With the growth of Data science in recent years, we have seen a growth in the development of the tools for it. R and Python have been steady languages used by people worldwide. But before R and Python, there was only one key player and it was MATLAB. MATLAB is still in usage in most of the academics areas and mostly all the researchers throughout the world use MATLAB.
In this blog, we will look at the reasons why MATLAB is a good contender to R and Python for Data science. Furthermore, we will discuss different courses which offer data science with MATLAB.
What is MATLAB?
MATLAB is a high-performance language for technical computing. It integrates computation, visualization, and programming in an easy-to-use environment where problems and solutions are expressed in familiar mathematical notation.
It is a programming platform, specifically for engineers and scientists. The heart of MATLAB is the MATLAB language, a matrix-based language allowing the most natural expression of computational mathematics.
Typical uses include:
Math and computation
Algorithm development
Modelling, simulation, and prototyping
Data analysis, exploration, and visualization
Scientific and engineering graphics
Application development, including Graphical User Interface building
The language, apps, and built-in math functions enable you to quickly explore multiple approaches to arrive at a solution. MATLAB lets you take your ideas from research to production by deploying to enterprise applications and embedded devices, as well as integrating with Simulink® and Model-Based Design.
Features of MATLAB
Following are the basic features of MATLAB −
It is a high-level language for numerical computation, visualization and application development
Provides an interactive environment for iterative exploration, design and problem-solving.
Holds a vast library of mathematical functions for linear algebra, statistics, Fourier analysis, filtering, optimization, numerical integration and solving ordinary differential equations.
It provides built-in graphics for visualizing data and tools for creating custom plots.
MATLAB’s programming interface gives development tools for improving code quality maintainability and maximizing performance.
It provides tools for building applications with custom graphical interfaces.
It provides functions for integrating MATLAB based algorithms with external applications and languages such as C, Java, .NET and Microsoft Excel.
Why Use MATLAB in Data Science?
Physical-world data: MATLAB has native support for the sensor, image, video, telemetry, binary, and other real-time formats. Explore this data using MATLAB MapReduce functionality for Hadoop, and by connecting interfaces to ODBC/JDBC databases.
Machine learning, neural networks, statistics, and beyond: MATLAB offers a full set of statistics and machine learning functionality, plus advanced methods such as nonlinear optimization, system identification, and thousands of prebuilt algorithms for image and video processing, financial modelling, control system design.
High-speed processing of large data sets. MATLAB’s numeric routines scale directly to parallel processing on clusters and cloud.
Online and real-time deployment: MATLAB integrates into enterprise systems, clusters, and clouds, and can be targeted to real-time embedded hardware.
Also, MATLAB finds its features available for the entire data science problem-solving journey. Let us have a look at how MATLAB fits in every stage of a data science problem pipeline
1. Accessing and Exploring Data
The first step in performing data analytics is to access the wealth of available data to explore patterns and develop deeper insights. From a single integrated environment, MATLAB helps you access data from a wide variety of sources and formats like different databases, CSV, audio, video etc
2. Preprocessing and Data Munging
When working with data from numerous sources and repositories, engineers and scientists need to preprocess and prepare data before developing predictive models. For example, data might have missing values or erroneous values, or it might use different timestamp formats. MATLAB helps you simplify what might otherwise be time-consuming tasks such as cleaning data, handling missing data, removing noise from the data, dimensionality reduction, feature extraction and domain analysis such as videos/audios.
3. Developing Predictive Models
Prototype and build predictive models directly from data to forecast and predict the probabilities of future outcomes. You can compare machine learning approaches such as logistic regression, classification trees, support vector machines, and ensemble methods, and use model refinement and reduction tools to create an accurate model that best captures the predictive power of your data. Use flexible tools for processing financial, signal, image, video, and mapping data to create analytics for a variety of fields within the same development environment.
4. Integrating Analytics with Systems
Integrate analytics developed in MATLAB into production IT environments without having to recode or create custom infrastructure. MATLAB analytics can be packaged as deployable components compatible with a wide range of development environments such as Java, Microsoft .NET, Excel, Python, and C/C++. You can share standalone MATLAB applications or run MATLAB analytics as a part of the web, database, desktop, and enterprise applications. For low latency and scalable production applications, you can manage MATLAB analytics running as a centralized service that is callable from many diverse applications.
People these days use MATLAB only when they need to create a quick prototype and then for doing trial and error for validating a fresh concept. The real implementation will never be made with MATLAB but with python, c++ or a similar language. In my opinion MATLAB and python (or python libs) serve for different purposes. Scripting is just one feature out of thousands of features in MATLAB but it is the only feature in python. People use both python and MATLAB scripts where in some other faculties people rely on only MATLAB toolboxes with zero scripting. Hence both python and MATLAB will exist in future but most probably the usage of MATLAB “outside” may be reduced. MATLAB will exist until we have a better alternative of it.
Summary
MATLAB provides a lot of inbuilt utilities which one can directly apply in data science. Furthermore, MATLAB today finds it’s heavy usage in the field of academics and research. Although languages like R and Python are dominating data science worldwide, they are no way near to the simplicity level which MATLAB has to offer. Also, MATLAB will go a long way in the field of data science in the years to come. Additionally, learning MATLAB will be a great bonus for those who are willing to pursue a career in research!
