Reports suggest that around 2.5 quintillion bytes of data are generated every single day. As the online usage growth increases at a tremendous rate, there is a need for immediate Data Science professionals who can clean the data, obtain insights from it, visualize it, train model and eventually come up with solutions using Big data for the betterment of the world.
By 2020, experts predict that there will be more than 2.7 million data science and analytics jobs openings. Having a glimpse of the entire Data Science pipeline, it is definitely tiresome for a single human to perform and at the same time excel at all the levels. Hence, Data Science has a plethora of career options that require a spectrum set of skill sets.
Let us explore the top 5 data science career options in 2019 (In no particular order).
1. Data Scientist
Data Scientist is one of the ‘high demand’ job roles. The day to day responsibilities involves the examination of big data. As a result of the analysis of the big data, they also actively perform data cleaning and organize the big data. They are well aware of the machine learning algorithms and understand when to use the appropriate algorithm. During the due course of data analysis and the outcome of machine learning models, patterns are identified in order to solve the business statement.
The reason why this role is so crucial in any organisation is that the company tends to take business decisions with the help of the insights discovered by the Data Scientist to have an edge over the company’s competitors. It is to be noted that the Data Scientist role is inclined more towards the technical domain. As the role demands a wide range of skill set, Data Scientists are one among the highest paid jobs.
Core Skills of a Data Scientist
Communication
Business Awareness
Database and querying
Data warehousing solutions
Data visualization
Machine learning algorithms
2. Business Intelligence Developer
BI Developer is a job role inclined more towards the Non-Technical domain but has a fair share of Technical responsibilities as well (if required) as a part of their day to day responsibilities. BI developers are responsible for creating and implementing business policies as a result of the insights obtained from the Technical team.
Apart from being a policymaker involving the usage of dedicated (or custom) Business Intelligence analytics tools, they will also have a fair share of coding in order to explore the dataset, present the insights of the dataset in a non-verbal manner. They help in bridging the gap between the technical team that works with the deepest technical understanding and the clients that want the results in the most non-technical manner. They are expected to generate reports from the insights and make it ‘less technical’ for others in the organisation. It is noted that the BI Developers have a deep understanding of Business when compared to Data Scientist.
Core Skills of a Business Analytics Developer
Business model analysis
Data warehousing
Design of business workflow
Business Intelligence software integration
3. Machine Learning Engineer
Once the data is clean and ready for analysis, the machine learning engineers work on these big data to train a predictive model that predicts the target variable. These models are used to analyze the trends of the data in the future so that the organisation can take the right business decisions. As the dataset involved in a real-life scenario would involve a lot of dimensions, it is difficult for a human eye to interpret insights from it. This is one of the reasons for training machine learning algorithms as it easily deals with such complex dataset. These engineers carry out a number of tests and analyze the outcomes of the model.
The reason for conducting constant tests on the model using various samples is to test the accuracy of the developed model. Apart from the training models, they also perform exploratory data analysis sometimes in order to understand the dataset completely which will, in turn, help them in training better predictive models.
Core Skills of Machine Learning Engineers
Machine Learning Algorithms
Data Modelling and Evaluation
Software Engineering
4. Data Engineer
The pipeline of any data-oriented company begins with the collection of big data from numerous sources. That’s where the data engineers operate in any given project. These engineers integrate data from various sources and optimize them according to the problem statement. The work usually involves writing queries on big data for easy and smooth accessibility. Their day to day responsibility is to provide a streamlined flow of big data from various distributed systems. Data engineering differs from the other data science careers as in, it is concentrated on the system and hardware that aids the company’s data analysis, rather than the analysis of data itself. They provide the organisation with efficient warehousing methods as well.
Core Skills of Data Engineer
Database Knowledge
Data Warehousing
Machine Learning algorithm
5. Business Analyst
Business Analyst is one of the most essential roles in the Data Science field. These analysts are responsible for understanding the data and it’s related trend post the decision making about a particular product. They store a good amount of data about various domains of the organisation. These data are really important because if any product of the organisation fails, these analysts work on these big data to understand the reason behind the failure of the project. This type of analysis is vital for all the organisations as it makes them understand the loopholes in the company. The analysts not only backtrack the loophole and in turn provide solutions for the same making sure the organisation takes the right decision in the future. At times, the business analyst act as a bridge between the technical team and the rest of the working community.
Core skills of Business Analyst
Business awareness
Communication
Process Modelling
Conclusion
The data science career options mentioned above are in no particular order. In my opinion, every career option in Data Science field works complimentary with one another. In any data-driven organization, regardless of the salary, every career role is important at the respective stages in a project.
There are a huge number of ML algorithms out there. Trying to classify them leads to the distinction being made in types of the training procedure, applications, the latest advances, and some of the standard algorithms used by ML scientists in their daily work. There is a lot to cover, and we shall proceed as given in the following listing:
Statistical Algorithms
Classification
Regression
Clustering
Dimensionality Reduction
Ensemble Algorithms
Deep Learning
Reinforcement Learning
AutoML (Bonus)
1. Statistical Algorithms
Statistics is necessary for every machine learning expert. Hypothesis testing and confidence intervals are some of the many statistical concepts to know if you are a data scientist. Here, we consider here the phenomenon of overfitting. Basically, overfitting occurs when an ML model learns so many features of the training data set that the generalization capacity of the model on the test set takes a toss. The tradeoff between performance and overfitting is well illustrated by the following illustration:
Overfitting – from Wikipedia
Here, the black curve represents the performance of a classifier that has appropriately classified the dataset into two categories. Obviously, training the classifier was stopped at the right time in this instance. The green curve indicates what happens when we allow the training of the classifier to ‘overlearn the features’ in the training set. What happens is that we get an accuracy of 100%, but we lose out on performance on the test set because the test set will have a feature boundary that is usually similar but definitely not the same as the training set. This will result in a high error level when the classifier for the green curve is presented with new data. How can we prevent this?
Cross-Validation
Cross-Validation is the killer technique used to avoid overfitting. How does it work? A visual representation of the k-fold cross-validation process is given below:
From Quora
The entire dataset is split into equal subsets and the model is trained on all possible combinations of training and testing subsets that are possible as shown in the image above. Finally, the average of all the models is combined. The advantage of this is that this method eliminates sampling error, prevents overfitting, and accounts for bias. There are further variations of cross-validation like non-exhaustive cross-validation and nested k-fold cross validation (shown above). For more on cross-validation, visit the following link.
There are many more statistical algorithms that a data scientist has to know. Some examples include the chi-squared test, the Student’s t-test, how to calculate confidence intervals, how to interpret p-values, advanced probability theory, and many more. For more, please visit the excellent article given below:
Classification refers to the process of categorizing data input as a member of a target class. An example could be that we can classify customers into low-income, medium-income, and high-income depending upon their spending activity over a financial year. This knowledge can help us tailor the ads shown to them accurately when they come online and maximises the chance of a conversion or a sale. There are various types of classification like binary classification, multi-class classification, and various other variants. It is perhaps the most well known and most common of all data science algorithm categories. The algorithms that can be used for classification include:
Logistic Regression
Support Vector Machines
Linear Discriminant Analysis
K-Nearest Neighbours
Decision Trees
Random Forests
and many more. A short illustration of a binary classification visualization is given below:
From openclassroom.stanford.edu
For more information on classification algorithms, refer to the following excellent links:
Regression is similar to classification, and many algorithms used are similar (e.g. random forests). The difference is that while classification categorizes a data point, regression predicts a continuous real-number value. So classification works with classes while regression works with real numbers. And yes – many algorithms can be used for both classification and regression. Hence the presence of logistic regression in both lists. Some of the common algorithms used for regression are
Linear Regression
Support Vector Regression
Logistic Regression
Ridge Regression
Partial Least-Squares Regression
Non-Linear Regression
For more on regression, I suggest that you visit the following link for an excellent article:
Both articles have a remarkably clear discussion of the statistical theory that you need to know to understand regression and apply it to non-linear problems. They also have source code in Python and R that you can use.
4. Clustering
Clustering is an unsupervised learning algorithm category that divides the data set into groups depending upon common characteristics or common properties. A good example would be grouping the data set instances into categories automatically, the process being used would be any of several algorithms that we shall soon list. For this reason, clustering is sometimes known as automatic classification. It is also a critical part of exploratory data analysis (EDA). Some of the algorithms commonly used for clustering are:
Hierarchical Clustering – Agglomerative
Hierarchical Clustering – Divisive
K-Means Clustering
K-Nearest Neighbours Clustering
EM (Expectation Maximization) Clustering
Principal Components Analysis Clustering (PCA)
An example of a common clustering problem visualization is given below:
From Wikipedia
The above visualization clearly contains three clusters.
Another excellent article on clustering refer the link
Dimensionality Reduction is an extremely important tool that should be completely clear and lucid for any serious data scientist. Dimensionality Reduction is also referred to as feature selection or feature extraction. This means that the principal variables of the data set that contains the highest covariance with the output data are extracted and the features/variables that are not important are ignored. It is an essential part of EDA (Exploratory Data Analysis) and is nearly always used in every moderately or highly difficult problem. The advantages of dimensionality reduction are (from Wikipedia):
It reduces the time and storage space required.
Removal of multi-collinearity improves the interpretation of the parameters of the machine learning model.
It becomes easier to visualize the data when reduced to very low dimensions such as 2D or 3D.
It avoids the curse of dimensionality.
The most commonly used algorithm for dimensionality reduction is Principal Components Analysis or PCA. While this is a linear model, it can be converted to a non-linear model through a kernel trick similar to that used in a Support Vector Machine, in which case the technique is known as Kernel PCA. Thus, the algorithms commonly used are:
Ensembling means combining multiple ML learners together into one pipeline so that the combination of all the weak learners makes an ML application with higher accuracy than each learner taken separately. Intuitively, this makes sense, since the disadvantages of using one model would be offset by combining it with another model that does not suffer from this disadvantage. There are various algorithms used in ensembling machine learning models. The three common techniques usually employed in practice are:
Simple/Weighted Average/Voting: Simplest one, just takes the vote of models in Classification and average in Regression.
Bagging: We train models (same algorithm) in parallel for random sub-samples of data-set with replacement. Eventually, take an average/vote of obtained results.
Boosting: In this models are trained sequentially, where (n)th model uses the output of (n-1)th model and works on the limitation of the previous model, the process stops when result stops improving.
Stacking: We combine two or more than two models using another machine learning algorithm.
(from Amardeep Chauhan on Medium.com)
In all four cases, the combination of the different models ends up having the better performance that one single learner. One particular ensembling technique that has done extremely well on data science competitions on Kaggle is the GBRT model or the Gradient Boosted Regression Tree model.
We include the source code from the scikit-learn module for Gradient Boosted Regression Trees since this is one of the most popular ML models which can be used in competitions like Kaggle, HackerRank, and TopCoder.
GradientBoostingClassifier supports both binary and multi-class classification. The following example shows how to fit a gradient boosting classifier with 100 decision stumps as weak learners:
GradientBoostingRegressor supports a number of different loss functions for regression which can be specified via the argument loss; the default loss function for regression is least squares ('ls').
import numpy as np
from sklearn.metrics import mean_squared_error
from sklearn.datasets import make_friedman1
from sklearn.ensemble import GradientBoostingRegressor
X, y = make_friedman1(n_samples=1200, random_state=0, noise=1.0)
X_train, X_test = X[:200], X[200:]
y_train, y_test = y[:200], y[200:]
est = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1,
max_depth=1, random_state=0, loss='ls').fit(X_train, y_train)
mean_squared_error(y_test, est.predict(X_test))
You can also refer to the following article which discusses Random Forests, which is a (rather basic) ensembling method.
In the last decade, there has been a renaissance of sorts within the Machine Learning community worldwide. Since 2002, neural networks research had struck a dead end as the networks of layers would get stuck in local minima in the non-linear hyperspace of the energy landscape of a three layer network. Many thought that neural networks had outlived their usefulness. However, starting with Geoffrey Hinton in 2006, researchers found that adding multiple layers of neurons to a neural network created an energy landscape of such high dimensionality that local minima were statistically shown to be extremely unlikely to occur in practice. Today, in 2019, more than a decade of innovation later, this method of adding addition hidden layers of neurons to a neural network is the classical practice of the field known as deep learning.
Deep Learning has truly taken the computing world by storm and has been applied to nearly every field of computation, with great success. Now with advances in Computer Vision, Image Processing, Reinforcement Learning, and Evolutionary Computation, we have marvellous feats of technology like self-driving cars and self-learning expert systems that perform enormously complex tasks like playing the game of Go (not to be confused with the Go programming language). The main reason these feats are possible is the success of deep learning and reinforcement learning (more on the latter given in the next section below). Some of the important algorithms and applications that data scientists have to be aware of in deep learning are:
Long Short term Memories (LSTMs) for Natural Language Processing
Recurrent Neural Networks (RNNs) for Speech Recognition
Convolutional Neural Networks (CNNs) for Image Processing
Deep Neural Networks (DNNs) for Image Recognition and Classification
Hybrid Architectures for Recommender Systems
Autoencoders (ANNs) for Bioinformatics, Wearables, and Healthcare
Deep Learning Networks typically have millions of neurons and hundreds of millions of connections between neurons. Training such networks is such a computationally intensive task that now companies are turning to the 1) Cloud Computing Systems and 2) Graphical Processing Unit (GPU) Parallel High-Performance Processing Systems for their computational needs. It is now common to find hundreds of GPUs operating in parallel to train ridiculously high dimensional neural networks for amazing applications like dreaming during sleep and computer artistry and artistic creativity pleasing to our aesthetic senses.
Artistic Image Created By A Deep Learning Network. From blog.kadenze.com.
For more on Deep Learning, please visit the following links:
In the recent past and the last three years in particular, reinforcement learning has become remarkably famous for a number of achievements in cognition that were earlier thought to be limited to humans. Basically put, reinforcement learning deals with the ability of a computer to teach itself. We have the idea of a reward vs. penalty approach. The computer is given a scenario and ‘rewarded’ with points for correct behaviour and ‘penalties’ are imposed for wrong behaviour. The computer is provided with a problem formulated as a Markov Decision Process, or MDP. Some basic types of Reinforcement Learning algorithms to be aware of are (some extracts from Wikipedia):
1.Q-Learning
Q-Learning is a model-free reinforcement learning algorithm. The goal of Q-learning is to learn a policy, which tells an agent what action to take under what circumstances. It does not require a model (hence the connotation “model-free”) of the environment, and it can handle problems with stochastic transitions and rewards, without requiring adaptations. For any finite Markov decision process (FMDP), Q-learning finds a policy that is optimal in the sense that it maximizes the expected value of the total reward over any and all successive steps, starting from the current state. Q-learning can identify an optimal action-selection policy for any given FMDP, given infinite exploration time and a partly-random policy. “Q” names the function that returns the reward used to provide the reinforcement and can be said to stand for the “quality” of an action taken in a given state.
2.SARSA
State–action–reward–state–action (SARSA) is an algorithm for learning a Markov decision process policy. This name simply reflects the fact that the main function for updating the Q-value depends on the current state of the agent “S1“, the action the agent chooses “A1“, the reward “R” the agent gets for choosing this action, the state “S2” that the agent enters after taking that action, and finally the next action “A2” the agent choose in its new state. The acronym for the quintuple (st, at, rt, st+1, at+1) is SARSA.
3.Deep Reinforcement Learning
This approach extends reinforcement learning by using a deep neural network and without explicitly designing the state space. The work on learning ATARI games by Google DeepMind increased attention to deep reinforcement learning or end-to-end reinforcement learning. Remarkably, the computer agent DeepMind has achieved levels of skill higher than humans at playing computer games. Even a complex game like DOTA 2 was won by a deep reinforcement learning network based upon DeepMind and OpenAI Gym environments that beat human players 3-2 in a tournament of best of five matches.
For more information, go through the following links:
If reinforcement learning was cutting edge data science, AutoML is bleeding edge data science. AutoML (Automated Machine Learning) is a remarkable project that is open source and available on GitHub at the following link that, remarkably, uses an algorithm and a data analysis approach to construct an end-to-end data science project that does data-preprocessing, algorithm selection,hyperparameter tuning, cross-validation and algorithm optimization to completely automate the ML process into the hands of a computer. Amazingly, what this means is that now computers can handle the ML expertise that was earlier in the hands of a few limited ML practitioners and AI experts.
AutoML has found its way into Google TensorFlow through AutoKeras, Microsoft CNTK, and Google Cloud Platform, Microsoft Azure, and Amazon Web Services (AWS). Currently it is a premiere paid model for even a moderately sized dataset and is free only for tiny datasets. However, one entire process might take one to two or more days to execute completely. But at least, now the computer AI industry has come full circle. We now have computers so complex that they are taking the machine learning process out of the hands of the humans and creating models that are significantly more accurate and faster than the ones created by human beings!
The basic algorithm used by AutoML is Network Architecture Search and its variants, given below:
Network Architecture Search (NAS)
PNAS (Progressive NAS)
ENAS (Efficient NAS)
The functioning of AutoML is given by the following diagram:
If you’ve stayed with me till now, congratulations; you have learnt a lot of information and cutting edge technology that you must read up on, much, much more. You could start with the links in this article, and of course, Google is your best friend as a Machine Learning Practitioner. Enjoy machine learning!
Python and R have been around for well over 20 years. Python was developed in 1991 by Guido van Rossum, and R in 1995 by Ross Ihaka and Robert Gentleman. Both Python and R have seen steady growth year after year in the last two decades. Will that trend continue, or are we coming to an end of an era of the Python-R dominance in the data science segment? Let’s find out!
Python
Python in the last decade has grown from strength to strength. In 2013, Python overtook R as the most popular language used fordata science, according to the Stack Overflow developer survey (Link).
In the last three years, Python was the most wanted language according to this survey (25% in 2018, JavaScript was second with 19%). It is by far the easiest programming language to learn, the Julia and the Go programming languages being honorable mentions in this regard.
Python shines in its versatility, being easy to use for data science, web development, utility programming, and as a general-purpose programming language. Even full-stack development can be done in Python, the only area where it is not used being mobile (although that may change if the Kivy mobile programming framework comes of age and stops stalling all the time). It was also ranked higher than JavaScript in the most loved programming languages for the last three years (Node.js and React.js have ranked below it consistently).
Will Python’s Dominance Continue?
We believe, yes, definitely. Two words – data science.
From https://www.digitaldesignjournal.com
Data science is such a hot and happening field right now, and the data scientist job is hyped as the ‘sexiest job of the 21st century‘, according to Forbes. Python is by far the most popular language for data science. The only close competitor is R, which Python overtook in the KDNuggets data science survey of 2016 . As shown in the link, in 2018, Python held 65.6% of the data science market, and R was actually below RapidMiner, at 48.5%. From the graphs, it is easy to see that Python is eating away at R’s share in the market. But why?
Deep Learning
In 2018, we say a huge push towards advancement across all verticals in the industry due to deep learning. And what is the most famous tool for deep learning? TensorFlow and Keras – both Python-based frameworks! While we have Keras and TensorFlow interfaces in R and RStudio now, Python was the initial choice and is still the native library – kerasR and tensorflow in RStudio being interfaces to the Python packages. Also, a real-life implementation of a deep learning project contains more than the deep learning model preparation and data analysis.
There is the data preprocessing, data cleaning, data wrangling, data preparation, outlier detection and missing data values management section which is infamous for taking up 99% of the time of a data scientist, with actual deep learning model work taking just 1% or less of their on-duty time! And what language is used for this commonly? For general purpose programming, Python is the goto language in most cases. I’m not saying that R doesn’t have data preprocessing packages. I’m saying that standard data science operations like web scraping are easier in Python than in R.And hence Python will be the language used in most cases, except in the statistics and the university or academic fields.
Our prediction for Python – growth – even to 70% of the data science market as more and more research-level projects like AutoML keep using Python as a first language of choice.
What About R?
In 2016, the use of R for data science in the industry was 55%, and Python stood at 51%. Python increased by 33% and R decreased by 25% in 2 years. Will that trend continue and will R continue on its downward spiral? I believe perhaps in figures, but not in practice. Here’s why.
Data science is at its heart, the field of the statistician. Unless you have a strong background in statistics, you will be unable to process the results of your experiments, especially in concepts like p-values, tests of significance, confidence intervals, and analysis of experiments. And R is the statistician’s language.Statistics and mathematics students will always find working in R remarkably easy and simple, which explains its popularity in academia. R programming lends itself to statistics. Python lends itself to model building and decent execution performance (R can be 4x slower). R, however, excels in statistical analysis. So what is the point that I am trying to express?
Simple – Python and R are complementary. They are best used together. You will find that knowledge of both Python and R will suit you best for most projects. You need to learn both. You can find this trend expressed in every article that speaks about becoming a data science unicorn – knowledge of both Python and R is required as a norm.
Yes, R is having a downturn in popularity. However, due to the complementary nature of the tools, I believe that R will have a part to play in the data scientist’s toolbox, even if it does dip a bit in growth in the years to come. Very simply, R is too convenient for a statistician to be neglected by the industry completely. It will continue to have its place in the toolbox. And yes; deep learning is now practical in R with support for Keras and AutoML as well as of right now.
Dimensionless Technologies
Dimensionless Technologies
Dimensionless Technologies is the market leader as far as training in AI, cloud, deep learning and data science in Python and R is concerned. Of course, you don’t have to spend 40k for a data science certification, you could always go for its industry equivalent – 100-120 lakhs for a US university’s Ph.D. research doctorate! What Dimensionless Technologies has as an advantage over its closest rival – (Coursera’s John Hopkins University’s Data Science Specialization) – is:
Live Video Training
The videos that you get on Coursera, edX, Dataquest, MIT OCW (MIT OpenCourseWare), Udacity, Udemy, and many other MOOCs have a fundamental flaw – they are NOT live! If you have a doubt in a video lecture, you only have the comments as a communication tool to the lectures. And when over 1,000 students are taking your class, it is next to impossible to respond to every comment. You will not and cannot get personalized attention for your doubts and clarifications. This makes it difficult for many, especially Indian students who may not be used to foreign accents to have a smooth learning curve in the popular MOOCs available today.
Try Before You Buy Fully
Dimensionless Technologies offers 20 hours of the course for Rs 5000, with the remaining 35k (10k of 45k waived if you qualify for the scholarship) payable after 2 weeks / 20 hours of taking the course on a trial basis. You get to evaluate the course for 20 hours before deciding whether you want to go through the entire syllabus with the highly experienced instructors who are strictly IIT alumni.
Instructors with 10 years Plus Industry Experience
In Coursera or edX, it is more common for Ph.D. professors than industry experienced professionals to teach the course. If you are good with American accents and next to zero instructor support, you will be able to learn a little bit about the scholastic side of your field. However, if you want to prepare for a 100K USD per year US data scientist job, you would be better off learning from professionals with industry experience. I am Not criticizing the Coursera instructors here, most have industry experience as well in the USA. However, if you want connections and contacts in the data science industry in India and the US, you might be a bit lost in the vast numbers of student who take those courses. Industry experience in instructors is rare in a MOOC and critically important to your landing a job.
Personalized Attention and Job Placement Guarantee
Dimensionless has a batch size of strictly not more than 25 per batch. This means that unlike other MOOCs with hundreds or thousands of students, every student in a class will get individual attention and training. This is the essence of what makes this company the market leader in this space. No other course provider has this restriction, which makes it certain that when you pay the money, you are 100% certain of completing your course, unlike all the other MOOCs out there. You are also given training for creating a data science portfolio, and how to prepare for data science interviews when you start applying to companies. The best part of this entire process is the 100% job placement guarantee.
If this has got your attention, and you are highly interested in data science, I encourage you to go to the following link to see more about the Data Science Using Python and R course, a strong foundation for a data science career:
The amount of data that is generated every day is mind-boggling. There was an article on Forbes by Bernard Marr that blew my mind. Here are some excerpts. For the full article, go to Link
There are 2.5 quintillion bytes of data created each day. Over the last two years alone 90 percent of the data in the world was generated.
Europe has more than 307 million people on Facebook
There are five new Facebook profiles created every second!
More than 300 million photos get uploaded per day
Every minute there are 510,000 comments posted and 293,000 statuses updated (on Facebook)
And all this data was gathered 21st May, last year!
Photo by rawpixel on Unsplash
So I decided to do a more up to date survey. The data below was from an article written on 25th Jan 2019, given at the following link:
By 2020, the accumulated volume of big data will increase from 4.4 zettabytes to roughly 44 zettabytes or 44 trillion GB.
Originally, data scientists maintained that the volume of data would double every two years thus reaching the 40 ZB point by 2020. That number was later bumped to 44ZB when the impact of IoT was brought into consideration.
The rate at which data is created is increased exponentially. For instance, 40,000 search queries are performed per second (on Google alone), which makes it 3.46 million searches per day and 1.2 trillion every year.
The data gathered is no more text-only. An exponential growth in videos and photos is equally prominent. On YouTube alone, 300 hours of video are uploaded every minute.
IDC estimates that by 2020, business transactions (including both B2B and B2C) via the internet will reach up to 450 billion per day.
Globally, the number of smartphone users will grow to 6.1 billion by 2020 (this will overtake the number of basic fixed phone subscriptions).
In just 5 years the number of smart connected devices in the world will be more than 50 billion – all of which will create data that can be shared, collected and analyzed.
Photo by Fancycrave on UnsplashSo what does that mean for us, as data scientists?
Data = raw information. Information = processed data.
Theoretically, inside every 100 MB of the 44,000,000,000,000,000 GB available in the world, today produced as data there lies a possible business-sector disrupting insight!
But who has the skills to look through 44 trillion GB of data?
The answer: Data Scientists! WithCreativity and Originality in their Out-of-the-Box Thinking, as well as DisciplinedFocus.
Here is a description estimating the salaries for data scientists followed by a graphic which shows you why data science is so hyped right now:
Freshers in Analytics get paid more than then any other field, they can be paid up-to 6-7 Lakhs per annum (LPA) minus any experience, 3-7 years experienced professional can expect around 10-11 LPA and anyone with more than 7-10 years can expect, 20-30 LPA.
Opportunities in tier 2 cities can be higher, but the pay-scale of Tier 1 cities is much higher.
E-commerce is the most rewarding career with great pay-scale especially for Fresher’s, offering close to 7-8 LPA, while Analytics service provider offers the lowest packages, 6 LPA.
It is advised to combine your skills to attract better packages, skills such as SAS, R Python, or any open source tools, offers around 13 LPA.
Machine Learning is the new entrant in analytics field, attracting better packages when compared to the skills of big data, however for a significant leverage, acquiring the skill sets of both Big Data and Machine Learning will fetch you a starting salary of around 13 LPA.
Combination of knowledge and skills makes you unique in the job market and hence attracts high pay packages.
Picking up the top five tools of big data analytics, like R, Python, SAS, Tableau, Spark along with popular Machine Learning Algorithms, NoSQL Databases, Data Visualization, will make you irresistible for any talent hunter, where you can demand a high pay package.
As a professional, you can upscale your salary by upskilling in the analytics field.
So there is no doubt about the demand or the need for data scientists in the 21st century.
Now we have done a survey for India. but what about the USA?
The following data is an excerpt from an article by IBM< which tells the story much better than I ever could:
Jobs requiring machine learning skills are paying an average of $114,000.
Advertised data scientist jobs pay an average of $105,000 and advertised data engineering jobs pay an average of $117,000.59% of all Data Science and Analytics (DSA) job demand is in Finance and Insurance, Professional Services, and IT.
Annual demand for the fast-growing new roles of data scientist, data developers, and data engineers will reach nearly 700,000 openings by 2020.
By 2020, the number of jobs for all US data professionals will increase by 364,000 openings to 2,720,000 according to IBM.
Data Science and Analytics (DSA) jobs remain open an average of 45 days, five days longer than the market average.
And yet still more! Look below:
By 2020 the number of Data Science and Analytics job listings is projected to grow by nearly 364,000 listings to approximately 2,720,000 The following is the summary of the study that highlights how in-demand data science and analytics skill sets are today and are projected to be through 2020.
There were 2,350,000 DSA job listings in 2015
By 2020, DSA jobs are projected to grow by 15%
Demand for Data scientists and data engineers is projectedto grow byneary40%
DSA jobs advertise average salaries of 80,265 USD$
81% of DSA jobs require workers with 3-5 years of experience or more.
Machine learning, big data, and data science skills are the most challenging to recruit for and potentially can create the greatest disruption to ongoing product development and go-to-market strategies if not filled.
So where does Dimensionless Technologies, with courses in Python, R, Deep Learning, NLP, Big Data, Analytics, and AWS coming soon, stand in the middle of all the demand?
The answer: right in the epicentre of the data science earthquake that is no hitting our IT sector harder than ever.The main reason I say this is because of the salaries increasing like your tummy after you finish your fifth Domino’s Dominator Cheese and Pepperoni Pizza in a row everyday for seven days! Have a look at the salaries for data science:
Do you know which city in India pays highest salaries to data scientist?
Mumbai pays the highest salary in India around 12.19L p.a.
Report of Data Analytics Salary of the Top Companies in India
Accenture’s Data Analytics Salary in India: 90% gets a salary of about Rs 980,000 per year
Tata Consultancy Services Limited Data Analytics Salary in India: 90% of the employees get a salary of about Rs 550,000 per year. A bonus of Rs 20,000 is paid to the employees.
EY (Ernst & Young) Data Analytics Salary in India: 75% of the employees get a salary of Rs 620,000 and 90% of the employees get a salary of Rs 770,000.
HCL Technologies Ltd. Data Analytics Salary in India: 90% of the people are paid Rs 940,000 per year approximately.
In the USA
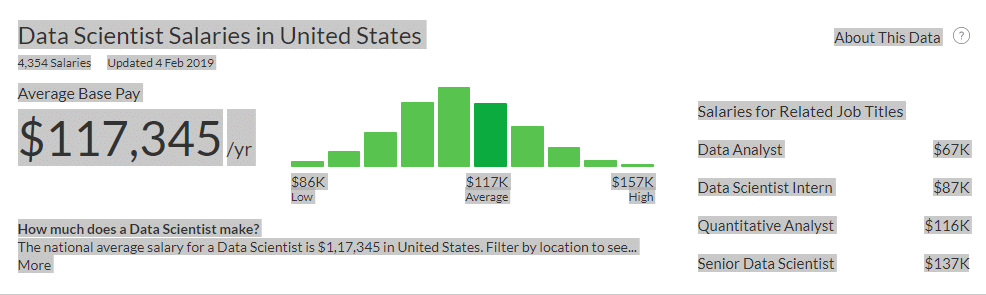
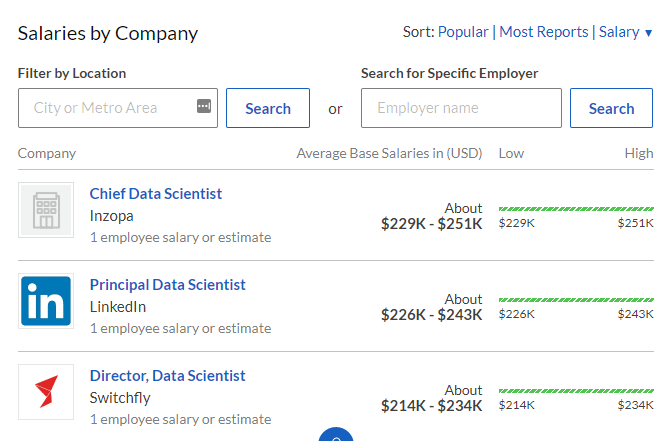
From glassdoor.com
To convert into INR, in the US, the salaries of a data scientist stack up as follows:
Lowest: 86,000 USD = 6,020,000 INR per year (60 lakh per year)
Average: 117,00 USD = 8,190,000 INR per year (81 lakh per year)
Highest: 157,000 USD = 10,990,000 INR per year(109 lakh per year or approximately one crore)
at the exchange rate of 70 INR = 1 USD.
By now you should be able to understand why everyone is running after data science degrees and data science certifications everywhere.
The only other industry that offers similar salaries is cloud computing.
A Personal View
On my own personal behalf, I often wondered – why does everyone talk about following your passion and not just about the money. The literature everywhere advertises“Follow your heart and it will lead you to the land of your dreams”. But then I realized – passion is more than your dreams. A dream, if it does not serve others in some way, is of no inspirational value. That is when I found the fundamental role – focus on others achieving their hearts desires, and you will automatically discover your passion. I have many interests, and I found my happiness doing research in advanced data science and quantum computing and dynamical systems, focusing on experiments that combine all three of them together as a single unified theory. I found that that was my dream. But, however, I have a family and I need to serve them. I need to earn.
Thus I relegated my dreams of research to a part-time level and focused fully on earning for my extended family, and serving them as best as I can. Maybe you will come to your own epiphany moment yourself reading this article. What do you want to do with your life? Personally, I wish to improve the lives of those around me, especially the poor and the malnourished. That feeds my heart. Hence my career decision – invest wisely in the choices that I make to garner maximum benefit for those around me. And work on my research papers in the free time that I get.
So my hope for you today is: having read this article, understand the rich potential that lies before you if you can complete your journey as a data scientist. The only reason that I am not going into data science myself is that I am 34 years old and no longer in the prime of my life to follow this American dream. Hence I found my niche in my interest in research. And further, I realized that a fundamental ‘quantum leap’ would be made if my efforts were to succeed. But as for you, the reader of this article, you may be inspired or your world-view expanded by reading this article and the data contained within. My advice to you is: follow your heart. It knows you best and will not betray you into any false location. Data science is the future for the world. make no mistake about that. And – from whatever inspiration you have received go forward boldly and take action. Take one day at a time. Don’t look at the final goal. Take one day at a time. If you can do that, you will definitely achieve your goals.
The salary at the top, per year. From glassdoor.com. Try not to drool. 🙂
Finding Your Passion
Many times when you’re sure you’ve discovered your passion and you run into a difficult topic, that leaves you stuck, you are prone to the famous impostor syndrome. “Maybe this is too much for me. Maybe this is too difficult for me. Maybe this is not my passion. Otherwise, it wouldn’t be this hard for me.” My dear friend, this will hit you. At one point or the other. At such moments, what I do, based upon lessons from the following course, which I highly recommend to every human being on the planet, is: Take a break. Do something different that completely removes the mind from your current work. Be completely immersed in something else. Or take a nap. Or – best of all – go for a run or a cycle. Exercise. Workout. This gives your brain cells rest and allows them to process the data in the background. When you come back to your topic, fresh, completely free of worry and tension, completely recharged, you will have an insight into the problem for you that completely solves it. Guaranteed. For more information, I highly suggest the following two resources:
or the most popular MOOC of all time, based on the same topic: Coursera
Learning How to Learn – Coursera and IEEE
This should be your action every time you feel stuck. I have completely finished this MOOC and the book and it has given me the confidence to tackle any subject in the world, including quantum mechanics, topology, string theory, and supersymmetry theory. I strongly recommend this resource (from experience).
So Dimensionless Technologies (link given above) is your entry point to all things data science. Before you go to TensorFlow, Hadoop, Keras, Hive, Pig, MapReduce, BigQuery, BigTable, you need to know the following topics first:
All the best. Your passion is not just a feeling. It is a choice you make the day in and a day out whether you like it or not. That is the definition of character – to do what must be done even if you don’t feel like it. Internalize this advice, and there will be no limits to how high you can go.All the best!
Data science is a booming industry, with potentially millions of job openings by 2020, according to the latest analyst’s business predictions. But what if you want to learn data science without the heavy cost of a postgraduate degree or the US university MOOC specialization? What is the best way to prepare for this upcoming wave of opportunity and maximize your chances for a 100K+ USD (annual) job? Well – there are many challenges that stand before you in such a case. Not only is the market saturated with an abundance of existing fresh talent, but most of the training you receive in college has no relationship to the actual type of work you get on the job. With so many engineering graduates passing out every year from so many established institutions such as the IITs, how can you hope to realistically compete? Well – there is one possibility you can choose if you wish to stand out from the rest of the competition – high-quality data science programs or courses. And in this article, we are going to list the top ten advantages of choosing such a course compared to other options, like a Ph.D., or an online MOOC Specialization from a US university (which are very tempting options, especially if you have the money for them).
Top Ten Advantages of Data Science Certification
1. Stick to Essentials, Cut the Fluff.
Now if you are a professional data scientist, no one expects you to derive any AI algorithms from first principles. You also don’t need to extensively dig into the (relatively) trivial history behind each algorithm, nor learn SVD (Singular Value Decomposition) or Gaussian Elimination on a real matrix without a computer to assist you. There is so much material that an academic degree covers that is never used on the job! Yes, you need to have an intuitive idea about the algorithms. But unless you’re going in for ML research, there’s not much use of knowing, say, Jacobians or Hessians in depth. Professional data scientists work in very different domains while compared to academic researchers or academic counterparts. Learn what you need on the job. If you try to cover everything mentioned in class, you’ve already lost the race. Focus on learning bare essentials thoroughly. You always have Google and StackOverflow to assist you as long as you’re not writing an exam!
2.Learning from Instructors with Work Experience, not PhD scientists!
Now from whom should you receive training? From PhD academics who’ve never worked on a real professional project but have published extensively, or instructors with real-life professional project experience? Very often, the teachers and instructors in colleges and universities belong to the former category, and you are remarkably fortunate if you have an instructor who has that invaluable component called industry experience. The latter category are rare and difficult to find, and you are lucky – even remarkably so – if you are studying under them. They will be able to teach you with context to the job experience in real-life, which is always exactly what you need the most.
3. Working with the Latest Technology Stacks.
Now, who would be better able to land you a job – teachers who teach what they studied ten years ago, or professionals who work with the latest tools available in the industry? It’s undoubtedly true that the people with industry experience can help you to choose what technologies you should learn and master. Academics, in comparison, could even be working with technology stacks over ten years old! Please try to stick with instructors who have work experience.
4. Individual Attention.
In a college or a MOOC with thousands of students, it’s simply not possible for each student to get individual attention. However, in data science programs, it is true that every student will receive individual attention tailored to their needs, which is exactly what you need. Every student is different and will have their own understanding of the projects available. This customized attention that is available when batch sizes are less than 30-odd is the greatest advantage such students have over college and MOOC students.
5. GitHub Project Portfolio Guidance.
Every college lecturer will advise you to develop a GitHub project portfolio, but they cannot give your individual profile genuine attention. The reason for that is that they have too many students and requirements upon their time to be able to spend time with individual project portfolios and actually mentor you in designing and establishing your own project portfolio. However, data science programs are different and it is genuinely possible for the instructors to mentor you individually in designing your project portfolios. Experienced industry professionals can even help you identify ‘niches’ within your fieldin which you can shine and carve out a special brand for your own project specialties so that you can really distinguish yourself and be a class apart from the rest of your competition.
6. Mentoring even After Getting Placed in a Company and Working by Yourself.
Trust me, no college professor will be able or even available to help you once you get placed within the industry since your domains will be so different. However, its a very different story with industry professionals who become instructors. You can even go to them or contact them for guidance even after placement, which is, simply not something most academic professors will be able to do unless they too have industry experience, which is very rare.
7. Placement Assistance.
People who have worked in the industry will know the importance of having company referrals in the placement process. It is one thing to have a cold call with a company with no internal referrals. Having someone already established within the company you apply to can be the difference between a successful and unsuccessful recruitment process. Every industry professional will have contacts in many companies, which puts them in a unique position to aid you at the time of placement opportunities.
8. Learn Critical but Non-Technical Job Skills, such as Networking, Communication, and Teamwork
teamwork in data science
While it is important to know the basics, one reason why brilliant students do badly in the industry after they get a job is the lack of soft skills like communication and teamwork. A job in the industry is so much more than bare skills studied in class. You need to be able to communicate effectively and to work well in teams, which can be guided by industry professionals but not by professors since they will have no experience in this area because they have never worked in the industry. Professionals will know who to guide you with regard to this aspect of your expertise, since its a case of being in that position and having learnt the necessary skills in the industry through their job experiences and work capacities.
9. Reduced Cost Requirements
It is one thing to be able to sponsor your own PhD doctoral fees. It is quite another thing to learn the very same skills for less than 1% of the cost of a PhD degree in, say, the USA. Not only is it financially less demanding, but you also don’t have to worry about being able to pay off massive student loans through industry work and fat paychecks, often at the cost of compromising your health or your family needs. Why take a Rs. 75 lakh student loan, when you can get the same outcome from a course less than 0.5% of the price? The takeaways will still be the same! In most cases, you will even receive better training through the data science program than an academic qualification because your instructors will have job experience.
10. Highly Reduced Time Requirements
A PhD degree takes, on average, 5 years. A data science program gets you job-ready in a few months time. Why don’t you decide which is better for you? This is especially true when you already have job experience in another domain or you are more than 23-25 years old, and doing a full PhD program could put you on the wrong side of 30 with almost no job experience. Please go for the data science program, since the time spent working in your 20s is critical for most companies who are hiring today since they consider you to a be a good ‘çultural fit’ for the company environment, especially when you have less than 3-4 years experience.
Summary
Thus, its easy to see that in so many ways, a data science program can be much better for you than a data science degree. So, the critical takeaway for this article is that there is no need to spend Rs. 75,000,000+ for skills which you can acquire for Rs. 35,000 max. It really is a no-brainer. These data science programs really offer true value for money. In case you’re interested, please do check out the following data science programs, each of which have every one of the advantages listed above: