Artificial intelligence uses data science and algorithms to automate, optimize and find value hidden from the human eye. By one estimate, artificial intelligence will drive nearly $2 trillion worth of business value worldwide in 2019 alone. Hence, that’s an excellent incentive to grab a slice of the AI bounty. Also, fortune favors those who get an early start. Therefore, the laggards might not be so fortunate.
Artificial Intelligence (AI) is the rage now, but like all things tech, it is in a continuous state of evolution. Here is how Artificial Intelligence is expected to play out in 2019.
Trends in Artificial Intelligence
1. Automation of DevOps to achieve AIOps
There’s been a lot of attention in recent years about how artificial intelligence (AI) and machine learning (ML). Furthermore, DevOps is all about automation of tasks. Its focus is on automating and monitoring steps in the software delivery process, ensuring that work gets done quickly. AI and ML are perfect fits for a DevOps culture. Also, they can process vast amounts of information and help perform menial tasks. They can learn patterns, anticipate problems and suggest solutions. If DevOps’ goal is to unify development and operations, AI and ML can smooth out some of the tensions that separate the two disciplines in the past.
Moreover, one of the key tenets of DevOps is the use of continuous feedback loops at every stage of the process. This includes using monitoring tools to provide feedback on the operational performance of running applications. Additionally, this is one area today where ML is impacting DevOps already. Also, using automation technology, chatbots, and other AI systems, these communications channels can become more streamlined and proactive. Also, in the future, we can see AI/ML’s application in other stages of the software development life cycle. This will provide enhancements to a DevOps methodology or approach.
Furthermore, one area where this may happen could be in the area of software testing. Unit tests, regression tests, and other tests all produce large amounts of data in the form of test results. Applying AI to these test results could identify patterns of poor codes resulting in errors caught by the tests.
2. The Emergence of More Machine Learning Platforms
People are yet not done figuring out machine learning, and now there is a rise of a new advanced term on the market for machine learning, and, i.e. “Automated Machine Learning.” Automated machine learning is a more straightforward concept, and it makes things easier for developers and professionals. Furthermore, AutoML is a shift from traditional rule-based programming to an automation form where machines can learn the rules. Also, in automated machine learning, we offer a relevant and diverse set of reliable data to, in the beginning, to help automate the process of decision making. The engineers will no longer have to spend time on repetitive tasks, thanks to AutoML. The growth in the demand for machine learning professionals will get a massive boost with the rise of AutoML.
We’re in a golden era where all platform mega-vendors providing mobile infrastructure are rolling out mobile-accessible tools for mobile developers. For example:
Imagine a world where you can sit next to your customers and have a one on one conversation about their expectations from your brand with every interaction, and deliver on their expectations every single time. As we move forward in the digital era, this might be the reality for the brands, where businesses get the opportunity to win their customers’ heart with every single interaction. Artificial Intelligence and Augmented Reality are two such technologies, which will show the most potential in connecting with consumers in 2019 and will rule the technology landscape. The key reason behind this trend is that, compared to virtual reality, which needs a hardware device like Oculus Rift, it is fairly simple to implement augmented reality. It only needs a smartphone and an app.
Since the entry barrier is low, today’s tech-savvy consumers do not shy away from experimenting with the technology, and for enterprises, it only requires a thought-through AR-based app. Further, with tech giants like Apple, Google, Facebook making it easier for developers to build AR-based apps for their platforms, it has become easier even for smaller businesses to invest in augmented reality. Also, industries like retail, healthcare, travel etc. have already created a lot of exciting use cases with AR. With technology giants Apple, Google, Facebook etc. offering tools to make the development of AR-based apps easier, 2019 will see an upsurge in the number of AR apps being released.
4. Agent-Based Simulations
Agent-based modelling is a powerful simulation modelling technique that has seen a number of applications in the last few years, including applications to real-world business problems. Furthermore, in agent-based modelling (ABM), a system is modelled as a collection of autonomous decision-making entities called agents. Each agent individually assesses its situation and makes decisions on the basis of a set of rules. Agents may execute various behaviours appropriate for the system they represent — for example, producing, consuming, or selling.
The benefits of ABM over other modelling techniques can be captured in three statements: (i) ABM captures emergent phenomena; (ii) ABM provides a natural description of a system; and (iii) ABM is flexible. It is clear, however, that the ability of ABM to deal with emergent phenomena is what drives the other benefits.
Also, ABM uses a “bottom-up” approach, creating emergent behaviours of an intelligent system through “actors” rather than “factors”. However, macro-level factors have a direct impact on macro behaviours of the system. Macy and Willer (2002) suggest that bringing those macro-level factors back will make agent-based modelling more effective, especially in intelligent systems such as social organizations.
5. IoT
The Internet of Things is reshaping life as we know it from the home to the office and beyond. IoT products grant us extended control over appliances, lights, and door locks. They also help streamline business processes; and more thoroughly connect us to the people, systems, and environments that shape our lives. IoT and data remain intrinsically linked together. Data consumed and produced keeps growing at an ever expanding rate. This influx of data is fueling widespread IoT adoption as there will be nearly 30.73 billion IoT connected devices by 2020.
Data Analytics has a significant role to play in the growth and success of IoT applications and investments. Analytics tools will allow the business units to make effective use of their datasets as explained in the points listed below.
Volume: There are huge clusters of data sets that IoT applications make use of. The business organizations need to manage these large volumes of data and need to analyze the same for extracting relevant patterns. These datasets along with real-time data can be analyzed easily and efficiently with data analytics software.
Structure: IoT applications involve data sets that may have a varied structure as unstructured, semi-structured and structured data sets. There may also be a significant difference in data formats and types. Data analytics will allow the business executive to analyze all of these varying sets of data using automated tools and software.
Driving Revenue: The use of data analytics in IoT investments will allow the business units to gain insight into customer preferences and choices. This would lead to the development of services and offers as per the customer demands and expectations. This, in turn, will improve the revenues and profits earned by the organizations.
6. AI Optimized Hardware
The demand for artificial intelligence will increase tremendously in the next couple of years, and it’s no surprise considering the fact it’s disrupting basically every major industry. Yet as these systems do more and more complex tasks, they demand more computation power from hardware. Machine learning algorithms are also present locally on a variety of edge devices to reduce latency, which is critical for drones and autonomous vehicles. Local deployment also decreases the exchange of information with the cloud which greatly lowers networking costs for IoT devices.
Current hardware, however, is big and uses a lot of energy, which limits the types of devices which can run these algorithms locally. But being the clever humans we are, we’re working on many other chip architectures optimized for machine learning which are more powerful, energy efficient, and smaller.
There’s a ton of companies working on AI specific hardware
Google’s tensor processing units (TPU), which they offer over the cloud and costs just a quarter compared to training a similar model on AWS.
Microsoft is investing in field programmable gate arrays (FGPA) from Intel for training and inference of AI models. FGPA’s are highly configurable, so they can easily be configured and optimized for new AI algorithms.
Intel has a bunch of hardware for specific AI algorithms like CNN’s. They’ve also acquired Nervana, a startup working on AI chips, with a decent software suite for developers as well.
IBM’s doing a lot of research into analogue computation and phase changing memory for AI.
Nvidia’s dominated the machine learning hardware space because of their great GPU’s, and now they’re making them even better for AI applications, for example with their Tesla V100 GPU’s.
7. Natural Language Generation
The global natural language generation market size will grow from USD 322.1 million in 2018 to USD 825.3 million by 2023. A necessity to understand customers’ behaviour has led to a rise in better customer experience across different industry verticals. This factor is driving organisations to build personalised relationships based on customers’ activities or interactions. Moreover, big data created an interest among organisations to derive insights from collected data for taking better and real-time decisions. Thus, NLG solutions have gained significance in extracting insights into human-like languages that are easy to understand. However, the lack of a skilled workforce to deploy NLG solutions is a major factor restraining the growth of the market.
8. Streaming Data Platforms
Streaming data platforms bring together are not only about just low-latency analysis of information. But, the important aspect lies in the ability to integrate data between different sources. Furthermore, there is a rise in the importance of data-driven organizations and the focus on low-latency decision making. Hence, the speed of analytics increased almost as rapidly as the ability to collect information. This is where the world of streaming data platforms comes into play. These modern data management platforms bring the ability to integrate information from operation systems in real-time/near real-time.
Through Streaming analytics, real-time information can be gathered and analyzed from and on the cloud. The information is captured by devices and sensors that are connected to the Internet. Some examples of these streaming platforms can be
Apache Flink
Kafka
Spark Streaming/Structured Streaming
Azure Streaming services
9. Driverless Vehicles
Car manufacturers are hoping autonomous-driving technology will spur a revolution among consumers, igniting sales and repositioning the U.S. as the leader in the automotive industry. Companies like General Motors and Ford are shifting resources away from traditional product lines and — alongside tech companies like Google’s Waymo — pouring billions into the development of self-driving cars. Meanwhile, the industry is pressuring Congress to advance a regulatory framework that gives automakers the confidence to build such vehicles without worrying whether they’ll meet as-yet-unspecified regulations that might bar them from the nation’s highways.
Supporters say the technology holds immense promise in reducing traffic deaths and giving elderly individuals and other population groups access to safe and affordable alternatives to driving themselves. Achieving those benefits, however, will come with trade-offs.
10. Conversational BI and Analytics
We are seeing two major shifts happening in entire BI/Analytics and AI space. First, analytic capabilities are moving toward augmented analytics, which is capable of giving more business down insights and has less dependency on domain experts. Second, we are seeing is the convergence of conversational platforms with these enhanced capabilities around augmented analytics. We expect these capabilities and adoption to quickly proliferate across organizations, especially those organizations that already are having some form for BI in place.
Summary
Many technology experts postulate that the future of AI and machine learning is certain. It is where the world is headed. In 2019 and beyond these technologies are going to shore up support as more businesses come to realize the benefits. However, the concerns surrounding the reliability and cybersecurity will continue to be hotly debated. The artificial intelligence trends and machine learning trends for 2019 and beyond hold promises to amplify business growth while drastically shrinking the risks. So, are you ready to take your business to the next level with Artificial Intelligence trends?
Follow this link, if you are looking to learn more about data science online!
Interactive notebooks are experiencing a rise in popularity. How do we know? They’re replacing PowerPoint in presentations, shared around organizations, and they’re even taking workload away from BI suites. Today there are many notebooks to choose from Jupyter, R Markdown, Apache Zeppelin, Spark Notebook and more. There are kernels/backends to multiple languages, such as Python, Julia, Scala, SQL, and others. Notebooks are typically used by data scientists for quick exploration tasks.
In this blog, we are going to learn about Jupyter notebooks and Google colab. We will learn about writing code in the notebooks and will focus on the basic features of notebooks. Before diving directly into writing code, let us familiarise ourselves with writing the code notebook style!
The Notebook way
Traditionally, notebooks have been used to document research and make results reproducible, simply by rerunning the notebook on source data. But why would one want to choose to use a notebook instead of a favorite IDE or command line? There are many limitations in the current browser-based notebook implementations, but what they do offer is an environment for exploration, collaboration, and visualization. Notebooks are typically used by data scientists for quick exploration tasks. In that regard, they offer a number of advantages over any local scripts or tools. Notebooks also tend to be set up in a cluster environment, allowing the data scientist to take advantage of computational resources beyond what is available on her laptop, and operate on the full data set without having to download a local copy.
Jupyter Notebooks
The Jupyter Notebook is an open source web application that you can use to create and share documents that contain live code, equations, visualizations, and text. Jupyter Notebook is maintained by the people at Project Jupyter.
Jupyter Notebooks are a spin-off project from the IPython project, which used to have an IPython Notebook project itself. The name, Jupyter, comes from the core supported programming languages that it supports: Julia, Python, and R. Jupyter ships with the IPython kernel, which allows you to write your programs in Python, but there are currently over 100 other kernels that you can also use.
Why Jupyter Notebooks
Jupyter notebooks are particularly useful as scientific lab books when you are doing computational physics and/or lots of data analysis using computational tools. This is because, with Jupyter notebooks, you can:
Record the code you write in a notebook as you manipulate your data. This is useful to remember what you’ve done, repeat it if necessary, etc.
Graphs and other figures are rendered directly in the notebook so there’s no more printing to paper, cutting and pasting as you would have with paper notebooks or copying and pasting as you would have with other electronic notebooks.
You can have dynamic data visualizations, e.g. animations, which is simply not possible with a paper lab book.
One can update the notebook (or parts thereof) with new data by re-running cells. You could also copy the cell and re-run the copy only if you want to retain a record of the previous attempt.
Google Colab
Colaboratory is a free Jupyter notebook environment that requires no setup and runs entirely in the cloud. With Colaboratory you can write and execute code, save and share your analyses, and access powerful computing resources, all for free from your browser.
Why Google Colab
As the name suggests, Google Colab comes with collaboration backed in the product. In fact, it is a Jupyter notebook that leverages Google Docs collaboration features. It also runs on Google servers and you don’t need to install anything. Moreover, the notebooks are saved to your Google Drive account.
Some Extra Features
1. System Aliases
Jupyter includes shortcuts for common operations, such as ls and others.
2. Tab-Completion and Exploring Code
Colab provides tab completion to explore attributes of Python objects, as well as to quickly view documentation strings.
3. Exception Formatting
Exceptions are formatted nicely in Colab outputs
4. Rich, Interactive Outputs
Until now all of the generated outputs have been text, but they can be more interesting.
5. Integration with Drive
Colaboratory is integrated with Google Drive. It allows you to share, comment, and collaborate on the same document with multiple people:
Differences between Google Colab and Jupyter notebooks
1. Infrastructure Google Colab runs on Google Cloud Platform ( GCP ). Hence it’s robust, flexible
2. Hardware Google Colab recently added support for Tensor Processing Unit ( TPU ) apart from its existing GPU and CPU instances. So, it’s a big deal for all deep learning people.
3. Pricing Despite being so good at hardware, the services provided by Google Colab are completely free. This makes it even more awesome.
4. Integration with Google Drive Yes, this seems interesting as you can use your google drive as an interactive file system with Google Colab. This makes it easy to deal with larger files while computing your stuff.
5. Boon for Research and Startup Community Perhaps this is the only tool available in the market which provides such a good PaaS for free to users. This is overwhelmingly helpful for startups, the research community and students in deep learning space
Working with Notebooks — The Cells Based Method
Jupyter Notebook supports adding rich content to its cells. In this section, you will get an overview of just some of the things you can do with your cells using Markup and Code.
Cell Types
There are technically four cell types: Code, Markdown, Raw NBConvert, and Heading.
The Heading cell type is no longer supported and will display a dialogue that says as much. Instead, you are supposed to use Markdown for your Headings.
The Raw NBConvert cell type is only intended for special use cases when using the nbconvert command line tool. Basically, it allows you to control the formatting in a very specific way when converting from a Notebook to another format.
The primary cell types that you will use are the Code and Markdown cell types. You have already learned how code cells work, so let’s learn how to style your text with Markdown.
Styling Your Text
Jupyter Notebook supports Markdown, which is a markup language that is a superset of HTML. This tutorial will cover some of the basics of what you can do with Markdown.
Set a new cell to Markdown and then add the following text to the cell:
When you run the cell, the output should look like this:
If you would prefer to bold your text, use a double underscore or double asterisk.
