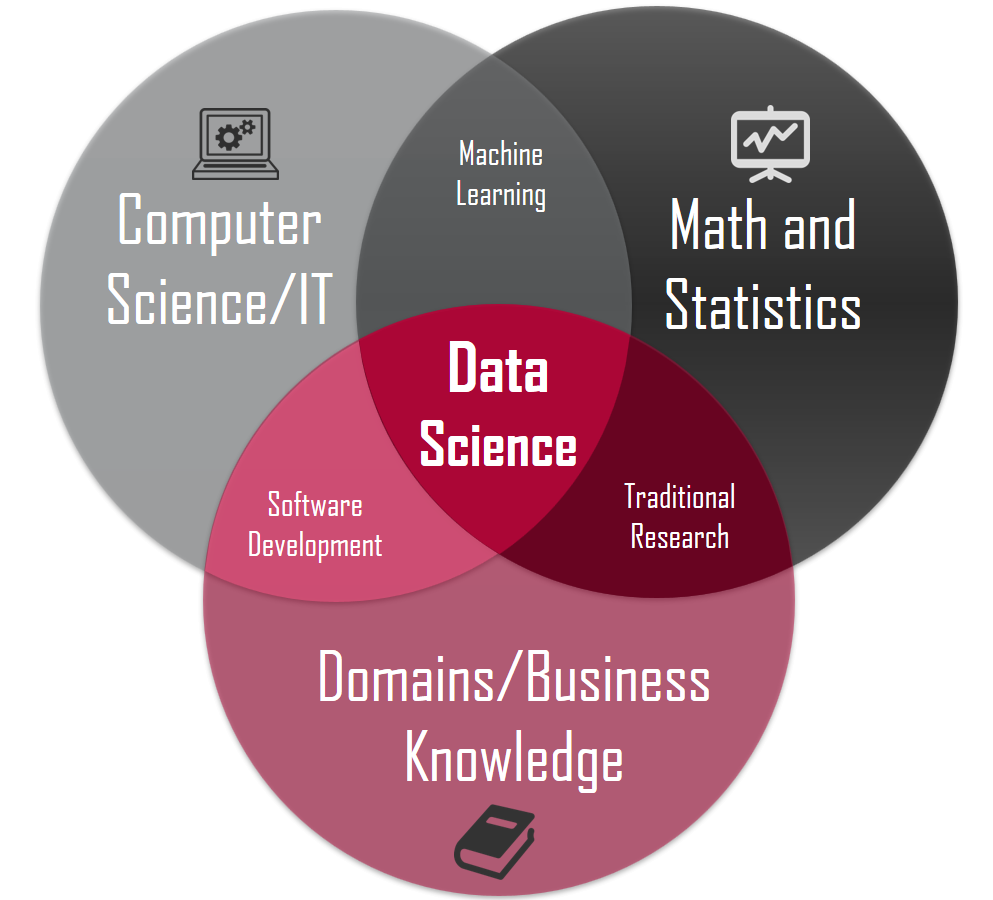
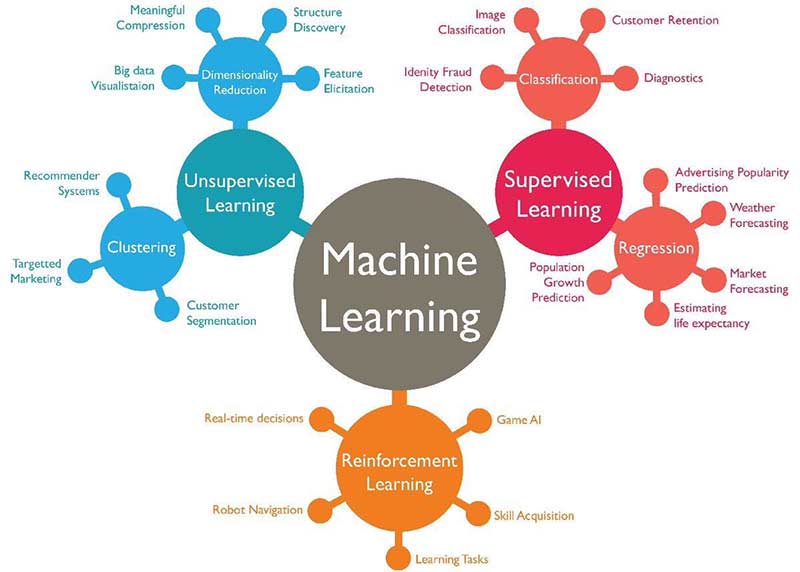
As we move towards a data-driven world, we tend to realize how the power of analytics could unearth the most minute details of our lives. From drawing insights from data to making predictions of some unknown scenarios, both small and large industries are thriving under the power of big data analytics.
