Setting up a new business? Or trying to grow an existing one? No matter which one it is, web scraping is the best way to collect data for growing your business today. It will help you get valuable insights, and information about your latest competition, no matter what you deal in – products or services. Although web scraping has been going on for quite some time, it has never been as heavily used, or as reliable as it is today.
In this blog, we will learn about web scraping. Furthermore, we will also learn about making our own web scraper and collect data from the websites. We will implement the scraper in python using the Beautiful Soup library. So before we jump into web scraping, let us first understand what web scraping actually is!
What is Web Scraping?
Web scraping is the process of extracting data from websites. All the job is carried out by a piece of code which is called a “scraper”. First, it sends a “GET” query to a specific website. Then, it parses an HTML document based on the received result. After it’s done, the scraper searches for the data you need within the document, and, finally, convert it into the specified format.
Web-scraping is an important technique, frequently employed in a lot of different contexts, especially data science and data mining. Python is largely considered the go-to language for web-scraping, the reason being the batteries-included nature of Python. With Python, you can create a simple scraping script in about 15 minutes and in under 100 lines of code. So regardless of usage, web-scraping is a skill that every Python programmer must have under his belt.
Uses of Web Scraping:
These include article extraction for websites that curate content, business listings extraction for companies that build databases of leads, and many different types of data extraction, sometimes called data mining. For example, one popular and sometimes controversial use of a web scraper is for pulling prices off of airlines to publish on airfare comparison sites.
Scraping Goal
In this blog, we will try to learn about web scraping by implementing it ourselves. Our goal is simple here. We have a blog section on our website. What we want is fairly simple. We need the data containing blog title, date, and the author name.
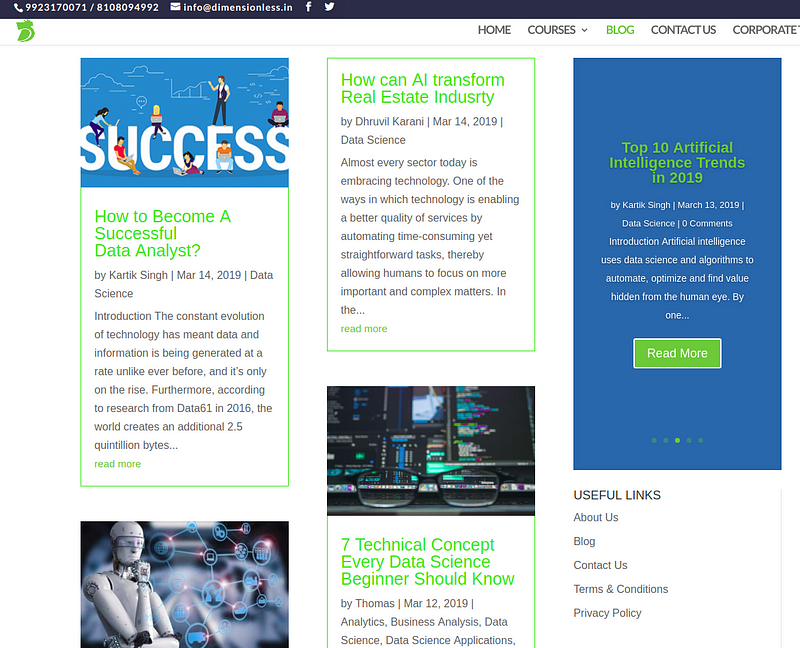
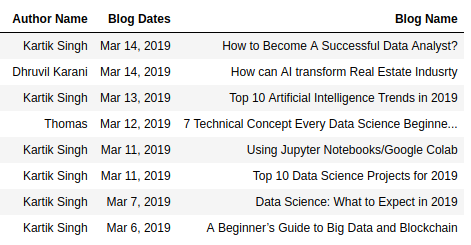
The target page looks like one below. You can visit the page through the following link.
Our target page for scraping
The Web Scraping Pipeline:
Before we directly jump to web scraping, let us have a look at the basic pipeline for this. We can understand web-scraping as a pipeline containing 3 components:
Downloading: Downloading the HTML web-page
Parsing: Parsing the HTML and retrieving data we’re interested in
Storing: Storing the retrieved data in our local machine in a specific format
In the next section, we will implement a web scraper to get all the blog names for us using python. We will use Beautiful Soup library in python for scraping web pages. One by one, we will go through the stages in the scraping pipeline. Full code will be present in the end section.
Implementing a Web Scraper using Beautiful Soup:
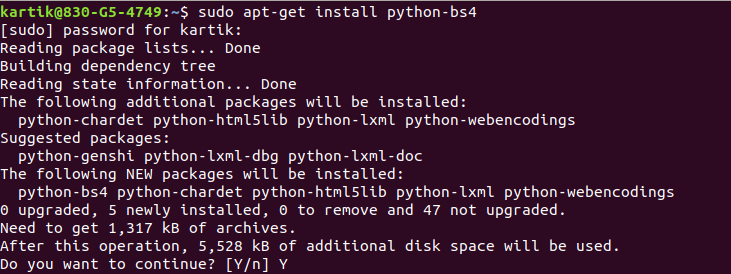
First of all, we need to install Beautiful Soup library in our system. To install it, you can use the following command
## Using apt-get
sudo apt-get install python-bs4
## Using pip
pip install bs4
Once you run the above command, it will start installing the packages for you.
In order to verify the installation, you can try importing the library following way
from bs4 import BeautifulSoup
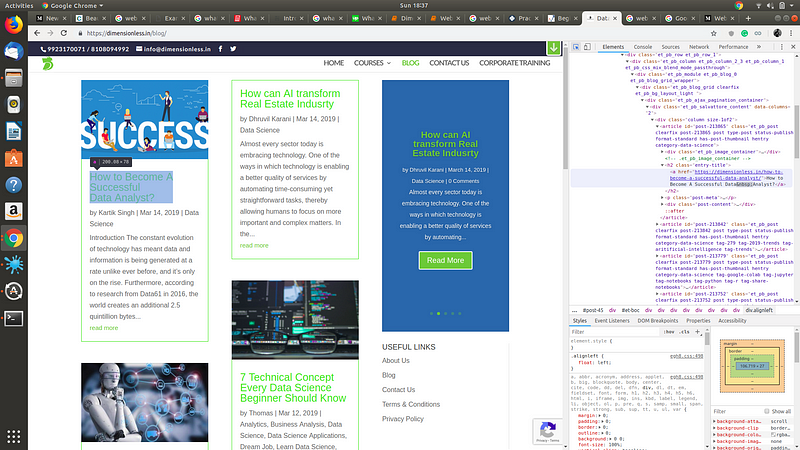
Let us start writing our scraper now. You need to analyze the HTML structure of the target web page. To do so, you can left click and select inspect element option. This will enable you to see the HTML code behind the web page.
With the pen icon button, you can hover over the website to find their code in the source code. For example, to find the HTML code for the author name, hover the mouse over the author name. On the right side, it will highlight for you the location of that code.
Let us dig deeper into the HTML code here.
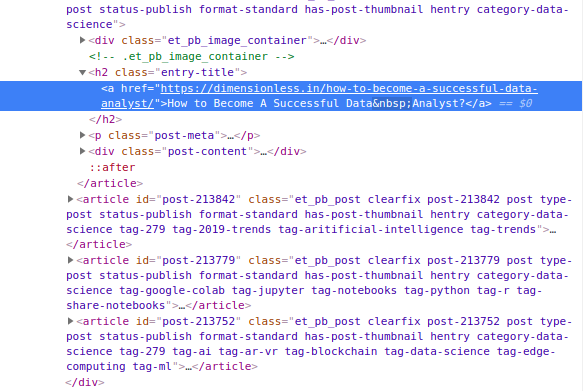
After hovering over the author name, we can clearly see the HTML code here for the same. All the author names have an H2 tag with class name “entry-title”. We can use this combination of tag and class name to get all the instances where the author name is there. A similar process will happen for the date and the author name.
We can start building our scraper now. First, we need to import all the basic libraries. We can do this by the following code
## For downloading HTML structure
import requests
## For Scraping through HTML
from bs4 import BeautifulSoup
## For visualising data in a table
import pandas as pd
Downloading the Data:
Once we have all the libraries, we start by downloading the HTML code of the target website. Now, we need to mention our target URL. After that, we need to download the HTML content from the target web page. In the end, we will have an object(Beautiful soup compatible) holding the data.
## Mentioning the target url
targetUrl = 'https://dimensionless.in/blog'
## Downloading the HTML content from the target page
r= requests.get(targetUrl)
data=r.text
##Converting the data into a Beautiful Soup compatible object
soup=BeautifulSoup(data)
Parsing the Data:
Once we have the entire HTML content available, we need to search for our specific information in this data. As we saw earlier, we can use the tag type and other identifiers like id or class to extract any specific information.
Upon exploring the code, I was able to find the following identifiers for our target information. You can also try to find out these using inspect elements. Try to analyze that this selection makes sense or doesn’t make sense.
Blog Name — — Tag-”H2″ — — class-”entry-title”
Author Name — — Tag-”span” — — class-”author vcard”
Blog Date — — Tag-”span” — — class-”published”
## Lists for holding the values
blog_names=[]
author_names=[]
blog_dates=[]
## Iterating through all the articles and extracting blog title, author name and blog date
for listing in soup.find_all('article'):
for blog_name in listing.find('h2', attrs={'class':"entry-title"}):
blog_names.append(blog_name.text)
for author_name in listing.find('span', attrs={'class':"author vcard"}):
author_names.append(author_name.text)
for blog_date in listing.find('span', attrs={'class':"published"}):
blog_dates.append(blog_date)
Visualising and Storing Results:
In the previous step, we have collected the data from the website using the code. Now, it is time to see the data. This task is fairly simple. You can use the pandas library available in python to store all the results in a table (data frame). The following code will perform this task for you!
## For downloading HTML structure
import requests
## For Scraping through HTML
from bs4 import BeautifulSoup
## For visualising data in a table
import pandas as pd
## Mentioning the target url
targetUrl = "https://dimensionless.in/blog"
## Downloading the HTML content from the target page
r= requests.get(targetUrl)
data=r.text
##Converting the data into a Beautiful Soup compatible object
soup=BeautifulSoup(data)
## Lists for holding the values
blog_names=[]
author_names=[]
blog_dates=[]
## Iterating through all the articles and extracting blog title, author name and blog date
for listing in soup.find_all('article'):
for blog_name in listing.find('h2', attrs={'class':"entry-title"}):
blog_names.append(blog_name.text)
for author_name in listing.find('span', attrs={'class':"author vcard"}):
author_names.append(author_name.text)
for blog_date in listing.find('span', attrs={'class':"published"}):
blog_dates.append(blog_date)
blogData=pd.DataFrame({"Blog Name":blog_names, "Author Name":author_names, "Blog Dates":blog_dates})
The Advantages of Web Scraping:
The major advantages of web scraping services are:
Inexpensive — Web scraping services provide an essential service at a low cost. It is paramount that data is collected back from websites and analyzed so that the internet functions regularly. Web scraping services do the job in an efficient and budget-friendly manner.
