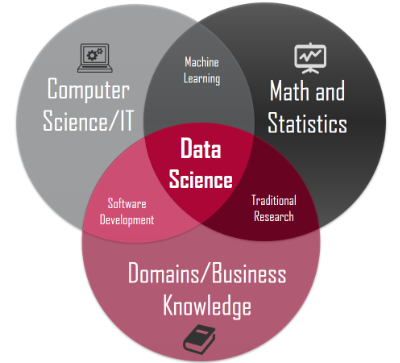
The field of Data Science has seen exponential growth in the last few years. Though the concept was prevalent previously as well the recent hype is the result of the variety of huge volumes of unstructured data that is getting generated across different industries and the enormous potential that’s hidden beneath those data. On top of the top, the massive computational power that modern day computers possess has made it even more possible to mine such huge chunks of data.
Now Data Science is a study which is comprised of several disciplines starting from exploratory data analysis to predictive analytics. There are various tools and techniques that professionals use to extract information from the data. However, there is a common misconception among them is to focus more on those tools rather than the math behind the data modelling. People tend to put too much importance on the Machine Learning algorithms instead of the Linear Algebra or the Probability concepts that are required to fetch relevant meaning from the data.
Thus, in this blog post, we would cover one of the pre-requisites in Data Science i.e. Linear Algebra and some of the basic concepts that you should learn.
Understanding the Linear Algebra Concepts
To comprehend the underlying theory behind Machine Learning or Deep Learning, it is necessary to have sufficient knowledge of some of the Linear Algebra concepts. You cannot master the state-of-art Machine Learning algorithms without knowing the math.
Below are some of the Linear Algebra concepts that you need to know for Machine Learning.
1. Matrix and Vectors
Arguably two of the most important concepts that you would encounter throughout your Machine Learning journey. An array of numbers is known as vectors whereas a matrix is 2-dimensional vectors which are generally expressed in uppercase.
In Machine Learning terms, a vector is the target variable in a supervised learning problem where the features form the matrix in the data. Several operations like multiplication, transformation, rank, conjugate, etc., could be performed with the matrix.
Two vectors of equal shape and with same number of elements could be added and subtracted.
2. Diagonal Matrix
A matrix whose non-diagonal elements are all zero is known as Diagonal Matrix. A diagonal matrix’s inverse is easy to find unlike a generic a matrix. Multiplication of diagonal matrices are also easier. A matrix has no inverse if it its diagonal matrix is not square.
3. Orthogonal Matrix
A matrix whose product of the transpose and the matrix itself is equal to an Identity matrix is known as orthogonal matrix. The concept of orthogonality is important in Machine Learning or specifically in Principal Component Analysis which solves the curse of dimensionality.
Orthogonal matrix are so useful because its inverse is equal to its transpose. Also if any orthogonal matrix is multiplied with a scalar term, the errors of the scalar would not be magnified. To maintain numerical stability, this is a very desirable behaviour.
4. Symmetric Matrix
One of the important concepts in Machine Learning and Linear Algebra is symmetric matrix. Matrices in Linear Algebra are often used to hold f(vi, vj). These are often symmetrical functions and the matrix corresponding to it are also symmetric. The feature distance between the data points could be measured by f and also it could calculate the covariance of features. Some of the properties of symmetric matrix are –
The inverse of a symmetric matrix is symmetrical in nature.
There are no complex numbers in the eigenvalues. All values are real numbers.
Even with repeated eigenvalues, n eigenvectors could be chosen of S to be orthogonal.
Multiplying a matrix with its transpose would form the symmetric matrix.
If the columns of a matrix are linearly independent, then the product of the matrix and its transpose is invertible in nature.
Property of factorization is another important property of a symmetric matrix.
5. Eigenvalues and Eigenvectors –
A vector which doesn’t change its direction but only scales by magnitude of its eigenvalue is known as the eigenvector. It is one of most sought after concepts in Data Science
Av = lambda * v
Here v is the (m x 1) eigenvectors and lambda is the (m x m) eigenvalues and A is a square matrix.
The basics of computing and mathematics is formed by the eigenvalues and the eigenvectors. A vector when plotted in an XY chart has a particular direction. Applying a linear transformation on certain vectors doesn’t change its direction which makes them extremely valuable in Machine Learning.
To reduce noise in the data both the eigenvalues and eigenvectors are used. In computationally intensive tasks, the efficiency could be improved using these two. Eigenvectors and Eigenvalues could also help to reduce overfitting as it eliminates the strongly co-related features.
Both eigenvectors and eigenvalues has a broad set of usages. Image, sound or textual data which has large set of features could often be difficult to visualize as it has more than three dimensions. Transforming such data using one-hot encoding or other methods is not space efficient at all. To resolve such scenarios, Eigenvectors and Eigenvalues are used which would capture the Information stored in a large matrix. Reducing the dimensions is the key in computationally intensive tasks. This lets us to the concept of PCA which we would describe below.
