Visualizing the data is important as it makes it easier to understand large amount of complex data using charts and graphs than studying documents and reports. It helps the decision makers to grasp difficult concepts, identify new patterns and get a daily or intra-daily view of their performance. Due to the benefits it possess, and the rapid growth in analytics industry, businesses are increasingly using data visualizations; which can be assessed from the prediction that the data visualization market is expected to grow annually by 9.47% to $7.76 billion by 2023 from $4.51 billion in 2017.
R is a programming language and a software environment for statistical computing and graphics. It offers inbuilt functions and libraries to present data in the form of visualizations. It excels in both basic and advanced visualizations using minimum coding and produces high quality graphs on large datasets.
This article will demonstrate the use of its packages ggplot2 and plotly to create visualizations such as scatter plot, boxplot, histogram, line graphs, 3D plots and Maps.
1. ggplot2
#install package ggplot2
install.packages("ggplot2")
#load the package
library(ggplot2)
There are a lot of datasets available in R in package ‘datasets’, you can run the command data() to list those datasets and use any dataset to work upon. Here I have used the dataset named ‘economics’ which gives the monthly U.S. data of various economic variables like unemployment for the time period 1967-2015.
You can view the data using view function-
view(economics)
Scatter Plot
We’ll make a simple scatter plot to view how unemployment has fluctuated over the years by using plot function-
plot(x = economics$date, y = economics$unemploy)
ggplot() is used to initialize the ggplot object which can be used to declare the input dataframe and set of plot aesthetics. We can add geom components to it that acts as its layer and are used to specify the plot’s features.
We would use its feature geom point which is used to create scatter plots.
ggplot(data = economics, aes(x = date , y = unemploy)) + geom_point()
Modifying Plots
We can modify the plot like its color, shape, size etc. using geom_point aesthetics.
ggplot(data = economics, aes(x = date , y = unemploy)) + geom_point(size = 3)
Lets view the graph by modifying its color-
ggplot(data = economics, aes(x = date , y = unemploy)) + geom_point(size = 3, color = "blue")
Boxplot
Boxplot is a method of graphically depicting groups of numerical data through their quartiles. a geom boxplot layer of ggplot is used to create boxplot of the data.
ggplot(data = economics, aes(x = date , y = unemploy)) + geom_boxplot()
When there is overplotting, one or more points are in the same place and we can’t tell by looking at the plot that how many points are there. In that case, we can use the jitter geom which adds a small amount of variation to the location of each point that is it slightly moves the point, which is used to spread out the points that would otherwise be overplotted.
ggplot(data = economics, aes(x = date , y = unemploy)) +
geom_jitter(alpha = 0.5, color = "red") + geom_boxplot(alpha = 0)
Line Graph
We can view the data in the form of a line graph as well using geom_line.
To change the names of the axis and to give a title to the graph, use labs feature-
ggplot(data = economics, aes(x = date, y = unemploy)) + geom_line()
+ labs(title = "Number of unemployed people in U.S.A. from 1967 to 2015",
x = "Year", y = "Number of unemployed people")
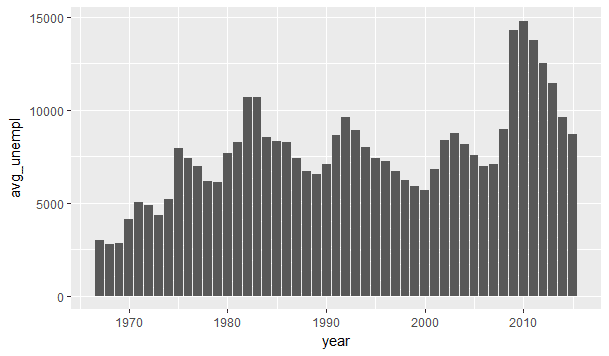
Let’s group the data according to year and view how average unemployment fluctuated through these years.
We will load dplyr package to manipulate our data and lubridate package to work with date column.
library(dplyr)
library(lubridate)
Now we will use mutate function to create a column year from the date column given in economics dataset by using the year function of lubridate package. And then we will group the data according to year and summarise it according to average unemployment-
Now, lets view the data as a line plot using line geom of ggplot2
ggplot(data = economics_update, aes(x = year , y = avg_unempl)) + geom_bar(stat = “identity”)
(Since here we want the height of the bar be equal to avg_unempl, so we need to specify stat equal to identity)
This graph shows the average unemployment in each year
Plotting Time Series Data
In this section, I’ll be using a dataset that records the number of tourists who visited India from 2001 to 2015 which I have rearranged such that it has 3 columns, country, year and number of tourists arrived.
To visualize the plot of the number of tourists that visited the countries over the years in the form of line graph, we use geom_line-
Unfortunately, we get this graph which looks weird because we have plotted all the countries data together.
So, we group the graph by country by specifying it in aesthetics-
ggplot(data = tourist1, aes(x = year, y = number_tourist, group = Country)) + geom_line()
This graph is showing the country wise line graph which shows the trend of a number of tourists arrived from these countries over the years.
To better view the graph that distinguishes countries and is bigger in size, we can specify color and size-
ggplot(data = tourist1, aes(x = year, y = number_tourist, group = Country,
color = Country)) + geom_line(size = 1)
Faceting
Faceting is a feature in ggplot which enables us to split one plot into multiple plots based on some factor. We can use it to visualize one-time series for each factor separately-
ggplot(data = tourist1, aes(x = year, y = number_tourist, group =
Country, color = Country)) + geom_line(size = 1) + facet_wrap(~Country)
For convenience purpose, you can change the theme of the background as well, here I am keeping the theme as white-
ggplot(data = tourist1, aes(x = year, y = number_tourist,
group = Country, color = Country)) + geom_line(size = 1) +
facet_wrap(~Country) + theme_bw()
These were some basic functions of ggplot2, for more functions, check out the official guide.
2. Plotly
Plotly is deemed to be one of the best data visualization tools in the industry.
Line graph
Lets construct a simple line graph of two vectors by using plot_ly function that initiates a visualization in plotly. Since we are creating a line graph, we have to specify type as ‘scatter’ and mode as ‘lines’.
plot_ly(x = c(1,2,3), y = c(10,20,30), type = "scatter", mode = "lines")
Now let’s create a line graph using the economics dataset that we used earlier-
plot_ly(x = economics$date, y = economics$unemploy, type = "scatter", mode = "lines")
Now, we’ll use the dataset ‘women’ that is available in R which records the average height and weight of American women.
Scatter Plot
Now lets create a scatter plot for which we need to specify mode as ‘markers’ –
plot_ly(x = women$height, y = women$weight, type = "scatter", mode = "markers")
Bar Chart
Now, to create a bar chart, we need to specify the type as ‘bar’.
plot_ly(x = women$height, y = women$weight, type = "bar")
Histogram
To create a histogram in plotly, we need to specify the type as ‘histogram’ in plot_ly.
1. Normal distribution
Let x follow a normal distribution with n=200
X < -rnorm(200)
We then plot this normal distribution in histogram,
plot_ly(x = x, type = "histogram")
Since its a normally distributed data, so the shape of this histogram is bell-shaped.
2. Chi-Square Distribution
Let y follow a chi square distribution with n = 200 and df = 4,
y = rchisq(200, 4)
Then, we construct a histogram of y-
plot_ly(x = y, type = "histogram")
This histogram represents a chi square distribution, so it is positively skewed
Boxplot
We will build a boxplot of a normally distributed data, fr that we need to specify the type as ‘box’.
plot_ly(x = rnorm(200, 0, 1), type = "box")
here x follows a normal distribution with mean 0 and sd 1,
So in this box plot, the median is at 0 as in normal distribution, median is equal to mean.
Adding Traces
We can add multiple traces to the plot using pipelines and add_trace feature-
plot_ly(x = iris$Sepal.Length, y = iris$Sepal.Width,
type = "scatter", mode = "markers")%>%
add_trace(x = iris$Petal.Length, y = iris$Petal.Width)
Now let’s construct two boxplots from two normally distributed datasets, one with mean 0 and other with mean 1-
Now, let’s modify the size and color of the plot, since the mode is a marker, so we would specify the marker as a list with the modifications that we require.
plot_ly(x = women$height, y = women$weight, type = "scatter",
mode = "markers", marker = list(size = 10, color = "red"))
We can modify points individually as well if we know the number of points in the graph-
We can modify the plot using the layout function as well which allows us to customize the x-axis and y-axis. We can specify the modifications in the form of a list-
plot_ly(x = women$height, y = women$weight, type = "scatter", mode = "markers",
marker = list(size = 10, color = "red"))%>%
layout(title = "scatter plot", xaxis = list(showline = T, title = "Height"),
yaxis = list(showline = T, title = "Weight"))
Here, we have given a title to the graph and the x-axis and y-axis as well. Also, we have the X-axis line and Y-axis line
Let’s say we want to distinguish the points in the plot according to a factor-
plot_ly(x = iris$Sepal.Length, y = iris$Sepal.Width, type = "scatter",
color = ~iris$Species, colors = "Set1")
here, if we don’t specify the mode, it will set the mode to ‘markers’ by default
Mapping Data to Symbols
We can map the data into differentiated symbols so that we can view the graph better for different factors-
plot_ly(x = iris$Sepal.Length, y = iris$Sepal.Width, type = "scatter",
mode = “markers”, symbol = ~iris$Species)
here, the points pertaining to 3 factors are distinguished by symbols that R assigned to it.
We can customize the symbols as well-
plot_ly(x = iris$Sepal.Length, y = iris$Sepal.Width, type = "scatter",
mode = “makers”, symbol = ~iris$Species, symbols = c("circle", "x", "o"))
3D Line Plot
We can construct a 3D plot as well by specifying it in type. Here we are constructing a 3D line plot-
plot_ly(x = c(1,2,3), y = c(2,4,6), z = c(3,6,9), type = "scatter3d",
mode = "lines")
Map Visualization
We can visualize map as well by specifying in type as ‘scattergeo’. Since its a map, so we need to specify lattitude and longitude.
plot_ly(lon = c(40, 50), lat = c(10, 20), type = "scattergeo", mode = "markers")
We can modify the map as well. Here we have increased the size of the points and changed its color. We have also added text that is the location of the point which would show the location name when the cursor is placed on it.
plot_ly(lon = c(-95, 80), lat = c(30, 20), type = "scattergeo",
mode = "markers", size = 10, color = "Set2", text = c("U.S.A.", "India"))
These were some of the visualizations from package ggplot2 and plotly. R has various other packages for visualizations like graphics and lattice. Refer to the official documentation of R to know more about these packages.
To know more about our Data Science course, click below
Unless you’ve been living with your head under a rock for the last 4 years, you will definitely have heard of Bitcoin. You would also have heard about the technology behind Bitcoin, Blockchain. Now cryptocurrencies are banned in most cases in India and China, but the Americas and Europe still use cryptocurrencies extensively. And in my opinion, Asia stands to lose a lot if blockchain is not adopted extensively everywhere. Because make no mistake about it – blockchain technology will change the world as we know it. Forever.
Blockchain is the technology powering Bitcoin and other cryptocurrencies. To explain what blockchain is and what bitcoin is you can go through anyone of the articles below. Don’t worry these articles are carefully selected to be as interesting and fun to read as possible. (This also gives me space to add my own original ideas instead of copying or rewording existing articles – and I have plenty (of ideas)!
In fact, that last link is so amazingly simple visual and clear that I recommend everyone read it. Just so that we’re on the same page.
Exciting Applications
From Pixabay
Cut to the chase. A little confession here. I was asked to do this article nearly 16 days ago. Now I have some experience with blockchain before since having gone through it extensively as a research topic for my own blog. Then a remarkable idea hit me. An idea for a startup that could (in theory) become a multi-billion dollar enterprise. I spent a few days refining it, even going so far as to see if I could start this company with this area myself, until reality set in – I lacked the experience and the business skills.
No sooner had this realization struck me and the excitement cooled a little, another idea to improve blockchain struck me, and I promise to sketch out that idea as well. I am doing this for two reasons:
I am staunch support of the FOSS (free open source software movement and would like to be credited with the idea, and I am starting a free to use, open source project on GitHub – working on it, currently moving towards an alpha release as of now.
I believe in the power of technology to remove economic inequality. Now you may say that technology has evolved to the point that 4-5 monolithic companies dominate the entire world. But I believe that technology when used ethically has the potential to create more opportunities than it removes.