A-Z Glossary
There are various terms, keywords, concepts that are associated with Analytics. This field of study is broad, and hence, it could be overwhelming to know each one of it. This blog covers some of the critical concepts in analytics from A-Z, and explain the intuition behind that.
A: Artificial Intelligence – AI is the field of study which deals with the creation of intelligent machines that could behave like humans. Some of the widespread use cases where Artificial Intelligence has found its way are ChatBots, Speech Recognition, and so on.
There are two main types of Artificial Intelligence –Narrow AI, and Strong AI. A poker game is an example for the weak or the narrow AI where you feed all the instructions into the machines. It is trained to understand every scenario and incapable of performing something on their own.
On the other hand, a Strong AI thinks and acts like a human being. It is still far-fetched, and a lot of work is being done to achieve ground-breaking results.
B: Big Data – The term Big Data is quite popular and is being used frequently in the analytical ecosystem. The concept of big data came into being with the advent of the enormous amount of unstructured data. The data is getting generated from a multitude of sources which bears the properties of volume, veracity, value, and velocity.
Traditional file storage systems are incapable of handling such volumes of data, and hence companies are looking into distributed computing to mine such data. Industries which makes full use of the big data are way ahead off their peers in the market.
C: Customer Analytics – Based on the customer’s behavior, relevant offers delivered to them. This process is known as Customer Analytics. Understanding the customer’s lifestyle and buying habits would ensure better prediction of their purchase behaviors, which would eventually lead to more sales for the company.
The accurate analysis of customer behavior would increase customer loyalty. It could reduce campaign costs as well. The ROI would increase when the right message delivered to each segmented group.
D: Data Science – Data Science is a holistic term which involves a lot of processes which includes data extraction, data pre-processing, building predictive models, data visualization, and so on. Generally, in big companies, the role of a Data Scientist is well defined unlike in startups where you would need to look after all the aspects of an end-to-end project.
source: Towards Data Science
To be a Data Scientist, you need to be fluent in Probability, and Statistics as well, which makes it a lucrative career. There are not many qualified Data Scientists out there, and hence mastering the relevant skills could put you in a pole position in the job market.
E: Excel –An old, and yet the most used after visualization tool in the market is Microsoft Excel. Excel is used in a variety of ways while presenting the data to the stakeholders. The graphs and charts lay down the proper demonstration of the work done, which makes it easier for the business to take relevant decisions.
Moreover, Excel has a rich set of utilities which could useful in analyzing structured data. Most companies still need personnel with the knowledge of MS Excel, and hence, you must master it.
F: Financial Analytics – Financial Data such as accounts, transactions, etc., are private and confidential to an individual. Banks refrain from sharing such sensitive data as it could breach privacy and lead to financial damage of a customer.
However, such data if used ethically could save losses for a bank by identifying potential fraudulent behaviors. It would also be used to predict the loan defaulting probability. Credit scoring is another such use case of financial analytics.
G: Google Analytics – For analyzing website traffic, Google provides a free tool known as Google Analytics. It is useful to track any marketing campaign which would give an idea about the behavior of customers.
There are four levels via which the Google Analytics collects the data – User level which understands each user’s actions, Session level which monitors the individual visit, Page view level which gives information about each page views, and Event level which is about the number of button clicks, views of videos, and so on.
H: Hadoop –The framework most commonly used to store, and manipulate big data is known as Hadoop. As a result of high computing power, the data is processed fast in Hadoop.
Moreover, parallel computing in multiple clusters protects the loss of data and provides more flexibility. It is also cheaper, and could easily be scaled to handle more data.