In facial recognition, eigenvectors and eigenvalues are used. Data could be better understood using the eigenvectors and the eigenvalues in non-linear motion dynamics.
6. Principal Component Analysis
A Machine Learning problem often suffers from the curse of dimensionality. It means that the features of the data are in higher dimension and is highly co-related. The problem that arises as a result of this is that it gets difficult to understand how each feature influences the target variable because highly co-related features would mean the target variable is equally influenced by both the features instead of one. Another issue with higher dimensional data is that you cannot visualize it because at most you could plot a 3-D data in a plane. Thus the performance of the model could not be interpreted as well.
PCA or Principal Component Analysis is a process by which you can reduce the dimension of your data to either a 2-D or 3-D data. The reduction in dimension is done keeping the maximum variance (95% to 99%) intact so that none of the information is lost. The data is reduced from a higher dimension to two or three independent principal components.
Now the maths behind Principal Component Analysis follows the concept of orthogonality. The data from higher dimension is projected on to a lower dimension sub-space and the goal is to reduce the projected error between the data points and the lower dimension sub-space. The reduction in the projected error would ensure increase in the variance.
Once, the number of principal components is decided (say two or three), the first principal component would carry maximum variance in the day followed by the second component which would have a slightly less variance and so on. PCA is a very good technique to decrease the number of features and reduce the complexity of the model.
However, one must not use Principal Component Analysis as the first step to reduce overfitting. Overfitting is a state where the model is complex and has high variance. To reduce overfitting, you should first try to increase the amount of data or choose less number of features if possible. If that doesn’t work, then the next best option is to use L1 or L2 regularization which would penalize the co-efficient try to make the model complex. PCA should the last technique used if none of the above mentions solution works.
7. Singular Value Decomposition
A matrix factorization method used in science, technology and various other domains. Singular Value Decomposition has seen in growing importance in recent times due machine learning. Data mining, developments. The product of matrix representation is known as Matrix Factorization.
For each element, the row and column index interchanges as the result of the conjugate transpose.
In a higher dimensional raw data, singular value decomposition could be used to untangle information. To compute Principal Component Analysis, we use the Singular Value Decomposition concept in Machine Learning. Some of the applications of Singular Value Decomposition are in image processing, recommending products, and also in processing natural data using Natural Language Processing.
However, the Singular Value Decomposition differs from Principal Component Analysis by the fact that you could find diagonal of a matrix with SVD into special matrices. These matrices could be analysed and are easy to manipulate. The data could be compressed into independent components as well.
Conclusion
Machine Learning is the word of the mouth of several professionals but to master it you must know the math behind it and learn some of the Linear Algebra concepts that is used in any ML or Deep Learning project.
Dimensionless has several blogs and training to get started with Python, and Data Science in general.
Follow this link, if you are looking to learn more about data science online!
Additionally, if you are having an interest in learning Data Science, Learnonline Data Science Course to boost your career in Data Science.
Furthermore, if you want to read more about data science, you can read our blogs here
Over the years the amount of data that’s getting generated has increased tremendously due to the advancement of technology and the variety of sources that’s is available in the current market. Most of the data now are unclean and messy and needs advanced tools and techniques to be able to extract meaningful insights from it.
These unstructured data, if mined properly could achieve ground-breaking results and help a business achieve outstanding results. As most companies want to stay ahead of their competitors in the market, they have introduced Machine Learning in their workflow to streamline the process of predictive analytics. The state-of-of-art Machine Learning algorithms could produce interesting results if tuned properly with the relevant features and the correct parameters.
However, the traditional Machine Learning algorithms lacks in performance and ability in comparison to its sub-field Deep Learning which works on the principle of Neural Networks. It also takes away the hassle of feature engineering in Machine Learning as more data it gets, the better it learns. To deploy Deep Learning algorithms in the workflow, one needs to have powerful computers with computational capacity.
In this article, you would learn about one of the classes of Deep Learning – Capsule Networks.
Introduction
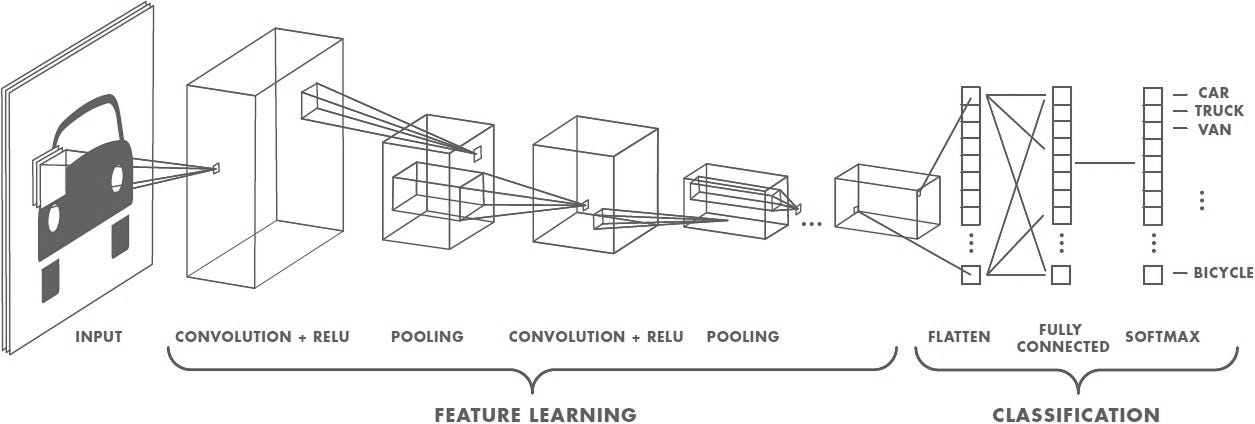
Convolutional Neural Networks or CNN is a class of Deep Learning which is commonly used for working with image data. In 2012, a paper was published which used Deep Convolutional Network to recognize images. Since then, Deep Learning made its breakthrough in all fields from Computer Vision to Natural Language Processing and more often than not gave impressive results. It prompted researches to try different techniques to various applications.
However, despite its insurmountable capabilities, Deep Learning was not going to work everywhere. The flaws starts to emerge when used extensively over a period of time for various purposes. In Convolutional Neural Network, the convolution operation are the main building blocks which detects key features. During training, these weights of these convolution operations are tweaked to identify key features in the image.
During face recognition, the convolutions could be triggers by ears or eyes. Once all the components are found, the face would be identified. However, the capabilities of Convolutional Neural Network could not stretch beyond this point. In a structured facial image, the CNN would work fine but when the image is disjointed and components of a face are misplaced, then it fails to identify the face correctly.
An important point to understand is that the features in the lower level are combined with the upper level features as the weighted sum and the following layer neuron’s weights multiplies the activation of a preceding layer and added. Despite all these, the relationships between features are not taken into account in this context. Convolutional Neural Network fails in the fact that the relationships between features is not considered which is resolved by the Capsule Networks.
Understanding Capsule Networks
For correct image recognition, the hierarchical relationship between the features of the image should be considered. To model these relationships, Capsules provides a new building block. It helps the model to identify the image based on its previous experience instead of relying on independent features. The use of vectors instead of scalars makes it possible to comprehend such rich feature representation. In Convolutional Neural Network, it was the weighting of input scalars, the scalar summation, and so on, whereas in Capsule Networks, the scalars are replaced by vectors. There is matrix multiplication, scalar weighting, and sum of the vectors. There also a non-linear vector-to-vector representation.
To encode more relational and relative information, vectors help to a large extent. With less training data, you could also get more accuracy using the Capsule Networks. A capsule could detect an image rotated in any direction. The vectors information of features like size, orientation allows the Capsule to provide a richer representation of the features. Instead of more examples, one example with a vector representation is enough for a Capsule Network to train.
In general, smaller objects make up any real object. Suppose, the trunk, roots, and crown forms the hierarchy of a tree. The branches and the leaves are further extensions of the crown. Now, there is some fixation points made by our human eye whenever it sees any object. To recognize this object later on, its relative positions and the fixation point’s nature are analysed by our brain. It decreases the hassle of processing every detail in our brain. The crown of a tree could be identified just by looking at some branches and leaves. The tree is identified after our brain combines such hierarchical information. These objects could be termed as entities.
To recognize certain entities, the CapsNet takes into account the group of neurons or the Capsules. The capsules, corresponding to each entity gives –
The probability of the existence of the entity.
The entities instantiation parameters.
The properties of an entity such as size, hue, position, etc., are the instantiation parameters. A rectangle is a geometric object and you would know about its instantiation parameters from its corresponding capsule. A rectangle consists of a six-dimensional capsule. As the probability of an entity existence is represented by the output vector’s length it should follow the condition 0 <= P <= 1. The capsule output could be transformed using the formula.
Vj = (||Sj||^2/ (1 + ||Sj||^2)) * (Sj / ||Sj||)
Here, s is the capsule output. It is a non-linear transformation known as the squashing function. Just like the ReLU activation in Convolutional Neural Network, this is the capsule networks activation function.
In a nutshell, a group of neurons is known as capsule whose activation v = < v1, v2, vn). The entities existence probability is represented by its length and also the instantiation parameter. There are several layers present in a CapsNet. The simple entities corresponds to the lower layer capsules. The output of the high-level capsules are obtained by its combination with the low-level capsules. The complex entities presence are bet by the low-level capsules. For example, a house presence could be comprehended by the presence of a rectangle and a triangle.
The low level capsules receives a feedback from the high-level capsules after its presence of a high-level entity was agreed by the low-level capsules. This is known as coupling effect and the bet on the high-level capsule is increased as a result of it. Now, suppose there are two capsule levels where the circles, triangles form the lower levels and the house, cars forms the high-level.
There would a high activation vectors for the rectangles, triangles capsules. The presence of the high-level objects would be bet by the rectangles, triangles, relative positions. The presence of the house would be agreed increasing the size of the output vector and it would be repeated four-five times which would increase the bets on the house presence compared to the boat or car.
CapsNet Mathematics
Consider layers l and l+1 with capsules m and n. At layer l+1, the capsule activations would be calculated based on the layer l activations. u and v denotes the activations of l and l+1 layers respectively.
At l+1 layer, for capsule j –
At layer l, the prediction vectors are first calculated and is the product of the weight matrix and the activation.
For the capsule j of layer l+1, the output vector is calculated. It is calculated by taking the prediction vectors weighted sum.
The activation is then calculated by applying the squashing function.
The squashing function is computed by adding an epsilon to the square root of the sum of squares and it implements the norm manually.
There is a certain advantage of using the Capsule Networks. The Convolutional Neural Network has pooling layers. The primitive type of Routing Mechanism is the MaxPool which is generally used. In a 4×4 grid of local pool, the higher layer is routed to the most active feature and in routing the higher-level detectors doesn’t have any say. The CapsNet’s routing by agreement mechanism could be compared to this. The Capsule Networks is advantageous over Convolutional Neural Network as it has routing mechanism which are super dynamic. The real-time information detection makes it dynamic in nature.
Conclusion
Deep Learning has revolutionised the analytical Eco space to a large extent. Its capabilities are causing more and more advanced technologies to be developed and several complex business problems are solved. From media to healthcare, everywhere Deep Learning is used to achieve impressive results.
Capsule Networks has been an upgrade over Convolutional Neural Network in classifying images or text. It makes a framework much more human-like and takes the drawbacks that CNN has. Face detection is an important application used over various industries to detect threat, surveillance, and so on. Thus having a system with accurate results could be achieved using the CapsNet.
Dimensionless has several blogs and training to get started with Python, and Data Science in general.
Follow this link, if you are looking to learn more about data science online!
Additionally, if you are having an interest in learning Data Science, Learnonline Data Science Course to boost your career in Data Science.
Furthermore, if you want to read more about data science, you can read our blogs here
Data Science is the study of extracting meaningful insights from the data using various tools and technique for the growth of the business. Despite its inception at the time when computers came into the picture, the recent hype is a result of the huge amount of unstructured data that is getting generated and the unprecedented computational capacity that modern computers possess.
However, there is a lot of misconception among the masses about the true meaning of this field with many of the opinion that it is about predicting future outcomes from the data. Though predictive analytics is a part of Data Science, it is certainly not all of what Data Science stands for. In an analytics project, the first and foremost role is to get the build the pipeline and get the relevant data to perform predictive analytics later on. The professional who is responsible for building such ETL pipelines and the creating the system for flawless data flow is the Data Engineer and this field is known as Data Engineering.
Over the years the role of Data Engineers has evolved a lot. Previously it was about building Relational Database Management System using Structured Query Language or run ETL jobs. These days, the plethora of unstructured data from a multitude of sources has resulted in the advent of Big Data. It is nothing but a different forms of voluminous data which carries a lot of information if mined properly.
Now, the biggest challenge that professionals face is to analyse these huge terabytes of data which traditional file storage systems are incapable of handling. This problem was resolved by Hadoop which is an open-source Apache framework built to process large data in the form of clusters. Hadoop has several components which takes care of the data and one such component is known as Map Reduce.
What is Hadoop?
Created by Doug Cutting and Mike Cafarella in 2006, Hadoop facilitates distributed storage and processing of huge data sets in the form parallel clusters. HDFS or Hadoop Distributed File System is the storage component of Hadoop where different file formats could be stored to be processed using the Map Reduce programming which we would cover later on in this article.
The HDFS runs on large clusters and follows a master/slave architecture. The metadata of the file i.e., information about the relative position of the file in the node is managed by the NameNode which is the master and could save several DataNodes to store the data. Some of the other components of Hadoop are –
Yarn – It manages the resources and performs job scheduling.
Hive – It allows users to write SQL-like queries to analyse the data.
Sqoop – Used for to and fro structured data transfer between the Hadoop Distributed file System and the Relational Database Management System.
Flume – Similar to Sqoop but it facilitates the transfer of unstructured and semi-structured data between the HDFS and the source.
Kafka – A messaging platform of Hadoop.
Mahout – It used to create Machine Learning operations on big data.
Hadoop is a vast concept and in detail explanation of each components is beyond the scope of this blog. However, we would dive into one of its components – Map Reduce and understand how it works.
What is Map Reduce Programming
Map Reduce is the programming paradigm that allows for massive scalability across hundreds or thousands of servers in a Hadoop Cluster, i.e. suppose you have a job to run and you write the Job using the MapReduce framework and then if there are a thousand machines available, the Job could run potentially in those thousand machines.
The Big Data is not stored traditionally in HDFS. The data gets divided into chunks of small blocks of data which gets stored in respective data nodes. No complete data’s present in one centralized location and hence a native client application cannot process the information right away. So a particular framework is needed with the capability of handling the data that stays as blocks of data into respective data nodes, and the processing can go there to process that data and bring back the result. In a nutshell, data is processed in parallel which makes processing faster.
To improve performance and for better efficiency, the idea of parallelization was developed. The process is automated and concurrently executed. The instructions which are fragmented could also run on a single machine or on different CPU’s. To gain direct disk access, multiple computers uses SAN or Storage Area Networks which is a common type of Clustered File System unlike the Distributed File Systems which sends the data using the network.
One term that is common in this maser/slave architecture of data processing is Load Balancing where among the processors the tasks are spread to avoid overload on any DataNode. Unlike the static balancers, there is more flexibility provided by the dynamic balancers.
The Map-Reduce algorithm which operates on three phases – Mapper Phase, Sort and Shuffle Phase and the Reducer Phase. To perform basic computation, it provides abstraction for Google engineers while hiding fault tolerance, parallelization, and load balancing details.
Map Phase – In this stage, the input data is mapped into intermediate key-value pairs on all the mappers assigned to the data.
Shuffle and Sort Phase – This phase acts as a bridge between the Map and the Reduce phase to decrease the computation time. The data here is shuffled and sorted simultaneously based on the keys i.e., all intermediate values from the mapper phase is grouped together with respect to the keys and passed on to reduce function.
Reduce Phase– The sorted data is the input to the Reducer which aggregates the value corresponding to each key and produces the desired output.
How Map Reduce works
Across multiple machines, the Map invocations are distributed and the input data is automatically partitioned into M pieces of size sixteen to sixty four megabytes per piece. On a cluster of machines, many copies of the program are then started up.
Among the copies, one is the master copy while the rest are the slave copies. The master assigns M map and R reduce tasks to the slaves. Any idle worker would be assigned a task by the master.
The map task worker would read the contents of the input and pass key-value pairs to the Map function defined by the user. In the memory buffer, the intermediate key-value pairs would be produced.
To the local disk, the buffered pairs are written in a periodic fashion. The partitioning function then partitions them into R regions. The master would forward the location of the buffered key-value pairs to the reduce workers.
The buffered data is read by the reduce workers after getting the location from the master. Once it is read, the data is sorted based on the intermediate keys grouping similar occurrences together.
The Reduce function defined the user receives a set of intermediate values corresponding to each unique intermediate key that it encounters. The final output file would consists of the appended output from the Reduce function.
The user program is woken up by the Master once all the Map and Reduce tasks are completed. In the R output files, the successful MapReduce execution output could be found.
Each and every worker’s aliveness is checked by the master after the execution by sending periodic pings. If any worker does not respond to the ping, it is marked as failed after a certain point if time and its previous works are reset.
In case of failures, the map tasks which are completed would be re-executed as their output would be inaccessible in the local disk. Output which are stored in the global file system need not to be re-executed.
Some of the examples of Map Reduce programming are –
Map Reduce programming could count the frequencies of the URL access. The logs of web page would be processed by the map function and stored as output say <URL, 1> which would be processed by the Reduce function by adding all the same URL and output their count.
Map Reduce programming could also be used to parse documents and count the number of words corresponding to each document.
For a given URL, the list of all the associated source URL’s could be obtained with the help of Map Reduce.
To calculate per host term vector, the map reduce programming could be used. The hostname and the term vector pair would be created for each document by the Map function which would be processed by the reduce function which in turn would remove less frequent terms and give a final hostname, term vector.
Conclusion
Data Engineering is a key step in any Data Science project and Map Reduce is undoubtedly an essential part of it. In this article we have a brief intuition about Big Data and provided an overview of Hadoop. Then we explained Map Reduce programming and its workflow and gave few real life applications of Map Reduce programming as well.
Dimensionless has several blogs and training to get started with Python, and Data Science in general.
Follow this link, if you are looking to learn more about data science online!
Additionally, if you are having an interest in learning Data Science, Learnonline Data Science Course to boost your career in Data Science.
