What does your business do with the huge volumes of data collected daily? For business, the huge volumes of data collected daily can be demanding and time-consuming. Gathering, analyzing and reporting this type of information and discovering the most important data from the report can be supported through clustering it all.
Clustering can help businesses to manage their data better – image segmentation, grouping web pages, market segmentation, and information retrieval are four examples. For retail businesses, data clustering helps with customer shopping behaviour, sales campaigns, and customer retention. In the insurance industry, clustering is regularly employed in fraud detection, risk factor identification and customer retention efforts. In banking, clustering is used for customer segmentation, credit scoring and analyzing customer profitability.
In this blog, we will understand cluster analysis in detail. We will also look at implementing cluster analysis in python and visualise results in the end!
What is Cluster Analysis?
Clustering is the process of grouping observations of similar kinds into smaller groups within the larger population. It has a widespread application in business analytics. One of the questions facing businesses is how to organize the huge amounts of available data into meaningful structures. Or break a large heterogeneous population into smaller homogeneous groups. Cluster analysis is an exploratory data analysis tool which aims at sorting different objects into groups in a way that the degree of association between two objects is maximal if they belong to the same group and minimal otherwise.
For example, A grocer retailer used clustering to segment its 1.3MM loyalty card customers into 5 different groups based on their buying behaviour. It then adopted customized marketing strategies for each of these segments in order to target them more effectively.
Applications of Cluster Analysis
1. Marketing
Help marketers discover distinct groups in their customer bases and then use this knowledge to develop targeted marketing programs
2. Land Use
Identification of areas of similar land use in an earth observation database
3. Insurance
Identifying groups of motor insurance policyholders with a high average claim cost
4. City-Planning
Identifying groups of houses according to their house type, value, and geographical location
5. Earthquake Studies
Observed earthquake epicenters should be clustered along continent faults
Algorithms for Cluster Analysis
1. K- Means clustering
Kmeans algorithm is an iterative algorithm that tries to partition the dataset into Kpre-defined distinct non-overlapping subgroups (clusters) where each data point belongs to only one group. It tries to make the inter-cluster data points as similar as possible while also keeping the clusters as different (far) as possible. It assigns data points to a cluster such that the sum of the squared distance between the data points and the cluster’s centroid (arithmetic mean of all the data points that belong to that cluster) is at the minimum. The less variation we have within clusters, the more homogeneous (similar) the data points are within the same cluster.
The way the kmeans algorithm works is as follows:
Specify the number of clusters K.
Initialize centroids by first shuffling the dataset and then randomly selecting K data points for the centroids without replacement.
Keep iterating until there is no change to the centroids. i.e assignment of data points to clusters isn’t changing.
Compute the sum of the squared distance between data points and all centroids.
Assign each data point to the closest cluster (centroid).
Compute the centroids for the clusters by taking the average of all data points that belong to each cluster.
The approach the kmeans follows to solve the problem is called Expectation-Maximization. The E-step is assigning the data points to the closest cluster. The M-step is computing the centroid of each cluster. Below is a break down of how we can solve it mathematically (feel free to skip it).
The objective function is:
where wik=1 for data point xi if it belongs to cluster k; otherwise, wik=0. Also, μk is the centroid of xi’s cluster.
2. Hierarchical Clustering
Hierarchical clustering is a type of unsupervised machine learning algorithm used to cluster unlabeled data points. Like K-means clustering, hierarchical clustering also groups together the data points with similar characteristics. In some cases, the result of hierarchical and K-Means clustering can be similar.
Following are the steps involved in agglomerative clustering:
At the start, treat each data point as one cluster. Therefore, the number of clusters at the start will be K, while K is an integer representing the number of data points.
Form a cluster by joining the two closest data points resulting in K-1 clusters.
Form more clusters by joining the two closest clusters resulting in K-2 clusters.
Repeat the above three steps until one big cluster is formed.
Once a single cluster is formed, dendrograms are used to divide into multiple clusters depending upon the problem. We will study the concept of dendrogram in detail in an upcoming section.
There are different ways to find the distance between the clusters. The distance itself can be Euclidean or Manhattan distance. Following are some of the options to measure the distance between two clusters:
Measure the distance between the closest points of two clusters.
Find the distance between the farthest points of two clusters.
Measure the distance between the centroids of two clusters.
Find the distance between all possible combination of points between the two clusters and take the mean.
Code Implementation
We will implement the kmeans algorithm to visualise data to bucket it into different categories. We are using poker hand public data which is available here
Each record is an example of a hand consisting of five playing cards drawn from a standard deck of 52. Each card is described using two attributes (suit and rank), for a total of 10 predictive attributes. There is one Class attribute that describes the “Poker Hand”. The order of cards is important, which is why there are 480 possible Royal Flush hands as compared to 4!
We will be implementing the k-means algorithm using python and will be visualising the results in the end
Let us start by loading the required libraries for our task. We are using pandas and numpy for managing the data frame and mathematical calculations
# load libraries
from pandas import Series, DataFrame
import pandas as pd
import numpy as np
import matplotlib.pylab as plt
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
from sklearn.cluster import KMeans
import urllib.request
from pylab import rcParams
rcParams['figure.figsize'] = 9, 8
Let us focus on the data preparation aspect of our implementation. We will be preparing our test and train data in this section. Train data is the one on which we will be performing the clustering process!
Before proceeding with the segmentation, let us rescale our values within a certain range in order to bring all the numbers at the same scale. This helps in visualising different features on the same base.
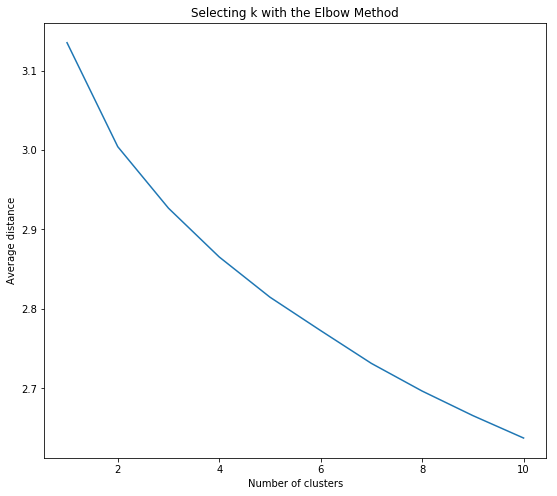
Also, before we start with clustering, we need to determine the number of clusters we are trying to identify. In most of the cases, you are looking for a particular k value for your k-means algorithm. If you select k=3, then the algorithm will try to find 3 different segments present in the data. In most of the cases, you will not be knowing the value of this k parameter. So how do you go about selecting the right “k” value for your model? The answer is “Elbow method”
The idea of the elbow method is to run k-means clustering on the dataset for a range of values of k, and for each value of k calculate the sum of squared errors (SSE).
Then, plot a line chart of the SSE for each value of k. If the line chart looks like an arm, then the “elbow” on the arm is the value of k that is the best. The idea is that we want a small SSE, but that the SSE tends to decrease toward 0 as we increase k (the SSE is 0 when k is equal to the number of data points in the dataset, because then each data point is its own cluster, and there is no error between it and the centre of its cluster). So our goal is to choose a small value of k that still has a low SSE, and the elbow usually represents where we start to have diminishing returns by increasing k
Let’s implement the elbow method to select our “k” value
clus_train = clustervar
from scipy.spatial.distance import cdist
clusters=range(1,11)
meandist=[]
# loop through each cluster and fit the model to the train set
# generate the predicted cluster assingment and append the mean distance my taking the sum divided by the shape
for k in clusters:
model=KMeans(n_clusters=k)
model.fit(clus_train)
clusassign=model.predict(clus_train)
meandist.append(sum(np.min(cdist(clus_train, model.cluster_centers_, 'euclidean'), axis=1))
clus_train.shape[0])
plt.plot(clusters, meandist)
plt.xlabel('Number of clusters')
plt.ylabel('Average distance')
plt.title('Selecting k with the Elbow Method')
Observing the elbow method,k=2 and k=3 are more reasonable options for our segmentation analysis
model3=KMeans(n_clusters=2)
model3.fit(clus_train)
# has cluster assingments based on using 3 clusters
clusassign=model3.predict(clus_train)
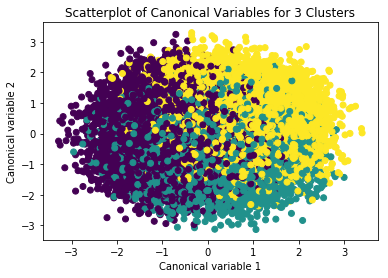
from sklearn.decomposition import PCA # CA from PCA function
pca_2 = PCA(2) # return 2 first canonical variables
plot_columns = pca_2.fit_transform(clus_train) # fit CA to the train dataset
plt.scatter(x=plot_columns[:,0], y=plot_columns[:,1], c=model3.labels_,)
# plot 1st canonical variable on x axis, 2nd on y-axis
plt.xlabel('Canonical variable 1')
plt.ylabel('Canonical variable 2')
# plt.zlabel('Canonical variable 3')
plt.title('Scatterplot of Canonical Variables for 2 Clusters')
plt.show()
Summary
In this blog, we implemented k-means clustering on poker hand dataset. Also, we understood about cluster analysis and different techniques in it. All the in-depth information was not covered in this blog, as it has been written for folks who are starting to explore data clustering in data science. Happy learning!!
Sifting through very large amounts of data for useful information. Data mining uses artificial intelligence techniques, neural networks, and advanced statistical tools. It reveals trends, patterns, and relationships, which might otherwise have remained undetected. In contrast to an expert system, data mining attempts to discover hidden rules underlying the data. Also called data surfing.
In this blog, we will be presenting a comprehensive detail about data mining. Additionally, this blog will help you to get into the details of data mining. Furthermore, it will help you to get the complete picture in one place!
What is Data Mining?
Data mining is not a new concept but a proven technology that has transpired as a key decision-making factor in business. There are numerous use cases and case studies, proving the capabilities of data mining and analysis. Yet, we have witnessed many implementation failures in this field, which can be attributed to technical challenges or capabilities, misplaced business priorities and even clouded business objectives. While some implementations battle through the above challenges, some fail in delivering the right data insights or their usefulness to the business. This article will guide you through guidelines for successfully implementing data mining projects.
Also, data mining is the process of uncovering patterns inside large sets of structured data to predict future outcomes. Structured data is data that is organized into columns and rows so that they can be accessed and modified efficiently. Using a wide range of machine learning algorithms, you can use data mining approaches for a wide variety of use cases to increase revenues, reduce costs, and avoid risks.
Also, at its core, data mining consists of two primary functions, description, for interpretation of a large database and prediction, which corresponds to finding insights such as patterns or relationships from known values. Before deciding on data mining techniques or tools, it is important to understand the business objectives or the value creation using data analysis. The blend of business understanding with technical capabilities is pivotal in making big data projects successful and valuable to its stakeholders.
Different Methods of Data Mining
Data mining commonly involves four classes of tasks [1]: (1) classification, arranges the data into predefined groups; (2) clustering, is like classification but the groups are not predefined, so the algorithm will try to group similar items together; (3) regression, attempting to find a function which models the data with the least error; and (4) association rule learning, searching for relationships between variables.
1. Association
Association is one of the best-known data mining technique. In association, a pattern is discovered based on a relationship between items in the same transaction. That’s is the reason why the association technique is also known as relation technique. The association technique is used in market basket analysis to identify a set of products that customers frequently purchase together.
Retailers are using association technique to research customer’s buying habits. Based on historical sale data, retailers might find out that customers always buy crisps when they buy beers, and, therefore, they can put beers and crisps next to each other to save time for the customer and increase sales.
2. Classification
Classification is a classic data mining technique based on machine learning. Basically, classification is used to classify each item in a set of data into one of a predefined set of classes or groups. Classification method makes use of mathematical techniques such as decision trees, linear programming, neural network, and statistics. In classification, we develop the software that can learn how to classify the data items into groups. For example, we can apply classification in the application that “given all records of employees who left the company, predict who will probably leave the company in a future period.” In this case, we divide the records of employees into two groups named “leave” and “stay”. And then we can ask our data mining software to classify the employees into separate groups.
3. Clustering
Clustering is a data mining technique that makes a meaningful or useful cluster of objects. These objects have similar characteristics using the automatic technique. Furthermore, the clustering technique defines the classes and puts objects in each class. But classification techniques, assignes objects into known classes. To make the concept clearer, we can take book management in the library as an example. In a library, there is a wide range of books on various topics available. The challenge is how to keep those books in a way that readers can take several books on a particular topic without hassle. By using the clustering technique, we can keep books that have some kinds of similarities in one cluster or one shelf and label it with a meaningful name.
4. Regression
In statistical terms, a regression analysis is a process of identifying and analyzing the relationship among variables. it can help you understand the characteristic value of the dependent variable changes if any one of the independent variables is varied. this means one variable is dependent on another, but it is not vice versa.it is generally used for prediction and forecasting.
Data Mining Process and Tools
The Cross-Industry Standard Process for Data Mining (CRISP-DM) is a conceptual tool that exists as a standard approach to data mining. The process outlines six phases:
Business understanding
Data understanding
Data preparation
Modelling
Evaluation
Deployment
The first two phases, business understanding and data understanding, are both preliminary activities. It is important to first define what you would like to know and what questions you would like to answer and then make sure that your data is centralized, reliable, accurate, and complete.
Once you’ve defined what you want to know and gathered your data, it’s time to prepare your data — this is where you can start to use data mining tools. Data mining software can assist in data preparation, modelling, evaluation, and deployment. Data preparation includes activities like joining or reducing data sets, handling missing data, etc.
The modelling phase in data mining is when you use a mathematical algorithm to find a pattern(s) that may be present in the data. This pattern is a model that can be applied to new data. Data mining algorithms, at a high level, fall into two categories — supervised learning algorithms and unsupervised learning algorithms. Supervised learning algorithms require a known output, sometimes called a label or target. Supervised learning algorithms include Naïve Bayes, Decision Tree, Neural Networks, SVMs, Logistic Regression, etc. Unsupervised learning algorithms do not require a predefined set of outputs but rather look for patterns or trends without any label or target. These algorithms include k-Means Clustering, Anomaly Detection, and Association Mining.
Data evaluation is the phase that will tell you how good or bad your model is. Cross-validation and testing for false positives are examples of evaluation techniques available in data mining tools. The deployment phase is the point at which you start using the results.
Importance of Data Mining
1. Marketing / Retail
Data mining helps marketing companies build models based on historical data to predict who will respond to the new marketing campaigns such as direct mail, online marketing campaign…etc. Through the results, marketers will have an appropriate approach to selling profitable products to targeted customers.
Data mining brings a lot of benefits to retail companies in the same way as marketing. Through market basket analysis, a store can have an appropriate production arrangement in a way that customers can buy frequent buying products together with pleasant. In addition, it also helps retail companies offer certain discounts for particular products that will attract more customers.
2. Finance / Banking
Data mining gives financial institutions information about loan information and credit reporting. By building a model from historical customer’s data, the bank, and financial institution can determine good and bad loans. In addition, data mining helps banks detect fraudulent credit card transactions to protect the credit card’s owner.
3. Manufacturing
By applying data mining in operational engineering data, manufacturers can detect faulty equipment and determine optimal control parameters. For example, semiconductor manufacturers have a challenge that even the conditions of manufacturing environments at different wafer production plants are similar, the quality of wafer are a lot the same and some for unknown reasons even has defects. Also, data mining has been applying to determine the ranges of control parameters that lead to the production of the golden wafer.
4. Governments
Data mining helps government agency by digging and analyzing records of the financial transaction to build patterns that can detect money laundering or criminal activities.
Applications of Data Mining
There are approximately 100,000 genes in the human body. Each gene is composed of hundreds of individual nucleotides which are arranged in a particular order. Ways of these nucleotides being ordered and sequenced are infinite to form distinct genes. Data mining technology can be used to analyze the sequential pattern. You can use it to search similarity and to identify particular gene sequences. In the future, data mining technology will play a vital role in the development of new pharmaceuticals. Also, it may provide advances in cancer therapies.
Financial data collected in the banking and financial industry is often relatively complete, reliable, and of high quality. This facilitates systematic data analysis and data mining. Typical cases include classification and clustering of customers for targeted marketing. It can also include detection of money laundering and other financial crimes. Furthermore, we can look into the design and construction of data warehouses for multidimensional data analysis.
The retail industry is a major application area for data mining since it collects huge amounts of data on customer shopping history, consumption, and sales and service records. Data mining on retail is able to identify customer buying habits, to discover customer purchasing pattern and to predict customer consuming trends. This technology helps design effective goods transportation, distribution policies, and less business cost.
Also, data mining in the telecommunication industry can help understand the business involved, identify telecommunication patterns, catch fraudulent activities, make better use of resources and improve service quality. Moreover, the typical cases include multidimensional analysis of telecommunication data, fraudulent pattern analysis and the identification of unusual patterns as well as multidimensional association and sequential pattern analysis.
Summary
The more data you collect…the more value you can deliver. And the more value you can deliver…the more revenue you can generate.
Data mining is what will help you do that. So, if you are sitting on loads of customer data and not doing anything with it…I want to encourage you to make a plan to start diving into it this week. Do it yourself or hire someone else…whatever it takes. Your bottom line will thank you.
Always query yourself how are you bringing value to your business with data mining!
After decades of a heavy slog with no promise of success, quantum computing is suddenly buzzing! Nearly two years ago, IBM made a quantum computer available to the world. The 5-quantum-bit (qubit) resource they now call the IBM Q experience. It was more like a toy for researchers than a way of getting any serious number crunching done. But 70,000 users worldwide have registered for it, and the qubit count in this resource has now quadrupled. With so many promises by quantum computing and data science being at the helm currently, are there any offerings by quantum computing for the AI? Let us explore that in this blog!
What is Quantum Computing?
A traditional computer works on bits of data that are binary, or Boolean, with only two possible values: 0 or 1. In contrast, a quantum bit has possible values of 1, 0 or a superposition of 1 and 0. According to scientists, qubits are more like physical atoms and molecular structures. However, many find it helpful to theorize a qubit as a binary data unit with superposition.
The use of qubits makes the practical quantum computer model quite difficult. Traditional hardware requires altering to read and use these unknown values. Another idea, known as entanglement, uses quantum theory to suggest that accurate values cannot be obtained in the ways that traditional computers read binary bits. It also has been suggested that a quantum computer is based on a non-deterministic model, where the computer has more than one possible outcome for any given case or situation. Each of these ideas provides a foundation for the theory of actual quantum computing, which is still problematic in today’s tech world.
Use of Quantum Computing
Let us look at some of the use cases of the quantum computing below. This will help you understand the scale of the application of quantum computing currently.
Use cases can be:
1. Cryptography
The most common area people associate quantum computing with is advanced cryptography. The ordinary computers we use today make it infeasible to break the encryption that uses very large prime number factorization (300+ integers). With quantum computers, this decryption could become trivial, leading to much stronger protection of our digital lives and assets. Of course, we’ll also be able to break traditional encryption much faster.
2. Aviation
Quantum technology could enable much more complex computer modelling like aeronautical scenarios. Aiding in the routing and scheduling of aircraft has enormous commercial benefits for time and costs. Large companies like Airbus and Lockheed Martin are actively researching and investing in the space to take advantage of the computing power and the optimization potential of the technology.
3. Data Analytics
Quantum mechanics and quantum computing can help solve problems on a huge scale. A field of study called topological analysis where geometric shapes behave in specific ways describes computations that are simply impossible with today’s conventional computers due to the data set used.
NASA is looking at using quantum computing for analyzing the enormous amount of data they collect about the universe, as well as research better and safer methods of space travel.
4. Forecasting
Predicting and forecasting various scenarios rely on large and complex data sets. Traditional simulation of, for example, the weather is limited in the inputs that can be handled with classical computing. If you add too many factors, then the simulation takes longer than for the actual weather to evolve.
5. Pattern Matching
Finding patterns in data and using these to predict future patterns is highly valuable. Volkswagen is currently looking into how they can use quantum computing to inform drivers of traffic conditions 45 minutes in advance. Matching traffic patterns and predicting the behaviour of a system as complex as modern day traffic is so far not possible for today’s computers, but this is going to change with quantum computers.
6. Medical Research
There are literally billions of possibilities to how something could react across the human body and even more when you consider that this could be a drug administered to billions of people, each with slight differences in their makeup.
Today, it takes pharmaceutical companies up to 10+ years and often billions of dollars to discover a new drug and bring it to market. Improving the front end of the process with quantum computing can dramatically cut costs and time to market, repurpose pre-approved drugs more easily for new applications, and empower computational chemists to make new discoveries faster that could lead to cures for a range of diseases.
7. Self-Driving Cars
Car companies like Tesla and tech companies like Apple and Google are actively developing driverless cars. Not only will these improve the standard of living for most people, but also cut pollution, reduce congestion and bring about a bunch of other benefits.
AI and Quantum Computing
Quantum computing is not a replacement for AI but you can see it more like an enhancement. AI is a major task which we are trying to solve and quantum computing helps us in optimising the sub-tasks of it. Currently, we have a limited scope of quantum computing in AI as technology is still currently new. But on a broad level, quantum computing affects the following tasks in AI
1. Simulation Simulation modelling is the process of creating and analyzing a digital prototype of a physical model to predict its performance in the real world. It is used to help designers and engineers understand whether, under what conditions, and in which ways a part could fail and what loads it can withstand. This modelling can also help to predict fluid flow and heat transfer patterns. It analyses the approximate working conditions by applying the simulation software.
2. Optimisation An optimization problem is a problem of finding the best solution from all feasible solutions. Optimization problems can be divided into two categories depending on whether the variables are continuous or discrete. An optimization problem with discrete variables is known as a discrete optimization. In a discrete optimization problem, we are looking for an object such as an integer, permutation or graph from a countable set. Problems with continuous variables include constrained problems and multimodal problems.
3. Sampling Data sampling is a statistical analysis technique used to select, manipulate and analyze a representative subset of data points to identify patterns and trends in the larger data set being examined. It enables data scientists, predictive modelers and other data analysts to work with a small, manageable amount of data about a statistical population to build and run analytical models more quickly, while still producing accurate findings.
Benefits of Quantum Computing in AI
1. Less time in training The big advantage of quantum computing is that it allows an exponential increase in the number of dimensions it can process. While a classical perceptron can process an input of N dimensions, a quantum perceptron can process 2N dimensions.
2. Better Results It turns out that quantum perceptron can easily classify the patterns in these simple images. We use the quantum model of perceptron as an elementary nonlinear classifier of simple patterns
3. Achieving parallelism The earliest examples of a quantum algorithm are exponentially faster than any possible deterministic classical algorithm. Quantum computing allows solving the problem since it is capable of simultaneously evaluating f(0)and f(1). This possibility stems from ‘quantum parallelism’. The quantum parallelism allows computing 2n entries for a state consisting of n-qubits. That is: from a linear growth in the number of qubits, we can achieve exponential growth in computing space.
Challenges
Sensitivity to interaction with the environment Quantum computers are extremely sensitive to interaction with the surroundings since any interaction (or measurement) leads to a collapse of the state function. This phenomenon is called decoherence. It is extremely difficult to isolate a quantum system, especially an engineered one for a computation, without it getting entangled with the environment. The larger the number of qubits the harder is it to maintain the coherence.
Error-correction Quantum error correction (QEC) is used in quantum computing to protect quantum information from errors due to decoherence and other quantum noise. Quantum error correction is essential if one is to achieve fault-tolerant quantum computation that can deal not only with noise on stored quantum information, but also with faulty quantum gates, faulty quantum preparation, and faulty measurements. Copying quantum information is not possible due to the no-cloning theorem. This theorem seems to present an obstacle to formulating a theory of quantum error correction
Constraints on state preparation State preparation is the essential first step to be considered before the beginning of any quantum computation. In most schemes, the qubits need to be in a superposition state for the quantum computation to proceed correctly. We have a variety of problems due to the nature of superposition and entanglements, and state transition using local transformations is not realistic in a large system. Macrosystems that have been used as model quantum computing systems [14, 33,34] appear to implement not pure states but mixtures. Thus it appears that the NMR experiments do not validate the quantum algorithm.
Summary
Three decades after they were first proposed, quantum computers remain largely theoretical. Even so, there’s been some encouraging progress toward realizing a quantum machine. There’s no doubt that these are hugely important advances. and the signs are growing steadily more encouraging that quantum technology will eventually deliver a computing revolution. The potential of quantum computing in artificial intelligence will be evident soon, but still, we do not know how to translate that potential into reality. Undoubtedly, time will put things in place
Data science is one of the hottest topics in the 21st century because we are generating data at a rate which is much higher than what we can actually process. A lot of business and tech firms are now leveraging key benefits by harnessing the benefits of data science. Due to this, data science right now is really booming.
In this blog, we will deep dive into the world of machine learning. We will walk you through machine learning basics and have a look at the process of building an ML model. We will also build a random forest model in python to ease out the understanding process.
What is Machine Learning?
Machine Learning is the science of getting computers to learn and act like humans do, and improve their learning over time in an autonomous fashion, by feeding them data and information in the form of observations and real-world interactions.
There are many different types of machine learning algorithms, with hundreds published each day, and they’re typically grouped by either learning style (i.e. supervised learning, unsupervised learning, semi-supervised learning) or by similarity in form or function (i.e. classification, regression, decision tree, clustering, deep learning, etc.). Regardless of learning style or function, all combinations of machine learning algorithms consist of the following:
Representation (a set of classifiers or the language that a computer understands)
Evaluation (aka objective/scoring function)
Optimization (search method; often the highest-scoring classifier, for example; there are both off-the-shelf and custom optimization methods used)
Steps for Building ML Model
Here is a step-by-step example of how a hospital might use machine learning to improve both patient outcomes and ROI:
1. Define Project Objectives
The first step of the life cycle is to identify an opportunity to tangibly improve operations, increase customer satisfaction, or otherwise create value. In the medical industry, discharged patients sometimes develop conditions that necessitate their return to the hospital. In addition to being dangerous and troublesome for the patient, these readmissions mean the hospital will spend additional time and resources on treating patients for the second time.