Headers
Creating headers in Markdown is also quite simple. You just have to use the humble pound sign. The more pound signs you use, the smaller the header. Jupyter Notebook even kind of previews it for you:
Then when you run the cell, you will end up with a nicely formatted header:
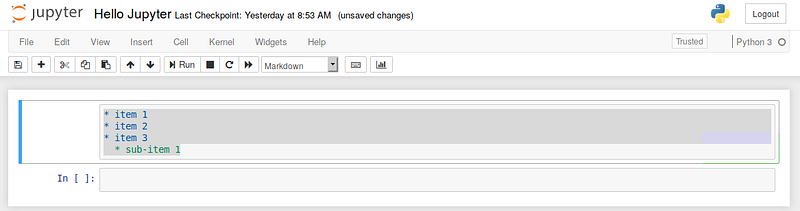
Creating Lists
You can create a list (bullet points) by using dashes, plus signs, or asterisks. Here is an example:
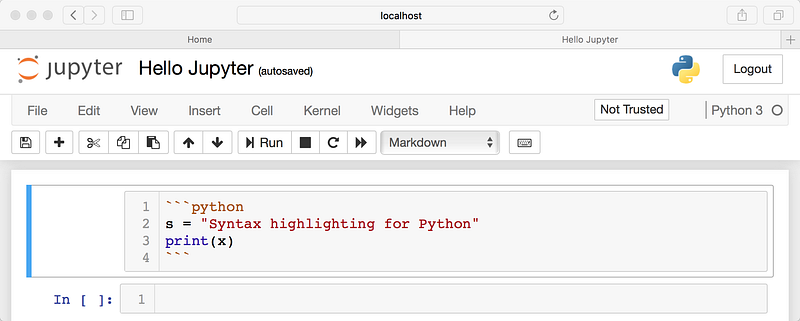
Code and Syntax Highlighting
If you want to insert a code example that you don’t want your end user to actually run, you can use Markdown to insert it. For inline code highlighting, just surround the code with backticks. If you want to insert a block of code, you can use triple backticks and also specify the programming language:
Useful Jupyter Notebook Extensions
Extensions are a very productive way of enhancing your productivity on Jupyter Notebooks. One of the best tools to install and use extensions I have found is ‘Nbextensions’. It takes two simple steps to install it on your machine (there are other methods as well but I found this the most convenient):
Step 1: Install it from pip:
pip install jupyter_contrib_nbextensions
Step 2: Install the associated JavaScript and CSS files:
jupyter contrib nbextension install --user
Once you’re done with this, you’ll see a ‘Nbextensions’ tab on the top of your Jupyter Notebook home. And voila! There are a collection of awesome extensions you can use for your projects.
Multi-user Notebooks
There is a thing called JupyterHub which is the proper way to host a multi-user notebook server which might be useful for collaboration and could potentially be used for teaching. However, I have not investigated this in detail as there is no need for it yet. If lots of people start using jupyter notebooks, then we could look into whether JupyterHub would be of benefit. Work is also ongoing to facilitate real-time live collaboration by multiple users on the same notebook — more information is available here and here.
Summary
Jupyter notebooks are useful as a scientific research record, especially when you are digging about in your data using computational tools. In this lesson, we learned about Jupyter notebooks. To add, in Jupyter notebooks, we can either be in insert mode or escape mode. While in insert mode, we can edit the cells and undo changes within that cell with cmd + z on a mac or ctl + z on windows. In escape mode, we can add cells with b, delete a cell with x, and undo deletion of a cell with z. We can also change the type of a cell to markdown with m and to Python code with y. Furthermore, we can have our code in a cell executed, we need to press shift + enter. If we do not do this, then the variables that we assigned in Python are not going to be recognized by Python later on in our Jupyter notebook.
Jupyter notebooks/Google colab are more focused on making work reproducible and easier to understand. These notebooks find the usage in cases where you need story telling with your code!
Follow this link, if you are looking to learn more about data science online!
Data scientists are one of the most hirable specialists today, but it’s not so easy to enter this profession without a “Projects” field in your resume. Furthermore, you need the experience to get the job, and you need the job to get the experience. Seems like a vicious circle, right? Also, the great advantage of data science projects is that each of them is a full-stack data science problem. Additionally, this means that you need to formulate the problem, design the solution, find the data, master the technology, build a machine learning model, evaluate the quality, and maybe wrap it into a simple UI. Hence, this is a more diverse approach than, for example, Kaggle competition or Coursera lessons.
Hence, in this blog, we will look at 10 projects to undertake in 2019 to learn data science and improve your understanding of different concepts.
Projects
1. Match Career Advice Questions with Professionals in the Field
Problem Statement: The U.S. has almost 500 students for every guidance counselor. Furthermore, youth lack the network to find their career role models, making CareerVillage.org the only option for millions of young people in America and around the globe with nowhere else to turn. Also, to date, 25,000 create profiles and opt-in to receive emails when a career question is a good fit for them. This is where your skills come in. Furthermore, to help students get the advice they need, the team at CareerVillage.org needs to be able to send the right questions to the right volunteers. The notifications for the volunteers seem to have the greatest impact on how many questions are answered.
Your objective: Develop a method to recommend relevant questions to the professionals who are most likely to answer them.
Problem Statement: In this competition, you must create an algorithm to identify metastatic cancer in small image patches taken from larger digital pathology scans. Also, the data for this competition is a slightly different version of the PatchCamelyon (PCam) benchmark dataset. PCam is highly interesting for both its size, simplicity to get started on, and approachability.
Your objective: Identify metastatic tissue in histopathologic scans of lymph node sections
Problem Statement: To assess the impact of climate change on Earth’s flora and fauna, it is vital to quantify how human activities such as logging, mining, and agriculture are impacting our protected natural areas. Furthermore, researchers in Mexico have created the VIGIA project, which aims to build a system for autonomous surveillance of protected areas. Moreover, the first step in such an effort is the ability to recognize the vegetation inside the protected areas. In this competition, you are tasked with the creation of an algorithm that can identify a specific type of cactus in aerial imagery.
Your objective: Determine whether an image contains a columnar cactus
Problem Statement: In a world, where movies made an estimate of $41.7 billion in 2018, the film industry is more popular than ever. But what movies make the most money at the box office? How much does a director matter? Or the budget? For some movies, it’s “You had me at ‘Hello. In this competition, you’re presented with metadata on over 7,000 past films from The Movie Database to try and predict their overall worldwide box office revenue. Also, the data points provided include cast, crew, plot keywords, budget, posters, release dates, languages, production companies, and countries. Furthermore, you can collect other publicly available data to use in your model predictions.
Your objective: Can you predict a movie’s worldwide box office revenue?
Problem Statement: An existential problem for any major website today is how to handle toxic and divisive content. Furthermore, Quora wants to tackle this problem head-on to keep their platform a place where users can feel safe sharing their knowledge with the world. On Quora, people can ask questions and connect with others who contribute unique insights and quality answers. A key challenge is to weed out insincere questions — those founded upon false premises, or that intend to make a statement rather than look for helpful answers.
In this competition, you need to develop models that identify and flag insincere questions. Moreover, to date, Quora has employed both machine learning and manual review to address this problem. With your help, they can develop more scalable methods to detect toxic and misleading content.
Your objective: Detect toxic content to improve online conversations
Problem Statement: This competition is provided as a way to explore different time series techniques on a relatively simple and clean dataset. You are given 5 years of store-item sales data and asked to predict 3 months of sales for 50 different items at 10 different stores. What’s the best way to deal with seasonality? Should stores be modelled separately, or can you pool them together? Does deep learning work better than ARIMA? Can either beat xgboost? Also, this is a great competition to explore different models and improve your skills in forecasting.
Your Objective: Predict 3 months of item sales at different stores
Problem Statement: This competition focuses on the problem of forecasting the future values of multiple time series, as it has always been one of the most challenging problems in the field. More specifically, we aim the competition at testing state-of-the-art methods designed by the participants, on the problem of forecasting future web traffic for approximately 145,000 Wikipedia articles. Also, the sequential or temporal observations emerge in many key real-world problems, ranging from biological data, financial markets, weather forecasting, to audio and video processing. Moreover, the field of time series encapsulates many different problems, ranging from analysis and inference to classification and forecast. What can you do to help predict future views?
Problem Statement: Forecast future traffic to Wikipedia pages
Problem Statement: What does physics have in common with biology, cooking, cryptography, diy, robotics, and travel? If you answer “all pursuits are under the immutable laws of physics” we’ll begrudgingly give you partial credit. Also, If you answer “people chose randomly for a transfer learning competition”, congratulations, we accept your answer and mark the question as solved.
In this competition, we provide the titles, text, and tags of Stack Exchange questions from six different sites. We then ask for tag predictions on unseen physics questions. Solving this problem via a standard machine approach might involve training an algorithm on a corpus of related text. Here, you are challenged to train on material from outside the field. Can an algorithm learn appropriate physics tags from “extreme-tourism Antarctica”? Let’s find out.
Your objective: Predict tags from models trained on unrelated topics
Problem Statement: MNIST (“Modified National Institute of Standards and Technology”) is the de facto “hello world” dataset of computer vision. Since its release in 1999, this classic dataset of handwritten images has served as the basis for benchmarking classification algorithms. As new machine learning techniques emerge, MNIST remains a reliable resource for researchers and learners alike. Furthermore, in this competition, your goal is to correctly identify digits from a dataset of tens of thousands of handwritten images.
Your objective: Learn computer vision fundamentals with the famous MNIST data
Problem Statement: The sinking of the RMS Titanic is one of the most infamous shipwrecks in history. On April 15, 1912, during her maiden voyage, the Titanic sank after colliding with an iceberg, killing 1502 out of 2224 passengers and crew. Furthermore, this sensational tragedy shocked the international community and led to better safety regulations for ships. Also, one of the reasons that the shipwreck led to such loss of life was that there were not enough lifeboats for the passengers and crew. Although there was some element of luck involved in surviving the sinking, some groups of people were more likely to survive than others, such as women, children, and the upper-class. In this challenge, we ask you to complete the analysis of what sorts of people were likely to survive.
Your objective: Predict survival on the Titanic and get familiar with ML basics
2019 looks to be the year of using smarter technology in a smarter way. Three key trends — artificial intelligence systems becoming a serious component in enterprise tools, custom hardware breaking out for special use-cases, and a rethink on data science and its utility — will all combine into a common theme.
In recent years, we’ve seen all manner of jaw-dropping technology, but the emphasis has been very much on what these gadgets and systems can do and how they do it, with much less attention paid to why.
In this blog, we will explore different areas in data science and figure out our expectations in 2019 in them. Areas include machine learning, AR/VR systems, edge computing etc. Let us go through them one by one
Machine Learning/Deep Learning
Businesses are using machine learning to improve all sorts of outcomes, from optimizing operational workflows and increasing customer satisfaction to discovering to a new competitive differentiator. But, now all the hype around AI is settling. Machine learning is not a cool term anymore. Furthermore, organisations are looking for more ways of identifying more options in the form of agent modelling. Apart from this, more adoption of these algorithms looks very feasible now. Adoption will be seen in new and old industries
Healthcare companies are already big users of AI, and this trend will continue. According to Accenture, the AI healthcare market might hit $6.6 billion by 2021, and clinical health AI applications can create $150 billion in annual savings for the U.S. healthcare economy by 2026.
In retail, global spending on AI will grow to $7.3 billion a year by 2022, up from $2 billion in 2018, according to Juniper Research. This is because companies will invest heavily in AI tools that will help them differentiate and improve the services they offer customers.
In cybersecurity, the adoption of AI brings a boom in startups that are able to raised$3.65 billion in equity funding in the last five years. Cyber AI can help security experts sort through millions of incidents to identify aberrations, risks, and signals of future threats.
And there is even an opportunity brewing in industries facing labour shortages, such as transportation. At the end of 2017, there was a shortage of 51,000 truck drivers (up from a shortage of 36,000 the previous year). And the ATA reports that the trucking industry will need to hire 900,000 more drivers in the next 10 years to keep up with demand. AI-driven autonomous vehicles could help relieve the need for more drivers in the future.
Programming Language
The practice of data science requires the use of analytics tools, technologies and programming languages to help data professionals extract insights and value from data. A recent survey of nearly 24,000 data professionals by Kaggle suggests that Python, SQL and R are the most popular programming languages. The most popular, by far, was Python (83%). Additionally, 3 out of 4 data professionals recommended that aspiring data scientists learn Python first.
Survey results show that 3 out of 4 data professionals would recommend Python as the programming language aspiring data scientists to learn first. The remaining programming languages are recommended at a significantly lower rate (R recommended by 12% of respondents; SQL by 5% of respondents. Anyhow, Python will also boom more in 2019. But, R community too have come up with a lot of recent advancements. With new packages and improvements, R is expected to come closer to python in terms of usage.
Blockchain and Big Data
In recent years, the blockchain is at the heart of computer technologies. It is a cryptographically secure distributed database technology for storing and transmitting information. The main advantage of the blockchain is that it is decentralized. In fact, no one controls the data entering or their integrity. However, these checks run through various computers on the network. These different machines hold the same information. In fact, faulty data on one computer cannot enter the chain because it will not match the equivalent data held by the other machines. To put it simply, as long as the network exists, the information remains in the same state.
Big Data analytics will be essential for tracking transactions and enabling businesses that use the Blockchain to make better decisions. That’s why new Data Intelligence services are emerging to help financial institutions and governments and other businesses discover who they interact with within the Blockchain and discover hidden patterns.
Augmented-Reality/Virtual Reality
The broader the canvas of visualization is, the better the understanding is. That’s exactly what happens when one visualizes big data through the Augmented Reality (AR) and Virtual Reality (VR). A combination of AR and VR could open a world of possibilities to better utilize the data at hand. VR and AR can practically improve the way we perceive data and could actually be the solution to make use of the large unused data.
By presenting the data in the form of 3D, the user will be able to decipher the major takeaways from the data better and faster with easier understanding. Many recent types of research show that the VR and AR has a high sensory impact which promotes faster learning and understanding.
This immersive way of representation of the data enables the analysts to handle the big data more efficiently. It makes the analysis and interpretation more of an experience and realisation that the traditional analysis. Instead of the user seeing numbers and figures, the person will be able to see beyond it and into the facts, happenings and reasons which could revolutionize the businesses.
Edge Computing
Computing infrastructure is an ever-changing landscape of technology advancements. Current changes affect the way companies deploy smart manufacturing systems to make the most of advancements.
The rise of edge computing capabilities coupled with traditional industrial control system (ICS) architectures provides increasing levels of flexibility. In addition, time-synchronized applications and analytics augment the need for larger Big Data operations in the cloud. This is regardless of cloud premise.
Edge is still in early stage adoption. But, one thing is clear that edge devices are subject to large-scale investments from cloud suppliers to offload bandwidth. Also, there are latency issues due to an explosion of the IoT data in both industrial and commercial applications.
Edge soon will likely increase in adoption where users have questions about the cloud’s specific use case. Cloud-level interfaces and apps will migrate to the edge. Industrial application hosting and analytics will become common at the edge. This will happen using virtual servers and simplified operational technology-friendly hardware and software.
The Rise of Semi-Automated Tools for Data Science
There has been a rise of self-service BI tools such as Tableau, Qlik Sense, Power BI, and Domo. Furthermore, now managers can obtain current business information in graphical form on demand. Although, IT may need to set up a certain amount of setup at the outset. Also, when adding a data source, most of the data cleaning work and analysis can be done by analysts. The analyses can update automatically from the latest data any time they are opened.
Managers can then interact with the analyses graphically to identify issues that need to be addressed. In a BI-generated dashboard or “story” about sales numbers, that might mean drilling down to find underperforming stores, salespeople, and products, or discovering trends in year-over-year same-store comparisons. These discoveries might in turn guide decisions about future stocking levels, product sales and promotions. Also, they may determine the building of additional stores in under-served areas.
Upgrade in Job Roles
In recent times, there have been a lot of advancements in the data science industry. With these advancements, different businesses are in better shape to extract much more value out of their data. With an increase in expectation, there is a shift in the roles of both data scientists and business analysts now. The data scientists should move from statistical focus phase to more of a research phase. But the business analysts are now filling in the gap left by data scientists and are taking their roles up.
We can see it as an upgrade in both the job roles. Business analysts now hold the business angle firm but are also handling the statistical and technical part of the things too. Business analysts are now more into predictive analytics. They are at a stage now where they can use off-the-shelf algorithms for predictions in their business domains. BA’s are not only for reporting and business mindset but now are more into the prescriptive analytics too. They are handling the role of model building, data warehousing and statistical analysing.
Summary
How this question is answered will be fascinating to watch. It could be that the data science field has to completely overhaul what it can offer, overcoming seeming off-limit barriers. Alternatively, it could be that businesses discover their expectations can’t be met and have to adjust to this reality in a productive manner rather than get bogged down in frustration.
In conclusion, 2019 promises to be a year where smart systems make further inroads into our personal and professional lives. More importantly, I expect our professional lives to get more sophisticated with a variety of agents and systems helping us get more of out of our time in the office!
Follow this link, if you are looking to learn more about data science online!
Over the last few years, blockchain has been one of the hottest areas of technology development across industries. It’s easy to see why. There seems to be no end to the myriad ways that forward-thinking businesses are finding. Furthermore, they are doing this to adapt the technology to suit a variety of use cases and applications. Much of the development, however, has come in one of two places. One is deep-pocket corporations and crypto-startups.
That means that the latest in blockchain technology is out of reach for businesses in the small and midsize enterprise (SME) sector. This leads to creating something of a digital divide that seems to be widening every day. But, there are a few blockchain projects that promise to democratise the technology for SMEs. Furthermore, this could even do the same for Big Data and analytics, to boot.
In this blog, we will explore the basics of both big data and blockchain. Furthermore, we will analyse the advantages of combining both big data and blockchain. In the end, we will have a look the applications in real-world and wrap up with predictions about blockchain in future!
What is Big Data?
Big data, in general, refers to sets of data that are so large in volume and complexity. Traditional data processing software are not capable of capturing and processing this data within a reasonable amount of time.
These big data sets can include structured, unstructured, and semistructured data, each of which can go through analysis for insights.
How much data actually constitutes “big” is open to debate. But it can typically be in multiples of petabytes — and for the largest projects in the exabytes range.
Often, big data is a combination of the three Vs:
an extreme volume of data
a broad variety of types of data
the velocity at which the data needs processing and analysis
The data that constitutes big data stores can come from sources like web sites, social media, desktop and mobile apps etc. The concept of big data comes components that enable organisations to put the data into practical use. Furthermore, they can solve a number of business problems with this. These include the IT infrastructure to support big data; the analytics applied to the data; technologies needed for big data projects; related skill sets; and the actual use cases that make sense for big data.
What is Block Chain?
The blockchain is a technology that is revolutionising the way the internet works. Some of the main distinguishing points of blockchain technology are:
The technology works by creating a series of data records where each new record resides in a block and has a link to the previous record. The term blockchain is derived from this system of linking blocks of data.
Blockchain technology makes possible a distributed ledger system which makes records more transparent.
It uses cryptography to protect user information, and the distributed ledger system is almost, if not impossible, to hack.
Forms the backbone of cryptocurrency but also has several other applications.
Cryptocurrency exchanges on the blockchain network can be central or a network.
Decentralised cryptocurrency exchanges are virtually impossible to hack because there are multiple nodes supporting the system.
Blockchain technology has made peer to peer sharing of content possible without the need for a middleman platform.
Regardless of what you share via the blockchain network, you retain ownership of your content unless you sell it to someone.
Personal information is highly secure and under protection with private key cryptography.
In a nutshell, the blockchain is a network technology that provides users with a chance to share content or make transactions securely without the need for a middleman or a central governing system.
What are the Blocks?
In very simple terms, a block, which is part of the blockchain, is a data file that records any type of transaction on the network. Data resides permanently on the block and becomes part of the chain and impossible to tamper with. For example, if you buy two bitcoins, the transaction is available in a block along with your private key. The private key is your digital signature and links the transaction to you. It is now forever recorded in one block that on that date, you bought two bitcoins.
If you want to buy something with one bitcoin, you will need to provide your private key. A bitcoin miner will use your key to track the last transaction to you and can verify that you have two bitcoins. When you use one bitcoin, that transaction resides in a new block and linked to your last transaction with a series of characters. In this way, all your transactions are audited on the network.
What are Hashes?
One of the reasons the blockchain is so popular is because the information on it, although distributed, is highly encrypted. Data on the blockchain is under encryption by creating a hash. An algorithm is required to create a hash, and it acts by taking the transaction information and converting it to a series of numbers and letters. Hashes are always of the same length.
On the surface, a hash does not make sense to anyone. This is where miners come in. Miners have the special skill set and the resources to decipher a hash and verify the transaction. Miners get paid in bitcoins that undergo generation every time they deliver a service.
What are the Nodes?
The blockchain and cryptocurrency have become synonymous with being decentralised. Decentralisation forms the entire basis of the transparency and the security of the system. But, even a decentralised system requires a support system to give it some form and structure. This support system comes in the form of nodes.
Nodes are focal points of activity spread all over the blockchain network. It is at nodes that blockchain copies are available, transactions undergo processing, and records are available. Nodes consist of individuals that are connected to the system via their own device. Each cryptocurrency has its own set of nodes to keep track of its coins.
Why Blockchain?
The advantage of blockchain is that it is decentralised — no single person or company controls data entry or its integrity; however, the sanctity of the blockchain is through check continuously happening by every computer on the network. As all points hold the same information, corrupt data at point “A” can’t become part of the chain because it won’t match up with the equivalent data at points “B” and “C”.
With the above in mind, blockchain is immutable — information remains in the same state for as long as the network exists.