I: Impala – Impala is a component of Hadoop which provides a SQL query engine for data processing. Written in Java, and C++, Impala is better than other SQL engines. Use SQL; the communication enabled between users and the HDFS, which is faster than Hive. Additionally, different formats of a file could also be read using Impala.
J: Journey Analytics – A sequential journey related to customer experience, which meets a specific business referred to as Journey Analytics. Over time, a customer’s interaction with the company compiled from its journey analytics.
K: K-means clustering – Clustering is a technique where you group a dataset into some small groups based on the similar properties shared among the members of the same group.
K-Means clustering is one such clustering algorithm where an unsupervised dataset split into k number of groups or clusters. K-Means clustering could be used to group a set of customers or products resembling similar properties.
L: Latent Dirichlet Allocation – LDA or Latent Dirichlet Allocation is a technique used over textual data in use cases such as topic modeling. Here, a set of topics imagined by the LDA representing a set of words. Then, it maps all the documents to the topics ensuring that those imaginary topics capture words in each text.
M: Machine Learning – Machine Learning is a field of Data Science which deals with building predictive models to make better business decisions.
A machine or a computer is first trained with some set of historical data so that it finds patterns in it, and then predict the outcome on an unknown test set. There are several algorithms used in Machine Learning, one such being K-means clustering.
source: TechLeer
N: Neural Networks – Deep Learning is the branch of Machine Learning, which thrives on large complex volumes of data and is used to cases where traditional algorithms are incapable of producing excellent results
Under the hood, the architecture behind Deep Learning is Neural Networks, which is quite similar to the neurons in the human brain.
O: Operational Analytics –The analytics behind the business, which focuses on improving the present state of operations, referred to as Operational Analytics.
Various data aggregation and data mining tools used which provides a piece of transparent information about the business. People who are expert in this field would use operational software provided knowledge to perform targeted analysis.
P: Pig –Apache Pig is a component of Hadoop which is used to analyze large datasets by parallelized computation. The language used is called Pig Latin.
Several tasks, such as Data Management could be served using Pig Latin. Data checking and filtering could be done efficiently and quickly with Pig.
Q: Q-Learning –It is a model-free reinforcement learning algorithm which learns a policy by informing an agent the actions to be taken under specific certain circumstances. The problems handled with stochastic transitions and rewards, and it doesn’t require adaptations.
R: Recurrent Neural Networks –RNN is a neural network where the input to the current step is the output from the previous step.
It used in cases such as text summarization was to predict the next word, the last words are needed to remember. The issue of the hidden layer was solved with the advent of RNN as it recalls sequence information.
S: SQL –One of the essential skill in analytics is Structured Query Language or SQL. It is used in RDBMS to fetch data from tables using queries.
Most companies use SQL for their initial data validation and analysis. Some of the standard SQL operations used are joins, sub-queries, window functions, etc.
T: Traffic Analytics –The study of analyzing a website’s source of traffic by looking into its clickstream data is known as traffic analytics. It could help in understanding whether direct, social, paid traffic, etc., are bringing in more users.
U: Unsupervised Machine Learning –The type of machine learning which deals with unlabeled data is known as unsupervised machine learning.
Here, no labels provided for a corresponding set of features, and information is grouped based on the similarity in the properties shared by the members of each group. Some of the unsupervised algorithms are PCA, K-Means, and so on.
V: Visualization –The analysis of data is useless if not presented in the forms of graphs and charts to the business. Hence, Data visualization is an integral part of any analytics project and also one of the key steps in data pre-processing and feature engineering.
W: Word2vec –It is a neural network used for text processing which takes in a text as input and output are a set of feature vectors of the words.
Some of the applications of word2vec are in genes, social media graphs, likes, etc. In a vector space, similar words are grouped using word2vec without the need for human intervention.
X: XGBoost –Boosting is a technique in machine learning by which a strong learner strengthens a weak learner in subsequent steps.
XGBoost is one such boosting algorithm which is robust to outliers, or NULL values. It is the go-to algorithm in Machine Learning competitions for its speed and accuracy.
Y: Yarn –YARN is a component of Hadoop which lies between HDFS, and the processing engines. In individual cluster nodes, the processing operations monitored by YARN.
The dynamic allocation of resources is also handled by it, which improves application performance and resource utilization.
Z: Z-test –A type of hypothesis testing used to determine whether to reject or accept the NULL hypothesis. By how many standard deviations, a data point is further away from the mean could be calculated using Z-test.
Conclusion
In this blog post, we covered some of the terms related to the analytics starting with each letter in the English.
If you are willing to learn more about Analytics, follow the blogs and courses of Dimensionless.
Follow this link, if you are looking to learn more about data science online!
Additionally, if you are having an interest in learning Data Science, Learnonline Data Science Course to boost your career in Data Science.
Furthermore, if you want to read more about data science, you can read our blogs here
Principal Component Analysis or PCA is one of the simplest and fundamental techniques used in machine learning. It is perhaps one of the oldest techniques available for dimensionality reduction, and thus, its understanding is of paramount importance for any aspiring Data Scientist/Analyst. An in-depth understanding of PCA in R will not only help in the implementation of effective dimensionality reduction but also help to build the foundation for development and understanding of other advanced and modern techniques.
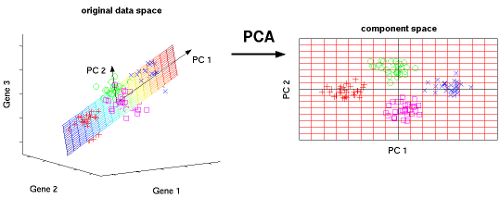
Examples of Dimension Reduction from 2-D space to 1-D space Courtesy: Bits of DNA
PCA aims to achieve two
primary goals:
1. Dimensionality
Reduction
Real-life data has several features generated from numerous resources. However, our machine learning algorithms are not adept enough to handle high dimensions efficiently. Feeding several features, all at once, almost always leads to poor results since the models cannot grasp and learn from such volume altogether. This is called the “Curse of Dimensionality” which leads to unsatisfactory results from the models implemented. Principal Component Analysis in R helps resolve this problem by projecting n dimensions to n-x dimensions (where x is a positive number), preserving as much variance as possible. In other words, PCA in R reduces the number of features by transforming the features into a lesser number of projections of themselves.
2. Visualization
Our visualization systems are limited to 2-dimensional space which prevents us from forming a visual idea of the high dimensional features in the dataset. PCA in R resolves this problem by projecting n dimensions to a 2-D environment, enabling sound visualization. These visualizations sometimes reveal a great deal about the data. For instance, the new feature projections may form clusters in the 2-D space which was previously not perceivable in higher dimensions.
Visualization with PCA (n-D to 2-D) Courtesy: nlpca.org
Intuition
Principal Component Analysis in R works with the simple idea of projection of a higher space to a lower space or dimension
The two alternate objectives of Principal Component Analysis are:
1. Variance Maximization
Formulation
2. Distance Minimization
Formulation
Let us demonstrate the above with the help of simple examples. If you have 2 features, and you wish to reduce the features to a 1-D feature set using PCA in R, you must lookout for the direction with maximal spread/variance. This becomes the new direction on which every data point is projected. The direction perpendicular to this direction has the least variance, and is thus, discarded.
Alternately, if one focuses on the perpendicular distance between a data point and the direction of maximum variance, our objective shifts to the minimization of that distance. This is because, lesser the distance, higher is the authenticity of the projection.
On completion of these projections, you would have successfully transformed your 2-D data to a 1-D dataset.
Mathematical Intuition
Principal Component Analysis in R locates the distance of maximal spread (or direction of minimal distance from data points) with the use of Eigen Vectors and Eigen Values. Every Eigen Vector (Vi) corresponds to an Eigen Value (Ei).
If X is a feature matrix (matrix with the feature values),
covariance matrix S = XT. X
If EiVi = SVi ,
Then Ei is an Eigen Value, and Vi becomes the corresponding Vector.
If there are d dimensions, there will be d Eigenvalues with d corresponding Eigen Vectors, such that:
E1>=E2>=E3>=E4>=…>=Ed
Each corresponding to V1, V2, V3, …., Vd
Here the vector corresponding to the largest Eigenvalue is the direction of Maximal spread since rotation occurs such that V1 is aligned with maximal variance in the feature space. Vd here has the least variance in its direction.
A very interesting property of Eigenvectors is the fact that if any two vectors are picked randomly from the set of d vectors, they will turn out to be perpendicular to each other. This happens because they align themselves such that they catch the most opposing directions in terms of variance.
When deciding between two Eigen Vector directions, Eigenvalues come into play. If V1 and V2 are two Eigen Vectors (perpendicular to each other), the values associated with these vectors, E1 and E2, help us identify the “percentage of variance explained” in either direction.
Percentage of variance explained Ei/(Sum(d Eigen Values)) where i is the direction we wish to calculate the percentage of variance explained for.
Implementation
Principal Component Analysis in R can either be applied with manual code using the above mathematical intuition, or it can be done using R’s inbuilt functions.
Even if the mathematical concept failed to leave a lasting impression on your mind, be assured that it is not of great consequence. On the other hand, understanding the basic high-level intuition counts. Without using the mathematical formulas, PCA in R can be easily applied using R’s prcomp() and princomp() functions which can be found here.
In order to demonstrate Principal Component Analysis, we will be using R, one of the most widely used languages in Data Science and Machine Learning. R was initially developed as a tool to aid researchers and scientists dealing with statistical problems in the academic field. With time, as more individuals from the academic spheres started seeping into the corporate and industrial sectors, they brought along R and its phenomenal uses along with them. As R got integrated into the IT sector, its popularity increased manifold and several revisions were made with the release of every new version. Today R has several packages and integrated libraries which enables developers and data scientists to instantly access statistical solutions without having to go into the complicated details of the operations. Principal Component Analysis is one such statistical approach which has been taken care of very well by R and its libraries.
For demonstrating PCA in R, we will be using the Breast Cancer Wisconsin Dataset which can be downloaded from here: Data Link
These code statements help to read data into the variables wdbc.
wdbc.pr <- prcomp(wdbc[c(3:32)], center = TRUE, scale = TRUE) summary(wdbc.pr)
The prcomp() function helps to apply PCA in R on the data variable wdbc. This function of R makes the entire process of implementing PCA as simple as writing just one line of code. The internal operations and functions are taken care of and are even optimized in terms of memory and performance to carry out the operations optimally. The range 3:32 is used to tell the function to apply PCA only on the features or columns which lie in the range of 3 to 32. This excludes the sample ID and diagnosis variables since they are identification columns and are invalid as features with no direct significance with regard to the target variable.
wdbc.pr
now stores the values of the principal components.
Let us now
visualize the different attributes of the resulting Principal Components for
the 30 features:
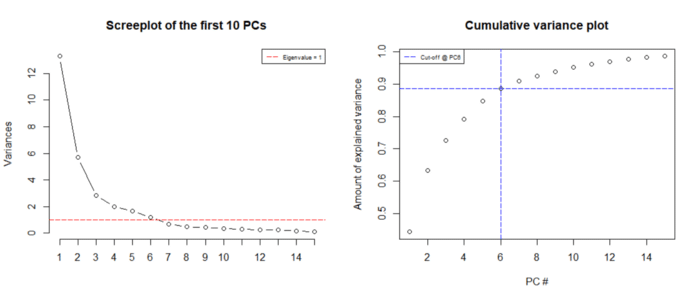
screeplot(wdbc.pr, type = "l", npcs = 15, main = "Screeplot of the first 10 PCs")
This plot
clearly demonstrates that the first 6 components account for 90% of the variance
in the dataset (with Eigen Value > 1). This means that one can easily
exclude 24 features out of 30 features in order to preserve 90% of the data.
Limitations of PCA
Even though Principal Component Analysis in R displays a highly intuitive technique, it hosts certain shocking limitations.
1. Loss of Variance: If the percentage of variance against the chosen axis is around 50-60%, it is evident that 40-50% of the information which contributes to the variance of the dataset is lost during dimensionality reduction. This happens often when the data is spherical or bulging in nature.
2. Loss of Clusters: If there are several clusters present in the original dataset, but most of them lie in the direction perpendicular to the chosen direction. Thus, all the points from different clusters will be projected to the same region on the line of chosen direction, leading to one cluster of data points which are in fact quite different in nature.
3. Loss of Data Patterns: If the dataset forms a nice wavy pattern in direction of maximal spread, PCA takes to project all the points on the line aligned against the direction. Thus, data points which formed a wave function are concentrated on one-dimensional space.
These demonstrate how PCA in R, even though very effective for certain datasets, is a weak instrument for dimensionality reduction or visualization. To resolve these limitations to a certain extent, t-SNE, which is another dimensionality reduction algorithm, is used. Stay tuned to our blogs for a similar and well-guided walkthrough in t-SNE.
The flux of data is increasing exponentially in this age of Digital awakening. Data has become so important to major industries and sectors around the globe that it can literally be referred to as digital gold! From simple company centric applications to major platforms interweaving people from all around the world, data has started to shape major decisions for not only autonomous machines, but also for the human race as a whole. This imagery is as intriguing as it is terrifying, but only if we make it so.
In order to handle this rapidly incoming data with relative ease, a competent system is required to act instantly and deliver results on the fly. Otherwise, such large-scale investments on data gathering and data generation will go to waste since the data will be left in its dormant state without any active or competent agent acting on it. This is where the concept of real time data streaming and processing comes up. So, what is real time data streaming?
As is already known, data is being generated from various sources at a lightening pace. If we stop to ingest enough data, process it in batches and then provide the results after enough time has passed, the results will tend to lose its relevance and will reflect outdated patterns and trends. This happens majorly because of the high rate of variance in incoming data and also because of time constraints.
For instance, suppose that you have a machine which tells you which horse to bet upon in a horse race. You have the option of changing your choice during the race until the last lap commences. In such a case, if your machine gives you predictions based on the first lap where horse A was showing promise, and predicts that horse A will win, where in fact, during the third lap, horse B shows further promise, you will lose your bet just because of a machine which lags behind by two laps. This problem can be avoided by processing incoming data instantly, or in other words, real time data streaming. A stack of old data or historical data is studied and incoming records are processed based on the studied patterns such that the results are delivered within milliseconds. For our example, the horse race prediction machine would have already studied data about the different horses in the race previously and then based on the incoming data (the horse number, position of the horse, time since beginning of race, number of contestants, etc.), will be able to instantly allocate a rank for the different participants with the help of real time data streaming.
How to Go About Real-Time Data Streaming?
In real time mission-critical applications, Apache Kafka has turned out to be one of the most widely used frameworks for implementation. Apache Kafka is integrated with efficient machine learning frameworks in order to enable model training and speedy deliverance by supporting real time data streaming.
What is Apache Kafka?
As per Kafka’s website, it defines itself and its tasks as follows:
“Kafka® is used for building real-time data pipelines and streaming apps. It is horizontally scalable, fault-tolerant, wicked fast, and runs in production in thousands of companies.”
“The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds. Its storage layer is essentially a “massively scalable pub/sub message queue designed as a distributed transaction log”, making it highly valuable for enterprise infrastructures to process streaming data.” – Wikipedia
These definitions might seem like a mouthful at first, but as we go through with this subject step by step in this discussion, one will easily get the hang of it in no time!
Why use Tensorflow as the machine learning platform which is to be integrated with Apache Kafka?
Tensorflow is one of the most popular and efficient open source machine learning platforms available. It has a beautiful and well-suited architecture which enables data flow with extreme grace and optimization. It enables users and developers to establish large-scale projects with minimal hassles and maximal resource optimization. It is thus, a very competent platform to integrate with Apache Kafka for the purpose of serving real-time data streaming.
Tensorflow’s tf.keras and tf.data are responsible for streaming data in and out. Previously however, these modules were limited in their usage and could only support a few data formats. Support for Kafka streaming was not included during the earlier versions of Tensorflow. It was also difficult to use Tensorflow supported modules like tf. Examples and TFRecord in Big data and the general community of Data Science as a whole and were, therefore, rarely spotted.
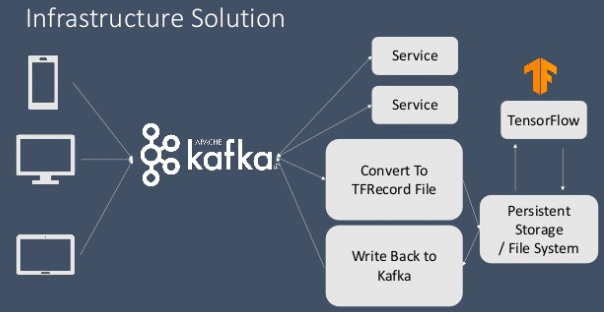
It was thus, a difficult task to integrate the Apache Kafka and Tensorflow frameworks. A lot of intermediary bridges had to be constructed in order to establish reliable handshakes between these two frameworks and ensure smooth integration. This was a burdensome process since it included designing of an entire infrastructure which turned out to be a fault prone mechanism most of the time. These were the steps which were required to be followed in order to establish a working data streaming flow:
Read data from the Kafka stream -> Convert to TFRecord format -> call Tensorflow’s function to read the TFRecord object from file system -> execute model and deliver result -> save the result in the file system again -> write results/ inference back to Kafka
Source: Kafka Summit NYC 2019, Yong Tang
However, with the release of Tensorflow 2.0, the tables turned and the support for Apache Kafka data streaming module was issued along with support for a varied set of other data formats in the interest of the data science and statistics community (released in the IO package from Tensorflow: here).
Source: Kafka Summit NYC 2019, Yong Tang
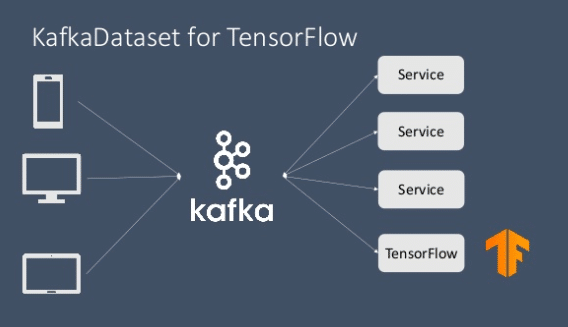
With this development, it is now possible to enable real time streaming with Kafka and Tensorflow with relative ease and minimized error. This process is implemented with the use of KafkaDataset module (written in C++) which is a part of the new release of the Tensorflow IO package. KafkaDataset module has been integrated as a subclass of tf.data.Dataset module. This module works just like any other data streaming module where users can simply read data from a kafka stream and use it in a Tensorflow graph or feed it to tf.keras and other Tensorflow specific modules for model training and evaluation purpose. The option of writing back through output stream is also possible of course.
Here is how to implement data streaming, processing, model training and inference gathering in just a few lines of code with Kafka support on Tensorflow:
Line 2 simply streams in data with the help of the KafkaDataset module and data processing and modeling are immediately commenced as can be seen in lines 3 and 4. Thereafter, we move on to the keras callback stage. Keras callbacks are very informative since they provide an overview of the internal stages and statistical details of the model during the training or prediction process. The callback function is written in the 7th line. The KafkaOutputSequence is responsible for writing the results to the output stream (with so much relative ease!). In line 13 the predict function is called to get the model details and inference on the test dataset.
Source: Kafka Summit NYC 2019, Yong Tang
Real time data streaming with Kafka and Tensorflow has not only helped in the elimination of the complicated infrastructure which previously bridged the wide gap between the two popular platforms, but has also made the process less error prone and more approachable for real time mission critical systems with respect to machine learning and data science. The above picture shows how easy it is now to implement Kafka along with Tensorflow with just one call for data streaming. Further development in this area looks highly promising and is sure to contribute manifold in the ease of scalability and smooth integration when it comes to Big Data, live or real time data streaming, machine learning and deep learning techniques to develop smart and autonomous systems across the globe!
Get a grip on the machine learning, data science, big data and several other intriguing topics by following our blogs or even our detailed courses provided in the links below:
Reports suggest that around 2.5 quintillion bytes of data are generated every single day. As the online usage growth increases at a tremendous rate, there is a need for immediate Data Science professionals who can clean the data, obtain insights from it, visualize it, train model and eventually come up with solutions using Big data for the betterment of the world.
By 2020, experts predict that there will be more than 2.7 million data science and analytics jobs openings. Having a glimpse of the entire Data Science pipeline, it is definitely tiresome for a single human to perform and at the same time excel at all the levels. Hence, Data Science has a plethora of career options that require a spectrum set of skill sets.
Let us explore the top 5 data science career options in 2019 (In no particular order).
1. Data Scientist
Data Scientist is one of the ‘high demand’ job roles. The day to day responsibilities involves the examination of big data. As a result of the analysis of the big data, they also actively perform data cleaning and organize the big data. They are well aware of the machine learning algorithms and understand when to use the appropriate algorithm. During the due course of data analysis and the outcome of machine learning models, patterns are identified in order to solve the business statement.
The reason why this role is so crucial in any organisation is that the company tends to take business decisions with the help of the insights discovered by the Data Scientist to have an edge over the company’s competitors. It is to be noted that the Data Scientist role is inclined more towards the technical domain. As the role demands a wide range of skill set, Data Scientists are one among the highest paid jobs.
Core Skills of a Data Scientist
Communication
Business Awareness
Database and querying
Data warehousing solutions
Data visualization
Machine learning algorithms
2. Business Intelligence Developer
BI Developer is a job role inclined more towards the Non-Technical domain but has a fair share of Technical responsibilities as well (if required) as a part of their day to day responsibilities. BI developers are responsible for creating and implementing business policies as a result of the insights obtained from the Technical team.
Apart from being a policymaker involving the usage of dedicated (or custom) Business Intelligence analytics tools, they will also have a fair share of coding in order to explore the dataset, present the insights of the dataset in a non-verbal manner. They help in bridging the gap between the technical team that works with the deepest technical understanding and the clients that want the results in the most non-technical manner. They are expected to generate reports from the insights and make it ‘less technical’ for others in the organisation. It is noted that the BI Developers have a deep understanding of Business when compared to Data Scientist.
Core Skills of a Business Analytics Developer
Business model analysis
Data warehousing
Design of business workflow
Business Intelligence software integration
3. Machine Learning Engineer
Once the data is clean and ready for analysis, the machine learning engineers work on these big data to train a predictive model that predicts the target variable. These models are used to analyze the trends of the data in the future so that the organisation can take the right business decisions. As the dataset involved in a real-life scenario would involve a lot of dimensions, it is difficult for a human eye to interpret insights from it. This is one of the reasons for training machine learning algorithms as it easily deals with such complex dataset. These engineers carry out a number of tests and analyze the outcomes of the model.
The reason for conducting constant tests on the model using various samples is to test the accuracy of the developed model. Apart from the training models, they also perform exploratory data analysis sometimes in order to understand the dataset completely which will, in turn, help them in training better predictive models.
Core Skills of Machine Learning Engineers
Machine Learning Algorithms
Data Modelling and Evaluation
Software Engineering
4. Data Engineer
The pipeline of any data-oriented company begins with the collection of big data from numerous sources. That’s where the data engineers operate in any given project. These engineers integrate data from various sources and optimize them according to the problem statement. The work usually involves writing queries on big data for easy and smooth accessibility. Their day to day responsibility is to provide a streamlined flow of big data from various distributed systems. Data engineering differs from the other data science careers as in, it is concentrated on the system and hardware that aids the company’s data analysis, rather than the analysis of data itself. They provide the organisation with efficient warehousing methods as well.
Core Skills of Data Engineer
Database Knowledge
Data Warehousing
Machine Learning algorithm
5. Business Analyst
Business Analyst is one of the most essential roles in the Data Science field. These analysts are responsible for understanding the data and it’s related trend post the decision making about a particular product. They store a good amount of data about various domains of the organisation. These data are really important because if any product of the organisation fails, these analysts work on these big data to understand the reason behind the failure of the project. This type of analysis is vital for all the organisations as it makes them understand the loopholes in the company. The analysts not only backtrack the loophole and in turn provide solutions for the same making sure the organisation takes the right decision in the future. At times, the business analyst act as a bridge between the technical team and the rest of the working community.
Core skills of Business Analyst
Business awareness
Communication
Process Modelling
Conclusion
The data science career options mentioned above are in no particular order. In my opinion, every career option in Data Science field works complimentary with one another. In any data-driven organization, regardless of the salary, every career role is important at the respective stages in a project.