2. Acquire and Explore Data
The next step is to collect and prepare all of the relevant data for use in machine learning. This means consulting medical domain experts to determine what data might be relevant in predicting readmission rates, gathering that data from historical patient records, and getting it into a format suitable for analysis, most likely into a flat file format such as a .csv.
3. Model Data
In order to gain insights from your data with machine learning, you have to determine your target variable, the factor of which you are trying to gain a deeper understanding. In this case, the hospital will choose “readmitted,” which is included as a feature in its historical dataset during data collection. Then, they will run machine learning algorithms on the dataset that build models that learn by example from the historical data. Finally, the hospital runs the trained models on data the model hasn’t been trained on to forecast whether new patients are likely to be readmitted, allowing it to make better patient care decisions.
4. Interpret and Communicate
One of the most difficult tasks of machine learning projects is explaining a model’s outcomes to those without any data science background, particularly in highly regulated industries such as healthcare. Traditionally, machine learning has been thought of as a “black box” because of how difficult it is to interpret insights and communicate their value to stakeholders and regulatory bodies alike. The more interpretable your model, the easier it will be to meet regulatory requirements and communicate its value to management and other key stakeholders.
5. Implement, Document, and Maintain
The final step is to implement, document, and maintain the data science project so the hospital can continue to leverage and improve upon its models. Model deployment often poses a problem because of the coding and data science experience it requires, and the time-to-implementation from the beginning of the cycle using traditional data science methods is prohibitively long.
Problem Statement
A certain car manufacturing company X is looking to target its customers for their particular car model. Customers are identified by their age, salary, and Gender. The organisation wants to identify or predict which customers will affect the sales of their new car and actually purchase it.
We have a purchased column here which holds two values i.e 0 and 1. 0 indicates that the car has not been purchased by a certain individual. 1 indicates the sale of the car.
Code Implementation
Importing the Required Libraries
You need to import all the required libraries first which will ease the model building parts for us. We are using keras to build our random forest model. We are using the matplotlib library to plot the charts and graphs and visualise results. In the end, we are also importing functions from the sklearn module which can help us in splitting our data into training and testing parts
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
Loading the Dataset
In this step, you need to load your dataset in the memory. After that, we separate out the dependent and the independent variables for the training of our classifier. In most of the cases, you need to separate the dependent and he the independent variables
# Importing the dataset
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, [2, 3]].values
y = dataset.iloc[:, 4].values
Splitting the Dataset to Form Training and Test Data
In all the cases, you need to make some partitions in your data. A major chunk of your data acts as a training set and a smaller chunk acts as a test set. There are no clearly defined criteria on the proportion of the training and the test set. But most people follow 70–30 or 75–25 rule where a larger chunk is your training set. We train the data on the training set and test it on the test set. This process is known as validation. The prime idea behind this purpose is that one needs to gauge the performance of the model on the data which model has never seen before. In the real-world scenarios, the model will be predicting values on the unseen data. Furthermore, techniques like validation help us in avoiding overfitting or underfitting the model.
Overfitting refers to the case when our model has learnt all about the specific data on which it trained. It will work well on the training data but will have poor accuracy for any unseen data point. Overfitting is like your model is very specific to the data it has and has no generality. Similarly, underfitting is the case where your model is very general and is not able to predict well for your specific use-case. To achieve the best model accuracy, you need to strike a perfect balance between overfitting and under-fitting.
# Splitting the dataset into the Training set and Test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
In this case, we are fitting our model with the training data. We are using the random forest model exposed by the sklearn package in python. Ultimately, we pass the dependent and independent features separately through which our model makes an internal mapping between them using mathematical coefficients.
# Fitting Random Forest Classification to the Training set
from sklearn.ensemble import RandomForestClassifier
classifier = RandomForestClassifier(n_estimators = 10, criterion = 'entropy', random_state = 0)
classifier.fit(X_train, y_train)
Predicting Results from the Classifier
In this part, we are passing unseen values to our model on which it is making predictions. We use a confusion matrix to derive metrics like accuracy, precision, and recall for our model. These metrics help us to understand the performance of the model.
# Predicting the Test set results
y_pred = classifier.predict(X_test)
# Making the Confusion Matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
Visualising the Predictions
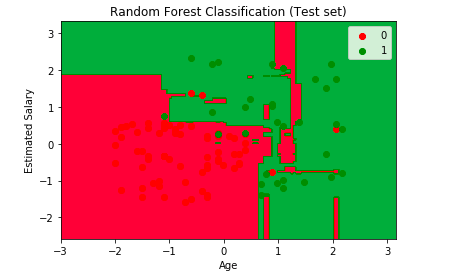
Additionally, we have made an attempt to visualise the predictions of our model using the below code.
# Visualising the Test set results
# Visualising the Test set results
from matplotlib.colors import ListedColormap
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('Random Forest Classification (Test set)')
plt.xlabel('Age')
plt.ylabel('Estimated Salary')
plt.legend()
plt.show()
Summary
Hence, in this Machine Learning Tutorial, we studied the basics of ML. Earlier machine learning was the theory that computers can learn without being programmed to perform specific tasks. But now, the researchers interested in artificial intelligence wanted to see if computers could learn from data. They learn from previous computations to produce reliable decisions and results. It’s a science that’s not new — but one that’s gaining fresh momentum.
Follow this link, if you are looking to learn more about data science online!
Launched back in 2006, AWS has succeeded in becoming the leading provider of on-demand cloud computing services. The cloud computing services provider secures a staggering 32% of the cloud computing market share up until the last quarter of 2018.
Every aspiring developer looking to make it big in the cloud computing ecosphere must have a stronghold on AWS. If you’re eyeing for the role of an AWS Developer, then these most important 20 AWS interview questions will help you take a step further towards your desired job avenue. So let us kickstart your AWS learning with Dimensionless!
AWS Interview Questions with Answers
1. What is AWS?
AWS attains as Amazon Web Service; this is a gathering of remote computing settings also identified as cloud computing policies. This unique realm of cloud computing is also recognized as IaaS or Infrastructure as a Service.
2. What are the Key Components of AWS?
The fundamental elements of AWS are
Route 53: A DNS web service
*Easy E-mail Service: It permits addressing e-mail utilizing RESTFUL API request or through normal SMTP
*Identity and Access Management: It gives heightened protection and identity control for your AWS account
*Simple Storage Device or (S3): It is warehouse equipment and the well-known widely utilized AWS service
*Elastic Compute Cloud (EC2): It affords on-demand computing sources for hosting purposes. It is extremely valuable in trouble of variable workloads
*Elastic Block Store (EBS): It presents persistent storage masses that connect to EC2 to enable you to endure data beyond the lifespan of a particular EC2
*CloudWatch: To observe AWS sources, It permits managers to inspect and obtain key Additionally, one can produce a notification alert in the state of crisis.