Easy to Implement — Once a web scraping services deploy the proper mechanism to extract data, you are assured that you are not only getting data from a single page but from the entire domain. This means that with just a onetime investment, a lot of data can be collected.
Low Maintenance and Speed– One aspect that is often overlooked when installing new services is the maintenance cost. Long term maintenance costs can cause the project budget to spiral out of control. Thankfully, web scraping technologies need very little to no maintenance over a long period. Another characteristic that must also be mentioned is the speed with which web scraping services do their job. A job that could take a person week is finished in a matter of hours.
Accuracy — The web scraping services are not only fast, but they are also accurate too. Simple errors in data extraction can cause major mistakes later on. Accurate extraction of any type of data is thus very important. In websites that deal in pricing data, sales prices, real estate numbers or any kind of financial data, the accuracy is extremely important.
Summary
In this blog, we learned about scraping web pages in python. We used BeautifulSoup library to perform the scraping for us. Web scraping is one of the most important methods of collecting data online. Let us touch upon a concept that often comes up and confuses most of us when we read about Web scraping: web crawling! So, what is web crawling? Web crawling entails downloading a web page’s data automatically, extracting the hyperlinks on the same and following them. This downloaded data can be organized in an index or a database, using a process called web indexing, to make it easily searchable. How are the two techniques different? In simple terms, you can use web scraping to extract book reviews from the Goodreads website to rate and evaluate books. You can use this data for an array of analytical experiments. On the other hand, one of the most popular applications of a web crawler is to download data from multiple websites and build a search engine. Googlebot is Google’s own web crawler.
Follow this link, if you are looking to learn more about data science online!
Interactive notebooks are experiencing a rise in popularity. How do we know? They’re replacing PowerPoint in presentations, shared around organizations, and they’re even taking workload away from BI suites. Today there are many notebooks to choose from Jupyter, R Markdown, Apache Zeppelin, Spark Notebook and more. There are kernels/backends to multiple languages, such as Python, Julia, Scala, SQL, and others. Notebooks are typically used by data scientists for quick exploration tasks.
In this blog, we are going to learn about Jupyter notebooks and Google colab. We will learn about writing code in the notebooks and will focus on the basic features of notebooks. Before diving directly into writing code, let us familiarise ourselves with writing the code notebook style!
The Notebook way
Traditionally, notebooks have been used to document research and make results reproducible, simply by rerunning the notebook on source data. But why would one want to choose to use a notebook instead of a favorite IDE or command line? There are many limitations in the current browser-based notebook implementations, but what they do offer is an environment for exploration, collaboration, and visualization. Notebooks are typically used by data scientists for quick exploration tasks. In that regard, they offer a number of advantages over any local scripts or tools. Notebooks also tend to be set up in a cluster environment, allowing the data scientist to take advantage of computational resources beyond what is available on her laptop, and operate on the full data set without having to download a local copy.
Jupyter Notebooks
The Jupyter Notebook is an open source web application that you can use to create and share documents that contain live code, equations, visualizations, and text. Jupyter Notebook is maintained by the people at Project Jupyter.
Jupyter Notebooks are a spin-off project from the IPython project, which used to have an IPython Notebook project itself. The name, Jupyter, comes from the core supported programming languages that it supports: Julia, Python, and R. Jupyter ships with the IPython kernel, which allows you to write your programs in Python, but there are currently over 100 other kernels that you can also use.
Why Jupyter Notebooks
Jupyter notebooks are particularly useful as scientific lab books when you are doing computational physics and/or lots of data analysis using computational tools. This is because, with Jupyter notebooks, you can:
Record the code you write in a notebook as you manipulate your data. This is useful to remember what you’ve done, repeat it if necessary, etc.
Graphs and other figures are rendered directly in the notebook so there’s no more printing to paper, cutting and pasting as you would have with paper notebooks or copying and pasting as you would have with other electronic notebooks.
You can have dynamic data visualizations, e.g. animations, which is simply not possible with a paper lab book.
One can update the notebook (or parts thereof) with new data by re-running cells. You could also copy the cell and re-run the copy only if you want to retain a record of the previous attempt.
Google Colab
Colaboratory is a free Jupyter notebook environment that requires no setup and runs entirely in the cloud. With Colaboratory you can write and execute code, save and share your analyses, and access powerful computing resources, all for free from your browser.
Why Google Colab
As the name suggests, Google Colab comes with collaboration backed in the product. In fact, it is a Jupyter notebook that leverages Google Docs collaboration features. It also runs on Google servers and you don’t need to install anything. Moreover, the notebooks are saved to your Google Drive account.
Some Extra Features
1. System Aliases
Jupyter includes shortcuts for common operations, such as ls and others.
2. Tab-Completion and Exploring Code
Colab provides tab completion to explore attributes of Python objects, as well as to quickly view documentation strings.
3. Exception Formatting
Exceptions are formatted nicely in Colab outputs
4. Rich, Interactive Outputs
Until now all of the generated outputs have been text, but they can be more interesting.
5. Integration with Drive
Colaboratory is integrated with Google Drive. It allows you to share, comment, and collaborate on the same document with multiple people:
Differences between Google Colab and Jupyter notebooks
1. Infrastructure Google Colab runs on Google Cloud Platform ( GCP ). Hence it’s robust, flexible
2. Hardware Google Colab recently added support for Tensor Processing Unit ( TPU ) apart from its existing GPU and CPU instances. So, it’s a big deal for all deep learning people.
3. Pricing Despite being so good at hardware, the services provided by Google Colab are completely free. This makes it even more awesome.
4. Integration with Google Drive Yes, this seems interesting as you can use your google drive as an interactive file system with Google Colab. This makes it easy to deal with larger files while computing your stuff.
5. Boon for Research and Startup Community Perhaps this is the only tool available in the market which provides such a good PaaS for free to users. This is overwhelmingly helpful for startups, the research community and students in deep learning space
Working with Notebooks — The Cells Based Method
Jupyter Notebook supports adding rich content to its cells. In this section, you will get an overview of just some of the things you can do with your cells using Markup and Code.
Cell Types
There are technically four cell types: Code, Markdown, Raw NBConvert, and Heading.
The Heading cell type is no longer supported and will display a dialogue that says as much. Instead, you are supposed to use Markdown for your Headings.
The Raw NBConvert cell type is only intended for special use cases when using the nbconvert command line tool. Basically, it allows you to control the formatting in a very specific way when converting from a Notebook to another format.
The primary cell types that you will use are the Code and Markdown cell types. You have already learned how code cells work, so let’s learn how to style your text with Markdown.
Styling Your Text
Jupyter Notebook supports Markdown, which is a markup language that is a superset of HTML. This tutorial will cover some of the basics of what you can do with Markdown.
Set a new cell to Markdown and then add the following text to the cell:
When you run the cell, the output should look like this:
If you would prefer to bold your text, use a double underscore or double asterisk.
Headers
Creating headers in Markdown is also quite simple. You just have to use the humble pound sign. The more pound signs you use, the smaller the header. Jupyter Notebook even kind of previews it for you:
Then when you run the cell, you will end up with a nicely formatted header:
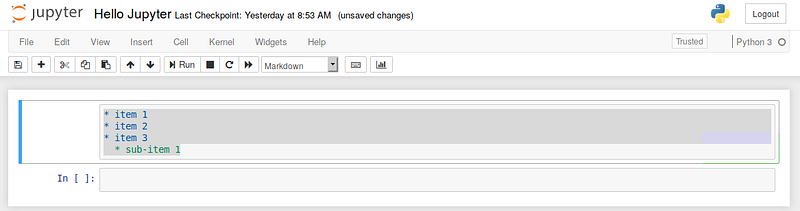
Creating Lists
You can create a list (bullet points) by using dashes, plus signs, or asterisks. Here is an example:
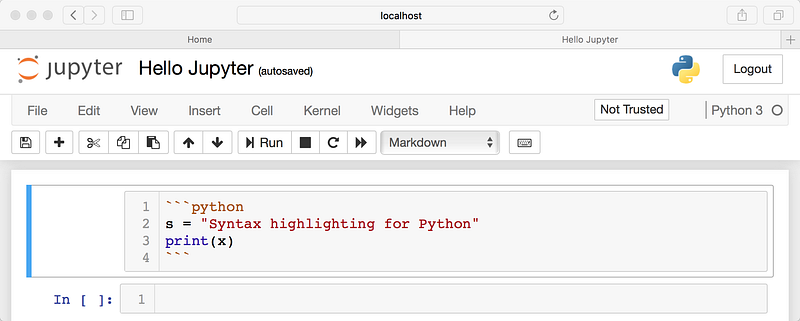
Code and Syntax Highlighting
If you want to insert a code example that you don’t want your end user to actually run, you can use Markdown to insert it. For inline code highlighting, just surround the code with backticks. If you want to insert a block of code, you can use triple backticks and also specify the programming language:
Useful Jupyter Notebook Extensions
Extensions are a very productive way of enhancing your productivity on Jupyter Notebooks. One of the best tools to install and use extensions I have found is ‘Nbextensions’. It takes two simple steps to install it on your machine (there are other methods as well but I found this the most convenient):
Step 1: Install it from pip:
pip install jupyter_contrib_nbextensions
Step 2: Install the associated JavaScript and CSS files:
jupyter contrib nbextension install --user
Once you’re done with this, you’ll see a ‘Nbextensions’ tab on the top of your Jupyter Notebook home. And voila! There are a collection of awesome extensions you can use for your projects.
Multi-user Notebooks
There is a thing called JupyterHub which is the proper way to host a multi-user notebook server which might be useful for collaboration and could potentially be used for teaching. However, I have not investigated this in detail as there is no need for it yet. If lots of people start using jupyter notebooks, then we could look into whether JupyterHub would be of benefit. Work is also ongoing to facilitate real-time live collaboration by multiple users on the same notebook — more information is available here and here.
Summary
Jupyter notebooks are useful as a scientific research record, especially when you are digging about in your data using computational tools. In this lesson, we learned about Jupyter notebooks. To add, in Jupyter notebooks, we can either be in insert mode or escape mode. While in insert mode, we can edit the cells and undo changes within that cell with cmd + z on a mac or ctl + z on windows. In escape mode, we can add cells with b, delete a cell with x, and undo deletion of a cell with z. We can also change the type of a cell to markdown with m and to Python code with y. Furthermore, we can have our code in a cell executed, we need to press shift + enter. If we do not do this, then the variables that we assigned in Python are not going to be recognized by Python later on in our Jupyter notebook.
Jupyter notebooks/Google colab are more focused on making work reproducible and easier to understand. These notebooks find the usage in cases where you need story telling with your code!
Follow this link, if you are looking to learn more about data science online!
Python and R have been around for well over 20 years. Python was developed in 1991 by Guido van Rossum, and R in 1995 by Ross Ihaka and Robert Gentleman. Both Python and R have seen steady growth year after year in the last two decades. Will that trend continue, or are we coming to an end of an era of the Python-R dominance in the data science segment? Let’s find out!