Blockchain has two major problems – energy consumption and resource consumption. But there are techniques that can alleviate both of these problems. We’ll deal with that as well in Part 2.
Finally, the vaunted hype about security for blockchain and cryptocurrencies is ridiculous when you think about it. For the sake of brevity, I will address the main security issues with blockchain in a separate article on Medium – (not here, since it has no relation to data science).
Application – A Personal Blockchain For Every Person On The Planet
In points (I assume you’ve gone through the graphical explanation of blockchain at least – if not you can review it here):
The trouble with end products of all types that are produced today is that there are so many intermediaries between the producer and the consumer that the producers receives a pittance compared to the end final price. It would be nice if we could track a product everywhere that it is used.
This is also applicable for books, music, articles, poems, pictures, any digital content of any sort. Currently Amazon and YouTube monopolize content distribution, the latter with a complete disregard for copyright and media ownership and payment. Suppose we had a tracking system that viewed every view of a video, and rewarded the original producer for it?
To emphasize the previous point, let us consider the case of Lindsey Stirling. Lindsey Stirling is a famous contemporary violinist who dances while playing. Her 118 video uploads have earned her 2,575,305,706 views, 2.5 billion approx, and her earnings from YouTube ads last month was 100K a month. Her net worth as on 10th April 2019 is 12 million USD (12,000,000).
But suppose Lindsey Stirling distributed her videos at a price of 1 USD every view. Her net worth would be 2.6 billion USD at the very least! She would be a multi-billionaire had this platform existed. It doesn’t – yet. And because it doesn’t exist she is 2.49 billion USD poorer!
Now everyone who knows blockchain technology will now realize this idea, the concept, and how blockchain can be used to overcome this problem – and its power. Disruptive power!
The Solution
The blockchain is a service that immutably assigns ownership.
The blockchain is also a database that stores every single transaction on a particular digitisable entity.
Finally, the Ethereum smart contract technology means that we can assign payments to go to every person on his own personal blockchain of all his digitisable goods.
This means we can build a world where producer pays a user-defined amount to every entity which created a particular digitisable product.
On this platform or website or marketplace, producers can adjust their prices and their payments and consumers can buy directly from them.
Everything can be tracked on the blockchain. Your own database of your own transactions can be used with smart contracts to pay the maximum possible fee to the most deserving person in the supply chain – fixed by each producer.
Hugely, Massively Disruptive
If you are interested or want to know more, you can leave a comment below with your email address. If you want to be a part of this new revolution and the new decentralised world – with all services provided free – please provide a comment below asking for my email ID with a statement of what and how you want to contribute to this endeavor. I promise to reply to every sincere query.
This is a fledgling project and a lot of work remains to be done. I will be writing articles and creating a team to work on this idea. Those of you who are interested please mail me at thomascherickal@gmail.com.
This will be an open source project and all services have to be offered free of cost. How do you go about making a profit from this? You don’t! The only way this can be fair to all players in countries like India is if it is specially designed to be applicable to anyone.
So this article gave a small glimpse into a world without intermediaries, corporations, money-making middlemen, and running purely on smart contracts. This is applicable to AI and data science since this technology will not reach anywhere significant without extensive use of AI and data science.
The more data that is available, the more analysis can be performed on it. And unless we have analysts who are running monitoring fraud detection systems fulltime on such a system, we might as well never build it – because blockchain data integrity cannot be hacked, but cryptocurrencies are hackable and have been hacked extensively since the beginning of Bitcoin.
For Part 2 of this series on Blockchain Applications of Data Science, you can go to the link below:
I have just completed my survey of data (from articles, blogs, white papers, university websites, curated tech websites, and research papers all available online) about predictive analytics.
And I have a reason to believe that we are standing on the brink of a revolution that will transform everything we know about data science and predictive analytics.
But before we go there, you need to know: why the hype about predictive analytics? What is predictive analytics?
Let’s cover that first.
Importance of Predictive Analytics
By PhotoMix Ltd
According to Wikipedia:
Predictive analytics is an area of statistics that deals with extracting information from data and using it to predict trends and behavior patterns. The enhancement of predictive web analytics calculates statistical probabilities of future events online. Predictive analytics statistical techniques include data modeling, machine learning, AI, deep learning algorithms and data mining.
Predictive analytics is why every business wants data scientists. Analytics is not just about answering questions, it is also about finding the right questions to answer. The applications for this field are many, nearly every human endeavor can be listed in the excerpt from Wikipedia that follows listing the applications of predictive analytics:
From Wikipedia:
Predictive analytics is used in actuarial science, marketing, financial services, insurance, telecommunications, retail, travel, mobility, healthcare, child protection, pharmaceuticals, capacity planning, social networking, and a multitude of numerous other fields ranging from the military to online shopping websites, Internet of Things (IoT), and advertising.
In a very real sense, predictive analytics means applying data science models to given scenarios that forecast or generate a score of the likelihood of an event occurring. The data generated today is so voluminous that experts estimate that less than 1% is actually used for analysis, optimization, and prediction. In the case of Big Data, that estimate falls to 0.01% or less.
Common Example Use-Cases of Predictive Analytics
Components of Predictive Analytics
A skilled data scientist can utilize the prediction scores to optimize and improve the profit margin of a business or a company by a massive amount. For example:
If you buy a book for children on the Amazon website, the website identifies that you have an interest in that author and that genre and shows you more books similar to the one you just browsed or purchased.
YouTube also has a very similar algorithm behind its video suggestions when you view a particular video. The site identifies (or rather, the analytics algorithms running on the site identifies) more videos that you would enjoy watching based upon what you are watching now. In ML, this is called a recommender system.
Netflix is another famous example where recommender systems play a massive role in the suggestions for ‘shows you may like’ section, and the recommendations are well-known for their accuracy in most cases
Google AdWords (text ads at the top of every Google Search) that are displayed is another example of a machine learning algorithm whose usage can be classified under predictive analytics.
Departmental stores often optimize products so that common groups are easy to find. For example, the fresh fruits and vegetables would be close to the health foods supplements and diet control foods that weight-watchers commonly use. Coffee/tea/milk and biscuits/rusks make another possible grouping. You might think this is trivial, but department stores have recorded up to 20% increase in sales when such optimal grouping and placement was performed – again, through a form of analytics.
