.
If you are willing to learn more about Big Data or Data Science in general, follow the blogs and courses of Dimensionless.
Follow this link, if you are looking to learn more about data science online!
Additionally, if you are having an interest in learning Data Science, Learn online Data Science Course to boost your career in Data Science.
Furthermore, if you want to read more about data science, you can read our blogs here