Part 1: Data Cleaning and Exploratory Data Analysis
Predicting whether an SMS is a spam
Natural language processing (NLP) is a subfield of computer science and artificial intelligence concerned with the interactions between computers and human (natural) languages.
When I first began learning NLP, it was difficult for me to process text and generate insights out of it. Before actually diving deep into NLP, I knew some of the basic techniques in NLP before but never could connect them together to view it as an end to end process of generating insights out of the text data.
In this blog, we will try to build a simple classifier using machine learning which will help in identifying whether a given SMS is a spam or not. Parallely, we will also be understanding a few basic components of Natural Language Processing (NLP) for the readers who are new to natural language processing.
Building SMS SPAM Classifier
In this section, we will be building a spam classifier step by step.
Step 1: Importing Libraries
We will be using pandas, numpy and Multinomial naive Bayes classifier for building a spam detector. Pandas will be used for performing operations on data frames. Furthermore using numpy, we will perform necessary mathematical operations.
from sklearn.naive_bayes import MultinomialNB
import pandas as pd
import numpy as np
Step 2: Reading the dataset and preparing it for basic processing in NLP
First, we read the csv using pandas read_csv function. We then modify the column names for easy references. In this dataset, the target variable is categorical (ham, spam) and we need to convert into a binary variable. Remember, machine learning models always take numbers as input and not the text hence we need to convert all categorical variables into numerical ones.
We replace ham with 0 (meaning not a spam) and spam with 1 (meaning that the SMS is a spam)
## Reading the dataset as a csv file
training_dataset = pd.read_csv("spam.csv", encoding="ISO-8859-1")
## Renaming columns
training_dataset.columns=["labels","comment"]
## Adding a new column to contain target variable
training_dataset["b_labels"] = [0 if x=="ham" else 1 for x in final_data["labels"] ]
Y = training_dataset["b_labels"].as_matrix()
training_dataset.head()
Step 3: Cleaning Data
Well, Cleaning text is one of the interesting and very important steps before performing any kind of analysis over it. Text from social media and another platform may contain many irregularities in it. People tend to express their feeling while writing and you may end up with words like gooood or goood or goooooooooooood in your dataset. Essentially all are same but we need to regularize this data first. I have made a function below which works fairly well in removing all the inconsistencies from the data.
Clean_data() function takes a sentence as it’s input and returns a cleaned sentence. This function takes care of the following
Removing web links from the text data as they are not pretty much useful
Correcting words like poooor and baaaaaad to poor and bad
Removing punctuations from the text
Removing apostrophes from the text to correct words like I’m to I am
Correcting spelling mistakes
Below is the snippet for clean_data function
def clean_data(sentence):
## removing web links
s = [ re.sub(r'http\S+', '', sentence.lower())]
## removing words like gooood and poooor to good and poor
s = [''.join(''.join(s)[:2] for _, s in itertools.groupby(s[0]))]
## removing appostophes
s = [remove_appostophes(s[0])]
## removing punctuations from the code
s = [remove_punctuations(s[0])]
return s[0]
Function to remove punctuations from the sentence
def remove_punctuations(my_str):
punctuations = '''!()-[]{};:'"\,./?@#$%^&@*_~'''
no_punct = ""
for char in my_str:
if char not in punctuations:
no_punct = no_punct + char
return no_punct
Function to remove apostrophes from the sentences
def remove_appostophes(sentence):
APPOSTOPHES = {"s" : "is", "re" : "are", "t": "not", "ll":"will","d":"had","ve":"have","m": "am"}
words = nltk.tokenize.word_tokenize(sentence)
final_words=[]
for word in words:
broken_words=word.split("'")
for single_words in broken_words:
final_words.append(single_words)
reformed = [APPOSTOPHES[word] if word in APPOSTOPHES else word for word in final_words]
reformed = " ".join(reformed)
return reformed
Example of using the clean_data function
## Sample Sentence to be cleaned
sentence="Goooood Morning! My Name is Joe & I'm going to watch a movie today https://youtube.com. ##"
## Using clean_data function
clean_data(sentence)
## Output
## good morning my name is joe i am going to watch a movie today
Now in order to process and clean all the text data in our dataset, we iterate over every text in the dataset and apply the clean_data function to retriever cleaner texts
for index in range(0,len(training_dataset["comment"])):
training_dataset.loc[index,"comment"] = clean_data(training_dataset["comment"].iloc[index])
Step 4: Understanding text data and finding Important words
After cleaning our text data, we want to analyze it but how de analyze text data? In the case of numbers, we could have gone with finding out mean, median, standard deviation, and other statistics to understand the data but how do we go about here?
We can not take a whole sentence up and generate meaning from it. Although, we can take words from those sentences and try to find out words that are frequently occurring in the text document or finding out the words which hold relatively higher importance in helping us understand what the complete sentence is about. In case of identifying a message as spam, we need to understand that are there any specific words or sequence of words that determine whether an SMS is a spam or not.
Tokenization and Lemmatization
We start by breaking each sentence into individual words. So a sentence like “Hey, You are awesome” will be broken into individual words into an array [‘hey’, ‘you’, ‘are’, ‘awesome’]. This process is known as tokenization and every single word is known as tokens. After getting each token, we try to get each token into its most basic form. For example, words like studies and goes will become study and go respectively. Also, remember that we need to remove stopwords like I, you, her, him etc as these words are very frequent in the text and hardly lead to any interpretation about any message being a spam or not!
Given below, I have made a tokenizer function which will take each sentence as input. It splits the sentence into individual tokens and then lemmatizes those words. In the end, we remove stop words from the tokens we have and return these tokens as an array.
def my_tokeniser(s):
s = clean_data(s)
s = s.lower()
tokens = nltk.tokenize.word_tokenize(s)
tokens = [t for t in tokens if len(t)>2]
tokens = [wordnet_lemmatizer.lemmatize(t) for t in tokens]
tokens = [t for t in tokens if t not in stopwords]
return tokens
Example showing the working of my_tokeniser function
## Sample Sentence
sentence="The car is speeding down the hill"
## Tokenising the sentence
my_tokeniser(sentence)
## Output
Array: ["car", "speed", "down", "hill"]
Understanding n-grams
An n-gram is a contiguous sequence of n items from a given sequence of text. Given a sentence, swe can construct a list of n-grams from s finding pairs of words that occur next to each other. For example, given the sentence “I am Kartik” you can construct bigrams (n-grams of length 2) by finding consecutive pairs of words which will be (“I”, “am”), (“am”, “Kartik”).
A consecutive pair of three words is known as tri-grams. This will help us to understand how exactly a sequence of tokens together determines whether an incoming message is a spam or not. In natural language processing (NLP), n-grams hold a lot of importance as they determine how sequences of words affect the meaning of a sentence.
We will be finding out most common bi-grams and tri-grams from the messages we have in the dataset separately for both spam and non-spam messages and consecutively will have a look at most commonly occurring sequences of text in each category.
Code for finding out bi-grams and tri-grams
Below is a python function which takes two input parameters i.e. label and n. The “label” parameter is the target label of the message. For spam messages, it is 1 whereas for non-spam messages it is 0. The “n” parameter is for selecting whether we want to extract bi-grams out or tri-grams out from the sentences. A too much high value for n will not make any sense as long sequences of text are majorly not common throughout the data
def get_grams(label,n):
bigrams = []
for sentence in training_dataset[training_dataset["Sentiment"]==sentiment_label]["Phrase"]:
tokens = my_tokeniser(sentence)
bigrams.append(tokens)
bigrams_final=[]
bigrams_values=0
bigrams_labels=0
if(n==2):
for bigram in bigrams:
for i in range(0,len(bigram)-1):
bigram_list_basic=bigram[i]+" "+bigram[i+1]
bigrams_final.append(bigram_list_basic)
else:
for bigram in bigrams:
for i in range(0,len(bigram)-2):
bigram_list_basic=bigram[i]+" "+bigram[i+1]+" "+bigram[i+2]
bigrams_final.append(bigram_list_basic)
bigrams_final = pd.DataFrame(bigrams_final)
bigrams_final.columns=["bigrams"]
bigrams_values=bigrams_final.groupby("bigrams")["bigrams"].count()
bigrams_labels=bigrams_final.groupby("bigrams").groups.keys()
bigrams_final_result = pd.DataFrame(
{
"bigram":[*bigrams_labels],
"count":bigrams_values
}
)
return bigrams_final_result
We will call the below function to directly plot all the common bigrams or trigrams as a word cloud. This function calls the above function to get all the bi_grams or tri_grams from the messages we have and will then plot it
Visualizing most frequent trigrams for non-spam messages
plot_grams(spam_label=0, gram_n=3)
Visualizing most frequent trigrams for spam messages
plot_grams(spam_label=1, gram_n=3)
Conclusion
Till now we have learned how to start with cleaning and understanding data. This process needs to be done before any kind of text analysis. One should always start with cleaning the text and then move on to fetch tokens out of the text. Getting tokens out of the text also requires to exclude stop words. Also, we need to get all the other words into their basic morphological form using lemmatization. In the next blog, we will have a look at finding out important words from the text data. We will also learn the word embeddings. In the end, we will finally build a classifier to segregate spam SMS out.
More organizations are adopting data-driven and technology-focused approaches to business and hence the need for analytics expertise continues to grow. As a result, career opportunities in analytics are around every corner. Due to this identifying analytics talent has become a priority for companies in nearly every industry, from healthcare, finance, and telecommunications to retail, energy, and sports.
In this blog, we will be talking about different career paths and option in the Business Analytics field. Furthermore, we will be discussing the qualifications required for being a business analyst and what are the primary roles a Business Analyst handles at a firm
In this blog, we will be discussing
Who are Business Analyst
Qualifications required for BA role
Career options in BA role
Career growth in BA role
Responsibilities of a Business Analyst
Expected Salary Packages in BA
Who are Business Analyst
Business analysts, also known as management analysts, work for all kinds of businesses, nonprofit organizations, and government agencies. Certainly, job functions can vary depending on the position, the work of business analysts involves studying business processes and operating procedures in search of ways to improve an organization’s operational efficiency and achieve better performance. Simply put, a Business Analyst is someone who works with people within an organization to understand their business problems and needs and then to interpret, translate and document those business needs in terms of specific business requirements for solution providers to implement.
Qualifications required to become a Business Analyst
Most entry-level business analyst positions require at least a bachelor’s degree. Therefore beginning Business Analysts need to have either a strong business background or extensive IT knowledge. Likewise, you can start to work as a business analyst with job responsibilities that include collecting, analyzing, communicating and documenting requirements, user-testing and so on. Entry-level jobs may include industry/domain expert, developer, and/or quality assurance.
With sufficient experience and good performance, a young professional can move into a junior business analyst position. In contrast, some choose instead to return to school to get master’s degrees before beginning work as business analysts in large organizations or consultancies.
Skills required to be a Business Analyst
Professional business analysts play a critical role in a company’s productivity, efficiency, and profitability. Hence, essential skill sets range from communication and interpersonal skills to problem-solving and critical thinking. Let us discuss each in a bit more detail
Communication Skills
First of all, Business analysts spend a significant amount of time interacting with clients, users, management, and developers. Therefore, being an effective communicator is key. You will be expected to facilitate work meetings, ask the right questions, and actively listen to your colleagues to take in new information and build relationships.
Problem-Solving Skills
Every project you work on is, at its core, is around developing a solution to a problem. Business analysts work to build a shared understanding of problems, outline the parameters of the project, and determine potential solutions. Hence, problem-solving skill is a must-have for this job position.
Negotiation Skills
A business analyst is an intermediary between a variety of people with various types of personalities: clients, developers, users, management, and IT. Therefore, you have to be able to achieve a profitable outcome for your company while finding a solution for the client that makes them happy. This balancing act demands the ability to influence a mutual solution and maintaining professional relationships.
Critical Thinking Skills
Business analysts must assess multiple choices before leading the team toward a solution. Effectively doing so requires a critical review of data, documentation, user input surveys, and workflow. They ask probing questions until every issue is evaluated in its entirety to determine the best conflict resolution. Therefore, critical thinking skill is a must have pre-requisite for this job position.
Career options in BA role
A career path of a business analyst usually begins with working at an entry level, and gradually with experience and with acquiring a better understanding of how businesses function, growing up the ladder.
Also, Business Analysts enjoy a seamless transition to different roles according to one’s interest because the profession consists of a set of skills which are highly specialized and can be applied to any industry and to any subject matter area successfully. As a result, this allows for the Business Analyst to move between industry, company and subject matter area with ease which becomes their career progression and a focus of professional development.
Other roles that one can take up after gaining experience as a Business Analyst can be
Operations Manager
Product Owner
Management Consultant
Project Manager
Subject Matter Expert
Business Architect
Program Manager
Career growth in BA role
Once you have several years of experience in the industry, you will finally reach a pivotal turning point where you can choose the next step in your business analyst career. After three to five years, you can be positioned to move up into roles such as IT business analyst, senior/lead business analyst or product manager.
But broadly beyond all the fancy names given to designations, we can consider four levels of professional analytics roles:
Level 1: The Business Analyst
Analyzes information for patterns and trends
Applies analytics to solve business problems
Identifies processes and business areas in need of improvement
Level 2: The Data Scientist
Builds analytics models and algorithms
Implements technical solutions to solve business problems
Extracts meaning from and interprets data
Level 3: The Analytics Decision Maker
Leverages data to influence decision-making, strategy, and operations
Explores and integrates the use of data to gain competitive advantages
Uses analytics to drive growth and create better organizational outcomes
Level 4: The Analytics Leader
Leads advanced analytics projects
Aligns business and analytics within the organization
Oversees data management and data governance
Responsibilities of a Business Analyst
Modern Analyst identifies several characteristics that make up the role of a business analyst as follows:
Working with the business to identify opportunities for improvement in business operations and processes
Involved in the design or modification of business systems or IT systems
Interacting with the business stakeholders and subject matter experts in order to understand their problems and needs
The analyst gathers, documents, and analyzes business needs and requirements
Solving business problems and, as needed, designs technical solutions
The analyst documents the functional and, sometimes, technical design of the system
Interacting with system architects and developers to ensure the system is properly implemented
Test the system and create system documentation and user manuals
Expected Salary Packages of BA
The average salary of a business analyst in India is around 6.5 L.P.A. As one continues to gain the experience in this field, the salary gets more lucrative.
The more experience you have as a business analyst, the more likely you are to be assigned larger and/or more complex projects. After eight to 10 years in various business analysis positions, you can advance to chief technology officer or work as a consultant. You can take the business analyst career path as far as you would like, progressing through management levels as far as your expertise, talents, and desires take you.
Conclusion
So with so many interesting, promising and rewarding options available for Business Analysts, they need to first get a firm hold about the basics of data analysis. You can also have a look at this post to know more about what are the different components in data science. It will help you to boost your business analyst career.
We, at Dimensionless Technologies, offer data science course which helps to make you industry ready. Do go through our website and let us know how we may help you.
The Harvard Business Review called the data scientist ‘the sexiest job of the 21st century’. As problem solvers and analysts, data scientists are the professionals identifying patterns, noticing trends and making new discoveries, often working with real-time data, machine learning, and AI.
Data scientists are in high demand, with forecasts from IBM suggesting that the number of data scientists will reach 28 percent by 2020. In the US alone, the number of roles for all US data professionals will reach 2.7 million. Also, powerful software programmes have given us access to deeper analytics than ever before. This analysis of data generated by people, places and things is a goldmine of invaluable insight
With the increase in demand, many people are rushing into the data science track. With the large influx of people into this field and most of them being freshers, people are committing many basic mistakes while progressing in their data science career.
10 Common Mistakes to Avoid to Master Data Science
In this blog, we will be looking at some of the very common mistakes that all of us as data scientists make. We will also try to address these issues with probable solutions to them.
Spending a lot of time learning concepts without any practical application All the work and no play makes Jack a dull boy! You may have heard of this during your childhood days and trust me, it significantly holds true in data science too. Learning too much theory and not applying them does more harm than good. The theory is designed as keeping the ideal conditions in mind but these things do not hold practical with real-world problems. For example, you learn to apply a specific algorithm to solve a problem. The algorithm takes some parameters as input which is there with you while learning theory. But, in real-world situations, half of those required parameters will be missing and then there will be a challenge to apply that algorithm to solve a given problem at hand. A good data scientist is one who knows how to handle real-world data and constraints and generate usable insights out of it rather than a one who has a lot of knowledge but no experience in implementing them. I am surely not saying that going over a lot of theory is bad, what I am saying is collecting a lot of theory in your mind and not applying it anywhere is worseSolution – Your learning process should be a mix of both theory and practice. Whenever you learn something new, try to find a dataset and apply it over there. Take part in different competitions on websites like kaggle because you will not only learn more here but also will gain experience with the implementation of different concepts
2. Directly jumping to Machine Learning and (fancy) algorithms Let us all clear this misconception first that machine learning is not everything data science has to offer. Data science is all about solving a given problem. It is a process which starts with understanding the problem and collecting data for the same to delivering insights and solutions for the problem. Between this, machine learning is a small portion(borrowed from computer science field) which helps in making predictions or wiser judgments with the data at hand. Many people directly jump to machine learning or give a lot of importance to it but this should not be the case. It is still ok if you want to be a machine learning engineer in the future but definitely not ok for a data scientist. Machine learning is not everything which data science has to offer. There are statistics, domain knowledge and communication skills attached to it too.
Solution – The solution here is pretty simple. First, if you are really interested in machine learning, you should focus on its internal math also. You should first ensure you have a good grasp of linear algebra and calculus before directly deep diving into the machine learning. Secondly, one should pay attention to other aspects of data science and should focus on problem understanding more than applying a fancy algorithm to solve it.
3. Considering model accuracy to be supreme Accuracy isn’t always what the business is after. Sure a model that predicts employee retention probability with 95% accuracy is good, but if you can’t explain how the model got there, which features led it there, and what your thinking was when building the model, your client will reject it. Accuracy sue is important but interpretability holds more importance. Maybe this is the case why deep neural networks are rarely used in the production given they are not highly interpretable.
Solution – You can have a trade-off between accuracy and interpretability of the model. Try to understand how much accuracy fits in the domain of the business problem and whether the client is interested more in results or understanding of the problem and factors related to it
4. More attention to tools rather than the problem at hand In data science, tools are not important but the solution to the problem is. It does not matter how you get to the solution considering tools in hand. Tools are for the purpose of making life easier and enabling one to perform tasks quickly hence one should not pay large attention to the usage of tools. For example, one should not try to fit in machine learning everywhere uselessly. Having a solid knowledge of tools and libraries is excellent, but it will only take you so far. Combining that knowledge with the business problem posed by the domain is where a true data scientist steps in. You should be aware of at least the basic challenges in the industry you are interested in (or are applying to). Solution – Search for datasets in a specific industry and try to work on them. This will create an impact on your resume. You should also focus on having domain knowledge of the problem you are trying to solve
5. Trying to learn everything at once This is one of the most common mistakes many data scientists end up doing. Being a jack of all trades and master of none may give your knowledge a lot of breadths and but you will always lack the required depth. You will be able to start an approach to provide a solution to the problem but it will be very rare that you will till the end of it properly. One can not learn everything in one go. Solution- Try to find an area of deeper interest within data science and try getting depth in your knowledge and after that, you can work on increasing the breadth
6. Jumping to conclusions without proper validation I have seen data scientists jumping straight to conclusions without validating results they are getting from their analysis or model predictions.
Solution- Perform hypothesis testing and validate/invalidate all the insights you have generated by conducting statistical tests for their significance
7. Negligence towards data cleansing, EDA and visualizations Many data scientist skim over the concepts of data cleaning, EDA and visualizations and move to data modeling. Understanding data first and make it usable for modeling is paramount hence a lot of attention should be given to these topics to emerge out as a successful data scientist Solution-
Take up datasets from different sources and try finding insights out of them. Try to build a story around datasets with help of graphs and numbers extracted out of the dataset. This practice will help you in understanding the data better
8. Thinking that communication skill is not required Communications skills are one of the most under-rated and least talked about aspects a data scientist absolutely MUST possess. I am yet to come across a course that places a solid emphasis on this. You can learn all the latest techniques, master multiple tools and make the best graphs, but if you cannot explain your analysis to your client, you will fail as a data scientist. And not just clients, you will also be working with team members who are not well versed with data science — IT, HR, finance, operations, etc. You can be sure that the interviewer will be monitoring this aspect throughout. Solution-
One of the things, I find most helpful, is explaining data science terms to a non-technical person. It helps me gauge how well I have articulated the problem. If you’re working in a small to medium-sized company, find a person in the marketing or sales department and do this exercise with them. It will help you immensely in the long term.
9. Giving too much importance to coding skills If you are a data scientist, you will have to code but this is not the hardest part of it. People tend to think that data science is all about coding and should put a lot of attention in coding skills. No doubt coding skills are required but one need not master it all-together.
Solution- People should focus more on creative ways of solving a problem rather than focussing too much on their coding skills. There are many software’s to perform the tasks for data scientists. Again coding is an essential skill but not a mandatory skill.
10. Insufficient research on the problem at hand Many problems do not reach a convincing solution just because the initial research on the problem was less or the domain knowledge related to that problem was not sufficient. People tend to jump into the problem directly without getting enough domain knowledge or performing a good initial research on what the problem is and how one should go about it
Solution- Conduct an extensive initial research and try to get the complete idea of the industry domain of the problem you are dealing with. Try to talk to the people from the same domain and understand how the process flows in that business line.
Conclusion
These mistakes are not easy to avoid when you are starting fresh in the data science career. I have also done many of the above mistakes that I have mentioned above. It takes an experience to understand why all the above points make sense. As we grow in experience, we learn and we get better and emerge out as a champion!
Data Science has been hailed as the transformative trend that is set to re-wire the industries and re-invent the ways people do things. Products and applications are being developed in agriculture, healthcare, urban planning, trade, commerce, finance, and the possibilities are growing.
It has been a buzzword for a while now with more people aiming to look ahead for the career opportunities it provides. If you are looking for a career change to data science or you want to build a career in it or you are really passionate about it, then Dimensionless Technologies has some great courses just for you.
Data Science is an umbrella term which is used to describe pretty much everything, from data engineering to data processing to data analysis to machine learning, pattern recognition, and deep learning.
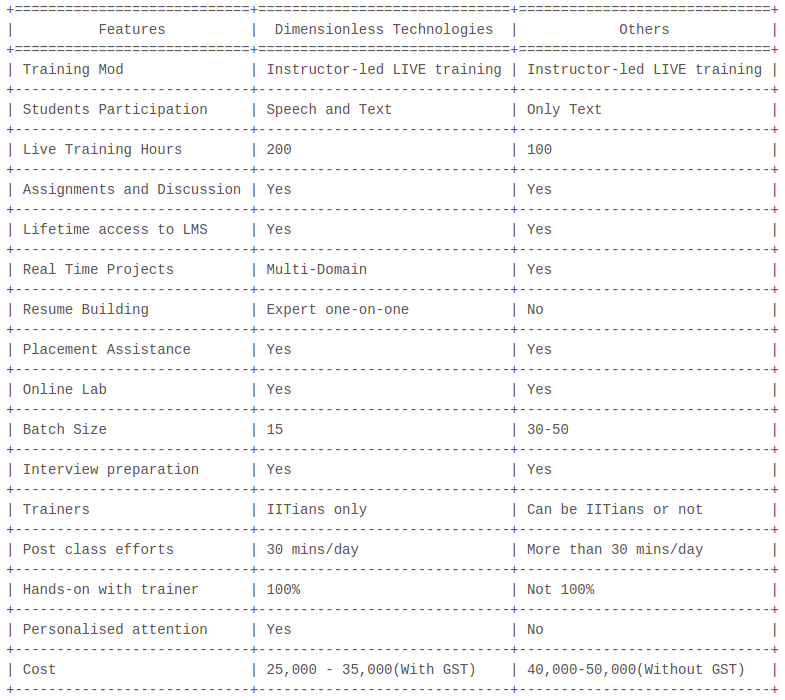
Dimensionless provides online data science training that provides in-depth course coverage, case study based learning, entirely Hands-on driven sessions with personalized attention to every participant. We provide only instructor-led LIVE online training sessions and not classroom training.
You can have a sneak peek into how classes are conducted which will help you make a wiser choice
Demo tutorial: Link
Why Dimensionless Technologies?
Dimensionless Technologies provide instructor-led LIVE online training with hands-on different problems. We do not provide classroom training but we deliver more as compared to what a classroom training could provide you with
Are you skeptical of online training or you feel that online mode is not the best platform to learn? Let us clear your insecurities about online training!
Live and Interactive sessions
We conduct classes through live sessions and not pre-recorded videos. The interactivity level is similar to classroom training and you get it in the comfort of your home. If you miss any class or didn’t understand some concepts, you can’t go through the class again. However, in online courses, it’s possible to do that. We share the recordings of all our classes after each class with the student. Also, there’s no hassle of long-distance commuting and disrupting your schedule.
Highly Experienced Faculty
We have very highly experienced faculty with us (IIT`ians) to help you grasp complex concepts and kick-start your career success journey
Up to Data Course content
Our course content is up to date which involves all the latest technologies and tools. Our course is well equipped for learners to grasp the knowledge required to solve real-world problems through their data analytical skills
Availability of software and computing resource
Any laptop with 2GB RAM and Windows 7 and above is perfectly fine for this course. All the software used in this course are Freely downloadable from the Internet. The trainers help you set it up in your systems. We also provide access to our Cloud-based online lab where these are already installed.
Industry-Based Projects
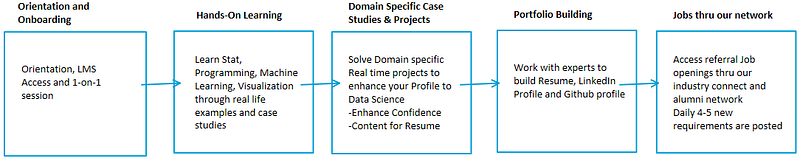
During the training, you will be solving multiple case studies from different domains. Once the LIVE training is done, you will start implementing your learnings on Real Time Datasets. You can work on data from various domains like Retail, Manufacturing, Supply Chain, Operations, Telecom, Oil and Gas and many more. You would be working on multiple projects so that you can gain enough content and confidence to enter into the field of Data Science.
Course Completion Certificate
Yes, we will be issuing a course completion certificate to all individuals who successfully complete the training.
Placement Assistance
We provide you with real-time industry requirements on a daily basis through our connection in the industry. These requirements generally come through referral channels, hence the probability to get through increases manifold.
Our Courses
Through our 3 well designed coursed, we have covered most of the aspects which data science encompasses and even have gone deeper into other domains like maths and computer science.
Comparison of Dimensionless Tech with Other E-learning platforms for data science
Our unique approach to conducting session sets us apart from other e-learning platforms for data science
Data Science using R and Python (Link)
This is our complete data science course which is specifically designed for all the people looking for a career in the data science. This course requires no pre-requisites and walks learners from basics to depth in every topic.
This course includes
1. Descriptive Statistics(Variability, Distributions, Central tendency etc)
2. Inferential Statistics(Hypothesis Testing, ANOVA, Regression, T-tests etc)
3. R (functions, libraries, dplyr, apply etc)
4. Python (Functions, pandas, numpy, sci-kit learn etc)
5. Machine Learning (Regression, SVM, Naive Bayes, Time Series Forecasting etc)
6. Tableau
7. Final Project
Big Data and NLP (Link)
Data is everywhere and there is a lot of it actually. Big Data gives us the capability to work on this large amount of data. This course is designed for learners who want to understand how data science is applied in the industry over the big data setup. Also, this course will help learners to understand Natural Language Processing and making learners perform analytics when encountered with a lot of textual data
This course includes
1. Spark basics and its architecture
2. Data Manipulation with Spark
3. Applied Machine Learning with Spark
4. Text Processing using NLTK
5. Building Text Classifiers with Machine Learning
6. Semantic Analysis
Deep Learning (Link)
Machine Learning has been booming off late. This course is designed for all the people who are looking for machine learning engineer profile. This covers the concept starting from the basics of neural networks to building them to solve different case studies
This course includes
1. Understanding Neural networks and Deep Learning
2. Tuning Deep Neural Networks
3. Convolutional Neural Networks
4. Recursive Neural Network
Our Faculty
Himanshu (IIT, Bombay – 10+ years experience in Data Science), A machine-learning practitioner, fascinated by the numerous application of Artificial Intelligence in the day to day life. I enjoy applying my quantitative skills to new large-scale, data-intensive problems. I am an avid learner keen to be the frontrunner in the field of AI.
Kushagra, (IIT Delhi – 8+ years experience in Analytics & data science), has a keen interest in Problem Solving, Deriving insights & Improving the efficiency of processes with new age technologies. Trained 500+ participants in R, Machine Learning, Tableau and Python, Big Data Analytics at Dimensionless Conducted workshops and training on Data Analytics for Corporate and Colleges.
The Final Picture
Our courses have been designed considering the overall growth of the learners in the data science field. We not only cover the data science domain but we have courses for you to learn text mining or production level technologies like Apache Spark. We have a deep learning course for all the machine learning enthusiasts to extend their knowledge and step into the world of AI
From machine learning to Data processing, from multi-domain problems to writing production grade code on Apache Spark, Dimensionless Technologies have covered it all for you!
Visit Dimensionless and enroll now to give your career a kick-start in data science! [LINK]
Data science is one of the hottest topics in the 21st century because we are generating data at a rate which is much higher than what we can actually process. A lot of business and tech firms are now leveraging key benefits by harnessing the benefits of data science. Due to this, data science right now is really booming.
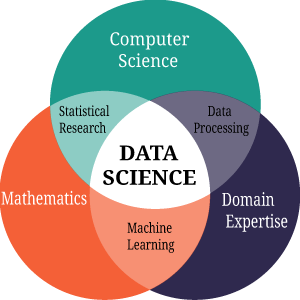
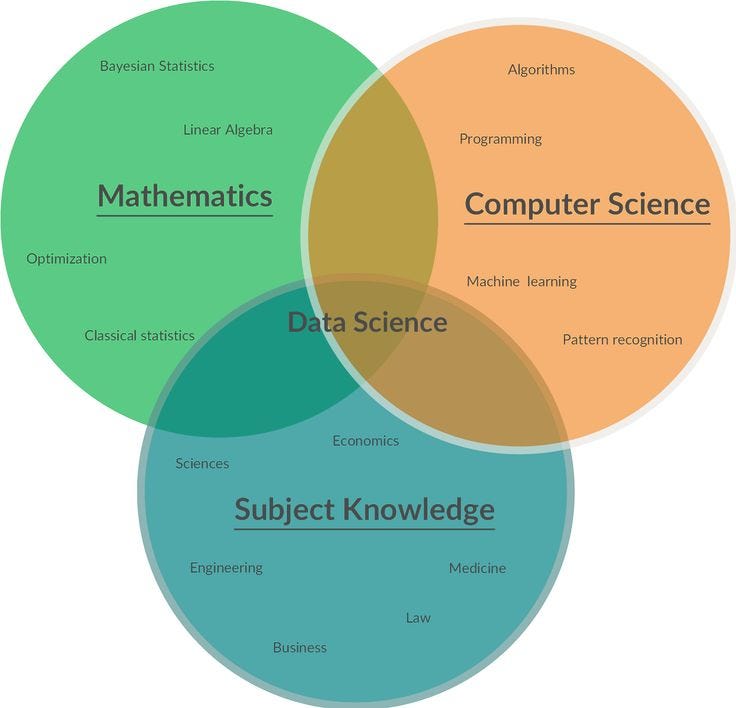
Data science is an amalgamation of three different fields namely
Computer Science
Mathematics
Business Knowledge
Starting from this article, We at Dimensionless will be helping you to kick-start your data science career if you are from one of the fields above or even not from them at all.
You may have seen those memes which talk about your engineering/high school maths not being used anywhere in the real world. This won’t be the case henceforth though.
Today, we will talk about what are different things you should learn in mathematics for becoming a data scientist. This will not be so difficult for you too because we at Dimensionless Technologies have all the right courses for you to kick-start your success journey.
Who we are and what we have for you
Dimensionless Tech provides best online data science training that provides in-depth course coverage, case study based learning, entirely Hands-on driven sessions with Personalised attention to every participant. As a result, we guarantee Learning.
Dimensionless has courses which are well-tailored for the beginners to understand the data science as a whole. This course takes into the account the importance of having math knowledge hence we start with learning statistic itself.
We provide only instructor-led LIVE online training sessions. Above all, the interactivity level is similar to classroom training and you get it in the comfort of your home. If you miss any class or didn’t understand some concepts, you can go through the classes again as we provide you with recordings of each class.
Examples where mathematics play a role in data science
Finding immediate insights out of data
We use descriptive statistics here to gather immediate information about the data at hand. For example, in a house price dataset, we can find out the in Region X has the most number of expensive houses.
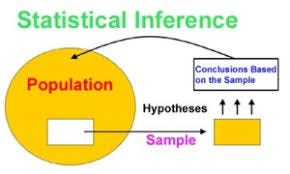
Inferencing from data and validating it
We use inferential statistics to infer about our findings from data. On finding maximum house price at a region X, we formulate some hypothesis on why prices are higher in that region. After forming hypotheses, we check their validity using hypothesis tests
Making predictions from data
Machine learning and math is one of the greatest love stories. These algorithms are a mix of logic and a lot of maths. Hence understanding the math behind may result in you appreciating it furthermore
How we help you in accelerating your learning
If you’ve just entered the word of Data Science, you might have come across people stating “Math” as a prerequisite to Data Science. In all honesty, it’s not Maths, rather Statistics that’s a major prerequisite for Data Science.
Well, statistics is something which is present everywhere in the data science field. Hence, you surely can not be a good data scientist without knowing and understanding statistics well enough. But, Dimensionless has come up with the great courses which talk about the in-depth understanding of statistics and their applications.
These days, libraries like Tensorflow hide almost all the complex Mathematics away from the user. Good for us, but it’s still good to have a basic understanding of the underlying principles on which these things work because having a general understanding of basic statistics for Data Science can help you utilize these libraries better.
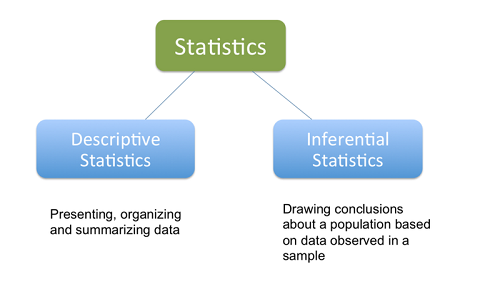
Types of Statistics
Descriptive Statistic
First of all, doing a descriptive statistical analysis of your dataset is absolutely crucial. A lot of people skip this part and therefore lose a lot of valuable insights about their data, which often leads to wrong conclusions. Take your time and carefully run descriptive statistics and finally make sure that the data meets the requirements to do further analysis.
We use descriptive statistics for data exploration because it provides simple summaries of the dataset. Together with graphics analysis, this is the first step in every data analysis.
A small peek of what we have in the course by understanding about central tendency
In statistics, we have to deal with the mean, mode, and the median. These are also called the Central Tendency. These are just three different kinds of averages and certainly the most popular ones.
The mean is simply the average and considered the most reliable measure of central tendency for making assumptions about a population from a single sample. Central tendency determines the tendency for the values of your data to cluster around its mean, mode, or median. We calculate median by the sum of all values, divided by the number of values.
The mode is the value or category that occurs most often within the data. Therefore a dataset has no mode, if no number is repeated or if no category is the same. The mode is also the only measure of central tendency that can be used for categorical variables since you can’t compute for example the average for the variable gender. You simply report categorical variables as numbers and percentages.
The median is the “middle” value or midpoint in your data. Note that outliers affect do not affect median much as compared to mean. Let us take an example here: Imagine you have a dataset of housing prizes that range mostly from Rs 10,00,000 to Rs 70,00,000 but contains a few houses that are worth more than 70 lakhs. These expensive houses will heavily effect then mean since it is the sum of all values, divided by the number of values. The outliers will not affect the median much since it is only the “middle” value of all data points. Therefore the median is a much more suited statistic, to report about your data.
This is just a small peek of what you will be learning in descriptive stats. All the topics are taught in the order which well help learner form mind maps of different concept connected to each other and have a strong grasp over them.
With inferential statistics, you are trying to reach conclusions that extend beyond the immediate data alone. For instance, we use inferential statistics to try to infer from the sample data what the population might think. Or, we use inferential statistics to make judgments of the probability that an observed difference between groups is a dependable one or one that might have happened by chance in this study. Thus, we use inferential statistics to make inferences from our data to more general conditions; we use descriptive statistics simply to describe what’s going on in our data.
t-tests (One Sample, Two Sample Dependent, Two-sample Independent)
ANOVA
Correlation
Regression
Chi-square Test
Apart from probability and statistics, Our courses include an in-depth explanation of machine learning algorithms by going deeper into the math. There has been a lot of booms lately in the field of machine learning and deep learning. With our up-to-date courses, we give you the essence of maths required to understand machine learning in great detail. We have covered topics like linear algebra, regression and the math behind different machine learnings algorithms exhaustively.