3. What is S3?
S3 holds for Simple Storage Service. You can utilize S3 interface to save and recover the unspecified volume of data, at any time and from everywhere on the web. For S3, the payment type is “pay as you go”.
4. What is the Importance of Buffer in Amazon Web Services?
An Elastic Load Balancer ensures that the incoming traffic is distributed optimally across various AWS instances. A buffer will synchronize different components and makes the arrangement additional elastic to a burst of load or traffic. The components are prone to work in an unstable way of receiving and processing the requests. The buffer creates the equilibrium linking various apparatus and crafts them effort at the identical rate to supply more rapid services.
5. What Does an AMI Include?
An AMI comprises the following elements:
A template to the source quantity concerning the instance
Launch authorities determine which AWS accounts can avail the AMI to drive instances
A base design mapping that defines the amounts to join to the instance while it is originated.
6. How Can You Send the Request to Amazon S3?
Amazon S3 is a REST service, you can transmit the appeal by applying the REST API or the AWS SDK wrapper archives that envelop the underlying Amazon S3 REST API.
7. How many Buckets can you Create in AWS by Default?
In each of your AWS accounts, by default, You can produce up to 100 buckets.
8. List the Component Required to Build Amazon VPC?
Subnet, Internet Gateway, NAT Gateway, HW VPN Connection, Virtual Private Gateway, Customer Gateway, Router, Peering Connection, VPC Endpoint for S3, Egress-only Internet Gateway.
9. What is the Way to Secure Data for Carrying in the Cloud?
One thing must be ensured that no one should seize the information in the cloud while data is moving from point one to another and also there should not be any leakage with the security key from several storerooms in the cloud. Segregation of information from additional companies’ information and then encrypting it by means of approved methods is one of the options.
10. Name the Several Layers of Cloud Computing?
Here is the list of layers of the cloud computing
PaaS — Platform as a Service
IaaS — Infrastructure as a Service
SaaS — Software as a Service
11. Explain- Can You Vertically Scale an Amazon Instance? How?
Surely, you can vertically estimate on Amazon instance.
Twist up a fresh massive instance than the one you are currently governing
Delay that instance and separate the source webs mass of server and dispatch
Next, quit your existing instance and separate its source quantity
Note the different machine ID and connect that source mass to your fresh server
12. What are the Components Involved in Amazon Web Services?
There are 4 components involved and areas below. Amazon S3: with this, one can retrieve the key information which are occupied in creating cloud structural design and amount of produced information also can be stored in this component that is the consequence of the key specified. Amazon EC2 instance: helpful to run a large distributed system on the Hadoop cluster. Automatic parallelization and job scheduling can be achieved by this component.
Amazon SQS: this component acts as a mediator between different controllers. Also worn for cushioning requirements those are obtained by the manager of Amazon.
Amazon SimpleDB: helps in storing the transitional position log and the errands executed by the consumers.
13. What is Lambda@edge in Aws?
In AWS, we can use Lambda@Edge utility to solve the problem of low network latency for end users.
In Lambda@Edge there is no need to provision or manage servers. We can just upload our Node.js code to AWS Lambda and create functions that will be triggered on CloudFront requests.
When a request for content is received by CloudFront edge location, the Lambda code is ready to execute.
This is a very good option for scaling up the operations in CloudFront without managing servers.
14. Distinguish Between Scalability and Flexibility?
The aptitude of any scheme to enhance the tasks on hand on its present hardware resources to grip inconsistency in command is known as scalability. The capability of a scheme to augment the tasks on hand on its present and supplementary hardware property is recognized as flexibility, hence enabling the industry to convene command devoid of putting in the infrastructure at all. AWS has several configuration management solutions for AWS scalability, flexibility, availability and management.
15. Name the Various Layers of the Cloud Architecture?
There are 5 layers and are listed below
CC- Cluster Controller
SC- Storage Controller
CLC- Cloud Controller
Walrus
NC- Node Controller
16. What is the Difference Between Azure and AWS?
AWS and Azure are subsets in terms of cloud computing. Both are used to build and host applications. Azure helped many companies, such as the platform, such as PaaS. … Storage: – AWS has temporary storage that is assigned when an instance is started and destroyed when the instance is terminated.
17. Explain- What is T2 Instances?
T2 instances are outlined to present average baseline execution and the ability to explode to powerful execution as needed by the workload.
18. In VPC with Private and Public Subnets, Database Servers should ideally be launched into which Subnet?
Among private and public subnets in VPC, database servers should ideally originate toward separate subnets.
19. What is AWS SageMaker?
Amazon SageMaker is a fully managed machine learning service. With Amazon SageMaker, data scientists and developers can quickly and easily build and train machine learning models, and then directly deploy them into a production-ready hosted environment. It provides an integrated Jupyter authoring notebook instance for easy access to your data sources for exploration and analysis, so you don’t have to manage servers. It also provides common machine learning algorithms that are optimized to run efficiently against extremely large data in a distributed environment.
20. While Connecting to your Instance What are the Possible Connection Issues one Might Face?
The feasible connection failures one might battle while correlating instances are
Consolidation timed out
User key not acknowledged by the server
Host key not detected, license denied
The unguarded private key file
Server rejected our key or No sustained authentication program available
Error handling Mind Term on Safari Browser
Error utilizing Mac OS X RDP Client
21. Explain Elastic Block Storage? What Type of Performance can you Expect? How do you Back itUp? How do you Improve Performance?
That indicates it is RAID warehouse to begin with, so it’s irrelevant and faults tolerant. If disks expire in the RAID you don’t miss data. Excellent! It is more virtualized, therefore you can provision and designate warehouse, and connect it to your server with multiple API appeals. No calling the storage specialist and asking him or her to operate specific requests from the hardware vendor.
Execution of EBS can manifest variability. Such signifies that can run above the SLA enforcement level, suddenly descend under it. The SLA gives you among a medium disk I/O speed you can foresee. That can prevent any groups particularly performance specialists who suspect stable and compatible disk throughput on a server. Common physically entertained servers perform that direction. Pragmatic AWS cases do not.
Backup EBS masses by utilizing the snap convenience through API proposal or by a GUI interface same elasticfox.
Progress execution by practising Linux software invasion and striping over four extents.
22. Which Automation Gears can Help with Spinup Services?
The API tools can be used for spinup services and also for the written scripts. Those scripts could be coded in Perl, bash or other languages of your preference. There is one more option that is patterned administration and stipulating tools such as a dummy or improved descendant. A tool called Scalr can also be used and finally, we can go with a controlled explanation like a RightScale.
23. What is an Ami? How Do I Build One?
AMI holds for Amazon Machine Image. It is efficiently a snap of the source filesystem. Products appliance servers have a bio that shows the master drive report of the initial slice on a disk. A disk form though can lie anyplace physically on a disc, so Linux can boot from an absolute position on the EBS warehouse interface.
Create a unique AMI at beginning rotating up and instance from a granted AMI. Later uniting combinations and components as needed. Comprise wary of setting delicate data over an AMI (learn salesforce online). For instance, your way credentials should be joined to an instance later spinup. Among a database, mount an external volume that carries your MySQL data next spinup actually enough.
24. What are the Main Features of Amazon Cloud Front?
Some of the main features of Amazon CloudFront are as follows: Device Detection Protocol Detection Geo Targeting Cache Behavior Cross-Origin Resource Sharing Multiple Origin Servers HTTP Cookies Query String Parameters Custom SSL.
25. What is the Relation Between an Instance and Ami?
AMI can be elaborated as Amazon Machine Image, basically, a template consisting software configuration part. For example an OS, applications, application server. If you start an instance, a duplicate of the AMI in a row as an unspoken attendant in the cloud.
26. What is Amazon Ec2 Service?
Amazon Elastic Compute Cloud (Amazon EC2) is a web service that provides resizable (scalable) computing capacity in the cloud. You can use Amazon EC2 to launch as many virtual servers you need. In Amazon EC2 you can configure security and networking as well as manage storage. Amazon EC2 service also helps in obtaining and configuring capacity using minimal friction.
27. What are the Features of the Amazon Ec2 Service?
As the Amazon EC2 service is a cloud service so it has all the cloud features. Amazon EC2 provides the following features:
The virtual computing environment (known as instances)
re-configured templates for your instances (known as Amazon Machine Images — AMIs)
Amazon Machine Images (AMIs) is a complete package that you need for your server (including the operating system and additional software)
Amazon EC2 provides various configurations of CPU, memory, storage and networking capacity for your instances (known as instance type)
Secure login information for your instances using key pairs (AWS stores the public key and you can store the private key in a secure place)
Storage volumes of temporary data are deleted when you stop or terminate your instance (known as instance store volumes)
A firewall that enables you to specify the protocols, ports, and source IP ranges that can reach your instances using security groups
Static IP addresses for dynamic cloud computing (known as Elastic IP address)
Amazon EC2 provides metadata (known as tags)
Amazon EC2 provides virtual networks that are logically isolated from the rest of the AWS cloud, and that you can optionally connect to your own network (known as virtual private clouds — VPCs)
28. What is the AWS Kinesis
Amazon Kinesis Data Streams can collect and process large streams of data records in real time. You can create data-processing applications, known as Kinesis Data Streams applications. A typical Kinesis Data Streams application reads data from a data stream as data records. These applications can use the Kinesis Client Library, and they can run on Amazon EC2 instances. You can send the processed records to dashboards, use them to generate alerts, dynamically change pricing and advertising strategies, or send data to a variety of other AWS services
29. Distinguish Between Scalability and Flexibility?
The aptitude of any scheme to enhance the tasks on hand on its present hardware resources to grip inconsistency in command is known as scalability. The capability of a scheme to augment the tasks on hand on its present and supplementary hardware property is recognized as flexibility, hence enabling the industry to convene command devoid of putting in the infrastructure at all. AWS has several configuration management solutions for AWS scalability, flexibility, availability and management.
30. What are the Different Types of Events Triggered By Amazon Cloud Front?
Different types of events triggered by Amazon CloudFront are as follows:
Viewer Request: When an end user or a client program makes an HTTP/HTTPS request to CloudFront, this event is triggered at the Edge Location closer to the end user.
Viewer Response: When a CloudFront server is ready to respond to a request, this event is triggered.
Origin Request: When CloudFront server does not have the requested object in its cache, the request is forwarded to the Origin server. At this time this event is triggered.
Origin Response: When CloudFront server at an Edge location receives the response from the Origin server, this event is triggered.
31. Explain Storage for Amazon Ec2 Instance.?
Amazon EC2 provides many data storage options for your instances. Each option has a unique combination of performance and durability. These storages can be used independently or in combination to suit your requirements.
There are mainly four types of storages provided by AWS:
Amazon EBS: Its durable, block-level storage volumes can be attached in running Amazon EC2 instance. The Amazon EBS volume persists independently from the running life of an Amazon EC2 instance. After an EBS volume is attached to an instance, you can use it like any other physical hard drive. Amazon EBS encryption feature supports encryption feature.
Amazon EC2 Instance Store: Storage disk that is attached to the host computer is referred to as instance store. The instance storage provides temporary block-level storage for Amazon EC2 instances. The data on an instance store volume persists only during the life of the associated Amazon EC2 instance; if you stop or terminate an instance, any data on instance store volumes is lost.
Amazon S3: Amazon S3 provides access to reliable and inexpensive data storage infrastructure. It is designed to make web-scale computing easier by enabling you to store and retrieve any amount of data, at any time, from within Amazon EC2 or anywhere on the web.
Adding Storage: Every time you launch an instance from an AMI, a root storage device is created for that instance. The root storage device contains all the information necessary to boot the instance. You can specify storage volumes in addition to the root device volume when you create an AMI or launch an instance using block device mapping.
32. What are the Security Best Practices for Amazon Ec2?
There are several best practices for secure Amazon EC2. Following are a few of them.
Use AWS Identity and Access Management (AM) to control access to your AWS resources.
Restrict access by only allowing trusted hosts or networks to access ports on your instance.
Review the rules in your security groups regularly, and ensure that you apply the principle of least
Privilege — only open up permissions that you require.
Disable password-based logins for instances launched from your AMI. Passwords can be found or cracked, and are a security risk.
33. Explain Stopping, Starting, and Terminating an Amazon Ec2 Instance?
Stopping and Starting an instance: When an instance is stopped, the instance performs a normal shutdown and then transitions to a stopped state. All of its Amazon EBS volumes remain attached, and you can start the instance again at a later time. You are not charged for additional instance hours while the instance is in a stopped state.
Terminating an instance: When an instance is terminated, the instance performs a normal shutdown, then the attached Amazon EBS volumes are deleted unless the volume’s deleteOnTermination attribute is set to false. The instance itself is also deleted, and you can’t start the instance again at a later time.
34. What is S3? What is it used for? Should Encryption be Used?
S3 implies for Simple Storage Service. You can believe it similar ftp warehouse, wherever you can transfer records to and from beyond, merely not uprise it similar to a filesystem. AWS automatically places your snaps there, at the same time AMIs there. sensitive data is treated with Encryption, as S3 is an exclusive technology promoted by Amazon themselves, and as still unproven vis-a-vis a protection viewpoint.