Also, follow this link, if you are looking to learn more about data science online!
Python and R have been around for well over 20 years. Python was developed in 1991 by Guido van Rossum, and R in 1995 by Ross Ihaka and Robert Gentleman. Both Python and R have seen steady growth year after year in the last two decades. Will that trend continue, or are we coming to an end of an era of the Python-R dominance in the data science segment? Let’s find out!
Python
Python in the last decade has grown from strength to strength. In 2013, Python overtook R as the most popular language used fordata science, according to the Stack Overflow developer survey (Link).
In the last three years, Python was the most wanted language according to this survey (25% in 2018, JavaScript was second with 19%). It is by far the easiest programming language to learn, the Julia and the Go programming languages being honorable mentions in this regard.
Python shines in its versatility, being easy to use for data science, web development, utility programming, and as a general-purpose programming language. Even full-stack development can be done in Python, the only area where it is not used being mobile (although that may change if the Kivy mobile programming framework comes of age and stops stalling all the time). It was also ranked higher than JavaScript in the most loved programming languages for the last three years (Node.js and React.js have ranked below it consistently).
Will Python’s Dominance Continue?
We believe, yes, definitely. Two words – data science.
From https://www.digitaldesignjournal.com
Data science is such a hot and happening field right now, and the data scientist job is hyped as the ‘sexiest job of the 21st century‘, according to Forbes. Python is by far the most popular language for data science. The only close competitor is R, which Python overtook in the KDNuggets data science survey of 2016 . As shown in the link, in 2018, Python held 65.6% of the data science market, and R was actually below RapidMiner, at 48.5%. From the graphs, it is easy to see that Python is eating away at R’s share in the market. But why?
Deep Learning
In 2018, we say a huge push towards advancement across all verticals in the industry due to deep learning. And what is the most famous tool for deep learning? TensorFlow and Keras – both Python-based frameworks! While we have Keras and TensorFlow interfaces in R and RStudio now, Python was the initial choice and is still the native library – kerasR and tensorflow in RStudio being interfaces to the Python packages. Also, a real-life implementation of a deep learning project contains more than the deep learning model preparation and data analysis.
There is the data preprocessing, data cleaning, data wrangling, data preparation, outlier detection and missing data values management section which is infamous for taking up 99% of the time of a data scientist, with actual deep learning model work taking just 1% or less of their on-duty time! And what language is used for this commonly? For general purpose programming, Python is the goto language in most cases. I’m not saying that R doesn’t have data preprocessing packages. I’m saying that standard data science operations like web scraping are easier in Python than in R.And hence Python will be the language used in most cases, except in the statistics and the university or academic fields.
Our prediction for Python – growth – even to 70% of the data science market as more and more research-level projects like AutoML keep using Python as a first language of choice.
What About R?
In 2016, the use of R for data science in the industry was 55%, and Python stood at 51%. Python increased by 33% and R decreased by 25% in 2 years. Will that trend continue and will R continue on its downward spiral? I believe perhaps in figures, but not in practice. Here’s why.
Data science is at its heart, the field of the statistician. Unless you have a strong background in statistics, you will be unable to process the results of your experiments, especially in concepts like p-values, tests of significance, confidence intervals, and analysis of experiments. And R is the statistician’s language.Statistics and mathematics students will always find working in R remarkably easy and simple, which explains its popularity in academia. R programming lends itself to statistics. Python lends itself to model building and decent execution performance (R can be 4x slower). R, however, excels in statistical analysis. So what is the point that I am trying to express?
Simple – Python and R are complementary. They are best used together. You will find that knowledge of both Python and R will suit you best for most projects. You need to learn both. You can find this trend expressed in every article that speaks about becoming a data science unicorn – knowledge of both Python and R is required as a norm.
Yes, R is having a downturn in popularity. However, due to the complementary nature of the tools, I believe that R will have a part to play in the data scientist’s toolbox, even if it does dip a bit in growth in the years to come. Very simply, R is too convenient for a statistician to be neglected by the industry completely. It will continue to have its place in the toolbox. And yes; deep learning is now practical in R with support for Keras and AutoML as well as of right now.
Dimensionless Technologies
Dimensionless Technologies
Dimensionless Technologies is the market leader as far as training in AI, cloud, deep learning and data science in Python and R is concerned. Of course, you don’t have to spend 40k for a data science certification, you could always go for its industry equivalent – 100-120 lakhs for a US university’s Ph.D. research doctorate! What Dimensionless Technologies has as an advantage over its closest rival – (Coursera’s John Hopkins University’s Data Science Specialization) – is:
Live Video Training
The videos that you get on Coursera, edX, Dataquest, MIT OCW (MIT OpenCourseWare), Udacity, Udemy, and many other MOOCs have a fundamental flaw – they are NOT live! If you have a doubt in a video lecture, you only have the comments as a communication tool to the lectures. And when over 1,000 students are taking your class, it is next to impossible to respond to every comment. You will not and cannot get personalized attention for your doubts and clarifications. This makes it difficult for many, especially Indian students who may not be used to foreign accents to have a smooth learning curve in the popular MOOCs available today.
Try Before You Buy Fully
Dimensionless Technologies offers 20 hours of the course for Rs 5000, with the remaining 35k (10k of 45k waived if you qualify for the scholarship) payable after 2 weeks / 20 hours of taking the course on a trial basis. You get to evaluate the course for 20 hours before deciding whether you want to go through the entire syllabus with the highly experienced instructors who are strictly IIT alumni.
Instructors with 10 years Plus Industry Experience
In Coursera or edX, it is more common for Ph.D. professors than industry experienced professionals to teach the course. If you are good with American accents and next to zero instructor support, you will be able to learn a little bit about the scholastic side of your field. However, if you want to prepare for a 100K USD per year US data scientist job, you would be better off learning from professionals with industry experience. I am Not criticizing the Coursera instructors here, most have industry experience as well in the USA. However, if you want connections and contacts in the data science industry in India and the US, you might be a bit lost in the vast numbers of student who take those courses. Industry experience in instructors is rare in a MOOC and critically important to your landing a job.
Personalized Attention and Job Placement Guarantee
Dimensionless has a batch size of strictly not more than 25 per batch. This means that unlike other MOOCs with hundreds or thousands of students, every student in a class will get individual attention and training. This is the essence of what makes this company the market leader in this space. No other course provider has this restriction, which makes it certain that when you pay the money, you are 100% certain of completing your course, unlike all the other MOOCs out there. You are also given training for creating a data science portfolio, and how to prepare for data science interviews when you start applying to companies. The best part of this entire process is the 100% job placement guarantee.
If this has got your attention, and you are highly interested in data science, I encourage you to go to the following link to see more about the Data Science Using Python and R course, a strong foundation for a data science career:
Modern technologies such as artificial intelligence, machine learning, data science, and Big Data have become the phrases everyone talks about, but no one fully understands them. To a layman, they seem very complex. All these words resemble a business executive or a student from a non-technical background. People are often confused by words such as AI, ML, and data science.
People are often confused about using technology for growing their business. With a plethora of technologies available and rise and shine of data science in recent times, the decision makes individuals & companies face the consent dilemma of whether to choose big data or ML or data science which can boost their businesses. In this blog, we will understand different concepts and have a look at this problem.
Let us understand key terms first i.e data science, machine learning, and big data
What is Data Science
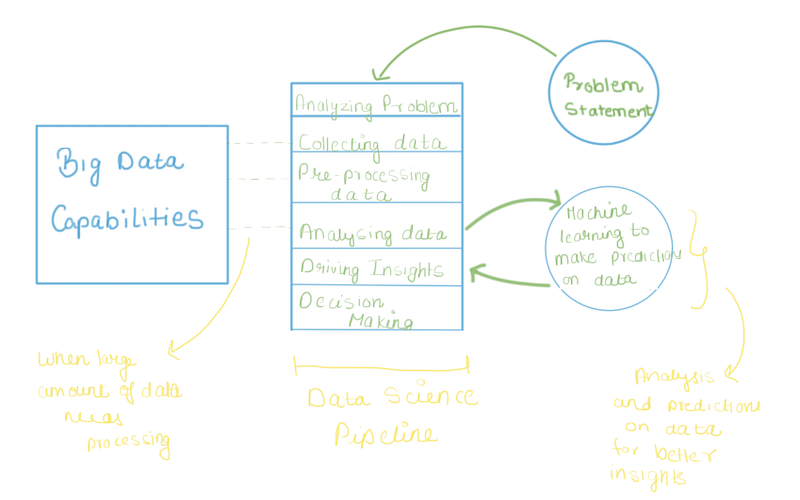
Data science is the umbrella under which all these terminologies take the shelter. Data science is a like a complete subject which has different stages within itself. Suppose a retailer wants to forecast the sales of an X item present in its inventory in the coming month. This is a business problem and data science aims to provide optimal solutions for the same.
Data science enables us to solve this business problem with a series of well-defined steps.
Collecting data
Pre-processing data
Analyzing data
Driving insights and generating BI report
Taking insight-bases decisions
Generally, these are the steps we mostly follow to solve a business problem. All the terminologies related to data science falls under different steps which we are going to understand just in a while. Different terminologies fall under different steps listed above.
You can learn more about the different component in data science from here
If you want to learn data science online then follow the link here
What is Big Data
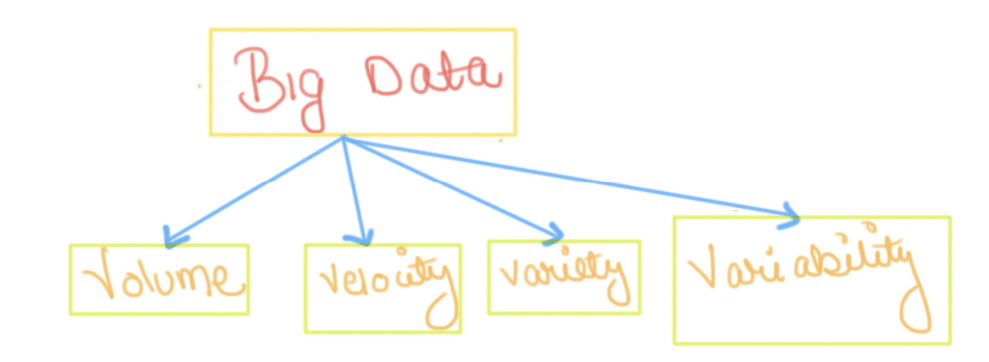
Big data is high-volume, high-velocity and/or high-variety information assets that demand cost-effective, innovative forms of information processing that enable enhanced insight, decision making, and process automation.
Characteristics Of ‘Big Data’
Volume — The name ‘Big Data’ itself is related to a size which is enormous. Size of data plays a very crucial role in determining value out of data. Also, whether a particular data can actually be considered as a Big Data or not, is dependent upon the volume of data. Hence, ‘Volume’ is one characteristic which needs to be considered while dealing with ‘Big Data’.
Variety — The next aspect of ‘Big Data’ is its variety. Variety refers to heterogeneous sources and the nature of data, both structured and unstructured. During earlier days, spreadsheets and databases were the only sources of data. Nowadays, analysis applications use data in the form of emails, photos, videos, monitoring devices, PDFs, audio, etc. This variety of unstructured-data poses certain issues for storage, mining and analyzing data.
Velocity — The term ‘velocity’ refers to the speed of generation of data. How fast the data is generated and processed to meet the demands, determines real potential in the data. Big Data Velocity deals with the speed at which data flows in from sources like business processes, application logs, networks, and social media sites, sensors, Mobile devices, etc. The flow of data is massive and continuous.
Variability — This refers to the inconsistency which can be shown by the data at times, thus hampering the process of being able to handle and manage the data effectively.
If you are looking to learn Big Data online then follow the link here
What is Machine Learning
At a very high level, machine learning is the process of teaching a computer system how to make accurate predictions when fed data.
Those predictions could be answering whether a piece of fruit in a photo is a banana or an apple, spotting people crossing the road in front of a self-driving car, whether the use of the word book in a sentence relates to a paperback or a hotel reservation, whether an email is a spam, or recognizing speech accurately enough to generate captions for a YouTube video.
The key difference from traditional computer software is that a human developer hasn’t written code that instructs the system how to tell the difference between the banana and the apple.
Instead, a machine-learning model has been taught how to reliably discriminate between the fruits by being trained on a large amount of data, in this instance likely a huge number of images labelled as containing a banana or an apple.
You can read more on how to be an expert in AI from here
The relationship between Data Science, Machine learning and Big Data
Data science is a complete journey of solving a problem using data at hand wheres Big data and machine learning are tools for the data scientists. It helps them to perform some specific tasks. While, Machine learning is more around making predictions using data present at hand whereas Big data emphasis on all the techniques that can be used to analyze a large set of data(thousands of petabytes may be, to begin with)
Let us understand in detail the difference between machine learning and Big Data
Big Data Analytics vs Machine Learning
You will find both similarities and differences when you compare between big data analytics and machine learning. However, the major differences lie in their application.
Big data analytics as the name suggest is the analysis of patterns or extraction of information from big data. So, in big data analytics, the analysis is done on big data. Machine learning, in simple terms, is teaching a machine how to respond to unknown inputs but still produce desirable outputs.
Most data analysis activities which do not involve expert task can be done through big data analytics without the involvement of machine learning. However, if the computational power required is beyond human expertise, then machine learning will be required.
Normal big data analytics is all about cleaning and transforming data to extract information, which then can be fed to a machine learning system in order to enable further analysis or predict outcomes without the requirement of human involvement.
Big data analytics and machine learning can go hand-in-hand and it would benefit a lot to learn both. Both fields offer good job opportunities as the demand is high for professionals across industries. When it comes to salary, both profiles enjoy similar packages. If you have skills in both of them, you are a hot property in the field of analytics.
However, if you do not have the time to learn both, you can go for whichever you are interested in.
So what to choose?
After understanding the 3 key phrases i.e Data science, Big data and machine learning, we are now in a better position to understand their selection and usage in business. We now know that data science is a complete process of using the power of data to boost business growth. So any decision-making process involving data has to involve data science.
There are few factors which may determine whether you should go for machine learning or Big data way for your organisation. Let us have a look at these factors and understand them in more detail
Factors affecting the selection
1. Goal
Selection of Big Data or Machine learning depends upon the end-goal of the business. If you are looking forward to generating predictions say based on customer behaviour or you want to build recommender systems then machine learning is the way to go. On the other hand, if you are looking for data handling and manipulation support where you can extract, load and transform data then Big Data will be the right choice for you.
2. Scale of operations
The scale of operation is one deciding factor between Big data and machine learning. If you have lots and lots of data like thousands of TB’s etc then employing Big data capabilities is the only choice. Traditional systems are not built to handle this much amount of data. Various businesses these days are sitting over huge chunks of data collected but lack the ability to meaningfully process them. Big Data systems allow handling of such amounts of data. Big data employs the concept of parallel computing which eases enables the systems to process and manipulate data in bulk quantities
3. Available resources
Employing Big data or machine learning capabilities requires a lot of investment both in terms of human resource and capital. If an organisation has resources trained for big data capabilities, then only they can manage such big infrastructure and leverage its benefits
Applications of Machine Learning
1. Image Recognition
It is one of the most common machine learning applications. There are many situations where you can classify the object as a digital image. For digital images, the measurements describe the outputs of each pixel in the image.
2. Speech Recognition
Speech recognition (SR) is the translation of spoken words into text. It is also known as “automatic speech recognition” (ASR), “computer speech recognition”, or “speech to text” (STT).
3. Learning Associations
Learning association is the process of developing insights into various associations between products. A good example is how seemingly unrelated products may reveal an association with one another. When analyzed in relation to buying behaviours of customers.
4. Recommendation systems
These applications have been the bread and butter for many companies. When we talk about recommendation systems, we are referring to the targeted advertising on your Facebook page, the recommended products to buy on Amazon, and even the recommended movies or shows to watch on Netflix.
Applications of Big Data
1. Government
Big data analytics has proven to be very useful in the government sector. Big data analysis played a large role in Barack Obama’s successful 2012 re-election campaign. The Indian Government utilizes numerous techniques to ascertain how the Indian electorate is responding to government action, as well as ideas for policy augmentation.
2. Social Media Analytics
The advent of social media has led to an outburst of big data. Various solutions have been built in order to analyze social media activity like IBM’s Cognos Consumer Insights, a point solution running on IBM’s BigInsights Big Data platform, can make sense of the chatter. Social media can provide valuable real-time insights into how the market is responding to products and campaigns. With the help of these insights, the companies can adjust their pricing, promotion, and campaign placements accordingly.
3. Technology
The technological applications of big data comprise of the following companies which deal with huge amounts of data every day and put them to use for business decisions as well. For example, eBay.com uses two data warehouses at 7.5 petabytes and 40PB as well as a 40PB Hadoop cluster for search, consumer recommendations, and merchandising. Inside eBay‟s 90PB data warehouse. Amazon.com handles millions of back-end operations every day, as well as queries from more than half a million third-party sellers.
4. Fraud detection
For businesses whose operations involve any type of claims or transaction processing, fraud detection is one of the most compelling Big Data application examples. Big Data platforms that can analyze claims and transactions in real time, identifying large-scale patterns across many transactions or detecting anomalous behaviour from an individual user, can change the fraud detection game.
Examples
1. Amazon
Amazon employs both machine learning and big data capabilities to serve its customers. It uses ML in form of recommender systems to suggest new products to its customers. They use big data to maintain and serve all the products data they have. Right from processing all the images and the content, to displaying them over the website, it is handled by the employed big data systems.
2. Facebook
Facebook similarly like Amazon has loads and loads of user data available with it. It uses machine learning to segment all the users based on their activity. Then, Facebook finds the best advertisements for its users in order to increase the clicks on the ads. All this is done through machine learning. With large user data at disposal, traditional systems can not process this data and make it ready for machine learning purposes. Facebook has employed big data systems so that they can process and transform this huge data and actually can derive insights out of it. Big data is required to make all this huge data processable.
Conclusion
In this blog, we learned how data science, machine learning and Big data link with each other. Whenever you want to solve any problem by using data at hand, data science is the process to solve it. If the data is too large and traditional systems or small-scale machines cannot handle it then BIG data techniques are the option to analyze such large chunks of data set. Machine learning covers the part when you want to make predictions of some kind, based on data you have at your end. These predictions will help you in validating your hypothesis around data and will enable smarter decision making.
Follow this link, if you are looking to learn more about data science online!
In very simple words, Amazon Web Services is a subsidiary of Amazon that provides on-demand cloud computing platforms to individuals, companies and governments, on a paid subscription basis. The technology allows subscribers to have at their disposal a virtual cluster of computers, available all the time, through the Internet.
Let us give a shot at a very technical description of AWS. Amazon Web Services (AWS) is a secure cloud services platform, offering computing power, database storage, content delivery and other functionality to help businesses scale and grow. Explore how millions of customers are currently leveraging AWS cloud products and solutions to build sophisticated applications with increased flexibility, scalability and reliability.
Capabilities?
Websites & Website Hosting: Amazon Web Services offers cloud web hosting solutions that provide businesses, non-profits, and governmental organizations with low-cost ways to deliver their websites and web applications. Whether you’re looking for marketing, rich media, or e-commerce website, AWS offers a wide range of website hosting options, and we’ll help you select the one that is right for you.
Backup & Recovery: AWS offers the most storage services, data-transfer methods, and networking options to build solutions that protect your data with unmatched durability and security
Data Archive: Amazon Web Services offers a complete set of cloud storage services for archiving. You can choose Amazon Glacier for affordable, non-time sensitive cloud storage, or Amazon Simple Storage Service (S3) for faster storage, depending on your needs. With AWS Storage Gateway and our solution provider ecosystem, you can build a comprehensive, storage solution.
DevOps: AWS provides a set of flexible services designed to enable companies to more rapidly and reliably build and deliver products using AWS and DevOps practices. These services simplify provisioning and managing infrastructure, deploying application code, automating software release processes, and monitoring your application and infrastructure performance.
Big Data: AWS delivers an integrated suite of services that provide everything needed to quickly and easily build and manage a data lake for analytics. AWS-powered data lakes can handle the scale, agility, and flexibility required to combine different types of data and analytics approaches to gain deeper insights, in ways that traditional data silos and data warehouses cannot. AWS gives customers the widest array of analytics and machine learning services, for easy access to all relevant data, without compromising on security or governance.
Why learn AWS?
DevOps Automation
You don’t want your data scientists spending time on DevOps tasks like creating AMIs, defining Security Groups, and creating EC2 instances. Data science workloads benefit from large machines for exploratory analysis in tools like Jupyter or RStudio, as well as elastic scalability to support bursty demand from teams, or parallel execution of data science experiments, which are often computationally intensive.
Cost controls, resource monitoring, and reporting
Data science workloads often benefit from high-end hardware, which can be expensive. When data scientists have more access to scalable compute, how do you mitigate the risk of runaway costs, enforce limits, and attribute across multiple groups or teams?
Environment management
Data scientists need agility to experiment with new open source tools and packages, which are evolving faster than ever before. System administrators must ensure stability and safety of environments. How can you balance these two points in tension?
GPUs
Neural networks and other effective data science techniques benefit from GPU acceleration, but configuring and utilizing GPUs remains easier said than done. How can you provide efficient access to GPUs for your data scientists without miring them in DevOps configuration tasks?
Security
AWS offers world-class security in their environment — but you must still make choices about how you configure security for your applications running on AWS. These choices can make a significant difference in mitigating risk as your data scientists transfer logic (source code) and data sets that may represent your most valuable intellectual property.
Our AWS Course
1. AWS Introduction
This section covers the basic and different concepts and terms which are AWS specific. This lays out the basic setting where learners are fed with all the AWS specific terms and are prepared for the deep dive.
2. VPC Subnet
A virtual private cloud (VPC) is a virtual network dedicated to your AWS account. It is logically isolated from other virtual networks in the AWS Cloud. You can launch your AWS resources, such as Amazon EC2 instances, into your VPC.
3. Route
A route table contains a set of rules, called routes, that are used to determine where network traffic is directed. Each subnet in your VPC must be associated with a route table; the table controls the routing for the subnet. A subnet can only be associated with one route table at a time, but you can associate multiple subnets with the same route table.
4. EC2
Amazon Elastic Compute Cloud (Amazon EC2) is a web service that provides secure, resizable compute capacity in the cloud. It is designed to make web-scale cloud computing easier for developers.
5. IAM
AWS Identity and Access Management (IAM) is a web service that helps you securely control access to AWS resources. You use IAM to control who is authenticated (signed in) and authorized (has permissions) to use resources.
6. S3
Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance. This means customers of all sizes and industries can use it to store and protect any amount of data for a range of use cases, such as websites, mobile applications, backup and restore, archive, enterprise applications, IoT devices, and big data analytics.
7. Lambda
AWS Lambda is a ‘compute’ service that lets you run code without provisioning or managing servers. AWS Lambda executes your code only when needed and scales automatically, from a few requests per day to thousands per second
8. SNS
Amazon Simple Notification Service (SNS) is a highly available, durable, secure, fully managed pub/sub messaging service that enables you to decouple microservices, distributed systems, and serverless applications. Amazon SNS provides topics for high-throughput, push-based, many-to-many messaging.
9. SQS
Amazon Simple Queue Service (SQS) is a fully managed message queuing service that enables you to decouple and scale microservices, distributed systems, and serverless applications. SQS eliminates the complexity and overhead associated with managing and operating message-oriented middleware and empowers developers to focus on differentiating work.
10. RDS
Amazon Relational Database Service (Amazon RDS) makes it easy to set up, operate, and scale a relational database in the cloud. It provides cost-efficient and resizable capacity while automating time-consuming administration tasks such as hardware provisioning, database setup, patching and backups.
11. Dynamo DB
Amazon DynamoDB is a key-value and document database that delivers single-digit millisecond performance at any scale. It’s a fully managed, multi-region, multi-master database with built-in security, backup and restores, and in-memory caching for internet-scale applications. DynamoDB can handle more than 10 trillion requests per day and support peaks of more than 20 million requests per second.
13. Cloud Formation
AWS CloudFormation provides a common language for you to describe and provision all the infrastructure resources in your cloud environment. CloudFormation allows you to use a simple text file to model and provision, in an automated and secure manner, all the resources needed for your applications across all regions and accounts. This file serves as the single source of truth for your cloud environment.
14. Projects
No learning can happen without doing any project. This is our mantra at Dimensionless Technologies. We have different projects planned for our learners which will help in implementing all the learners during the course.
Why Dimensionless as your learning partner?
