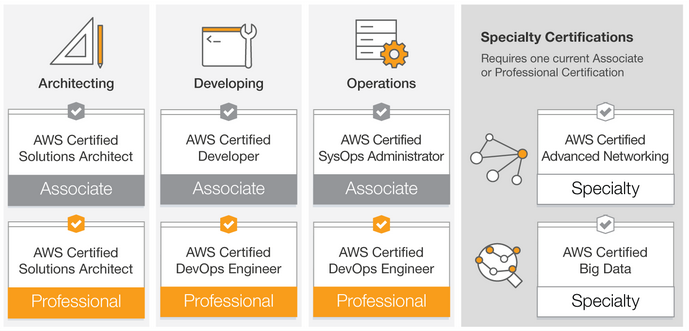
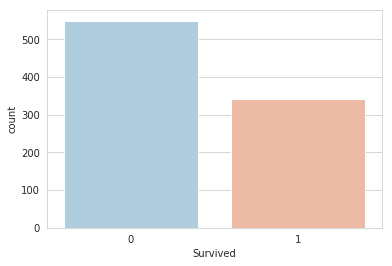So you want to do your AWS certification! Personal comment from me – an excellent choice. Not only is it the most valuable certification available right now (money-wise), it also has excellent career prospects abroad. And did we mention money? Starting salary for an AWS Big Data Speciality Certified Professional is $160,000 USD a year. With experience and good performance, in three years, if you work hard and show rockstar potential, you are looking at an annual salary of 250,000+ USD!
There are numerous advantages to becoming AWS certified. Amazon Web Services certifications…
1. Validate your skills and knowledge in the preeminent cloud computing platform. 2. Consistently listed among the top paying info-tech certifications worldwide. 3. Garner more interviews for aspiring cloud specialists, and higher wages once hired. 4. Recognized industry-wide as reliable and well-designed tech credentials. 5. Demonstrate credibility and dedication to your cloud computing career path. 6. Provide access to a network of like-minded peers and AWS thought-leaders. 7. Require recertification which ensures that your AWS skills remain current.
From www.itcareerfinder.com
If you want to be in high demand and command the highest salaries in the market, go for AWS.
Now there’s no better way to prepare than to have hands-on experience with AWS for two years at least. Also, the Big Data Speciality requires you to have a primary AWS Associate-level certification first, and at least five years experience in the data analytics field.
To know more about preparing for AWS Big Data Certification have a look at the official document from Amazon, available at the following link:
Now you may tell me, how do I get practical experience if I am a beginner? Well, we have good news for you, newbie. Amazon offers a free training digital course for all of its certifications. To know more, visit the following link:
As a beginner, you will have to go through the ranks until you do an Associate certification or become a Certified Cloud Practitioner. In order to motivate you to do this, here are the average starting salaries for the five most common AWS jobs (from a Google Search – applies to the US and to Canada):
Source: 2017 IT Skills & Salary Report by Global Knowledge
You can join a startup if you like to work with computers and have a passion for code. In other cases, say in which you are a student, do the following free courses from Amazon Online AWS Training:
You may wonder, this is an article for preparation for a certification which requires 5 years+ work experience in data analytics. And starting at the bottom and working your way up is a long and arduous journey. What can someone who is just starting out really do in the AWS field?
Don’t worry.
Dimensionless Technologies has you covered!
We’ve got your back, bro!
AWS Cloud Computing Course with Big Data
Dimensionless Technologies has a new cloud computing big data course that is starting very soon. To learn more about it, please go to the link below:
I encourage you to visit the link above. I will give a short summary on this blog page as well.
Dimensionless Technologies
Dimensionless has an advantage over nearly all other online training courses on the market, simply because the courses are conducted in a classroom environment – but remote, and online. Students of all levels ranging from beginners to college grads to industry professionals will find themselves at home with this course. This course is unlike many other options available online because just 40 students are enrolled in one batch. This automatically ensures the following:
Personalized attention for every student
Ability to clear doubts with the instructor since every session is live
Guaranteed completion of the course
Assured job placement with faculty having several industry contacts
Live projects for the best learning experience
AWS project portfolio creation and mentoring for every student.
And you get to evaluate all of that with an initial payment of just 72$ USD.
Please do make the investment, because this is a chance of a lifetime.
An extremely prosperous and prestigious career is waiting for you.
Trust me, you won’t regret it!
For more details on the Big Data Certification Speciality, please refer to the article below:
All the best, and remember: you are among a privileged few who will ever have an opportunity to work on such advanced and intrinsically interesting technology as a professional calling.
Love your work.
Enjoy what you do.
Because you are truly privileged to be in this position.
My future is so bright that I need to wear sunglasses! (Flickr.com)
Now, in theory, it is possible to become a data scientist, without paying a dime. What we want to do in this article is to list out the best of the best options to learn what you need to know to become a data scientist. Many articles offer 4-5 courses under each heading. What I have done is to search through the Internet covering all free courses and choose the single best course for each topic.
These courses have been carefully curated and offer the best possible option if you’re learning for free. However – there’s a caveat. An interesting twist to this entire story. Interested? Read on! And please – make sure you complete the full article.
Topics For A Data Scientist Course
The basic topics that a data scientist needs to know are:
Machine Learning Theory and Applications
Python Programming
R Programming
SQL
Statistics & Probability
Linear Algebra
Calculus Basics (short)
Machine Learning in Python
Machine Learning in R
Tableau
So let’s get to it. Here is the list of the best possible options to learn every one of these topics, carefully selected and curated.
Machine Learning – Stanford University – Andrew Ng (audit option)
The world-famous course for machine learning with the highest rating of all the MOOCs in Coursera, from Andrew Ng, a giant in the ML field and now famous worldwide as an online instructor. Uses MATLAB/Octave. From the website:
This course provides a broad introduction to machine learning, data mining, and statistical pattern recognition. Topics include:
(ii) Unsupervised learning (clustering, dimensionality reduction, recommender systems, deep learning)
(iii) Best practices in machine learning (bias/variance theory; innovation process in machine learning and AI)
The course will also draw from numerous case studies and applications, so that you’ll also learn how to apply learning algorithms to building smart robots (perception, control), text understanding (web search, anti-spam), computer vision, medical informatics, audio, database mining, and other areas.
This course is extremely effective and has many benefits. However, you will need high levels of self-discipline and self-motivation. Statistics show that90% of those who sign up for a MOOC without a classroom or group environment never complete the course.
Learn Python The Hard Way – Zed Shaw – Free Online Access
You may ask me, why do I want to learn the hard way? Shouldn’t we learn the smart way and not the hard way? Don’t worry. This ebook, online course, and web site is a highly popular way to learn Python. Ok, so it says the hard way. Well, the only way to learn how to code is to practice what you have learned. This course integrates practice with learning. Other Python books you have to take the initiative to practice.
Here, this book shows you what to practice, how to practice. There is only one con here – although this is the best self-driven method, most people will not complete all of it. The main reason is that there is no external instructor for supervision and a group environment to motivate you. However, if you want to learn Python by yourself, then this is the best way. But not the optimal one, as you will see at the end of this article since the cost of the book is 30$ USD (2100 INR approx).
Interactive R and Data Science Programming – SwiRl
Swirlstats is a wonderful tool to learn R and data science scripting in R interactively and intuitively by teaching you R commands from within the R console. This might seem like a very simple tool, but as you use it, you will notice its elegance in teaching you literally how to express yourselves in R and the finer nuances of the language and integration with the console and tidyverse. This is a powerful method of learning R and what is more, it is also a lot of fun!
KhanAcademy is a free non-profit organization on a mission – they want to provide a world-class education to you regardless of where you may be in the world. And they’re doing a fantastic job! This course has been covered in several very high profile blogs and Quora posts as the best online course for statistics – period. What is more, it is extremely high quality and suitable for beginners – and – free! This organization is doing wonderful work. More power to them!
Mathematics for Data Science
Now the basic mathematics for data science content includes linear algebra, single-variable, discrete mathematics, and multivariable calculus (selected topics) and basics of differential equations. Now you could take all of these topics separately in KhanAcademy and that is a good option for Linear Algebra and Multivariate Calculus (in addition to Statistics and Probability).
For Linear Algebra, the link of what you need to know given in a course in KhanAcademy is given below:
These courses are completely free and very accessible to beginners.
Discrete Mathematics
This topic deserves a section to itself because discrete mathematics is the foundation of all computer science. There are a variety of options available to learn discrete mathematics, from ebooks to MOOCs, but today, we’ll focus on the best possible option. MIT (Massachusetts Institute of Technology) is known as one of the best colleges in the world and they have an Open information initiative known as MIT OpenCourseWare (MIT OCW). These are actual videos of the lectures taken by the students at one of the best engineering colleges in the world. You will benefit a lot if you follow the lectures at this link, they give all the basic concepts as clearly as possible. It’s a bit technical because this is open mostly for students at an advanced level. The link is given below:
It is also technical and from MIT but might be a little more accessible than the earlier option.
SQL
SQL (see-quel) or Structured Query Language is a must-learn if you are a data scientist. You will be working with a lot of databases, and SQL is the language used to access and generate data from database systems like Oracle and Microsoft SQL Server. The best free course I could find online is undoubtedly the one below:
We have covered Python, R, Machine Learning using MATLAB, Data Science with R (SwiRl teaches data science as well), Statistics, Probability, Linear Algebra, and Basic Calculus. Now we just need to get a course for Data Science with Python, and we are done! Now I looked at many options but was not satisfied. So instead of a course, I have provided you with a link to the scikit-learn documentation. Why?
Because that’s as good as an online course by itself. If you read through the main sections, get the code (Ctrl-X, Ctrl-V) and execute it in an Anaconda environment, and then play around with it, experiment, and observe and read up on what every line does, you will already know who to solve standard textbook problems. I recommend the following order:
This book is free to learn online. Get the data files, get the script files, use RStudio, and just as with Python, play, enjoy, experiment, execute, and explore. A little hard work will have you up and running with R in no time! But make sure you try as many code examples as possible. The libraries you can focus on are:
dplyr (data manipulation)
tidyr (data preprocessing “tidying”)
ggplot2 (graphical package)
purrr (functional toolkit)
readr (reading rectangular data files easily)
stringr (string manipulation)
tibble (dataframes)
Tableau
To make it short, simple, and sweet, since we have already covered SQL and this content is for beginners, I recommend the following course:
This is a course on Udemy rated 4.2/5 and completely free. You will learn everything you need to work with Tableau (the most commonly used corporate-level visualization tool). This is an extremely important part of your skill set. You can make all the greatest analyses, but if you don’t visualize them and do it well, management will never buy into your machine learning solution, and neither will anyone who doesn’t know the technical details of ML (which is a large set of people on this planet). Visualization is important. Please make sure to learn the basics (at least!) of Tableau.
From Unsplash
Kaggle Micro-Courses (Add-Ons – Short Concise Tutorials)
Kaggle is a wonderful site to practice your data science skills, but recently, they have added a set of hands-on courses to learn data science practicals. And, if I do say, so myself, it’s brilliant. Very nicely presented, superb examples, clear and concise explanations. And of course, you will cover more than we discussed earlier. Please, if you read through all the courses discussed so far in this article, and if you do just the courses at Kaggle.com, you will have spent your time wisely (though not optimally – as we shall see).
Kaggle Learn
Dimensionless Technologies
Dimensionless Technologies
Now, if you are reading this article, you might have a fundamental question. This is a blog of a company that offers courses in data science, deep learning, and cloud computing. Why would we want to list all our competitors and publish it on our site? Isn’t that negative publicity?
Quite the opposite.
This is the caveat we were talking about.
Our course is a better solution than every single option given above!
We have nothing to hide.
And we have an absolutely brilliant top-class product.
Every option given above is a separate course by itself.
And they all suffer from a very prickly problem – you need to have excellent levels of discipline and self-motivation to complete just one of the courses above – let alone all ten.
You also have no classroom environment, no guidance for doubts and questions, and you need to know the basics about programming.
Our product is the most cost-effective option in the market for learning data science, as well as the most effective methodology for everyone – every course is conducted live in a classroom environment from the comfort of your home. You can work at a standard job, spend two hours on the internet every day, do extra work and reading on weekends, and become a professional data scientist in 6 months time.
We also have personalized GitHub project portfolio creation, management, and faculty guidance. Not to mention individual attention for each student.
And IITians for faculty who also happen to have 9+ years of industry experience.
So when we say that our product is the best on the market, we really mean it. Because of the live session teaching of the classes, which no other option on the Internet today has.
Am I kidding? Absolutely not. And you can get started with Dimensionless Technologies Data Science with Python and R course for just 70-odd USD. Which is the most cost-effective option on the market!
And unlike all the 10 courses and resources detailed above, instead of doing 10 courses, you just need to do one single course, with the extracted meat of all that you need to know as a data scientist. And yes, we cover:
Machine Learning
Python Programming
R Programming
SQL
Statistics & Probability
Linear Algebra
Calculus Basics
Machine Learning in Python
Machine Learning in R
Tableau
GitHub Personal Project Portfolio Creation
Live Remote Daily Sessions
Experts with Industrial Experience
A Classroom Environment (to keep you motivated)
Individual Attention to Every Student
I hope this information has you seriously interested. Please sign up for the course – you will not regret it.
And we even have a two-week trial for you to experience the course for yourself.
Choose wisely and optimally.
Unleash the data scientist within!
An excellent general article on emerging state-of-the-art technology, AI, and blockchain:
I am so thrilled to welcome you to the absolutely awesome world of data science. It is an interesting subject, sometimes difficult, sometimes a struggle but always hugely rewarding at the end of your work. While data science is not as tough as, say, quantum mechanics, it is not high-school algebra either.
It requires knowledge of Statistics, some Mathematics (Linear Algebra, Multivariable Calculus, Vector Algebra, and of course Discrete Mathematics), Operations Research (Linear and Non-Linear Optimization and some more topics including Markov Processes), Python, R, Tableau, and basic analytical and logical programming skills.
.Now if you are new to data science, that last sentence might seem more like pure Greek than simple plain English. Don’t worry about it. If you are studying the Data Science course at Dimensionless Technologies, you are in the right place. This course covers the practical working knowledge of all the topics, given above, distilled and extracted into a beginner-friendly form by the talented course material preparation team.
This course has turned ordinary people into skilled data scientists and landed them with excellent placement as a result of the course, so, my basic message is, don’t worry. You are in the right place and with the right people at the right time.
What is Data Science?
To quote Wikipedia:
Data science is a multi-disciplinary field that uses scientific methods, processes, algorithms, and systems to extract knowledge and insights from structured and unstructured data. Data science is the same concept as data mining and big data: “use the most powerful hardware, the most powerful programming systems, and the most efficient algorithms to solve problems.”
Data Science is the art of extracting critical knowledge from raw data that provides significant increases in profits for your organization.
We are surrounded by data (Google ‘data deluge’ and you’ll see what I mean). More data has been created in the last two years that in the last 5,000 years of human existence.
The companies that use all this data to gain insights into their business and optimize their processing power will come out on top with the maximum profits in their market.
Companies like Facebook, Amazon, Microsoft, Google, and Apple (FAMGA), and every serious IT enterprise have realized this fact.
Hence the demand for talented data scientists.
I have much more to share with you on this topic, but to keep this article short, I’ll just share the links below which you can go through in your free time (everyone’s time is valuable because it is a strictly finite resource):
Now as I was planning this article a number of ideas came to my mind. I thought I could do a textbook-like reference to the field, with Python examples.
But then I realized that true competence in data science doesn’t come when you read an article.
True competence in data science begins when you take the programming concepts you have learned, type them into a computer, and run it on your machine.
And then; of course, modify it, play with it, experiment, run single lines by themselves, see for yourselves how Python and R work.
That is how you fall in love with coding in data science.
At least, that’s how I fell in love with simple C coding. Back in my UG in 2003. And then C++. And then Java. And then .NET. And then SQL and Oracle. And then… And then… And then… And so on.
If you want to know, I first started working in back-propagation neural networks in the year 2006. Long before the concept of data science came along! Back then, we called it artificial intelligence and soft computing. And my final-year project was coded by hand in Java.
Having come so far, what have I learned?
That it’s a vast massive uncharted ocean out there.
The more you learn, the more you know, the more you become aware of how little you know and how vast the ocean is.
But we digress!
To get back to my point –
My final decision was to construct a beginner project, explain it inside out, and give you source code that you can experiment with, play with, enjoy running, and modify here and there referring to the documentation and seeing what everything in the code actually does.
Kaggle – Your Home For Data Science
www.kaggle.com
If you are in the data science field, this site should be on your browser bookmark bar. Even in multiple folders, if you have them.
Kaggle is the go-to site for every serious machine learning practitioner. They hold competitions in data science (which have a massive participation), have fantastic tutorials for beginners, and free source code open-sourced under the Apache license (See this link for more on the Apache open source software license – don’t skip reading this, because as a data scientist this is something about software products that you must know).
As I was browsing this site the other day, a kernel that was attracting a lot of attention and upvotes caught my eye.
This kernel is by a professional data scientist by the name of Fatma Kurçun from Istanbul (the funny-looking ç symbol is called c with cedilla and is pronounced with an s sound).
It was quickly clear why it was so popular. It was well-written, had excellent visualizations, and a clear logical train of thought. Her professionalism at her art is obvious.
Since it is an open source Apache license released software, I have modified her code quite a lot (diff tool gives over 100 changes performed) to come up with the following Python classification example.
But before we dive into that, we need to know what a data science project entails and what classification means.
Let’s explore that next.
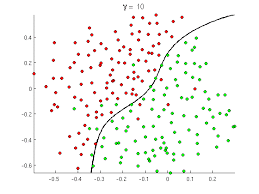
Classification and Data Science
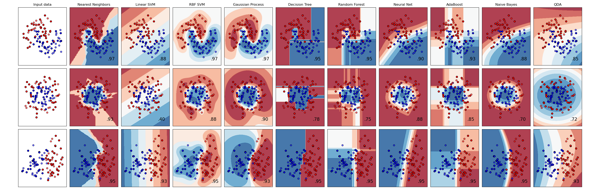
So supervised classification basically means mapping data values to a category defined in advance. In the image above, we have a set of customers who have certain data values (records). So one dot above corresponds with one customer with around 10-20 odd fields.
Now, how do we ascertain whether a customer is likely to default on a loan, and which customer is likely to be a non-defaulter? This is an incredibly important question in the finance field! You can understand the word, “classification”, here. We classify a customer into a defaulter (red dot) class (category) and a non-defaulter (green dot) class.
This problem is not solvable by standard methods. You cannot create and analyze a closed-form solution to this problem with classical methods. But – with data science – we can approximate the function that captures or models this problem, and give a solution with an accuracy range of 90-95%. Quite remarkable!
Now, again we can have a blog article on classification alone, but to keep this article short, I’ll refer you to the following excellent articles as references:
At some time in your machine learning career, you will need to go through the article above to understand what a machine learning project entails (the bread-and-butter of every data scientist).
Jupyter Notebooks
From Wikipedia
To run the exercises in this section, we use a Jupyter notebook. Jupyter is short for Julia, Python, and R. This environment uses kernels of any of these languages and has an interactive format. It is commonly used by data science professionals and is also good for collaboration and for sharing work.
To know more about Jupyter notebooks, I can suggest the following article (read when you are curious or have the time):
Data Science Libraries in Python
The standard data science stack for Python has the scikit-learn Python library as a basic lowest-level foundation.
The scikit-learn python library is the standard library in Python most commonly used in data science. Along with the libraries numpy, pandas, matplotlib, and sometimes seaborn as well this toolset is known as the standard Python data science stack. To know more about data science, I can direct you to the documentation for scikit-learn – which is excellent. The text is lucid, clear, and every file contains a working live example as source code. Refer to the following links for more:
This last link is like a bible for machine learning in Python. And yes, it belongs on your browser bookmarks bar. Reading and applying these concepts and running and modifying the source code can help you go a long way towards becoming a data scientist.
This is the classification standard data science beginner problem that we will consider. To quote Kaggle.com:
The sinking of the RMS Titanic is one of the most infamous shipwrecks in history. On April 15, 1912, during her maiden voyage, the Titanic sank after colliding with an iceberg, killing 1502 out of 2224 passengers and crew. This sensational tragedy shocked the international community and led to better safety regulations for ships.
One of the reasons that the shipwreck led to such loss of life was that there were not enough lifeboats for the passengers and crew. Although there was some element of luck involved in surviving the sinking, some groups of people were more likely to survive than others, such as women, children, and the upper-class.
In this challenge, we ask you to complete the analysis of what sorts of people were likely to survive. In particular, we ask you to apply the tools of machine learning to predict which passengers survived the tragedy.
We’ll be trying to predict a person’s category as a binary classification problem – survived or died after the Titanic sank.
So now, we go through the popular source code, explaining every step.
Import Libraries
These lines given below:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt;
import seaborn as sns
%matplotlib inline
Are standard for nearly every Python data stack problem. Pandas refers to the data frame manipulation library. NumPy is a vectorized implementation of Python matrix manipulation operations that are optimized to run at high speed. Matplotlib is a visualization library typically used in this context. Seaborn is another visualization library, at a little higher level of abstraction than matplotlib.
The Problem Data Set
We read the CSV file:
train = pd.read_csv('../input/train.csv')
Exploratory Data Analysis
Now, if you’ve gone through the links given in the heading ‘Steps involved in Data Science Projects’ section, you’ll know that real-world data is messy, has missing values, and is often in need of normalization to adjust for the needs of our different scikit-learn algorithms. This CSV file is no different, as we see below:
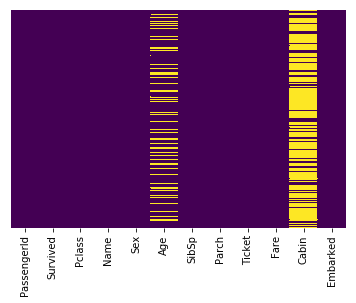
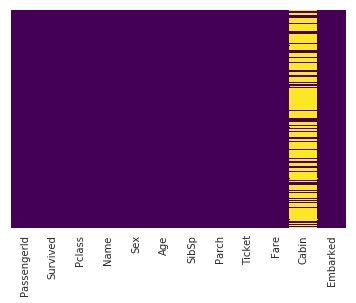
Missing Data
This line uses seaborn to create a heatmap of our data set which shows the missing values:
<matplotlib.axes._subplots.AxesSubplot at 0x7f3b5ed98ef0>
Interpretation
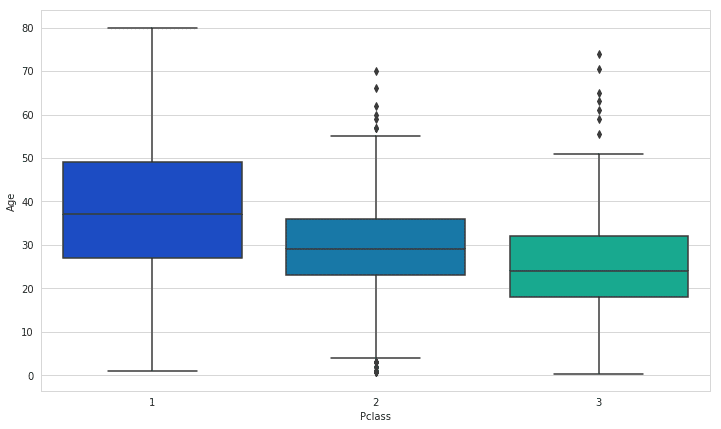
The yellow bars indicate missing data. From the figure, we can see that a fifth of the Age data is missing. And the Cabin column has so many missing values that we should drop it.
Graphing the Survived vs. the Deceased in the Titanic shipwreck:
<matplotlib.axes._subplots.AxesSubplot at 0x7f3b54fe2390>
As we can see, in our sample of the total data, more than 500 people lost their lives, and less than 350 people survived (in the sample of the data contained in train.csv).
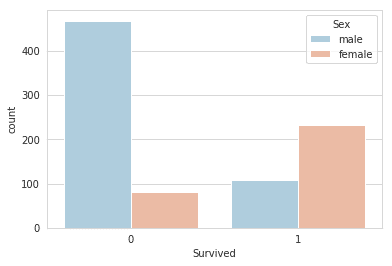
<matplotlib.axes._subplots.AxesSubplot at 0x7f3b54f49da0>
Over 400 men died, and around 100 survived. For women, less than a hundred died, and around 230 odd survived. Clearly, there is an imbalance here, as we expect.
Data Cleaning
The missing age data can be easily filled with the average of the age values of an arbitrary category of the dataset. This has to be done since the classification algorithm cannot handle missing values and will be error-ridden if the data values are not error-free.
<matplotlib.axes._subplots.AxesSubplot at 0x7f3b54d132e8>
We use these average values to impute the missing values (impute – a fancy word for filling in missing data values with values that allow the algorithm to run without affecting or changing its performance).
def impute_age(cols):
Age = cols[0]
Pclass = cols[1]
if pd.isnull(Age):
if Pclass == 1:
return 37
elif Pclass == 2:
return 29
else:
return 24
else:
return Age
We use one-hot encoding to convert the categorical attributes to numerical equivalents. One-hot encoding is yet another data preprocessing method that has various forms. For more information on it, see the link
sex = pd.get_dummies(train['Sex'],drop_first=True)
embark = pd.get_dummies(train['Embarked'],drop_first=True)
train.drop(['Embarked','Name','Ticket'],axis=1,inplace=True)
train = pd.concat([train,sex,embark],axis=1)
<matplotlib.axes._subplots.AxesSubplot at 0x7f3b54743ac8>
No missing data and all text converted accurately to a numeric representation means that we can now build our classification model.
Building a Gradient Boosted Classifier model
Gradient Boosted Classification Trees are a type of ensemble model that has consistently accurate performance over many dataset distributions. I could write another blog article on how they work but for brevity, I’ll just provide the link here and link 2 here:
We split our data into a training set and test set.
The performance of a classifier can be determined by a number of ways. Again, to keep this article short, I’ll link to the pages that explain the confusion matrix and the classification report function of scikit-learn and of general classification in data science:
A wonderful article by one of our most talented writers. Skip to the section on the confusion matrix and classification accuracy to understand what the numbers below mean.
For a more concise, mathematical and formulaic description, read here
from sklearn.metrics import classification_report,confusion_matrix
print(confusion_matrix(y_test,predictions))
[[89 16]
[29 44]]
So as not make this article too disjointed, let me explain at least the confusion matrix to you.
The confusion matrix has the following form:
[[ TP FP ]
[ FN TN ]]
The abbreviations mean:
TP – True Positive – The model correctly classified this person as deceased.
FP – False Positive – The model incorrectly classified this person as deceased.
FN – False Negative – The model incorrectly classified this person as a survivor
TN – True Negative – The model correctly classified this person as a survivor.
So, in this model published on Kaggle, there were:
So the model, when used with Gradient Boosted Classification Decision Trees, has a precision of 75% (the original used Logistic Regression).
Wrap-Up
I have attached the dataset and the Python program to this document, you can download it by clicking on these links. Run it, play with it, manipulate the code, view the scikit-learn documentation. As a starting point, you should at least:
Use other algorithms (say LogisticRegression / RandomForestClassifier a the very least)
Refer the following link for classifiers to use: Sections 1.1 onwards – every algorithm that has a ‘Classifier’ ending in its name can be used – that’s almost 30-50 odd models!
Try to compare performances of different algorithms
Try to combine the performance comparison into one single program, but keep it modular.
Make a list of the names of the classifiers you wish to use, apply them all and tabulate the results. Refer to the following link:
Use XGBoost instead of Gradient Boosting
Titanic Training Dataset (here used for training and testing):
Clone with Git (use TortoiseGit for simplicity rather than the command-line) and enjoy.
To use Git, take the help of a software engineer or developer who has worked with it before. I’ll try to cover the relevance of Git for data science in a future article.
Install Git and TortoiseGit (the latter only if necessary)
Open the command line with Run… cmd.exe
Create an empty directory.
Copy paste the following string into the command prompt and watch the magic after pressing Enter: “git clone https://github.com/thomascherickal/datasciencewithpython-article-src.git” without the double quotes, of course.
Use Anaconda (a common data science development environment with Python,, R, Jupyter, and much more) for best results.
Cheers! All the best into your wonderful new adventure of beginning and exploring data science!
Learning done right can be awesome fun! (Unsplash)
We discussed earlier in Part 1 of Blockchain Applications of Data Science on this blog how the world could be made to become much more profitable for not just a select set of the super-rich but also to the common man, to anyone who participates in creating a digitally trackable product. We discussed how large scale adoption of cryptocurrencies and blockchain technology worldwide could herald a change in the economic demography of the world that could last for generations to come. In this article, we discuss how AI and data science can be used to tackle one of the most pressing questions of the blockchain revolution – how to model the future price of the Bitcoin cryptocurrency for trading for massive profit.
A Detour
But first, we take a short detour to explore another aspect of cryptocurrency that is not commonly talked about. Looking at the state of the world right now, it should be discussed more and I feel compelled to share this information with you before we skip to the juicy part about cryptocurrency price forecasting.
The Environmental Impact of Cryptocurrency Mining
Now, two fundamental assumptions. I assume you’ve read Part 1, which contained a link to a visual guide of how cryptocurrencies work. In case you missed the latter, here’s a link for you to check again.
The following articles speak about the impact of cryptocurrency mining on the environment. Read at least one partially at the very least so that you will understand as we progress with this article:
So cryptocurrency mining involves a huge wastage of computational resources, energy, and enough electrical power to run an entire country. This is mainly due to the model of the Proof-of-Work PoW mining system used by Bitcoin. For more, see the following article..
In PoW mining, miners compete against each other in a desperate race to see who can find the solution to a mathematical hashing problem the quickest. And in every race, only one miner is rewarded with the Bitcoin value.
Ethereum goes Green! (From Pixabay)
In a significant step forward, Vitalin Buterik’s Ethereum cryptocurrency has shifted to Proof-of-Stake based (PoS) mining system. This makes the mining process significantly less energy intensive than PoW. Some claim the energy savings may be 99.9% more efficient than PoW. Whatever the statistics may be, a PoS based mining process is a big step forward and may completely change the way the environmentalists feel about cryptocurrencies.