35. What is AWS Cloud Search
Amazon CloudSearch is a managed service in the AWS Cloud that makes it simple and cost-effective to set up, manage, and scale a search solution for your website or application.
Amazon CloudSearch supports 34 languages and popular search features such as highlighting, autocomplete, and geospatial search
36. What is Qlik Sense Charts?
Qlik Sense Charts is another software as a service (SaaS) offering from Qlik which allows Qlik Sense visualizations to be easily shared on websites and social media. Charts have limited interaction and allow users to explore and discover.
37. Define Auto Scaling?
Answer: Auto-scaling is one of the conspicuous characteristics feature of AWS anywhere it authorizes you to systematize and robotically obligation and twist up new models externally that necessary for your entanglement. This can be accomplished by initiating brims and metrics to view. If these proposals are demolished, the latest model of your preference will be configured, wrapped up and cloned into the weight administrator panel.
38. Which Automation Gears can Help with Spinup Services?
For the written scripts we can use spinup services with the help of API tools. These scripts could be coded in bash, Perl, or any another language of your choice. There is one more alternative that is patterned control and stipulating devices before-mentioned as a dummy or advanced descendant. A machine termed as Scalar can likewise be utilized and ultimately we can proceed with a constrained expression like a RightScale.
39. Explain what EC2 Instance Metadata is. How does an EC2 instance get its IAM access key and Secret key?
EC2 instance metadata is a service accessible from within EC2 instances, which allows querying or managing data about a given running instance.
It is possible to retrieve an instance’s IAM access key by accessing the iam/security-credentials/role-name metadata category. This returns a temporary set of credentials that the EC2 instance automatically uses for communicating with AWS services.
40. What is AWS snowball?
Snowball is a petabyte-scale data transport solution that uses devices designed to be secure to transfer large amounts of data into and out of the AWS Cloud. Using Snowball addresses common challenges with large-scale data transfers including high network costs, long transfer times, and security concerns. Customers today use Snowball to migrate analytics data, genomics data, video libraries, image repositories, backups, and to archive part of data center shutdowns, tape replacement or application migration projects. Transferring data with Snowball is simple, fast, more secure, and can be as little as one-fifth the cost of transferring data via high-speed Internet.
41. Explain in Detail the Function of Amazon Machine Image (AMI)?
An Amazon Machine Image AMI is a pattern that comprises a software conformation (for instance, an operating system, a request server, and applications). From an AMI, we present an example, which is a duplicate of the AMI successively as a virtual server in the cloud. We can even offer plentiful examples of an AMI.
42. If I’m expending Amazon Cloud Front, can I custom Direct Connect to handover objects from my own data center?
Certainly. Amazon Cloud Front stipulations culture rises computing sources of separate AWS. By AWS Direct Connect, you will be accelerating with the appropriate information substitution rates. AWS Training Free Demo
43. If My AWS Direct Connect flops, will I lose my Connection?
If a gridlock AWS Direct connects has been transposed, in the event of a let-down, it will convert over to the next one. It is voluntary to allow Bidirectional Forwarding Detection (BFD) while systematizing your rules to safeguard quicker identification and failover. Proceeding the opposite hand, if you have built a backup IPsec VPN connecting as an option, all VPC transactions will failover to the backup VPN association routinely.
44. What is AWS Certificate Manager?
AWS Certificate Manager (ACM) manages the complexity of extending, provisioning, and regulating certificates granted over ACM (ACM Certificates) to your AWS-based websites and forms. You work ACM to petition and maintain the certificate and later practice other AWS services to provision the ACM Certificate for your website or purpose. As designated in the subsequent instance, ACM Certificates are currently ready for performance with only Elastic Load Balancing and Amazon CloudFront. You cannot handle ACM Certificates outside of AWS.
45. Explain What is Redshift?
The executes it easy and cost-effective to efficiently investigate all your data employing your current marketing intelligence devices which is a completely controlled, high-speed, it is petabyte-scale data repository service known as Redshift.
46. Mention What are the Differences Between Amazon S3 and EC2?
S3: Amazon S3 is simply a storage aid, typically applied to save huge binary records. Amazon too has additional warehouse and database settings, same as RDS to relational databases and DynamoDB concerning NoSQL.
EC2: An EC2 instance is similar to a foreign computer working Linux or Windows and on which you can install whatever software you need, including a Network server operating PHP code and a database server.
47. Explain What is C4 Instances?
C4 instances are absolute for compute-bound purposes that serve from powerful-performance processors. AWS Interview Questions and Answers
48. Explain What is DynamoDB in AWS?
Amazon DynamoDB is a completely controlled NoSQL database aid that renders quick and anticipated execution with seamless scalability. You can perform Amazon DynamoDB to formulate a database table that can save and reclaim any quantity of data, and help any level of application transactions. Amazon DynamoDB automatically increases the data and transactions for the table above an adequate number of servers to supervise the inquiry function designated by the customer and the volume of data saved, while keeping constant and quick execution.
49. Explain What is ElastiCache?
A web service that executes it comfortable to set up, maintain, and scale classified in-memory cache settings in the cloud is known as ElastiCache.
50. What is the AWS Key Management Service?
A managed service that makes it easy for you to create and control the encryption keys used to encrypt your data is known as the AWS Key Management Service (AWS KMS).
Summary
The above questions will provide you with a fair idea of how to get ready for an AWS interview. You are required to have all the concepts relating to AWS in your fingertips to crack the interview with ease. These questions and Answers will boost your confidence level in attending the interviews.

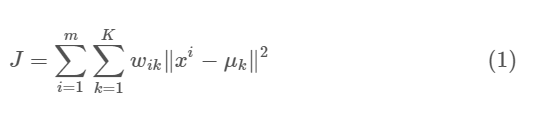






;" src="https://dimensionless.in/how-to-visualize-aws-cost-and-usage-data-using-amazon-athena-and-quicksight/embed/#?secret=2MIISNr341" data-secret="2MIISNr341" width="600" height="338" title="“How to Visualize AWS Cost and Usage Data Using Amazon Athena and QuickSight” — DIMENSIONLESS TECHNOLOGIES PVT.LTD." frameborder="0" marginwidth="0" marginheight="0" scrolling="no"></iframe>)
;" src="https://dimensionless.in/how-to-discover-and-classify-metadata-using-apache-atlas-on-amazon-emr/embed/#?secret=uQZUBd9j4w" data-secret="uQZUBd9j4w" width="600" height="338" title="“How to Discover and Classify Metadata using Apache Atlas on Amazon EMR” — DIMENSIONLESS TECHNOLOGIES PVT.LTD." frameborder="0" marginwidth="0" marginheight="0" scrolling="no"></iframe>)