Dimensionless Technologies provide instructor-led LIVE online training with hands-on different problems. We do not provide classroom training but we deliver more as compared to what a classroom training could provide you with
Are you sceptical of online training or you feel that online mode is not the best platform to learn? Let us clear your insecurities about online training!
Live and Interactive sessions
We conduct classes through live sessions and not pre-recorded videos. The interactivity level is similar to classroom training and you get it in the comfort of your home.
Highly Experienced Faculty
We have very highly experienced faculty with us (IIT`ians) to help you grasp complex concepts and kick-start your career success journey
Up to Data Course content
Our course content is up to date which involves all the latest technologies and tools. Our course is well equipped for learners to grasp the knowledge required to solve real-world problems through their data analytical skills
Availability of software and computing resource
Any laptop with 2GB RAM and Windows 7 and above is perfectly fine for this course. All the software used in this course are Freely downloadable from the Internet. The trainers help you set it up in your systems. We also provide access to our Cloud-based online lab where these are already installed.
Industry-Based Projects
During the training, you will be solving multiple case studies from different domains. Once the LIVE training is done, you will start implementing your learnings on Real Time Datasets. You can work on data from various domains like Retail, Manufacturing, Supply Chain, Operations, Telecom, Oil and Gas and many more.
Course Completion Certificate
Yes, we will be issuing a course completion certificate to all individuals who successfully complete the training.
Placement Assistance
We provide you with real-time industry requirements on a daily basis through our connection in the industry. These requirements generally come through referral channels, hence the probability to get through increases manifold
Conclusion
Dimensionless technologies have the right courses for you if you are aiming to kick-start your career in the field of data science. Not only we cover all the important concepts and technologies but also focus on their implementation and usage in real-world business problems. Follow the link to register yourself for the free demo of the courses!
International Data Corp. (IDC) expects worldwide revenue for big data and business analytics (BDA) solutions to reach $260 billion in 2022, with a compound annual growth rate (CAGR) of 11.9%. It values the current market at $166 billion, up 11.7% over 2017.
The industries making the largest investments in big data and business analytics solutions are banking, manufacturing, professional services, and government. At a high level, organizations are turning to Big Data and analytics solutions to navigate the convergence of their physical and digital worlds
In this blog, we will be looking into various Big Data solutions provided by AWS(Amazon Web Services). This will give an idea about different services available on AWS for obtaining Big Data capabilities for their Businesses/Organisations.
Also, if you are looking to learn Big Data, then you will really like this amazing course
What is Big Data?
Big data is high-volume, high-velocity and/or high-variety information assets that demand cost-effective, innovative forms of information processing that enable enhanced insight, decision making, and process automation.
Big Data comprises of 4 important V’s which defines the characteristics of Big Data. Let us discuss these ones before moving to AWS
Volume — The name ‘Big Data’ itself is related to a size which is enormous. Size of data plays a very crucial role in determining value out of data. Also, whether a particular data is Big Data or not, is dependent upon the volume of data. Hence, ‘Volume’ is one of the important characteristic while dealing with ‘Big Data’.
Variety — The next aspect of ‘Big Data’ is its variety. Variety refers to heterogeneous sources and the nature of data, both structured and unstructured. During earlier days, spreadsheets and databases were the only sources of data. Nowadays, analysis applications use data in the form of emails, photos, videos, monitoring devices, PDFs, audio, etc. This variety of unstructured-data poses certain issues for storage, mining and analyzing data.
Velocity — The term ‘velocity’ refers to the speed of generation of data. How fast the data is generated and processed to meet the demands, determines real potential in the data. Big Data Velocity deals with the speed at which data flows in from sources like business processes, application logs, networks, and social media sites, sensors, Mobile devices, etc. Also, the flow of data is massive and continuous.
Variability — This refers to the inconsistency which can be shown by the data at times, thus hampering the process of being able to handle and manage the data effectively.
If you are looking to learn Big Data online then follow the link here
What is AWS?
AWS comprises of many different cloud computing products and services. The highly profitable Amazon division provides servers, storage, networking, remote computing, email, mobile development and security. Furthermore. AWS can be split into two main products: EC2, Amazon’s virtual machine service and S3, a storage system by Amazon. It is so large and present in the computing world that it’s now at least 10 times the size of its nearest competitor and hosts popular websites like Netflix and Instagram
AWS is split into 12 global regions, each of which has multiple availability zones in which its servers are located. These serviced regions are split in order to allow users to set geographical limits on their services (if they so choose), but also to provide security by diversifying the physical locations in which data is held.
AWS solutions for Big Data
AWS has numerous solutions for all the development and deployment purposes. Also, in the field of Data Science and Big Data, AWS has come up with recent developments in different aspects of Big Data handling. Before jumping to tools, let us understand different aspects in Big Data for which AWS can provide solutions
Data Ingestion Collecting the raw data — transactions, logs, mobile devices and more — is the first challenge many organizations face when dealing with big data. A good big data platform makes this step easier, allowing developers to ingest a wide variety of data — from structured to unstructured — at any speed — from real-time to batch.
Storage of Data Any big data platform needs a secure, scalable, and durable repository to store data prior to or even after processing tasks. Depending on your specific requirements, you may also need temporary stores for data-in-transit
Data Processing This is the step where data transformation happens from its raw state into a consumable format — usually by means of sorting, aggregating, joining and even performing more advanced functions and algorithms. The resulting data sets undergo storage for further processing or made available for consumption via business intelligence and data visualization tools.
Visualisation Big data is all about getting high value, actionable insights from your data assets. Ideally, data is available to stakeholders through self-service business intelligence and agile data visualization tools that allow for fast and easy exploration of datasets. Depending on the type of analytics, end-users may also consume the resulting data in the form of statistical “predictions” — in the case of predictive analytics — or recommended actions — in the case of prescriptive analytics.
AWS tools for Big Data
In the previous sections, we looked at the fields in Big Data where AWS can provide solutions. Additionally, AWS has multiple tools and services in its arsenal to enable customers with the capabilities of Big Data
Let us look at the various solutions provided by AWS for handling different stages involved in handling Big Data
Ingestion
Kinesis Amazon Kinesis Firehose is a fully managed service for delivering real-time streaming data directly to Amazon S3. Kinesis Firehose automatically scales to match the volume and throughput of streaming data and requires no ongoing administration. Kinesis Firehose is configurable to transform streaming data before it’s stored in Amazon S3. Its transformation capabilities include compression, encryption, data batching, and Lambda functions. Kinesis Firehose can compress data before it’s storage in Amazon S3. It currently supports GZIP, ZIP, and SNAPPY compression formats. GZIP is a better choice because it can be used by Amazon Athena, Amazon EMR, and Amazon Redshift. Kinesis Firehose encryption supports Amazon S3 server-side encryption with AWS Key Management Service (AWS KMS) for encrypting delivered data in Amazon S3
Snowball You can use AWS Snowball to securely and efficiently migrate bulk data from on-premises storage platforms and Hadoop clusters to S3 buckets. After you create a job in the AWS Management Console, a Snowball appliance will be automatically shipped to you. After a Snowball arrives, connect it to your local network, install the Snowball client on your on-premises data source, and then use the Snowball client to select and transfer the file directories to the Snowball device. The Snowball client uses AES-256-bit encryption. No encryption keys with the Snowball device the makes data transfer process is highly secure. After the data transfer is complete, the Snowball’s E Ink shipping label will automatically update. Ship the device back to AWS. Upon receipt at AWS, data transfer takes place from the Snowball device to your S3 bucket and stored as S3 objects in their original/native format. Snowball also has an HDFS client, so data migration may happen directly from Hadoop clusters into an S3 bucket in its native format.
Storage
Amazon S3 Amazon S3 is secure, highly scalable, durable object storage with millisecond latency for data access. S3 can store any type of data from anywhere — websites and mobile apps, corporate applications, and data from IoT sensors or devices. It can also store and retrieve any amount of data, with unmatched availability, and built from the ground up to deliver 99.999999999% (11 nines) of durability. S3 Select focuses on data read and retrieval, reducing response times up to 400%. S3 provides comprehensive security and compliance capabilities that meet even the most stringent regulatory requirements.
AWS Glue AWS Glue is a fully manageable service that provides a data catalogue to make data in the data lake discoverable. Additionally, it has the ability to do extract, transform, and load (ETL) to prepare data for analysis. Also, the inbuilt data catalogue is like a persistent metadata store for all data assets, making all of the data searchable, and queryable in a single view.
Processing
EMR For big data processing using the Spark and Hadoop, Amazon EMR provides a managed service that makes it easy, fast, and cost-effective to process vast amounts data. Furthermore, EMR supports 19 different open-source projects including Hadoop, Spark, and HBase. Also it comes with managed EMR Notebooks for data engineering, data science development, and collaboration. Each project updates in EMR within 30 days of a version release. It ensures you have the latest and greatest from the community, effortlessly.
Redshift For data warehousing, Amazon Redshift provides the ability to run complex, analytic queries against petabytes of structured data. Also, it includes Redshift Spectrum that runs SQL queries directly against Exabytes of structured or unstructured data in S3 without the need for unnecessary data movement. Amazon Redshift is less than a tenth of the cost of traditional solutions. Start small for just $0.25 per hour, and scale out to petabytes of data for $1,000 per terabyte per year.
Visualisations
Amazon QuickSight For dashboards and visualizations, Amazon Quicksight provides you fast, cloud-powered business analytics service. It makes it easy to build stunning visualizations and rich dashboards. Additionally, they can be accessed from any browser or mobile device.
Conclusion
Amazon Web Services provides a fully integrated portfolio of cloud computing services. Furthermore, tt helps you build, secure, and deploy your big data applications. Also, with AWS, there’s no hardware to procure and infrastructure to maintain and scale. Due to this, you can focus your resources on uncovering new insights. With new features added constantly, you’ll always be able to leverage the latest technologies without making long-term investment commitments.
Additionally, if you are interested in learning Big Data and NLP, click here to get started
Furthermore, if you want to read more about data science, you can read our blogs here
Also, the following are some suggested blogs you may like to read