Python
Python in the last decade has grown from strength to strength. In 2013, Python overtook R as the most popular language used fordata science, according to the Stack Overflow developer survey (Link).
In the last three years, Python was the most wanted language according to this survey (25% in 2018, JavaScript was second with 19%). It is by far the easiest programming language to learn, the Julia and the Go programming languages being honorable mentions in this regard.
Python shines in its versatility, being easy to use for data science, web development, utility programming, and as a general-purpose programming language. Even full-stack development can be done in Python, the only area where it is not used being mobile (although that may change if the Kivy mobile programming framework comes of age and stops stalling all the time). It was also ranked higher than JavaScript in the most loved programming languages for the last three years (Node.js and React.js have ranked below it consistently).
Will Python’s Dominance Continue?
We believe, yes, definitely. Two words – data science.
From https://www.digitaldesignjournal.com
Data science is such a hot and happening field right now, and the data scientist job is hyped as the ‘sexiest job of the 21st century‘, according to Forbes. Python is by far the most popular language for data science. The only close competitor is R, which Python overtook in the KDNuggets data science survey of 2016 . As shown in the link, in 2018, Python held 65.6% of the data science market, and R was actually below RapidMiner, at 48.5%. From the graphs, it is easy to see that Python is eating away at R’s share in the market. But why?
Deep Learning
In 2018, we say a huge push towards advancement across all verticals in the industry due to deep learning. And what is the most famous tool for deep learning? TensorFlow and Keras – both Python-based frameworks! While we have Keras and TensorFlow interfaces in R and RStudio now, Python was the initial choice and is still the native library – kerasR and tensorflow in RStudio being interfaces to the Python packages. Also, a real-life implementation of a deep learning project contains more than the deep learning model preparation and data analysis.
There is the data preprocessing, data cleaning, data wrangling, data preparation, outlier detection and missing data values management section which is infamous for taking up 99% of the time of a data scientist, with actual deep learning model work taking just 1% or less of their on-duty time! And what language is used for this commonly? For general purpose programming, Python is the goto language in most cases. I’m not saying that R doesn’t have data preprocessing packages. I’m saying that standard data science operations like web scraping are easier in Python than in R.And hence Python will be the language used in most cases, except in the statistics and the university or academic fields.
Our prediction for Python – growth – even to 70% of the data science market as more and more research-level projects like AutoML keep using Python as a first language of choice.
What About R?
In 2016, the use of R for data science in the industry was 55%, and Python stood at 51%. Python increased by 33% and R decreased by 25% in 2 years. Will that trend continue and will R continue on its downward spiral? I believe perhaps in figures, but not in practice. Here’s why.
Data science is at its heart, the field of the statistician. Unless you have a strong background in statistics, you will be unable to process the results of your experiments, especially in concepts like p-values, tests of significance, confidence intervals, and analysis of experiments. And R is the statistician’s language.Statistics and mathematics students will always find working in R remarkably easy and simple, which explains its popularity in academia. R programming lends itself to statistics. Python lends itself to model building and decent execution performance (R can be 4x slower). R, however, excels in statistical analysis. So what is the point that I am trying to express?
Simple – Python and R are complementary. They are best used together. You will find that knowledge of both Python and R will suit you best for most projects. You need to learn both. You can find this trend expressed in every article that speaks about becoming a data science unicorn – knowledge of both Python and R is required as a norm.
Yes, R is having a downturn in popularity. However, due to the complementary nature of the tools, I believe that R will have a part to play in the data scientist’s toolbox, even if it does dip a bit in growth in the years to come. Very simply, R is too convenient for a statistician to be neglected by the industry completely. It will continue to have its place in the toolbox. And yes; deep learning is now practical in R with support for Keras and AutoML as well as of right now.
Dimensionless Technologies
Dimensionless Technologies
Dimensionless Technologies is the market leader as far as training in AI, cloud, deep learning and data science in Python and R is concerned. Of course, you don’t have to spend 40k for a data science certification, you could always go for its industry equivalent – 100-120 lakhs for a US university’s Ph.D. research doctorate! What Dimensionless Technologies has as an advantage over its closest rival – (Coursera’s John Hopkins University’s Data Science Specialization) – is:
Live Video Training
The videos that you get on Coursera, edX, Dataquest, MIT OCW (MIT OpenCourseWare), Udacity, Udemy, and many other MOOCs have a fundamental flaw – they are NOT live! If you have a doubt in a video lecture, you only have the comments as a communication tool to the lectures. And when over 1,000 students are taking your class, it is next to impossible to respond to every comment. You will not and cannot get personalized attention for your doubts and clarifications. This makes it difficult for many, especially Indian students who may not be used to foreign accents to have a smooth learning curve in the popular MOOCs available today.
Try Before You Buy Fully
Dimensionless Technologies offers 20 hours of the course for Rs 5000, with the remaining 35k (10k of 45k waived if you qualify for the scholarship) payable after 2 weeks / 20 hours of taking the course on a trial basis. You get to evaluate the course for 20 hours before deciding whether you want to go through the entire syllabus with the highly experienced instructors who are strictly IIT alumni.
Instructors with 10 years Plus Industry Experience
In Coursera or edX, it is more common for Ph.D. professors than industry experienced professionals to teach the course. If you are good with American accents and next to zero instructor support, you will be able to learn a little bit about the scholastic side of your field. However, if you want to prepare for a 100K USD per year US data scientist job, you would be better off learning from professionals with industry experience. I am Not criticizing the Coursera instructors here, most have industry experience as well in the USA. However, if you want connections and contacts in the data science industry in India and the US, you might be a bit lost in the vast numbers of student who take those courses. Industry experience in instructors is rare in a MOOC and critically important to your landing a job.
Personalized Attention and Job Placement Guarantee
Dimensionless has a batch size of strictly not more than 25 per batch. This means that unlike other MOOCs with hundreds or thousands of students, every student in a class will get individual attention and training. This is the essence of what makes this company the market leader in this space. No other course provider has this restriction, which makes it certain that when you pay the money, you are 100% certain of completing your course, unlike all the other MOOCs out there. You are also given training for creating a data science portfolio, and how to prepare for data science interviews when you start applying to companies. The best part of this entire process is the 100% job placement guarantee.
If this has got your attention, and you are highly interested in data science, I encourage you to go to the following link to see more about the Data Science Using Python and R course, a strong foundation for a data science career:
Are you from a computer science background and moving into data science? Are you planning to learn coding being from a non-programming background in data science? Then you need not worry because in this blog we will be talking about the importance of computer science in the data science world. Furthermore, we will also be looking at why is it necessary to be fluent with coding(basic at least) in the data science world.
Before enumerating the role of computer science in the data science world, let us clear our understanding of the above two terms. This will allow us to be on the same page before we reason out the importance of coding in data science.
What is Computer Science
Computer Science is the study of computers and computational systems. Unlike electrical and computer engineers, computer scientists deal mostly with software and software systems; this includes their theory, design, development, and application.
Principal areas of study within Computer Science include artificial intelligence, computer systems, and networks, security, database systems, human-computer interaction, vision and graphics, numerical analysis, programming languages, software engineering, bioinformatics and theory of computing.
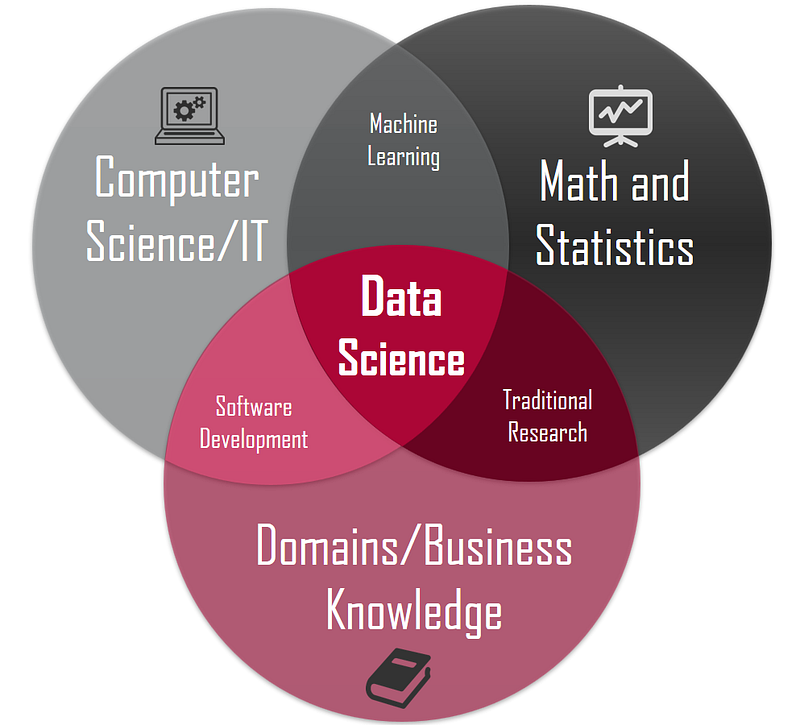
What is Data Science
Data science is the umbrella under which all these terminologies take the shelter. Data science is a like a complete subject which has different stages within itself. Suppose a retailer wants to forecast the sales of an X item present in its inventory in the coming month. This is known as a business problem and data science aims to provide optimized solutions for the same.
Data science enables us to solve this business problem with a series of well-defined steps.
1: Collecting data 2: Pre-processing data 3: Analysing data 4: Driving insights and generating BI reports 5: Taking decision based on insights
Generally, these are the steps we mostly follow to solve a business problem. All the terminologies related to data science falls under different steps which we are going to understand just in a while. Different terminologies fall under different steps listed above.
Data science as you can see is an amalgamation of Business, maths and computer science. A computer engineer is familiar with the entire CS aspect of it and much of maths sections is also covered. Hence, there is no denying fact that Computer science engineers will have a little advantage while beginning their career as data scientists.
Application of computer science in data science
After understanding the difference between Computer Science and Data Science, we will look at the areas in data science where computer science is employed
Data Collection (Big data and data engineering)
Computer science gives you an edge in understanding and working hands-on with aspects of BIG Data. Big data works mainly on important concepts like map-reduce, master-slave concepts etc. These concepts are something by which most of the computer engineers are aware of. Hence, familiarity with these concepts enables a head start in learning these technologies and using them effectively for the complex cases.
Data Pre-Processing (Cleaning, SQL)
Data extraction involves heavy usage of SQL in data sciences. SQL is one of a primary skill in data sciences. SQL is something which is never an alien term to Computer Engineers as most of them are/should be adept in it. Computer science engineers are taught the databases and their management in and out and hence knowledge of SQL is elementary to them.
Analysis(EDA etc)
For data analysis, knowledge of one of the programming language (R or Python mostly)is elementary. Being proficient in one of these languages grants the learner an ability to quickly get started with complex ETL operations. Additionally, the ability to understand and implement code quickly can enable you to go one extra mile while doing your analysis. Also, it reduces your time spent on such tasks as one is already through all the basic concepts.
Insights( Machine Learning/Deep Learning)
Computer scientists invented the name machine learning, and it’s part of computer science, so in that sense, it’s 100% computer science. Furthermore, computer scientists view machine learning as “algorithms for making good predictions.” Unlike statisticians, computer scientists are interested in the efficiency of the algorithms and often blur the distinction between the model and how the model is fit. Additionally, they are not too interested in how we got the data or in models as representations of some underlying truth. For them, machine learning is black boxes making predictions. And computer science has, for the most part, dominated statistics when it comes to making good predictions.
Visual Reports(Visualisations)
Visualizations are an important aspect of data science. Although Data science has multiple tools available for visualization, complex representation requires that extra coding effort. Complex enhancements in visualizations may require some technical aspect of changing few extra parameters of the base library or even the framework you are working with.
Pros of Computer Science knowledge in Data Science
Headstart with all technical aspect of data science
Ability to design, scale and optimise technical solutions
Interpreting algorithm/tool behaviour for different business use cases
Bringing a fresh perspective of looking at a business problem
Proficiency with most of the hands-on coding work
Cons of Computer Science knowledge in Data Science
May end up with a fixed mindset of doing things the “Computer Science” way.
You have to catch up with a lot of business knowledge and applications
Need to pay greater attention to maths and statistics as they are vital aspects of data science
Conclusion
In this blog, we had a look at the various application of computer science in the data science industry. No wonder that because of multiple applications of computer science in the data science industry, computer engineers find it easy, to begin with. Also, at no point in time, we imply that only computer science graduates can excel in the data science domain. Although, being a bachelor in computer science has its own perils in the science field. But, it also comes with its own set of disadvantages like lack of business knowledge and statistics. Anyone can excel in data science who can master all three aspects of it regardless of their bachelor degrees. All you need is right guidance outside and motivation within. Additionally, we at Dimensionless Technologies, provide hands-on training on Data Science, Big Data and NLP. You can check our courses here.
Furthermore, for more blogs on data science, visit our blog section here.
Also, you may also want to have a look at some of our previous blogs below.
For those of you who don’t know, Julia is a multiple-paradigm (fullyimperative, partially functional, and partially object-oriented) programming language designed for scientific and technical (read numerical) computing. It offers significant performance gains over Python (when used without optimization and vectorized computing using Cython and NumPy). Time to develop is reduced by a factor of 2x on average. Performance gains range in the range from 10x-30x over Python (R is even slower, so we don’t include it. R was not built for speed). Industry reports in 2016 indicated that Julia was a language with high potential and possibly the chance of becoming the best option for data science if it received advocacy and adoption by the community. Well, two years on, the 1.0 version of Julia was out in August 2018 (version 1.0), and it has the advocacy of the programming community and the adoption by a number of companies (see https://www.juliacomputing.com) as the preferred language for many domains – including data science.
From https://blog.simos.info/learning-the-julia-computer-language-on-ubuntu/
While it shares many features with Python (and R) and various other programming languages like Go and Ruby, there are some primary factors that set Julia apart from the rest of the competition:
Advantages of Julia
Performance
Basically, Julia is a compiled language, whereas Python and R are interpreted. That means that Julia code is executed directly on the processor as executable code. There are optimizations that can be done for compiler output that cannot be done with an interpreter. You could argue that Python, which is implemented in C as the Cython package, can be optimized to Julia-like levels of performance, can also be optimized if you know the language well. But the real answer to the performance question is that Julia gives you C-like speed without optimization and hand-crafted profiling techniques. If such performance is available without optimization in the first place, why go for Python? Juia could well be the solution to all your performance problems.
Having said that, Julia is still a teenager as far as growth and development maturity as a programming language is concerned. Certain operations like I/O cause the performance to drop rather sharply if not properly managed. From experience, I suggest that if you plan to implement projects in Julia, go for Jupyter Notebooks running Julia 1.0 as a kernel. The Juno IDE on the Atom editor is the recommended environment, but the lack of a debugger is a massive drawback if you want to use Julia code in production in a Visual Studio-like environment. Jupyter allows you to develop your code one feature at a time, and easy access to any variable and array values that you need to ‘watch’. The Julia ecosystem has an enthusiastic and broad community developing it, but since the update to 1.0 was less than six months ago, not all the packages in Julia from version 0.7 have been migrated completely, so you could come up with the odd package versioning problem while installing necessary packages for your project.
HPC Laptop use (from Unsplash)
2. GPU Support
This is directly related to performance. GPU support is handled transparently by some packages like TensorFlow.jl and MXNet.jl. For developers in 2018 already using extremely powerful GPUs for various applications with CUDA or cryptocurrency mining (just to take two common examples), this is a massive bonus, and performance boosts can even go anywhere between 100x to even 1000x for certain operations and configurations. If you want certain specific GPU capacity, Julia has you covered with libraries like cuBLAS.jl and cuDNN.jl for vendor-specific and CUDANative.jl for hand-crafted GPU programming and support. Low-level CUDA programming is also possible in Julia with CUDAdrv.jl and the runtime library CUDArt.jl. Clearly, Julia has evolved well beyond standard GPU support and capabilities. And even as you read this article, an active community is at work to extend and polish the GPU support for Julia.
3. Smooth Learning Curve, and Extensive Built-in Functionality
Julia is remarkably simple to learn and enjoyable to use. If you are a Python program, you will feel completely at home using Julia. In Julia, everything is an expression and there is basic functional programming support. Higher order functions are supported by simple assignment (=) and the function operator -> (lambda in Python, => in C#). Multidimensional matrix support is excellent – functions for BLAS and LINPACK packages are included in the LinearAlgebra package of the standard library. Rows are separated with the comma(,) delimiter, and columns with the semicolon(;) during initialization. Matrix transpose, adjoint, factorization, matrix division, identity, slicing, linear equation system solving, triangulization, and many more functionalities are single function callsaway. Even jagged multidimensional matrix support is available. Missing, nothing, any, all, isdef, istype, oftype, hash, Base as a parent class for every Julia object, isequal, and even undef (to represent uninitialized values) are just a few of the many keywords and functions available to increase the readability of your code. Other notable features include built-in support for arbitrary precision arithmetic, complex numbers, Dictionaries, Sets, BitStrings, BitArrays, and Pipelines. I have just scratched the surface here. The extensive built-in functionality is one of Julia’s best features, with many more easily available and well-documented modules.
4. Multiple Dispatch
This is a central core feature of the Julia programming language. Multiple dispatch or the multimethod functionality basically means that functions can be called dynamically at run-time to behave in different ways depending upon more than just the arguments passed (which is called function overloading) and can instead vary upon the objects being passed into it dynamically at runtime. This concept is fundamentally linked to the Strategy and Template design patterns in object-oriented terminology. We can vary the behaviour of the program depending upon any attribute as well as the calling object and the objects being passed into the function at runtime. This is one of the killer features of Julia as a language. It is possible to pass any object to a function and thus dynamically vary its behaviour depending upon any minute variation in its implementation, and in many cases, the standard library is built around this concept. Some research statistics indicate that the average lines of boilerplate code required in a complex system is reduced by a factor of three or more (!) by this language design choice. This simplifies development in highly complex software systems considerably and cleanly, without any unpredictable or erratic behaviour. It is, therefore, no surprise that Julia is receiving the acclaim now thatit richly deserves.
5. Distributed and Parallel Computing Support
Julia supports parallel and distributed computing using multiple topologies transparently. There is support for coroutines, like in the Go programming language, which are helper functions that operate in parallel on multicore architectures. There is extensive support for threads and synchronization primitives have been carefully designed to maximize performance and minimize the risk of race conditions. Through simple text macros and decorators/annotations like @Parallel, any programmer can write code that executes in parallel. OpenMP support is also present for executing parallel code with compiler directives and macros. From the beginning of its existence, Julia was a language designed to support high-performance computing with multiple worker processes executing simultaneously. And this makes it much easier to use for parallel computing than (say) Python, which has always had the GIL (Global Interpreter Lock for threads) as a serious performance problem.
6. Interoperation with other programming languages (C, Java, Python, etc)
Julia can call C, Go, Java, MATLAB, R, and Python code using native wrapper functions – in fact, every commonly used programming language today has interoperability support with Julia. This makes working with other languages infinitely easier. The only major difference is that in Julia, array indexes begin at 1 (like R) whereas in many other languages it begins at 0 (C, C++, Java, Python, C#, and many more). The interoperability support makes life as a Julia developer much simpler and easier than if you were working in Python or C++/Java. In the real world, calling other libraries and packages is a part of the data scientist’s daily routine – part of a developer’s daily routine. Open source packages are at an advantage here since they can be modified as required for your problem domain. Interoperability with all the major programming languages is one of Julia’s strongest selling points.
Programming Fundamentals 🙂
Current Weaknesses
Julia is still developing despite the 1.0 release. Performance, the big selling point, is affected badly by using global variables and the first run of a program is always slow, compared to execution following the first. The core developers of the Julia language need to work on its package management system, and critically, migration of all the third-party libraries to version 1.0. Since this is something that will happen over time with active community participation (kind of like the Python 2.7 to 3.6 migration, but with much less difficulty), this is an issue that will resolve itself as time goes by. Also, there needs to be more consistency in the language for performance on older devices. Legacy systems without quality GPUs could find difficulties in running Julia with just CPU processing power. (GPUs are not required, but are highly recommended to run Julia and for the developer to be optimally productive, especially for deep learning libraries likeKnet (Julia library for neural networks and deeplearning)). The inclusion of support for Unicode 11.0 can be a surprise for those not accustomed to it, and string manipulation can be a headache. Because Julia needs to mature a little more as a language, you must also be sure to use aprofiler to identify and handle possible performance bottlenecks in your code.
Conclusion
So you might ask yourself a question – if you’re a company running courses in R and Python, why would you publish an article that advocates another language for data science? Simple. If you’re new to data science and programming, learning Python and R is the best way to begin your exploration into the current industry immediately (it’s rather like learning C before C++). And Python and R are not going anywhere anytime soon. Since there is both a massive codebase and a ton of existing frameworks and production code that run on Python and to a lesser level, on R, the demand for data scientists who are skilled in Python will extend far into the future. So yes, it is fully worth your time to learn both Python and R. Furthermore, Julia has yet to be adopted industry-wide (although there are many Julia evangelists who promote it actively – e.g. see www.stochasticlifestyle.com). For at least ten years more, expect Python to be the main player as far as data science is concerned.
Furthermore, programming languages never fully die out. COBOL wasdesigned by a committee led by Grace Hopper in 1959 and is still the go-to language for mainframe programming fifty years later. Considering that, expect the ubiquitously used Python and R to be market forces for at least two decades more. Even if more than 70% of the data science community turned to Julia as the first choice for data science, the existing codebase in Python and R will not disappear any time soon. Julia also requires more maturity as a language (as already mentioned) – some functions run slower than Python where the implementation has not been optimal and well tested, especially on older devices. Hence, Julia’s maturity as a programming language could still be a year or two away. So – reading this article, realize that Python and R are very much prerequisite skills in becoming a professional data scientist right now. But – do explore Julia a little in your free time. All the best!
For further information on choosing data science as a career, I highly recommend the following articles: