International Data Corp. (IDC) expects worldwide revenue for big data and business analytics (BDA) solutions to reach $260 billion in 2022, with a compound annual growth rate (CAGR) of 11.9%. It values the current market at $166 billion, up 11.7% over 2017.
The industries making the largest investments in big data and business analytics solutions are banking, manufacturing, professional services, and government. At a high level, organizations are turning to Big Data and analytics solutions to navigate the convergence of their physical and digital worlds
In this blog, we will be looking into various Big Data solutions provided by AWS(Amazon Web Services). This will give an idea about different services available on AWS for obtaining Big Data capabilities for their Businesses/Organisations.
Also, if you are looking to learn Big Data, then you will really like this amazing course
What is Big Data?
Big data is high-volume, high-velocity and/or high-variety information assets that demand cost-effective, innovative forms of information processing that enable enhanced insight, decision making, and process automation.
Big Data comprises of 4 important V’s which defines the characteristics of Big Data. Let us discuss these ones before moving to AWS
Volume — The name ‘Big Data’ itself is related to a size which is enormous. Size of data plays a very crucial role in determining value out of data. Also, whether a particular data is Big Data or not, is dependent upon the volume of data. Hence, ‘Volume’ is one of the important characteristic while dealing with ‘Big Data’.
Variety — The next aspect of ‘Big Data’ is its variety. Variety refers to heterogeneous sources and the nature of data, both structured and unstructured. During earlier days, spreadsheets and databases were the only sources of data. Nowadays, analysis applications use data in the form of emails, photos, videos, monitoring devices, PDFs, audio, etc. This variety of unstructured-data poses certain issues for storage, mining and analyzing data.
Velocity — The term ‘velocity’ refers to the speed of generation of data. How fast the data is generated and processed to meet the demands, determines real potential in the data. Big Data Velocity deals with the speed at which data flows in from sources like business processes, application logs, networks, and social media sites, sensors, Mobile devices, etc. Also, the flow of data is massive and continuous.
Variability — This refers to the inconsistency which can be shown by the data at times, thus hampering the process of being able to handle and manage the data effectively.
If you are looking to learn Big Data online then follow the link here
What is AWS?
AWS comprises of many different cloud computing products and services. The highly profitable Amazon division provides servers, storage, networking, remote computing, email, mobile development and security. Furthermore. AWS can be split into two main products: EC2, Amazon’s virtual machine service and S3, a storage system by Amazon. It is so large and present in the computing world that it’s now at least 10 times the size of its nearest competitor and hosts popular websites like Netflix and Instagram
AWS is split into 12 global regions, each of which has multiple availability zones in which its servers are located. These serviced regions are split in order to allow users to set geographical limits on their services (if they so choose), but also to provide security by diversifying the physical locations in which data is held.
AWS solutions for Big Data
AWS has numerous solutions for all the development and deployment purposes. Also, in the field of Data Science and Big Data, AWS has come up with recent developments in different aspects of Big Data handling. Before jumping to tools, let us understand different aspects in Big Data for which AWS can provide solutions
Data Ingestion Collecting the raw data — transactions, logs, mobile devices and more — is the first challenge many organizations face when dealing with big data. A good big data platform makes this step easier, allowing developers to ingest a wide variety of data — from structured to unstructured — at any speed — from real-time to batch.
Storage of Data Any big data platform needs a secure, scalable, and durable repository to store data prior to or even after processing tasks. Depending on your specific requirements, you may also need temporary stores for data-in-transit
Data Processing This is the step where data transformation happens from its raw state into a consumable format — usually by means of sorting, aggregating, joining and even performing more advanced functions and algorithms. The resulting data sets undergo storage for further processing or made available for consumption via business intelligence and data visualization tools.
Visualisation Big data is all about getting high value, actionable insights from your data assets. Ideally, data is available to stakeholders through self-service business intelligence and agile data visualization tools that allow for fast and easy exploration of datasets. Depending on the type of analytics, end-users may also consume the resulting data in the form of statistical “predictions” — in the case of predictive analytics — or recommended actions — in the case of prescriptive analytics.
AWS tools for Big Data
In the previous sections, we looked at the fields in Big Data where AWS can provide solutions. Additionally, AWS has multiple tools and services in its arsenal to enable customers with the capabilities of Big Data
Let us look at the various solutions provided by AWS for handling different stages involved in handling Big Data
Ingestion
Kinesis Amazon Kinesis Firehose is a fully managed service for delivering real-time streaming data directly to Amazon S3. Kinesis Firehose automatically scales to match the volume and throughput of streaming data and requires no ongoing administration. Kinesis Firehose is configurable to transform streaming data before it’s stored in Amazon S3. Its transformation capabilities include compression, encryption, data batching, and Lambda functions. Kinesis Firehose can compress data before it’s storage in Amazon S3. It currently supports GZIP, ZIP, and SNAPPY compression formats. GZIP is a better choice because it can be used by Amazon Athena, Amazon EMR, and Amazon Redshift. Kinesis Firehose encryption supports Amazon S3 server-side encryption with AWS Key Management Service (AWS KMS) for encrypting delivered data in Amazon S3
Snowball You can use AWS Snowball to securely and efficiently migrate bulk data from on-premises storage platforms and Hadoop clusters to S3 buckets. After you create a job in the AWS Management Console, a Snowball appliance will be automatically shipped to you. After a Snowball arrives, connect it to your local network, install the Snowball client on your on-premises data source, and then use the Snowball client to select and transfer the file directories to the Snowball device. The Snowball client uses AES-256-bit encryption. No encryption keys with the Snowball device the makes data transfer process is highly secure. After the data transfer is complete, the Snowball’s E Ink shipping label will automatically update. Ship the device back to AWS. Upon receipt at AWS, data transfer takes place from the Snowball device to your S3 bucket and stored as S3 objects in their original/native format. Snowball also has an HDFS client, so data migration may happen directly from Hadoop clusters into an S3 bucket in its native format.
Storage
Amazon S3 Amazon S3 is secure, highly scalable, durable object storage with millisecond latency for data access. S3 can store any type of data from anywhere — websites and mobile apps, corporate applications, and data from IoT sensors or devices. It can also store and retrieve any amount of data, with unmatched availability, and built from the ground up to deliver 99.999999999% (11 nines) of durability. S3 Select focuses on data read and retrieval, reducing response times up to 400%. S3 provides comprehensive security and compliance capabilities that meet even the most stringent regulatory requirements.
AWS Glue AWS Glue is a fully manageable service that provides a data catalogue to make data in the data lake discoverable. Additionally, it has the ability to do extract, transform, and load (ETL) to prepare data for analysis. Also, the inbuilt data catalogue is like a persistent metadata store for all data assets, making all of the data searchable, and queryable in a single view.
Processing
EMR For big data processing using the Spark and Hadoop, Amazon EMR provides a managed service that makes it easy, fast, and cost-effective to process vast amounts data. Furthermore, EMR supports 19 different open-source projects including Hadoop, Spark, and HBase. Also it comes with managed EMR Notebooks for data engineering, data science development, and collaboration. Each project updates in EMR within 30 days of a version release. It ensures you have the latest and greatest from the community, effortlessly.
Redshift For data warehousing, Amazon Redshift provides the ability to run complex, analytic queries against petabytes of structured data. Also, it includes Redshift Spectrum that runs SQL queries directly against Exabytes of structured or unstructured data in S3 without the need for unnecessary data movement. Amazon Redshift is less than a tenth of the cost of traditional solutions. Start small for just $0.25 per hour, and scale out to petabytes of data for $1,000 per terabyte per year.
Visualisations
Amazon QuickSight For dashboards and visualizations, Amazon Quicksight provides you fast, cloud-powered business analytics service. It makes it easy to build stunning visualizations and rich dashboards. Additionally, they can be accessed from any browser or mobile device.
Conclusion
Amazon Web Services provides a fully integrated portfolio of cloud computing services. Furthermore, tt helps you build, secure, and deploy your big data applications. Also, with AWS, there’s no hardware to procure and infrastructure to maintain and scale. Due to this, you can focus your resources on uncovering new insights. With new features added constantly, you’ll always be able to leverage the latest technologies without making long-term investment commitments.
Additionally, if you are interested in learning Big Data and NLP, click here to get started
Furthermore, if you want to read more about data science, you can read our blogs here
Also, the following are some suggested blogs you may like to read
In this data-driven world, Data Analytics has become vital in the decision-making processes in the Banking and Financial Services Industry. Investment banking and other businesses wherein, real-time information is used, volume, as well as the velocity of data, has become critical factors. Also, Data Analytics comes into the picture in cases like this when the sheer volume and size of the data is beyond the capability of traditional databases to collect.
Today, data analytics practices have made the monitoring and evaluation of vast amounts of client data including personal and security information by Banks and other financial organisations much simpler.
In this article, we will further stress down on the different areas in the BFSI domain where we use data sciences to reap huge benefits!
What is the BFSI sector?
BFSI is an acronym for Banking, Financial Services and Insurance and popular as an industry term for companies that provide a range of such products/services and is commonly used by IT/ITES/BPO companies and technical/professional services firms that manage data processing, application testing and software development activities in this domain. Banking may include core banking, retail, private, corporate, investment, cards and the like. Financial Services may include stock-broking, payment gateways, mutual funds etc. Insurance covers both life and non-life.
Data Sciences is allowing the BFSI industry to reach out to new markets and offer novel products and services through efficient delivery channels. Also, data security and availability of information updates is critical to the banking and insurance business, mandating high network uptime, rapid fault detection and quick problem resolution. The banking and financial industry is also challenged by a large number of existing legacy systems in its infrastructure.
Applications of Data Science in Banking Sector
Fraud detection
Machine learning is crucial for effective detection and prevention of fraud involving credit cards, accounting, insurance, and more. Proactive fraud detection in banking is essential for providing security to customers and employees. The sooner a bank detects fraud, the faster it can restrict account activity to minimize loses. By implementing a series of fraud detection schemes banks can achieve the necessary protection and avoid significant loses.
The key steps to fraud detection include:
Obtaining data samplings for model estimation and preliminary testing
Model estimation
Testing stage and deployment.
Since every data set is different, each requires individual training and fine-tuning by data scientists. Transforming the deep theoretical knowledge into practical applications demands expertise in data-mining techniques, such as association, clustering, forecasting, and classification.
Lifetime value prediction
Customer lifetime value (CLV) is a prediction of all the value a business will derive from their entire relationship with a customer. The importance of this measure is growing fast, as it helps to create and sustain beneficial relationships with selected customers, therefore generating higher profitability and business growth.
Acquiring and retaining profitable customers is an ever-growing challenge for banks. As the competition is getting stronger, banks now need a 360-degree view of each customer to focus their resources efficiently. This is where the data science comes in. First, a large amount of data must be taken into account: such as notions of client’s acquisition and attrition, use of diverse banking products and services, their volume and profitability, as well as other client’s characteristics like geographical, demographic, and market data.
Customer segmentation
Customer segmentation means singling out the groups of customers based on either their behaviour (for behavioural segmentation) or specific characteristics (e.g. region, age, income for demographic segmentation). There is a whole bunch of techniques in data scientists’ arsenal such as clustering, decision trees, logistic regression, etc. and, as a result, they help to learn the CLV of every customer segment and discover high-value and low-value segments.
There is no need to prove that such segmentation of clients allows for the effective allocation of marketing resources and the maximization of the point-based approach to each client group as well as selling opportunities. Do not forget that customer segmentation is designed to improve customer service and help in loyalty and retention of customers, which is so necessary for the banking sector.
Applications of Data Science in the Financial Services Sector
Algorithmic trading
This area probably has the biggest impact from real-time analytics since every second is at stake here. Based on the most recent information from analyzing both traditional and non-traditional data, financial institutions can make real-time beneficial decisions. And because this data is often only valuable for a short time, being competitive in this sector means having the fastest methods of analyzing it.
Another prospective opens when combining real-time and predictive analytics in this area. It used to be a popular practice for financial companies have to hire mathematicians who can develop statistical models and use historical data to create trading algorithms that forecast market opportunities. However, today artificial intelligence offers techniques to make this process faster and what is especially important — constantly improving.
Robo-advisory
Robo-advisors are now commonplace in the financial domain. Currently, there are two major applications of machine learning in the advisory domain.
Portfolio management is an online wealth management service that uses algorithms and statistics to allocate, manage and optimize clients’ assets. Users enter their present financial assets and goals, say, saving a million dollars by the age of 50. A robot-advisor then allocates the current assets across investment opportunities based on the risk preferences and the desired goals.
Recommendation of financial products. Many online insurance services use robot-advisors to recommend personalized insurance plans to a particular user. Customers choose robot-advisors over personal financial advisors due to lower fees, as well as personalized and calibrated recommendations.
Applications of Data Science in Insurance Sector
Underwriting and credit scoring
Machine learning algorithms fit perfectly with the underwriting tasks that are so common in finance and insurance.
Data scientists train models on thousands of customer profiles with hundreds of data entries for each customer. A well-trained system can then perform the same underwriting and credit-scoring tasks in real-life environments. Such scoring engines help human employees work much faster and more accurately.
Banks and insurance companies have a large number of historical consumer data, so they can use these entries to train machine learning models. Alternatively, they can leverage datasets generated by large telecom or utility companies.
Auto Insurance
Picture a world in which wireless “telematics” devices transmit real-time driving data back to an insurance company. Now picture a bunch of auto insurers drooling over their desks.
Telematics-based insurance products have been around since 1998 when Progressive first launched them. But technology has come a long way in the intervening years. Telematics devices currently include embedded navigation systems (e.g., GM’s OnStar), on-board diagnostics (e.g., Progressive’s Snapshot) and smartphones.
These can be used to create personalized plans. In a SAS white paper, Telematics: How Big Data is Transforming the Auto Insurance Industry, the authors highlight two of these options:
PAYD: Pay-As-You-Drive
PHYD: Pay-How-You-Drive
PAYD is pretty straightforward. It charges customers based on the number of miles or kilometres driven. Hollard Insurance, a South African insurer, has six mileage options.
But PAYD does not take into account driving habits. PHYD plans use telematics to monitor a wide variety of factors — speed, acceleration, cornering, braking, lane changing, fuel consumption — as well as geo-location, date and time. If an accident occurs, the insurance company has the ability to recreate the situation.
Personalised marketing
The customers are always willing to get personalised services which would match their needs and lifestyle perfectly well. The insurance industry is not an exception in this case. The insurers face the challenge of assuring digital communication with their customers to meet these demands.
Highly personalised and relevant insurance experiences are assured with the help of the artificial intelligence and advanced analytics extracting the insights from a vast amount of the demographic data, preferences, interaction, behaviour, attitude, lifestyle details, interests, hobbies, etc. The consumers tend to look for personalised offers, policies, loyalty programs, recommendations, and options.
The platforms collect all the possible data to define the major customers` requirements. After that, they work on the hypothesis on what will work or won`t work. Here comes the turn to develop the suggestion or to choose the proper one to fit the specific customer, which can be achieved with the help of the selection and matching mechanisms.
Also, the personalisation of offers, policies, pricing, recommendations, and messages along with a constant loop of communication largely contribute to the rates of the insurance company.
BFSI companies using Data Science
BBVA Bancomer is collaborating with an alternative credit-scoring platform Destacame. The bank aims to increase credit access for customers with thin credit history in Latin America. Delta came accesses bill payment information from utility companies via open APIs. Using bill payment behaviour, Destacame produces a credit score for a customer and sends the result to the bank.
JPMorgan Chase launched a Contract Intelligence (COiN) platform that leverages Natural Language Processing, one of the machine learning techniques. The solution processes legal documents and extracts essential data from them. Manual review of 12,000 annual commercial credit agreements would typically take up around 360,000 labour hours. Whereas, machine learning allows to review the same number of contracts in just a few hours.
Wells Fargo uses an AI-driven chatbot through the Facebook Messenger platform to communicate with users and provide assistance with passwords and accounts.
Privatbank is a Ukrainian bank that implemented chatbot assistants across its mobile and web platforms. Chatbots sped up the resolution of general customer queries and allowed to decrease the number of human assistants.
Conclusion
The list of use cases in the Banking and Financial sector is growing day by day. The massive increase in the amount of data to be analysed and acted upon in the Banking and Financial Sector has made it essential to incorporate the implementation of Big Data Analytics. Knowing the importance of data science is crucial in these sectors and should be integrated into all decision-making processes based on actionable insights from customer data. Furthermore, Big Data is the next step in ensuring highly personalised and secure banking and financial services to improve customer satisfaction. In this extremely competitive market, it is essential for companies to invest heavily in Data Analytics.
Data science is a rapidly growing career path in the 21 century. The leaders across all industries, fields, and governments are putting their best minds to the task of harnessing the power of data.
As organizations seek to derive greater insights and to present their findings with greater clarity, the premium placed on high-quality data visualization will only continue to increase.
What are Data Visualisation tools?
Data visualization is a general term that describes an effort to help people understand the significance of data by placing it in a visual context. Patterns, trends and correlations that might go undetected in text-based data can be exposed and recognized easier with data visualization software.
Furthermore, today’s data visualization tools go beyond the standard charts and graphs used in Microsoft Excel spreadsheets, displaying data in more sophisticated ways such as infographics, dials and gauges, geographic maps, sparklines, heat maps, and detailed bar, pie and fever charts.
What is Tableau?
Tableau is a powerful and fastest growing data visualization tool used in the Business Intelligence Industry. It helps in simplifying raw data into the very easily understandable format.
Also, data analysis is very fast with Tableau and the visualizations created are in the form of dashboards and worksheets. The data that is created using Tableau can be understood by professional at any level in an organization. Furthermore, It even allows a non-technical user to create a customized dashboard.
Why Tableau?
1. Tableau makes interacting with your data easy
Tableau is a very effective tool to create interactive data visualizations very quickly. It is very simple and user-friendly. Tableau can create complex graphs giving a similar feel as the pivot table graphs in Excel. Moreover, it can handle a lot more data and quickly provide calculations on datasets.
2. Extensive Data analytics
Tableau allows the user to plot varied graphs which can help in making detailed data visualisations. There are 21 different types of graph among which users can mix match and dish out appealing and informative visualisations. From heat maps, pie chart and bar charts to bubbe graph, Gantt chart and bullet graphs, Tableau has way more lot of visualisations to offer than other data visualisations tool out there
3. Easy Data discovery
Tableau is capable of handling large datasets really well. Handling large dataset is one problem where tools like MS Excel and even R shiny fails to generate visualisation dashboards. Ability to handle such large chunks of data empowers tableau to generate insights out of it. This, in turn, allows users to find patterns and trends in their data. Furthermore, tableau can be connected to multiple data sources be it different cloud providers or databases or data warehouses.
4. No Coding
The one great thing about tableau is that you do not need to code at all to generate powerful and meaningful visualisations. It is all a game of selecting a chart and drag and drop! Being user-friendly allows the user to focus more on visualisations and storytelling through it rather than handling all the coding aspects around it.
5. Huge Community
Tableau boasts of a large user community which works for solving doubts and problems faced while using Tableau. Having such large community support helps users to find answers to their queries and issues faced while using Tableau. One does not need to worry about having less learning material too.
6. Proved to have satisfied customers
Tableau users are genuinely happy with the product. For example, the yearly Gartner research about Business Intelligence and Analytics Platforms, based on the user feedback, indicates Tableau´s success and ability to deliver a genuinely user-friendly solution for the customers. We have noticed the same enthusiasm and positive feedback about Tableau among our customers.
7. Mobile support
Tableau provides mobile support for the dashboards. So you do not need to confine to just desktop and laptops but can develop visualisations on the fly using Tableau
Tableau in fortune 500 companies
LinkedIn
LinkedIn has over 460 million users. The business analytics team of LinkedIn’s salesforce is massively using Tableau to process petabytes of customer data. They access Tableau server on a weekly basis by 90% of LinkedIn’s salesforce. Furthermore, sales analytics can measure performance and gauge the churn using Tableau dashboards. Higher revenue, therefore, results due to a more proactive sales cycle. Michael Li, Senior Director of Business Analytics at LinkedIn believes that LinkedIn’s analytics portal is the go-to destination for salespeople to get what they require to convey that information that is exactly required by the clients.
Cisco
Cisco uses Tableau software to work with 14,000 items to evaluate Product Demand Variability, match distribution centres with customers, depict the flow of goods through the supply chain network, assess the location and spend within the supply chain. Tableau strikes a balance of a sophisticated network of suppliers to the end customer. This looks after inventory and reduces order-to-ship cycle. Also, Cisco uses Tableau server to spread the content gracefully. It helps to create the right message, streamline the data, drive the conception and also in the scaling of data.
Deloitte
Deloitte uses Tableau to help customers implement self-reliant data-driven culture which is also agile which can garner high business value from enterprise data. Higher signal detection abilities and real-time interactive dashboards are available to an enterprise by Deloitte that allow their clients to assess huge complex datasets with high efficiency and greater ease of use. Furthermore, there are more than 5000 Deloitte employees who are trained in Tableau and are successfully delivering high-end projects.
Walmart
Walmart considers it was a good move shifting to rich vivid visualizations that can be modified in real time and shared easily from Excel sheets. Furthermore, they found that people responded better when there is more creativity, the presentation would turn to be good, and executives receive it better. Rather than a datasheet, Tableau is used to convey data story more effectively. Also, they had built dashboards which could be accessible to the entire organization. Over 5000 systems have Tableau desktop in Walmart and it is doing great with this BI tool.
Conclusion
After reading this list we hope you are ready to conquer the world of data with Tableau. To help you to just do it, we offer data science courses including Tableau. Also, you can view the course here.
Additionally, if you are interested in learning Big Data and NLP, click here to get started
Furthermore, if you want to read more about data science, you can read our blogs here
Also, the following are some suggested blogs you may like to read
Data Science has been a buzzword for a while now with more people aiming to look ahead for the career opportunities it provides. Additionally, if you are looking for a career change to data science or you want to build a career in it or you are really passionate about it, then Dimensionless Technologies has some great courses just for you
Also, Dimensionless Tech provides best online data science training that provides in-depth course coverage, case study based learning, entirely Hands-on driven sessions with personalised attention to every participant. But we provide only instructor-led LIVE online training sessions and not classroom training.
Furthermore, we present you top courses in data science that you should take in 2019. Moreover, these courses have been picked based on their popularity and exhaustiveness in covering data science syllabus. Also, you can have a sneak peek into how we conduct classes at Dimensionless which will help you make a wiser choice ahead.
Demo tutorial: Link
Online Courses
1. Stanford’s Foundation for Data Science
You can break into the rapidly growing field of data science with Stanford University’s Foundations for Data Science professional program. Additionally, it comprises of three comprehensive and introductory online courses. Moreover, this program will teach you the foundational programming and statistics skills you need to kick-start a career in data science — no prior experience necessary.
Also, you get to learn from Stanford faculty with step-by-step instructions, listen to insights from industry experts, and develop your understanding through case studies and real-world examples. Additionally, the program includes ungraded programming exercises to help build and practice your skills. No final exam or capstone project is required.
Furthermore, you can find more about the program from the below link
Additionally, over the course of seven weeks, you will take your data analytics skills to the next level as you learn the theory and practice behind recommendation engines, regressions, network and graphical modelling, anomaly detection, hypothesis testing, machine learning, and big data analytics.
Also, you can enrol for the course using the below link
Link: https://bigdataanalytics.mit.edu/
Dimensionless Technologies-Data Science using R and Python
Dimensionless Technologies provides best online data science training that provides in-depth course coverage, case study based learning, entirely Hands-on driven sessions with personalized attention to every participant. But we provide only instructor-led LIVE online training sessions and not classroom training. Although, this one is not a free course as compared to the above ones but has good ROI. Additionally, the course is suitable for the beginners who are looking to make a career in data science as course covers all the important concepts in great detail along with their practical applications. Also as compared to the above courses, this course is based on the live interaction of students and teachers online rather than having pre-recorded videos through which one can clear their doubts very easily
This is our complete data science course which is specifically designed for all the people looking for a career in the data science. Furthermore, this course requires no pre-requisites and walks learners from basics to depth in every topic.
This course includes
1. Descriptive Statistics(Variability, Distributions, Central tendency etc)
2. Inferential Statistics(Hypothesis Testing, ANOVA, Regression, T-tests etc)
3. R (functions, libraries, dplyr, apply etc)
4. Python (Functions, pandas, numpy, sci-kit learn etc)
5. Machine Learning (Regression, SVM, Naive Bayes, Time Series Forecasting etc)
6. Tableau
7. Final Project
Data is everywhere and there is a lot of it actually. Also, Big Data gives us the capability to work on this large amount of data. This course is designed for learners who want to understand how data science is applied in the industry over the big data setup. Also, this course will help learners to understand Natural Language Processing and making learners perform analytics when encountered with a lot of textual data
This course includes
1. Spark basics and its architecture
2. Data Manipulation with Spark
3. Applied Machine Learning with Spark
4. Text Processing using NLTK
5. Building Text Classifiers with Machine Learning
6. Semantic Analysis
Machine Learning has been booming off late. This course is designed for all the people who are looking for machine learning engineer profile. Furthermore, this covers the concept starting from the basics of neural networks to building them to solve different case studies
This course includes
1. Understanding Neural networks and Deep Learning
2. Tuning Deep Neural Networks
3. Convolutional Neural Networks
4. Recursive Neural Network
Also, you can enrol for the courses here
Link: https://dimensionless.in
3. University of Michigan -Data Science Course
The mission of the University of Michigan is to serve the people of Michigan and the world through preeminence in creating, communicating, preserving and applying knowledge, art, and academic values. Also, it believes in developing leaders and citizens who will challenge the present and enrich the future.
This course will introduce the learner to the basics of the Python programming environment, including fundamental python programming techniques such as lambdas, reading and manipulating CSV files, and the numpy library. Also, the course will introduce data manipulation and cleaning techniques using the popular python pandas data science library and introduce the abstraction of the Series and DataFrame as the central data structures for data analysis, along with tutorials on how to use functions such as groupby, merge, and pivot tables effectively. Furthermore, by the end of this course, students will be able to take tabular data, clean it, manipulate it, and run basic inferential statistical analyses.
Additionally, the course covers
Introduction to Data Science in Python
Applied Plotting, Charting & Data Representation in Python
Machine Learning in Python
Text Mining in Python
Social Network Analysis in Python
Also, you can enrol for the course using below link
4. John Hopkins University- Data Science Specialisation
This Specialization covers the concepts and tools you’ll need throughout the entire data science pipeline, from asking the right kinds of questions to making inferences and publishing results. Also, in the final Capstone Project, you’ll apply the skills learned by building a data product using real-world data. At completion, students will have a portfolio demonstrating their mastery of the material.
The specialisation covers
The Data Scientist’s Toolbox
R Programming
Getting and Cleaning Data
Exploratory Data Analysis
Reproducible Research
Statistical Inference
Regression Models
Practical Machine Learning
Developing Data Products
Also, you can find more about it on the below link
Data Science has been ranked as one of the hottest professions and the demand for data practitioners is booming. Furthermore, this Professional Certificate from IBM is intended for anyone interested in developing skills and experience to pursue a career in Data Science or Machine Learning.
Additionally, this program consists of 9 courses providing you with latest job-ready skills and techniques covering a wide array of data science topics including open source tools and libraries, methodologies, Python, databases, SQL, data visualization, data analysis, and machine learning. Also, you will practice hands-on in the IBM Cloud using real data science tools and real-world data sets.
This specialisation includes
Introduction to Data Science
Open source tools for Data Science
Data Science methodology
Python for Data Science
Database and SQL for Data Science
Python for Data Analysis
Data Visualisation in Python
Machine Learning in Python
Also, you can read more about the course on the below link
In this blog, we discussed top courses you can take for Data Sciences in 2019. Furthermore, all these courses are highly rated by students worldwide. Also, they have been provided by the institutes renowned across the globe. Although most of the courses above offer certification from an international institution, they may not be a feasible choice when running on a budget. In contrast, Dimensionless technologies have the right courses, in your budget, for you if you are aiming to kick-start your career in the field of data science. Not only we cover all the important concepts and technologies but also focus on their implementation and usage in real-world business problems. Also, you can follow the link to register yourself for the free demo of the courses!
Also, you can read more on data science in our blog section here. Furthermore, you can have a look at some of the suggested blogs below
Are you from a computer science background and moving into data science? Are you planning to learn coding being from a non-programming background in data science? Then you need not worry because in this blog we will be talking about the importance of computer science in the data science world. Furthermore, we will also be looking at why is it necessary to be fluent with coding(basic at least) in the data science world.
Before enumerating the role of computer science in the data science world, let us clear our understanding of the above two terms. This will allow us to be on the same page before we reason out the importance of coding in data science.
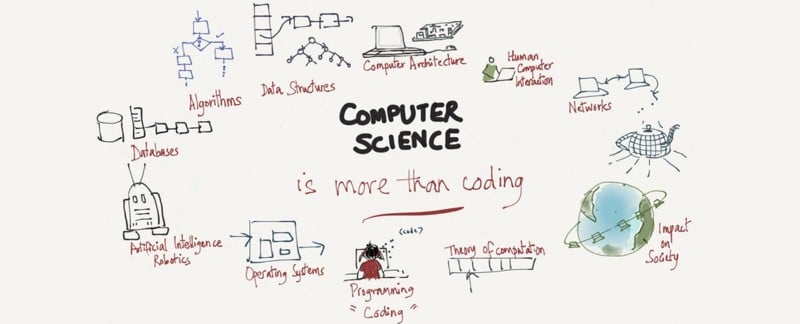
What is Computer Science
Computer Science is the study of computers and computational systems. Unlike electrical and computer engineers, computer scientists deal mostly with software and software systems; this includes their theory, design, development, and application.
Principal areas of study within Computer Science include artificial intelligence, computer systems, and networks, security, database systems, human-computer interaction, vision and graphics, numerical analysis, programming languages, software engineering, bioinformatics and theory of computing.
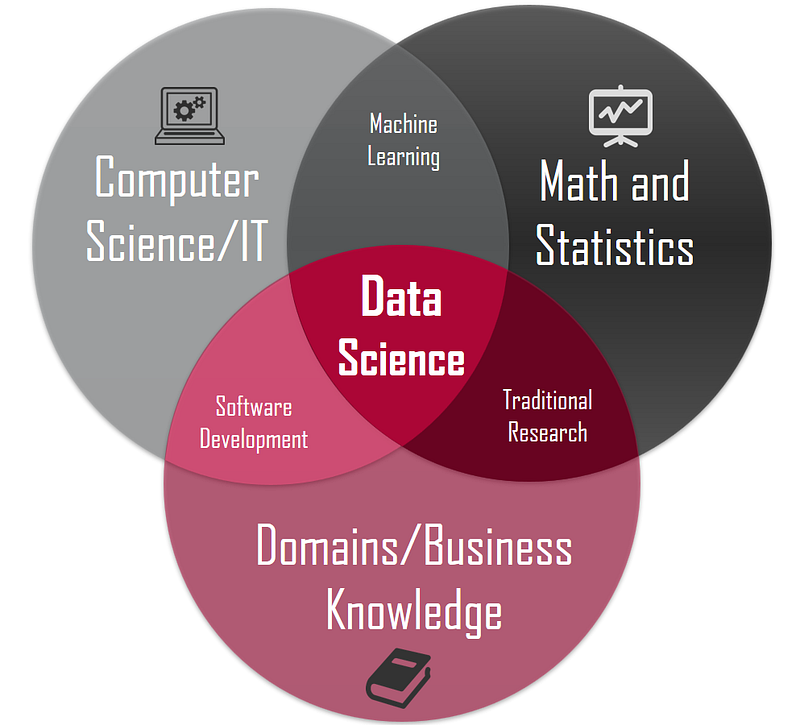
What is Data Science
Data science is the umbrella under which all these terminologies take the shelter. Data science is a like a complete subject which has different stages within itself. Suppose a retailer wants to forecast the sales of an X item present in its inventory in the coming month. This is known as a business problem and data science aims to provide optimized solutions for the same.
Data science enables us to solve this business problem with a series of well-defined steps.
1: Collecting data 2: Pre-processing data 3: Analysing data 4: Driving insights and generating BI reports 5: Taking decision based on insights
Generally, these are the steps we mostly follow to solve a business problem. All the terminologies related to data science falls under different steps which we are going to understand just in a while. Different terminologies fall under different steps listed above.
Data science as you can see is an amalgamation of Business, maths and computer science. A computer engineer is familiar with the entire CS aspect of it and much of maths sections is also covered. Hence, there is no denying fact that Computer science engineers will have a little advantage while beginning their career as data scientists.
Application of computer science in data science
After understanding the difference between Computer Science and Data Science, we will look at the areas in data science where computer science is employed
Data Collection (Big data and data engineering)
Computer science gives you an edge in understanding and working hands-on with aspects of BIG Data. Big data works mainly on important concepts like map-reduce, master-slave concepts etc. These concepts are something by which most of the computer engineers are aware of. Hence, familiarity with these concepts enables a head start in learning these technologies and using them effectively for the complex cases.
Data Pre-Processing (Cleaning, SQL)
Data extraction involves heavy usage of SQL in data sciences. SQL is one of a primary skill in data sciences. SQL is something which is never an alien term to Computer Engineers as most of them are/should be adept in it. Computer science engineers are taught the databases and their management in and out and hence knowledge of SQL is elementary to them.
Analysis(EDA etc)
For data analysis, knowledge of one of the programming language (R or Python mostly)is elementary. Being proficient in one of these languages grants the learner an ability to quickly get started with complex ETL operations. Additionally, the ability to understand and implement code quickly can enable you to go one extra mile while doing your analysis. Also, it reduces your time spent on such tasks as one is already through all the basic concepts.
Insights( Machine Learning/Deep Learning)
Computer scientists invented the name machine learning, and it’s part of computer science, so in that sense, it’s 100% computer science. Furthermore, computer scientists view machine learning as “algorithms for making good predictions.” Unlike statisticians, computer scientists are interested in the efficiency of the algorithms and often blur the distinction between the model and how the model is fit. Additionally, they are not too interested in how we got the data or in models as representations of some underlying truth. For them, machine learning is black boxes making predictions. And computer science has, for the most part, dominated statistics when it comes to making good predictions.
Visual Reports(Visualisations)
Visualizations are an important aspect of data science. Although Data science has multiple tools available for visualization, complex representation requires that extra coding effort. Complex enhancements in visualizations may require some technical aspect of changing few extra parameters of the base library or even the framework you are working with.
Pros of Computer Science knowledge in Data Science
Headstart with all technical aspect of data science
Ability to design, scale and optimise technical solutions
Interpreting algorithm/tool behaviour for different business use cases
Bringing a fresh perspective of looking at a business problem
Proficiency with most of the hands-on coding work
Cons of Computer Science knowledge in Data Science
May end up with a fixed mindset of doing things the “Computer Science” way.
You have to catch up with a lot of business knowledge and applications
Need to pay greater attention to maths and statistics as they are vital aspects of data science
Conclusion
In this blog, we had a look at the various application of computer science in the data science industry. No wonder that because of multiple applications of computer science in the data science industry, computer engineers find it easy, to begin with. Also, at no point in time, we imply that only computer science graduates can excel in the data science domain. Although, being a bachelor in computer science has its own perils in the science field. But, it also comes with its own set of disadvantages like lack of business knowledge and statistics. Anyone can excel in data science who can master all three aspects of it regardless of their bachelor degrees. All you need is right guidance outside and motivation within. Additionally, we at Dimensionless Technologies, provide hands-on training on Data Science, Big Data and NLP. You can check our courses here.
Furthermore, for more blogs on data science, visit our blog section here.
Also, you may also want to have a look at some of our previous blogs below.