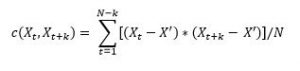Data science is a rapidly growing career path in the 21 century. The leaders across all industries, fields, and governments are putting their best minds to the task of harnessing the power of data.
As organizations seek to derive greater insights and to present their findings with greater clarity, the premium placed on high-quality data visualization will only continue to increase.
What are Data Visualisation tools?
Data visualization is a general term that describes an effort to help people understand the significance of data by placing it in a visual context. Patterns, trends and correlations that might go undetected in text-based data can be exposed and recognized easier with data visualization software.
Furthermore, today’s data visualization tools go beyond the standard charts and graphs used in Microsoft Excel spreadsheets, displaying data in more sophisticated ways such as infographics, dials and gauges, geographic maps, sparklines, heat maps, and detailed bar, pie and fever charts.
What is Tableau?
Tableau is a powerful and fastest growing data visualization tool used in the Business Intelligence Industry. It helps in simplifying raw data into the very easily understandable format.
Also, data analysis is very fast with Tableau and the visualizations created are in the form of dashboards and worksheets. The data that is created using Tableau can be understood by professional at any level in an organization. Furthermore, It even allows a non-technical user to create a customized dashboard.
Why Tableau?
1. Tableau makes interacting with your data easy
Tableau is a very effective tool to create interactive data visualizations very quickly. It is very simple and user-friendly. Tableau can create complex graphs giving a similar feel as the pivot table graphs in Excel. Moreover, it can handle a lot more data and quickly provide calculations on datasets.
2. Extensive Data analytics
Tableau allows the user to plot varied graphs which can help in making detailed data visualisations. There are 21 different types of graph among which users can mix match and dish out appealing and informative visualisations. From heat maps, pie chart and bar charts to bubbe graph, Gantt chart and bullet graphs, Tableau has way more lot of visualisations to offer than other data visualisations tool out there
3. Easy Data discovery
Tableau is capable of handling large datasets really well. Handling large dataset is one problem where tools like MS Excel and even R shiny fails to generate visualisation dashboards. Ability to handle such large chunks of data empowers tableau to generate insights out of it. This, in turn, allows users to find patterns and trends in their data. Furthermore, tableau can be connected to multiple data sources be it different cloud providers or databases or data warehouses.
4. No Coding
The one great thing about tableau is that you do not need to code at all to generate powerful and meaningful visualisations. It is all a game of selecting a chart and drag and drop! Being user-friendly allows the user to focus more on visualisations and storytelling through it rather than handling all the coding aspects around it.
5. Huge Community
Tableau boasts of a large user community which works for solving doubts and problems faced while using Tableau. Having such large community support helps users to find answers to their queries and issues faced while using Tableau. One does not need to worry about having less learning material too.
6. Proved to have satisfied customers
Tableau users are genuinely happy with the product. For example, the yearly Gartner research about Business Intelligence and Analytics Platforms, based on the user feedback, indicates Tableau´s success and ability to deliver a genuinely user-friendly solution for the customers. We have noticed the same enthusiasm and positive feedback about Tableau among our customers.
7. Mobile support
Tableau provides mobile support for the dashboards. So you do not need to confine to just desktop and laptops but can develop visualisations on the fly using Tableau
Tableau in fortune 500 companies
LinkedIn
LinkedIn has over 460 million users. The business analytics team of LinkedIn’s salesforce is massively using Tableau to process petabytes of customer data. They access Tableau server on a weekly basis by 90% of LinkedIn’s salesforce. Furthermore, sales analytics can measure performance and gauge the churn using Tableau dashboards. Higher revenue, therefore, results due to a more proactive sales cycle. Michael Li, Senior Director of Business Analytics at LinkedIn believes that LinkedIn’s analytics portal is the go-to destination for salespeople to get what they require to convey that information that is exactly required by the clients.
Cisco
Cisco uses Tableau software to work with 14,000 items to evaluate Product Demand Variability, match distribution centres with customers, depict the flow of goods through the supply chain network, assess the location and spend within the supply chain. Tableau strikes a balance of a sophisticated network of suppliers to the end customer. This looks after inventory and reduces order-to-ship cycle. Also, Cisco uses Tableau server to spread the content gracefully. It helps to create the right message, streamline the data, drive the conception and also in the scaling of data.
Deloitte
Deloitte uses Tableau to help customers implement self-reliant data-driven culture which is also agile which can garner high business value from enterprise data. Higher signal detection abilities and real-time interactive dashboards are available to an enterprise by Deloitte that allow their clients to assess huge complex datasets with high efficiency and greater ease of use. Furthermore, there are more than 5000 Deloitte employees who are trained in Tableau and are successfully delivering high-end projects.
Walmart
Walmart considers it was a good move shifting to rich vivid visualizations that can be modified in real time and shared easily from Excel sheets. Furthermore, they found that people responded better when there is more creativity, the presentation would turn to be good, and executives receive it better. Rather than a datasheet, Tableau is used to convey data story more effectively. Also, they had built dashboards which could be accessible to the entire organization. Over 5000 systems have Tableau desktop in Walmart and it is doing great with this BI tool.
Conclusion
After reading this list we hope you are ready to conquer the world of data with Tableau. To help you to just do it, we offer data science courses including Tableau. Also, you can view the course here.
Additionally, if you are interested in learning Big Data and NLP, click here to get started
Furthermore, if you want to read more about data science, you can read our blogs here
Also, the following are some suggested blogs you may like to read
Loosely speaking, a time series describes the behavior of a variable with time. For example a company’s daily closing stock prices. Our major interest lies in forecasting this variable or the stock price in our case in the future. We try to develop various statistical and machine learning models to fit the data, capture the patterns and forecast the variable well in the future.
In this article, we will try traditional models like ARIMA, popular machine learning algorithms like Random Forest and deep learning algorithms like LSTM.
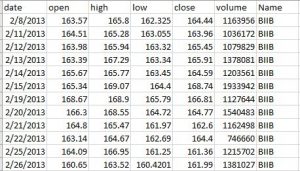
Tutorial link (you can download the data from this repository)
Before we actually dive into the model, let’s see if the data is in it’s the best form for our model.
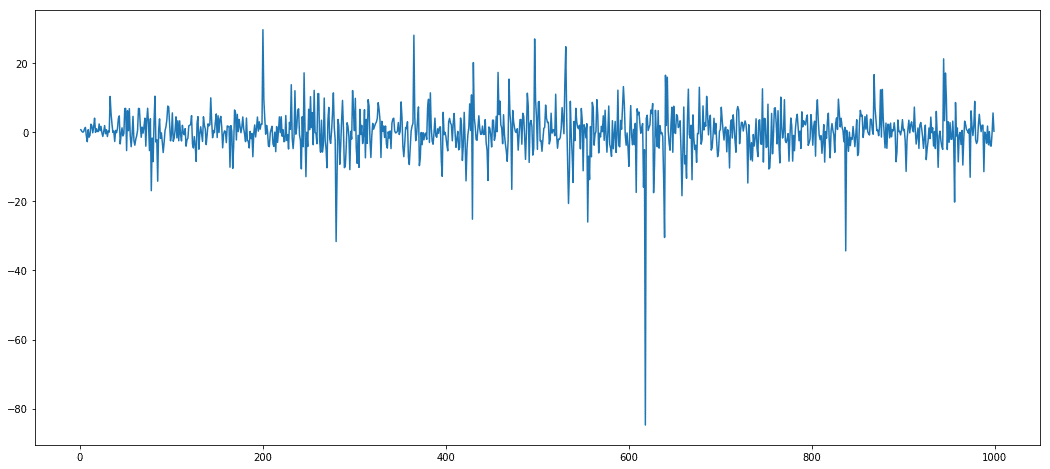
Clearly, we see there is an upwards trend. When we analyze a time series, we want it to be stationary, meaning the mean and variance should be constant along the time series. Why? This is because it is useful to analyze such a series from a statistical point of view. Like in our case, usually there exists a trend. To make a time series stationary, a common way is to difference it
I.e. a series having [a,b,c,d] is transformed to [b-a,c-b,d-c].
A differenced time series looks something like this –
The mean and variance looks almost constant, except for a few outliers. Such a differenced time series is suitable for modelling.
OK! We know something about how our data should look like. But what exactly is ARIMA?
Let’s break it down into 3 terms
AR – This term indicates the number of auto-regressive terms (p) in the model. Intuitively, it denotes the number of previous time steps the current value of our variable depends on. For example, at time T, our variable Xt depends on Xt-1 and Xt-2, linearly. In this case, we have 2 AR terms and hence our p parameter=2
I – As stated earlier, to make our time series stationary, we have to difference it. Depending on the data, we difference it once or multiple times (usually once or twice). The number of times we do it is denoted by d.
MA – This term is a measure of the average over multiple time periods we take into account. For example, to calculate the value of our variable at the current time step, if we take an average over previous 2 timesteps, the number of MA terms, denoted by q=2
Specifying the parameters (p,d,q) will specify our model completely. But how do we select these parameters?
We use something called ACF (Autocorrelation plot) and PACF(Partial autocorrelation plot) for this purpose. Let’s get an intuition of what autocorrelation and partial autocorrelation mean.
We know that for 2 variables X and Y, correlation denotes how the two variables behave with each other. Highly positive correlation denotes that X increases with Y. Highly negative correlation denotes that X decreases with Y. So what is autocorrelation?
In a time series, it denotes the variance of the predicted variable at a particular time step with its previous time steps. Mathematically,
Where X’ is the mean, k is the lag (number of time steps we look back. k=1 means t-1), N is the total number of points. C is the autocovariance. For a stationary time series, c does not depend on t. It only depends on k or the lag.
Partial autocorrelation is a bit tricky concept. Just get an intuition for now. Consider an example – We have the following data – body fat level (F), triceps measurement (Tr) and thigh circumference (Th). We want to measure the correlation between F and Tr but we also don’t want thigh circumference or Th to play any role. So what do we do? We try to remove linearity from F and Tr introduced by Th. Let F’ be the fat levels predicted by Th, linearly. Similarly, let Tr’ be triceps measurement as predicted by Th, linearly.
The residuals for fat levels is given by F-F’ and for tricep measurement is given by Tr-Tr’. Partial correlation is the correlation measured between these residuals.
In our case the
Next, we answer two important questions
What suggests AR terms in a model?
ACF shows a decay
PACF cuts off quickly
What suggests MA terms in a model?
ACF cuts off sharply
PACF decays gradually
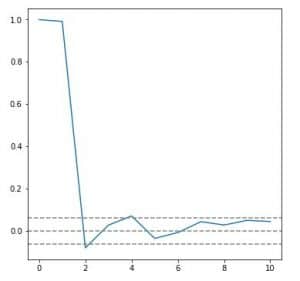
In our case, the ACF looks something like
From lag 0 it decays gradually. The top and bottom grey dashed lines show the significance level. Between these levels, the autocorrelation is attributed to noise and not some actual relation. Therefore q=0
PACF looks like
It cuts off quickly, unlike the gradual decay in ACF. Lag 1 is significantly high, indicating the presence of 1 AR term. Therefore p=1.
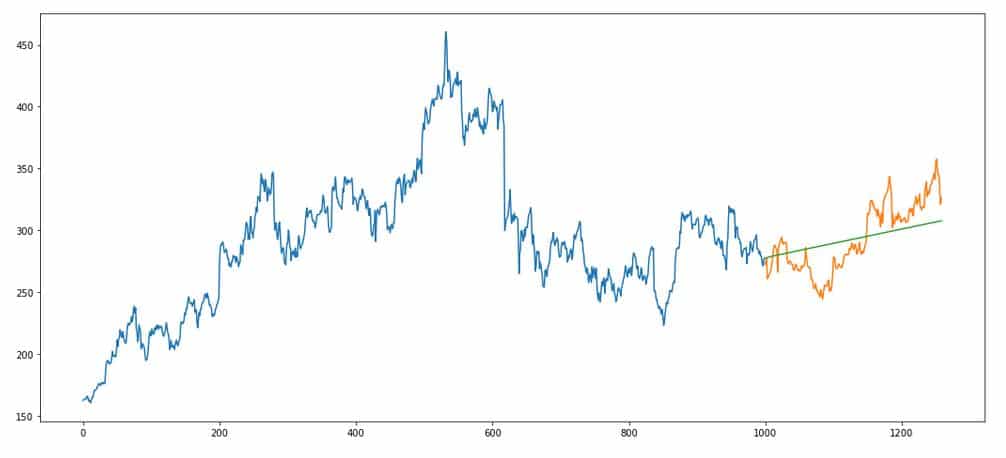
So now we have specified our model. Let’s fir our ARIMA(p=1,d=1,q=0) model. Follow the tutorial to implement the model. Results look something like –
Blue portion is the data on which the model is fitted. Orange is the holdout/validation set. Green is our model’s performance. Note that we only need the predicted variable for ARIMA. Nothing else.
The mean squared error for our model turns out to be 439.38.
Machine and Deep learning algorithms
To see if machine learning and deep learning algorithms work well on our data, we test two algorithms – Random Forest and LSTM. The data is the same except for that we use all the features and not just the predicted variable. We do some basic feature engineering like extracting the month, day and year.
Deep Learning Model – LSTM
LSTM or long short-term memory network is a variation of the standard vanilla RNN (Recurrerent Neural Networks). RNNs, many times tend to suffer through a problem of vanishing/exploding gradients. This means that the gradient values become too large or too small, causing problems in updating the weights of RNN. LSTMs are improvised versions of RNN that solve this problem through the use of gates. For a detailed explanation, I highly recommend this video – https://youtu.be/8HyCNIVRbSU
In our case, we use Keras framework to train an LSTM.
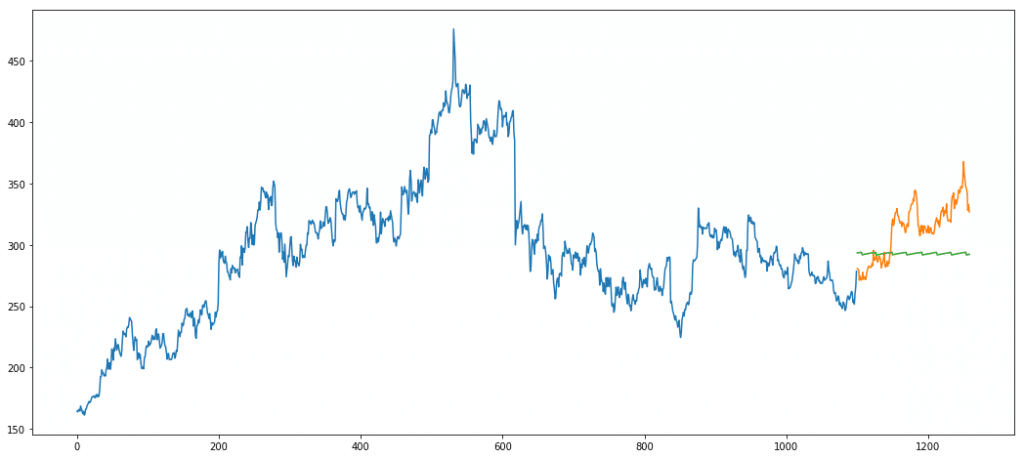
Error = 895.06
As we can see, LSTM performs really poorly on our data. Main reason is the lack of data. We train only on 1000 data points. This is really less for a deep neural network. This is a classic example where neural nets don’t always outperform traditional algorithms.
Random Forest
Random forest is a tree bases supervised machine learning algorithm. It builds short weak tree learners by randomly sampling features to split the data on. This ensures features getting adequate representation in the model unlike the greedy approach classical decision trees take.
Suppose we train 10 trees. For a data point, each tree outputs its own y value. In a regression problem the average of these 10 trees is taken as the final value for the data point. In classification, majority vote is the final call.
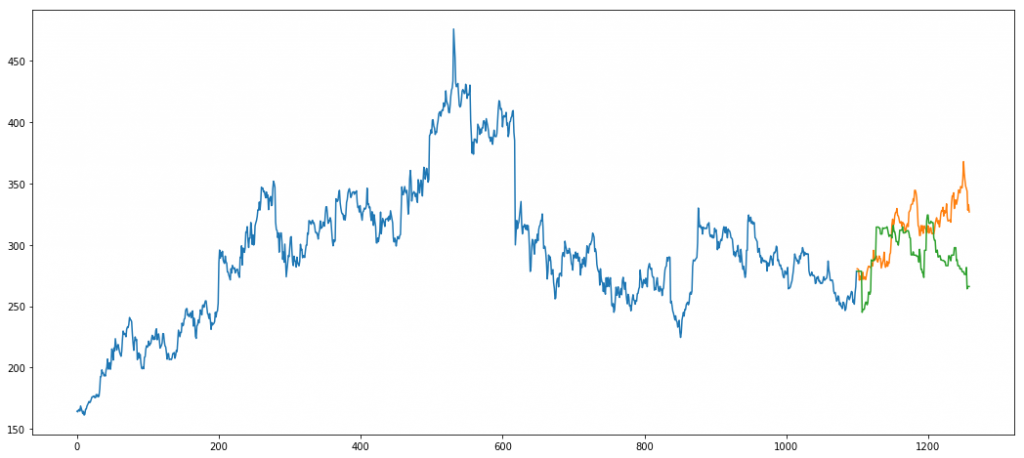
Using grid search we set the appropriate parameters. Our final predictions look something like
Error = 1157.91
If you notice carefully, our holdout set does not follow the peaks that our train set follows. The model fails to predict the same as it has learned to predict peaks like the ones in blue. Such an unexpected shift in trend is not captured by models.
Are you from a computer science background and moving into data science? Are you planning to learn coding being from a non-programming background in data science? Then you need not worry because in this blog we will be talking about the importance of computer science in the data science world. Furthermore, we will also be looking at why is it necessary to be fluent with coding(basic at least) in the data science world.
Before enumerating the role of computer science in the data science world, let us clear our understanding of the above two terms. This will allow us to be on the same page before we reason out the importance of coding in data science.
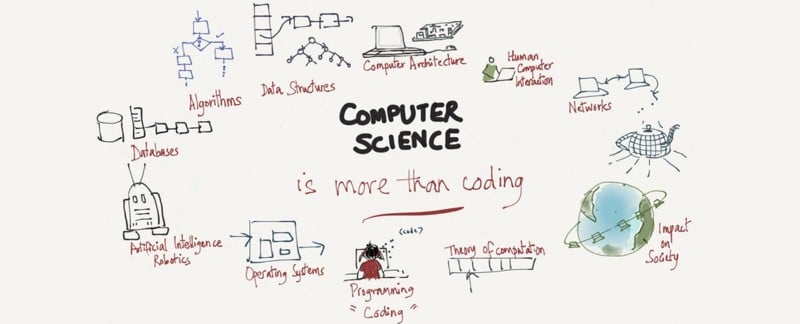
What is Computer Science
Computer Science is the study of computers and computational systems. Unlike electrical and computer engineers, computer scientists deal mostly with software and software systems; this includes their theory, design, development, and application.
Principal areas of study within Computer Science include artificial intelligence, computer systems, and networks, security, database systems, human-computer interaction, vision and graphics, numerical analysis, programming languages, software engineering, bioinformatics and theory of computing.
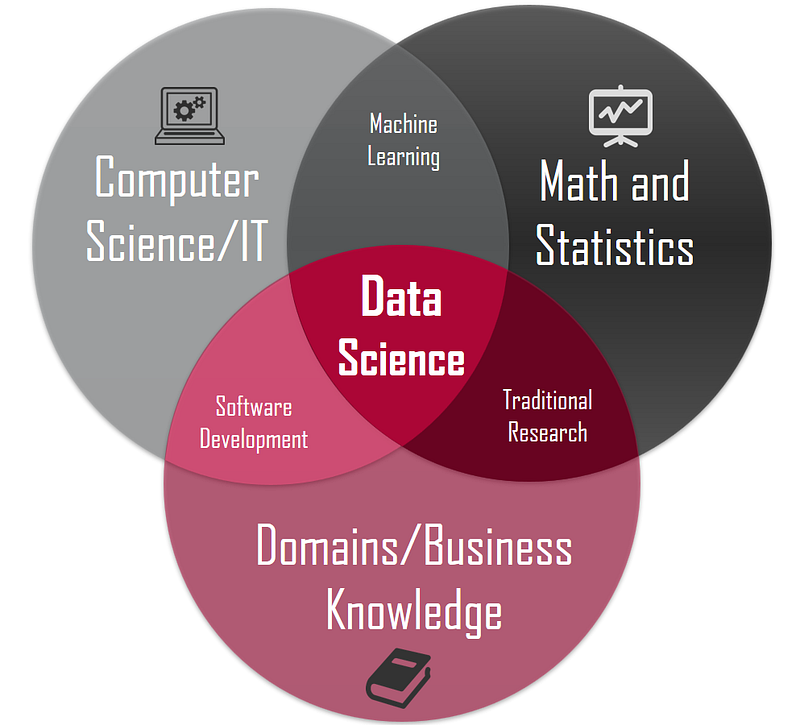
What is Data Science
Data science is the umbrella under which all these terminologies take the shelter. Data science is a like a complete subject which has different stages within itself. Suppose a retailer wants to forecast the sales of an X item present in its inventory in the coming month. This is known as a business problem and data science aims to provide optimized solutions for the same.
Data science enables us to solve this business problem with a series of well-defined steps.
1: Collecting data 2: Pre-processing data 3: Analysing data 4: Driving insights and generating BI reports 5: Taking decision based on insights
Generally, these are the steps we mostly follow to solve a business problem. All the terminologies related to data science falls under different steps which we are going to understand just in a while. Different terminologies fall under different steps listed above.
Data science as you can see is an amalgamation of Business, maths and computer science. A computer engineer is familiar with the entire CS aspect of it and much of maths sections is also covered. Hence, there is no denying fact that Computer science engineers will have a little advantage while beginning their career as data scientists.
Application of computer science in data science
After understanding the difference between Computer Science and Data Science, we will look at the areas in data science where computer science is employed
Data Collection (Big data and data engineering)
Computer science gives you an edge in understanding and working hands-on with aspects of BIG Data. Big data works mainly on important concepts like map-reduce, master-slave concepts etc. These concepts are something by which most of the computer engineers are aware of. Hence, familiarity with these concepts enables a head start in learning these technologies and using them effectively for the complex cases.
Data Pre-Processing (Cleaning, SQL)
Data extraction involves heavy usage of SQL in data sciences. SQL is one of a primary skill in data sciences. SQL is something which is never an alien term to Computer Engineers as most of them are/should be adept in it. Computer science engineers are taught the databases and their management in and out and hence knowledge of SQL is elementary to them.
Analysis(EDA etc)
For data analysis, knowledge of one of the programming language (R or Python mostly)is elementary. Being proficient in one of these languages grants the learner an ability to quickly get started with complex ETL operations. Additionally, the ability to understand and implement code quickly can enable you to go one extra mile while doing your analysis. Also, it reduces your time spent on such tasks as one is already through all the basic concepts.
Insights( Machine Learning/Deep Learning)
Computer scientists invented the name machine learning, and it’s part of computer science, so in that sense, it’s 100% computer science. Furthermore, computer scientists view machine learning as “algorithms for making good predictions.” Unlike statisticians, computer scientists are interested in the efficiency of the algorithms and often blur the distinction between the model and how the model is fit. Additionally, they are not too interested in how we got the data or in models as representations of some underlying truth. For them, machine learning is black boxes making predictions. And computer science has, for the most part, dominated statistics when it comes to making good predictions.
Visual Reports(Visualisations)
Visualizations are an important aspect of data science. Although Data science has multiple tools available for visualization, complex representation requires that extra coding effort. Complex enhancements in visualizations may require some technical aspect of changing few extra parameters of the base library or even the framework you are working with.
Pros of Computer Science knowledge in Data Science
Headstart with all technical aspect of data science
Ability to design, scale and optimise technical solutions
Interpreting algorithm/tool behaviour for different business use cases
Bringing a fresh perspective of looking at a business problem
Proficiency with most of the hands-on coding work
Cons of Computer Science knowledge in Data Science
May end up with a fixed mindset of doing things the “Computer Science” way.
You have to catch up with a lot of business knowledge and applications
Need to pay greater attention to maths and statistics as they are vital aspects of data science
Conclusion
In this blog, we had a look at the various application of computer science in the data science industry. No wonder that because of multiple applications of computer science in the data science industry, computer engineers find it easy, to begin with. Also, at no point in time, we imply that only computer science graduates can excel in the data science domain. Although, being a bachelor in computer science has its own perils in the science field. But, it also comes with its own set of disadvantages like lack of business knowledge and statistics. Anyone can excel in data science who can master all three aspects of it regardless of their bachelor degrees. All you need is right guidance outside and motivation within. Additionally, we at Dimensionless Technologies, provide hands-on training on Data Science, Big Data and NLP. You can check our courses here.
Furthermore, for more blogs on data science, visit our blog section here.
Also, you may also want to have a look at some of our previous blogs below.
All the best dataset, Artificial Intelligence, Machine Learning, and Business Intelligence tools are useless without effective visualization capabilities. In the end, data science is all about presentation, Whether you are a chief data scientist at Google or an all-in-one ‘many-hats’ data scientist at a start-up, you still have to show the results of your algorithm to a management executive for approval. We have all heard the adage, “a picture is worth a thousand words”. I would rephrase that for data science as “An effective infographic is worth an infinite amount of data”. Because even if you present the most amazing algorithms and statistics in the universe to your management, they will be unable to comprehend it. But present even a simple infographic – and everyone in the boardroom, from the CEO to your personnel manager, will be able to understand what your findings mean for your business enterprise.
Tools for Visualization
Because of the fundamental truth stated above, there are a ton of data visualization tools out there for the needs of every data scientist on the planet. There is a wide variety available. From premium and power-user based, to products from giants like Microsoft and Google, to free offerings for developers like Plot.ly across multiple languages and bokeh for Python developers, to DataWrapper for non-technical users. So I have picked five tools that vary widely but are all very effective and worth learning in depth. So let’s get started!
Tableau Sample Email Marketing ReportTableau is the market leader for visualization as far as data science is concerned. The statistics speak for themselves. Over 32,000 companies use Tableau around the world and this tool is by far the most popular choice among top companies like Facebook and Amazon. What is more, once you learn Tableau, you will know visualization well enough to handle every other tool in the market. This tool is the most popular, the most powerful, and yet surprisingly intuitive to use. If you wanted to learn one single tool for data science, this is It.
Qlikview is another solution like Tableau that requires payment for a commercial user, yet it is so powerful that I couldn’t help but include it in my article. This tool is situated more for the power-user and the well-experienced data scientists. While not as intuitive as Tableau, this tool boasts of powerful features that can be used by large-scale users. This is a very powerful choice for many companies all over the world.
Unlike the first two tools, Microsoft Power BI (Business Intelligence) is completely free to use and download. It integrates beautifully with Microsoft tools. If you’re on Microsoft Azure as a cloud computing solution, you will enjoy this tool’s seamless integration with Microsoft products. Contrary to popular business ethos at Microsoft, this tool is both free to download (full-featured) and free to use, even the Desktop version. If you use Microsoft tools, then this could be a solution that fits you well. (Although Tableau is the tool used the most by software companies).
This tool is strictly cloud-based and its highest USP is that it tightly integrates with the Google Internet Website Ecosystem. In fact, it is better that the solution be cloud-based and not on your desktop since a copy on your desktop would have to be continually resynchronized, whereas a cloud solution manages all requirements as required with the latest Internet datasets, refreshed every time you load the page. Nearly every single tool you need is at your fingertips, and this is one way to learn the Google-based way to manage your website or company. And did I mention – like Microsoft Power BI, it is completely free of cost! But again, Tableau is still the preferred solution for mainstream software companies.
This is by far the most user-friendly visualization tool for data science available on the Internet today. And while I was skeptical, this tool can be used by completely non-technical users. And the version I used was free up to to a massive 10,000 chart views. So if you want to create a visualization and don’t have technical skills in coding or Python, this may be your best way to get started. In case you’re feeling skeptical (as I was), visit the website above and view the instructions video (100 seconds – less than 2 minutes). If you are a beginner to data visualization, this is where to go first.
This is an article on visualization and communicating concepts and analysis through graphics, so it would not be complete without this free gallery of samples at www.informationisbeautiful.net. What do we plan to communicate but information? Information is processed data. Data scientists deal with data but produce as output information. This website has opened my eyes as to how data can be presented effectively. While this is not something you would use for an industrial report, do visit the site for inspiration for ways to make your data visualization more good-looking. If you have business transformational data, it requires the best presentation available. This is a post for five data visualization tools, but consider this sixth one as a bonus for inspiration and all the times you wished your dashboard or charts could be more effective graphically.
Conclusion
While there is a ton of information out there, choose tools that cater to your domain. If you are a large scale enterprise, Tableau could be your best option. If you are a student or want a high-quality free solution, go for DataWrapper. QlikView can be used by companies who want to save on their budget and have plenty of experienced professionals (although this is also a use-case for Tableau). For convenient tools, you can’t go wrong with Microsoft Power BI if your company uses Microsoft ecosystem and Google Data Studio is you are integrated into the Google ecosystem instead. Finally, if you are a student of data visualization or just want to improve your data presentation, please visit informationisbeautiful.net. Trust me, it will be an eye-opener.
Finally, Tableau is what you need to learn to be a true data science professional, especially in FAMGA (Facebook, Apple, Microsoft, Google, and Amazon).
Also, remember to enjoy your work. This adds a fun element to your current job and ensures against burnout and other such problems. This is, in the end, artistry. Even if you are into coding. All the best!
For more on Data Visualization, I strongly recommend the articles below:
As more businesses look to data-driven technologies like automation and AI, the need for talented workers who can interpret the data is only expected to rise. In fact, IBM predicts that the demand for data scientists will soar 28% by 2020. Due to high demand and lucrative offers, many people are already shifting their career choice towards data science, hence data science live classes are becoming popular.
Are you among those preparing for data science jobs? If you are, you might have also faced a dilemma of either go for self-learning or take up a live course online. In this blog, we will be talking on differences between self-learning and live courses. Furthermore, we will also be looking at why taking a course can be a wiser choice.
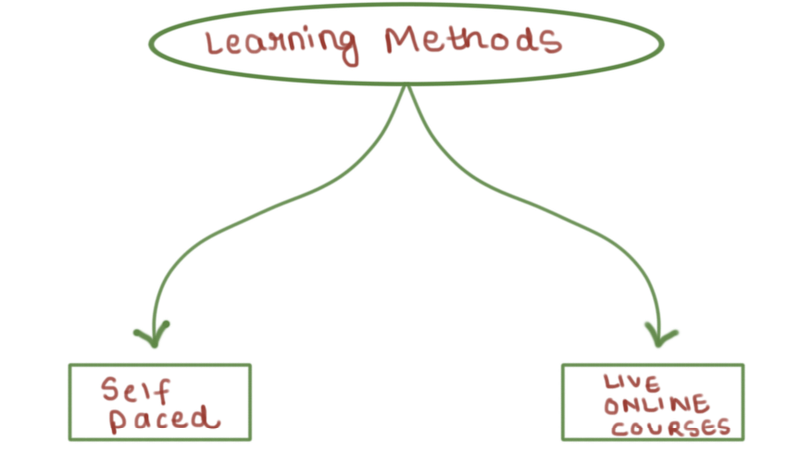
Learning Methodologies
With the advent of advanced communicational technology and more diverse content consumption media, training and learning have become easier than ever. Practical training has experienced perhaps the greatest leap forward
Self Paced
With self-paced learning you can make your own decisions instead of completing a specific data science course within a certain amount of time, learners are able to learn concepts within the time that is needed for them. Each participant can decide what time is needed to complete a given course.
Advantages can be like no time pressure, no need for a schedule, suitable to people with different learning styles
Instructor-Led Online Courses
This type of training is facilitated by an instructor either online or in a classroom setting. Instructor-led training allows for learners and instructors or facilitators to interact and discuss the training material, either individually or in a group setting. Online instructor-led training is known as virtual instructor-led training or VILT.
Advantages can be easier to adapt, more social and easier to enforce capabilities
You can also have a look at topmost skills to become a data scientist here
Challenges in learning data science
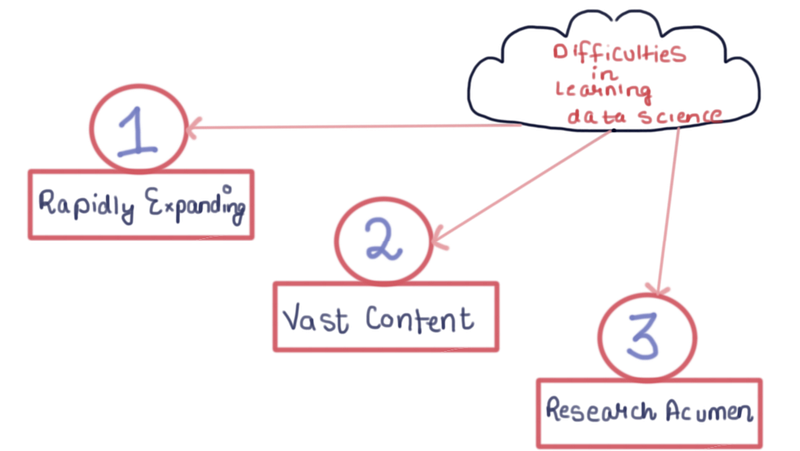
Data science is not an easy nut to crack. It is difficult to master regardless of your professional experience. You may face a lot of difficulties while learning data science when starting your career. Let us list some reasons and understand why actually data science is a little tougher to learn
A vast content to learn
Data science consists of a large number of concepts and fields. Few examples can be problem definition to data fetching, cleaning, featuring, modeling, visualization and what not. It is impossible to learn all the things at once. This case gets even trickier when you realize that all the separate fields are important and can not be omitted. To be a good data scientist, one has to learn all the things like maths and statistics, machine learning, programming languages, communication, and analytical skills etc. Becoming a data scientist is not a short-term process. It demands years of efforts and diligence.
Rapidly expanding and dynamic field
Data science is relatively new and a major chunk of it is still under research. There have been advancements happening in data science all around the globe. With such fast advancements, it is difficult to catch up to the latest concepts in data sciences. Algorithms are evolving, visualizations are getting smarter, the problem-solving methodology is also under constant development. There are high chances of other frameworks or techniques rolling out by the time you finish with one. Hence, it is a little difficult to learn data science and catch up with all the advancements in short duration. Although basics are nowhere to go, you will need much more than that to tackle real-world problems.
Research Acumen
Data sciences demand research acumen from learners. Data science is more about researching new techniques and methodologies to enhance solutions for real-world problems. Learners should not only be skilled at using available techniques but should also be able to creatively suggest new ones. Furthermore, these tasks get more complex when you are still in a learning stage. Only be able to use available techniques will make you a business analyst rather than a data scientist.
Why Data Science live learning?
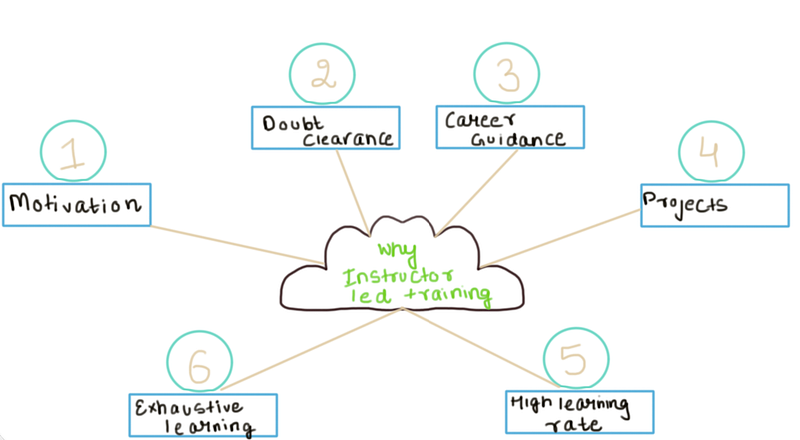
Learning data science comes along with its own set of challenges. It becomes practically very difficult to handle above-mentioned challenges alongside learning. A self-paced approach is a little less capable of handling the high learning curve in data science. What do we do then? We have to look at instructor based mode of learning. In this section, we will be looking at reasons why we should go for an instructor based online learning for data science
Easy to maintain motivation
One problem with the self-paced learning program is keeping the motivation high throughout the learning. Learners tend to burn out eventually and it happens even faster when learning is exponential. Motivation is the prime fuel which powers self-paced learning. Without motivation, self-paced learning cannot happen. This the reason why you need an instructor based method. It keeps your schedule and learning under constant check. Furthermore, it also reduces the chances of lagging behind in terms of your pre-defined targets.
Doubts clearance
One of the most important reasons to opt for the instructor-led method is getting the daily doubts cleared. Getting doubts cleared on time is important for higher learning rate. If doubts are not cleared, you won’t be able to move ahead even with all your study material.
Career guidance and assistance
Apart from regular learning schedules, you can also get career advice and guidance from your instructors. Data science opportunity is the only reason that you are learning data science in the first place. With industry experience and contacts, instructors can impart valuable guidance to the learners about their career.
You can also look at data science interview questions here.
Knowing what to learn
Keeping the motivation to learn is one thing and knowing what to learn is other. Data science is a very vast field. One just can not learn all of it at once because it is too big to explore. Instructor-led programs help learners identify the correct topics to study and in the right order. Instructor-led data science programs can help learners focus more on basics and getting them right. Learning advanced topics early can lead to a terrible mixture a bland basics curry and undercooked advanced concepts.
You can have a look at our comprehensive data science course and syllabus here
Real-time projects
Data science projects offer you a promising way to kick-start your career in this field. Not only do you get to learn data science by applying it, but you also get projects to showcase on your CV! Nowadays, recruiters evaluate a candidate’s potential by his/her work and don’t put a lot of emphasis on certifications. It wouldn’t matter if you just tell them how much you know if you have nothing to show them! That’s where most people struggle and miss out. Instructor based data science courses provide you with the opportunity for hands-on industry projects. Learnings while doing a project are immense and can not be matched with any tutorial.
Looking for some good data science projects? You might want to check them out here
High Knowledge intake
Instructor-led courses enable learners to digest concepts at a faster rate. Although a bit more effort has to be put in as compared to self-paced courses, results are much better. You end up learning more and in less time. This result is more important when you are learning something like data science as there is a lot to learn.
Conclusion
Both methods have distinct pros and cons, as well the purposes. In our experience, learners prefer self-paced training for basic conceptual learning and virtual instructor-led training for more advanced training. Since both serve somewhat different purposes, there is no clear winner between the methods. But when learning data science is concerned, instructor-based learning has an edge over self-paced learning. Owing to the vast knowledge in the data science field and continuous advancements happening, instructor based online learning is a good bet to place.