The growth of data and its generation speed has been increasing exponentially since the last decade. According to reports, more than 3 quintillion bytes of data is generated per day! This has resulted in the formation of totally new and versatile professionals known as data scientists. Data has risen to fame recently only but maths has been existing before that which introduces us to other class of professionals known as statisticians. So what exactly is the difference between the two?
In this blog, we are going to understand the difference between data scientists and a statistician. This will help us in understanding the subtle differences between the two!
Who is a Data Scientist?
A data scientist is someone stronger than any software engineer and superior to any statistician in software engineering. In general, information researchers evaluate large information or information repositories that are held throughout an organization or website but are nearly useless in terms of strategic or financial advantage. In order to obtain recommendations and suggestions for optimum company decision making, information researchers are fitted with statistical designs and evaluate previous and present information from such shops.
In the marketing and scheduling system information researchers are primarily involved in the identification of helpful ideas and statistics for the preparation, implementation, and tracking of results-driven marketing policies.
Who is a Statistician?
Statisticians gather and evaluate information, searching for behavioral patterns or environment descriptions. They create and create models with information. The models can be used to create projections and comprehend the universe. The festival of birthdays has been demonstrated to be safe. Statistics indicate that the eldest are those who celebrate the most birthdays.
A statistics scientist creates and uses statistical or mathematical models to gather and sum up helpful data to assist fix real issues. Data are collected and analyzed and used in a number of industries, including engineering, science, and business. The numerical data collected helps companies or clients understand quantitative data and track or predict potential trends that can be beneficial in making business decisions.
Difference in Skills
Data Scientist
1. Education
Informatics are extremely educated — 88 percent have a masters ‘ and 46 percent are doctoral students. There are noticeable exceptions, however, in order to create the depth of expertise needed for information science, a powerful instructional background is generally essential.
2. R Programming
Thorough knowledge of at least one such tool is generally preferred for data science R. R is designed specifically for the needs of data science. You can use R to fix any information about scientific problems. 43% of information researchers actually use R to address statistical difficulties. But R has a steep curve of teaching.
3. Python Coding
Python, like Java, Perl, or C / C++, is the most frequent coding language that I normally see needed for data science. For information researchers, Python is a good programming language.
4. Hadoop Platform
While this is not always a necessity, in many instances it is much preferred. Also, a powerful point of sale is the experience with Hive or Pig. Cloud instruments, such as Amazon S3, can also be useful.
5. SQL Database/Coding
As an information researcher, you need to be skilled in SQL. This is because SQL is intended specifically for accessing, communicating and working with information. It provides information when you are looking for a database. It contains concise instructions which can save you time and reduce the quantity of programming you need to query.
6. Machine Learning and AI
Many information researchers are not skilled in the area and methods of machine learning. This involves neural networks, strengthened teaching, enemy education, etc. You have to understand machine learning methods, such as monitored machine learning, decisions treaties, regression of logistics, etc. If you want to stand out from other information researchers.
7. Data Visualization
There is a lot of information in the company globe. The information should be converted into an easy-to-understand format. Naturally, people comprehend more than raw information images in charts and graphs.
8. Unstructured Data
It is crucial to be prepared to operate with unstructured data from a data scientist. Unstructured information is undefined input that is not included in database databases. Examples are photos, blog posts, client feedback, postings in social media, video, audio etc.
9. Business Acumen
You need to understand the sector you work in and what business issues your enterprise is attempting to resolve to be an information scientist.
10. Communication Skills
Companies seeking a powerful information researcher seek someone who can communicate their technical results obviously and fluently into a non-tech group like the marketing or sales office.
Statisticians
Deep theoretical knowledge in probability and inference
Numerical Skills: This skill reflects the person’s general intelligence and its development ensures at a great extent the attainment of organizational goals.
Analytical skills: The capacity to gather and evaluate data, solving issues and making choices is the subject of analytical abilities. These strengths can assist address the issues of a company and enhance its production and achievement generally.
Written and verbal communication skills
Good interpersonal skills: The characteristics and actions we show in communicating with others are interpersonal abilities. They are regarded as one of the soft skills most sought after. Whenever we participate in verbal or non-verbal interaction, we show it. Indeed, the essential characteristics of body and attitude are a major influence on our opportunities of excellence at the job.
Difference in Tools
Tools of a statistician
1. SPSS
Perhaps the most commonly used statistical software package in human behavior studies (SPSS), is the statistics package for the social sciences. SPSS allows the compilation by graphical user interface (GUI) of the descriptive stats, parametric and non-parametric analysis and graphical display of outcomes. The possibility of creating scripts for automating assessment or for sophisticated statistical handling is also included.
2. R
R is a free software suite used extensively in studies on human conduct and in other areas. Toolboxes are accessible for a wide spectrum of apps, allowing different elements of information handling to be simplified. Although R is a high-performance software, it has a steep learning curve that also requires some coding.
3. MATLAB (The Mathworks)
MatLab is a platform for analytics and programming that technicians and researchers commonly use. As with R, the route to studying is steep, and at some stage you will need to build your own software. There are also plenty of toolboxes to assist you address your study requests (e.g. EEGLab for EEG information analysis). While MatLab can be hard for novices to use, it provides huge flexibility as far as what you want to do is concerned-provided that you can write (or at least run the toolbox you need).
4. Microsoft Excel
MS Excel offers a broad range of data visualization instruments and easy statistics while not being a state of the art alternative for statistical analysis. Summary and customizable graphs and numbers are easy to create and are therefore a helpful instrument for many who want to see the foundations for their information. As many people and businesses own and understand how to use Excel, it is also an affordable choice for those seeking stats.
5. GraphPad Prism
GraphPad Prism provides a variety of capacities which can be used through a wide spectrum of areas, mainly in statistics relating to biology. In a way similar to SPSS, scripting alternatives are accessible for automating analyzes or for more complicated statistical calculations.
6. Minitab
A variety of fundamental and quite sophisticated statistical instruments for information assessment are available in the Minitab software. Like GraphPad Prism, GUI and scripted instructions may be used to make it available to novices and customers seeking more complicated analysis.
Tools of a Data Scientist
1. R:
R is a computer and graphics free software framework. The program compiles and operates on many UNIX, Windows and MacOS platforms
2. Python:
Python is a common language for programming. It was developed and published in 1991 by Guido van Rossum. It is used for server-side creation, computer production, mathematics, scripting of systems.
3. Julia:
Julia has been intended for elevated efficiency since the start. For various LLVM systems, Julia programs are compiling effective native code. Julia is type-dynamically, looks like a language for scripting and has great interactive assistance.
4. Tableau:
Tableau is one of the fastest growing instruments presently in use in the BI sector for data visualization. This is the best way to alter the raw information packed into a readily understood format, with zero technical understanding and coding.
5. QlikView:
QlikView is a major discovery platform for companies. Compared with traditional BI systems, it is distinctive in many respects. As an information analytics instrument, the connection between the information is always maintained, and colors are visually visible. It also displays unrelated information. Direct and indirect searches are provided by means of surveys in list boxes.
6. AWS:
In addition to computing energy, database storage and content delivery, Amazon web services (AWS) is a safe Cloud services platform that helps companies to scale and expand. Explore how millions of clients are presently using AWS cloud goods and alternatives to develop complex apps which are more flexible, scalable and reliable.
7. Spark:
Apache Spark is a quick cluster-computing scheme for general purposes. It offers Java, Scala, Python and R high-level APIs, as well as an optimized motor to support overall implementation charting.
8. RapidMiner:
RapidMiner has been created by the same-name business as the information scientific technology platform that offers an embedded information preparation, machine learning, profound learning, text mining, and prediction analyses atmosphere. It promotes all measures in machine learning including information preparing, outcome visualization, design verification, and optimization and it is used for both business and industrial apps, as well as for studies, schooling, teaching, fast Prototyping, and software growth.
9. Databricks:
In order to assist consumers to incorporate data science, technology, and the businesses behind them throughout the machine life cycle, DataBricks was developed for information researchers, engineers and researchers. This inclusion facilitates the process from information preparing to test and implementation for machine learning.
Difference in Salary
The work of data research is not only more prevalent than the job of stats. They are more profitable, too. The domestic median wage for an information researcher, according to Glass Door, is $118.709 versus $75.069 for statistics. A data scientist is an enterprise one-stop answer. Usually, the data scientist may have an issue open-ended, find out what information they need, obtain the deadline, perform the modeling/analysis and compose excellent software to perform this.
Career Path
Statistician Career Path
Statistical Analyst. Statistical analysts usually perform information analyzes under the guidance of a trained or senior statistician who may be a model mentor and professional. Over moment, many analysts are moving from “backroom” roles to take more and more accountability, to carry out more sophisticated technical duties and to work more separately.
Applied Statistician. For everything that is important, applied statistics are responsible for ensuring that the right data for analysis of the data (or for conducting such analyses) are collected and the results reported. They communicate carefully with other technical personnel and leadership and are ideally essential project team members.
Senior Statistician. Senior statistics also suppose wider duties, in relation to assuming the functions of applied statistics. They examine the issues holistically and seek to link them to the organization’s overall objectives. In order to propose fresh initiatives and initiatives that will profit their organizations or clients in the future, senior statistics perform a proactive position. They often participate profoundly in the early phases of a venture, help to quantitatively identify problems and suggest a route to senior leadership. They will then be involved in the preparation and presentation of the results. In statistical matters, they are often seen as the supreme source of information and expertise.
Statistical Manager. Statistical group managers–especially the youngest members of the group–are engaged in project planning and helping to identify what should happen. They pick the worker, give advice when required, and are responsible for the general achievement of the project. They keep senior management updated about the technical achievements of the group, assist to promote the group members ‘ interests and ambitions and create a vision for the future. They include employee recruitment and growth and efficiency assessments as their administrative duties. There are a restricted amount of roles.
Private Statistical Consultant. Some applied statistics go as personal statistical advisors to their own businesses. Special studies are undertaken by consultants, often for organizations with no statistics or that evaluate the job of professionals or other statisticians. Statistical advisors are frequently used to address legal questions, perhaps as expert evidence.
Data Scientist Career Path
Data Scientists: There are information researchers who adjust the statistical and mathematical models used for information. When a system is built to estimate the amount of loan card defaults in the following month, the data scientist’s head is in use.
Data Engineers: Data engineers depend mainly on their knowledge in software engineering to manage big quantities of information on a scale. These generalists are flexible and use computers to aid in processing big datasets. They usually concentrate on coding, cleaning and executing information researchers ‘ demands. They usually understand a wide range of programming languages between Python and Java. When someone takes the data scientist’s predictive model and puts it into code, they typically have the role of a data engineer.
Data Analysts: Finally, there are information scientists who examine the information, report and visualize what the information conceals. If someone helps individuals throughout the enterprise comprehend certain questions, they fulfill the function of the data analyst.
Summary
An outstanding analyst is not a shoddy version; his coding style is optimized for speed-specifically. They’re not even a poor statistician, because they’re uncertain, they’re not dealing with facts. The analyst’s main task is to state “Here is what is contained in our information. It is not my task to speak about what that implies, but perhaps the decision maker is to encourage a statistician to take up the issue.”
One of the most difficult tasks in Big data is to select an apt programming language for its applications. Most data scientists prefer R and Python for all the data processing and all the machine learning tasks whereas for all the Hadoop developers, Java, and Scala are the most preferred languages. Scala did not have much traction early, but with key technologies like Scala and Kafka playing a big role, Scala has recently gained a lot of traction for all the good reasons. It is somewhere between R/Python and Java for developers out there!
With spark written entirely in Scala, more than 70% of the Big data practitioners use Scala as the programming language. With spark enabling big data across multiple organisations and its high dependency on Scala, Scala is one important language to keep it in your arsenal. In this blog, we look to understand how to implement spark application using Scala
What is Spark?
Apache Spark is a map-reduce based cluster computing framework which enables lightning-fast processing of data. Spark provides a more efficient cover over Hadoop’s map-reduce framework including stream/batch processing and interactive queries. Spark leverages it’s the in-memory model to speed up the processing within applications to make them lightning quick!
Spark is designed for handling a broad variety of tasks and computations, such as batch requests, any recursive or repetitive algorithms, or be it any interactive queries, or live streaming data. It decreases the leadership strain of keeping distinct instruments in addition to helping all these workloads in a corresponding scheme.
What is Scala?
Scala is a programming language which is a mix of both object-oriented and functional paradigm to allow applications to run on a large scale. Scala is mostly influenced by Java and is more of a statically typed programing language. Java and Scala have a lot of similarities between them. To begin with, Scala is coded in a manner very similar to Java. To add, Scala can make use of many Java libraries and other third-party plugins
Also, Scala is named after its feature of ‘scalability’ in which most of the programming languages like R and Python lack a great deal. Scala allows us to perform multiple common programming tasks in a more of a clean, crisp and elegant manner. It is a pure object-oriented programming language providing additional capabilities from the functional paradigm
Spark+Scala Overview
Each Spark implementation at an uber level consists of a driver program running the primary feature of the user and performing multiple simultaneous activities on a grid. The primary abstraction provided by Spark is a resilient distributed dataset (RDD), a set of components partitioned across cluster nodes that can be worked on in conjunction. RDDs can be created by initializing and transforming any Scala collection in the main driver program of the spark context. Users may also request Spark to keep an RDD in memory so that it can be effectively recycled through simultaneous activities.
Understanding MapReduce
MapReduce is an algorithm for distributed data processing. It was introduced by Google in one of its technical publication. This algorithm finds its inspiration from the functional paradigm of the programming world. Map reduce, in a cluster environment, is highly efficient in running large data chunks parallelly. Powered by divide and conquer technique, it takes care of dividing any input tasks to a smaller number of subtasks such that they can be run parallelly
MapReduce Algorithm uses the following three main steps:
Map Function
Shuffle Function
Reduce Function
1. Map Function
Mapping is the first task of the MapReduce Algorithm. It takes input tasks and divides them into smaller parallel executable sub-tasks. In the end, all the required computations happen over these sub-tasks hence providing the real-essence of parallel computation
This step performs the following two sub-steps:
Splitting step takes input data from a source and divides into smaller datasets
Mapping happens after splitting step. It takes smaller datasets and performs computation on each of them
The output from this mapping module is a key-value pair like (Key, Value)
2.Shuffle Function
It is is the second step in MapReduce Algorithm. It is more like a combine function. It essentially performs the following two sub-steps:
It takes a list of outputs from the mapper module and performs the following two sub-steps on every key-value pair.
Merging: This step combines key-value pairs having the same keys. It can be viewed as an aggregate function applied to all keys. This step returns an unsorted list like (Key, List(Value)).
Sorting: This step is in charge of transforming the merge step input to a sorted key-value pair (sorted based on keys). This step gives back a key value list<Key, List<Value>> as a sorted key-value pair output.
3. Reduce Function
Reduce function is the ultimate step of the map-reduce algorithm. It has only one task i.e. reduce step. Having a sorted key-value pair as input, it’s sole responsibility is to run a reduce algorithm(a group function) to assemble all the keys together.
Understanding RDD
Spark as a framework is heavily built on the top of its basic element i.e RDD (Resilient Distributed Dataset). It is an immutable collection of objects that are distributed. Each RDD dataset is split into logical partitions that can be calculated on various cluster nodes. RDDs may comprise any sort of objects from Python, Java, or Scala, including user classes. Formal, an RDD is a set of documents read-only, partitioned. RDDs can be developed using either stable storage information or other RDDs deterministic activities. RDD is a fault-tolerant set of parallel-operable components.
There are two different ways to create RDDs-parallelising an existing collection in the driver’s program or referencing a data set in an externally stored system like a disk or Hadoop clusters.
To accomplish fast and effective MapReduce activities, Spark uses the RDD notion. Let’s talk about how and why MapReduce activities take place.
Goal
Our goal in this article will be to understand the implementation of spark using Scala. Below, we will implement two Scala codes to understanding it’s functioning. First will be the word count example. Here, we will be counting the frequency of words present in the document. Our second, task will be a utilizing rich ml library of spark. We will implement our first decision tree classifier here!
Setting up Spark and Scala
Our first task is to install the requirements before we can start actually implementing.
Every program needs an entry point to begin the execution. In Scala, we need to do that through a spark session object. Spark session is the entry point for our dataset to commence execution
Step 2: Data read and dataset formation
Data read can be performed with many available API’s. We can use read.text API or even textFile API which is generally used to read RDD’s.
Step 3: Split and group by word
Dataset has a lot of similar features as of RDD API. It has features like a map, groupByKey, etc all available. In the code below, lines are being split by spaces to obtain words. Later on, different words are grouped together
We are not generating any (key / value) pair here, as you can notice that. The reason for this is that unlike RDD, the dataset is low abstract. Each valuation has a line with several rows, and any column can behave as a grouping key as in the database.
Step 4: Counting the occurrences of the words
After grouping all the words as keys, we can indeed count the occurrences of all the words in the set. For this, we can use the reduceByKey function of RDD’s or can directly employ the count function available
Step 5: Displaying the results
Once we are done counting the word occurrences, we need to figure out a way of displaying them. There are multiple ways of doing this. We will be using the collect function to display our results in this case
You can find the implementation of the word-count example below
package com.oreilly.learningsparkexamples.mini.scala
import org.apache.spark._
import org.apache.spark.SparkContext._
object WordCountObject {
def main(args: Array[String]) {
val inputData = args(0)
val outputData = args(1)
val conf = new SparkConf().setAppName("wordCountExample")
// Creating a sparkContext for app entry
val sc = new SparkContext(conf)
// Loading the input data
val input = sc.textFile(inputData)
// Splitting sentences into words based on empty spaces
val all_words = input.flatMap(line => line.split(" "))
// Transforming words word count key value pairs.
val wordCounts = all_words.map(word => (word, 1)).reduceByKey{case (x, y) => x + y}
// Logging the results to the output file
counts.saveAsTextFile(outputData)
}
}
Summary
In this blog, we looked at Scala programming language showcasing its abilities from its functional paradigm and implementing them with the Spark. Spark has been a key player in the big data industry for quite a long time now. Spark provides all its full-fledged features in the form of Scala API’s. Hence it is very clear that in order to unlock Spark to its full potential, Scala is the way forward!
Data science is a comprehensive blend of maths, business and technology. One has to go from data inference to algorithm development and then all the way to use available technology to draw the solutions for complex problems. At its heart, all we have is data. All our inferences can only be brought up once we start its mining. In the end, data science uses multiple mathematical techniques to generate business value present in the data for various enterprises
On a very broad level, data science comprises of 3 important components namely maths or statistics, computer science and information science. A very strong statistical background knowledge is necessary if one is to pursue a career in data science. Various organisations prefer data scientists with strong statistical knowledge as statistics is one important component providing insights to leading businesses worldwide
In this blog, we will understand 5 important statistical concepts for data scientists. Let us understand them one by one in the next section.
Statistics and Data Science
Let us discuss the role of statistics in data science before beginning our journey into the math world!
In data science, you can always find statistics and computer science competing against each other for the ultimate supremacy. This happens, in particular, the areas concerning data acquisition and enrichment for predictive modelling
But somewhere, statistics have an upper hand as all the computer science applications in data science are more of it’s derivative
Statistics though is a key player in data science but not a solo player in any way. The real essence of data science can be obtained by combining statistics with the algorithms and mathematical modelling methods. Ultimately a balanced combination is required to generate a successful solution in data science
Important Concepts in Data Science
1. Probability Distributions
A distribution of probabilities is a characteristic that defines the likelihood that a random variable can take feasible values. In other words, the variable values differ according to the fundamental spread of likelihoods.
Suppose you draw a random sample and are measuring the income of the individuals. You can start creating a distribution of income as you keep on collecting the data. Distributions are important in the scenarios where we need to find out outcomes with high likelihood and want to measure their predicted/potential values over a range
2. Dimensionality Reduction
In machine learning classification problems, on the basis of which the final classification is done, there are often too many factors. These factors are essentially so-called characteristics variables. The greater the amount of characteristics, the more difficult it becomes to visualize and operate on the training set. Most of these characteristics are sometimes linked and therefore redundant. This is where algorithms for the decrease of dimensionality come into practice. Dimensionality reduction can be looked as a method or means of eliminating a large number of variables to reach a smaller subset or arriving at the variables which matter more than then others. It can be split into a choice of features and removal of features.
An easy email classification problem can be used to discuss an intuitive instance of dimensionality reduction, where we need to identify whether the email is spam or not. This can include a big amount of characteristics, such as whether or not the email has a specific name, the email content, whether or not the email utilizes a model, etc. Some of these characteristics, however, may overlap. In another situation, a classification problem based on both humidity and rainfall may collapse into just one fundamental function, as both of the above are highly linked. Therefore, in such problems, we can reduce the number of features.
3. Over and Under-Sampling
In data sciences, we work with datasets representing some entities. It is required that all the entities have equal representation in the dataset which may not be the case every time. To cope with this, we have oversampling and undersampling as two measures in data science. These are data mining techniques and can modify unequal classes to create balanced sets. They are also known as resampling techniques
When one information category is the underrepresented minority group in the data sample, over-sampling methods can be used to replicate these outcomes for a more balanced quantity of beneficial teaching outcomes. Oversampling is used when there is inadequate information collection. SMOTE (Synthetic Minority Over-sampling Technique) is a common oversampling method that produces synthetic samples by randomly sampling the features of minority class events.
Also, If the information category is the over-represented majority class, undersampling can be used to mix this class with the minority class. Undersampling is used when there is an adequate quantity of information gathered. Common undersampling techniques include cluster centroids targeting prospective overlapping features within the gathered information sets to decrease the quantity of bulk information.
Simple duplication of information is seldom suggested in both oversampling and undersampling. Oversampling is generally preferable since undersampling can lead to the loss of significant information. Undersampling is suggested when the quantity of information gathered is greater than appropriate and can assist to keep information mining instruments within the boundaries of what they can process efficiently.
4. Bayesian Statistics
Bayesian statistics is an alternative paradigm in statistics as compared to the frequentist paradigm. It works on the principle of updating a pre-existing belief about random events. The belief gets updated after new data or evidence about that data pops in
Bayesian inference revolves around interpreting probability as one measure to evaluate the confidence of the occurrence of a particular event.
We may have a previous faith about an event, but when the fresh proof is put to light, our beliefs are probable to alter. Bayesian statistics provide us with a strong mathematical means of integrating our previous views and proof to generate fresh subsequent beliefs.
Bayesian statistics have the capability of providing methods to update our beliefs pertaining to the occurrence of an event in the light of new data or evidence
This contrasts with another type of inferential statistics, recognized as classical or frequency statistics, which believes that probabilities are the frequency of specific random occurrences that occur in a lengthy sequence of repeated trials.
For example, when we toss a coin repeatedly, in case of tossing a coin, we can find that the probability of heads or tail will come up to value close to 0.5.
Frequentist and Bayesian statistics span over different ideologies. For frequentist statistics, outcomes are thought to be observed over a large number of repeated trials and then all the observations are made as compared to Bayesian where our belief updates with every new event
By offering predictions, frequentist statistics attempt to eliminate the uncertainty. Bayesian statistics attempt to maintain and refine uncertainty by adapting personal views with fresh proof
5. Descriptive Statistics
This is the most prevalent of all types. It offers the analyst within the company with a perspective of important metrics and steps. Exploratory data analysis, unsupervised teaching, clustering and summaries of fundamental information are descriptive statistics. There are many uses of descriptive statistics, most particularly assisting us familiarize ourselves with an information collection. For any assessment, descriptive statistics are generally the starting point. Descriptive statistics often assist us to come up with hypotheses that will be checked subsequently with more official inference.
Descriptive statistics are very essential because it would be difficult to visualize what the information showed if we merely displayed our raw information, particularly if there were a bunch of them. Therefore, descriptive statistics enable us to show the information in a more significant manner, allowing the information to be interpreted more easily. For example, if we had the results of 1000 student marks for a specific student for the SAT exam, we might be interested in those students ‘ overall performance. We’d also be interested in spreading or distributing the marks. All the above-mentioned tasks and visualisations come under the idea of descriptive statistics
Let’s take an example here. Suppose you want to measure the demographics of the customers a retail giant is catering too. Now the retail giant is interested in understanding the variance present in the customer attributes and their shopping behaviours. For all these tasks, descriptive statistics is a bliss!
Conclusion
In this blog, we had a look at 5 most important concepts in statistics which every data scientist should know about. Although, we discussed them in detail these are not the only techniques in statistics. There are a lot more of them and are good to know!
The most beautiful aspect of machine learning is its ability to make predictions on the never seen before data points. In order to estimate the performance of ML models, we need to take our dataset and divide it into two parts. One part powers the model training whereas the other is used to make predictions. The former one is known as training dataset and the latter one is known as the test dataset
In this blog, we will study in depth the concept of cross-validation. We will further study about different cross-validation techniques too!
What is Cross-Validation?
Cross-validation is an extension of the training, validation, and holdout (TVH) process that minimizes the sampling bias of machine learning models. With cross-validation, we still have our holdout data, but we use several different portions of the data for validation rather than using one fifth for the holdout, one for validation, and the remainder for training
All in all, a model is generally provided with a set of known data, called the training data set, and a set of unknown data to be tested against the model, known as the test data set, for a prediction problem. The goal is to have a data set in the training phase to test the model and then provide insight into how the particular model adapts to an independent data set. A round of cross-validation involves partitioning information into additional subsets and then performing an assessment on a single subset. After that, on other subsets (exam sets) the assessment is validated.
Many runs of cross-validation are conducted using many distinct partitions to decrease variation and then an average of the outcomes is obtained. Cross-validation is a strong method of estimating the performance technique of the model.
Why Do We Need Cross-Validation?
The aim of cross-validation is to evaluate how an unidentified dataset conducts or behave on our prediction model. We will look at it from the point of perspective of a layman.
You’re learning to ride a vehicle. Now, on an vacant highway, anyone can ride a vehicle. In challenging traffic, the true experiment is how you ride. That’s why the trainers train you on traffic-intensive highways to get you used to it. So when it’s truly time for you to ride your vehicle, you’re ready to do that without the trainer seated next to you to guide you. You are prepared to deal with any scenario you may not have experienced before.
Goal
In this blog, we will be learning about different cross-validation techniques and will be implementing them in R. For this purpose, we will train a simple regression model in R. We will be evaluating its performance through different cross-validation techniques
Data Generation
In this section, we will generate data to train a simple linear regression model. We will evaluate our linear regression model with different cross-validation techniques in the next section.
gen_sim_data = function(size) {
x = runif(n = size, min = -1, max = 1)
y = rnorm(n = size, mean = x ^ 2, sd = 0.15)
data.frame(x, y)
}
Different Types of Cross-Validation
1. The Validation set Approach
A validation set is a collection of information used to train artificial intelligence in order to find and optimize the finest model for solving a particular issue. Also regarded as dev sets are validation sets. The bulk of the complete information is made up of training sets, approximately 60 per cent. In experimentation, in a method recognized as changing weights, the designs suit parameters.
The validation set represents approximately 20 per cent of the majority of the information used. In contrast to teaching and test sets, the validation set is an intermediate stage used to select and optimize the finest template.
Testing sets create up 20% of the data’s bulk. These sets are perfect information and outcomes for verifying an AI’s proper procedure. The test set is assured, usually through human verification, to be the input information clustered together with checked right inputs. This perfect environment is used to measure outcomes and evaluate the final model’s output.
set.seed(42)
data = gen_sim_data(sample_size = 200)
idx = sample(1:nrow(data), 160)
trn = data[idx, ]
val = data[-idx, ]
fit = lm(y ~ poly(x, 10), data = trn)
2. Leave out one cross-validation
Leave-one-out cross-validation is K-fold cross-validation that takes the number of data points in the set to its logical extreme, with K equal to N. That implies that N is instructed on all information separately, the feature approximator except for one stage, and a forecast is created for that stage. As before the model is calculated and used to assess the median mistake. The assessment provided by a cross-validation error leave-one-out (LOO-XVE) is nice, but it seems very costly to calculate at first glance. Locally weighted learners can, fortunately, create LOO predictions as readily as periodic projections are made. This asserts that computing the LOO method uses no more time than computing the error. Also, it is a much better way to evaluate models.
# Define training control
train.control = trainControl(method = "LOOCV")
# Train the model
model = train(Fertility ~., data = swiss, method = "lm",trControl = train.control)
# Summarize the results
print(model)
3. k-fold cross validation
One way to enhance the holdout technique is through K-fold cross-validation. The data set is split into k subsets and recurring k times are the holdout technique. One of the k subsets is used as the test set each time, and the other k-1 subsets are put together to form a training set. Then the median mistake is calculated in all k tests. The benefit of this technique is that how the information is split is less important. Each data point becomes precisely once in a test set and becomes k-1 times in a training set. Like “k” increases, the variance of the subsequent estimate is decreased.
The advantage of doing this is the independent selection of how large each test set is and how many trials one can average over.
### KFOLD
# Define training control
set.seed(123)
train.control = trainControl(method = "cv", number = 10)
# Train the model
model = train(y ~., data = sim_data, method = "lm", trControl = train.control)
# Summarize the results
print(model)
4. Adversarial validation
In terms of feature distribution, the general idea is to check the degree of similarity between training and testing: if they are difficult to distinguish, the distribution is likely to be similar and the usual validation techniques should work. It doesn’t seem like that, so we can assume that they’re quite distinct. Combining train and sample sets, assigning 0/1 tags (0 — train,1-test) and assessing a binary classification assignment can quantify this assumption.
5. Stratified k-fold cross validation
Stratification is the information rearrangement method to guarantee that each layer is a healthy representative of the whole. For example, in a binary classification issue where each class consists of 50 per cent of the data, it is best to arrange the data so that each class consists of about half of the instances in each fold. The intuition behind this concerns the bias of most algorithms for classification. They tend to weigh each example similarly, meaning that over-represented categories get too much weight (e.g. optimizing F-measure, accuracy, or an additional type of mistake). For an algorithm, stratification is not so essential that weights each category similarly
We have learnt about cross-validation in machine learning is and understood the importance of the concept. Although it is an important aspect of machine learning, it has its own limitations.
Cross-validation is only meaningful until the time world represented by data is perfect. If there are anomalies in data then predictive modelling fails to perform well
Let us consider an example where cross-validation can fail. Suppose we develop a model for predicting the one’s risk of suffering from a particular disease. However, if we train our model using data involving a specific section of the population. The moment we apply the model to the general population, the results may vary a lot.
Summary
In this blog, we had a look at different cross-validation techniques. We also touched upon the implementation of these techniques through the code in R. Cross-validation is a crucial concept in increasing the ML model’s ability to perform well on unseen data. These techniques help us to avoid underfitting and overfitting while training our ML models and hence should not be overlooked!
Machine learning paradigm is ruled by a simple theorem known as “No Free Lunch” theorem. According to this, there is no algorithm in ML which will work best for all the problems. To state, one can not conclude that SVM is a better algorithm than decision trees or linear regression. Selection of an algorithm is dependent on the problem at hand and other factors like the size and structure of the dataset. Hence, one should try different algorithms to find a better fit for their use case
In this blog, we are going to look into the top machine learning algorithms. You should know and implement the following algorithms to find out the best one for your use case
Top 10 Best Machine Learning Algorithms
1. Linear Regression
Regression is a method used to predict numerical numbers. Regression is a statistical measure which tries to determine the power of the relation between the label-related characteristics of a single variable and other factors called autonomous (periodic attributes) variable. Regression is a statistical measure. Just as the classification is used for categorical label prediction, regression is used for ongoing value prediction. For example, we might like to anticipate the salary or potential sales of a new product based on the prices of graduates with 5-year work experience. Regression is often used to determine how the cost of an item is affected by specific variables such as product cost, interest rates, specific industries or sectors.
The linear regression tries by a linear equation to model the connection between a scalar variable and one or more explaining factors. For instance, using a linear regression model, one might want to connect the weights of people to their heights
The driver calculates a linear pattern of regression. It utilizes the model selection criterion Akaike. A test of the comparative value of fitness to statistics is the Akaike information criterion. It is based on the notion of entropy, which actually provides a comparative metric of data wasted when a specified template is used to portray the truth. The compromise between bias and variance in model building or between the precision and complexity of the model can be described.
2. Logistic Regression
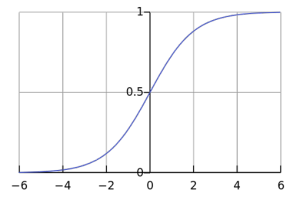
Logistic regression is a classification system that predicts the categorical results variable that may take one of the restricted sets of category scores using entry factors. A binomial logistical regression is restricted to 2 binary outputs and more than 2 classes can be achieved through a multinomial logistic regression. For example, classifying binary conditions as’ safe’/’don’t-healthy’ or’ bike’ /’ vehicle’ /’ truck’ is logistic regression. Logistic regression is used to create an information category forecast for weighted entry scores by the logistic sigmoid function.
The probability of a dependent variable based on separate factors is estimated by a logistic regression model. The variable depends on the yield that we want to forecast, whereas the indigenous variables or explaining variables may affect the performance. Multiple regression means an assessment of regression with two or more independent variables. On the other side, multivariable regression relates to an assessment of regression with two or more dependent factors.
3. Linear Discriminant Analysis
Logistic regression is traditionally a two-class classification problem algorithm. If you have more than two classes, the Linear Discriminant Analysis algorithm is the favorite technique of linear classification. It contains statistical information characteristics, which are calculated for each category.
For a single input variable this includes:
The mean value for each class.
The variance calculated across all classes.
The predictions are calculated by determining a discriminating value for each class and by predicting the highest value for each class. The method implies that the information is distributed Gaussian (bell curve) so that outliers are removed from your information in advance. It is an easy and strong way to classify predictive problem modeling.
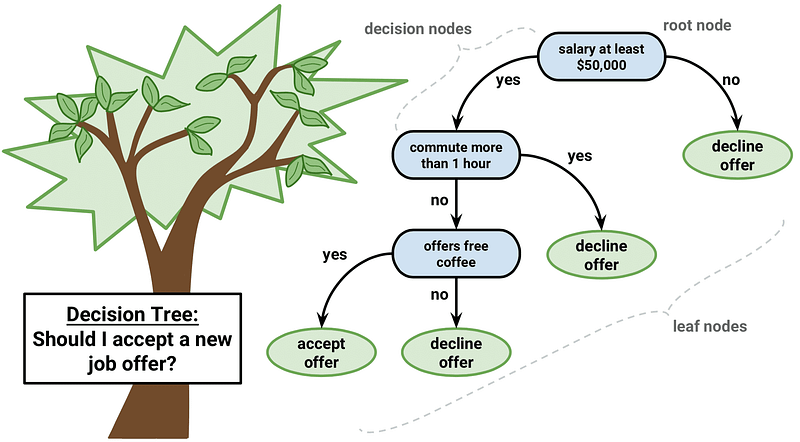
4. Classification and Regression Trees
Prediction Trees are used to forecast answer or YY class of X1, X2,…, XnX1,X2,… ,Xn entry. If the constant reaction is called a regression tree, it is called a ranking tree, if it is categorical. We inspect the significance of one entry XiXi at any point of the tree and proceed to the left or to the correct subbranch, based on the (binary) response. If we hit a tree, we will discover the forecast (generally the leaves as the most popular value of the accessible courses is a straightforward statistical figure of the dataset). In contrast to global model linear or polynomial regression (a predictive formula should be contained in the whole data space), trees attempt to split the data space in a sufficiently small part, where a simply different model can be applied on each side. For each xx information, the non-leaf portion of the tree is simply the process to determine what model we use for the classification of each information (i.e. which leaf).
5. Naive Bayes
A Naive Bayes classification is a supervised algorithm for machinery-learning which utilizes the theorem of Bayes, which implies statistical independence of its characteristics. The theorem depends on the naive premise that input factors are autonomous from each other, that is, that when an extra variable is provided there is no way to understand anything about other factors. It has demonstrated to be a classifier with excellent outcomes regardless of this hypothesis. The Bavarian Theorem, relying on a conditional probability, or in easy words, is used for the Naive Bayes classifications as a probability of a case (A) occurring considering that another incident (B) has already occurred. In essence, the theorem enables an update of the hypothesis every moment fresh proof is presented.
The equation below expresses Bayes’ Theorem in the language of probability:
Let’s explain what each of these terms means.
“P” is the symbol to denote probability.
P(A | B) = The probability of event A (hypothesis) occurring given that B (evidence) has occurred.
P(B | A) = The probability of the event B (evidence) occurring given that A (hypothesis) has occurred.
P(A) = The probability of event B (hypothesis) occurring.
P(B) = The probability of event A (evidence) occurring.
6. K-Nearest Neighbors
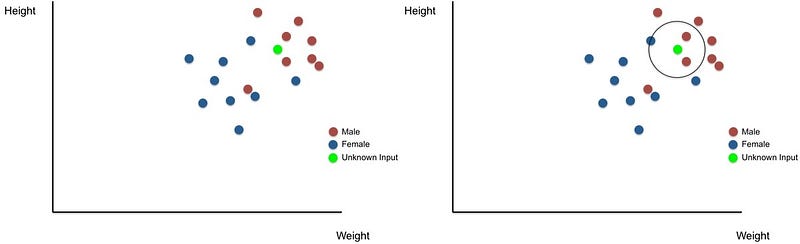
The KNN is a simple machine study algorithm which classifies an entry using its closest neighbours. The input of information points of particular males and women’s height and weight as shown below should be provided, for instance, by a k-NN algorithm. K-NN can peer into the closest k neighbour (personal) and determine if the entry gender is masculine in order to determine the gender of an unidentified object (green point). This technique is extremely easy and logical, with a strong achievement level for labelling unidentified input.
k-NN is used in a range of machine learning tasks; k-NN, for example, can help in computer vision in hand-written letters and the algorithm is used to identify genes that are contributing to a specific characteristic of the gene expression analysis. Overall, neighbours close to each other offer a mixture of ease and efficiency that makes it an appealing algorithm for many teaching machines.7. Learning Vector Quantization
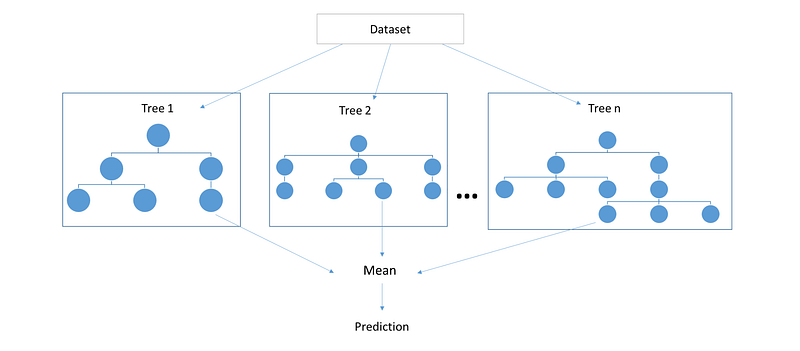
8. Bagging and Random Forest
A Random Forest is a group of easy tree predictors, each of which is capable of generating an answer when it has a number of predictor values. This reaction requires the form of a class affiliation for classification issues, which combines or classifies a number of indigenous predictor scores with one of the classifications in the dependent variable. Otherwise, the tree reaction is an assessment of the dependent variable considering the predictors for regression difficulties. Breiman has created the Random Forest algorithm.
An arbitrary amount of plain trees are a random forest used to determine the ultimate result. The ensemble of easy trees votes for the most common category for classification issues. Their answers are averaged to get an assessment of the dependent variable for regression problems. With tree assemblies, the forecast precision (i.e. greater capacity to detect fresh information instances) can improve considerably.
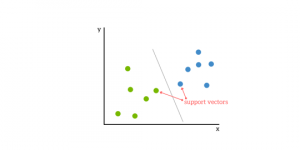
9. SVM
The support vector machine(SVM) is a supervised, classifying, and regressing machine learning algorithm. In classification issues, SVMs are more common, and as such, we shall be focusing on that article.SVMs are based on the idea of finding a hyperplane that best divides a dataset into two classes, as shown in the image below.
You can think of a hyperplane as a line that linearly separates and classifies a set of data.
The more our information points are intuitively located from the hyperplane, the more assured that they have been categorized properly. We would, therefore, like to see as far as feasible from our information spots on the right hand of the hyperplane.
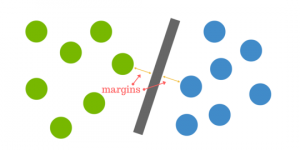
So when new test data are added, the class we assign to it will be determined on any side of the hyperplane.
The distance from the hyperplane to the nearest point is called the margin. The aim is to select a hyperplane with as much margin as feasible between the hyperplane and any point in the practice set to give fresh information a higher opportunity to be properly categorized.
But the data is rarely ever as clean as our simple example above. A dataset will often look more like the jumbled balls below which represent a linearly non-separable dataset.
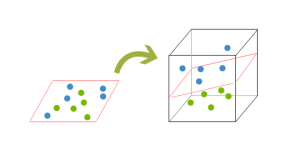
It is essential to switch from a 2D perspective to a 3D perspective to classify a dataset like the one above. Another streamlined instance makes it easier to explain this. Imagine our two balls stood on a board and this booklet is raised abruptly, throwing the balls into the air. You use the cover to distinguish them when the buttons are up in the air. This “raising” of the balls reflects a greater identification of the information. This is known as kernelling.
Our hyperplanes can be no longer a row because we are in three dimensions. It should be a flight now, as shown in the above instance. The concept is to map the information into greater and lower sizes until a hyperplane can be created to separate the information.
10. Boosting and AdaBoost
Boosting is an ensemble technology which tries to build a powerful classification of a set of weak classifiers. This is done using a training data model and then a second model has created that attempts the errors of the first model to be corrected. Until the training set is perfectly predicted or a maximum number of models are added, models are added.
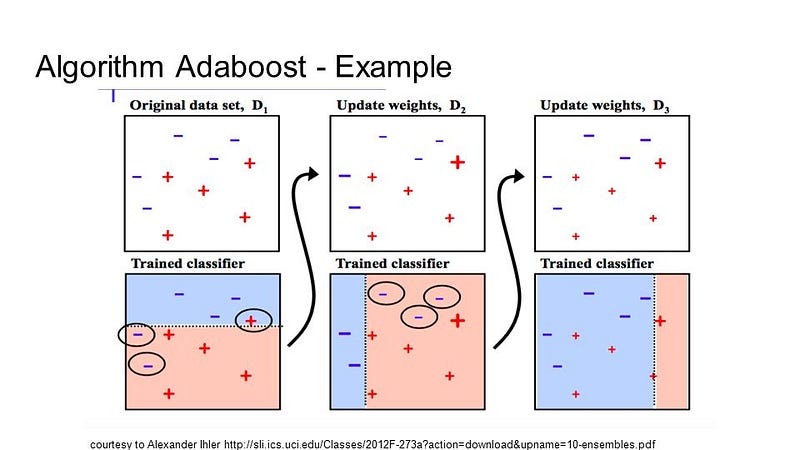
AdaBoost was the first truly effective binary classification boosting algorithm. It is the best point of start for improvement. Most of them are stochastic gradient boosters, based on AdaBoost modern boosting techniques.
With brief choice trees, AdaBoost is used. After the creation of the first tree, each exercise instance uses the performance of the tree to weigh how much attention should be given to the next tree to be built. Data that are difficult to forecast will be provided more weight, while cases that are easily predictable will be less important. Sequentially, models are produced one by one to update each of the weights on the teaching sessions which impact on the study of the next tree. After all, trees have been produced, fresh information are predicted and how precise it was on the training data weighs the efficiency of each tree.
Since the algorithm is so careful about correcting errors, it is essential that smooth information is deleted with outliers.
Summary
In the end, every beginner in data science has one basic starting questions that which algorithm is best for all the cases. The response to the issue is not straightforward and depends on many factors like information magnitude, quality and type of information; time required for computation; the importance of the assignment; and purpose of information
Even an experienced data scientist cannot say which algorithm works best before distinct algorithms are tested. While many other machine learning algorithms exist, they are the most common. This is a nice starting point to understand if you are a beginner for machine learning.