Bank loans and home loans are often approved with the credit scores of a customer. How is that calculated? An expert system of rules, classification, and extrapolation of existing patterns – you guessed it – using predictive analytics.
Allocating budgets in a company to maximize the total profit in the upcoming year is predictive analytics. This is simple at a startup, but imagine the situation in a company like Google, with thousands of departments and employees, all clamoring for funding. Predictive Analytics is the way to go in this case as well.
IoT (Internet of Things) smart devices are one of the most promising applications of predictive analytics. It will not be too long before the sensor data from aircraft parts use predictive analytics to tell its operators that it has a high likelihood of failure. Ditto for cars, refrigerators, military equipment, military infrastructure and aircraft, anything that uses IoT (which is nearly every embedded processing device available in the 21st century).
Fraud detection, malware detection, hacker intrusion detection, cryptocurrency hacking, and cryptocurrency theft are all ideal use cases for predictive analytics. In this case, the ML system detects anomalous behavior on an interface used by the hackers and cybercriminals to identify when a theft or a fraud is taking place, has taken place, or will take place in the future. Obviously, this is a dream come true for law enforcement agencies.
So now you know what predictive analytics is and what it can do. Now let’s come to the revolutionary new technology.
End-to-End Predictive Analytics Product – for non-tech users!
In a remarkable first, a research team at MIT, USA have created a new science called social physics, or sociophysics. Now, much about this field is deliberately kept highly confidential, because of its massive disruptive power as far as data science is concerned, especially predictive analytics. The only requirement of this science is that the system being modeled has to be a human-interaction based environment. To keep the discussion simple, we shall explain the entire system in points.
All systems in which human beings are involved follow scientific laws.
These laws have been identified, verified experimentally and derived scientifically.
Bylaws we mean equations, such as (just an example) Newton’s second law: F = m.a (Force equals mass times acceleration)
These equations establish laws of invariance – that are the same regardless of which human-interaction system is being modeled.
Hence the term social physics – like Maxwell’s laws of electromagnetism or Newton’s theory of gravitation, these laws are a new discovery that are universal as long as the agents interacting in the system are humans.
The invariance and universality of these laws have two important consequences:
The need for large amounts of data disappears – Because of the laws, many of the predictive capacities of the model can be obtained with a minimal amount of data. Hence small companies now have the power to use analytics that was mostly used by the FAMGA(Facebook, Amazon, Microsoft, Google, Apple) set of companies since they were the only ones with the money to maintain Big Data warehouses and data lakes.
There is no need for data cleaning. Since the model being used is canonical, it is independent of data problems like outliers, missing data, nonsense data, unavailable data, and data corruption. This is due to the orthogonality of the model ( a Knowledge Sphere) being constructed and the data available.
Performance is superior to deep learning, Google TensorFlow, Python, R, Julia, PyTorch, and scikit-learn. Consistently, the model has outscored the latter models in Kaggle competitions, without any data pre-processing or data preparation and cleansing!
Data being orthogonal to interpretation and manipulation means that encrypted data can be used as-is. There is no need to decrypt encrypted data to perform a data science task or experiment. This is significant because the independence of the model functioning even for encrypted data opens the door to blockchain technology and blockchain data to be used in standard data science tasks. Furthermore, this allows hashing techniques to be used to hide confidential data and perform the data mining task without any knowledge of what the data indicates.
Are You Serious?
That’s a valid question given these claims! And that is why I recommend everyone who has the slightest or smallest interest in data science to visit and completely read and explore the following links:
Now when I say completely read, I mean completely read. Visit every section and read every bit of text that is available on the three sites above. You will soon understand why this is such a revolutionary idea.
These links above are articles about the social physics book and about the science of sociophysics in general.
For more details, please visit the following articles on Medium. These further document Endor.coin, a cryptocurrency built around the idea of sharing data with the public and getting paid for using the system and usage of your data. Preferably, read all, if busy, at least read Article No, 1.
Upon every data set, the first action performed by the Endor Analytics Platform is clustering, also popularly known as automatic classification. Endor constructs what is known as a Knowledge Sphere, a canonical representation of the data set which can be constructed even with 10% of the data volume needed for the same project when deep learning was used.
Creation of the Knowledge Sphere takes 1-4 hours for a billion records dataset (which is pretty standard these days).
Now an explanation of the mathematics behind social physics is beyond our scope, but I will include the change in the data science process when the Endor platform was compared to a deep learning system built to solve the same problem the traditional way (with a 6-figure salary expert data scientist).
From Appendix A: Social Physics Explained, Section 3.1, pages 28-34 (some material not included):
Prediction Demonstration using the Endor System:
Data:
The data that was used in this example originated from a retail financial investment platform
and contained the entire investment transactions of members of an investment community.
The data was anonymized and made public for research purposes at MIT (the data can be
shared upon request).
Summary of the dataset:
– 7 days of data
– 3,719,023 rows
– 178,266 unique users
Automatic Clusters Extraction:
Upon first analysis of the data the Endor system detects and extracts “behavioral clusters” – groups of
users whose data dynamics violates the mathematical invariances of the Social Physics. These clusters
are based on all the columns of the data, but is limited only to the last 7 days – as this is the data that
was provided to the system as input.
Behavioural Clusters Summary
Number of clusters:268,218
Clusters sizes: 62 (Mean), 15 (Median), 52508 (Max), 5 (Min)
Clusters per user:164 (Mean), 118 (Median), 703 (Max), 2 (Min)
Users in clusters: 102,770 out of the 178,266 users
Records per user: 6 (Median), 33 (Mean): applies only to users in clusters
Prediction Queries
The following prediction queries were defined: 1. New users to become “whales”: users who joined in the last 2 weeks that will generate at least
$500 in commission in the next 90 days 2. Reducing activity : users who were active in the last week that will reduce activity by 50% in the
next 30 days (but will not churn, and will still continue trading) 3. Churn in “whales”: currently active “whales” (as defined by their activity during the last 90 days),
who were active in the past week, to become inactive for the next 30 days 4. Will trade in Apple share for the first time: users who had never invested in Apple share, and
would buy it for the first time in the coming 30 days
Knowledge Sphere Manifestation of Queries
It is again important to note that the definition of the search queries is completely orthogonal to the
extraction of behavioral clusters and the generation of the Knowledge Sphere, which was done
independently of the queries definition.
Therefore, it is interesting to analyze the manifestation of the queries in the clusters detected by the system: Do the clusters contain information that is relevant to the definition of the queries, despite the fact that:
1. The clusters were extracted in a fully automatic way, using no semantic information about the
data, and –
2. The queries were defined after the clusters were extracted, and did not affect this process.
This analysis is done by measuring the number of clusters that contain a very high concentration of
“samples”; In other words, by looking for clusters that contain “many more examples than statistically
expected”.
A high number of such clusters (provided that it is significantly higher than the amount
received when randomly sampling the same population) proves the ability of this process to extract
valuable relevant semantic insights in a fully automatic way.
Comparison to Google TensorFlow
In this section a comparison between prediction process of the Endor system and Google’s
TensorFlow is presented. It is important to note that TensorFlow, like any other Deep Learning library,
faces some difficulties when dealing with data similar to the one under discussion:
1. An extremely uneven distribution of the number of records per user requires some canonization
of the data, which in turn requires:
2. Some manual work, done by an individual who has at least some understanding of data
science.
3. Some understanding of the semantics of the data, that requires an investment of time, as
well as access to the owner or provider of the data
4. A single-class classification, using an extremely uneven distribution of positive vs. negative
samples, tends to lead to the overfitting of the results and require some non-trivial maneuvering.
This again necessitates the involvement of an expert in Deep Learning (unlike the Endor system
which can be used by Business, Product or Marketing experts, with no perquisites in Machine
Learning or Data Science).
Traditional Methods
An expert in Deep Learning spent 2 weeks crafting a solution that would be based
on TensorFlow and has sufficient expertise to be able to handle the data. The solution that was created
used the following auxiliary techniques:
1.Trimming the data sequence to 200 records per customer, and padding the streams for users
who have less than 200 records with neutral records.
2.Creating 200 training sets, each having 1,000 customers (50% known positive labels, 50%
unknown) and then using these training sets to train the model.
3.Using sequence classification (RNN with 128 LSTMs) with 2 output neurons (positive,
negative), with the overall result being the difference between the scores of the two.
Observations (all statistics available in the white paper – and it’s stunning)
1.Endor outperforms Tensor Flow in 3 out of 4 queries, and results in the same accuracy in the 4th
.
2.The superiority of Endor is increasingly evident as the task becomes “more difficult” – focusing on
the top-100 rather than the top-500.
3.There is a clear distinction between “less dynamic queries” (becoming a whale, churn, reduce
activity” – for which static signals should likely be easier to detect) than the “Who will trade in
Apple for the first time” query, which are (a) more dynamic, and (b) have a very low baseline, such
that for the latter, Endor is 10x times more accurate!
4.As previously mentioned – the Tensor Flow results illustrated here employ 2 weeks of manual improvements done by a Deep Learning expert, whereas the Endor results are 100% automatic and the entire prediction process in Endor took 4 hours.
Clearly, the path going forward for predictive analytics and data science is Endor, Endor, and Endor again!
Predictions for the Future
Personally, one thing has me sold – the robustness of the Endor system to handle noise and missing data. Earlier, this was the biggest bane of the data scientist in most companies (when data engineers are not available). 90% of the time of a professional data scientist would go into data cleaning and data preprocessing since our ML models were acutely sensitive to noise. This is the first solution that has eliminated this ‘grunt’ level work from data science completely.
The second prediction: the Endor system works upon principles of human interaction dynamics. My intuition tells me that data collected at random has its own dynamical systems that appear clearly to experts in complexity theory. I am completely certain that just as this tool developed a prediction tool with human society dynamical laws, data collected in general has its own laws of invariance. And the first person to identify these laws and build another Endor-style platform on them will be at the top of the data science pyramid – the alpha unicorn.
Final prediction – democratizing data science means that now data scientists are not required to have six-figure salaries. The success of the Endor platform means that anyone can perform advanced data science without resorting to TensorFlow, Python, R, Anaconda, etc. This platform will completely disrupt the entire data science technological sector. The first people to master it and build upon it to formalize the rules of invariance in the case of general data dynamics will for sure make a killing.
It is an exciting time to be a data science researcher!
Data Science is a broad field and it would require quite a few things to learn to master all these skills.
Dimensionless has several resources to get started with.
The advancement in the analytical eco-space has reached new heights in the recent past. The emergence of new tools and techniques has certainly made life easier for an analytics professional to play around with the data. Moreover, the massive amounts of data that’s getting generated from diverse sources need huge computational power and storage system for analysis.
Three of the most commonly used terms in analytics are Data mining, Machine Learning, and Data Science which is a combination of both. In this blog post, we would look into each of these three buzzwords along with examples.
Data Mining:
By term ‘mining’ we refer to extracting some object by digging. Similarly, that analogy could be applied to data where information could be extracted by digging into it. Data mining is one of the most used terms these days. Unlike previously, our life is circulated entirely by big data and we have the tools and techniques to handle such voluminous diverse meaningful data.
In the data, there are a lot of patterns which people could discover once the data has been gathered from relevant sources. The hidden patterns could be extracted to provide valuable insights by combining multiple sources of data even if it is junk. This entire process is known as Data mining.
Now the data used for mining could be enterprise data which are restricted and secured and has privacy issues. It could also be an integration of multiple sources which includes financial data, third-party data, etc. The more the data available to us, the better it is as we need to find patterns and insights in sequential and non-sequential data.
The steps involved in data mining are –
Data Collection – This is one of the most important steps in Data mining as getting the correct data is always a challenge in any organization. To find patterns in the data, we need to ensure that the source of the data is accurate and as much as possible data is gathered.
Data Cleaning – A lot of the times the data we get is not clean enough to draw insights from it. There could be missing values, outliers, NULL in the data which needs to be handled either by deletion or by imputation based on its significance to the business.
Data Analysis – Once the data is gathered, and cleaned the next step is to analyze the data which in short known as Exploratory Data Analysis. Several techniques and methodologies are applied in this step to derive relevant insights from the data.
Data Interpretation – Only analyzing the data is worthless unless it is interpreted through the form of graphs or charts to the stakeholders or the business who would make conclusions based on the analysis.
Data mining has several usages in the real world. For example, if we take the logs data for login in a web application, we would see that the data is messy containing information like timestamp, activities of the user, time spent on the website, etc. However, if we clean the data, and then analyze it, we would find some relevant information from it such as the user’s regular habit, the peak time for most of the activities, and so on. All this information could help to increase the efficiency of the system.
Another example of data mining is in crime prevention. Though data mining has most usage in education and healthcare, it is also used by agencies in the crime department to spot patterns in the data. This data would consist of information about some of the criminal activities that have taken place. Hence, mining, and gathering information from the data would help the agencies to predict future crime events and prevent it from occurring. The agencies could mine the data and find out the place where the next crime could take place. They could also prevent cross-border calamity by understanding which vehicle to check, the age of the occupants, etc.
However, a few of the important points one should remember about Data Mining –
Data mining should not be considered as the first solution to any analysis task if other accurate solutions are applicable. It should be used when such solutions fail to provide value.
Sufficient amount of data should be present to draw insights from it.
The problem should be understood to be a Regression or a Classification one.
Machine Learning:
Previously, we learned about Data mining which is about gathering, cleaning, analyzing, and interpreting relevant insights from the data for the business to draw conclusions from it.
If Data mining is about describing a set of events, Machine Learning is about predicting the future events. It is the term coined to define a system which learns from past data to generalize and predict the future events from the unknown set of data.
Machine Learning could be divided into three categories –
Supervised Learning – In supervised learning, the target is labeled i.e., for every corresponding row there is an output value.
Unsupervised Learning – The data set is unlabelled in unsupervised learning i.e., one has to cluster the data into various groups based on the similarities in the pattern of the data points.
Reinforcement Learning – It is a special category of Machine Learning which is mostly used in self-driving cars. In reinforcement learning, the learner is rewarded for every correct move, and penalized for any incorrect move.
The field of Machine Learning is vast, and it requires a blend of statistics, programming, and most importantly data intuition to master it. Supervised and unsupervised learning are used to solve regression, classification, and clustering problems.
In regression problems, the target is numeric i.e., continuous or discrete in nature. A continuous value could be an integer, float, or a decimal, whereas a discrete value is a number or an integer.
In classification problems, the target is categorical i.e., binary, multinomial, or ordinal in nature.
In clustering problems, the dataset is grouped into different clusters based on the similar properties among the data in a particular group.
Machine Learning has a vast usage in various fields such as Banking, Insurance, Healthcare, Manufacturing, Oil and Gas, and so on. Professionals from various disciplines feel the need to predict future outcomes in order to work efficiently and prepare for the best by taking appropriate actions. Some of the real-life examples where Machine Learning has found its usage is –
Email Spam filtering – This is the first application of Machine Learning where an email is classified as ‘Spam’ or ‘Not Spam’ based on certain keywords in the mail. It is a binary classification supervised learning problem where the system is initially trained with a set of sample emails to learn the patterns which would help in filtering out irrelevant emails. Once the system has generalized well, it is passed through a validation set to check for its efficiency, and then through a test set to find its accuracy.
Credit Risk Analytics – Machine Learning has vast influence in the Banking, and Insurance domain with one of its usage being in predicting the delinquency of a loan by a borrower. Defaulting a credit loan is a prevalent issue in which the lender or the bank has lost millions by failing to identify the possibility of a borrower not repaying back the loans or meeting the contractual agreements. However, Machine Learning has been introduced by various banks which takes into several features of a borrower and builds a predictive model which helps in mitigating the risk involved in giving credit card loans to them.
Product Recommendations – Flipkart, and Amazon are of the two biggest e-commerce industry in the world where millions of users shop every day the products of their choice. However, there is a recommendation algorithm that works behind the scenes which simplify the life of the customer by displaying them the products they make like based on their previous shopping or search patterns. This is an example of unsupervised learning where a customer is grouped based on their shopping patterns.
Data Science:
So far, we have learned about the two most common and important terms in Analytics i.e., Data mining and Machine Learning.
If Data mining deals with understanding and finding hidden insights in the data, then Machine Learning is about taking the cleaned data and predicting future outcomes. All of these together form the core of Data Science.
Data Science is a holistic study which involves both Descriptive and Predictive Analytics. A Data Scientist needs to understand and perform exploratory analysis as well as employ tools, and techniques to make predictions from the data.
A Data Scientist role is a mixture of the work done by a Data Analyst, a Machine Learning Engineer, a Deep Learning Engineer, or an AI researcher. Apart from that, a Data Scientist might also be required to build data pipelines which is the work of a Data Engineer. The skill set of a Data Scientist consists of Mathematics, Statistics, Programming, Machine Learning, Big Data, and communication.
Some of the applications of Data Science in the modern world are –
Virtual assistant – Amazon’s Alexa, and Apple’s Siri are two of the biggest achievements in the recent past where AI has been used to build human-like intelligent systems. A virtual assistant could perform most of the tasks that a human being could with proper instructions.
ChatBot – Another common usage of Data Science is the ChatBot development which is now being integrated into almost every corporation. A technique called Natural Language Processing is in the core of ChatBot development.
Identifying cancer cells – Deep Learning has made tremendous progress in the healthcare sector where it is used to identify the pattern in the cells to predict whether it is cancerous or not. Deep Learning uses neural networks which functions like the human brain.
Conclusion
Data mining, Machine Learning, and Data Science is a broad field and it would require quite a few things to learn to master all these skills.
Dimensionless has several resources to get started with.
There are a huge number of ML algorithms out there. Trying to classify them leads to the distinction being made in types of the training procedure, applications, the latest advances, and some of the standard algorithms used by ML scientists in their daily work. There is a lot to cover, and we shall proceed as given in the following listing:
Statistical Algorithms
Classification
Regression
Clustering
Dimensionality Reduction
Ensemble Algorithms
Deep Learning
Reinforcement Learning
AutoML (Bonus)
1. Statistical Algorithms
Statistics is necessary for every machine learning expert. Hypothesis testing and confidence intervals are some of the many statistical concepts to know if you are a data scientist. Here, we consider here the phenomenon of overfitting. Basically, overfitting occurs when an ML model learns so many features of the training data set that the generalization capacity of the model on the test set takes a toss. The tradeoff between performance and overfitting is well illustrated by the following illustration:
Overfitting – from Wikipedia
Here, the black curve represents the performance of a classifier that has appropriately classified the dataset into two categories. Obviously, training the classifier was stopped at the right time in this instance. The green curve indicates what happens when we allow the training of the classifier to ‘overlearn the features’ in the training set. What happens is that we get an accuracy of 100%, but we lose out on performance on the test set because the test set will have a feature boundary that is usually similar but definitely not the same as the training set. This will result in a high error level when the classifier for the green curve is presented with new data. How can we prevent this?
Cross-Validation
Cross-Validation is the killer technique used to avoid overfitting. How does it work? A visual representation of the k-fold cross-validation process is given below:
From Quora
The entire dataset is split into equal subsets and the model is trained on all possible combinations of training and testing subsets that are possible as shown in the image above. Finally, the average of all the models is combined. The advantage of this is that this method eliminates sampling error, prevents overfitting, and accounts for bias. There are further variations of cross-validation like non-exhaustive cross-validation and nested k-fold cross validation (shown above). For more on cross-validation, visit the following link.
There are many more statistical algorithms that a data scientist has to know. Some examples include the chi-squared test, the Student’s t-test, how to calculate confidence intervals, how to interpret p-values, advanced probability theory, and many more. For more, please visit the excellent article given below:
Classification refers to the process of categorizing data input as a member of a target class. An example could be that we can classify customers into low-income, medium-income, and high-income depending upon their spending activity over a financial year. This knowledge can help us tailor the ads shown to them accurately when they come online and maximises the chance of a conversion or a sale. There are various types of classification like binary classification, multi-class classification, and various other variants. It is perhaps the most well known and most common of all data science algorithm categories. The algorithms that can be used for classification include:
Logistic Regression
Support Vector Machines
Linear Discriminant Analysis
K-Nearest Neighbours
Decision Trees
Random Forests
and many more. A short illustration of a binary classification visualization is given below:
From openclassroom.stanford.edu
For more information on classification algorithms, refer to the following excellent links:
Regression is similar to classification, and many algorithms used are similar (e.g. random forests). The difference is that while classification categorizes a data point, regression predicts a continuous real-number value. So classification works with classes while regression works with real numbers. And yes – many algorithms can be used for both classification and regression. Hence the presence of logistic regression in both lists. Some of the common algorithms used for regression are
Linear Regression
Support Vector Regression
Logistic Regression
Ridge Regression
Partial Least-Squares Regression
Non-Linear Regression
For more on regression, I suggest that you visit the following link for an excellent article:
Both articles have a remarkably clear discussion of the statistical theory that you need to know to understand regression and apply it to non-linear problems. They also have source code in Python and R that you can use.
4. Clustering
Clustering is an unsupervised learning algorithm category that divides the data set into groups depending upon common characteristics or common properties. A good example would be grouping the data set instances into categories automatically, the process being used would be any of several algorithms that we shall soon list. For this reason, clustering is sometimes known as automatic classification. It is also a critical part of exploratory data analysis (EDA). Some of the algorithms commonly used for clustering are:
Hierarchical Clustering – Agglomerative
Hierarchical Clustering – Divisive
K-Means Clustering
K-Nearest Neighbours Clustering
EM (Expectation Maximization) Clustering
Principal Components Analysis Clustering (PCA)
An example of a common clustering problem visualization is given below:
From Wikipedia
The above visualization clearly contains three clusters.
Another excellent article on clustering refer the link
Dimensionality Reduction is an extremely important tool that should be completely clear and lucid for any serious data scientist. Dimensionality Reduction is also referred to as feature selection or feature extraction. This means that the principal variables of the data set that contains the highest covariance with the output data are extracted and the features/variables that are not important are ignored. It is an essential part of EDA (Exploratory Data Analysis) and is nearly always used in every moderately or highly difficult problem. The advantages of dimensionality reduction are (from Wikipedia):
It reduces the time and storage space required.
Removal of multi-collinearity improves the interpretation of the parameters of the machine learning model.
It becomes easier to visualize the data when reduced to very low dimensions such as 2D or 3D.
It avoids the curse of dimensionality.
The most commonly used algorithm for dimensionality reduction is Principal Components Analysis or PCA. While this is a linear model, it can be converted to a non-linear model through a kernel trick similar to that used in a Support Vector Machine, in which case the technique is known as Kernel PCA. Thus, the algorithms commonly used are:
Ensembling means combining multiple ML learners together into one pipeline so that the combination of all the weak learners makes an ML application with higher accuracy than each learner taken separately. Intuitively, this makes sense, since the disadvantages of using one model would be offset by combining it with another model that does not suffer from this disadvantage. There are various algorithms used in ensembling machine learning models. The three common techniques usually employed in practice are:
Simple/Weighted Average/Voting: Simplest one, just takes the vote of models in Classification and average in Regression.
Bagging: We train models (same algorithm) in parallel for random sub-samples of data-set with replacement. Eventually, take an average/vote of obtained results.
Boosting: In this models are trained sequentially, where (n)th model uses the output of (n-1)th model and works on the limitation of the previous model, the process stops when result stops improving.
Stacking: We combine two or more than two models using another machine learning algorithm.
(from Amardeep Chauhan on Medium.com)
In all four cases, the combination of the different models ends up having the better performance that one single learner. One particular ensembling technique that has done extremely well on data science competitions on Kaggle is the GBRT model or the Gradient Boosted Regression Tree model.
We include the source code from the scikit-learn module for Gradient Boosted Regression Trees since this is one of the most popular ML models which can be used in competitions like Kaggle, HackerRank, and TopCoder.
GradientBoostingClassifier supports both binary and multi-class classification. The following example shows how to fit a gradient boosting classifier with 100 decision stumps as weak learners:
GradientBoostingRegressor supports a number of different loss functions for regression which can be specified via the argument loss; the default loss function for regression is least squares ('ls').
import numpy as np
from sklearn.metrics import mean_squared_error
from sklearn.datasets import make_friedman1
from sklearn.ensemble import GradientBoostingRegressor
X, y = make_friedman1(n_samples=1200, random_state=0, noise=1.0)
X_train, X_test = X[:200], X[200:]
y_train, y_test = y[:200], y[200:]
est = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1,
max_depth=1, random_state=0, loss='ls').fit(X_train, y_train)
mean_squared_error(y_test, est.predict(X_test))
You can also refer to the following article which discusses Random Forests, which is a (rather basic) ensembling method.
In the last decade, there has been a renaissance of sorts within the Machine Learning community worldwide. Since 2002, neural networks research had struck a dead end as the networks of layers would get stuck in local minima in the non-linear hyperspace of the energy landscape of a three layer network. Many thought that neural networks had outlived their usefulness. However, starting with Geoffrey Hinton in 2006, researchers found that adding multiple layers of neurons to a neural network created an energy landscape of such high dimensionality that local minima were statistically shown to be extremely unlikely to occur in practice. Today, in 2019, more than a decade of innovation later, this method of adding addition hidden layers of neurons to a neural network is the classical practice of the field known as deep learning.
Deep Learning has truly taken the computing world by storm and has been applied to nearly every field of computation, with great success. Now with advances in Computer Vision, Image Processing, Reinforcement Learning, and Evolutionary Computation, we have marvellous feats of technology like self-driving cars and self-learning expert systems that perform enormously complex tasks like playing the game of Go (not to be confused with the Go programming language). The main reason these feats are possible is the success of deep learning and reinforcement learning (more on the latter given in the next section below). Some of the important algorithms and applications that data scientists have to be aware of in deep learning are:
Long Short term Memories (LSTMs) for Natural Language Processing
Recurrent Neural Networks (RNNs) for Speech Recognition
Convolutional Neural Networks (CNNs) for Image Processing
Deep Neural Networks (DNNs) for Image Recognition and Classification
Hybrid Architectures for Recommender Systems
Autoencoders (ANNs) for Bioinformatics, Wearables, and Healthcare
Deep Learning Networks typically have millions of neurons and hundreds of millions of connections between neurons. Training such networks is such a computationally intensive task that now companies are turning to the 1) Cloud Computing Systems and 2) Graphical Processing Unit (GPU) Parallel High-Performance Processing Systems for their computational needs. It is now common to find hundreds of GPUs operating in parallel to train ridiculously high dimensional neural networks for amazing applications like dreaming during sleep and computer artistry and artistic creativity pleasing to our aesthetic senses.
Artistic Image Created By A Deep Learning Network. From blog.kadenze.com.
For more on Deep Learning, please visit the following links:
In the recent past and the last three years in particular, reinforcement learning has become remarkably famous for a number of achievements in cognition that were earlier thought to be limited to humans. Basically put, reinforcement learning deals with the ability of a computer to teach itself. We have the idea of a reward vs. penalty approach. The computer is given a scenario and ‘rewarded’ with points for correct behaviour and ‘penalties’ are imposed for wrong behaviour. The computer is provided with a problem formulated as a Markov Decision Process, or MDP. Some basic types of Reinforcement Learning algorithms to be aware of are (some extracts from Wikipedia):
1.Q-Learning
Q-Learning is a model-free reinforcement learning algorithm. The goal of Q-learning is to learn a policy, which tells an agent what action to take under what circumstances. It does not require a model (hence the connotation “model-free”) of the environment, and it can handle problems with stochastic transitions and rewards, without requiring adaptations. For any finite Markov decision process (FMDP), Q-learning finds a policy that is optimal in the sense that it maximizes the expected value of the total reward over any and all successive steps, starting from the current state. Q-learning can identify an optimal action-selection policy for any given FMDP, given infinite exploration time and a partly-random policy. “Q” names the function that returns the reward used to provide the reinforcement and can be said to stand for the “quality” of an action taken in a given state.
2.SARSA
State–action–reward–state–action (SARSA) is an algorithm for learning a Markov decision process policy. This name simply reflects the fact that the main function for updating the Q-value depends on the current state of the agent “S1“, the action the agent chooses “A1“, the reward “R” the agent gets for choosing this action, the state “S2” that the agent enters after taking that action, and finally the next action “A2” the agent choose in its new state. The acronym for the quintuple (st, at, rt, st+1, at+1) is SARSA.
3.Deep Reinforcement Learning
This approach extends reinforcement learning by using a deep neural network and without explicitly designing the state space. The work on learning ATARI games by Google DeepMind increased attention to deep reinforcement learning or end-to-end reinforcement learning. Remarkably, the computer agent DeepMind has achieved levels of skill higher than humans at playing computer games. Even a complex game like DOTA 2 was won by a deep reinforcement learning network based upon DeepMind and OpenAI Gym environments that beat human players 3-2 in a tournament of best of five matches.
For more information, go through the following links:
If reinforcement learning was cutting edge data science, AutoML is bleeding edge data science. AutoML (Automated Machine Learning) is a remarkable project that is open source and available on GitHub at the following link that, remarkably, uses an algorithm and a data analysis approach to construct an end-to-end data science project that does data-preprocessing, algorithm selection,hyperparameter tuning, cross-validation and algorithm optimization to completely automate the ML process into the hands of a computer. Amazingly, what this means is that now computers can handle the ML expertise that was earlier in the hands of a few limited ML practitioners and AI experts.
AutoML has found its way into Google TensorFlow through AutoKeras, Microsoft CNTK, and Google Cloud Platform, Microsoft Azure, and Amazon Web Services (AWS). Currently it is a premiere paid model for even a moderately sized dataset and is free only for tiny datasets. However, one entire process might take one to two or more days to execute completely. But at least, now the computer AI industry has come full circle. We now have computers so complex that they are taking the machine learning process out of the hands of the humans and creating models that are significantly more accurate and faster than the ones created by human beings!
The basic algorithm used by AutoML is Network Architecture Search and its variants, given below:
Network Architecture Search (NAS)
PNAS (Progressive NAS)
ENAS (Efficient NAS)
The functioning of AutoML is given by the following diagram:
If you’ve stayed with me till now, congratulations; you have learnt a lot of information and cutting edge technology that you must read up on, much, much more. You could start with the links in this article, and of course, Google is your best friend as a Machine Learning Practitioner. Enjoy machine learning!





















 This histogram represents a chi square distribution, so it is positively skewed
This histogram represents a chi square distribution, so it is positively skewed So in this box plot, the median is at 0 as in normal distribution, median is equal to mean.
So in this box plot, the median is at 0 as in normal distribution, median is equal to mean.






