Why combine Big Data with Blockchain
1. Security
Instead of uploading data to a cloud server or storing it in a single location, blockchain breaks everything into small chunks and distributes them across the entire network of computers. It effectively cuts out the middle man. There is no need to engage a third-party to process a transaction. You don’t have to place your trust in a vendor or service provider when you can rely on a decentralized, immutable ledger. Also, everything that occurs on the blockchain is encrypted and it’s possible to prove that data has not been altered. Because of its distributed nature, you can check file signatures across all the ledgers on all the nodes in the network and verify that they haven’t been changed
2. Data Quality
Blockchain provides superior Data Security and Data Quality and, as a consequence, is changing the way people approach Big Data. This can be quite useful, as security remains a primary concern for the Internet of Things (IoT) ecosystems. IoT systems expose a variety of devices and huge amounts of data to security breaches. Blockchain has great potential for blocking hackers and providing security in a number of fields, ranging from banking to healthcare to Smart Cities.
3. Privacy
This is one of the main ways in which blockchain sets itself apart from the traditional models of technology that are common today. Blockchain does not require any identity for the network layer itself. This means no name, email, address or any other information is needed to download and start utilizing the technology. This lack of a hard requirement of personal information means that there is no central server storing users’ information, making blockchain technology considerably more secure than a central server which can be breached, putting its users’ sensitive data at risk.
4. Transparency
One of the most appealing aspects of blockchain technology is the degree of privacy that it can provide. However, this leads to some confusion about how privacy and transparency can effectively coexist. The transparency of a blockchain stems from the fact that the holdings and transactions of each public address are open to viewing. Using an explorer, with a user’s public address, it is possible to view their holdings and their transactions. This level of transparency has not existed within financial systems before, especially in regards to large businesses, and adds a degree of accountability that has not existed to date.
5. Automation
These days, the trend in business processes is undeniably moving away from slow, manual methods and toward greater automation and centralization. Automating your processes has a number of benefits: completing tasks faster, increasing visibility, standardizing outputs, reducing errors, and lowering costs, just to name a few. Although automation has done a great deal to help companies become more efficient and productive, there’s further change on the horizon. In particular, blockchain workflow automation can help organizations that rely heavily on transactions and document-based processes to take the next step in their digital transformation.
Applications
1. Anti Money Laundering
Blockchain technology and its ledger allows for more transparency with regulators improving the reporting process. Furthermore, the shared and immutable ledger allows for unaltered transaction history. Also, the ledger can act as a central hub for data storage to process transactions. It can act with the activity across with risk officers within the financial services companies and regulators.
Improved identity management using encryption-based technology on a decentralized network could be established. Furthermore, digital identity improvements can help financial institutions meet the ever-changing KYC and CDD requirements. Moreover, this can happen simultaneously reducing the costs associated with implementing a robust KYC program. Ultimately, financial crimes and compliance violations could be reduced in the long term.
2. Cybersecurity
Blockchain technology is present in every sphere of our lives from banking to healthcare and beyond. Furthermore, cybersecurity is an industry which has a lot to gain by this technology with a scope for more in the future. Also, by removing much of the human element from data storage, blockchains significantly mitigate the risk of human error, which is the largest cause of data breaches. The reason why this technology has high popularity is that you can put any digital asset or transaction into the blockchain, the industry does not matter. Additionally, blockchain technology can prevent any type of data breaches, identity thefts, cyber-attacks or foul play in transactions. Hence, the data remains private and secure.
3. Supply Chain Monitoring
The possibilities for application of Blockchain in Big-Data Supply Chain solutions are present in this KPMG Report. The goods are in addition to the Blockchain and a Mobile App monitors the status of the goods as they are in transportation. Data is available with all parties in “near real-time” according to the report. Among the benefits include verification of Product Labeling Claims and that of Product Origins. And most important is the possibility of ensuring human rights with regard to fair wages etc.
4. Financial AI Systems
In terms of financial transactions, Blockchain is taking off in a major way and is set to become a significant aspect of monetary transactions. There are many other innovative ways wherein Big Data and Blockchain can be synchronous to deliver powerful products in the financial services industry. Auditing can have enhancements in a very thorough manner by Blockchain implementation. Also, the Ernst & Young Report states that the “time for experimentation is now.”
5. Automobile AI Systems
The Automobile industry is entering an altogether new phase of existence as cars are now more in sharing, self-driven and available with a host of sensor and communication technologies. As automobiles become autonomous, the range of options available using Blockchain begins with the complete standardisation of vehicle data which makes up a 100 per cent information automobile market.
6. Medical Records
This is an area where records are crucial and are always reside and scrutinized. When the Big Data systems that power this data-oriented sector is put through a Blockchain system, all records preserve with a clear track record while all migrations and interpretations that have been made to records are maintainable in a transparent manner. Also, systems have been in talks whereby researchers can contribute to mining in return for data at an aggregate level. Google is also developing a Blockchain system towards ensuring the security of health records.
Summary
Blockchain technology is just one of the ways to evolve automation and business process management in the future. While Blockchains are still early in the technology life cycle the constant stress tests by wider public adoption will only make the ecosystem more robust by improving on the building blocks already in motion. No doubt that blockchain is promising for data science. But, the truth is that we do not have many blockchain technology systems on an industrial scale. Furthermore, for data scientists, this means that it will take a while for the data treasure that Blockchain technology has to offer.
Follow this link, if you are looking to learn more about data science online!