So by shifting to PoS mining we can save a huge amount of energy. That is a caveat you need to remember and be aware about because Bitcoin uses PoW mining only. It would be a dream come true for an environmentalist if Bitcoin could shift to PoS mining. Let’s hope and pray that it happens.
Now back to our main topic.
Use AI and Data Science to Predict Future Prices of Cryptocurrency – Including the Burst of the Bitcoin Bubble
What is a blockchain? A distributed database that is decentralized and has no central point of control. As on Feb 2018, the Bitcoin blockchain on a full node was 160-odd GB in size. Now in April 2019, it is 210 GB in size. So this is the question I am going to pose to you. Would it be possible to use the data in the blockchain distributed database to identify patterns and statistical invariances to invest minimally with maximum possible profit? Can we forecast and build models to predict the prices of cryptocurrency in the future using AI and data science? The answer is a definite yes.
Practical Considerations
You may wonder if applying data science techniques and statistical analysis can actually produce information that can help in forecasting the future price of bitcoin. I came across a remarkable kernel on www.Kaggle.com (a website for data scientists to practice problems and compete with each other in competitions) by a user with the handle wayward artisan and the profile name Tania J. I thought it was worth sharing since this is a statistical analysis of the rise and the fall of the bitcoin bubble vividly illustrating how statistical methods helped this user to forecast the future price of bitcoin. The entire kernel is very large and interesting, please do visit it at the link given below. Just the start and the middle section of the kernel is given here because of space considerations and intellectual property considerations as well.
Your home for data science.
A Kaggle Kernel That Modelled the Bitcoin Bubble Burst Within Reasonable Error Limits
This following kernel uses cryptocurrency financial data scraped from www.coinmarketcap.com. It is a sobering example of how AI predictions actually predicted the collapse of the bitcoin bubble, prompting as many sellers to sell as they did. Coming across this kernel is one of the main motivations to write this article. I have omitted a lot of details, especially building the model and analyzing its accuracy. I just wanted to show that it was possible.
For more details, visit the kernel on Kaggle at the link: https://www.kaggle.com/taniaj/cryptocurrency-price-forecasting (Please visit this page, all aspiring data scientists. And pay attention to every concept discussed and used. Use Google and Wikipedia and you will learn a lot.)
A subset of the code is given below (the first section):
import pandas as pd
from pandas import DataFrame
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from datetime import datetime, timedelta
from statsmodels.tsa.arima_model import ARIMA
from statsmodels.tsa.statespace.sarimax import SARIMAX
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from statsmodels.tsa.stattools import adfuller
from statsmodels.tsa.seasonal import seasonal_decompose
from scipy import stats
import statsmodels.api as sm
from itertools import product
from math import sqrt
from sklearn.metrics import mean_squared_error
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
colors = ["windows blue", "amber", "faded green", "dusty purple"]
sns.set(rc={"figure.figsize": (20,10), "axes.titlesize" : 18, "axes.labelsize" : 12,
"xtick.labelsize" : 14, "ytick.labelsize" : 14 })
<subsequent code not shown for brevity>
The dataset is available at the following link as a csv file in Microsoft Excel:
We focus on one of the middle sections with the first ARIMA model with SARIMAX (do look up Wikipedia and Google Search to learn about ARIMA and SARIMAX) which does the actual prediction at the time that the bitcoin bubble burst (only a subset of the code is shown). Visit the Kaggle kernel page on the link below this extract to get the entire code:
<data analysis and model analysis code section not shown here for brevity>
This code and the code earlier in the kernel (not shown for the sake of brevity) that built the model for accuracy gave the following predictions as output:
Bitcoin price forecasting at the time of the burst of the Bitcoin bubble
What do we learn? Surprisingly, the model captures the Bitcoin bubble burst with a remarkably accurate prediction (error levels ~ 10%)!
Conclusion
So, does AI and data science have anything to do with blockchain technology and cryptocurrency? The answer is a resounding, yes. Expect data science, statistical analysis, neural networks, and probability model distributions to play a heavy part when you want to forecast cryptocurrency prices.
For all the data science students out there, I am going to include one more screen from the same kernel on Kaggle (link):
The reason I want to show you this screen is that the terms and statistical lingo like kurtosis and heteroskedasticity are statistics concepts that you need to master in order to conduct forecasts like this, the main reason being to analyze the accuracy of the model you have constructed. The output window is given below:
So yes, blockchain technology and cryptocurrencies have a lot of overlap with applications. But also remember, data science can be applied to any field where finance is a factor.