Furthermore, if you want to read more about data science, you can read our blogs here
Machine Learning has seen a tremendous rise in the last decade, and one of its sub-fields which has contributed largely to its growth is Deep Learning. The large volumes of data and the huge computation power that modern system possess has given Data Scientist, Machine Learning Engineers, and others to achieve ground-breaking results in the Deep Learning and continue to bring in new developments in this field.
In this blog post, we would cover the deep learning data sets that you could work with as a Data Scientist but before that, we would provide an intuition about the concept of Deep Learning.
Understanding Deep Learning
A sub-field of Machine Learning, the working structure of Deep Learning is similar to our brain known as the Artificial Neural Networks. It is similar to our nervous system where each neuron connected to each other. Across multiple industries from image classification to language translation, Deep Learning has penetrated into every sphere of the analytical Eco space.
The foundation of Deep Learning is a Neural Network. To understand neural networks, let’s say for example for house price prediction where the house size and the price are the variables. To find the price we could use Linear Regression but if we apply Deep Learning here, then an input would be provided to a neuron which would generate the output after applying some activation function such as Rectified Linear Unit or ReLU. The input to the activation function is a real number and the output would be zero or that number.
The task of mapping input to a corresponding output after applying some function is known as Supervised Learning. There are different types of neural networks used for different purposes – for predicting house prices, or ad revenue, the Standard Neural Network is used whereas for image classification, we would use the Convolutional Neural Network. Additionally, the Recurrent Neural Network is used for Speech Recognition, Machine Translation, and so on.
Despite the increase in the amount of data, traditional Machine Learning algorithms like Logistic Regression, Support Vector Machines, Linear Regression, etc., fails to improve a whole lot. However, in case of Deep Learning, as the data increases the performance of the model also increases. Data, Computation Time, and Algorithms are the three scales of a Deep Learning process.
Previously, the sigmoid function was used which decreased the learning rate and hence the computation time was more. The ReLU activation function has solved this problem as the parameters are updated faster and the computation time is reduced. There are certain other concepts in Deep Learning which are important as well – Forward and Backpropagation whose explanation is beyond the scope of this article.
Now, in Deep Neural Networks, the hidden layers have a lot of significance. Suppose there is an image, then the first hidden layer would try to identify the edges in it and as you would go deeper, complex functions like face identification would be formed. Below is the working process of deep neural networks to identify a face and recognize audio.
Image -> Edges -> Face parts -> Faces -> desired face
Audio -> Low Level sound features (sss, bb) -> Phonemes -> Words -> Sentences
In a Deep Neural Network, the activation from the previous layer is the input to a layer, and its own activations are the output of the layer. We don’t need to write a large number of codes as the more data would give better results. Moreover, the right parameter choice is crucial for the efficiency of the model. During the backpropagation step, the parameters are updated. Hyperparameters of a Deep Neural Network are learning rate, the iteration number, the number of hidden layers, each hidden layer units, and the activation function.
Datasets for Deep Learning
1. MNIST – One of the popular deep learning datasets of handwritten digits which consists of sixty thousand training set examples, and ten thousand test set examples. The time spent in data pre-processing is minimum while you could try different deep recognition patterns, and learning techniques on the real-world data. The size of the dataset if nearly 50 MB.
2. MS-COCO – It is a dataset for segmentation, object detection, etc. The features of the COCO dataset are – object segmentation, context recognition, stuff segmentation, three hundred thirty thousand images, 1.5 million instances of the object, eighty categories of object, ninety-one categories of staff, five per image captions, 250,000 keynotes people. The size of the dataset is 25 GB.
3. ImageNet – An images dataset organized with regards to the WordNet hierarchy. There are one lakh phrases in WordNet and each phrase is illustrated by on average 1000 images. It is a huge dataset of size hundred and fifty gigabytes.
4. VisualQA – The open-ended questions about images is present in this dataset which requires vision and language understanding. The features are – 265,016 COCO and abstract scenes, three questions per image, ten true answers per question, three likely to be correct answers per question, automatic evaluation metric. The size is 25 GB.
5. CIFAR-10 – An image classification dataset consisting of ten classes of sixty thousand images. There are five training batches and one test batch in the dataset and there are 10000 images in each batch. The size is 170 MB.
6. Fashion-MNIST – There are sixty thousand training and ten thousand test images in the dataset. This dataset was created as a direct replacement for the MNIST dataset. The size is 30 MB.
7. Street View House Numbers – A dataset for object detection problems. Similar to MNIST dataset with minimum data pre-processing but more labeled data collected from Google Street viewed house numbers. The size is 2.5 GB.
8. Sentiment140 – It is a Natural Language Processing dataset which performs sentiment analysis. There are six features in the final dataset with emotions removed from the data. The features are – tweet polarity, the id of the tweet, tweet date, query, username, tweet text.
9. WordNet – It’s a large English synsets database which describes a different concept of synonyms. The size is nearly 10 MB.
10. Wikipedia Corpus – It consists of 1.9 billion textual records for more than four million articles. You could search using a phrase, word.
11. Free Spoken Digit – Inspired by MNIST dataset, it was created to identify spoken digits in audio samples. The more people contribute to it, the more it would grow. The characteristics of this dataset are three speakers, fifteen hundred recordings, and English pronunciations. The size of the dataset is nearly 10 MB.
12. Free Music Archive – It is a music analysis dataset which has HQ audio features and user-level metadata. The size is almost 1000 GB.
13. Ballroom – A dancing audio files dataset where in real audio format, many dance styles excerpts are provided. The dataset consists of six hundred and ninety-eight instances, a thirty seconds duration with a total duration of 20940 seconds.
14. Million Song – A million music tracks’ audio features and metadata are present in this dataset. The dataset is an alternative to create large datasets. There is only derived features, but no audio in this dataset. The size is nearly 280 GB.
15. LibriSpeech – It consists of English speech for a thousand hours. The dataset is properly segmented and there are Acoustic models which are trained by this.
16. VoxCeleb – It is a speaker identification dataset extracted from videos in YouTube consisting of one lakh utterances by 1251 celebrities. There is a balanced distributed of gender and a wide range of professions, accents, and so on. The intriguing task is to identify the superstar the voice belongs to.
17. Urban Sound Classification – This dataset consists of 8000 urban sounds excerpts from ten classes. The training size is three GB and the test set is 2 GB.
18. IMDB reviews – For any movie junkie, this is an ideal dataset. Used for binary sentiment classification and has unlabelled data as well apart from train and test review examples. The size is 80 MB.
19. Twenty Newsgroups – Newspaper information is present in the dataset. From twenty different newspapers, 1000 Usenet articles were used. Subject lines, signatures, etc., are some of the features. The size of the dataset is nearly 20 MB.
20. Yelp Reviews – This dataset is for learning the purpose and was released by Yelp. It consists of user reviews and more than twenty thousand pictures. The JSON file size is 2.66 GB, SQL is 2.9 GB. And Photos is 7.5 GB with all compressed together.
Conclusion –
Deep Learning, Artificial Intelligence has revolutionized our world and has solved numerous real-life problems. The unprecedented power of data has been deeply nurtured by the Data Scientists and would continue to do so to make the world an improved and safe place to live in. Every now and then, new developments are coming through and with the ever-increasing capacity of modern computers, the field of exploration is increasing exponentially as well.
As several professionals are trying to enter this field, it is necessary that they learn to programme first, and Python is an ideal language to start off their programming journey.
Dimensionless has several blogs and training to get started with Python, and Data Science in general.
Data Scientist is regarded as the sexiest job of the 21st century. It is a high paying lucrative jobs which comes with a lot of responsibility and commitment. Any professional needs to master state-of-the-art skills and technologies to become a Data Scientist in the modern world. It is a profession where people from different disciplines could fit in as there are a plethora of specialties embedded in a Data Scientist role.
Data Science is not a present-day phenomenon, however. The various skills like Machine Learning, Deep Learning, AI, and so on were there since the advent of computers. The recent hype is a result of the large volumes of data that are getting generated and the massive computation power that modern-day system possess. This has led to the rise of the concept of Big Data which we would cover later in this blog.
Now, the Data Scientist job may look like a Gold to outside but it certainly has its struggles and is not without major challenges. The dynamism of the role requires one to be a master of several skills which becomes overwhelming at times. In this article, we would cover the major challenges faced by a Data Scientist and how you could overcome it.
1. Misconception About the Role –
In big corporations, a Data Scientist is regarded as a jack of all trades who is assigned with the task of getting the data, building the model, and making right business decisions which is a big ask for any individual. In a Data Science team, the role should be split among different individuals such as Data Engineering, Data Visualizations. Predictive Analytics, model building, and so on.
The organization should be clear about their requirement and specialize the task the Data Scientist needs to perform without putting unrealistic expectations on the individual. Though a Data Scientist possesses the majority of the necessary skills, distributing the task would ensure flawless operation of the business. Thus a clear description and communication about the role are necessary before anyone starts working as a Data Scientist in the company.
2. Understanding the Right Metric and The KPI –
Due to the lack of understanding among the majority of stakeholders about the role of Data Scientist, they are expected to wave a magic wand and solve every business problem in a hitch which is never the case. Every business should have the right metric which goes in sync with its objectives. The metric would be parameters to evaluate the performance of the predictive model while the Key Performance Indicators which let the business work on the areas to improve.
A Data Scientist could build a model and gets high accuracy only to realize that the metric used doesn’t help the business at all. Each and every company has different parameters or metrics to identify their performance and thus defining one with clarity before starting any Data Science work is the key. The metrics and the KPIs should be identified and laid out and communicated to the Data Scientist who would then work accordingly.
3. Lack of Domain Knowledge –
This challenge is more applicable to a beginner Data Scientist in an organization than who has more years of experience working as a Data Scientist in the same organization. Someone who is just starting or is a fresh graduate has all the statistical skills and techniques to play with the data but without the right domain understanding, it is difficult to get the right results. A person with a particular domain knowledge who know what works and what doesn’t which is not the cause for a newbie.
Though domain expertise doesn’t come overnight and it takes time spending and working in a particular domain, one could, however, take up datasets across various domains and try to apply their Data Science skills to solve the problem. In doing so, the person would get accustomed to the data across various domains and get an idea about the variables or features that generally used.
4. Setting up the Data Pipeline –
In the modern world, we don’t deal with megabytes of data anymore, instead of with deal with terabytes of unstructured data generated from a multitude of sources. This data is voluminous in nature and traditional systems are incapable of handling such quantity. Hence the concept of Hadoop or Spark came into the picture which stores data in parallel clusters and processes it.
Thus for batch or real-time data processing, it is necessary that the data pipeline is properly set up beforehand to allow the continuous flow of data from external sources to the big data ecosystem which would then enable Data Scientists to use the data and process it further.
5. Getting the Right Data –
Quality is better than quantity is the call of the hour in this case. A Data Scientist role involves understanding the question asked and answer the question by analyzing the data using the right tools and techniques. Now, once the requirement is clear, it’s time to get the right data. There is no shortage of data in the present analytical Eco space but having enough data without much relevance would lead to a model failing to solve the actual business problem.
Thus to build an accurate model which works well with the business it is necessary to get the right data with the most meaningful features at the first instance. To overcome this data issue, the Data Scientist would need to communicate with the business to get enough data and then use domain understanding to get rid of the irrelevant features. This is a backward elimination process but one which often comes handy in most occasions.
6. Proper Data Processing –
A Data Scientist spends most of the time pre-processing the data to make it ideal for building a model. It’s often a hectic task which includes cleaning the data, removing outliers, encoding the variables and so on. Unlike in hackathons or boot camps, the real-life data is generally pretty unclean and it requires a lot of data wrangling using different techniques.
The drawback is that if the model is built on dirty data it would behave strangely when tested on an unknown set of data. Suppose the data has a lot of outliers or noise which are not removed and you train a model with that data, then the model would learn by heart all the unnecessary patterns in the data resulting in high variance. This high variance would cause the model to not generalize well and perform poorly on the new data set. No wonder, Data Scientists spend eighty percent of their time only cleaning the data and making it ready.
To overcome this data pre-processing issue, a Data Scientist should put all the effort in identifying all possible anomalies that could be present in the data and come up with solutions to get rid of those. Once that is done, the model would be trained on cleaned data which would allow it to generalize well to the patterns and get good performance of the test data.
7. Choosing the Right Algorithm –
This a subjective challenge as there is no such algorithm which works best on a dataset. If there is a linear relationship between the feature and the target variables, one generally chooses the linear models such as Linear Regression, Logistic Regression while for non-linear relationship the tree based models like Decision Tree, Random Forest, Gradient Boosting, etc., works better. Hence it is suggested to try different models on a dataset and evaluate based on the metric given. Once which minimizes the mean squared error or has a greater ROC curve is eventually considered to be the go-to model. Moreover the ensemble models i.e., the combination of different algorithms together generally provides better results.
8. Communication of the Results –
Managers or Stakeholders of a company are often ignorant of the tools and the working structure of the models. They are required to make key business decisions based on what they see in front of charts or graphs or the results communicated by a Data Scientist. Communicating the results in technical terms would not help much as people at the helm would struggle to decide what’s being said. Thus one explain in layman terms their findings and even use the metric and the KPIs finalized at the start to present their findings. This would entail the business to evaluate their performance and conclude on what key grounds improvements has to be done for the growth of the business.
9. Data Security –
Data Security is a major challenge in today’s world. The plethora of data sources which are interconnected has made it susceptible to attacks from the hackers. Thus the Data Scientist are struggling to get consent to use the data because of the lack of certainty and the vulnerability that clouds it. Following the global data protection is one way to ensure data security. Use of cloud platforms or additional security checks could also be implemented. Additionally, Machine Learning could be also used to protect against cyber-crimes or fraudulent behaviors.
Conclusion
Despite all the challenges faced, Data Scientist is the most in-demand role in the market and one should not let the challenges be a hindrance to achieve their goal.
As several professionals are trying to enter this field, it is necessary that they learn to programme first, and Python is an ideal language to start off their programming journey.
Dimensionless has several blogs and training to get started with R, and Data Science in general.